RabbitMQ的WorkQueues模型
WorkQueues模型
Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。
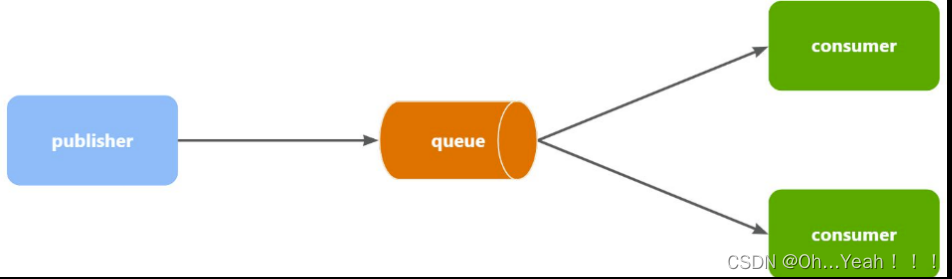
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高了。
接下来,我们就来模拟这样的场景。

首先,我们在控制台创建一个新的队列,命名为work.queue:
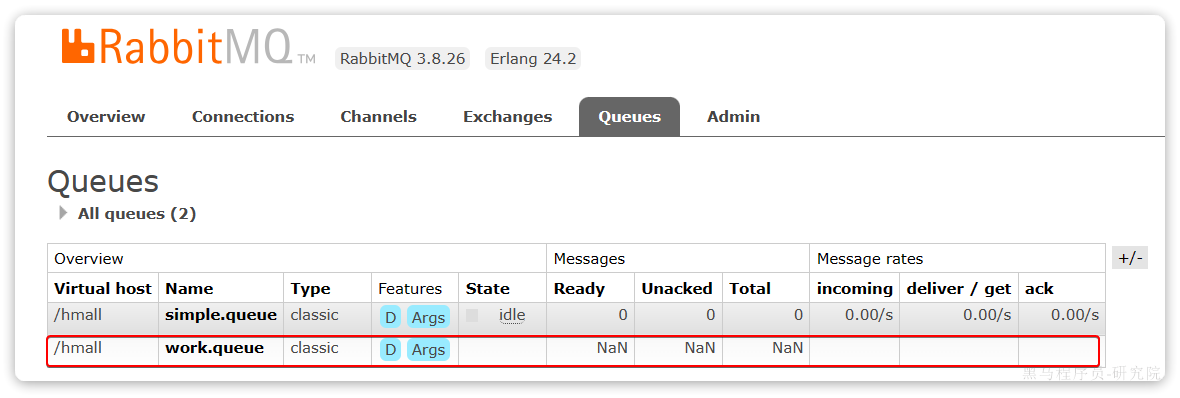
3.3.1.消息发送
这次我们循环发送,模拟大量消息堆积现象。
在publisher服务中的SpringAmqpTest类中添加一个测试方法:
/*** workQueue* 向队列中不停发送消息,模拟消息堆积。*/
@Test
public void testWorkQueue() throws InterruptedException {// 队列名称String queueName = "work.queue";// 消息String message = "hello, message_";for (int i = 0; i < 50; i++) {// 发送消息,每20毫秒发送一次,相当于每秒发送50条消息rabbitTemplate.convertAndSend(queueName, message + i);Thread.sleep(20);}
}
3.3.2.消息接收
要模拟多个消费者绑定同一个队列,我们在consumer服务的SpringRabbitListener中添加2个新的方法:
@RabbitListener(queues = "work.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now());Thread.sleep(20);
}@RabbitListener(queues = "work.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now());Thread.sleep(200);
}
注意到这两消费者,都设置了Thead.sleep,模拟任务耗时:
- 消费者1 sleep了20毫秒,相当于每秒钟处理50个消息
- 消费者2 sleep了200毫秒,相当于每秒处理5个消息
3.3.3.测试
启动ConsumerApplication后,在执行publisher服务中刚刚编写的发送测试方法testWorkQueue。
最终结果如下:
消费者1接收到消息:【hello, message_0】21:06:00.869555300
消费者2........接收到消息:【hello, message_1】21:06:00.884518
消费者1接收到消息:【hello, message_2】21:06:00.907454400
消费者1接收到消息:【hello, message_4】21:06:00.953332100
消费者1接收到消息:【hello, message_6】21:06:00.997867300
消费者1接收到消息:【hello, message_8】21:06:01.042178700
消费者2........接收到消息:【hello, message_3】21:06:01.086478800
消费者1接收到消息:【hello, message_10】21:06:01.087476600
消费者1接收到消息:【hello, message_12】21:06:01.132578300
消费者1接收到消息:【hello, message_14】21:06:01.175851200
消费者1接收到消息:【hello, message_16】21:06:01.218533400
消费者1接收到消息:【hello, message_18】21:06:01.261322900
消费者2........接收到消息:【hello, message_5】21:06:01.287003700
消费者1接收到消息:【hello, message_20】21:06:01.304412400
消费者1接收到消息:【hello, message_22】21:06:01.349950100
消费者1接收到消息:【hello, message_24】21:06:01.394533900
消费者1接收到消息:【hello, message_26】21:06:01.439876500
消费者1接收到消息:【hello, message_28】21:06:01.482937800
消费者2........接收到消息:【hello, message_7】21:06:01.488977100
消费者1接收到消息:【hello, message_30】21:06:01.526409300
消费者1接收到消息:【hello, message_32】21:06:01.572148
消费者1接收到消息:【hello, message_34】21:06:01.618264800
