PyTorch C++扩展用于AMD GPU
PyTorch C++ Extension on AMD GPU — ROCm Blogs
本文演示了如何使用PyTorch C++扩展,并通过示例讨论了它相对于常规PyTorch模块的优势。实验在AMD GPU和ROCm 5.7.0软件上进行。有关支持的GPU和操作系统的更多信息,请参阅系统要求(Linux)。
介绍
由于易用性和模型的广泛可用性,PyTorch已成为机器学习从业者和爱好者的首选开发框架。PyTorch还允许您通过创建`torch.nn.Module`的派生类来轻松定制模型,这减少了与可微性相关的重复代码的需要。简而言之,PyTorch提供了广泛的支持。
但如果您想加速自定义模型呢?PyTorch提供了C++扩展来加速您的工作负载。这些扩展有优势:
• 它们为源外操作(PyTorch中不可用的操作)提供了一个快速的C++测试台,并且可以轻松集成到PyTorch模块中。
• 它们可以快速编译模型,无论是在CPU还是GPU上,只需一个附加的构建文件来编译C++模块。
PyTorch的自定义C++和CUDA扩展教程由Peter Goldsborough编写,这篇文章解释了PyTorch C++扩展如何减少模型的编译时间。PyTorch建立在一个C++后端之上,实现快速的计算操作。然而,构建PyTorch C++扩展的方式与PyTorch本身的构建方式不同。您可以在您的C++文件中包含PyTorch的库(torch.h),以充分利用PyTorch的`tensor`和`Variable`接口,同时使用原生的C++库,如`iostream`。下面的代码片段是从PyTorch教程中取的使用C++扩展的例子:
#include <torch/extension.h>#include <iostream>torch::Tensor d_sigmoid(torch::Tensor z) {auto s = torch::sigmoid(z);return (1 - s) * s;
}_d_sigmoid_函数计算了sigmoid函数的导数,并在后向传播中使用。您可以看到,实现是PyTorch的一个C++扩展。例如,`d_sigmoid`函数的返回值数据类型以及函数参数`z`是`torch::Tensor`。这是因为`torch/extension.h`头文件包含了著名的`ATen`张量计算库。让我们现在看看如何通过查看一个完整的示例来使用C++扩展来加速程序。

