动手学深度学习(Pytorch版)代码实践 -计算机视觉-37微调
37微调

import os
import torch
import torchvision
from torch import nn
import liliPytorch as lp
import matplotlib.pyplot as plt
from d2l import torch as d2l# 获取数据集
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')data_dir = d2l.download_extract('hotdog')
#Downloading ../data\hotdog.zip from http://d2l-data.s3-accelerate.amazonaws.com/hotdog.zip...# 分别读取训练和测试数据集中的所有图像文件
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
# ImageFolder 会递归地读取指定目录下的所有图像文件。
# print(train_imgs.classes)#一个类名列表 # ['hotdog', 'not-hotdog']
# print(train_imgs.class_to_idx) # 一个字典,类名映射到类索引 # {'hotdog': 0, 'not-hotdog': 1}
# print(train_imgs.imgs) # 一个包含所有图像路径和对应类索引的列表
# 例如:[('../data\\hotdog\\train\\hotdog\\0.png', 0), ('../data\\hotdog\\train\\hotdog\\1.png', 0)
# , ('../data\\hotdog\\train\\not-hotdog\\999.png', 1)]
# 显示了前8个正类样本图片和最后8张负类样本图片# hotdogs = [train_imgs[i][0] for i in range(8)] #train_imgs[i] 返回一个元组 (image, label),
# # 其中 image 是图像张量,label 是对应的标签。[0] 只提取图像张量。# not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)] # 索引从 -1 到 -8# d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4)
# plt.show() # 显示图片# 使用RGB通道的均值和标准差,以标准化每个通道
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])train_augs = torchvision.transforms.Compose([#从图像中裁切随机大小和随机长宽比的区域,然后将该区域缩放为224 * 224torchvision.transforms.RandomResizedCrop(224),torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor(),normalize])test_augs = torchvision.transforms.Compose([torchvision.transforms.Resize([256, 256]),torchvision.transforms.CenterCrop(224), # 裁剪中央224 * 224torchvision.transforms.ToTensor(),normalize])# 定义和初始化模型
# 使用在ImageNet数据集上预训练的ResNet-18作为源模型
pretrained_net = torchvision.models.resnet18(pretrained=True)# 源模型实例包含许多特征层和一个输出层fc
print(pretrained_net.fc)
# Linear(in_features=512, out_features=1000, bias=True)finetune_net = pretrained_net
# 改变输出层fc
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
# 参数初始化
nn.init.xavier_uniform_(finetune_net.fc.weight)def train_batch_ch13(net, X, y, loss, trainer, devices):"""使用多GPU训练一个小批量数据。参数:net: 神经网络模型。X: 输入数据,张量或张量列表。y: 标签数据。loss: 损失函数。trainer: 优化器。devices: GPU设备列表。返回:train_loss_sum: 当前批次的训练损失和。train_acc_sum: 当前批次的训练准确度和。"""# 如果输入数据X是列表类型if isinstance(X, list):# 将列表中的每个张量移动到第一个GPU设备X = [x.to(devices[0]) for x in X]else:X = X.to(devices[0])# 如果X不是列表,直接将X移动到第一个GPU设备y = y.to(devices[0])# 将标签数据y移动到第一个GPU设备net.train() # 设置网络为训练模式trainer.zero_grad()# 梯度清零pred = net(X) # 前向传播,计算预测值l = loss(pred, y) # 计算损失l.sum().backward()# 反向传播,计算梯度trainer.step() # 更新模型参数train_loss_sum = l.sum()# 计算当前批次的总损失train_acc_sum = d2l.accuracy(pred, y)# 计算当前批次的总准确度return train_loss_sum, train_acc_sum# 返回训练损失和与准确度和def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices=d2l.try_all_gpus()):"""训练模型在多GPU参数:net: 神经网络模型。