学习入门 chatgpt原理 一
学习文章:人人都能看懂的chatGpt原理课
笔记作为学习用,侵删
Chatph和自然语言处理
什么是ChatGpt
ChatGPT(Chat Generative Pre-training Transformer) 是一个 AI 模型,属于自然语言处理( Natural Language Processing , NLP ) 领域,NLP 是人工智能的一个分支。
NLP(自然语言处理)是指,让计算机来理解并正确地操作自然语言(人们日常生活中接触和使用的英语、汉语、德语等等),完成人类指定的任务,比如关键词抽取,文本分类,机器翻译,对话系统(聊天机器人,也是chatgpt完成的工作)
ChatGPT 的建模形式
Chatgpt的工作形式:
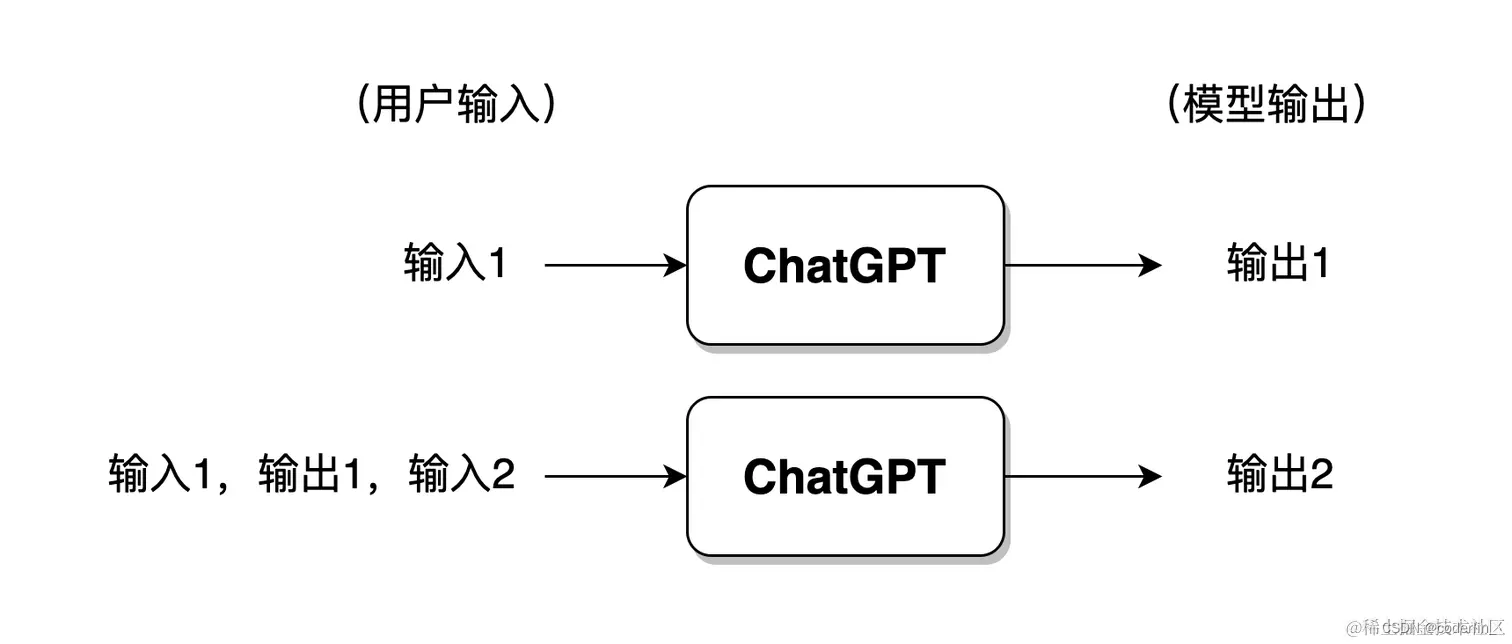
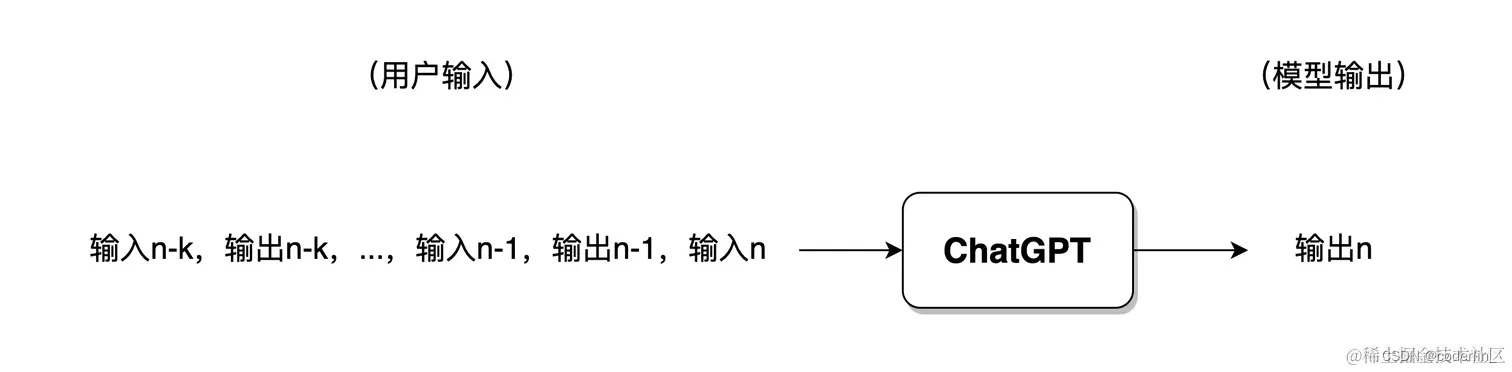
多轮对话时,一般来讲模型仅会保留最近几轮对话的信息,此前的对话信息将被遗忘。
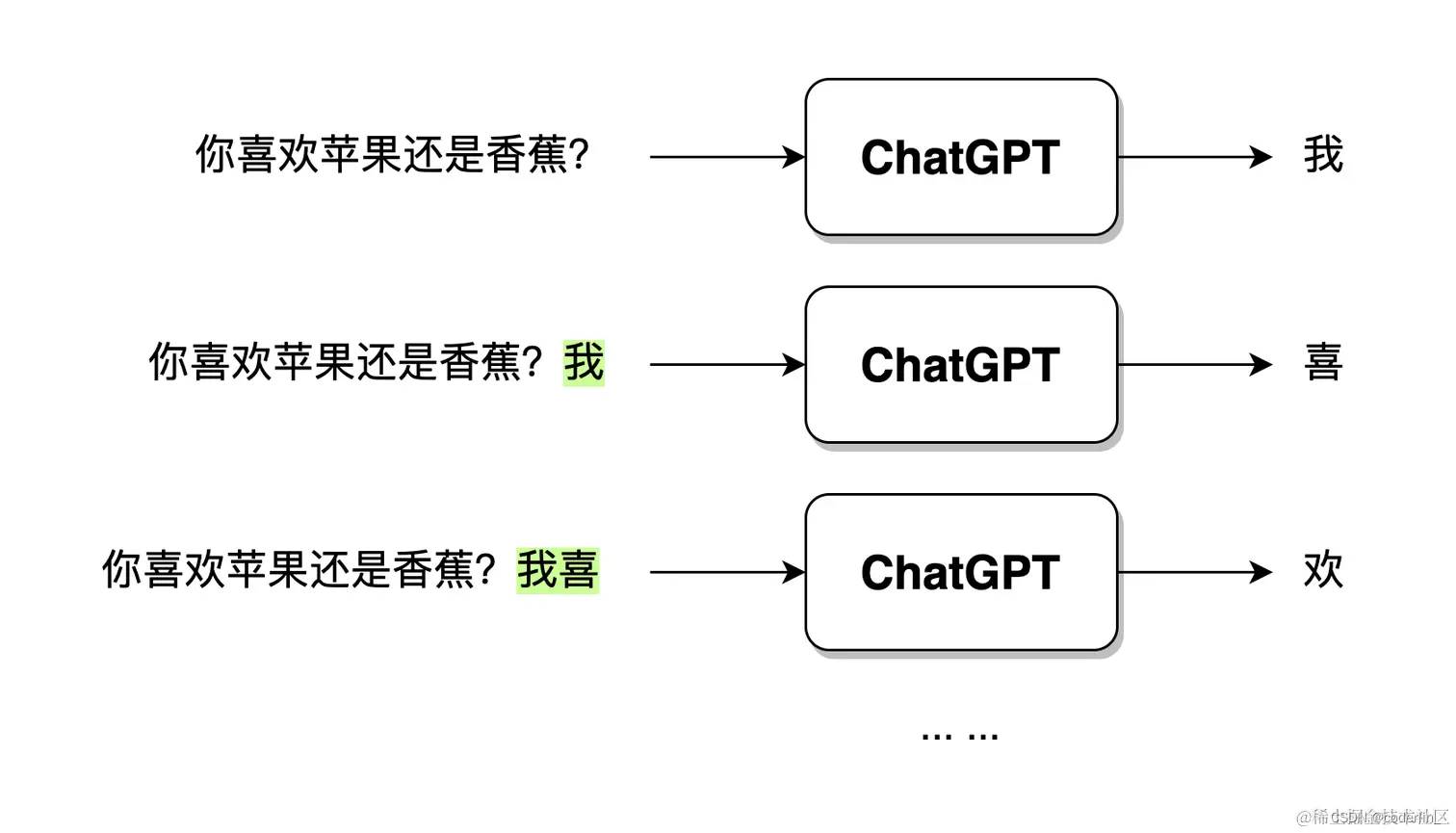
且Chatgpt在输出的时候,并不是直接一口气直接生成的,而是一个字一个字生成的,这种组逐字生成,即生成式,如
Chatgpt和NLP的发展历程
基于规则的NLP->基于统计的NLP->基于强化学习的NLP
- 基于
规则的NLP:顾名思义就是人工编写规则,让计算机根据规则来解析和生成自然语言。但是缺点很明显:规则无穷无尽,且自然语言中,任何规则都无法覆盖需求,本质上也没有将自然语言处理的方式交给计算机,仍然是人在主导。比如早期的"人工智能"。 - 基于
统计的NLP:利用机器学习算法,从大量的语料库中学习自然语言的规律特征(如chatGpt)。规则是隐形的,暗含在模型参数重,由模型根据训练得到,而基于规则的NLP,规则就是显性的,是人工编写的。但基于统计的也有缺点:黑盒不确定性,即规则是隐形的,暗含在参数中,比如gpt 有时候会给出云里雾里模糊的答案。
预训练:
在 ChatGPT 中,主要采用预训练( Pre-training ) 技术来完成基于统计的 NLP 模型学习。
它的重点在于,根据大规模原始语料学习一个语言模型,而这个模型并不直接学习如何解决具体的某种任务,而是学习从语法、词法、语用,到常识、知识等信息,把它们融汇在语言模型中。直观地讲,它更像是一个知识记忆器,而非运用知识解决实际问题。
基于强化学习的NLP
