Pip换源详解
Pip换源是指将pip(Python的包管理工具)的默认源更改为其他源。以下是关于Pip换源的详细说明:
一、Pip换源的原因
- 访问被阻止的源:在某些地区或网络环境下,直接访问官方的Python Package Index (PyPI) 可能受到限制或被阻止,此时需要更换为可访问的源。
- 提高下载速度:由于官方源在全球范围内被广泛使用,当在国内访问时,可能会受到网络延迟和带宽限制的影响,导致下载速度较慢。因此,切换到国内的镜像源可以显著提高下载速度。
- 使用特定的镜像源:为了获取特定版本的包或避免某些包的兼容性问题,可能需要更换为相应的源。
二、Pip换源的方法
- 临时切换pip源
- 使用命令行参数:在运行pip命令时,使用
-i参数指定源地址。例如:pip install <package_name> -i <mirror_url>。 - 使用环境变量:在Linux或macOS系统上,可以通过
export PIP_INDEX_URL=<mirror_url>来设置环境变量;在Windows系统上,可以使用set PIP_INDEX_URL=<mirror_url>。
- 使用命令行参数:在运行pip命令时,使用
- 永久切换pip源
- 修改pip配置文件:在Linux和macOS上,配置文件通常位于
~/.pip/pip.conf;在Windows上,配置文件位于%APPDATA%\pip\pip.ini。如果文件不存在,可以手动创建。在文件中添加类似以下内容:[global] index-url=<mirror_url>。 - 使用pip命令设置:执行
pip config set global.index-url <mirror_url>命令,pip会自动创建或更新配置文件,并将默认源设置为你指定的地址。
- 修改pip配置文件:在Linux和macOS上,配置文件通常位于
三、常用镜像源地址
- 清华大学开源软件镜像站:
https://pypi.tuna.tsinghua.edu.cn/simple - 阿里云开源镜像站:
https://mirrors.aliyun.com/pypi/simple - 中国科学技术大学:
http://mirrors.ustc.edu.cn/pypi/web/simple/ - 豆瓣开源镜像站:
http://pypi.douban.com/simple/
四、注意事项
- 不同的pip版本可能有略微不同的配置文件格式,具体请参考你所使用的pip版本的文档。
- 在选择镜像源时,建议根据自己所在的地区和网络环境选择合适的镜像源,以获得最佳的下载速度和稳定性。
- 如果遇到无法下载或安装的问题,可以尝试清除pip的缓存(使用
pip cache purge命令),然后再尝试从新的源进行下载和安装。
后续会持续更新分享相关内容,记得关注哦!
相关文章:

Pip换源详解
Pip换源是指将pip(Python的包管理工具)的默认源更改为其他源。以下是关于Pip换源的详细说明: 一、Pip换源的原因 访问被阻止的源:在某些地区或网络环境下,直接访问官方的Python Package Index (PyPI) 可能受到限制或…...

【Docker】——安装镜像和创建容器,详解镜像和Dockerfile
前言 在此记录一下docker的镜像和容器的相关注意事项 前提条件:已安装Docker、显卡驱动等基础配置 1. 安装镜像 网上有太多的教程,但是都没说如何下载官方的镜像,在这里记录一下,使用docker安装官方的镜像 Docker Hub的官方链…...
利用LinkedHashMap实现一个LRU缓存
一、什么是 LRU LRU是 Least Recently Used 的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。 简单的说就是,对于一组数据,例如:int[] a {1,2,3,4,5,6},…...

git-pull详解
NAME git-pull - Fetch from and integrate with another repository or a local branch SYNOPSIS git pull [<options>] [<repository> [<refspec>…]] DESCRIPTION Incorporates changes from a remote repository into the current branch. If the…...
、count(*) 与 count(列名) 的区别)
【SQL】count(1)、count(*) 与 count(列名) 的区别
在 SQL 中,COUNT 函数用于计算查询结果集中的行数。COUNT(1)、COUNT(*) 和 COUNT(列名) 都可以用来统计行数,但它们在实现细节和使用场景上有一些区别。以下是详细的解释: 1. COUNT(1) 定义: COUNT(1) 计算查询结果集中的行数。实现: 在执行…...

