数据可视化实验二:回归分析、判别分析与聚类分析
目录
一、使用回归分析方法分析某病毒是否与温度呈线性关系
1.1 代码实现
1.2 线性回归结果
1.3 相关系数验证
二、使用判别分析方法预测某病毒在一定的温度下是否可以存活,分别使用三种判别方法,包括Fish判别、贝叶斯判别、LDA
2.1 数据集展示:实验二2-2.csv
2.2 代码实现
2.3 判别结果
三、使用聚类分析方法分析病毒与温度、湿度的关系
3.1 代码实现
3.2 聚类分析结果
未完待续-----
一、使用回归分析方法分析某病毒是否与温度呈线性关系
数据集:实验三2-1.xls
| T | COUNT |
| 5 | 1000 |
| 10 | 950 |
| 12 | 943 |
| 14 | 923 |
| 20 | 910 |
| 21 | 900 |
| 25 | 889 |
| 27 | 879 |
| 30 | 870 |
| 32 | 832 |
| 33 | 827 |
| 35 | 801 |
| 38 | 783 |
| 40 | 620 |
采用线性回归分析方法
1.1 代码实现
import pandas as pd
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# 中文字体调整
plt.rcParams['font.family'] = ['Arial Unicode Ms']# 读取 Excel 文件并创建数据框
file_path = '实验三3-1.xls'
data = pd.read_excel(file_path)# 定义自变量和因变量
X = data[['T']]
y = data['COUNT']# 创建并拟合线性回归模型
model = LinearRegression()
model.fit(X, y)# 获取回归系数和截距
slope = model.coef_[0]
intercept = model.intercept_# 打印回归方程
print(f"回归方程: 病毒存活数 = {intercept:.2f} + {slope:.2f} * 温度")# 绘制散点图和回归线
plt.scatter(X, y, color='blue', label='实际数据')
plt.plot(X, model.predict(X), color='red', linewidth=2, label='拟合回归线')
# 主题
plt.title('病毒存活数量与温度的线性关系')
plt.xlabel('温度(℃)') # x 轴标签添加属性和单位
plt.ylabel('病毒存活数量(个)') # y 轴标签添加属性和单位
plt.legend()
plt.show()1.2 线性回归结果
回归方程如下
 将线性回归结果绘制成如下图形
将线性回归结果绘制成如下图形
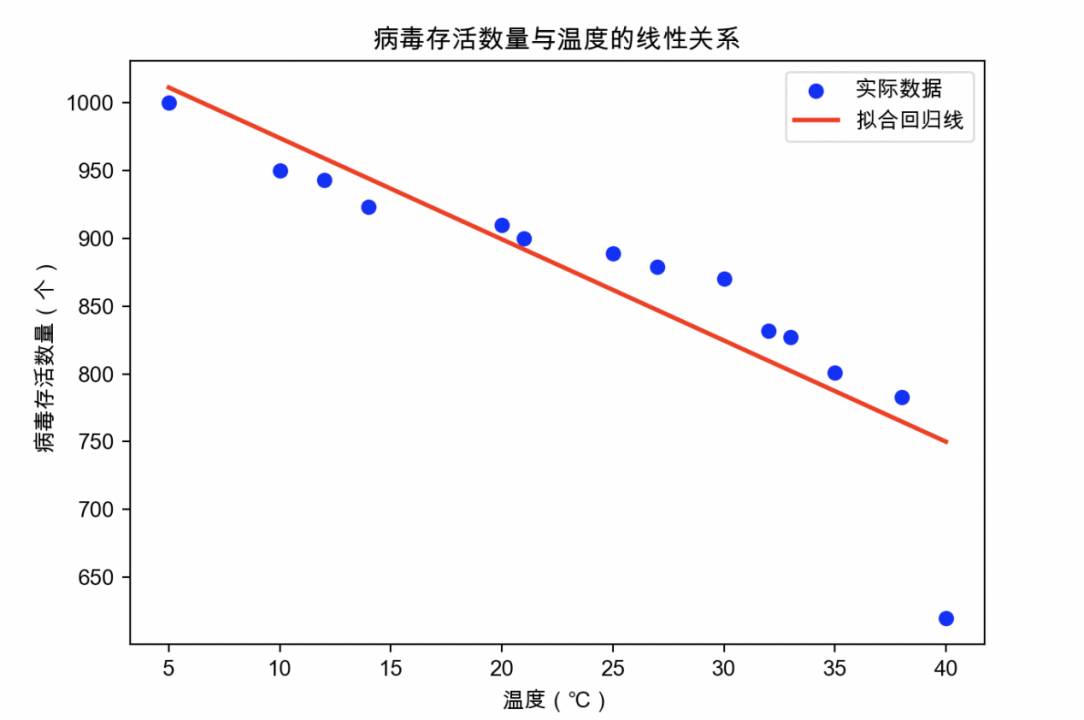
可以看出,除了40摄氏度下的病毒存活数量偏低,其他点都很好的符合回归方程: 病毒存活数 = 1048.50 + -7.46 * 温度。
1.3 相关系数验证
(1)代码如下
import pandas as pd# 读取 Excel 文件并创建数据框
file_path = '实验三3-1.xls'
data = pd.read_excel(file_path)# 计算 Pearson 相关系数
pearson_corr = data['T'].corr(data['COUNT'], method='pearson')# 计算 Spearman 相关系数
spearman_corr = data['T'].corr(data['COUNT'], method='spearman')print(f"Pearson 相关系数: {pearson_corr:.2f}")
print(f"Spearman 相关系数: {spearman_corr:.2f}")(2)根据数据集计算出的相关系数结果如下

