七、(正点原子)Linux并发与竞争
Linux是多任务操作系统,肯定会存在多个任务共同操作同一段内存或者设备的情况,多个任务甚至中断都能访问的资源叫做共享资源。在驱动开发中要注意对共享资源的保护,也就是要处理对共享资源的并发访问。
一、并发与竞争
1、简介
并发就是多个“用户”同时访问同一个共享资源,带来的问题就是竞争问题。Linux 系统是个多任务操作系统,会存在多个任务同时访问同一片内存区域,这些任务可能会相互覆盖这段内存中的数据,造成内存数据混乱。针对这个问题必须要做处理,严重的话可能会导致系统崩溃。现在的 Linux 系统并发产生的原因很复杂,总结一下有下面几个主要原因:
- 多线程并发访问
- 抢占式并发访问
- 中断程序并发访问
- SMP(多核)间并发访问
举一个简单的例子:比如说C语言中 a = 3 这样一句代码,它编译时候其实不是一句代码,而是编译成汇编的3句代码:
1 ldr r0, =0X30000000 /* 变量 a 地址 */
2 ldr r1, = 3 /* 要写入的值 */
3 str r1, [r0] /* 将 3 写入到 a 变量中 */比如正在执行上面的第二条语句时候,这个时候被其他任务打断,CPU被其他任务占用而且这个任务也是给一个变量赋值 b = 5 那么当这个任务运行到第二步时又被前面 a = 3 的任务打断,那么此时 r1 寄存器的值保存的就不是 3 而是 5 导致出现错误。
2、保护的内容是什么
并发是同时访问一个共享资源,那么共享资源是什么呢?说简单一点,共享资源其实就是数据,比如一个全局变量等等,所以找到要保护的数据才是重点,一般像全局变量,设备结构体这些肯定是必须保护的对象,其他的数据就要根据实际的驱动而定。
二、原子操作
1、简介
原子在化学中是最小的组成,不可再往下分,所以,原子操作就是指不可以再进一步分割的操作,一般原子操作用于变量或位操作。Linux内核提供了两组API函数,一组是对整型(int)变量进行操作,一组是对位进性操作。
- 整型原子操作API
Linux内核定义了叫 atomic_t 的结构体来完成整型数据的原子操作,使用原子变量来代替整型变量。定义在 include/linux/types.h中:

2、原子操作API函数
要使用原子操作API函数(定义在include/asm/atomic.h),首先要定义一个atomic_t的原子变量。
| 函数 | 描述 |
|---|---|
| ATOMIC_INIT(int i) | 定义原子变量并初始化 |
| int atomic_read(atomic_t *v) | 读取v的值,并返回 |
| void atomic_set(atomic_t *v, int i) | 给v写入i值 |
| void atomic_add(int i,atomic_t *v) | 给v加上i值 |
| void atomic_sub(int i,atomic_t *v) | 给v减去i值 |
| void atomic_inc(atomic_t *v) | v自增1 |
| void atomic_dec(atomic_t *v) | v自减1 |
| int atomic_inc_return(atomic_t *v) | v自增1,并返回v的值 |
| int atomic_dec_return(atomic_t *v) | v自减1,并返回v的值 |
| int atomic_inc_and_test(atomic_t *v) | v自增1,如果v==0返回真,否者返回假 |
