使用Kafka框架发送和接收消息(Java示例)
Kafka是一个开源的分布式流处理平台,以其在大数据和实时处理领域的广泛应用而闻名。以下是Kafka的关键特性以及它在消息传输方面的优势:
-
高吞吐量与低延迟:Kafka能够每秒处理数百万条消息,具有极低的延迟,这使得它非常适合处理大规模的实时数据流。
-
可扩展性:Kafka的分布式架构设计允许其轻松扩展,支持从少量到成千上万的生产者和消费者。
-
持久性和高可靠性:所有消息在Kafka中都被持久化存储到磁盘,并利用多副本机制来实现数据的高可用性和容错性。
-
容错能力:Kafka设计了高度的容错机制,确保即使在节点故障的情况下也能维持数据传输的连续性和可靠性。
-
多语言客户端API:Kafka提供了广泛的客户端API,支持包括Java、Python、Go和Scala在内的多种编程语言,简化了集成过程。
-
异步通信:Kafka支持生产者和消费者之间的异步通信模式,这有助于提高后端业务流程的并行处理效率。
-
流量控制:Kafka能够缓冲大量数据,作为削峰填谷的工具,防止后端系统因数据流量突增而过载。
-
扩展性:Kafka的分布式系统设计允许在不停机的情况下进行机器扩展,以应对不断增长的数据需求。
-
消息存储:Kafka将消息存储在磁盘上,实现了生产者和消费者之间的解耦,提供了更灵活的消息处理方式。
-
零拷贝技术:Kafka利用零拷贝技术优化了网络数据传输效率,减少了系统开销。
-
高性能:Kafka能够处理大规模的消息流,同时保持亚秒级的消息延迟,确保了高性能的数据传输。
这些特性使Kafka成为构建高性能、可靠的分布式消息传递基础设施的理想选择,特别适用于需要处理大规模数据和实时数据流的应用场景。
以下是一个简单的Java示例,演示如何使用Kafka框架发送和接收消息。这个例子假设你已经安装了Kafka,并配置了ZooKeeper服务。
1. 创建Kafka生产者(Producer)
首先,创建一个生产者,用于向Kafka主题发送消息。
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {// Kafka 配置Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 创建 Kafka 生产者实例Producer<String, String> producer = new KafkaProducer<>(props);// 创建消息String message = "Hello, Kafka!";ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", message);// 发送消息producer.send(record, (metadata, exception) -> {if (exception == null) {System.out.println("Message sent successfully to topic: " + metadata.topic());System.out.println("Partition: " + metadata.partition() + ", Offset: " + metadata.offset());} else {exception.printStackTrace();}});// 关闭生产者producer.close();}
}2. 创建Kafka消费者(Consumer)
接下来,创建一个消费者,用于从Kafka主题接收消息。
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;import java.util.Collections;
import java.util.Properties;public class KafkaConsumerExample {public static void main(String[] args) {// Kafka 配置Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-consumer-group");props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");// 创建 Kafka 消费者实例Consumer<String, String> consumer = new KafkaConsumer<>(props);// 订阅主题consumer.subscribe(Collections.singletonList("test-topic"));while (true) {// 轮询消息ConsumerRecords<String, String> records = consumer.poll(100);for (String record : records) {System.out.printf("Received message: (%s, %d) %n", record.key(), record.value());}}}
}注意事项:
- 确保Kafka服务正在运行,并且
test-topic主题已经创建。 - 根据你的Kafka版本和配置,可能需要调整序列化器和反序列化器。
- 消费者示例中的
GROUP_ID_CONFIG和AUTO_OFFSET_RESET_CONFIG属性用于控制消费者组的行为和消息偏移的重置策略。
这个例子展示了如何在Java中使用Kafka发送和接收消息。在实际应用中,你可能需要处理更复杂的逻辑,例如错误处理、消息过滤和事务处理。
相关文章:
)
使用Kafka框架发送和接收消息(Java示例)
Kafka是一个开源的分布式流处理平台,以其在大数据和实时处理领域的广泛应用而闻名。以下是Kafka的关键特性以及它在消息传输方面的优势: 高吞吐量与低延迟:Kafka能够每秒处理数百万条消息,具有极低的延迟,这使得它非常…...
高可用电商支付架构设计方案
高可用电商支付架构设计 在现代电商业务中,支付过程是其中至关重要的一环,一个高可用、安全稳定的支付架构不仅可以提高整个系统的可靠性和扩展性,降低维护成本,还可以优化用户体验,增加用户黏性。 本文将提出一种高…...
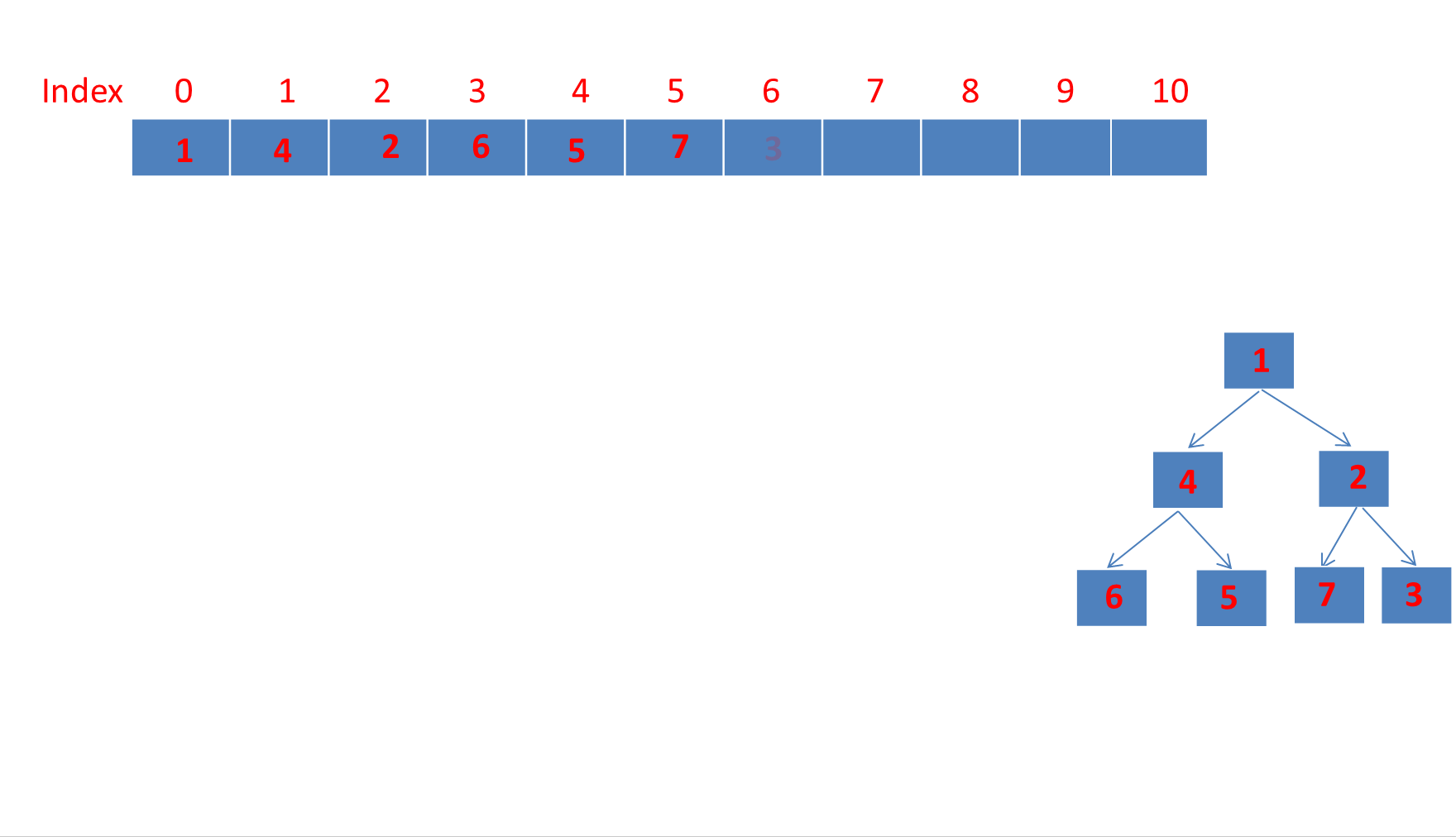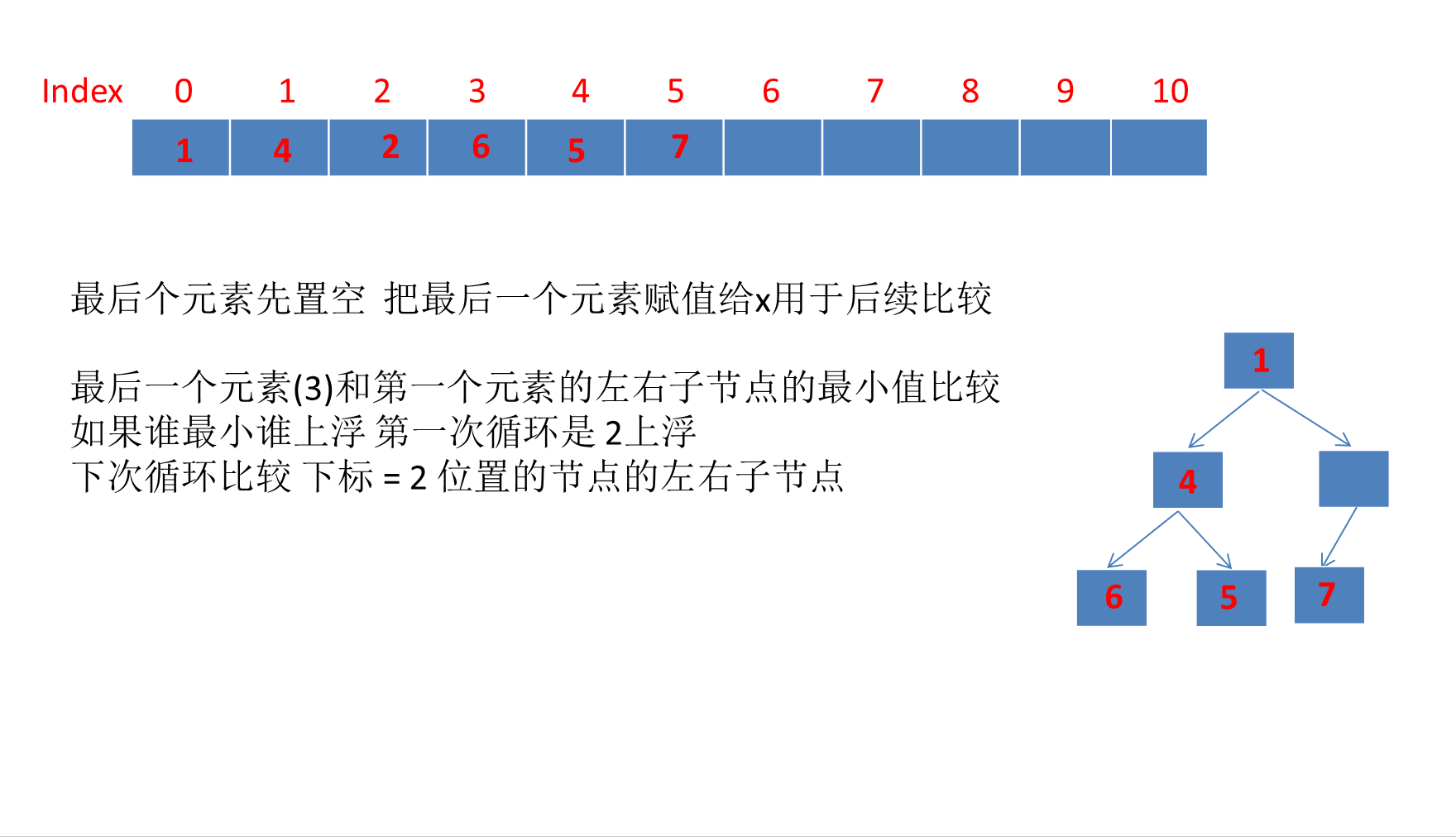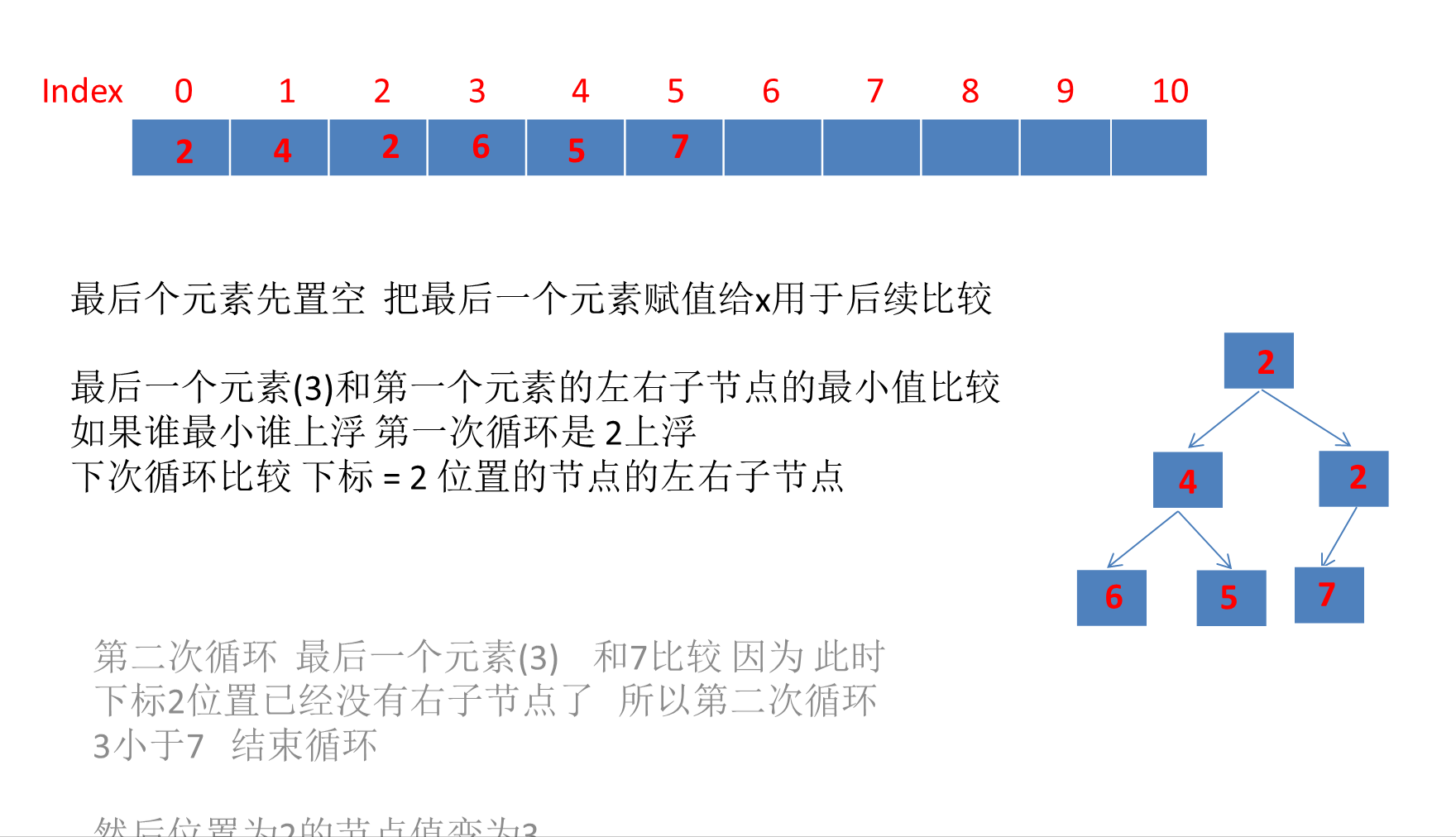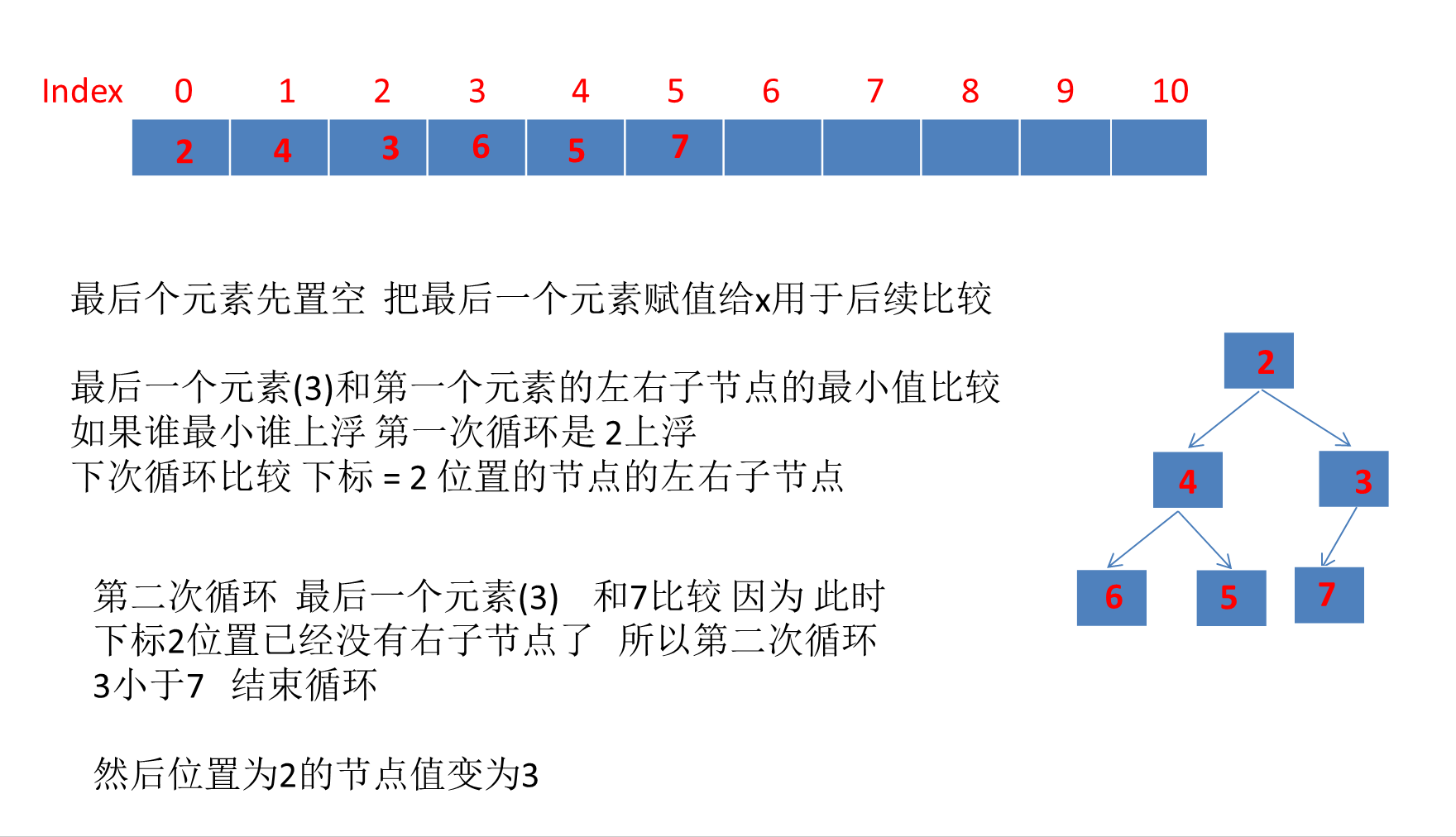
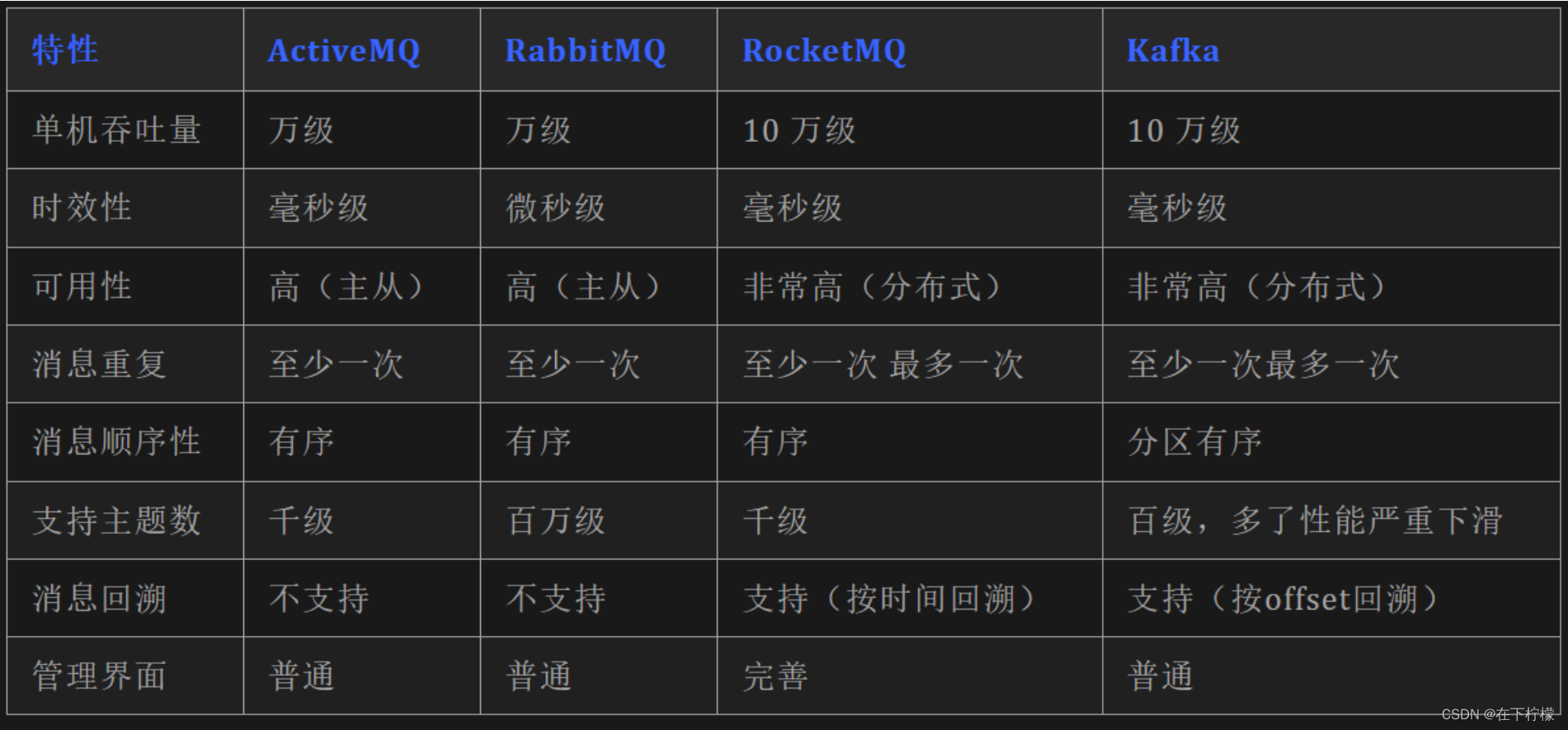
PriorityQueue详解(含动画演示)
目录 PriorityQueue详解1、PriorityQueue简介2、PriorityQueue继承体系3、PriorityQueue数据结构PriorityQueue类属性注释完全二叉树、大顶堆、小顶堆的概念☆PriorityQueue是如何利用数组存储小顶堆的?☆利用数组存储完全二叉树的好处? 4、PriorityQueu…...