train_iter: 训练数据集的迭代器。test_iter: 测试数据集的迭代器。loss: 损失函数。trainer: 优化器。num_epochs: 训练的轮数。devices: GPU设备列表,默认使用所有可用的GPU。"""# 初始化计时器和训练批次数timer, num_batches = d2l.Timer(), len(train_iter)# 初始化动画器,用于实时绘制训练和测试指标animator = lp.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],legend=['train loss', 'train acc', 'test acc'])# 将模型封装成 DataParallel 模式以支持多GPU训练,并将其移动到第一个GPU设备net = nn.DataParallel(net, device_ids=devices).to(devices[0])# 训练循环,遍历每个epochfor epoch in range(num_epochs):# 初始化指标累加器,metric[0]表示总损失,metric[1]表示总准确度,# metric[2]表示样本数量,metric[3]表示标签数量metric = lp.Accumulator(4)# 遍历训练数据集for i, (features, labels) in enumerate(train_iter):timer.start() # 开始计时# 训练一个小批量数据,并获取损失和准确度l, acc = train_batch_ch13(net, features, labels, loss, trainer, devices)metric.add(l, acc, labels.shape[0], labels.numel()) # 更新指标累加器timer.stop() # 停止计时# 每训练完五分之一的批次或者是最后一个批次时,更新动画器if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[3], None))test_acc = d2l.evaluate_accuracy_gpu(net, test_iter) # 在测试数据集上评估模型准确度animator.add(epoch + 1, (None, None, test_acc))# 更新动画器# 打印最终的训练损失、训练准确度和测试准确度print(f'loss {metric[0] / metric[2]:.3f}, train acc 'f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')# 打印每秒处理的样本数和使用的GPU设备信息print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on 'f'{str(devices)}')def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,param_group=True):"""参数:net: 神经网络模型。learning_rate: 学习率。batch_size: 每个小批量的大小,默认为128。num_epochs: 训练的轮数,默认为5。param_group: 是否对不同层使用不同的学习率,默认为True。"""train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),batch_size=batch_size, shuffle=True) # 创建训练数据集的迭代器test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),batch_size=batch_size) # 创建测试数据集的迭代器devices = d2l.try_all_gpus() # 获取所有可用的GPU设备loss = nn.CrossEntropyLoss(reduction="none") # 定义损失函数# 如果使用参数组if param_group:# 获取除最后全连接层外的所有参数# 列表params_1x,包含除最后一层全连接层外的所有参数。params_1x = [param for name, param in net.named_parameters()if name not in ["fc.weight", "fc.bias"]]# 定义优化器,分别为不同的参数组设置不同的学习率trainer = torch.optim.SGD([{'params': params_1x},{'params': net.fc.parameters(),'lr': learning_rate * 10}],lr=learning_rate, weight_decay=0.001)else:# 如果不使用参数组,为所有参数设置相同的学习率trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0.001)# 调用训练函数,开始训练train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)train_fine_tuning(finetune_net, 5e-5)
# loss 0.211, train acc 0.927, test acc 0.938
# 456.7 examples/sec on [device(type='cuda', index=0)]"""
为了进行比较,我们定义了一个相同的模型,但是将其所有模型参数初始化为随机值。
由于整个模型需要从头开始训练,因此我们需要使用更大的学习率。
"""
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
train_fine_tuning(scratch_net, 5e-4, param_group=False)
# loss 0.338, train acc 0.842, test acc 0.859
# 457.7 examples/sec on [device(type='cuda', index=0)]plt.show() #显示图片
预训练resnet18模型运行效果:

初始化resnet18模型运行效果:

相关文章:
动手学深度学习(Pytorch版)代码实践 -计算机视觉-37微调
37微调 import os import torch import torchvision from torch import nn import liliPytorch as lp import matplotlib.pyplot as plt from d2l import torch as d2l# 获取数据集 d2l.DATA_HUB[hotdog] (d2l.DATA_URL hotdog.zip,fba480ffa8aa7e0febbb511d181409f899b9baa5…...

视频监控平台:支持交通部行业标准JT/T905协议(即:出租汽车服务管理信息系统)的源代码的函数和功能介绍及分享
目录 一、视频监控平台介绍 (一)概述 (二)视频接入能力介绍 (三)功能介绍 二、JT/T905协议介绍 (一)概述 (二)主要内容 1、设备要求 2、业务功能要求…...

【jenkins1】gitlab与jenkins集成
文章目录 1.Jenkins-docker配置:运行在8080端口上,机器只要安装docker就能装载image并运行容器2.Jenkins与GitLab配置:docker ps查看正在运行,浏览器访问http://10....:8080/2.1 GitLab与Jenkins的Access Token配置:不…...

边缘计算设备有哪些
边缘设备是指那些位于数据源附近,能够执行数据处理、分析和决策的计算设备。这些设备通常具有一定的计算能力、存储能力和网络连接能力,能够减少数据传输到云端的需要,从而降低延迟、节省带宽并提高数据处理的效率。以下是一些常见的边缘设备…...

C++初学者指南第一步---7.控制流(基础)
C初学者指南第一步—7.控制流(基础) 文章目录 C初学者指南第一步---7.控制流(基础)1.术语:表达式/语句Expressions表达式Statements语句 2.条件分支3.Switching(切换):基于值的分支4.三元条件运算符5.循环迭代基于范围的循环 C…...
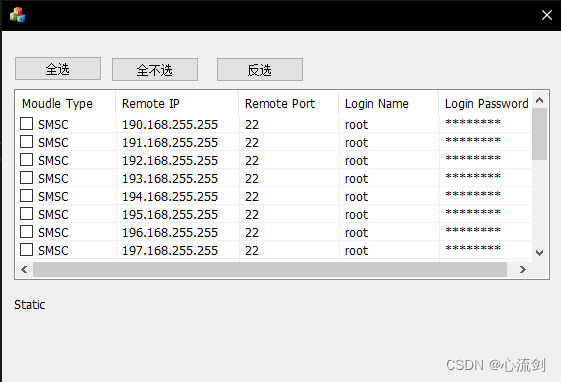
MFC学习--CListCtrl复选框以及选择
如何展示复选框 //LVS_EX_CHECKBOXES每一行的最前面带个复选框//LVS_EX_FULLROWSELECT整行选中//LVS_EX_GRIDLINES网格线//LVS_EX_HEADERDRAGDROP列表头可以拖动m_listctl.SetExtendedStyle(LVS_EX_FULLROWSELECT | LVS_EX_CHECKBOXES | LVS_EX_GRIDLINES); 全选,全…...

如何与PM探讨项目
我曾在2020年撰写过一篇名为对产品经理的一些思考的文章,紧接着在2021年,我又写了一篇对如何分析项目的思考。在这两篇文章中,我提出了一个核心观点:“船长需要把控所有事情,但最核心的是:需要知道目标是什…...

今年618各云厂商的香港服务器优惠活动汇总
又到了一年618年中钜惠活动时间,2024年各大云服务器厂商都有哪些活动呢?有哪些活动包括香港服务器呢?带着这些问题,小编给大家一一讲解各大知名厂商的618活动有哪些值得关注的地方,如果对你有帮助,欢迎点赞…...

Android平台下VR头显如何低延迟播放4K以上超高分辨率RTSP|RTMP流
技术背景 VR头显需要更高的分辨率以提供更清晰的视觉体验、满足沉浸感的要求、适应透镜放大效应以及适应更广泛的可视角度,超高分辨率的优势如下: 提供更清晰的视觉体验:VR头显的分辨率直接决定了用户所看到的图像的清晰度。更高的分辨率意…...

WHAT - NextJS 系列之 Rendering - Server Components
目录 一、Server Components1.1 Server Components特点使用 1.2 Client Components特点使用 1.3 综合使用示例1.4 小结 二、Server Components 优势三、Streaming 特性3.1 基本介绍和使用Streaming的理解工作原理使用示例服务器端组件客户端组件页面流程解释 3.2 HTTP/1.1和HTT…...