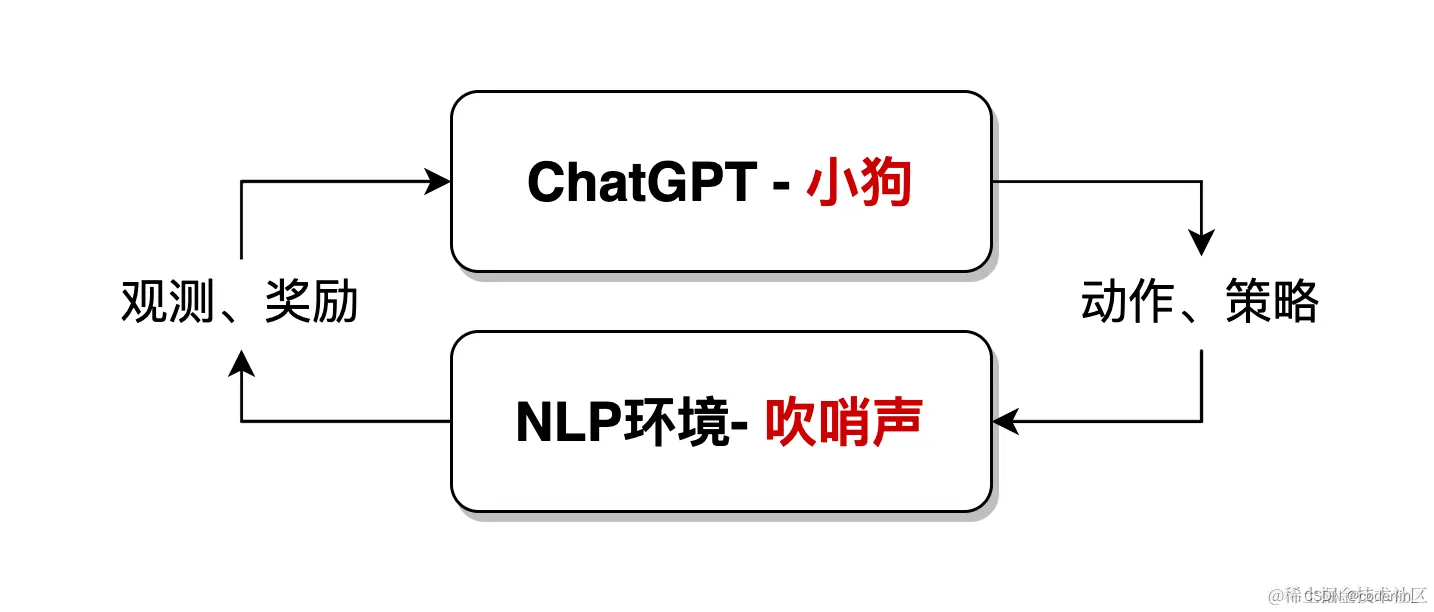
Chatgpt是基于统计的,然而他又利用新方法,带人工反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF),所谓强化学习,就是一种机器学习的方式,旨在让chatGpt(智能体,如NLP中的深度神经网络模型)通过与环境的交互来学习如何做出最优决策。
比如训练小狗,小狗就是chatGpt,通过听口令(环境)来做出对应的动作(学习目标)
一只小狗,当听到主人吹哨后,就会被奖励食物;而当主人不吹哨时,小狗只能挨饿。通过反复的进食、挨饿,小狗就能建立起相应的条件反射,实际上就是完成了一次强化学习。
在NLP领域,环境是人为构造出来的一种语言环境模型。
基于统计的方式,能让模型以最大自由度去拟合训练数据集,而强化学习,就是赋予模型更大的自由度,让模型能够自主学习,突破既定的数据集限制,chatGpt模型就是融合统计学习方法+强化学习方法,如
NLP 技术的发展脉络
基于规则,基于统计,基于强化学习这三种方式,并不仅仅是一种处理自然语言的手段,而是一种思想。一个解决某一个问题的模型,往往是融合了这三种解决思想的产物。
如果把计算机当作一个小孩,自然语言处理就像是人类来教育小孩子成长
基于规则:家长百分之百控制小孩子,强调手把手教。
基于统计:家长只告诉小孩子学习方法,而不教每一道题,让小孩子自己去学习,强调半引导,对于NLP,学习重心放在了神经网络模型上,但主动权仍有算法工程师执导。
基于强化学习:家长只给小孩制定目标,比如我要你考90分,然后就不管孩子如何学习,全靠孩子自学。小孩拥有极高的自由度和主动权,家长只对最终结果做出奖励和惩罚,不参与整个教育过程。对于NLP来说:整个过程的重心和主动权都在模型本身。
NLP 的发展一直以来都在逐渐向基于统计的方式靠拢,最终由基于强化学习的方式取得完全的胜利,胜利的标志,即 ChatGPT 的问世;
ChatGPT 的神经网络结构 Transformer
ChatGPT 是一个大型的神经网络,其内部结构是由若干层 Transformer 构成的,Transformer 是一种神经网络的结构。
Transformer 的核心是自注意力机制(Self-Attention),它可以帮助模型在处理输入的文字序列时,自动关注与当前位置字符相关的,其他位置字符,自注意力机制可以将输入序列中的每个位置当作一个向量,他们可以同时参与计算,从而实现高效的并行运算。也就是