根据计算结果可以得出结论:温度与病毒数量之间呈现出较强的负相关关系。
Pearson相关系数为-0.89,表明温度与病毒数量之间存在着高度负相关关系。即随着温度的升高,病毒数量呈现下降的趋势;反之,温度降低时,病毒数量则可能增加。Spearman相关系数为-1.00,说明温度与病毒数量之间存在着完全的负相关关系,即它们的关系是单调递减的,温度每上升一个单位,病毒数量就会减少一个单位。
综合以上分析,可以得出结论:温度与病毒数量之间呈现出明显的负相关关系,即温度的变化对病毒数量有着显著的影响,通常情况下温度升高会导致病毒数量减少,而温度降低则可能导致病毒数量增加。
二、使用判别分析方法预测某病毒在一定的温度下是否可以存活,分别使用三种判别方法,包括Fish判别、贝叶斯判别、LDA
2.1 数据集展示:实验二2-2.csv
| temperature | humidity | class |
| 5.127 | 74.978 | 1 |
| -9.274 | 96.247 | 1 |
| -21.371 | 79.613 | 1 |
| -37.5 | 85.109 | 1 |
| -51.325 | 69.282 | 1 |
| -52.477 | 80.49 | 0 |
| -39.804 | 71.718 | 1 |
| -30.588 | 60.388 | 1 |
| 1.671 | 69.788 | 1 |
| 13.191 | 78.306 | 1 |
| 38.537 | 60.747 | 1 |
| 52.938 | 65.94 | 1 |
| 53.882 | 73.829 | 0 |
| 23.675 | 60.753 | 1 |
2.2 代码实现
import pandas as pdfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
import numpy as np# 生成包含极端数据的随机数据
np.random.seed(42)
random_temperatures = np.array([-70.0, 45.0, 23.0, 9.0, -50.0, -50.0, 50.0, 36.0, 10.0, 20.0])
random_humidity = np.array([10.0, 98.0, 93.0, 68.0, 5.0, 100.0, 95.0, 80.0, 77.0, 70.0])new_data = pd.DataFrame({'temperature': random_temperatures, 'humidity': random_humidity})# 读取 Excel 文件并创建数据框
file_path = '实验三3-2.csv'
data = pd.read_excel(file_path)
df = pd.DataFrame(data)X = df[['temperature', 'humidity']]
y = df['class']# Fisher判别
lda = LinearDiscriminantAnalysis()
lda.fit(X, y)# 贝叶斯判别
nb = GaussianNB()
nb.fit(X, y)# LDA
qda = QuadraticDiscriminantAnalysis()
qda.fit(X, y)# 新数据预测
fisher_pred = lda.predict(new_data)
bayes_pred = nb.predict(new_data)
lda_pred = qda.predict(new_data)# 输出结果
result_map = {0: '不可以存活', 1: '可以存活'}
fisher_pred_label = [result_map[pred] for pred in fisher_pred]
bayes_pred_label = [result_map[pred] for pred in bayes_pred]
lda_pred_label = [result_map[pred] for pred in lda_pred]output_data = pd.DataFrame({'temperature': random_temperatures,'humidity': random_humidity,'Fisher判别预测结果': fisher_pred_label,'贝叶斯判别预测结果': bayes_pred_label,'LDA预测结果': lda_pred_label
})print("随机生成的10组数据及其三种判别结果:")
print(output_data)2.3 判别结果