03-ES6新语法
1. ES6 函数 1.1 函数参数的扩展 1.1.1 默认参数 function fun(name,age17){console.log(name","age); } fn("张美丽",18); // "张美丽",18 fn("张美丽",""); // "张美丽" fn("张美丽"); // &…...

Linux中的文本编辑器vi与vim
摘要: 本文将深入探讨VI和VIM编辑器的基本概念、特点、使用方法以及它们在Linux环境中的重要性。通过对这两款强大的文本编辑器的详细分析,读者将能够更全面地理解它们的功能,并掌握如何有效地使用它们进行日常的文本编辑和处理任务。 引言&…...
)
MATLAB基础应用精讲-【数模应用】三因素方差(附R语言、MATLAB和python代码实现)
目录 几个高频面试题目 群体分布是否服从高斯分布? 数据是否不匹配? “误差”是否独立存在? 您是否真的想比较平均值? 是否存在三项因素? 这三项因素是否均属于“固定因素”,而非“随机因素”? 算法原理 EXCEL spss三因素方差分析步骤 一、spss三因素…...
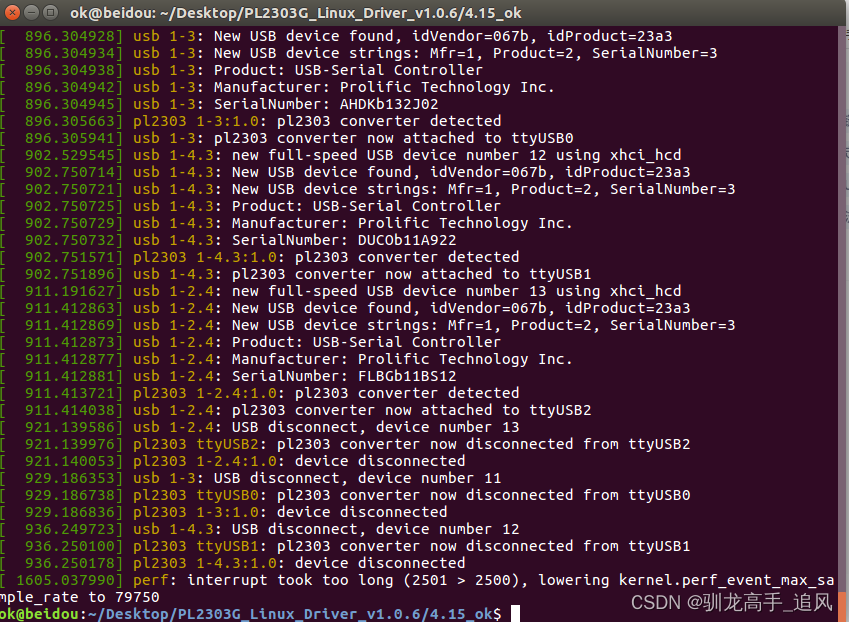
Linux ubuntu安装pl2303USB转串口驱动