python 字符串驻留机制
偶然发现一个python字符串的现象: >>> a 123_abc >>> b 123_abc >>> a is b True >>> c abc#123 >>> d abc#123 >>> c is d False 这是为什么呢,原来它们的id不一样。 >>> id(a)…...
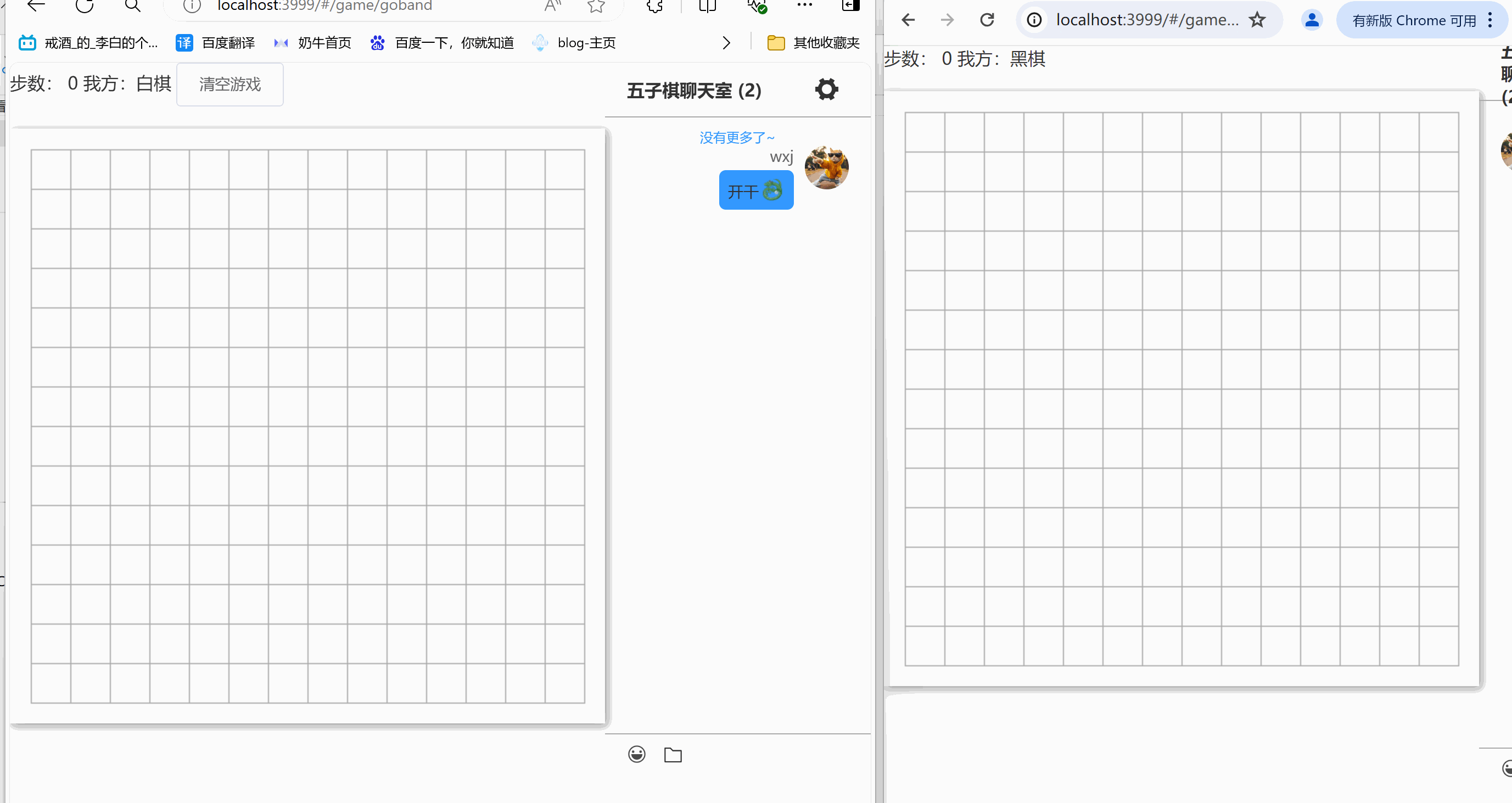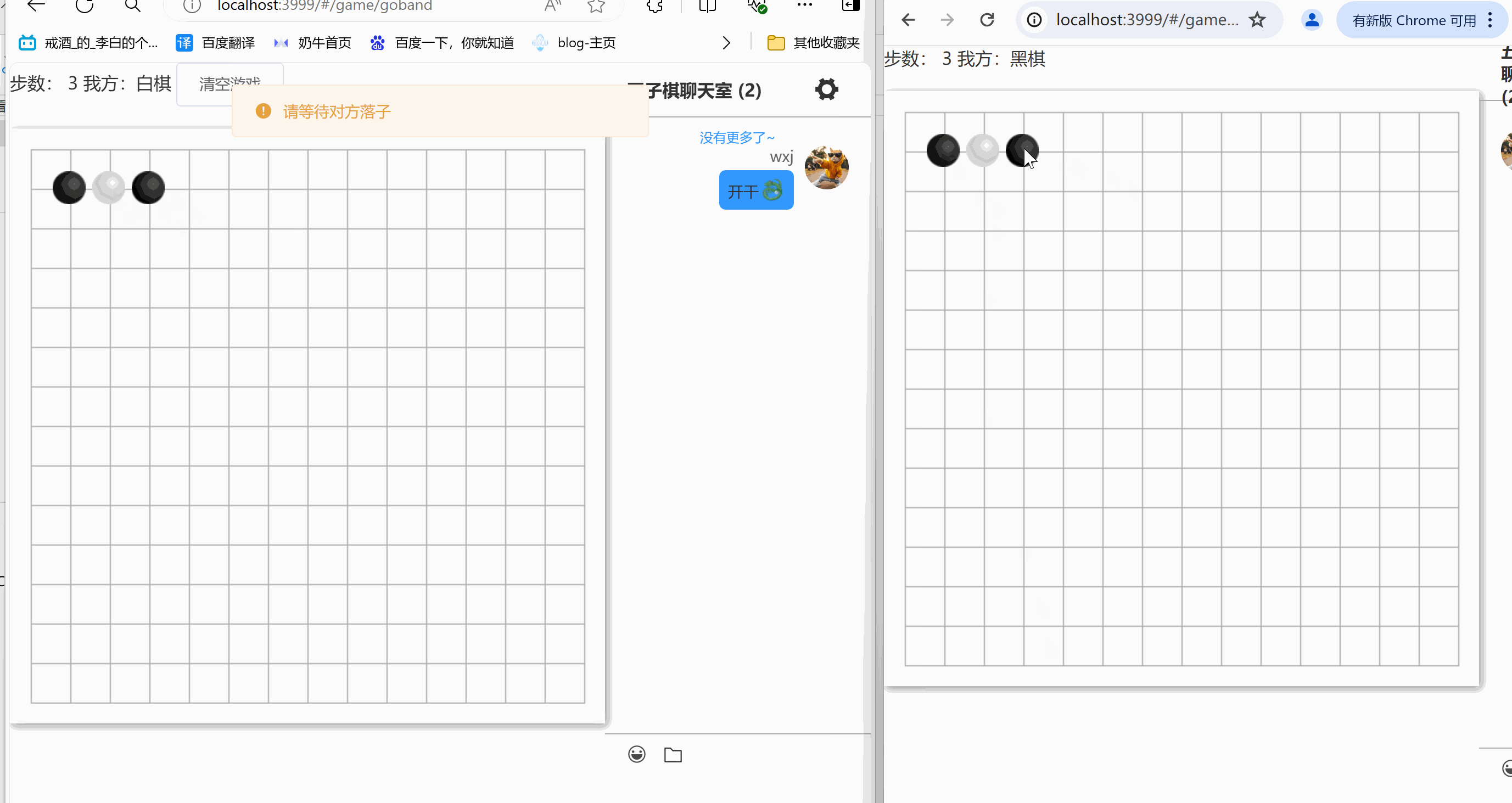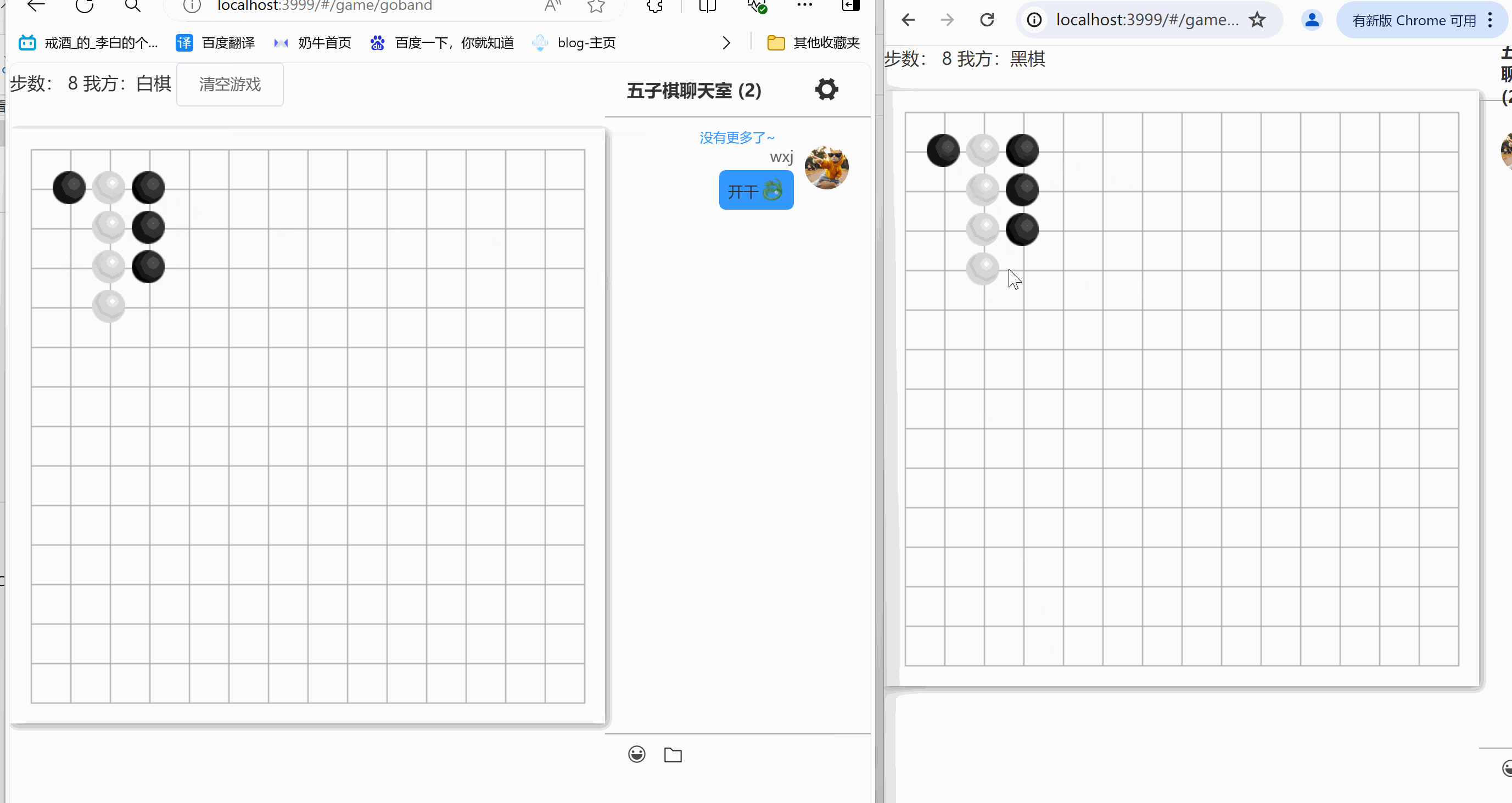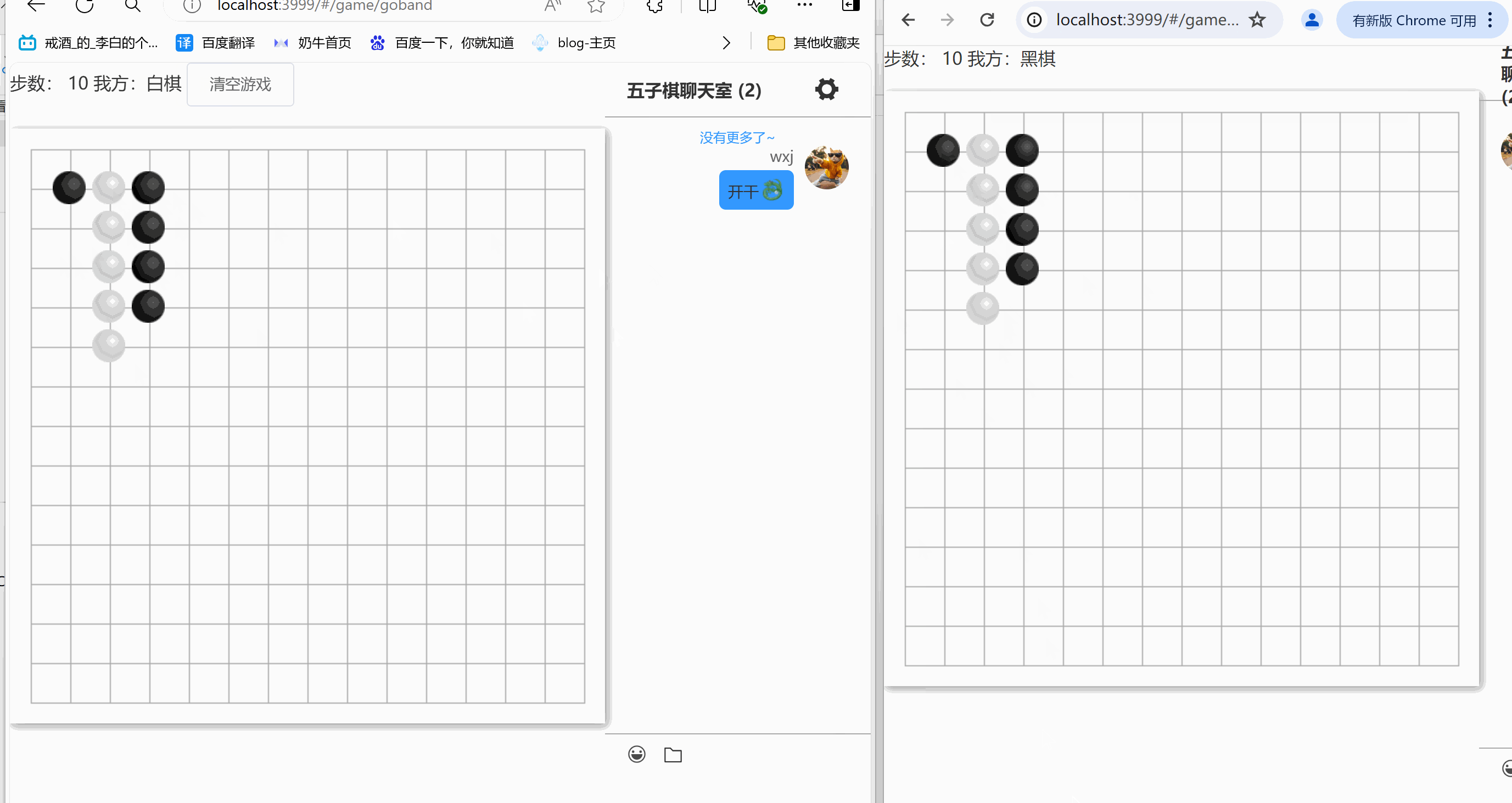
express+vue 在线五子棋(一)
示例 在线体验地址五子棋,记得一定要再拉个人才能对战 本期难点 1、完成了五子棋的布局,判断游戏结束 2、基本的在线对战 3、游戏配套im(这个im的实现,请移步在线im) 下期安排 1、每步的倒计时设置 2、黑白棋分配由玩家自定义 3、新增旁观…...
AI 大模型企业应用实战(06)-初识LangChain
LLM大模型与AI应用的粘合剂。 1 langchain是什么以及发展过程 LangChain是一个开源框架,旨在简化使用大型语言模型构建端到端应用程序的过程,也是ReAct(reasonact)论文的落地实现。 2022年10月25日开源 54K star 种子轮一周1000万美金,A轮2…...