| int atomic_dec_and_test(atomic_t *v) | v自减1,如果v==0返回真,否者返回假 |
| int atomic_sub_and_test(int i,atomic_t *v) | v减i值,如果v==0返回真,否者返回假 |
| int atomic_add_negative(int i,atomic_t *v) | v加i值,如果v为负返回真,否者返回假 |
如果使用的时64位的SOC的话,要使用到64位的原子变量:
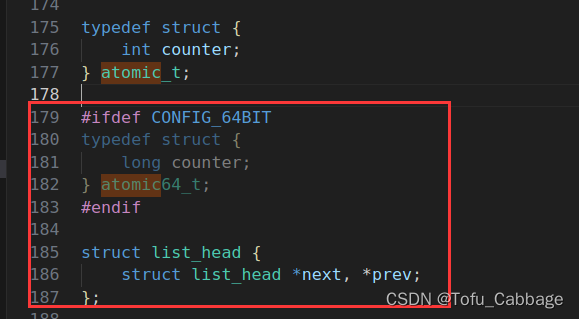
相应的API函数也是一样,将“atomic_”换位“atomic64_”。将“int”换为“long long”。
- 原子位操作API
位操作也就是将对应的位置1或清零这样的操作。Linux 内核也提供了一系列的原子位操作 API 函数,只不过原子位操作不像原子整形变量那样有个 atomic_t 的数据结构,原子位操作是直接对内存进行操作,API 函数(定义在include/asm/bitops.h):
| 函数 | 描述 |
|---|---|
| void set_bit(int nr, void *p) | 将p地址的第nr位置1 |
| void clear_bit(int nr, void *p) | pps将p地址的第nr位清零 |
| void change_bit(int nr, void *p) | 将p地址的第nr位翻转 |
| int test_bit(int nr, void *p) | 获取p地址的第nr位的值。 |
| int test_and_set_bit(int nr, void *p) | 获取p地址的nr位并将该位置1,返回nr位原来的值 |
| int test_and_clear_bit(int nr, void *p) | 获取p地址的nr位并将该位清零,返回nr位原来的值 |
| int test_and_change_bit(int nr, void *p) | 获取p地址的nr位并将该位翻转,返回nr位原来的值 |
三、自旋锁
1、简介
原子操作只能对整形变量或者位进行保护,但是,在实际的使用环境中不可能只有整形变量或位这么简单的临界区(代码保护区)。举个最简单的例子,设备结构体变量就不是整型变量,我们对于结构体中成员变量的操作也要保证原子性,在线程 A 对结构体变量使用期间,应该禁止其他的线程来访问此结构体变量,这些工作原子操作都不能胜任,需要本节要讲的锁机制,在 Linux内核中就是自旋锁。
当一个线程要访问某个共享资源的时候首先要先获取相应的锁, 锁只能被一个线程持有,只要此线程不释放持有的锁,那么其他的线程就不能获取此锁。对于自旋锁而言,如果自旋锁正在被线程 A 持有,线程 B 想要获取自旋锁,那么线程 B 就会处于忙循环-旋转-等待状态,线程 B 不会进入休眠状态或者说去做其他的处理,而是会一直傻傻的在那里“转圈圈”的等待锁可用。
自旋锁的“自旋”也就是“原地打转”的意思,“原地打转”的目的是为了等待自旋锁可以用,可以访问共享资源。把自旋锁比作一个变量 a,变量 a=1 的时候表示共享资源可用,当 a=0的时候表示共享资源不可用。现在线程 A 要访问共享资源,发现 a=0(自旋锁被其他线程持有),那么线程 A 就会不断的查询 a 的值,直到 a=1。从这里我们可以看到自旋锁的一个缺点:那就等待自旋锁的线程会一直处于自旋状态,这样会浪费处理器时间,降低系统性能,所以自旋锁的持有时间不能太长。
Linux内核使用结构体spinlock_t表示自旋锁,在linux/spinlock_types.h中定义:

在使用自旋锁之前,要先定义一个自旋锁变量,然后可以使用相应的API函数(定义在include/linux/spinlock.h)来操作自旋锁。
2、自旋锁API函数
| 函数 | 描述 |
|---|---|
| DEFINE_SPINLOCK(spinlock_t lock) | 定义并初始化一个自旋锁变量 |
| int spin_lock_init(spinlock_t *lock) | 初始化自旋锁 |
| void spin_lock(spinlock_t *lock) | 加锁 |
| void spin_unlock(spinlock_t *lock) | 解锁 |
| int spin_trylock(spinlock_t *lock) | 加锁,如果加锁失败返回0 |
| int spin_is_locked(spinlock_t *lock) | 检查lock是否被获取,如果没有被获取返回非0,否则返回0 |
自旋锁API适用于SMP(多核)或单CPU支持抢占的线程之间的并发访问,中断中也可以使用自旋锁,但是在中断里面使用自旋锁的时候,在获取锁之前一定要先禁止本地中断(也就是本 CPU 中断,对于多核 SOC来说会有多个 CPU 核),否则可能导致锁死现象的发生。被自旋锁保护的临界区一定不能调用任何能够引起睡眠和阻塞的API 函数,否则的话会可能会导致死锁现象的发生自旋锁会自动禁止抢占,也就说当线程 A得到锁以后会暂时禁止内核抢占。如果线程 A 在持有锁期间进入了休眠状态,那么线程 A 会自动放弃 CPU 使用权。线程 B 开始运行,线程 B 也想要获取锁,但是此时锁被 A 线程持有,而且内核抢占还被禁止了!线程 B 无法被调度出去,那么线程 A 就无法运行,锁也就无法释放,死锁发生!
所以,一般在使用自旋锁之前,我们先关闭本地中断。Linux内核也提供了一些相应的API函数:
| 函数 | 描述 |
|---|---|
| void spin_lock_irq(spinlock_t *lock) | 禁止本地中断,并自锁 |
| void spin_unlock_irq(spinlock_t *lock) | 激活本地中断,并解锁 |
| void spin_lock_irqsave(spinlock_t *lock,unsigned long falgs) | 保存中断状态,禁止本地中断,并自锁 |
| void spin_unlock_irqrestore(spinlock_t *lock,unsigned long falgs) | 将中断恢复原来状态,激活本地中断,并解锁 |
3、其他类型的锁
- 读写自旋锁
我们的数据使用自旋锁对其保护时,每次只能一个读和写操作,但是,实际上是可以多个线程并发读取数据的。只需要保证在修改数据的时候没有线程读取,或者读取时,没有线程在修改数据。也就是渡河写操作不能同时进性。所以引入了读写自旋锁。
读写自旋锁为读操作和写操作提供了不同的锁,一次只能允许一个写操作,在进性写操作时,不能进性读操作。可以多线程一起读操作,但读操作时不能进性写操作。Linux内核中定义了rwlock_t结构体(定义在include/linux/rwlock_types.h中)表示读写锁操作:
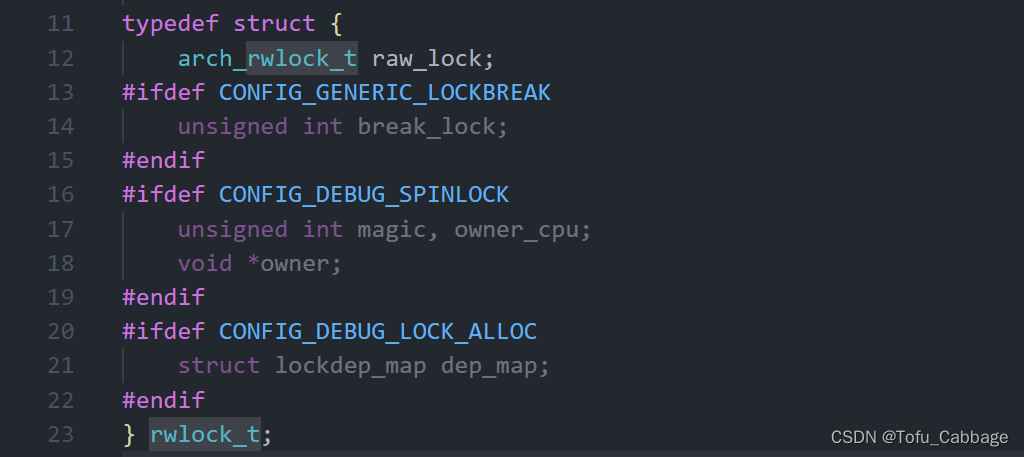
读写自旋锁的API函数(定义在include/linux/rwlock.h):
| 函数 | 描述 |
|---|---|
| DEFINE_RWLOCK(rwlock_t lock) | 定义并初始化读写锁 |
| void rwlock_init(rwlock_t *lock) | 初始化读写锁 |
| 读锁 | |
| void read_lock(rwlock_t *lock) | 获取读锁 |
| void read_unlock(rwlock_t *lock) | 释放读锁 |
| void read_lock_irq(rwlock_t *lock) | 禁止本地中断,并且获取读锁 |
| void read_unlock_irq(rwlock_t *lock) | 打开本地中断,并且释放读锁 |
| void read_lock_irqsave(rwlock_t *lock, unsigned long flags) | 保存中断状态,禁止本地中断,并获取读锁 |
| void read_unlock_irqrestore(rwlock_t *lock, unsigned long flags) | 将中断状态恢复到以前的状态,并且激活本地中断,释放读锁 |
| 写锁 | |
| void write_lock(rwlock_t *lock) | 获取写锁 |
| void write_unlock(rwlock_t *lock) | 释放写锁 |
| void write_lock_irq(rwlock_t *lock) | 禁止本地中断,并且获取写锁 |
| void write_unlock_irq(rwlock_t *lock) | 打开本地中断,并且释放写锁 |