实现
在本节中,我们将在原生PyTorch和PyTorch C++中测试一个具有一个隐藏层的通用MLP网络。源代码受到了Peter的LLTM(长期记忆模型)示例的启发,我们为我们的MLP模型建立了类似的流程。
现在让我们在C++中实现_mlp_forward_和_mlp_backward_函数。PyTorch有`torch.autograd.Function`来在后台实现后向传递。PyTorch C++扩展要求我们在C++中定义后向传递,然后将它们绑定到PyTorch的`autograd`函数中。
如下所示,_mlp_forward_函数执行与MLP Python类中的计算相同,_mlp_backward_函数实现了输出相对于输入的导数。如果您对理解数学推导感兴趣,可以查看Prof. Tony Jebara的ML幻灯片中定义的_反向传播_部分中的后向传递方程。他代表了一个有两个隐藏层的MLP网络,并详细说明了后向传播的微分方程。为了简单起见,我们的示例中只考虑了一个隐藏层。请注意,在C++中编写自定义的微分方程是一项具有挑战性的任务,并且需要领域专家知识。
#include <torch/extension.h>
#include <vector>
#include <iostream>torch::Tensor mlp_forward( torch::Tensor input, torch::Tensor hidden_weights, torch::Tensor hidden_bias, torch::Tensor output_weights, torch::Tensor output_bias) { // Compute the input/hidden layer auto hidden = torch::addmm(hidden_bias, input, hidden_weights.t()); hidden = torch::relu(hidden); // Compute the output layer auto output = torch::addmm(output_bias, hidden, output_weights.t()); // Return the output return output; } std::vector<torch::Tensor> mlp_backward( torch::Tensor input, torch::Tensor hidden_weights, torch::Tensor hidden_bias, torch::Tensor output_weights, torch::Tensor output_bias,torch::Tensor grad_output) { // Compute the input/hidden layerauto hidden = torch::addmm(hidden_bias, input, hidden_weights.t());hidden = torch::relu(hidden); // Compute the output layer auto output = torch::addmm(output_bias, hidden, output_weights.t()); // Compute the gradients for output layerauto grad_output_weights = torch::mm(grad_output.t(), hidden);auto grad_output_bias = torch::sum(grad_output, /*dim=*/0).unsqueeze(0); // Compute the gradients for input/hidden layer using chain ruleauto grad_hidden = torch::mm(grad_output, output_weights);// grad_hidden = grad_hiddenauto grad_hidden_weights = torch::mm(grad_hidden.t(), input);auto grad_hidden_bias = torch::sum(grad_hidden, /*dim=*/0).unsqueeze(0);// Compute the gradients for inputauto grad_input = torch::mm(grad_hidden , hidden_weights);// Return the gradients return {grad_input, grad_hidden_weights, grad_hidden_bias, grad_output_weights, grad_output_bias};
}以下是将C++实现使用`ATen`的Python绑定函数封装起来的示例。`PYBIND11_MODULE`将关键字_forward_映射到`mlp_forward`函数的指针,以及_backward_映射到`mlp_backward`函数。这将C++实现绑定到Python定义。宏`TORCH_EXTENSION_NAME`将在构建时在setup.py文件中传递的名称定义。
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {m.def("forward", &mlp_forward, "MLP forward");m.def("backward", &mlp_backward, "MLP backward");
}接下来,编写一个`setup.py`文件,导入`setuptools`库来帮助编译C++代码。要构建并安装C++扩展,运行`python setup.py install`命令。该命令会创建所有与`mlp.cpp`文件相关的构建文件,并提供一个可以导入到PyTorch模块中的模块`mlp_cpp`。
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CppExtensionsetup(name='mlp_cpp',ext_modules=[CppExtension('mlp_cpp', ['mlp.cpp']),],cmdclass={'build_ext': BuildExtension})现在,让我们使用`torch.nn.Module`和`torch.autograd.Function`的帮助,准备一个由C++函数驱动的PyTorch的MLP类。这允许以更符合PyTorch原生方式使用C++函数。在下面的示例中,_MLP_类的forward函数指向`MLPFunction`的forward函数,它又指向C++的`mlp_forward`函数。这个信息流建立了一个工作流程,可以无缝地作为常规的PyTorch模型运行。
import math
from torch import nn
from torch.autograd import Function
import torchimport mlp_cpptorch.manual_seed(42)class MLPFunction(Function):@staticmethoddef forward(ctx, input, hidden_weights, hidden_bias, output_weights, output_bias):output = mlp_cpp.forward(input, hidden_weights, hidden_bias, output_weights, output_bias)variables = [input, hidden_weights, hidden_bias, output_weights, output_bias]ctx.save_for_backward(*variables)return output@staticmethoddef backward(ctx, grad_output):grad_input, grad_hidden_weights, grad_hidden_bias, grad_output_weights, grad_output_bias = mlp_cpp.backward( *ctx.saved_variables, grad_output)return grad_input, grad_hidden_weights, grad_hidden_bias, grad_output_weights, grad_output_biasclass MLP(nn.Module):def __init__(self, input_features=5, hidden_features=15):super(MLP, self).__init__()self.input_features = input_featuresself.hidden_weights = nn.Parameter(torch.rand(hidden_features,input_features))self.hidden_bias = nn.Parameter(torch.rand(1, hidden_features))self.output_weights = nn.Parameter(torch.rand(1,hidden_features))self.output_bias = nn.Parameter(torch.rand(1, 1))self.reset_parameters()def reset_parameters(self):stdv = 0.001for weight in self.parameters():weight.data.uniform_(-stdv, +stdv)def forward(self, input):return MLPFunction.apply(input, self.hidden_weights, self.hidden_bias, self.output_weights, self.output_bias)现在,让我们使用 [trainer.py](PyTorch C++ Extension on AMD GPU — ROCm Blogs) 来测试前向和后向计算的速度,并将原生 PyTorch 实现与 C++ 实现进行比较。
注意:在某些情况下,在进行基准测试以期望看到速度提升的趋势之前,你可能需要多次运行程序。
python trainer.py pyForward: 0.102 milliseconds (ms) | Backward 0.223 milliseconds (ms)我们可以看到,在 100,000 次运行中,原生 PyTorch 模型的平均前向传递时间是 0.102 毫秒,而对于 C++ 模型,它只需要 0.0904 毫秒(提升约 8%)。如果后向传递没有遵循相同的趋势,其实现可能没有优化。如前所述,将数学微分方程转换为 C++ 代码是一项具有挑战性的任务。随着模型的复杂性和大小的增加,在两个实验之间我们可能会看到更大的差异,正如 Peter 的 LLTM 示例中所注释的。尽管有一些实现挑战,C++ 正在证明它的速度更快,而且与 PyTorch 集成也更方便。
完整代码可以在 [src](PyTorch C++ Extension on AMD GPU — ROCm Blogs) 文件夹中找到,它包含了以下结构:
- [setup.py](https://rocm.blogs.amd.com/_downloads/1e638f7ade5de8f2cc73cd9f4ca07e54/setup.py) - 编译 C++ 模块的构建文件
- [mlp.cpp](https://rocm.blogs.amd.com/_downloads/72080e8113297740e24fb96f8fe46b65/mlp.cpp) - C++ 模块
- [mlp_cpp_train.py](https://rocm.blogs.amd.com/_downloads/00f3258c26bf3c8838dc72eb3a6ded8a/mlp_cpp_train.py) - 将 C++ 扩展应用于 PyTorch 模型
- [mlp_train.py](https://rocm.blogs.amd.com/_downloads/65248a2373711bbdef8139c524f96a28/mlp_train.py) - 用于对比的原生 PyTorch 实现
- [trainer.py](https://rocm.blogs.amd.com/_downloads/0d2415a09361672c52a5736a414ff5eb/trainer.py) - 用于测试 PyTorch 与 PyTorch 的 C++ 扩展的训练文件。