Web项目部署后浏览器刷新返回Nginx的404错误对应解决方案
data: 2024/6/22 16:05:34 周六 limou3434 叠甲:以下文章主要是依靠我的实际编码学习中总结出来的经验之谈,求逻辑自洽,不能百分百保证正确,有错误、未定义、不合适的内容请尽情指出! 文章目录 1.源头2.排错3.原因4.解…...
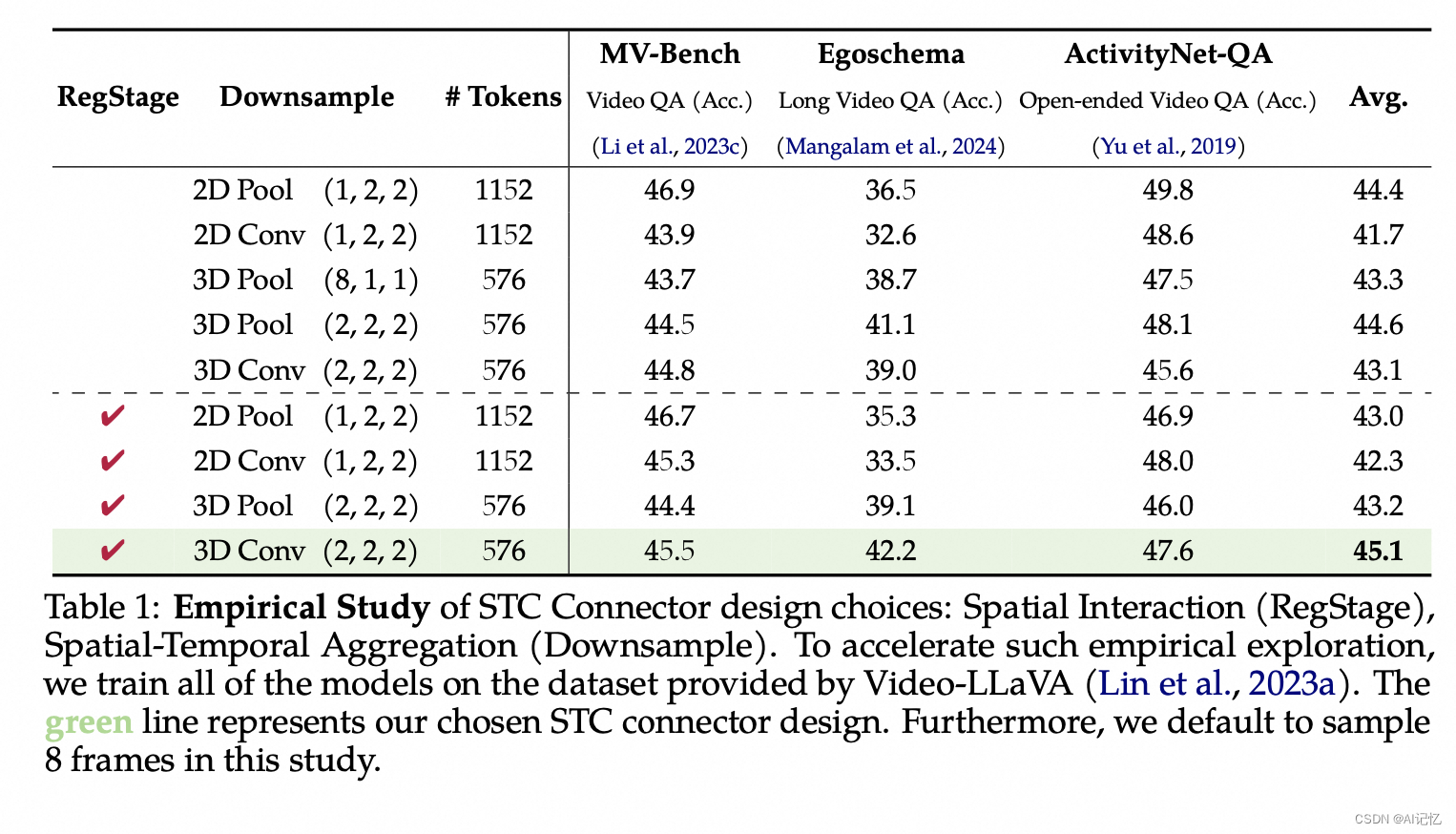
视频与音频的交响:探索达摩院VideoLLaMA 2的技术创新
一、简介 文章:https://arxiv.org/abs/2406.07476 代码:https://github.com/DAMO-NLP-SG/VideoLLaMA2 VideoLLaMA 2是由阿里巴巴集团的DAMO Academy团队开发的视频大型语言模型(Video-LLM),旨在通过增强空间-时间建模…...

更改ip后还被封是ip质量的原因吗?
不同的代理IP的质量相同,一般来说可以根据以下几个因素来进行判断: 1.可用率 可用率就是提取的这些代理IP中可以正常使用的比率。假如我们无法使用某个代理IP请求目标网站或者请求超时,那么就代表这个代理不可用,一般来说免费代…...