三、使用聚类分析方法分析病毒与温度、湿度的关系
数据集与上题相同,此处不作呈现;
另外采用三种聚类分析方法,包括要求的k-均值聚类、层次聚类,还使用了高斯混合模型(GMM)聚类。
3.1 代码实现
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans, AgglomerativeClustering
from sklearn.mixture import GaussianMixture
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['Arial Unicode Ms']# 读取 Excel 文件并创建数据框
file_path = '实验三3-2.csv'
data = pd.read_excel(file_path)
df = pd.DataFrame(data)# k-均值聚类
kmeans = KMeans(n_clusters=2)
df['kmeans_cluster'] = kmeans.fit_predict(df[['temperature', 'humidity']])# 层次聚类
agg = AgglomerativeClustering(n_clusters=2)
df['agg_cluster'] = agg.fit_predict(df[['temperature', 'humidity']])# 高斯混合模型聚类
gmm = GaussianMixture(n_components=3)
df['gmm_cluster'] = gmm.fit_predict(df[['temperature', 'humidity']])# 定义红绿蓝颜色列表,熟悉的颜色,可视化效果会更好
colors_rgb = [(1, 0, 0), (0, 1, 0), (0, 0, 1)]# 可视化结果
plt.figure(figsize=(18, 6))
plt.subplot(131)
plt.scatter(df['temperature'], df['humidity'], c=[colors_rgb[i] for i in df['kmeans_cluster']])
plt.title('K-Means聚类分析结果')
plt.xlabel('温度')
plt.ylabel('湿度')plt.subplot(132)
plt.scatter(df['temperature'], df['humidity'], c=[colors_rgb[i] for i in df['agg_cluster']])
plt.title('层次聚类分析结果')
plt.xlabel('温度')
plt.ylabel('湿度')plt.subplot(133)
plt.scatter(df['temperature'], df['humidity'], c=[colors_rgb[i] for i in df['gmm_cluster']])
plt.title('高斯混合模型聚类分析结果')
plt.xlabel('温度')
plt.ylabel('湿度')plt.show()3.2 聚类分析结果
首先是对每种聚类分析方法中蔟数量的设置,在k-均值聚类方法和层次聚类方法中,蔟设置为2种;高斯混合模型聚类种,蔟设置为3种。
通过观察绘出的图像,可以观察到在高温高湿的条件下形成一类簇,而在低温低湿的条件下形成另一类簇。在低温低湿的条件更为密集,因此低温低湿更适合病毒的生存。
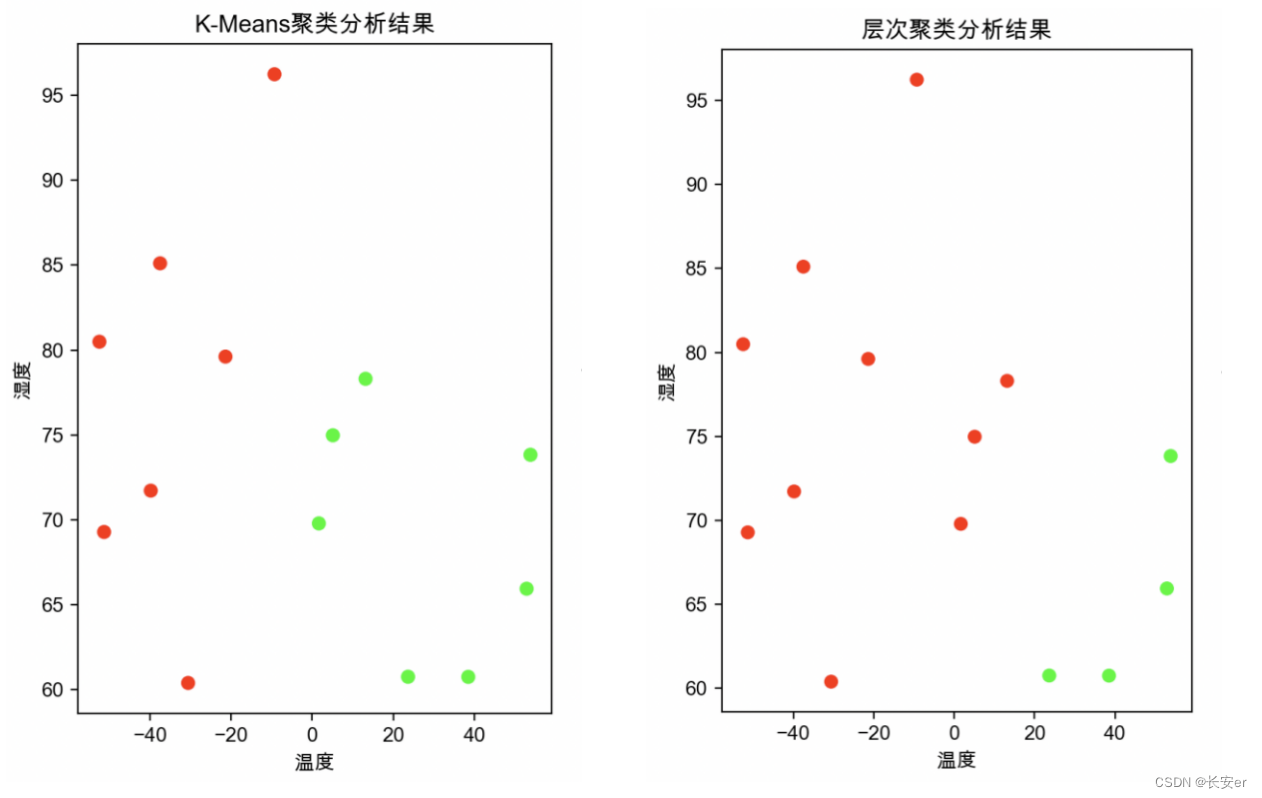
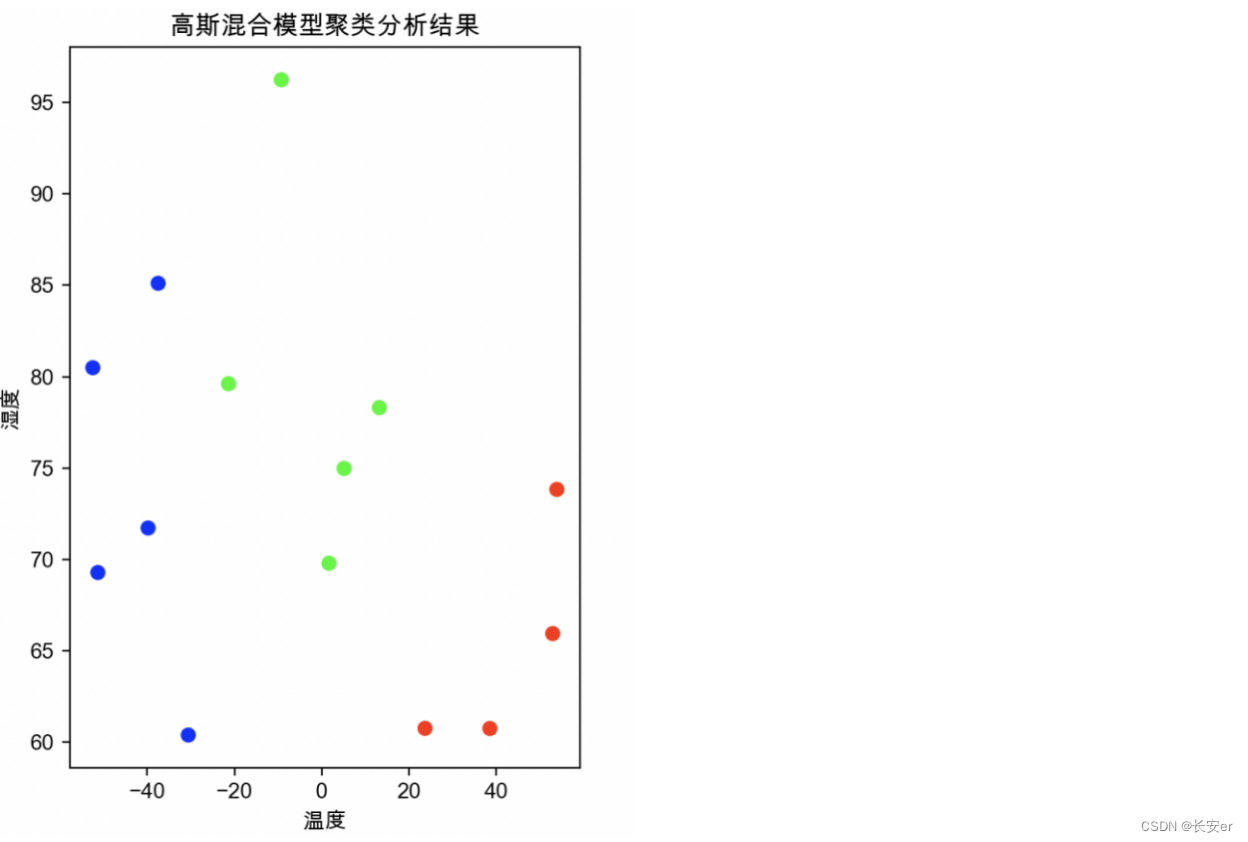
未完待续-----

