Python 基础 (标准库):堆 heap
1. 官方文档
heapq --- 堆队列算法 — Python 3.12.4 文档
2. 相关概念
堆 heap 是一种具体的数据结构(concrete data structures);优先级队列 priority queue 是一种抽象的数据结构(abstract data structures),可以通过堆、二叉搜索树、链表等多种方式来实现 priority queue,其中,堆是最流行的实现优先级队列的具体数据结构。
2.1 优先级队列 Priority Queue
抽象数据结构是一种逻辑上的概念,描述了数据的组织方式和操作方式。优先级队列 Priority Queue 通常用于优化任务执行,其目标是处理具有最高优先级的任务。任务完成后,其优先级降低,并返回到队列中。
Priority Queue 支持三种操作:
- is_empty:检查队列是否为空。
- add_element:向队列中添加一个元素。
- pop_element:弹出优先级最高的元素。
对于元素的优先级有两种约定(约定或惯例 convention,指约定俗称的用法或含义,特定上下文中使用的特定术语、符号、语法或行为的含义):1. 最大的元素具有最高的优先级;2. 最小的元素具有最高的优先级。
这两种约定其实是等价的,如果元素由数字组成,那么使用负数即可完成转换。Python heapq 模块使用第二种,这也是两种约定中更常见的一种。在这个约定下,最小的元素具有最高的优先级。
优先级队列对于查找某个极端元素是非常有用的,如:找到点击率前三的博客文章、找到从一个点到另一个点的最快方法、根据到站频率预测哪辆公共汽车将首先到达车站等问题。
2.2 堆 heap
2.2.1 堆属性
堆是特殊的完全二叉树(complete binary tree),其中每个上级节点的值都小于等于它的任意子节点(堆属性),堆常用于实现优先级队列。
二叉树(binary tree)中,每个节点最多有两个子节点。完全二叉树是一种特殊的二叉树,其定义是: 若设二叉树的深度为 h,除第 h 层外,其它各层 1~h-1 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边。也就是说,完全二叉树的所有非叶子节点都必须被填满,叶子节点都必须连续排列在最左边。满二叉树是特殊的完全二叉树。完全二叉树的性质保证,树的深度是元素数的以2为底的对数向上取整。
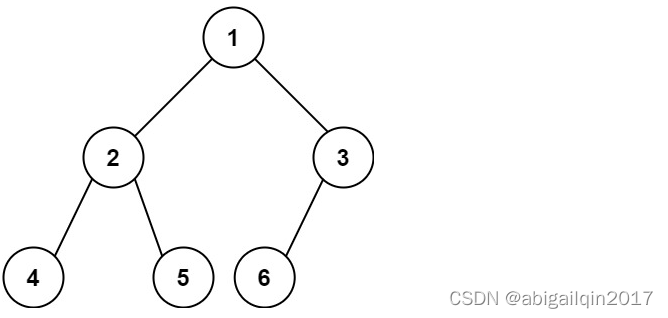
在堆树中,一个节点的值总是小于它的两个子节点,这被称为堆属性(与二叉搜索树不同,二叉搜索树中,只有左侧节点的值小于其父节点的值)。在堆中,同一层的节点之间并没有大小关系的限制,唯一的限制是每个节点的值必须符合堆属性。
add 操作: 1. 创建新节点添加到堆的末尾。如果底层未满,将节点添加到最深层下一个开放槽中,否则,创建一个新的层级,将元素添加到新的层中。 2. 将新元素与其父节点比较,如果新元素比父节小,则交换它们的位置,直到新元素的值小于其父节点的值或者新元素成为了根节点。
pop 操作: 1. 根据堆属性,该元素位于树的根。将堆顶元素弹出,并将堆末尾元素移到堆顶。 2. 将堆顶元素与其左右子节点比较,将其与较大(或较小)的子节点交换位置,直到堆顶元素的值大于(或小于)其左右子节点的值或者堆顶元素成为了叶子节点。
2.2.2 性能保证 performance guarantees
具体数据结构实现抽象数据结构中定义的操作,并明确性能保证 performance guarantees,即数据规模和操作所需时间之间的关系,性能保证可用于预测程序行为,比如,当输入的大小发生变化时,程序将花费多少时间完成操作。
优先级队列的堆实现保证推入(添加)和弹出(删除)元素都是对数时间操作。这意味着执行push 和 pop 所需的时间与元素数量的以2为底的对数成正比。对数增长缓慢。以2为底15的对数约为4,以2为底1万亿的对数约为40。这意味着,如果一个算法在处理15个元素时足够快,那么它在处理1万亿个元素时只会慢10倍。
2.2.3 堆与二叉搜索树的区别
排序方式不同:堆是一种基于完全二叉树的数据结构,它的每个节点都满足堆的性质,即父节点的值大于(最大堆)(或小于,即最小堆)子节点的值。而二叉搜索树则是一种有序的二叉树结构,它的每个节点都满足左子树的节点值小于该节点的值,右子树的节点值大于该节点的值。
操作不同:堆常用于实现优先队列,可以快速找到最大或最小值。堆的插入和删除操作都比较快,但查找操作比较慢。而二叉搜索树可以快速查找、插入和删除节点,但是在某些特殊情况下,可能会出现树的不平衡,导致性能下降。
强调:Python 的 heapq 模块和堆数据结构一般都不支持查找除最小元素之外的任何元素,如果想检索指定大小的元素,可以使用二叉搜索树。
堆作为优先级队列的实现,是解决涉及极端问题的好工具,当在问题描述中存在如:最大、最小、前、底、最低,最优等字眼,表明需要寻找某些极端元素时,可以考虑一下堆。
3. Python heapq Module
前面将堆描述为树,不过它是一个完全二叉树,这意味着除了最后一层之外,每层有多少元素是确定的。因此,堆可以使一个列表实现。Python 中的 heapq 模块就是使用列表实现堆的,heapq 将列表的第一个元素视为堆的根节点。