【Oracle】调用HTTP接口
Oracle调用http接口 前情提要1.创建HTTP请求函数2.创建ACL并授予权限3.测试HTTP请求函数其他操作 一点建议参考文档 前情提要 公司唯有oracle被允许访问内外网,因此在oracle中发起HTTP请求。 1.创建HTTP请求函数 CREATE OR REPLACE FUNCTION HTTP_REQUEST(v_url …...
Minillama3->sft训练
GitHub - leeguandong/MiniLLaMA3: llama3的迷你版本,包括了数据,tokenizer,pt的全流程llama3的迷你版本,包括了数据,tokenizer,pt的全流程. Contribute to leeguandong/MiniLLaMA3 development by creating an account on GitHub.https://github.com/leeguandong/MiniLL…...

【教师资格证考试综合素质——法律专项】学生伤害事故处理办法以及未成人犯罪法笔记相关练习题
目录 《学生伤害事故处理办法》 第一章 总 则 第二章 事故与责任 (谁有错,谁担责) 第三章 事故处理程序 第四章 事故损害的赔偿 第五章 事故责任者的处理 第六章 附 则 《中华人民共和国预防未成人犯罪法》 第一章 总 则 第二章 预…...

Vite: 关于静态资源的处理机制
概述 随着前端技术的飞速发展,项目规模和复杂度不断增加,如何高效地处理静态资源成为了提升开发效率和应用性能的关键Vite,作为新一代前端构建工具,以其轻量级、快速启动和热更新著称,同时也为静态资源的管理和优化提…...

React之useEffect
在React中,useEffect 是一个非常重要的Hook,它用于管理副作用操作。副作用指的是那些不直接与组件渲染相关的操作,例如数据获取、订阅、手动DOM操作等。本文将详细介绍 useEffect 的概念、基础使用、参数说明以及如何清除副作用,并…...
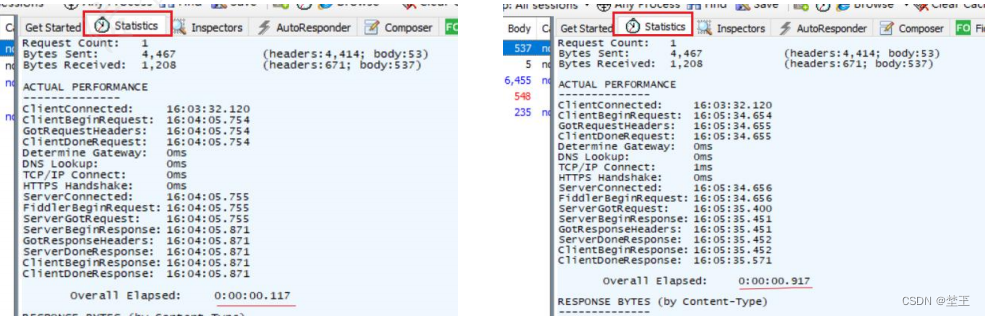
测试辅助工具(抓包工具)的使用3 之 弱网测试
1.为什么要进行弱网测试? 1.带宽1M和带宽100M打开tpshop网站效果一样吗? 2.手机使用2G网络和使用3G网络打开京东的效果一样吗? 弱网环境下,出现丢包、延时软件的处理机制,避免造成用户的流失。 2.如何进行弱网测试&…...
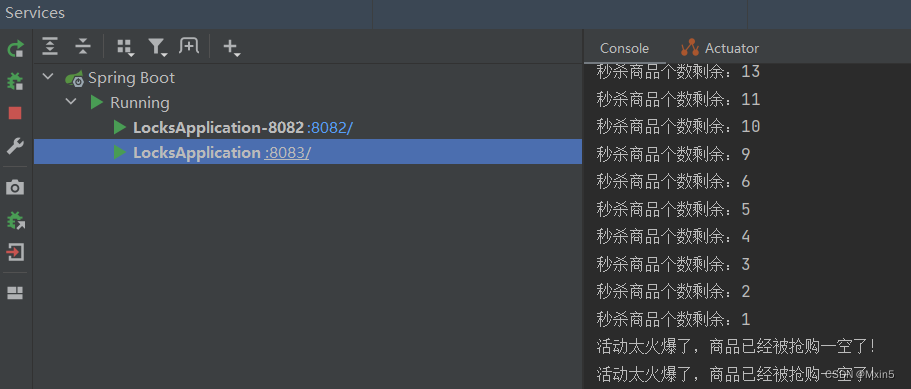
【Redis】基于Redission实现分布式锁(代码实现)
目录 基于Redission实现分布式锁解决商品秒杀超卖的场景: 1.引入依赖: 2.加上redis的配置: 3.添加配置类: 4.编写代码实现: 5.模拟服务器分布式集群的情况: 1.右键点击Copy Configuration 2.点击Modi…...