Transformer 能够更好地捕捉句子中,跨越很长距离的词汇之间的关系,解决文本上下文的长依赖
总结
- NLP 领域的发展逐渐由人为编写规则、逻辑控制计算机程序,到完全交由网络模型去适应语言环境。
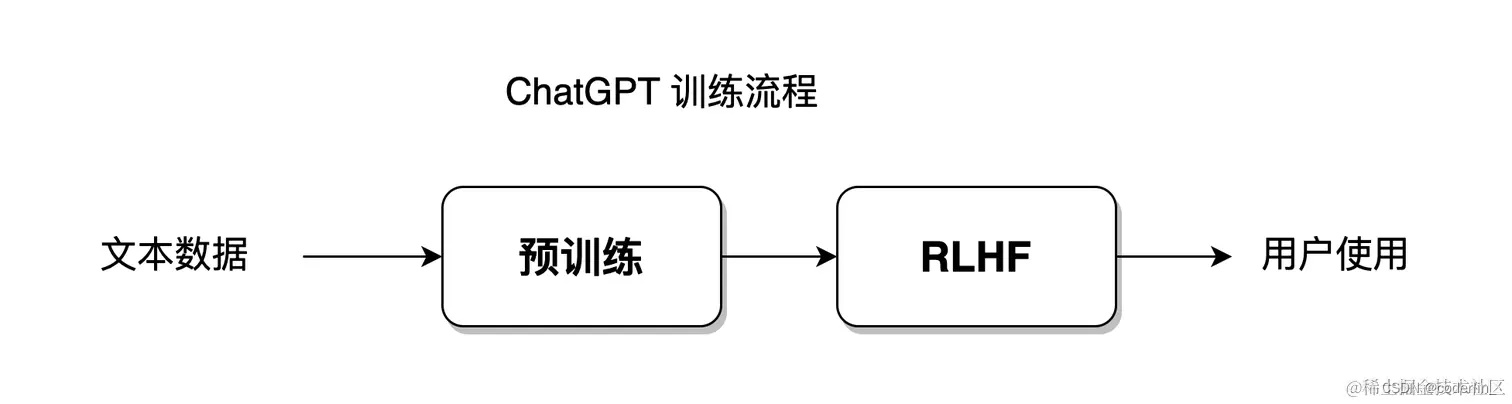
- ChatGPT 的工作流程是一个生成式的对话系统。
- ChatGPT 的训练过程包括语言模型的预训练,RLHF 带人工反馈的强化学习。
- ChatGPT 的模型结构采用以自注意力机制为核心的 Transformer。
从Gpt1.0到ChatGPT
若把 ChatGPT 比作一个健康聪明的青年人,那么早期的模型就是他的婴儿时期、青少年时期,GPT 的发展历程像是朝着模拟人类发展。
GPT 初代
GPT,Bert,ELMO模型,一起将 NLP 带进了大规模神经网络语言模型(Large Language Model, LLM)时代。它们正式标志着 NLP 领域开始全面拥抱预训练的方式。
GPT 的语言建模
GPT 初代所做的事就是从从大规模的文本语料中,将每一条文本随机地分成两部分,只保留上半部分,让模型学习下半部分学习到底该填写什么,这种学习方法让模型具备了在当时看来非常强的智能。所谓语言模型(Language Model,LM),就是从大量的数据中学习复杂的上下文联系
GPT-2
GPT-2 的论文名就叫做【Language Models are Unsupervised Multitask Learners】,语言模型是多任务学习者。
GPT-2 主要就是在 GPT 初代的基础上,又添加了多个任务,比如机器翻译、问答、文本摘要等等,扩增了数据集和模型参数,又训练了一番。
元学习(meta-learning),实际上就是语言模型的一脑多用。
GPT-3
大模型中的大模型
小样本(Few-Shot)学习
GPT3 的论文标题叫做【Language Models are Few-Shot Learners】,语言模型是小样本学习者
以往在训练 NLP 模型的时候,都需要用到大量的标注数据。可是标注数据的成本实在是太高了,这些都得人工手工一个个来标注完成!有没有什么不这么依赖大量标注的方式吗?
GPT3 就提出了小样本学习的概念,简单来讲,就是让模型学习语言时,不需要那么多的样例数据。
如
假设,我们训练一个可抽取文本中人名的模型,就需要标注千千万万个人名,比如“张雪华”、“刘星宇”等。千千万万个标注数据,就像是教了模型千千万万次同一个题目一样,这样才能掌握。