消费者1接收到消息:【hello, message_36】21:06:01.660780600
消费者2........接收到消息:【hello, message_9】21:06:01.689189300
消费者1接收到消息:【hello, message_38】21:06:01.705261
消费者1接收到消息:【hello, message_40】21:06:01.746927300
消费者1接收到消息:【hello, message_42】21:06:01.789835
消费者1接收到消息:【hello, message_44】21:06:01.834393100
消费者1接收到消息:【hello, message_46】21:06:01.875312100
消费者2........接收到消息:【hello, message_11】21:06:01.889969500
消费者1接收到消息:【hello, message_48】21:06:01.920702500
消费者2........接收到消息:【hello, message_13】21:06:02.090725900
消费者2........接收到消息:【hello, message_15】21:06:02.293060600
消费者2........接收到消息:【hello, message_17】21:06:02.493748
消费者2........接收到消息:【hello, message_19】21:06:02.696635100
消费者2........接收到消息:【hello, message_21】21:06:02.896809700
消费者2........接收到消息:【hello, message_23】21:06:03.099533400
消费者2........接收到消息:【hello, message_25】21:06:03.301446400
消费者2........接收到消息:【hello, message_27】21:06:03.504999100
消费者2........接收到消息:【hello, message_29】21:06:03.705702500
消费者2........接收到消息:【hello, message_31】21:06:03.906601200
消费者2........接收到消息:【hello, message_33】21:06:04.108118500
消费者2........接收到消息:【hello, message_35】21:06:04.308945400
消费者2........接收到消息:【hello, message_37】21:06:04.511547700
消费者2........接收到消息:【hello, message_39】21:06:04.714038400
消费者2........接收到消息:【hello, message_41】21:06:04.916192700
消费者2........接收到消息:【hello, message_43】21:06:05.116286400
消费者2........接收到消息:【hello, message_45】21:06:05.318055100
消费者2........接收到消息:【hello, message_47】21:06:05.520656400
消费者2........接收到消息:【hello, message_49】21:06:05.723106700可以看到消费者1和消费者2竟然每人消费了25条消息:
- 消费者1很快完成了自己的25条消息
- 消费者2却在缓慢的处理自己的25条消息。
也就是说消息是平均分配给每个消费者,并没有考虑到消费者的处理能力。导致1个消费者空闲,另一个消费者忙的不可开交。没有充分利用每一个消费者的能力,最终消息处理的耗时远远超过了1秒。这样显然是有问题的。
3.3.4.能者多劳(prefetch)
在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:
spring:rabbitmq:listener:simple:prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
再次测试,发现结果如下:
消费者1接收到消息:【hello, message_0】21:12:51.659664200
消费者2........接收到消息:【hello, message_1】21:12:51.680610
消费者1接收到消息:【hello, message_2】21:12:51.703625
消费者1接收到消息:【hello, message_3】21:12:51.724330100
消费者1接收到消息:【hello, message_4】21:12:51.746651100
消费者1接收到消息:【hello, message_5】21:12:51.768401400
消费者1接收到消息:【hello, message_6】21:12:51.790511400
消费者1接收到消息:【hello, message_7】21:12:51.812559800