结论
这个博客通过一个使用自定义 PyTorch C++ 扩展的例子逐步向你演示。我们观察到,与原生 PyTorch 实现相比,自定义 C++ 扩展提高了模型的性能。这些扩展易于实现,并且可以轻松地插入到 PyTorch 模块中,预编译的开销很小。
此外,PyTorch 的 Aten 库为我们提供了大量功能,可以导入到 C++ 模块中,并模仿 PyTorch 风格的代码。总的来说,PyTorch C++ 扩展易于实现,是测试自定义操作在 CPU 和 GPU 上的性能的一个很好的选择。
致谢
我们想要感谢 Peter Goldsborough,因为他写了一篇非常精彩的[文章](Custom C++ and CUDA Extensions — PyTorch Tutorials 2.3.0+cu121 documentation)。
相关文章:
PyTorch C++扩展用于AMD GPU
PyTorch C Extension on AMD GPU — ROCm Blogs 本文演示了如何使用PyTorch C扩展,并通过示例讨论了它相对于常规PyTorch模块的优势。实验在AMD GPU和ROCm 5.7.0软件上进行。有关支持的GPU和操作系统的更多信息,请参阅系统要求(Linux…...
Hadoop archive
Index of /dist/hadoop/commonhttps://archive.apache.org/dist/hadoop/common/...

R语言——R语言基础
1、用repeat、for、while计算从1-10的所有整数的平方和 2、编写一个函数,给出两个正整数,计算他们的最小公倍数 3、编写一个函数,让用户输入姓名、年龄,得出他明年的年龄。用paste打印出来。例如:"Hi xiaoming …...