JavaScript的学习之旅之初始JS
目录 一、认识三个常见的js代码 二、js写入的第二种方式 三、js里内外部文件 一、认识三个常见的js代码 <script>//写入js位置的第一个地方// 控制浏览器弹出一个警告框alert("这是一个警告");// 在计算机页面输入一个内容(写入body中ÿ…...

DataStructure.时间和空间复杂度
时间和空间复杂度 【本节目标】1. 如何衡量一个算法的好坏2. 算法效率3. 时间复杂度3.1 时间复杂度的概念3.2 大O的渐进表示法3.3 推导大O阶方法3.4 常见时间复杂度计算举例3.4.1 示例13.4.2 示例23.4.3 示例33.4.4 示例43.4.5 示例53.4.6 示例63.4.7 示例7 4.空间复杂度4.1 示…...

[Spring Boot]Netty-UDP客户端
文章目录 简述Netty-UDP集成pom引入ClientHandler调用 消息发送与接收在线UDP服务系统调用 简述 最近在一些场景中需要使用UDP客户端进行,所以开始集成新的东西。本文集成了一个基于netty的SpringBoot的简单的应用场景。 Netty-UDP集成 pom引入 <!-- netty --…...

基础C语言知识串串香11☞宏定义与预处理、函数和函数库
六、C语言宏定义与预处理、函数和函数库 6.1 编译工具链 源码.c ——> (预处理)——>预处理过的.i文件——>(编译)——>汇编文件.S——>(汇编)——>目标文件.o->(链接)——>elf可执行程序 预处理用预处理器,编译用编译器,…...