消费者1接收到消息:【hello, message_8】21:12:51.834500600
消费者1接收到消息:【hello, message_9】21:12:51.857438800
消费者1接收到消息:【hello, message_10】21:12:51.880379600
消费者2........接收到消息:【hello, message_11】21:12:51.899327100
消费者1接收到消息:【hello, message_12】21:12:51.922828400
消费者1接收到消息:【hello, message_13】21:12:51.945617400
消费者1接收到消息:【hello, message_14】21:12:51.968942500
消费者1接收到消息:【hello, message_15】21:12:51.992215400
消费者1接收到消息:【hello, message_16】21:12:52.013325600
消费者1接收到消息:【hello, message_17】21:12:52.035687100
消费者1接收到消息:【hello, message_18】21:12:52.058188
消费者1接收到消息:【hello, message_19】21:12:52.081208400
消费者2........接收到消息:【hello, message_20】21:12:52.103406200
消费者1接收到消息:【hello, message_21】21:12:52.123827300
消费者1接收到消息:【hello, message_22】21:12:52.146165100
消费者1接收到消息:【hello, message_23】21:12:52.168828300
消费者1接收到消息:【hello, message_24】21:12:52.191769500
消费者1接收到消息:【hello, message_25】21:12:52.214839100
消费者1接收到消息:【hello, message_26】21:12:52.238998700
消费者1接收到消息:【hello, message_27】21:12:52.259772600
消费者1接收到消息:【hello, message_28】21:12:52.284131800
消费者2........接收到消息:【hello, message_29】21:12:52.306190600
消费者1接收到消息:【hello, message_30】21:12:52.325315800
消费者1接收到消息:【hello, message_31】21:12:52.347012500
消费者1接收到消息:【hello, message_32】21:12:52.368508600
消费者1接收到消息:【hello, message_33】21:12:52.391785100
消费者1接收到消息:【hello, message_34】21:12:52.416383800
消费者1接收到消息:【hello, message_35】21:12:52.439019
消费者1接收到消息:【hello, message_36】21:12:52.461733900
消费者1接收到消息:【hello, message_37】21:12:52.485990
消费者1接收到消息:【hello, message_38】21:12:52.509219900
消费者2........接收到消息:【hello, message_39】21:12:52.523683400
消费者1接收到消息:【hello, message_40】21:12:52.547412100
消费者1接收到消息:【hello, message_41】21:12:52.571191800
消费者1接收到消息:【hello, message_42】21:12:52.593024600
消费者1接收到消息:【hello, message_43】21:12:52.616731800
消费者1接收到消息:【hello, message_44】21:12:52.640317
消费者1接收到消息:【hello, message_45】21:12:52.663111100
消费者1接收到消息:【hello, message_46】21:12:52.686727
消费者1接收到消息:【hello, message_47】21:12:52.709266500
消费者2........接收到消息:【hello, message_48】21:12:52.725884900
消费者1接收到消息:【hello, message_49】21:12:52.746299900可以发现,由于消费者1处理速度较快,所以处理了更多的消息;消费者2处理速度较慢,只处理了6条消息。而最终总的执行耗时也在1秒左右,大大提升。
正所谓能者多劳,这样充分利用了每一个消费者的处理能力,可以有效避免消息积压问题。
3.3.5.总结(如何解决消息堆积的问题?)
Work模型的使用:
- 多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预取的消息数量