其实我本以为最终上岸一定是很激动的,但却出奇的平静,但却又那么符合常理。出奇的是自己当初焦虑到做梦都是相关场景,理应非常激动,而不出奇的是与之前打比赛时的经历不谋而合,付出得越多反而越平静。此时的平静自许为成熟的平静,是对于一切结果的坦然,以及聚焦于当下道路的注意力,表现出来的就是当下没有多余的心情让我消费在结果上面,因为我认为人在与环境交互的过程中,总是需要学会接受一切正面和负面的反馈,并且使之不对自己当下的步伐产生负面影响,而这我认为是最大化我们目标的重要学习策略之一。
-------------ypp
相关文章:
数据可视化实验二:回归分析、判别分析与聚类分析
目录 一、使用回归分析方法分析某病毒是否与温度呈线性关系 1.1 代码实现 1.2 线性回归结果 1.3 相关系数验证 二、使用判别分析方法预测某病毒在一定的温度下是否可以存活,分别使用三种判别方法,包括Fish判别、贝叶斯判别、LDA 2.1 数据集展示&am…...

FL论文专栏|设备异构、异步联邦
论文:Asynchronous Federated Optimization(12th Annual Workshop on Optimization for Machine Learning) 链接 实现Server的异步更新。每次Server广播全局Model的时候附带一个时间戳,Client跑完之后上传将时间戳和Model同时带回…...
【Java毕业设计】基于JavaWeb的礼服租赁系统
文章目录 摘 要Abstract目录1 绪论1.1 课题背景和意义1.2 国内外研究现状1.2.1 国外研究现状 1.3 课题主要内容 2 开发相关技术介绍2.1 Spring Boot框架2.2 Vue框架2.3 MySQL数据库2.4 Redis数据库 3 系统分析3.1 需求分析3.1.1 用户需求分析3.1.2 功能需求分析 3.2 可行性分析…...

代码随想录训练营Day 66|卡码网101.孤岛的总面积、102.沉没孤岛、103.水流问题、104.建造最大岛屿
1.孤岛的总面积 101. 孤岛的总面积 | 代码随想录 代码:(bfs广搜) #include <iostream> #include <vector> #include <queue> using namespace std; int dir[4][2] {1,0,0,1,-1,0,0,-1}; int count; void bfs(vector<vector<int>>&a…...

根据状态转移写状态机-二段式
目录 描述 输入描述: 输出描述: 描述 题目描述: 如图所示为两种状态机中的一种,请根据状态转移图写出代码,状态转移线上的0/0等表示的意思是过程中data/flag的值。 要求: 1、 必须使用对应类型的状…...

PyTorch C++扩展用于AMD GPU
PyTorch C Extension on AMD GPU — ROCm Blogs 本文演示了如何使用PyTorch C扩展,并通过示例讨论了它相对于常规PyTorch模块的优势。实验在AMD GPU和ROCm 5.7.0软件上进行。有关支持的GPU和操作系统的更多信息,请参阅系统要求(Linux…...
Hadoop archive
Index of /dist/hadoop/commonhttps://archive.apache.org/dist/hadoop/common/...

R语言——R语言基础
1、用repeat、for、while计算从1-10的所有整数的平方和 2、编写一个函数,给出两个正整数,计算他们的最小公倍数 3、编写一个函数,让用户输入姓名、年龄,得出他明年的年龄。用paste打印出来。例如:"Hi xiaoming …...