| void write_lock_irqsave(rwlock_t *lock, unsigned long flags) | 保存中断状态,禁止本地中断,并获取写锁 |
| void write_unlock_irqrestore(rwlock_t *lock, unsigned long flags) | 将中断状态恢复到以前的状态,并且激活本地中断,释放读锁 |
- 顺序锁
顺序锁在读写锁的基础上衍生而来的,使用读写锁的时候读操作和写操作不能同时进行。使用顺序锁的话可以允许在写的时候进行读操作,也就是实现同时读写,但是不允许同时进行并发的写操作。虽然顺序锁的读和写操作可以同时进行,但是如果在读的过程中发生了写操作,最好重新进行读取,保证数据完整性。顺序锁保护的资源不能是指针,因为如果在写操作的时候可能会导致指针无效,而这个时候恰巧有读操作访问指针的话就可能导致意外发生,比如读取野指针导致系统崩溃。
Linux 内核使用 seqlock_t 结构体(定义在include/linux/seqlock.h)表示顺序锁,结构体定义如下:
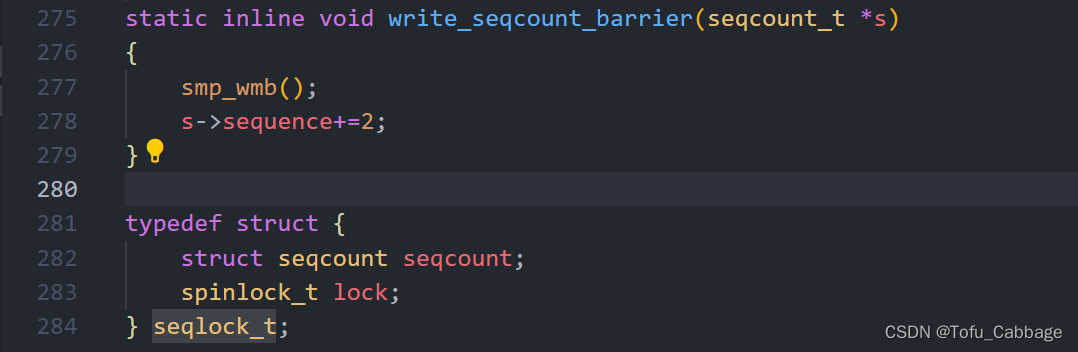
关于顺序锁的API函数(定义在include/linux/seqlock.h):
| 函数 | 描述 |
|---|---|
| DEFINE_SEQLOCK(seqlock_t sl) | 定义并初始化顺序锁 |
| void seqlock_ini seqlock_t *sl) | 初始化顺序锁 |
| 顺序表写操作 | |
| void write_seqlock(seqlock_t *sl) | 获取写顺序锁 |
| void write_sequnlock(seqlock_t *sl) | 释放写顺序锁 |
| void write_seqlock_irq(seqlock_t *sl) | 禁止本地中断,并且获取写顺序锁 |
| void write_sequnlock_irq(seqlock_t *sl) | 打开本地中断,并且释放写顺序锁 |
| void write_seqlock_irqsave(seqlock_t *sl, unsigned long flags) | 保存中断状态,禁止本地中断,并获取写顺序锁 |
| void write_sequnlock_irqrestore(seqlock_t *sl, unsigned long flags) | 将中断状态恢复到以前的状态,并且激活本地中断,释放写顺序锁 |
| 顺序表读操作 | |
| unsigned read_seqbegin(const seqlock_t *sl) | 读单元访问共享资源的时候调用此函数,此函数会返回顺序锁的顺序号 |
| unsigned read_seqretry(const seqlock_t *sl, unsigned start) | 读结束以后调用此函数检查在读的过程中有没有对资源进行写操作,如果有的话就要重读 |
4、自旋锁使用注意事项
- 因为在等待自旋锁的时候处于“自旋”状态,因此锁的持有时间不能太长,一定要短,否则的 话会降低系统性能。如果临界区比较大,运行时间比较长的话要选择其他的并发处理方式, 比如稍后要讲的信号量和互斥体。
- 自旋锁保护的临界区内不能调用任何可能导致线程休眠的 API 函数,否则的话可能导致死 锁。
- 不能递归申请自旋锁,因为一旦通过递归的方式申请一个你正在持有的锁,那么你就必须 “自旋”,等待锁被释放,然而你正处于“自旋”状态,根本没法释放锁。所以就死锁。
- 在编写驱动程序的时候我们必须考虑到驱动的可移植性,因此不管你用的是单核的还是多核 的 SOC,都将其当做多核 SOC 来编写驱动程序。
四、信号量
1、简介
这里的信号量与FreeRTOS或者UCOS的信号量一样,常常用于控制对共享资源的访问。比如停车位举例:有10个停车位,信号量为10,当有一辆车进来停车,停车位减一,相当于一个线程读取数据一次,信号量减1。当停车位停满了,信号量减为零,就不能再停下一辆车,线程不能再读取数据,只能等别的车离开,才能停车,相当于线程读取数据完成后,信号量加一。此时,又可以停车。
相比于自旋锁,信号量可以时线程进入休眠状态,比如说:A现在再厕所上厕所,这个时候B也想上厕所,但是看到厕所现在A在使用,B就无法使用,B可以一直在厕所等待,就相当于自旋锁。或者B可以先离开去干其他的事,等A上完厕所后再通知B让B去上厕所,就相当于信号量线程可以进入休眠状态。
信号量特点:
- 因为信号量可以使等待资源线程进入休眠状态,因此适用于那些占用资源比较久的场
- 信号量不能用于中断中,因为信号量会引起休眠,中断不能休眠。
- 如果共享资源的持有时间比较短,那就不适合使用信号量了,因为频繁的休眠、切换线 程引起的开销要远大于信号量带来的那点优势。
- 当信号量的值设置为1时,为二值信号量,可以互斥访问。当信号量的值大于1时,为计 数型信号量,不可以互斥访问。
2、信号量API函数
Linux 内核使用 semaphore 结构体(定义在include/linux/semaphore.h)表示信号量:

使用信号量之前先定义和初始化信号量结构体,再使用信号量API函数(定义在include/linux/semaphore.h):
| 函数 | 描述 |
|---|---|
| DEFINE_SEAMPHORE(name) | 定义一个信号量,并且设置信号量的值为 1 |
| void sema_init(struct semaphore *sem, int val) | 初始化信号量 sem,设置信号量值为 val |
| void down(struct semaphore *sem) | 获取信号量,因为会导致休眠,因此不能在中断中使用 |
| int down_trylock(struct semaphore *sem) | 尝试获取信号量,如果能获取到信号量就获取,并且返回 0。如果不能就返回非 0,并且不会进入休眠 |
| int down_interruptible(struct semaphore *sem) | 获取信号量,和 down 类似,只是使用 down 进入休眠状态的线程不能被信号打断。而使用此函数进入休眠以后是可以被信号打断的。 |
| void up(struct semaphore *sem) | 释放信号量 |
四、互斥体
1、简介
将信号量的值设置为 1 就可以使用信号量进行互斥访问了,虽然可以通过信号量实现互斥,但是 Linux 提供了一个比信号量更专业的机制来进行互斥,它就是互斥体—mutex。
互斥访问表示一次只有一个线程可以访问共享资源,不能递归申请互斥体。Linux内核使用mutex结构体(定义在include/linux/mutex.h)表示互斥体: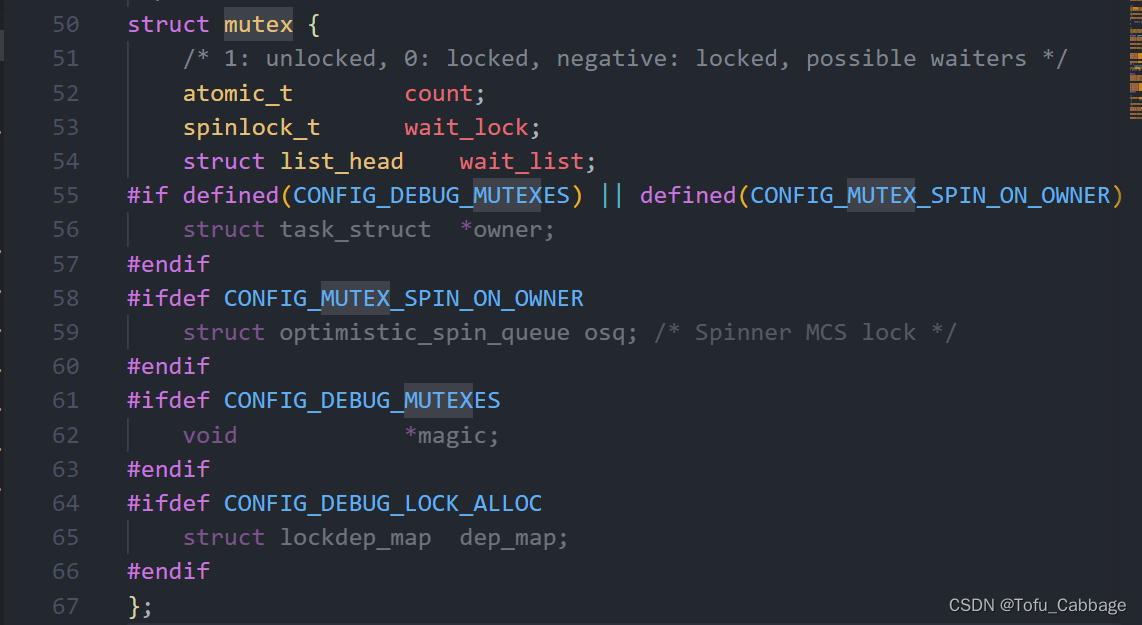
注意事项:
- mutex 可以导致休眠,因此不能在中断中使用 mutex,中断中只能使用自旋锁
- 和信号量一样, mutex 保护的临界区可以调用引起阻塞的 API 函数
- 因为一次只有一个线程可以持有 mutex,因此,必须由 mutex 的持有者释放 mutex。 并且 mutex 不能递归上锁和解锁
2、互斥体API函数
| 函数 | 描述 |
|---|---|
| DEFINE_MUTEX(name) | 定义并初始化一个 mutex 变量 |
| void mutex_init(mutex *lock) | 初始化 mutex |
| void mutex_lock(struct mutex *lock) | 获取 mutex,也就是给 mutex 上锁。如果获取不到就进休眠 |
| void mutex_unlock(struct mutex *lock) | 释放 mutex,也就给 mutex 解锁 |
| int mutex_trylock(struct mutex *lock) | 尝试获取 mutex,如果成功就返回 1,如果失败就返回 0 |
| int mutex_is_locked(struct mutex *lock) | 判断 mutex 是否被获取,如果是的话就返回1,否则返回 0 |
| int mutex_lock_interruptible(struct mutex *lock) | 使用此函数获取信号量失败进入休眠以后可以被信号打断 |
相关文章:
七、(正点原子)Linux并发与竞争
Linux是多任务操作系统,肯定会存在多个任务共同操作同一段内存或者设备的情况,多个任务甚至中断都能访问的资源叫做共享资源。在驱动开发中要注意对共享资源的保护,也就是要处理对共享资源的并发访问。 一、并发与竞争 1、简介 并发就是多个…...