Python 3 函数
Python 3 函数 引言 Python 是一种高级编程语言,以其简洁明了的语法和强大的功能而闻名。在 Python 中,函数是一等公民,扮演着至关重要的角色。它们是组织代码、提高代码复用性和模块化编程的关键。本文将深入探讨 Python 3 中的函数,包括其定义、特性、类型以及最佳实践…...

【Linux详解】冯诺依曼架构 | 操作系统设计 | 斯坦福经典项目Pintos
目录 一. 冯诺依曼体系结构 (Von Neumann Architecture) 注意事项 存储器的意义:缓冲 数据流动示例 二. 操作系统 (Operating System) 操作系统的概念 操作系统的定位与目的 操作系统的管理 系统调用和库函数 操作系统的管理: sum 三. 系统调…...
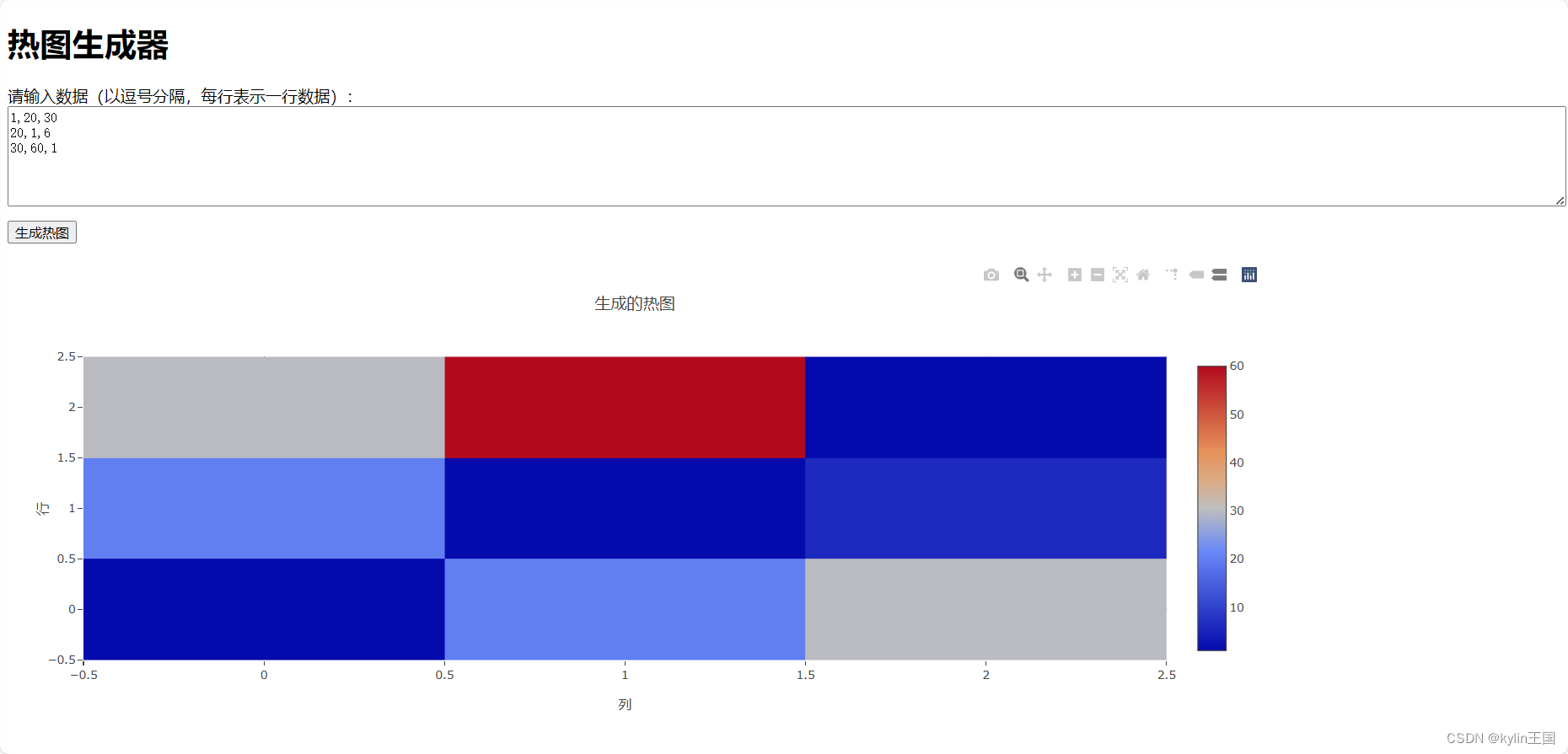
html做一个画热图的软件
完整示例 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><title>热图生成器</title><script src"https://cdn.plot.ly/plotly-latest.min.js"></script><style>body …...
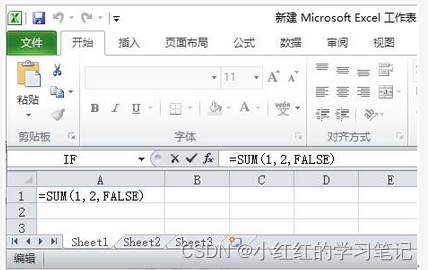
软考初级网络管理员__软件单选题
1.在Excel 中,设单元格F1的值为56.323,若在单元格F2中输入公式"TEXT(F1,"¥0.00”)”,则单元格F2的值为()。 ¥56 ¥56.323 ¥56.32 ¥56.00 2.要使Word 能自动提醒英文单…...