堆队列中,索引为 k 的元素与其周围元素之间的关系:
- 它的第一个子结点是 2*k + 1。
- 它的第二个子结点是 2*k + 2。
- 它的父结点是 (k - 1) // 2。
堆队列中的元素总是有父元素,但有些元素可能没有子元素。如果 2*k 超出了列表的末尾,则该元素没有任何子元素。如果 2*k + 1是有效索引,但 2*k + 2不是,则该元素只有一个子元素。
h[k] <= h[2*k + 1] and h[k] <= h[2*k + 2] 可能引发IndexError,但永远不会为False。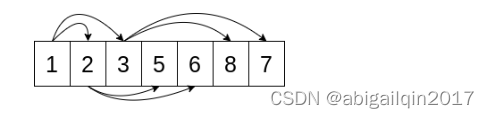
3.1 heapq 模块
Python 的 heapq 模块使用列表实现堆操作,与许多其他模块不同,heapq 模块不定义自定义类,但定义了直接处理列表的函数。
3.1.1 堆函数
| 函数 | 功能 |
| heapq.heapify(x) | 将list x 转换成堆,原地,线性时间内。 |
| ===== heapq 模块中的其他基本操作假设列表已经是堆 ===== | |
| heapq.heappush(heap, item) | 将 item 的值加入 heap 中,保持堆的不变性。 |
| heapq.heappop(heap) | 弹出并返回 heap 的最小的元素,保持堆的不变性。 如果堆为空,抛出 IndexError 。 使用 heap[0] ,可以只访问最小的元素而不弹出它。 |
| heapq.heappushpop(heap, item) | 将 item 放入堆中,然后弹出并返回 heap 的最小元素。 heappushpop() is equivalent to heappush() followed by heappop(). |
| heapq.heapreplace(heap, item) | 弹出并返回 heap 中最小的一项,同时推入新的 item。 如果堆为空引发 IndexError。 heapreplace() is equivalent to heappop() followed by heappush(). 单步骤 heappushpop 和 heaprepalce 比分开执行 pop 和 push 更高效; 它们是 pop 和 push 的组合,非常适合在固定大小的堆使用: heapreplace() 从堆中返回一个元素并将其替换为 item;heaprepalce 返回的值可能会比新加入的值大,如果不希望如此,可改用 heappushpop(),它返回两个值中较小的一个,将较大的留在堆中。 |
- 空列表或长度为1的列表总是一个堆。
- 创建堆时,可以从空堆开始,将元素一个接一个地插入到堆中。如果已经有一个元素列表,使用 heapq 模块 heapify() 函数把它原地转换成有效堆。
- heapify() 就地修改列表,但不对其排序,堆不必为了满足堆属性而进行排序。但是,由于每个排序列表都满足堆属性,在排序列表上运行 heapify() 不会改变列表中元素的顺序。
- 由于树的根是第一个元素,第一个元素 a[0] 总是最小的元素。
import heapq
a = [3, 5, 1, 2, 6, 8, 7]
heapq.heapify(a)
a
# [1, 2, 3, 5, 6, 8, 7]heapq.heappop(a)
# 1
a
# [2, 5, 3, 7, 6, 8]heapq.heappush(a, 4)
heapq.heappop(a)
# 2
heapq.heappop(a)
# 3
heapq.heappop(a)
# 43.1.2 通用函数
| 函数 | 功能 |
| heapq.merge(*iterables, key=None, reverse=False) | merge 函数用于 merging sorted sequences,它假设输入的可迭代对象已经排序,使用堆来合并多个可迭代对象(例如,合并来自多个日志文件的带时间戳的条目),返回一个迭代器,而不是一个列表。 类似于 sorted(itertools.chain(*iterables)), 但需假定每个输入流都是已排序的(从小到大),且返回一个可迭代对象 iterator,不会一次性地将数据全部放入内存(节省内存)。 具有两个可选参数: key 指定带有单个参数的 key function,用于从每个输入元素中提取比较键。 默认值为 None (直接比较元素)。 reverse 为一个布尔值。 如果设为 True,则输入元素将按比较结果逆序进行合并。 要达成与 sorted(itertools.chain(*iterables), reverse=True) 类似的行为,所有可迭代对象必须是已从大到小排序的。 |
| heapq.nlargest(n, iterable, key=None) | 从 iterable 所定义的数据集中返回前 n 个最大元素组成的列表。 key 为一个单参数的函数,用于从 iterable 的每个元素中提取比较键 (例如 key=str.lower)。 等价于:sorted(iterable, key=key, reverse=True)[:n]。 |