VFB电压反馈和CFB电流反馈运算放大器(运放)选择指南
VFB电压反馈和CFB电流反馈运算放大器(运放)选择指南 电流反馈和电压反馈具有不同的应用优势。在很多应用中,CFB和VFB的差异并不明显。当今的许多高速CFB和VFB放大器在性能上不相上下,但各有其优缺点。本指南将考察与这两种拓扑结构相关的重要考虑因素。…...
)
elasticsearch安装(centos7)
先给出网址 elasticsearch:Download Elasticsearch | Elastic elasticKibana:Download Kibana Free | Get Started Now | Elastic Logstash:Download Logstash Free | Get Started Now | Elastic ik分词:Releases infinilabs/…...
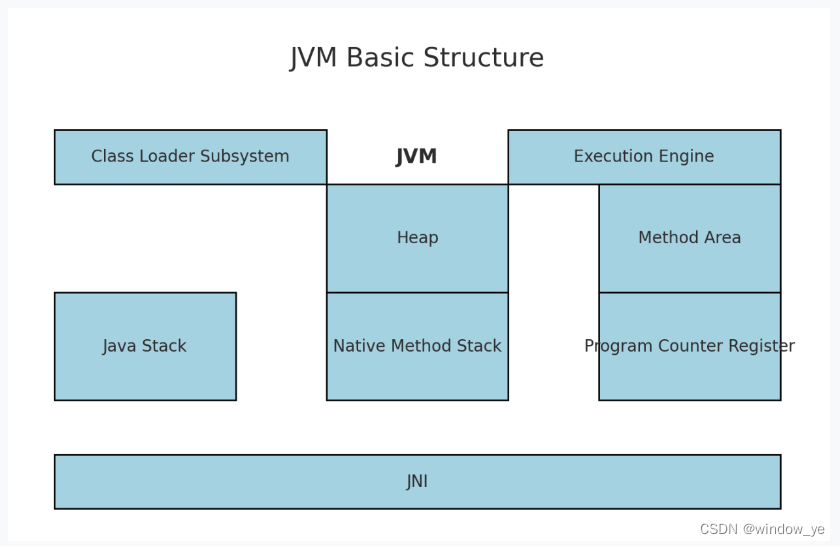
Java高手的30k之路|面试宝典|精通JVM(二)
JVM基本结构 类加载子系统:负责将.class文件加载到内存中,并进行验证、准备、解析和初始化。运行时数据区:包括堆(Heap)、方法区(Method Area)、Java栈(Java Stack)、本…...
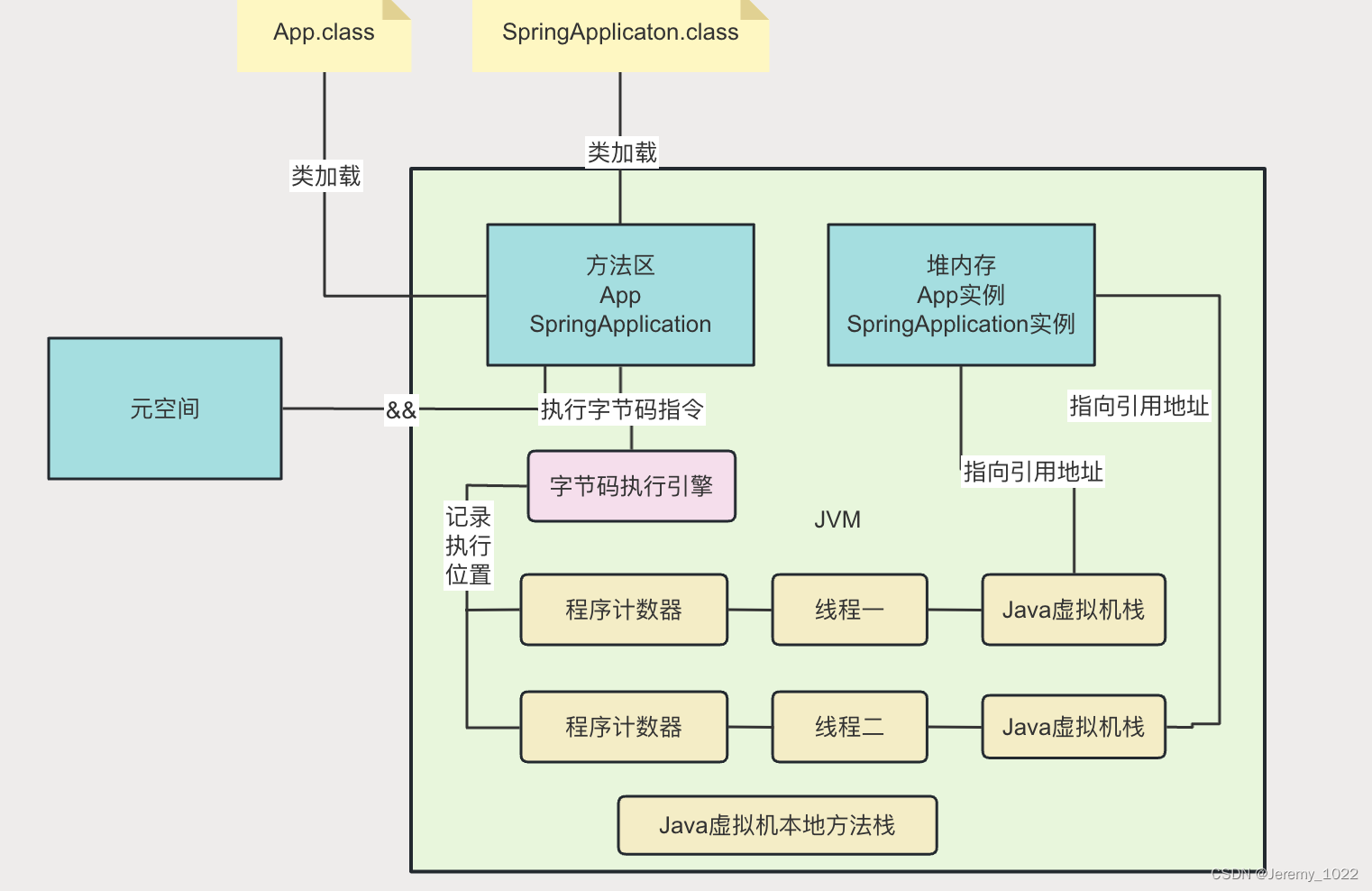
JVM专题六:JVM的内存模型
前面我们通过Java是如何编译、JVM的类加载机制、JVM类加载器与双亲委派机制等内容了解到了如何从我们编写的一个.Java 文件最终加载到JVM里的,今天我们就来剖析一下这个Java的‘中介平台’JVM里面到底长成啥样。 JVM的内存区域划分 Java虚拟机(JVM&…...