而人脑却不是这样,当被告知“山下惠子”是一个日本人名以后(仅仅被教学了一次),人脑马上就能理解,“中岛晴子”大概率也是一个日本人名,尽管人脑从来没听说过这个名字。
ChatGPT
ChatGPT 模型结构上和之前的几代都没有太大变化,主要变化的是训练策略变了。
强化学习
ChatGPT 将 NLP 带入了强化学习时代。
训练 ChatGPT 所需要的文本,主要来自于互联网,这是一个有限的集合,但是我们提出的问题,无穷无尽,有的在网上根本找不到。
对于传统的深度神经网络模型的训练思路,只能根据网上已有的数据做训练,学习的只是已有的数据本身。
而chatgpt的强化学习思路,则是模拟一个环境模型(Reward)。
chatgpt会根据一个问题给出一个答案,而环境模型则会给他打分。高分代表奖励,低分代表惩罚,不会给出标准答案。
而chatgpt接收到评价反馈后,可以根据这个数值做模型的进一步训练,朝着生成更加恰当答案的方向拟合。
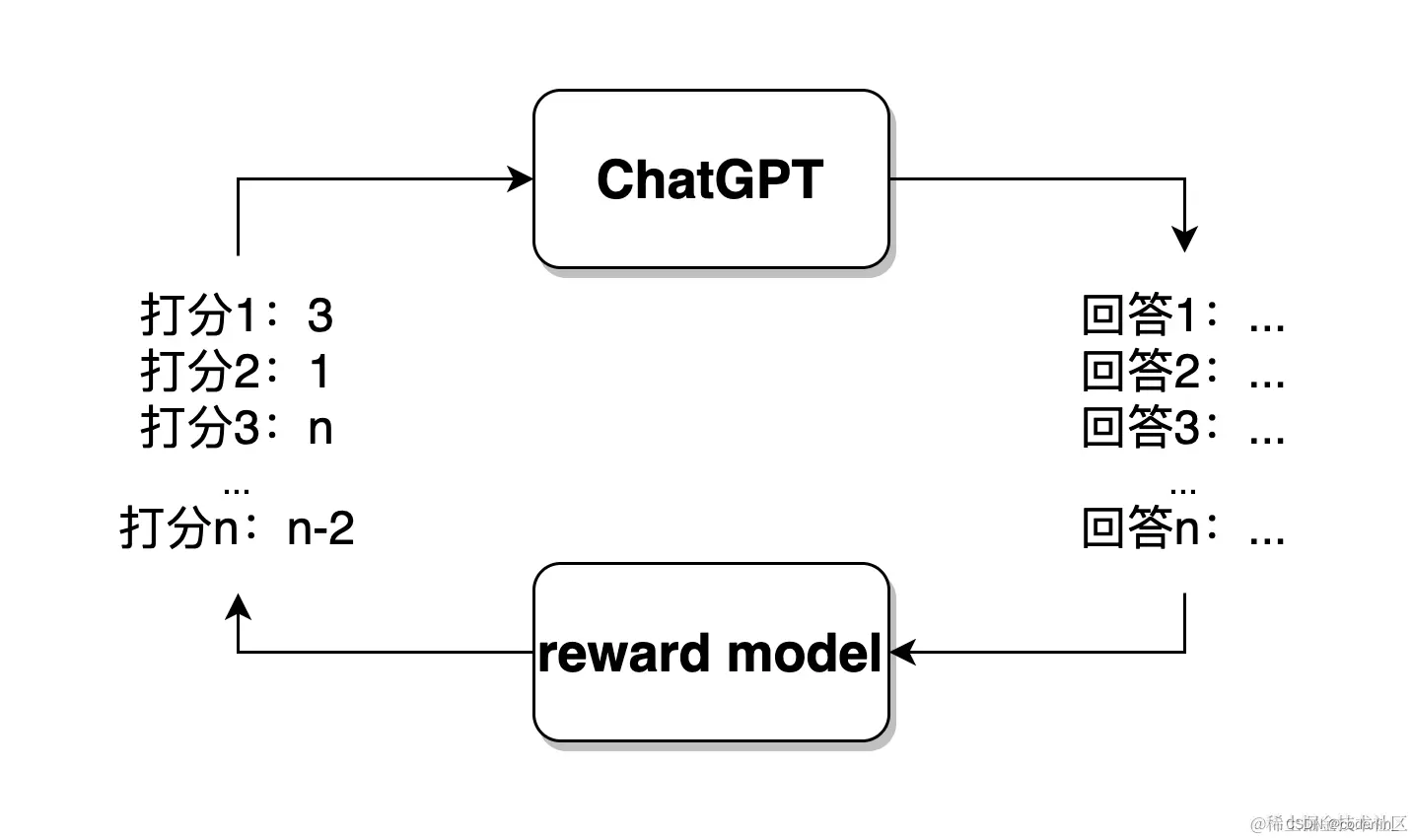
由此,chatgpt 模型已经不再局限于已有的训练数据集,可以扩展至更大的范围,应对从未见过的问题。
总结
- 纵观 ChatGPT 模型的进化历史,可以看出,模型的发展脚步就是在朝着模拟人类的方式前进着
- 人类接收语言文字信息,输出语言文字,应用了编解码方式,ChatGPT 也利用了编解码的方式(编码解码)。
- 人类的大脑神经元数量是所有生物中最多的,ChatGPT 应用了超千亿的大规模参数模型(gpt3的模型参数量达1750亿)。
- 人类采用了对话的方式进行交流,ChatGPT 建模也采用了对话的方式(对话方式学习)。
- 人类的大脑具有多种多样的功能,ChatGPT 也融合了多任务,各种各样的NLP任务(gpt2 多任务学习)。
- 人类可以通过极少量的样例进行学习,ChatGPT 也可以完成小样本学习(gpt3 小样本学习,比如日本名中上惠子)。
- 人类可以在与实际环境的交互中学习知识,塑造语言,ChatGPT 也添加了强化学习,模拟与人类的交互(环境模型打分机制)。
- ChatGPT 的发展史,就是人工智能模拟人脑的历史。
相关文章:
学习入门 chatgpt原理 一
学习文章:人人都能看懂的chatGpt原理课 笔记作为学习用,侵删 Chatph和自然语言处理 什么是ChatGpt ChatGPT(Chat Generative Pre-training Transformer) 是一个 AI 模型,属于自然语言处理( Natural Lang…...