| heapq.nsmallest(n, iterable, key=None) | 从 iterable 所定义的数据集中返回前 n 个最小元素组成的列表。 key 为一个单参数的函数,用于从 iterable 的每个元素中提取比较键 (例如 key=str.lower)。 等价于: sorted(iterable, key=key)[:n]。 在 n 值较小时可考虑使用 heapq.nlargest 和 heapq.nsmallest; 对于较大的值,使用 sorted() 函数更有效率; 当 n==1 时,使用内置的 min() 和 max() 函数更高效; 如果需要重复使用这些函数,可考虑将可迭代对象转为真正的堆。 |
3.1.3 应用示例
调度(合并)多组周期性任务
假设有一个系统,系统中存在几种电子邮件,不同类型的电子邮件有不同发送频率,比如 A 类邮件每15分钟发送一次,B 类每40分钟发送一次。 可以使用堆设计一个调度程序:首先,将各种类型的电子邮件添加到队列中,每封电子邮件带一个时间戳,指示下一次发送的时间;然后,查看具有最小时间戳的元素,计算在发送之前需要睡眠的时间,当调度程序醒来时,处理此邮件;处理完成后,从优先级队列中取出电子邮件,计算该邮件的下一个时间戳,放回到队列中正确的位置。
import datetime
import heapqdef email(frequency, email_type):current = datetime.datetime.now()while True:current += frequencyyield current, email_typefast_email = email(datetime.timedelta(minutes=10), "fast email")
slow_email = email(datetime.timedelta(minutes=30), "slow email")unified = heapq.merge(fast_email, slow_email)
for _ in range(10):print(next(unified))# (datetime.datetime(2024, 6, 14, 16, 40, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 16, 50, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 0, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 0, 8, 28884), 'slow email')
# (datetime.datetime(2024, 6, 14, 17, 10, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 20, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 30, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 30, 8, 28884), 'slow email')
# (datetime.datetime(2024, 6, 14, 17, 40, 8, 28884), 'fast email')
# (datetime.datetime(2024, 6, 14, 17, 50, 8, 28884), 'fast email')上述代码中,heapq.merge() 的输入是无限生成器,返回值也是一个无限迭代器,这个迭代器将按照未来时间戳的顺序生成待发送的电子邮件序列。观察 print 打印的结果,fast email 每10分钟发送一次,slow email 每40分钟发送一次,两种邮件合理交错。merge 不读取所有输入,而是动态地工作,因此,尽管两个输入都是无限迭代器,前10项的打印依然能很快完成。
得分前 N 项(后 N 项)
已知2016年夏季奥运会女子100米决赛的成绩,要求打印前三名运动员姓名。
import heapqresults="""\
Christania Williams 11.80
Marie-Josee Ta Lou 10.86
Elaine Thompson 10.71
Tori Bowie 10.83
Shelly-Ann Fraser-Pryce 10.86
English Gardner 10.94
Michelle-Lee Ahye 10.92
Dafne Schippers 10.90
"""
top_3 = heapq.nsmallest(3, results.splitlines(), key=lambda x: float(x.split()[-1]))
print("\n".join(top_3))
# Elaine Thompson 10.71
# Tori Bowie 10.83
# Marie-Josee Ta Lou 10.86相关文章:
Python 基础 (标准库):堆 heap
1. 官方文档 heapq --- 堆队列算法 — Python 3.12.4 文档 2. 相关概念 堆 heap 是一种具体的数据结构(concrete data structures);优先级队列 priority queue 是一种抽象的数据结构(abstract data structures)&…...