相关文章:
RabbitMQ的WorkQueues模型
WorkQueues模型 Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。 当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,…...

【LeetCode】每日一题:最大子数组和
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组是数组中的一个连续部分。 解题思路 要注意最小值是整个前缀,主要是cumsum然后按照买卖股票的思路做的&a…...
什么是进程?
前言👀~ 上一章我们介绍了计算机组成的入门知识,了解这些之后,今天来聊聊进程 进程 PCB pcb中的常见属性 进程调度 进程的状态 进程的优先级 上下文 记账信息 虚拟地址空间 如果各位对文章的内容感兴趣的话,请点点小赞&a…...

后端返回base64文件流下载
后端返回base64文件流: 前端处理: downloadTemplate () {this.$API.downloadTemplate().then(({ data }) > {const binaryString atob(data) // 解码base64字符串const byteArray new Uint8Array(binaryString.length) // 创建一个Uint8Arrayfor (let i 0; i…...

云原生面试
云原生面试 Kubernetes原理Kubernetes 如何保证集群的安全性。简述 Kubernetes 准入机制简述Kubernetes Secret 有哪些使用方式简述Kubernetes PodSecurityPolicy机制简述Kubernetes PodSecurityPolicy机制能实现哪些安全策略简述Kubernetes 网络策略原理简述Kubernetes 数据持…...
深度学习入门2—— 神经网络的组成和3层神经网络的实现
由上一章结尾,我们知道神经网络的一个重要性质是它可以自动地从数据中学习到合适的权重参数。接下来会介绍神经网络的概要,然后再结合手写数字识别案例进行介绍。 1.神经网络概要 1.1从感知机到神经网 我们可以用图来表示神经网络,我们把最…...
tensorflow学习:错误 InternalError: Dst tensor is not initialized
tensorflow学习:错误 InternalError: Dst tensor is not initialized_dst tensor is not initialized.-CSDN博客https://blog.csdn.net/wanglitao588/article/details/77033659...

Docker环境安装anythingllm
拉镜像 docker pull mintplexlabs/anythingllm建目录 export STORAGE_LOCATION$HOME/anythingllm && \ mkdir -p $STORAGE_LOCATION && \ touch "$STORAGE_LOCATION/.env"检查目录具有写权限 # 为目录anythingllm赋写权限 chmod 777 anythingllm 启…...

FEC 向前纠错编码
随写,看的有点杂,简单记一下。 应该叫ReedSolomon FEC RS算法简单来讲就是,根据已有数据,构造模型,然后根据模型判纠错? 简单来讲,两点确定一条直线,直线直线上的点都会满足 y kx…...
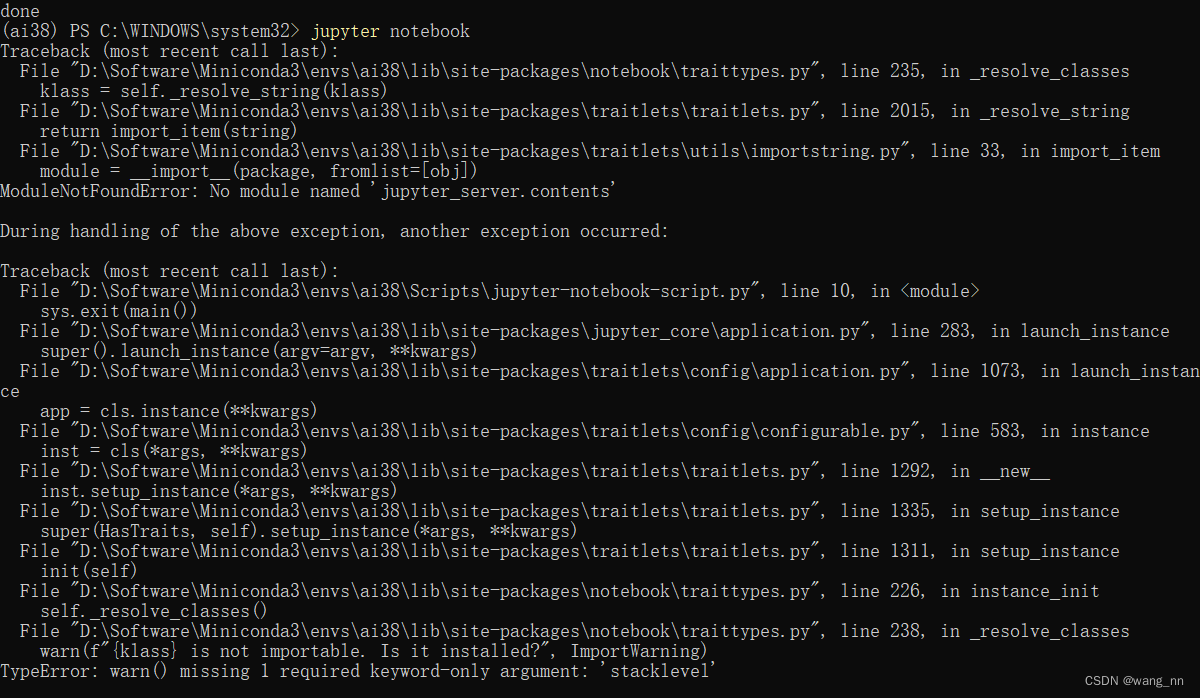
【jupyter notebook】解决打不开以及安装扩展插件的问题
文章目录 问题描述问题 1解决问题 2解决 问题描述 问题 1 在自定义的虚拟环境下,安装 jupyter notebook 6.4.12 版本时,报以下错误: 解决 查了一些 解决方法,执行以下命令即可解决: conda install traitlets5.9.0 …...