文章目录 1.绿联PL2303串口驱动下载2.驱动安装3.验证方法 1.绿联PL2303串口驱动下载 下载地址:https://www.lulian.cn/download/16-cn.html 也可以直接通过CSDN下载:https://download.csdn.net/download/Axugo/89447539 2.驱动安装 下载后解压找到Lin…...
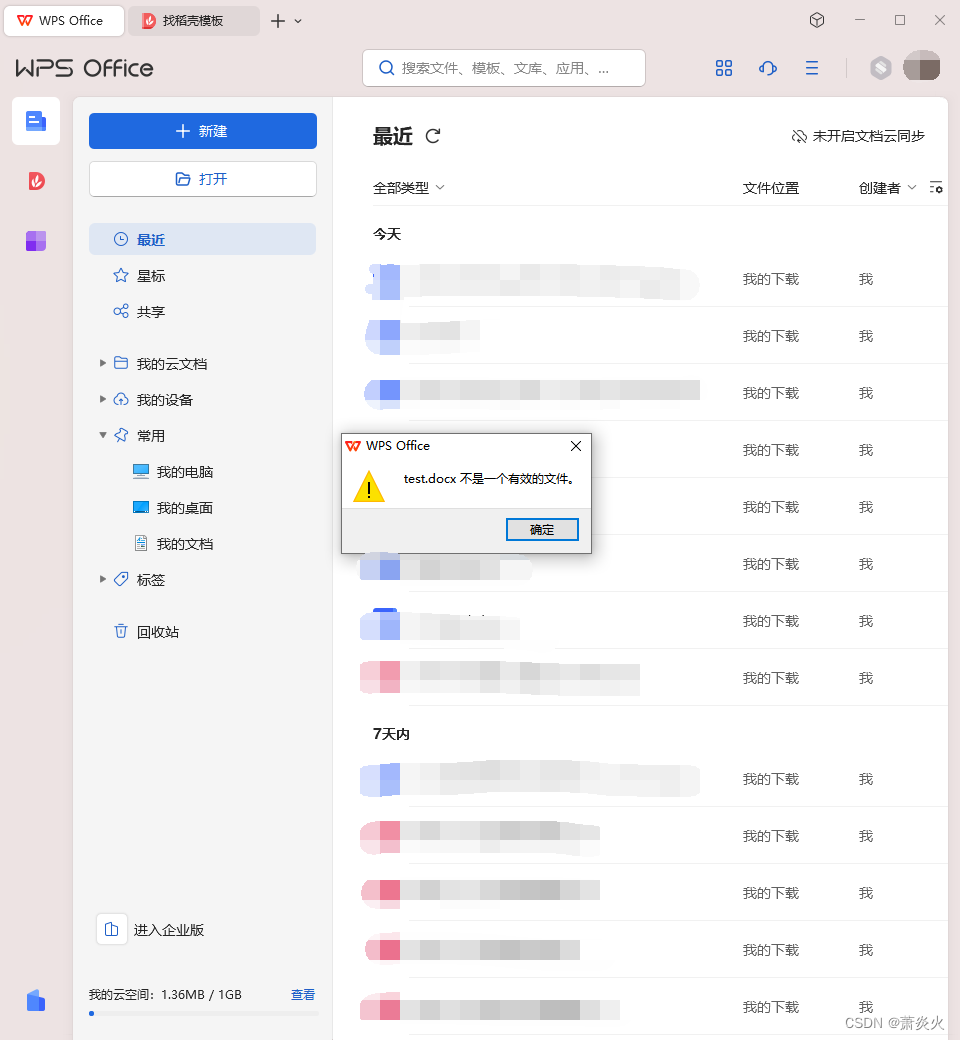
关于使用命令行打开wps word文件
前言 在学习python-docx时,想在完成运行时使用命令行打开生成的docx文件。 总结 在经过尝试后,得出以下代码: commandrstart "C:\Users\86136\AppData\Local\Kingsoft\WPS Office\12.1.0.16929\office6\wps.exe" "./result…...
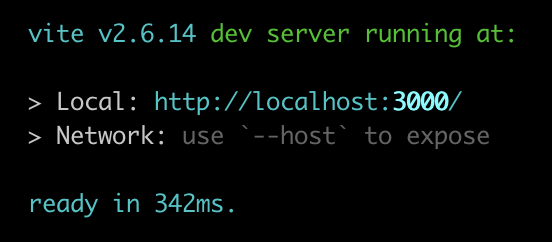
将Vite添加到您现有的Web应用程序
Vite(发音为“veet”)是一个新的JavaScript绑定器。它包括电池,几乎不需要任何配置即可使用,并包括大量配置选项。哦——而且速度很快。速度快得令人难以置信。 本文将介绍将现有项目转换为Vite的过程。我们将介绍别名、填充webp…...