数据库新技术【分布式数据库】
文章目录 第一章 概述1.1 基本概念1.1.1 分布式数据库1.1.2 数据管理的透明性1.1.3 可靠性1.1.4 分布式数据库与集中式数据库的区别 1.2 体系结构1.3 全局目录1.4 关系代数1.4.1 基操1.4.2 关系表达式1.4.3 查询树 第二章 分布式数据库的设计2.1 设计策略2.2 分布设计的目标2.3…...

关于运用人工智能帮助自己实现英语能力的有效提升?
# 实验报告 ## 实验目的 - 描述实验的目标:自己可以知道,自己的ai学习方法是否可以有效帮助自己实现自己的学习提升。 预期结果:在自己利用科技对于自己进行学习的过程中,自己的成长速度应该是一个幂指数的增长 ## 文献回顾 根据…...

IPv6知识点整理
IPv6:是英文“Internet Protocol Version 6”(互联网协议第6版)的缩写,是互联网工程任务组(IETF)设计的用于替代IPv4的下一代IP协议,其地址数量号称可以为全世界的每一粒沙子编上一个地址 。 国…...
——体系:数据标准化——概述、关注焦点)
数据赋能(127)——体系:数据标准化——概述、关注焦点
概述 数据标准化是指将数据按照一定的规范和标准进行处理的过程。 数据标准化是属于数据整理过程。 数据标准化的目的在于提高数据的质量、促进数据的共享和交互、降低数据管理的成本,并增强数据的安全性。通过数据标准化,可以使得数据具有统一的格式…...

【 ARMv8/ARMv9 硬件加速系列 3.5.1 -- SVE 谓词寄存器有多少位?】
文章目录 SVE 谓词寄存器(predicate registers)简介SVE 谓词寄存器的位数SVE 谓词寄存器对向量寄存器的控制SVE 谓词寄存器位数计算SVE 谓词寄存器小结 SVE 谓词寄存器(predicate registers)简介 ARMv9的Scalable Vector Extension (SVE) 引入了谓词寄存器(Predica…...

Python - 调用函数时检查参数的类型是否合规
前言 阅读本文大概需要3分钟 说明 在python中,即使加入了类型注解,使用注解之外的类型也是不报错的 def test(uid: int):print(uid)test("999")但是我就想要类型不对就直接报错确实可以另辟蹊径,实现报错,似乎有强…...

ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch + CUDA环境配置与避坑
ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch CUDA环境配置与避坑 在深度学习模型部署领域,BFloat16数据类型正逐渐成为提升推理性能的新宠。这种16位浮点格式保留了与32位浮点相同的指数位,在保持数值范围的同时减少了内存占…...

NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南
NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专业的显卡优化工具,专为…...

ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准
ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准 当你把ADXL335加速度计接入Arduino,兴奋地跑起第一个测试程序时,那些跳动的数字可能很快会浇灭你的热情。原始读数像得了疟疾般颤抖,静止时本该稳定的1g重力加速…...

如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案
如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在任何设备上畅玩PC游戏?无论是想…...

树莓派扩展板EYESPI Pi Beret:简化硬件连接,加速原型开发
1. 项目概述:为什么我们需要EYESPI Pi Beret?玩树莓派的朋友,尤其是喜欢捣鼓屏幕和传感器的,肯定都经历过那个阶段:面对一堆杜邦线,对照着屏幕驱动板的引脚定义,一个个数着树莓派的GPIO针脚&…...

基于Stable Diffusion与LoRA技术打造个人AI头像:从原理到实战
1. 项目概述:当AI开始“自拍”——SelfyAI的定位与核心价值最近在AI图像生成领域,一个名为SelfyAI的项目引起了我的注意。它不是一个简单的文生图工具,而是瞄准了一个非常具体且高频的需求:生成高质量、风格一致的个人AI头像。简单…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...

Unity区域加载系统:实现开放世界无缝加载与内存优化
1. 项目概述:一个高效、可扩展的Unity区域加载系统 最近在做一个开放世界风格的项目,场景大了之后,加载卡顿和内存管理就成了老大难问题。传统的Unity场景加载,要么一股脑全塞进内存,要么就得自己写一堆脚本来手动控制…...

Nixtla时间序列预测生态:从统计模型到深度学习的统一实践
1. 项目概述:时间序列预测的“瑞士军刀”如果你正在处理时间序列数据,无论是销售预测、服务器监控、还是能源消耗分析,那么你很可能听说过或正在使用一些经典的库,比如statsmodels、prophet,或者更现代的深度学习框架。…...

多数人支持!微软或把 Xbox 重新品牌化为 XBOX,回归最初形式
Xbox 品牌重塑:从民意调查到账号更名微软 Xbox 首席执行官阿莎夏尔马在 X(原推特)上发起民意调查,询问粉丝微软应使用 Xbox 还是 XBOX,结果多数人支持 XBOX,随后公司将其 X 账号更名。不过,Xbox…...