学习java第一百零七天
解释JDBC抽象和DAO模块 使用JDBC抽象和DAO模块,我们可以确保保持数据库代码的整洁和简单,并避免数据库资源关闭而导致的问题。它在多个数据库服务器给出的异常之上提供了一层统一的异常。它还利用Spring的AOP模块为Spring应用程序中的对象提供事务管理服…...
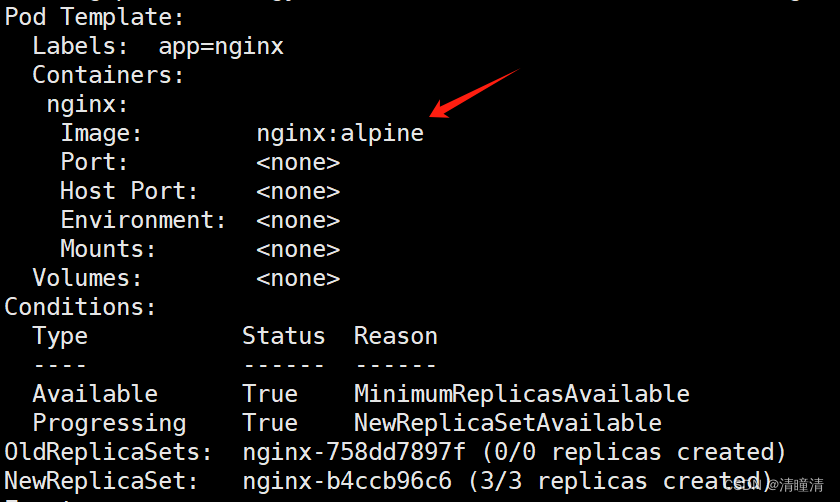
k8s上尝试滚动更新和回滚
滚动更新和回滚 实验目标: 学习如何进行应用的滚动更新和回滚操作。 实验步骤: 创建一个 Deployment。更新 Deployment 的镜像版本,观察滚动更新过程。回滚到之前的版本,验证回滚操作。 今天呢,我们继续来进行我们k…...
GitHub Copilot 登录账号激活,已经在IntellJ IDEA使用
GitHub Copilot 想必大家都是熟悉的,一款AI代码辅助神器,相信对编程界的诸位并不陌生。 今日特此分享一项便捷的工具,助您轻松激活GitHub Copilot,尽享智能编码之便利! GitHub Copilot 是由 GitHub 和 OpenAI 共同开…...
)
进程知识点(二)
文章目录 一、进程关系?二、孤儿态进程(Orphan)定义危害处理 三、僵尸进程定义处理 四、守护进程(Daemon )定义作用 总结 一、进程关系? 亲缘关系:亲缘关系主要体现于父子进程,子进程父进程创建,代码继承于父进程&…...

【线性代数】【一】1.6 矩阵的可逆性与线性方程组的解
文章目录 前言一、求解逆矩阵二、线性方程组的解的存在性总结 前言 前文我们引入了逆矩阵的概念,紧接着我们就需要讨论一个矩阵逆的存在性以及如何求解这个逆矩阵。最后再回归上最初的线性方程组的解,分析其中的联系。 一、求解逆矩阵 我们先回想一下在…...
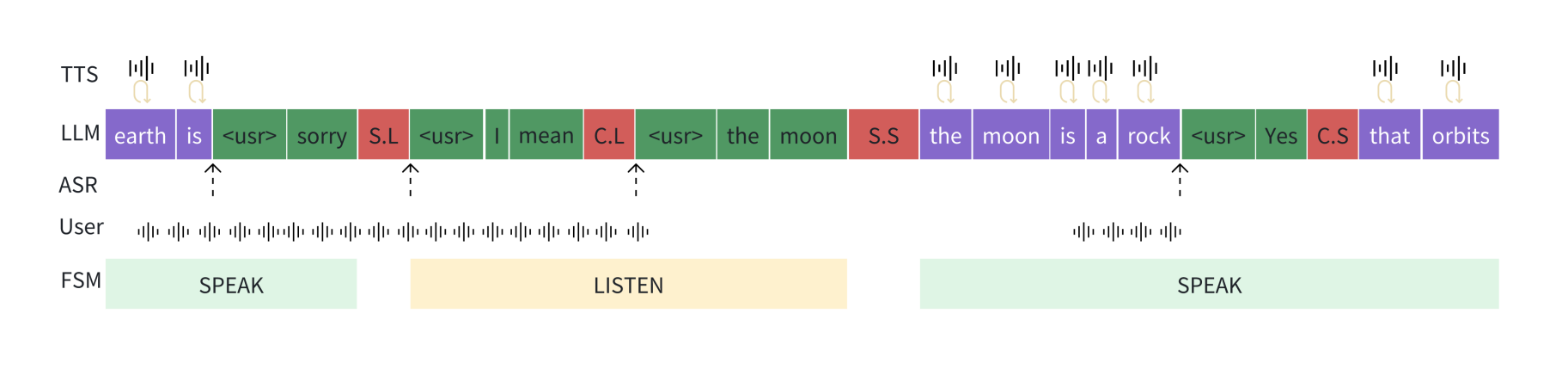
基于大型语言模型的全双工语音对话方案
摘要解读 我们提出了一种能够以全双工方式运行的生成性对话系统,实现了无缝互动。该系统基于一个精心调整的大型语言模型(LLM),使其能够感知模块、运动功能模块以及一个具有两种状态(称为神经有限状态机,n…...