Perl文件句柄深度解析:掌握文件操作的核心
Perl中的文件句柄是进行文件输入输出操作的关键。它们提供了一种机制,允许Perl脚本打开文件、读写数据、定位文件指针,以及关闭文件。理解文件句柄的使用对于编写高效的Perl脚本至关重要。本文将深入探讨Perl文件句柄的概念、使用方法和最佳实践。 1. 文…...
Tomcat 下载部署到 idea
一、下载Tomcat Tomcat 是Apache 软件基金会(Apache Software Foundation)下的一个核心项目,免费开源、并支持Servlet 和JSP 规范。属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发…...

FutureTask如何使用?
FutureTask是Java中的一个具体类,它实现了RunnableFuture接口,该接口结合了Runnable和Future的功能。FutureTask可以用于表示一个可以取消的异步计算。FutureTask非常适合用于与Executor框架一起使用,但也可以单独使用。 FutureTask的基本用…...
Webpack: 如何借助预处理器、PostCSS 等构建现代 CSS 工程环境
概述 在开发 Web 应用时,我们通常需要编写大量 JavaScript 代码 —— 用于控制页面逻辑;编写大量 CSS 代码 —— 用于调整页面呈现形式。问题在于,CSS 语言在过去若干年中一直在追求样式表现力方面的提升,工程化能力薄弱ÿ…...

一篇文章告诉你如何正确使用chatgpt提示词
在chatgpt大火的时候,出现了一波学习chatgpt提示词的热潮,互联网出现很多了使用的学习提示词的课程。其中我觉得斯坦福大学教授吴恩达博士推出prompt engineer课最全面。接下来总结他课程中正确使用提示词工程的方法。 1. 明确目标 明确你希望ChatGPT完…...

qt基于QGraphicsView的屏幕旋转
一、代码实现 实现代码示例 MainWindow2 w;QGraphicsScene *scene new QGraphicsScene;QGraphicsProxyWidget *gw scene->addWidget(&w);// 旋转角度gw->setRotation(90);QGraphicsView *view new QGraphicsView(scene);//view->resize(1024, 600);//scene-&g…...
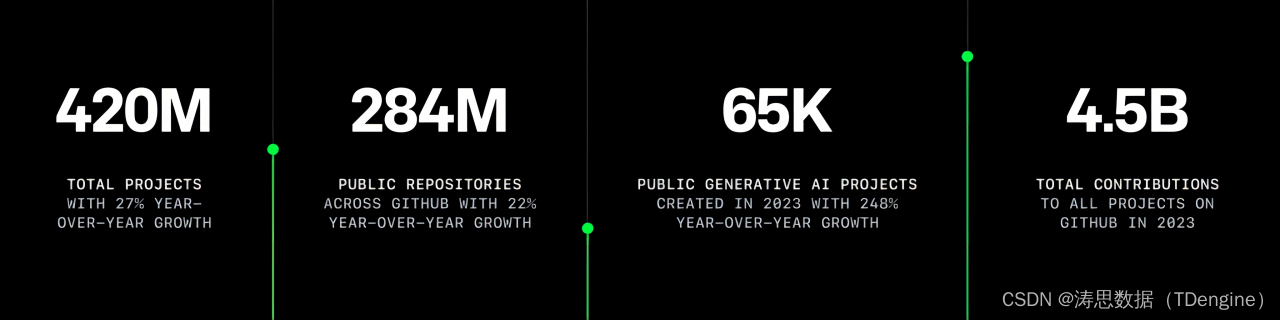
一个土木工程专业背景的开发者,讲述开源带给他的力量
在前段时间我们举办的“TDengine Open Day”第一季技术沙龙中,TDengine 应用研发高级工程师谭雪峰进行的“开源之路:程序员的成长与探索”主题分享获得了众多参会者的好评。谭雪峰从自身独特的职业发展经历出发,分享了自己在开源领域的种种收…...
express+vue在线im实现【四】
往期内容 expressvue在线im实现【一】 expressvue在线im实现【二】 expressvue在线im实现【三】 本期示例 本期总结 支持了音频的录制和发送,如果觉得对你有用,还请点个免费的收藏与关注 下期安排 在线语音 具体实现 <template><kl-dial…...