生命在于学习——Python人工智能原理(4.7)
四、Python的程序结构与函数 4.4 函数 函数能将代码划分为若干模块,每一个模块可以相对独立的实现某一个功能,函数有两个主要功能,分别是降低编程难度和实现代码复用,函数是一种功能抽象,复用它可以将一个复杂的大问…...
经典游戏案例:仿植物大战僵尸
学习目标:仿植物大战僵尸核心玩法实现 游戏画面 项目结构目录 部分核心代码 using System; using System.Collections; using System.Collections.Generic; using UnityEngine; using UnityEngine.SceneManagement; using Random UnityEngine.Random;public enum…...

[Day 18] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
強化學習與生成對抗網絡(GAN) 引言 強化學習 (Reinforcement Learning, RL) 和生成對抗網絡 (Generative Adversarial Networks, GANs) 是現代人工智能中的兩大關鍵技術。強化學習使得智能體可以通過與環境交互學習最佳行動策略,而生成對抗網絡則通過兩個相互競爭…...

【Mac】DMG Canvas for mac(DMG镜像制作工具)软件介绍
软件介绍 DMG Canvas 是一款专门用于创建 macOS 磁盘映像文件(DMG)的软件。它的主要功能是让用户可以轻松地设计、定制和生成 macOS 上的安装器和磁盘映像文件,以下是它的一些主要特点和功能。 主要特点和功能 1. 用户界面设计 DMG Canva…...