VFB电压反馈和CFB电流反馈运算放大器(运放)选择指南
VFB电压反馈和CFB电流反馈运算放大器(运放)选择指南 电流反馈和电压反馈具有不同的应用优势。在很多应用中,CFB和VFB的差异并不明显。当今的许多高速CFB和VFB放大器在性能上不相上下,但各有其优缺点。本指南将考察与这两种拓扑结构相关的重要考虑因素。…...
)
elasticsearch安装(centos7)
先给出网址 elasticsearch:Download Elasticsearch | Elastic elasticKibana:Download Kibana Free | Get Started Now | Elastic Logstash:Download Logstash Free | Get Started Now | Elastic ik分词:Releases infinilabs/…...
Java高手的30k之路|面试宝典|精通JVM(二)
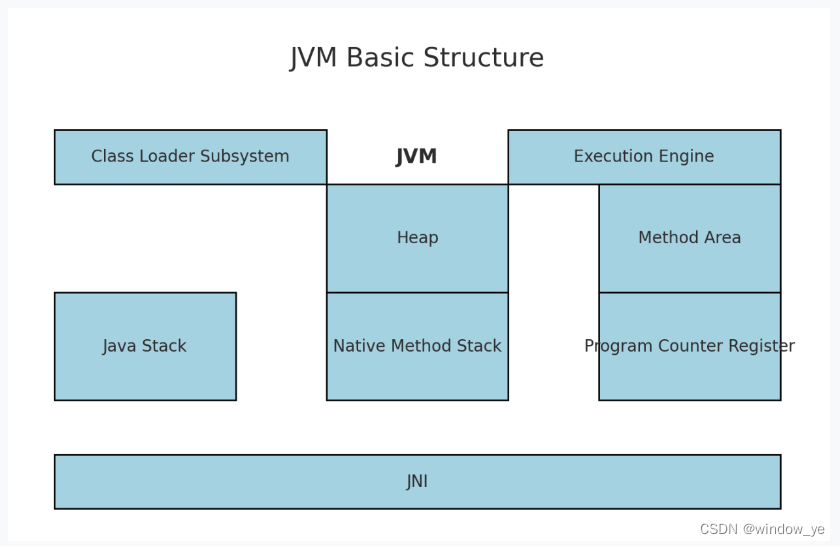
JVM基本结构 类加载子系统:负责将.class文件加载到内存中,并进行验证、准备、解析和初始化。运行时数据区:包括堆(Heap)、方法区(Method Area)、Java栈(Java Stack)、本…...
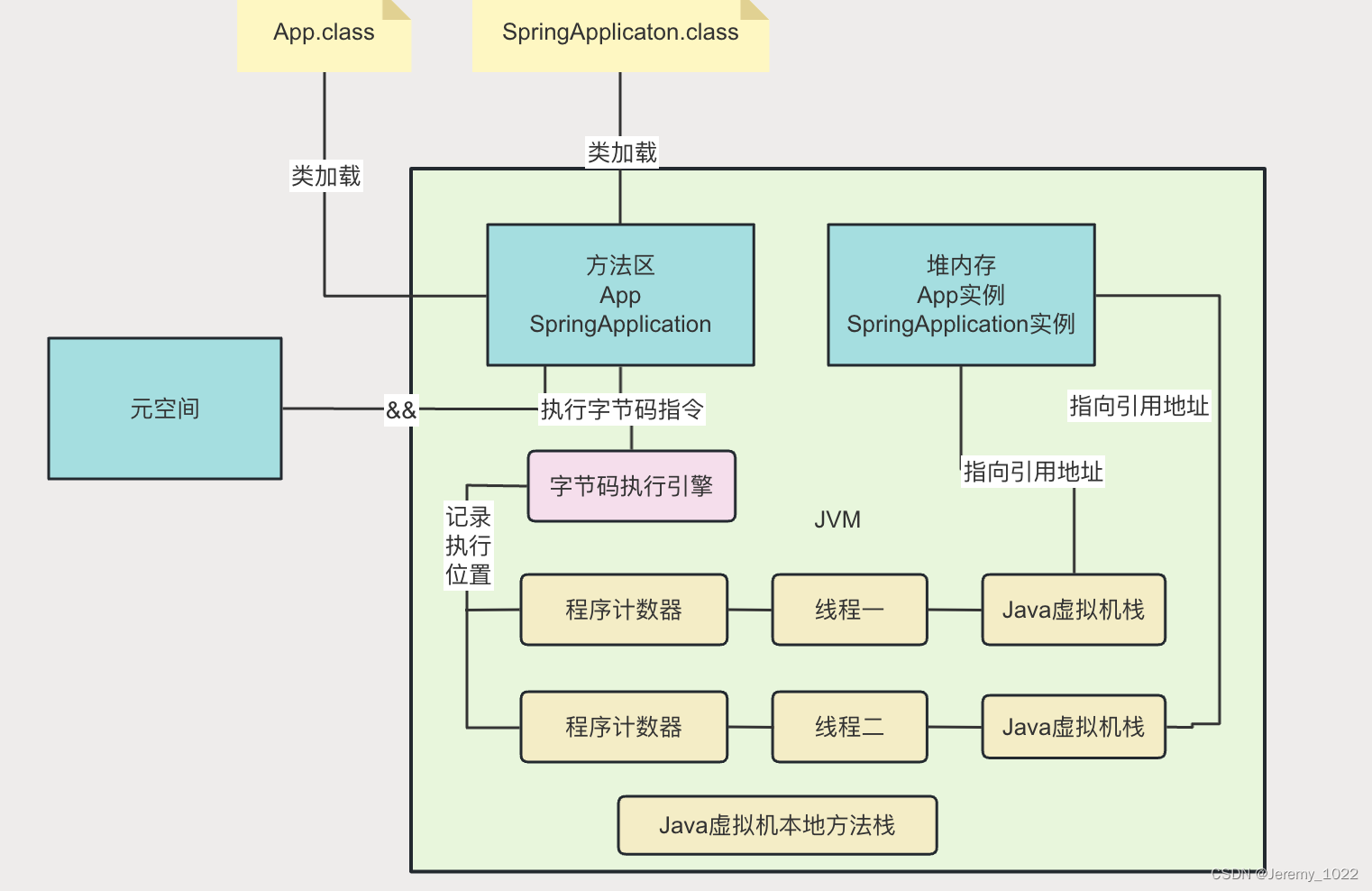
JVM专题六:JVM的内存模型
前面我们通过Java是如何编译、JVM的类加载机制、JVM类加载器与双亲委派机制等内容了解到了如何从我们编写的一个.Java 文件最终加载到JVM里的,今天我们就来剖析一下这个Java的‘中介平台’JVM里面到底长成啥样。 JVM的内存区域划分 Java虚拟机(JVM&…...