代码实践 -卷积神经网络-30Kaggle竞赛:图片分类)
动手学深度学习(Pytorch版)代码实践 -卷积神经网络-30Kaggle竞赛:图片分类
30Kaggle竞赛:图片分类 比赛链接: https://www.kaggle.com/c/classify-leaves 导入包 import torch import torchvision from torch.utils.data import Dataset, DataLoader from torchvision import transforms import numpy as np import pandas as…...

【LeetCode】每日一题:数组中的第K大的元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。 请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。 你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。 解题思路 第一种是快排,快…...
安装)
Keil5.38ARM,旧编译器(V5)安装
站内文章KEIL5MDK最新版(3.37)安装以及旧编译器(V5)安装_keil5 mdk-CSDN博客...

【perl】脚本编程的一些坑案例
引言 记录自己跳进的【perl】编程小坑,以己为鉴。 1、eq $str1 "12345\n"; $str2 "12345"; if ($str1 eq $str2) { print "OK" } 上述代码不会打印 OK。特别在读文件 ,匹配字符串时容易出BUG。 案例说明: 有…...

MIX OTP——使用 GenServer 进行客户端-服务器通信
在上一章中,我们使用代理来表示存储容器。在 mix 的介绍中,我们指定要命名每个存储容器,以便我们可以执行以下操作: 在上面的会话中,我们与“购物”存储容器进行了交互。 由于代理是进程,因此每个存储容器…...

2024年云安全发展趋势预测
《2024年云安全发展趋势预测》 摘要: 云计算的普及带来了新的安全挑战。本文汇总了多家云安全厂商、专业媒体和研究机构对2024年云安全发展趋势的预测,为企业组织提供了洞察云安全威胁的新视角。 云计算的灵活性和可扩展性使其成为企业关键任务负载的首…...
java.io.eofexception:ssl peer shut down incorrectly
可能是因为 1)https设置 2)超时设置 FeignConfig.java package zwf.service;import java.io.IOException; import java.io.InputStream; import java.security.KeyStore;import javax.net.ssl.SSLContext; import javax.net.ssl.SSLSocketFactory;import org.apac…...
Unity之HTC VIVE Cosmos环境安装(适合新手小白)(一)
提示:能力有限,错误之处,还望指出,不胜感激! 文章目录 前言一、unity版本电脑配置相关关于unity版本下载建议:0.先下载unity Hub1.不要用过于旧的版本2.不要下载最新版本或者其他非长期支持版本 二、官网下…...