百度网盘直链解析终极指南:如何实现高速下载的完整技术方案
百度网盘直链解析终极指南:如何实现高速下载的完整技术方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在云存储服务普及的今天,百度网盘作为国内用…...

告别标题栏!在RK3568 Buildroot固件上,让你的Qt应用开机全屏显示的保姆级教程
RK3568嵌入式全屏实战:从Weston配置到Qt应用独占显示的完整指南 在嵌入式Linux系统开发中,GUI应用的全屏显示往往成为工程师面临的第一个"拦路虎"。当你在RK3568平台上精心开发的Qt应用启动后,却发现屏幕顶部顽固地挂着Weston窗口管…...

Vim-ai插件深度指南:在Vim中无缝集成AI提升开发效率
1. 项目概述:当Vim遇上AI,一场编辑器生产力的革命如果你和我一样,是个在终端里泡了十多年的老Vim用户,那你一定经历过这样的场景:面对一个复杂的函数重构,手指在键盘上飞舞,:s、%s、宏录制轮番上…...

从零构建专属大语言模型:Self-LLM开源项目全流程实践指南
1. 项目概述与核心价值最近在开源社区里,一个名为datawhalechina/self-llm的项目引起了我的注意。乍一看,这像是一个关于大语言模型(LLM)的仓库,但“self”这个前缀又让人浮想联翩。经过一段时间的深入研究和实践&…...

Nixtla时间序列预测生态:从统计模型到深度学习的统一实践
1. 项目概述:时间序列预测的“瑞士军刀”如果你正在处理时间序列数据,无论是销售预测、服务器监控、还是能源消耗分析,那么你很可能听说过或正在使用一些经典的库,比如statsmodels、prophet,或者更现代的深度学习框架。…...

Arduino nRF52 BLE开发:GATT服务与特征值配置实战详解
1. 项目概述如果你正在用Arduino和nRF52系列芯片(比如nRF52832或nRF52840)做蓝牙低功耗(BLE)开发,那你肯定绕不开GATT(通用属性配置文件)这一关。GATT是BLE通信的“语言规则”,它定义…...

基于RAG与智能体技术构建专业客服AI:从知识注入到流程执行
1. 项目概述:一个面向客服场景的AI智能体指南最近在GitHub上看到一个挺有意思的项目,叫mrqhocungdungai-vn/hermes-cskh-guide。从名字就能猜个大概,这是一个关于“Hermes”的客服(CSKH)指南,而且看起来是越…...

MySQL高可用与扩展-主从复制读写分离分库分表
当单库压力越来越大时,常见演进路线是先做主从复制,再做读写分离;如果数据量和写入压力继续增长,就需要考虑分库分表。 这三者解决的问题不同:方案主要解决什么主从复制数据冗余、读扩展、故障切换基础读写分离缓解读请…...

微服务架构实战:从DDD设计到K8s部署的完整指南
1. 项目概述与核心价值最近几年,微服务架构的热度一直居高不下,从互联网大厂到初创团队,几乎人人都在谈微服务。但说实话,真正能把微服务玩转、落地,并且能稳定支撑业务发展的团队,其实并不多。很多项目要么…...

如何在Windows上高效使用酷安社区:UWP桌面客户端完全指南
如何在Windows上高效使用酷安社区:UWP桌面客户端完全指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 你是否经常在手机小屏幕上刷酷安,眼睛酸痛却停不下来&…...