学习java第一百零七天
解释JDBC抽象和DAO模块 使用JDBC抽象和DAO模块,我们可以确保保持数据库代码的整洁和简单,并避免数据库资源关闭而导致的问题。它在多个数据库服务器给出的异常之上提供了一层统一的异常。它还利用Spring的AOP模块为Spring应用程序中的对象提供事务管理服…...
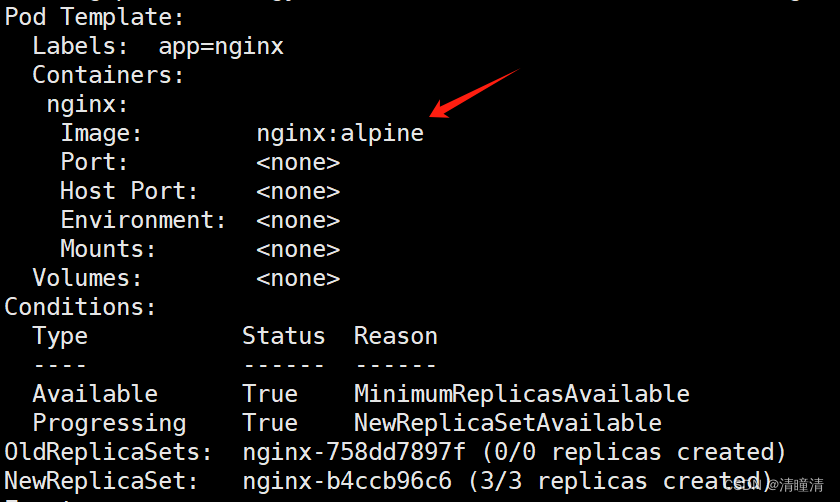
k8s上尝试滚动更新和回滚
滚动更新和回滚 实验目标: 学习如何进行应用的滚动更新和回滚操作。 实验步骤: 创建一个 Deployment。更新 Deployment 的镜像版本,观察滚动更新过程。回滚到之前的版本,验证回滚操作。 今天呢,我们继续来进行我们k…...
GitHub Copilot 登录账号激活,已经在IntellJ IDEA使用
GitHub Copilot 想必大家都是熟悉的,一款AI代码辅助神器,相信对编程界的诸位并不陌生。 今日特此分享一项便捷的工具,助您轻松激活GitHub Copilot,尽享智能编码之便利! GitHub Copilot 是由 GitHub 和 OpenAI 共同开…...
)
进程知识点(二)
文章目录 一、进程关系?二、孤儿态进程(Orphan)定义危害处理 三、僵尸进程定义处理 四、守护进程(Daemon )定义作用 总结 一、进程关系? 亲缘关系:亲缘关系主要体现于父子进程,子进程父进程创建,代码继承于父进程&…...

【线性代数】【一】1.6 矩阵的可逆性与线性方程组的解
文章目录 前言一、求解逆矩阵二、线性方程组的解的存在性总结 前言 前文我们引入了逆矩阵的概念,紧接着我们就需要讨论一个矩阵逆的存在性以及如何求解这个逆矩阵。最后再回归上最初的线性方程组的解,分析其中的联系。 一、求解逆矩阵 我们先回想一下在…...
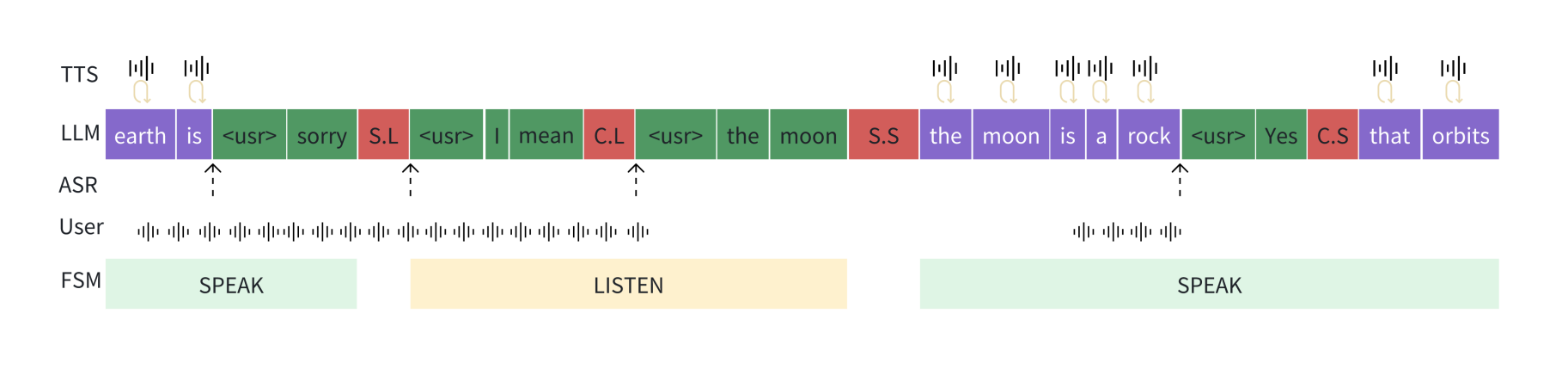
基于大型语言模型的全双工语音对话方案
摘要解读 我们提出了一种能够以全双工方式运行的生成性对话系统,实现了无缝互动。该系统基于一个精心调整的大型语言模型(LLM),使其能够感知模块、运动功能模块以及一个具有两种状态(称为神经有限状态机,n…...