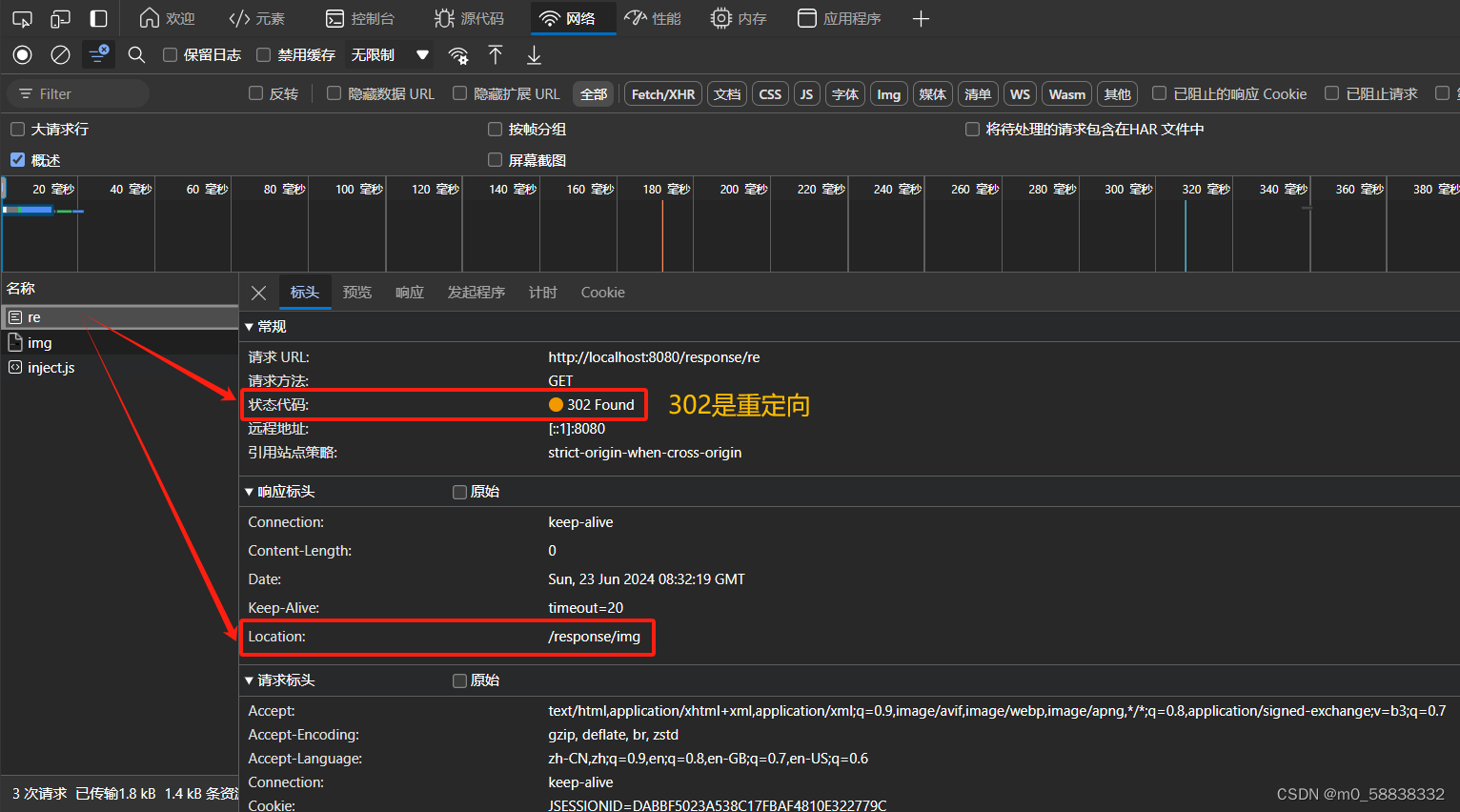
入门JavaWeb之 Response 验证码和重定向
Response 写验证码: package com.demo.response;import javax.imageio.ImageIO; import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse…...

2024-06-26 问AI: 在大数据模型中,deep speed 是什么?
文心一言 在大数据模型中,DeepSpeed是一个由微软开发并维护的开源深度学习优化库。其主要目的是提高大规模模型训练的效率和可扩展性,帮助开发者更有效率地管理及优化大模型的训练、部署任务。以下是DeepSpeed的主要特点和功能: 提高效率和…...

mobaxterm x11 转发Ubuntu mac
目录 royal tsx —— 一款Mac平台MobaXterm平替工具 mobaxterm x11 转发Ubuntu 软件 royal tsx —— 一款Mac平台MobaXterm平替工具 Royal Apps Termius Mac mobaxterm x11 转发Ubuntu 软件 所以直接在 ssh 的时候加上 - X 就可以了 ssh -X -p xxx usernameIP 运行 xclock …...