Spring Boot集成Minio插件快速入门
1 Minio介绍 MinIO 是一个基于 Apache License v2.0 开源协议的对象存储服务。它兼容亚马逊 S3 云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小&…...

【C++新特性】右值引用
右值和右值的区别 C11 中右值可以分为两种:一个是将亡值( xvalue, expiring value),另一个则是纯右值( prvalue, PureRvalue): 纯右值:非引用返回的临时变量、运算表达式产生的临时变…...
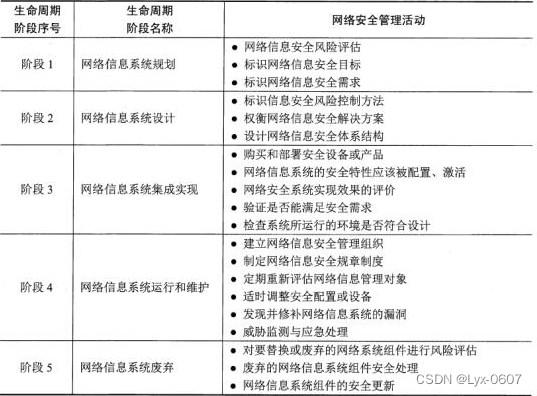
信息安全基础知识(完整)
信息安全基础知识 安全策略表达模型是一种对安全需求与安全策略的抽象概念表达,一般分为自主访问控制模型(HRU)和强制访问控制模型(BLP、Biba)IDS基本原理是通过分析网络行为(访问方式、访问量、与历史访问…...
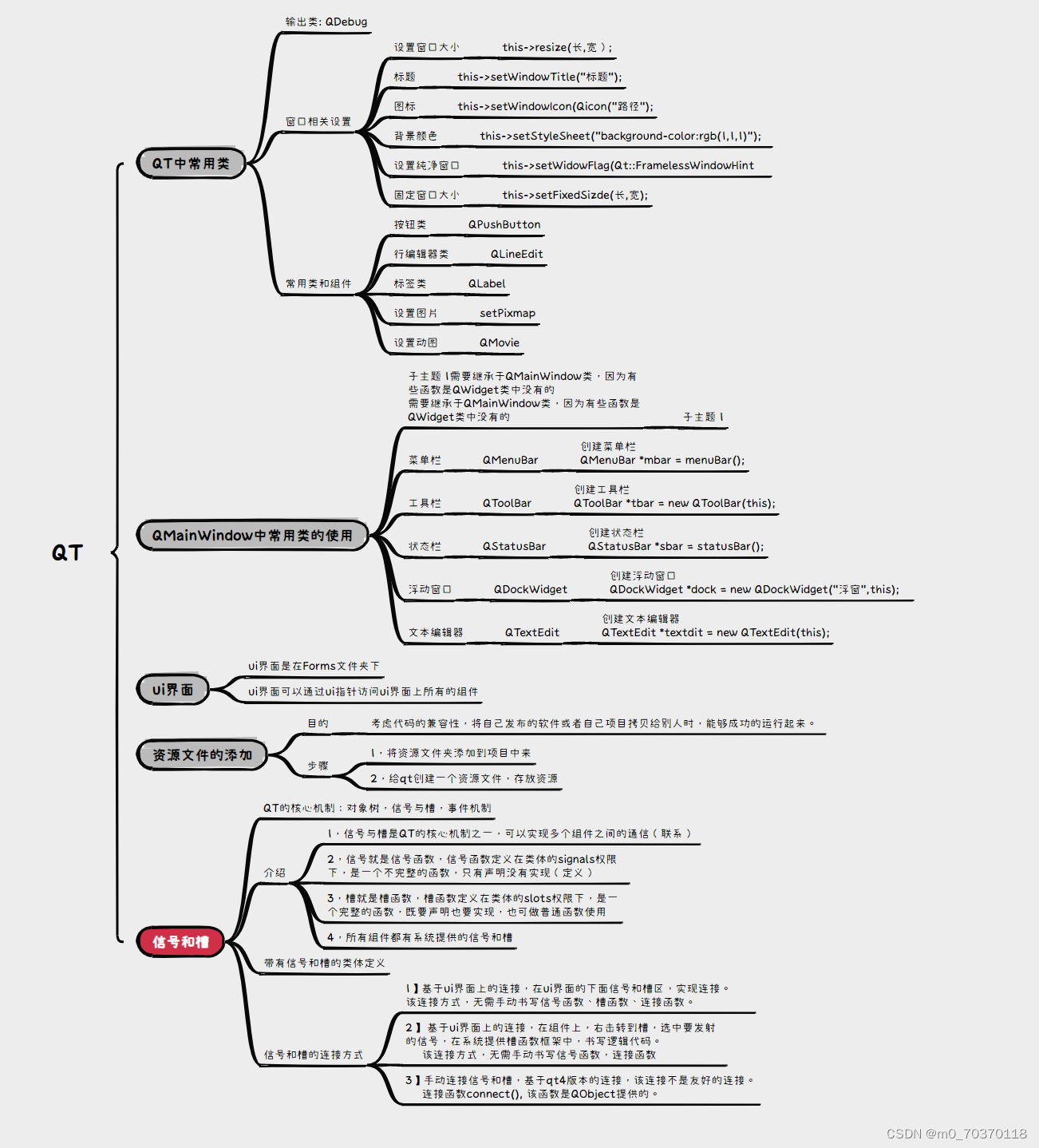
QT
#include "widget.h" #include "ui_widget.h" Widget::Widget(QWidget *parent) : QWidget(parent) , ui(new Ui::Widget) ,Gcancle(new QPushButton("取消",this)) ,EmmEdit(new QLineEdit(this)) { ui->setupUi(this);…...