RAG分块方法 从固定大小到自然语言处理分块——深入研究文本分块技术
发掘文本分块-准确的搜索结果和更智能的语言模型背后的秘诀,通过了解如何有效地分块文本,我们可以改进索引文档、处理用户查询和利用搜索结果的方式。准备好揭开文本分块的秘密了吗? 一、了解分块 分块是一种旨在嵌入尽可能少噪音的内容,同…...

FFmpeg 系列
📚 此篇文章是先引入ffmpeg的概念以及主要的功能,后面会根据每一个特点进行详解,喜欢ffmpeg的可以持续关注。 ffmpeg是什么? FFmpeg 是一个开源的跨平台音视频处理工具,它可以用来录制、转换以及流化音视频内容。具体…...
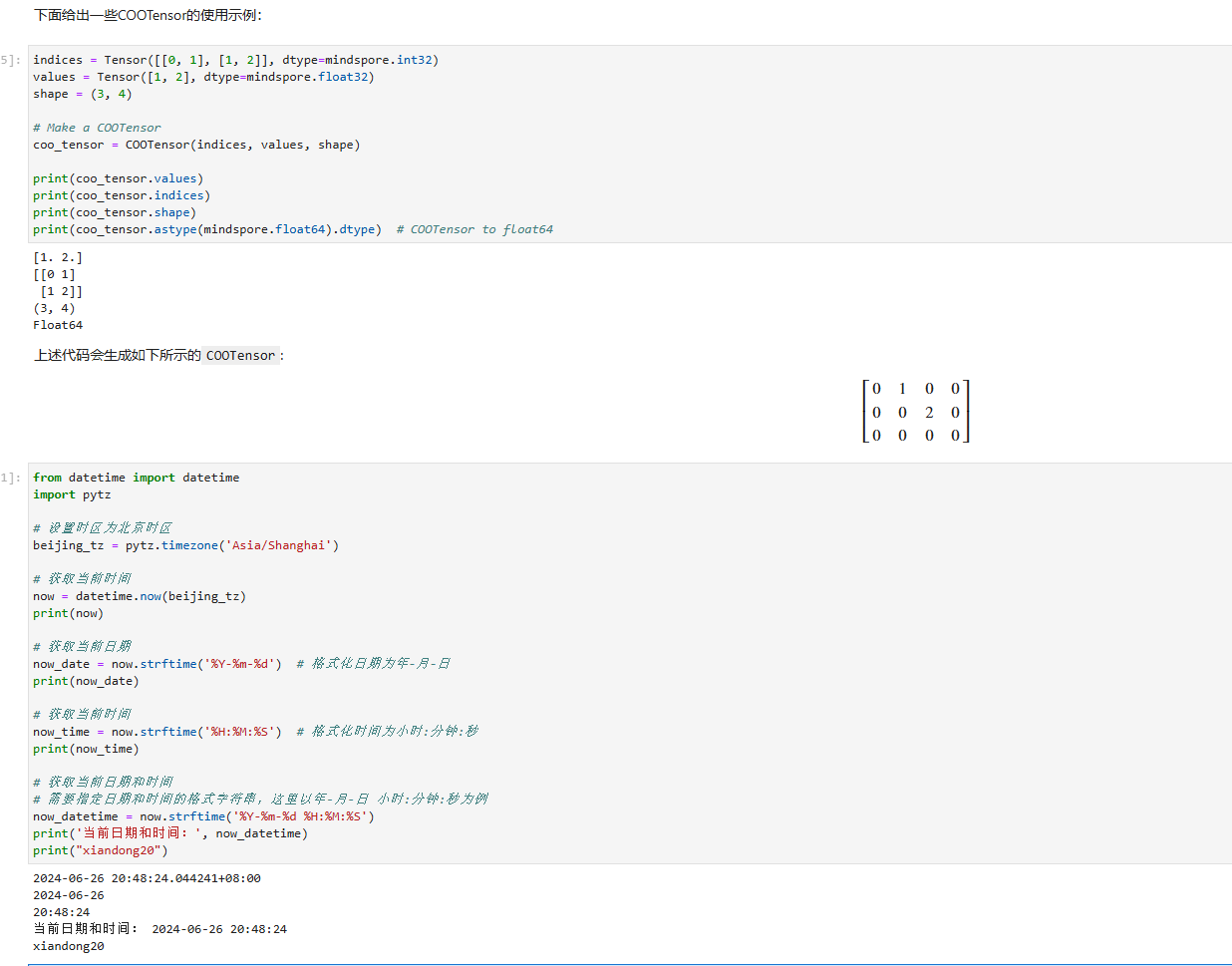
240626_昇思学习打卡-Day8-稀疏矩阵
240626_昇思学习打卡-Day8-稀疏矩阵 稀疏矩阵 在一些应用场景中,比如训练二值化图像分割时,图像的特征是稀疏的,使用一堆0和极个别的1表示这些特征即费事又难看,此时就可以使用稀疏矩阵。通过参考大佬博文,结合个人理…...

Docker: 使用容器化数据库
使用容器化数据库 使用本地容器化数据库提供了灵活性和简易的设置,使您能够在不需要传统数据库安装开销的情况下,紧密模拟生产环境。Docker 简化了这一过程,只需几条命令就可以在隔离的容器中部署、管理和扩展数据库。 在本指南中,您将学习如何: 运行本地容器化数据库访…...

Oracle对用户敏感数据进行编码处理
由于系统运行时间比较长,没有对用户的身份证号、邮箱、手机号进行脱敏处理,后期对数据进行了编码。 更新表数据 sql UPDATE sys_staff SET MOBIL_PHONE CASEWHEN MOBIL_PHONE IS NULL THEN ELSE utl_raw.cast_to_varchar2(utl_encode.base64_encode(ut…...