vue2+TS,el-table表格单选的写法
1.打开表格 //父组件引入 <customerChoose ref"customerChooseRef" onSure"setOrderInfoFn"></customerChoose>//子传父,接收值,操作private async setOrderInfoFn(data) {this.form.customerId data.idthis.form.cu…...

北邮《计算机网络》蒋老师思考题及答案-传输层
蒋yj老师yyds! 答案自制,仅供参考,欢迎质疑讨论 问题一览 传输层思考题P2P和E2E的区别使用socket的c/s模式通信,流控如何反映到编程模型三次握手解决什么问题举一个两次握手失败的例子为什么链路层是两次握手而非三次?…...

学懂C#编程:常用高级技术【元组的详细使用】——利用元组获取多个返回值
C#常用高级技术——利用元组获取多个返回值 在C# 7.0及更高版本中,您可以使用元组(Tuples)来实现这种返回多个值的方法。您提供的代码片段是正确的,它定义了一个名为Calculate的方法,该方法接受两个整数参数a和b&#…...

解决IDEA使用卡顿的问题,设置JVM内存大小和清理缓存
解决IntelliJ IDEA中卡顿问题,可以尝试以下几个常见且有效的步骤: 1 增加IDEA的JVM内存分配: 位于IDEA安装目录的bin文件夹下,找到对应的操作系统配置文件(idea64.exe.vmoptions(Windows)或id…...
Python爬虫从入门到入狱之爬取知乎用户信息
items中的代码主要是我们要爬取的字段的定义 class UserItem(scrapy.Item):id \ Field()name \ Field()account\_status \ Field()allow\_message\ Field()answer\_count \ Field()articles\_count \ Field()avatar\_hue \ Field()avatar\_url \ Field()avatar\_url\_template…...
apk反编译修改教程系列-----去除apk软件更新方法步骤列举 记录八种最常见的去除方法
在前面几期博文中 有说明去除apk软件更新的步骤方法。我们在对应软件反编译去除更新中要灵活运用。区别对待。同一个软件可以有不同的去除更新方法可以适用。今天的教程对于软件更新去除列举几种经常使用的修改步骤。 通过基础课程可以了解 1-----软件反编译更新去除的几种常…...

SpringMVC系列六: 视图和视图解析器
视图和视图解析器 💞基本介绍💞 自定义视图为什么需要自定义视图自定义试图实例-代码实现自定义视图工作流程小结Debug源码默认视图解析器执行流程多个视图解析器执行流程 💞目标方法直接指定转发或重定向使用实例指定请求转发流程-Debug源码…...

MySQL数据备份的分类
MySQL数据库的备份 在我们使用MySQL数据库的过程中,一些意外情况的发生,有可能造成数据的损失。例如,意外的停电,不小心的操作失误等都可能造成数据的丢失。 所以为了保证数据的安全与一致性,需要定期对数据进行备份。…...
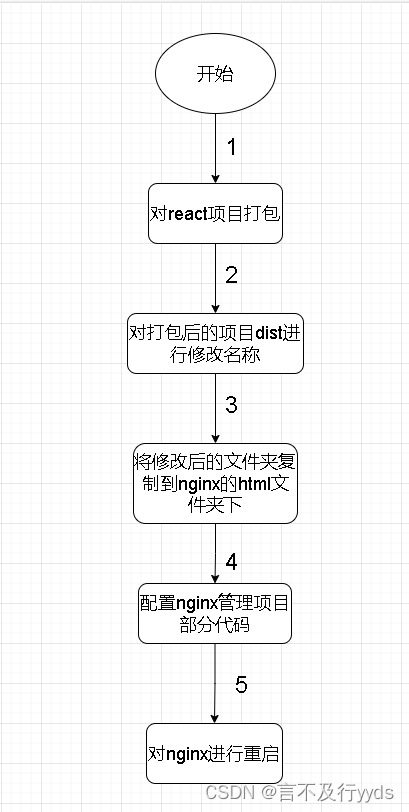
node+nginx实现对react进行一键打包部署--windows版
文章目录 nodenginx实现对react进行一键打包部署--windows版1.功能展示及项目准备1.1功能展示 1.2 项目准备1.2.1技术点1.2.2安装相关配置(windows) 2.实现2.1 实现思路2.2 实现步骤2.1 项目准备2.1.1 创建env文件2.1.2 创建api/index.js文件2.1.3 添加解决跨域代码 2.2 项目实…...