【Qt 实现3D按钮】
要在Qt中实现3D按钮,你可以使用QML和Qt 3D模块。这是一个简单的例子,展示了如何在Qt中创建一个3D按钮: 首先,确保你的系统中已经安装了Qt 3D模块。在命令行中输入以下命令检查: qmlscene --version如果没有安装&…...

8.每日LeetCode-笔试题,交替打印数字和字母
代码地址:interview-go: Go高级面试总结 问题描述 交替打印数字和字母 使用两个 goroutine 交替打印序列,一个 goroutine 打印数字, 另外一个 goroutine 打印字母, 最终效果如下: 12AB34CD56EF78GH910IJ1112KL…...

从流水线卡顿到丝滑训练:Deepspeed Pipeline Parallelism实战调优避坑指南
从流水线卡顿到丝滑训练:Deepspeed Pipeline Parallelism实战调优避坑指南 当你的Transformer模型参数量突破百亿级别,传统数据并行开始显露出明显的局限性——GPU内存不足、通信开销激增、计算资源利用率低下。这时,流水线并行(P…...

基于规则与启发式的Claude对话内容自动Markdown格式化工具实现
1. 项目概述与核心价值最近在折腾文档自动化生成工具时,发现了一个挺有意思的项目,叫looseleaf-acrylic560/claude-md-generator。乍一看这个名字,你可能觉得它就是个普通的Markdown生成器,但实际用下来,我发现它远不止…...

SpringBoot+Vue农产品电商系统源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...

团队协作福音:如何用EasyYapi插件统一SpringBoot项目的接口文档风格?
团队协作福音:如何用EasyYapi插件统一SpringBoot项目的接口文档风格? 在微服务架构盛行的今天,一个SpringBoot项目往往由多个团队协作开发。当接口数量突破三位数时,文档风格不统一、字段说明缺失等问题会让协作效率直线下降。上周…...

无线渗透测试框架Airecon:自动化工具链整合与实战应用
1. 项目概述与核心价值最近在整理自己的渗透测试工具箱时,又翻出了pikpikcu/airecon这个老伙计。说实话,在无线安全评估这个细分领域里,它可能不是名气最响的那个,但绝对是我个人在内部网络渗透和红队演练中最顺手、最高效的“组合…...

高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题
高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题 解析几何作为高考数学的压轴题型,常常让考生望而生畏。面对复杂的计算和抽象的条件,如何在有限时间内快速找到突破口?极点极线理论作为高等几何中的重要工具&#x…...

告别showSoftInput失效:一文读懂Android 11+的WindowInsetsController输入法控制
Android输入法控制演进:从InputMethodManager到WindowInsetsController的深度解析 在移动应用开发中,输入法交互是最基础却又最容易被忽视的细节之一。许多开发者都曾遇到过这样的场景:精心设计的登录界面,光标在输入框闪烁&#…...

Steam成就管理器终极指南:3步修复错失的游戏成就
Steam成就管理器终极指南:3步修复错失的游戏成就 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&a…...

三维重建实时映射技术在智慧水利中的核心应用
三维重建实时映射技术在智慧水利中的核心应用在国家大力推进数字孪生水利建设、实现水安全精准保障的背景下,智慧水利已从传统监测、调度向全域感知、智能预判、协同处置、一屏统管升级。智慧水利的核心目标,是实现对江河湖库、灌区、泵站、堤坝、闸站等…...

Arm Morello平台模型与CHERI安全扩展开发指南
1. Arm Morello平台模型概述Morello是Arm公司推出的实验性处理器架构,基于CHERI(Capability Hardware Enhanced RISC Instructions)安全扩展技术。这个平台模型本质上是一个功能准确的虚拟硬件环境,允许开发者在物理芯片问世前18-…...