VXLAN详解:概念、架构、原理、搭建过程、常用命令与实战案例
一、VXLAN概述 1.1 VXLAN的定义 VXLAN(Virtual Extensible LAN,虚拟可扩展局域网)是一种网络虚拟化技术,通过在现有IP网络上创建虚拟网络,使数据中心可以实现大规模的网络隔离和扩展。VXLAN使用MAC-in-UDP封装技术&a…...

Redis-数据类型-Hash
文章目录 1、查看redis是否启动2、通过客户端连接redis3、切换到db3数据库4、插入新数据返回15、获取指定哈希(hash)对象的所有字段(field)名6、获取存储在指定哈希(hash)对象中的所有字段(fiel…...
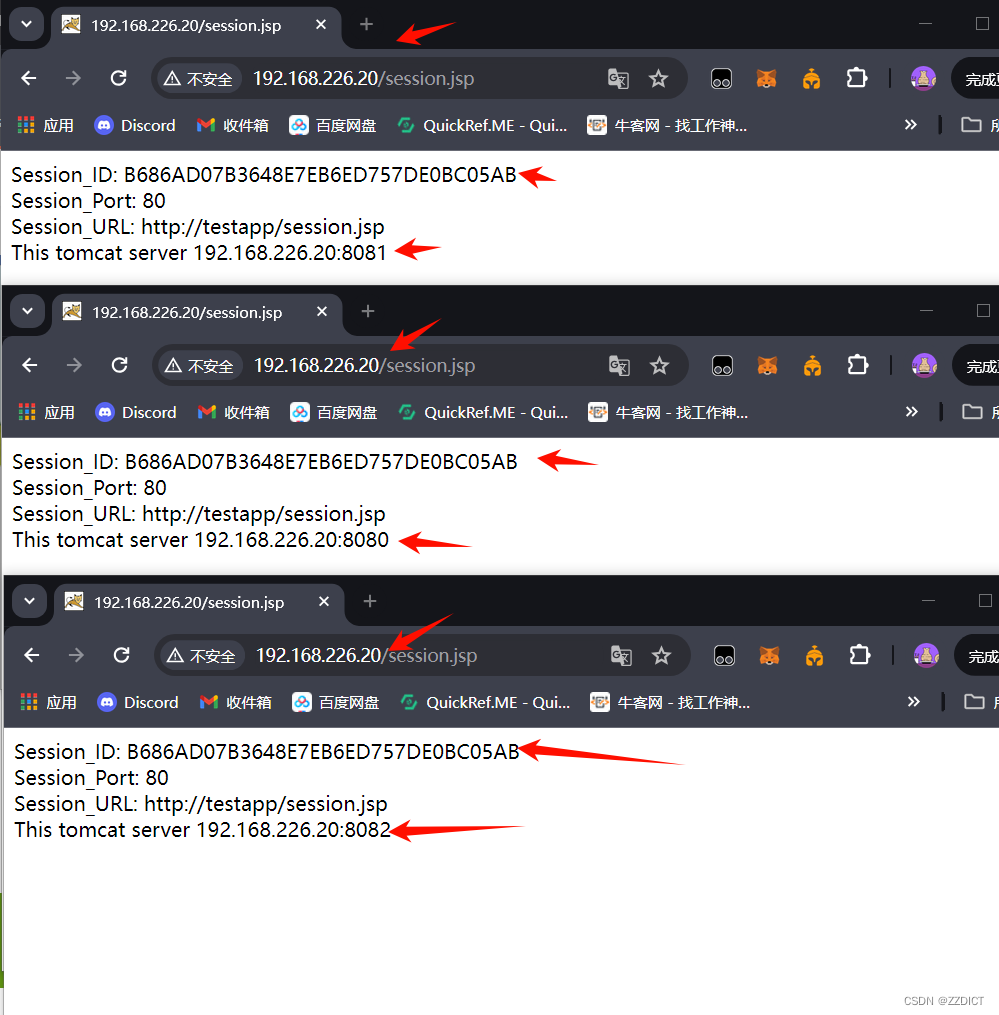
基于redisson实现tomcat集群session共享
目录 1、环境 2、修改server.xml 3、修改context.xml 4、新增redisson配置文件 5、下载并复制2个Jar包到Tomcat Lib目录中 6、 安装redis 7、配置nginx负载均衡 8、配置测试页面 9、session共享测试验证 前言: 上篇中,Tomcat session复制及ses…...
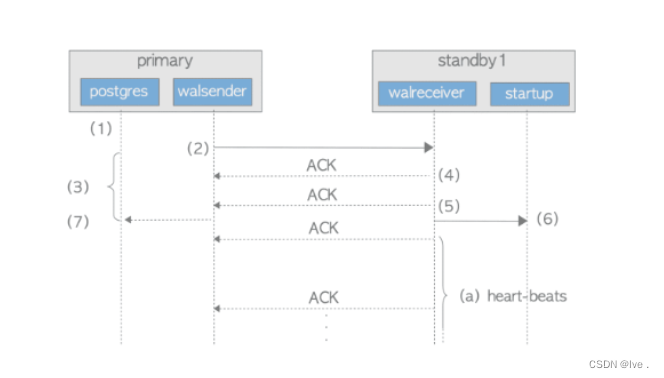
postgres数据库的流复制
1. 流复制和逻辑复制的差异 逻辑复制和流复制最直观的不同是,逻辑复制支持表级别复制区分点事原理不同 逻辑日志是在wal日志产生的数据库上,由逻辑解析模块对wal日志进行初步的解析,解析结果是ReorderBufferChange(理解为HeapTup…...