Apache Kafka与Spring整合应用详解
引言 Apache Kafka是一种高吞吐量的分布式消息系统,广泛应用于实时数据处理、日志聚合和事件驱动架构中。Spring作为Java开发的主流框架,通过Spring Kafka项目提供了对Kafka的集成支持。本文将深入探讨如何使用Spring Kafka整合Apache Kafka,…...
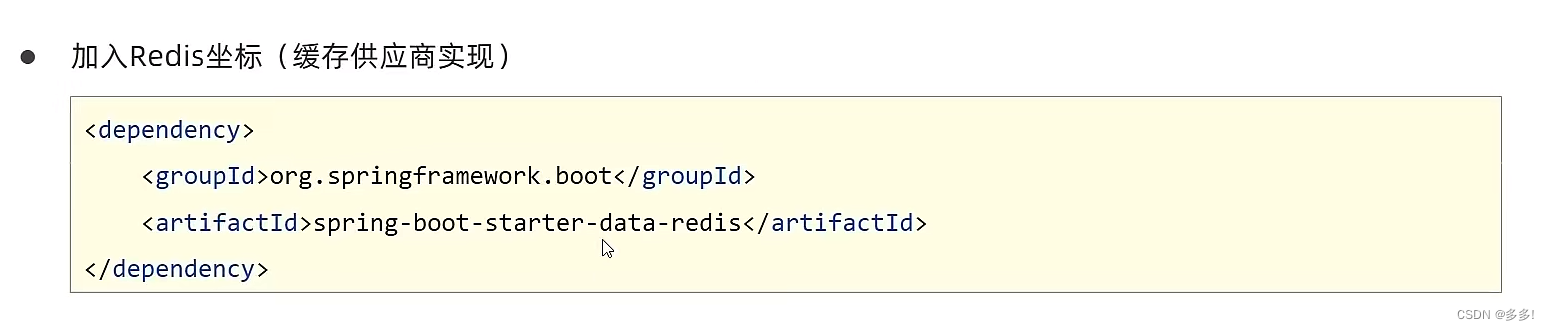
SpringBoot配置第三方专业缓存技术Redis
Redis缓存技术 Redis(Remote Dictionary Server)是一个开源的内存中数据结构存储系统,通常用作数据库、缓存和消息中间件。它支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等,并提供了丰富的功能和灵活的…...
以及使用)
javascript的toFixed()以及使用
toFixed() 是 JavaScript 中数字类型(Number)的一个方法,用来将数字转换为指定小数位数的字符串表示形式。 使用方式和示例: let num 123.45678; let fixedNum num.toFixed(2); console.log(fixedNum); // 输出 "123.46&qu…...

软件功能测试和性能测试包括哪些测试内容?又有什么联系和区别?
软件功能测试和性能测试是保证软件质量和稳定性的重要手,无论是验证软件的功能正确性,还是评估软件在负载下的性能表现,这些测试都是必不可少的。 一、软件功能测试 软件功能测试是指对软件的各项功能进行验证和确认,确保软件…...
从工具产品体验对比spark、hadoop、flink
作为一名大数据开发,从工具产品的角度,对比一下大数据工具最常使用的框架spark、hadoop和flink。工具无关好坏,但人的喜欢有偏好。 目录 评价标准1 效率2 用户体验分析从用户的维度来看从市场的维度来看从产品的维度来看 3 用户体验的基本原则…...

【软件设计】详细设计说明书(word原件,项目直接套用)
软件详细设计说明书 1.系统总体设计 2.性能设计 3.系统功能模块详细设计 4.数据库设计 5.接口设计 6.系统出错处理设计 7.系统处理规定 软件全套资料:本文末个人名片直接获取或者进主页。...
优缺点,以及适用场景)
java本地缓存(map,Guava,echcache,caffeine)优缺点,以及适用场景
前言 在高并发系统环境下,jvm本地缓存扮演着至关重要的角色,合理的应用能够使系统响应迅速,提高用户体验感,而分布式缓存redis则存在着网络io,以及流量消耗问题,需要和本地缓存搭配使用,才能使…...