【机器学习】基于Gumbel-Sinkhorn网络的“潜在排列问题”求解
1. 引言 1.1.“潜在排列”问题 本文将深入探索一种特殊的神经网络方法,该方法在处理离散对象时展现出卓越的能力,尤其是针对潜在排列问题的解决方案。在现代机器学习和深度学习的领域中,处理离散数据一直是一个挑战,因为传统的神经网络架构通常是为连续数据设计的。然而,…...

create-react-app创建的项目中设置webpack配置
create-react-app 创建的项目默认使用的是 react-scripts(存在于node_modules文件夹中)来处理开发服务器和构建,它内置了一些webpack相关配置。一般不会暴露出来给开发者,但是在有些情况下我们需要修改下webpack默认配置ÿ…...
【ai】tx2 nx :安装torch、torchvision for yolov5
torchvision 是自己本地构建的验证torchvision nvidia@tx2-nx:~/twork/03_yolov5/torchvision$ nvidia@tx2-nx:~/twork/03_yolov5/torchvision$ python3 Python 3.6.9 (default, Mar 10 2023, 16:46:00) [GCC 8.4.0] on linux Type "help", "copyright",…...

【报错】在终端中输入repo命令后系统未能识别这个命令
1 报错 已经使用curl命令来下载repo工具,但是在终端中输入repo命令后系统未能识别这个命令。 2 分析 通常是因为repo...

【机器学习】K-Means算法详解:从原理到实践
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 K-Means算法详解:从原理到实践引言1. 基本原理1.1 簇与距离度量1.2 …...

解决qiankun项目与子应用样式混乱问题
背景 qiankun项目用的是Vue2Antdesign2,但其中一个子应用用的是Vue3Antdesign4。集成之后发现子应用的样式混乱,渲染的是Antdesign2的样式。 解决 以下步骤在子应用里操作 1. 在main.js引入ConfigProvider ,在app全局注册ConfigProvider …...
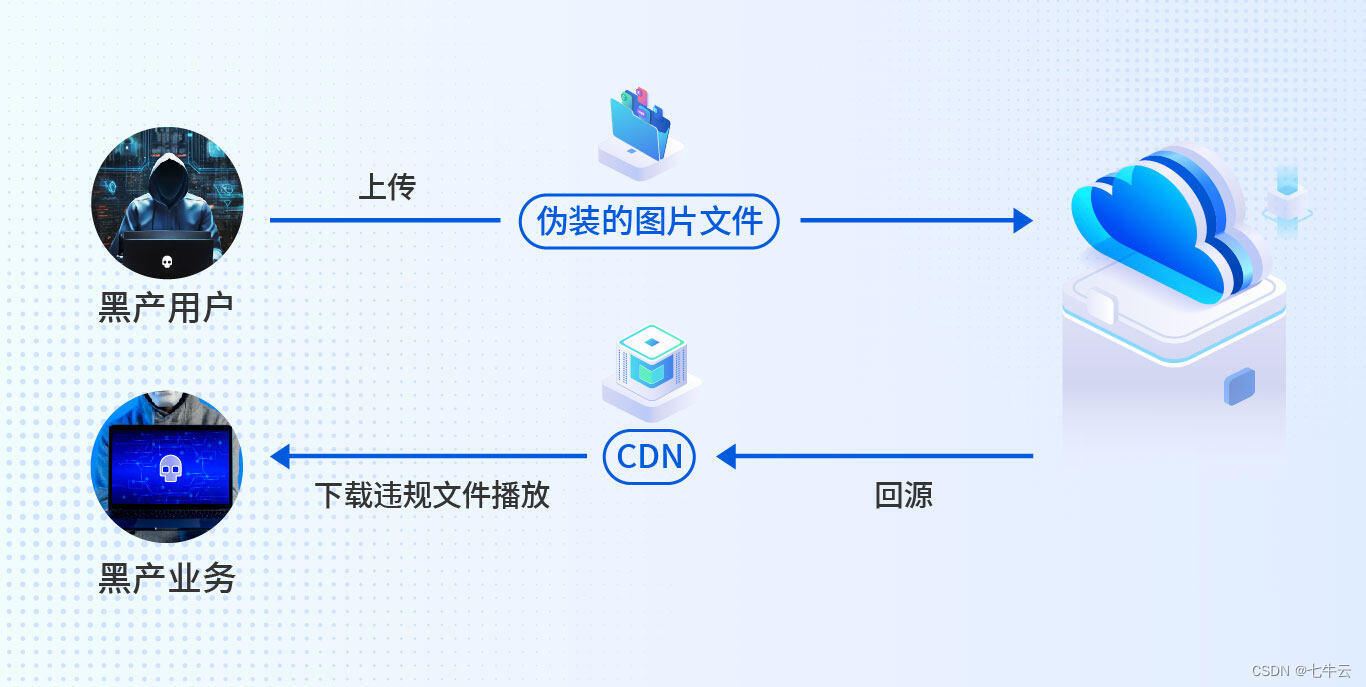
黑产当前,如何识别异常图片?
在这个人人都是创作者的年代, UGC 已成为诸多平台的重要组成。 有利益的地方就会有黑产存在, 不少 UGC 平台都被黑产「薅羊毛」搞的心烦意乱, 用户传的图片,怎么就变成视频链接了? 正常运营的平台,为何流量…...