Dxf库中的DL_Extrusion类
类DL_Extrusion DL_Extrusion 是 DXF 库中的一个类,用于表示三维实体的扩展信息。在 DXF 文件中,DL_Extrusion 类通常用于表示具有高度的三维图形实体,如立方体、圆柱体等,以及其它具有体积的几何对象。 以下是一个简单的示例代…...
“ONLYOFFICE 8.1版本评测:功能更强大,用户体验更佳”
最新版本的在线编辑器已经发布 ONLYOFFICE在线编辑器的最新版本8.1已经发布,整个套件带来了30多个新功能和432个bug修复。这个强大的文档编辑器支持处理文本文档、电子表格、演示文稿、可填写的表单和PDF,并允许多人在线协作,同时支持AI集成…...

搜维尔科技:【研究】触觉手套比控制器更能带来身临其境、更安全、更高效的虚拟体验
自然交互可提高VR模拟的有效性。研究表明,触觉手套比控制器更能带来身临其境、更安全、更高效的虚拟体验。 以下是验证 医疗培训中的触觉技术 “ 95.5%的参与者表示触摸是 XR 教育的重要组成部分,90.9% 的参与者表示 XR 触觉将提供一个安全的学习场所。…...

【小学期】实体类设计——以学生管理系统为例
项目目录中的位置 将Student.java文件放在src/model目录中,即: student_management │ ├── src │ ├── model │ │ ├── Student.java // 这里是Student实体类 │ │ └── StudentDAO.java │ │ │ ├── view │ │ …...

Java测试类
在Java中,为了编写测试类,通常使用JUnit框架。 1. 首先,创建一个名为Calculator的简单Java类,它包含一个方法add用于计算两个整数的和: public class Calculator {public int add(int a, int b) {return a b;} } 2.…...

python 中面向对象编程:深入理解封装、继承和多态
在本章中,我们将深入探讨Python中的高级面向对象编程概念,包括封装、继承和多态。让我们开始吧! 目录 面向对象简介类和实例属性和方法继承和多态 高级面向对象概念私有变量使用 property使用 __slots__类的特殊成员__doc____call____str____…...
:波数域解析、阵列流形可视化与频率响应设计)
阵列信号处理笔记(2):波数域解析、阵列流形可视化与频率响应设计
1. 波数域解析:空域频率的物理意义 波数域是理解阵列信号处理的关键视角。简单来说,波数(k)相当于空域中的"频率",就像时域中的角频率(ω)描述信号随时间变化的快慢一样,波…...

Faust高级特性:窗口聚合与状态管理完整教程
Faust高级特性:窗口聚合与状态管理完整教程 【免费下载链接】faust Python Stream Processing. A Faust fork 项目地址: https://gitcode.com/gh_mirrors/faus/faust 掌握Faust的窗口聚合与状态管理功能,构建高效的Python流处理应用!&…...

Go语言模板方法模式:算法骨架
Go语言模板方法模式:算法骨架 1. 模板方法实现 type AbstractClass struct{}func (a *AbstractClass) TemplateMethod() {a.Step1()a.Step2()a.Step3() }func (a *AbstractClass) Step1() {} func (a *AbstractClass) Step2() {} func (a *AbstractClass) Step3() {…...

HsMod终极指南:如何通过55项功能全面优化炉石传说游戏体验
HsMod终极指南:如何通过55项功能全面优化炉石传说游戏体验 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是基于BepInEx框架开发的炉石传说模改插件,专为提升…...

基于RP2040与VL53L1X的自动触发空气炮:嵌入式感知-决策-执行系统实践
1. 项目概述:一个会“思考”的自动空气炮如果你玩过或者听说过那些在鬼屋里突然喷气吓人的恶作剧道具,那你大概能想象出这个项目的最终效果。但今天我们要做的,远不止一个简单的“吓人盒子”。这是一个融合了现代嵌入式系统、高精度传感器和气…...
)
你还在手写提示词?:2024最稀缺的提示词自动化工作流(含可运行Python脚本+权重映射API)
更多请点击: https://intelliparadigm.com 第一章:Midjourney提示词编写的核心范式演进 早期提示词依赖直觉式描述(如“a cat”),而现代范式已转向结构化、分层可控的语义工程。当前主流实践将提示词解耦为三类要素&a…...
使用 QLineF 从 QTransform 提取角度信息
我们在对 QGraphicsItem 进行变换时,QT 提供了很多便捷的方法。但当我们想获取当前变换的角度时却有些困难,因为 QTransform 没有提供获取角度的方法。在文章Qt 从 QTransform 逆向解出 Translate/Scale/Rotate(平移/缩放/旋转)分…...

【c++面向对象编程】第22篇:输入输出运算符重载:<< 与 >> 的友元实现
目录 一、为什么不能是成员函数? 二、标准写法(两步法) 第1步:在类中声明友元函数 第2步:实现全局函数 三、为什么要返回引用? 支持链式输出 正确 vs 错误示例 四、为什么需要友元?能否不…...

AI智能体长期记忆架构:构建Agent Shadow Brain解决上下文限制
1. 项目概述:当AI智能体拥有一个“影子大脑”最近在AI智能体开发领域,一个名为“Agent Shadow Brain”的项目引起了我的注意。这个项目由开发者theihtisham发起,其核心思想是为大型语言模型驱动的智能体配备一个独立的、持续运行的“影子大脑…...

郎朗乐境音乐会定档7月5日深圳:以破界之姿,开启全维感官盛宴
2026年7月5日,郎朗乐境音乐会将在深圳市宝安体育中心体育馆启幕,作为“深圳国际形象大使”的郎朗,将在这座以创新著称的国际化都市,,进一步探索艺术表达形式的多重可能,呈现一场融合音乐、文化与多维感官体…...