Monica
在 《long long ago》中,我论述了on是一个刚出生的孩子的脐带连接在其肚子g上的形象,脐带就是long的字母l和字母n,l表脐带很长,n表脐带曲转冗余和连接之性,on表一,是孩子刚诞生的意思,o是身体&a…...

国产数据库中读写分离实现机制
在数据库高可用架构下会存在1主多备的部署,备节点可以根据业务场景分发一部分流量以充分利用资源,并减轻主库的压力,因此在数据库的功能上需要读写分离来实现。 充分利用备节点的资源,提升业务的吞吐量;防止运维等非业…...

CodeDroidAI:本地化AI代码助手的设计原理与工程实践
1. 项目概述:一个面向开发者的AI代码助手最近在GitHub上看到一个挺有意思的项目,叫“FMXExpress/CodeDroidAI”。光看这个名字,可能有点摸不着头脑,但如果你是个经常和代码打交道的开发者,尤其是对提升编码效率、探索A…...

OpenWebUI智能管道:连接本地AI模型与高性能推理后端
1. 项目概述:一个连接OpenWebUI与本地AI模型的智能管道最近在折腾本地大语言模型(LLM)的朋友,估计都绕不开OpenWebUI(原名Ollama WebUI)这个项目。它提供了一个极其美观、功能强大的Web界面,让我…...

AI与XR融合实战:Mosaic-Bridge中间件架构与性能调优
1. 项目概述:一个连接AI与XR世界的桥梁 最近在探索AI与扩展现实(XR)融合的落地场景时,我遇到了一个非常有意思的开源项目—— MosaicXR-AI/mosaic-bridge 。乍一看这个标题,你可能会觉得它只是一个普通的“桥接”工…...

Android本地代理服务器droidproxy:原理、部署与流量分析实战
1. 项目概述与核心价值最近在折腾Android应用网络调试和流量分析时,发现了一个挺有意思的开源项目——anand-92/droidproxy。简单来说,这是一个运行在Android设备上的HTTP/HTTPS代理服务器。你可能觉得,代理工具不是满大街都是吗?…...

国产手机涨价,苹果却开启了降价模式,618可能还要降,怎么打?
苹果的iPhone17可能是苹果史上降价最慢的手机了,这款手机上市以来降价速度非常缓慢,但是昨晚苹果CEO库克还中国的时候,苹果就官宣iPhone17Pro系列降价1000元,与国产手机因存储芯片涨价而涨价形成鲜明对比。值得注意的是当下iPhone…...
气体传感器阵列与数据采集(附完整 C 语言驱动))
【嵌入式 AI 实战第 9 期】环境感知(一)气体传感器阵列与数据采集(附完整 C 语言驱动)
一、前言在物联网与人工智能快速发展的今天,环境感知能力已成为智能设备的核心功能之一。气体传感器作为环境感知的 "嗅觉器官",广泛应用于智能家居、工业安全、农业生产、医疗诊断等领域。传统的单一气体传感器只能检测特定类型的气体&#x…...

【NotebookLM图书馆学研究实战指南】:20年图情专家亲授AI时代知识管理新范式
更多请点击: https://codechina.net 第一章:NotebookLM图书馆学研究的范式革命 传统图书馆学研究长期依赖人工文献综述、卡片目录索引与线性知识组织方式,而NotebookLM的引入正从根本上重构知识发现、关联与推理的底层逻辑。作为Google推出的…...

英雄联盟智能助手Seraphine:如何用3个核心功能提升你的排位胜率
英雄联盟智能助手Seraphine:如何用3个核心功能提升你的排位胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否曾在英雄联盟排位赛中因为BP阶段手忙脚乱而错失先机?是否因为不了…...

终极Python通达信数据读取指南:5分钟快速入门量化分析
终极Python通达信数据读取指南:5分钟快速入门量化分析 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易领域,通达信数据读取一直是Python开发者面临…...

claude code用户如何通过taotoken解决账号封禁与token不足难题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何通过 Taotoken 解决账号封禁与 Token 不足难题 对于深度依赖 Claude Code 作为编程助手的开发者而言…...