双例集合(三)——双例集合的实现类之TreeMap容器类
Map接口有两个实现类,一个是HashMap容器类,另一个是TreeMap容器类。TreeMap容器类的使用在API上于HashMap容器类没有太大的区别。它们的区别主要体现在两个方面,一个是底层实现方式上,HashMap是基于Hash算法来实现的吗,…...

[SAP ABAP] 运算符
1.算数运算符 算术运算符描述加法-减法*乘法/除法MOD取余 示例1 输出结果: 输出结果: 2.比较运算符 比较运算符描述示例 等于 A B A EQ B <> 不等于 A <> B A NE B >大于 A > B A GT B <小于 A < B A LT B >大于或等于 A > B A GE B <小…...
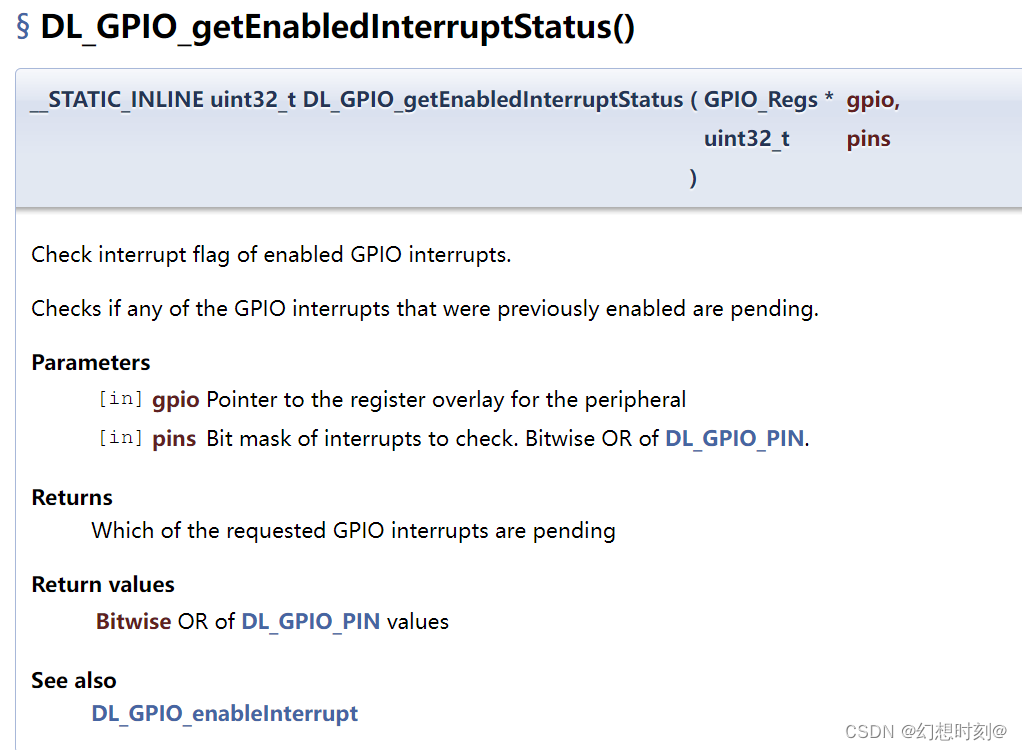
MSPM0G3507 ——GPIO例程讲解2——simultaneous_interrupts
主函数: #include "ti_msp_dl_config.h"int main(void) {SYSCFG_DL_init();/* Enable Interrupt for both GPIOA and GPIOB ports */NVIC_EnableIRQ(GPIO_SWITCHES_GPIOA_INT_IRQN); //启用SWITCHES——A的中断 NVIC_EnableIRQ(GPIO_S…...