数据模型(models)
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 (1)在App中添加数据模型 在app1的models.py中添加如下代码: from django.db import models # 引入django.…...
743. 网络延迟时间 - Dijkstra算法题解)
【CS.AL】算法核心之贪心算法 —— 力扣(LeetCode)743. 网络延迟时间 - Dijkstra算法题解
文章目录 题目描述References 题目描述 743. 网络延迟时间 - 力扣(LeetCode) 有 N 个网络节点,标记为 1 到 N。 给定一个列表 times,其中 times[i] (u, v, w) 表示有一条从节点 u 到节点 v 的时延为 w 的有向边。 现在…...

25、架构-微服务的驱动力
微服务架构的驱动力可以从多方面探讨,包括灵活性、独立部署、技术异构性、团队效率和系统弹性等。 灵活性和可维护性 灵活性是微服务架构的一个主要优势。通过将单体应用拆分成多个独立的微服务,开发团队可以更容易地管理、维护和更新各个服务。每个微…...

避坑指南:从ADS导入DXF到Altium Designer时,如何解决封装丢失和铺铜失败的常见问题
从ADS到Altium Designer的工程迁移:封装与铺铜问题的深度解决方案 在射频与微波电路设计领域,工程师常常面临一个典型困境:如何在ADS(Advanced Design System)中完成高频仿真后,将设计无缝迁移到Altium Des…...

STM32F108C8T6小白入门特训营__1.4GPIO.C 代码分析
目录 1.只需要搞明白 cubemx 跟 代码对应关系就可以了 2.GPIO.C 代码加上注释 3.注意引脚的宏定义 1.只需要搞明白 cubemx 跟 代码对应关系就可以了 2.GPIO.C 代码加上注释 读懂注释部分代码即可 /* USER CODE BEGIN Header */ /*****************************************…...

【NotebookLM要点提取黄金法则】:20年AI工具实战总结的5大避坑指南与3步精准萃取法
更多请点击: https://intelliparadigm.com 第一章:NotebookLM要点提取方法论全景概览 NotebookLM 是 Google 推出的面向研究者与知识工作者的 AI 原生笔记工具,其核心能力在于对用户上传文档(PDF、TXT、Google Docs)进…...

【ElevenLabs企业级克隆部署白皮书】:单模型支持12种语境情绪、延迟<480ms、通过GDPR+CCPA双认证
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs企业级语音克隆技术全景概览 ElevenLabs 企业级语音克隆技术以高保真度、低延迟和强可控性为核心,面向金融客服、跨国培训、无障碍内容生成等关键业务场景提供端到端语音合成解决…...

不只是CT重建:手把手教你用RTK+ITK+VS2022搭建可扩展的医学影像处理开发环境
构建医学影像算法开发平台:RTKITKVS2022全流程实战指南 医学影像处理领域正迎来前所未有的技术革新,从传统的CT重建到三维可视化、病灶自动检测等高级应用,开发者需要一套稳定且可扩展的开发环境。本文将带您从零开始,在Windows平…...

CH398X:USB3.2 Gen1 转千兆以太网 高集成国产芯片方案
一、前言轻薄本、平板、工控机、扩展坞、嵌入式主板等设备,普遍需要高速 USB 扩展千兆有线网口来满足大文件传输、直播推流、工业实时通信的低延迟稳定需求。传统转接方案存在外围复杂、功耗偏高、兼容性差、工控环境不稳定、国产化替代难等痛点。沁恒微电子&#x…...
)
别再死磕PSO了!用Python手把手教你实现GWO灰狼优化算法(附完整代码)
用Python实战GWO灰狼优化算法:告别传统优化方法的局限 在工程优化和机器学习领域,算法选择往往决定了问题求解的效率和质量。传统粒子群优化(PSO)算法虽然广为人知,但其参数调节复杂、易陷入局部最优的缺点也日益明显。灰狼优化算法(Grey Wol…...

基于Minicursor理念的Node.js后端服务快速搭建与架构解析
1. 项目概述与核心价值最近在折腾一个个人项目,需要快速搭建一个轻量级的、能处理实时数据流的后端服务。在寻找合适的脚手架时,我偶然在 GitHub 上发现了forrestchang/minicursor这个项目。乍一看名字,你可能会联想到数据库的“游标”&#…...
)
保姆级教程:从零开始给SkyWalking Agent写一个自定义日志插件(Logback篇)
深入SkyWalking Agent插件开发:构建自定义日志组件的完整方法论 在分布式系统的监控领域,SkyWalking以其强大的全链路追踪能力广受开发者青睐。但很多团队在基础监控之外,往往需要根据业务特点定制专属的监控指标——比如在日志中嵌入用户ID、…...

精通yum/dnf:从依赖地狱到高效Linux软件包管理
1. 从“依赖地狱”到“一键管理”:为什么你需要精通yum/dnf在Linux世界里,尤其是Red Hat系(RHEL、CentOS、Fedora、Rocky Linux、AlmaLinux)的用户,软件包管理是绕不开的日常。如果你还在用rpm -ivh一个接一个地手动安…...