Spring Boot集成Minio插件快速入门
1 Minio介绍 MinIO 是一个基于 Apache License v2.0 开源协议的对象存储服务。它兼容亚马逊 S3 云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小&…...

【C++新特性】右值引用
右值和右值的区别 C11 中右值可以分为两种:一个是将亡值( xvalue, expiring value),另一个则是纯右值( prvalue, PureRvalue): 纯右值:非引用返回的临时变量、运算表达式产生的临时变…...
)
自指系统在生命科学领域的机制与原理(世毫九实验室科普系列)
自指系统在生命科学领域的机制与原理(世毫九实验室科普系列) 作者:方见华 单位:世毫九实验室 1. 引言:自指系统的概念界定与研究意义 1.1 自指系统的定义与特征 自指系统(Self-referential Systems…...
)
手把手教你用TMS320F2803x DSP实现PMBus通信(附代码下载与避坑指南)
TMS320F2803x DSP实战:PMBus通信从零搭建到波形调试全攻略 1. 工程搭建与开发环境配置 在开始PMBus通信开发前,需要准备完整的软硬件环境。以下是基于TI C2000系列DSP的典型配置流程: 硬件准备清单: TMS320F2803x开发板࿰…...

FPGA静态侧信道攻击防御与传感器绕过技术解析
1. FPGA安全防御机制与静态侧信道攻击概述在现代数字安全领域,现场可编程门阵列(FPGA)因其可重构性和高性能特性,已成为加密加速、信号处理等关键应用的核心组件。然而,FPGA面临的物理安全威胁与日俱增,特别是针对硬件的侧信道攻击…...

基于ESP8266与TFT屏的桌面智能天气站DIY全攻略
1. 项目概述:打造一个桌面级的智能天气信息中心 几年前,当我第一次把玩ESP8266这块小芯片时,就被它“麻雀虽小,五脏俱全”的特性震撼了——一个比硬币大不了多少的模块,竟然内置了完整的Wi-Fi协议栈和可编程的微控制器…...

从官方例程到实战:剖析lwip+FreeRTOS在Zynq7020上的TCP热拔插实现与任务调度优化
1. 官方例程热拔插实现机制拆解 第一次在Zynq7020上看到TCP热拔插功能时,确实让我这个老嵌入式工程师也眼前一亮。官方例程里那个看似简单的link_detect_thread任务,实际上藏着不少精妙设计。我们先从PHY芯片的状态检测说起——这个看似基础的操作&#…...

Gita异步执行机制详解:高效管理大型项目的核心技术
Gita异步执行机制详解:高效管理大型项目的核心技术 【免费下载链接】gita Manage many git repos with sanity 从容管理多个git库 项目地址: https://gitcode.com/gh_mirrors/gi/gita 在现代软件开发中,开发者经常需要同时管理多个Git仓库。随着项…...
)
TVA智能体范式的工业视觉革命(8)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

Spring AI + Ollama 深度实战:从 RAG 问答到 Graph Agent 全流程指南
场景 Spring AI RAG 检索增强生成:概念、实战与完整代码: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/161055108 基于上面的基础,实现Graph工作流编排的简单示例。 大语言模型(LLM)在实际应用中面…...

大语言模型在模块化布局优化中的应用与实战
1. 项目概述:当大语言模型遇见模块化布局优化在芯片设计和建筑规划领域,模块布局优化一直是个令人头疼的NP难问题。想象一下,你面前有16个形状各异的乐高积木(模块),需要将它们严丝合缝地拼成一个矩形底板&…...

Elsevier投稿追踪插件:科研工作者的智能审稿管家
Elsevier投稿追踪插件:科研工作者的智能审稿管家 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 当您的论文投稿到Elsevier期刊后,漫长的审稿等待期往往成为科研工作者的焦虑来源。Elsevier投…...