如何快速解锁WeMod高级功能:面向游戏玩家的完整免费方案
如何快速解锁WeMod高级功能:面向游戏玩家的完整免费方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否为WeMod免费版的诸多限制感到…...

戴尔G15笔记本终极散热解决方案:TCC-G15开源温度控制中心完全指南
戴尔G15笔记本终极散热解决方案:TCC-G15开源温度控制中心完全指南 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 还在为戴尔G15笔记本玩游戏时过热…...

Linux巡检报告生成排查方法
Linux巡检报告生成排查方法本文面向具备一定 Linux 基础的技术人员,围绕巡检报告生成展开,重点讨论检查汇总、异常标记和结果归档。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

手机录音怎么转文字?2026实测免费付费工具对比与推荐
日常工作和生活中,我们常常需要把手机里的录音、语音转成文字。无论是记录会议内容、整理课堂笔记,还是提取视频文案,一个趁手的转录工具能节省大量时间。本文对市面上主流的手机录音转文字工具进行实测对比,帮你找到最适合的解决…...

告别Keil报错!手把手教你用MDK为国民技术N32G030K8L7搭建标准工程模板
国民技术N32G030K8L7开发实战:从零构建MDK工程模板的避坑指南 引言:为什么你的Keil工程总是编译失败? 刚拿到国民技术N32G030K8L7开发板时,许多开发者会直接套用STM32的工程模板习惯,结果在MDK环境下遭遇各种"玄学…...

手把手调优:如何榨干寒武纪MLU370系列卡的每一份算力?
寒武纪MLU370算力压榨实战:从芯片架构到BANG编程的深度调优指南 当一张价值数十万元的AI加速卡在数据中心里以30%的利用率运行时,每个周期都在烧掉本该属于企业的利润。寒武纪MLU370系列作为国产AI加速卡的代表作,其真实算力潜力往往被大多数…...

如何选择适合的贴片机:关键因素与选择指南
引言在现代电子制造业中,贴片机(Surface Mount Technology,简称SMT)作为核心设备之一,扮演着至关重要的角色。随着电子元器件的不断小型化和生产工艺的不断进步,选择一款合适的贴片机已经成为确保生产效率、…...

AI 挖洞新思路、深度解析两大间接提示词注入漏洞攻防思路,注入也能获得上万美金
0x01 简介 在移动 AI 领域,我已经很久没有关注过提示词注入漏洞了,在前两天关注到 Gemini 的漏洞之前,我对提示词注入的印象还停留在两年前,当时搞搞越狱,觉得这东西是纯内容安全,也只能等未来对能够进…...

2个实测免费的AI简历神器,简历回复率翻3倍,顺利过ATS机筛!
当前的求职市场,投简历简直像往海里扔石头。很多同学吐槽:明明自己挺优秀,投了100份简历却连一个面试邀请都没有。 其实,大厂HR第一轮根本不看简历,全是靠ATS(简历筛选系统)关键词过滤。如果你…...

跨越Android存储权限适配的深水区:从Android 11到13的实战避坑指南
1. 当存储权限遇上Android版本分裂:真实踩坑现场 去年接手一个图片下载功能时,我遭遇了职业生涯最诡异的兼容性问题。在荣耀Android 10、红米Android 11和小米Android 13上运行完美的代码,到了三星Galaxy S23 Ultra(Android 13&am…...