)
python数据分析实训任务三(‘职业’)
import pandas as pd import matplotlib.pyplot as plt data pd.read_csv(rC:\Users\XXGC\Desktop\职业2.csv,\ encodinggb2312) # 创建 DataFrame df pd.DataFrame(data) # 分析年龄和工资的关系 plt.scatter(df[年龄], df[工资]) plt.xlabel(年龄) pl…...
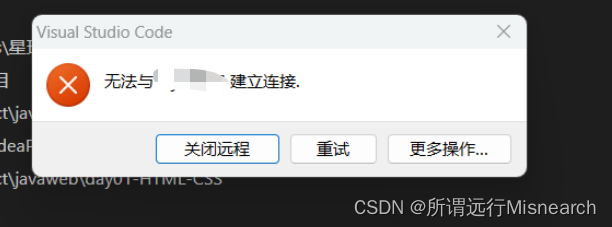
vscode连接SSH
1、安装Remote-SSH插件 2、点击左下角,选择SSH 3、点击连接到主机后,添加新的SSH主机,示例ssh 用户ip 4、点击服务器,输入密码登录服务器 5、可在远程资源管理器选项卡中查看 6、可以在ssh设置中打开ssh配置文件 config中的文件…...

金融科技行业创新人才培养与引进的重要性及挑战
金融科技行业作为金融与科技的深度融合产物,正以前所未有的速度改变着传统金融业的格局。在这一变革中创新人才的培养与引进成为了行业发展的核心驱动力。然而,尽管其重要性不言而喻,但在实际操作中却面临着诸多挑战。 一、创新人才培养与引进…...
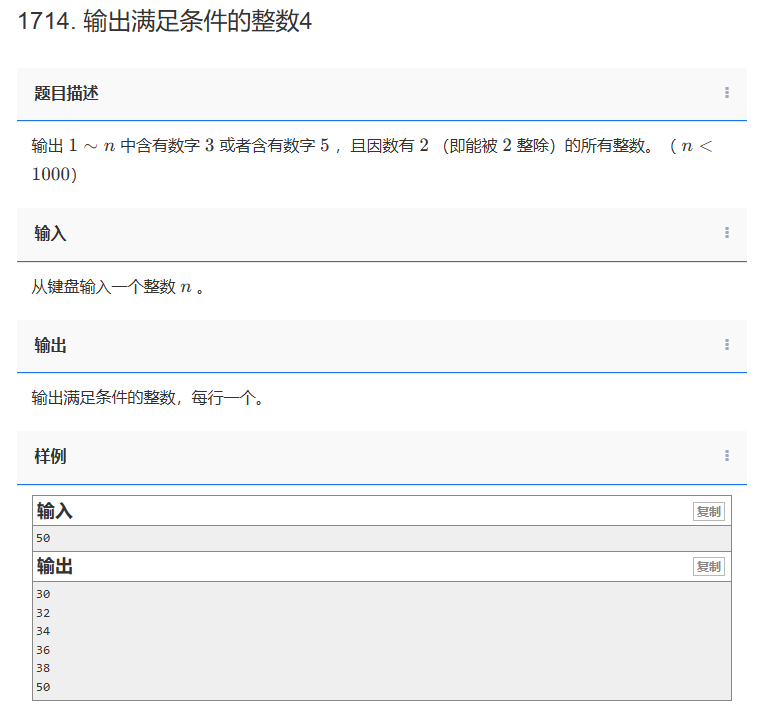
【C++题解】1714. 输出满足条件的整数4
问题:1714. 输出满足条件的整数4 类型:简单循环 题目描述: 输出 1∼n 中含有数字 3 或者含有数字 5 ,且因数有 2 (即能被 2 整除)的所有整数。(n<1000) 输入: 从键盘输入一个…...

如何安装和配置 Django 与 Postgres、Nginx 和 Gunicorn
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 先决条件 本教程假设您已经在Debian 7或类似的Linux发行版(如Ubuntu)上设置了您的droplet(VPS&#…...

Graphwalker基于模型的自动化测试
Graphwalker 基于模型的自动化测试 基于模型的自动化测试(Model-Based Testing,MBT)作为一种创新的测试方法,正逐渐受到广泛关注。Graphwalker 作为一款强大的基于模型的自动化测试工具,为我们提供了一种高效、全面的…...

Macbook M1 Fusion安装Debian/Linux
背景 本人主力工作电脑已经迁移到苹果芯片m1的macbook上,曾经尝试使用Fusion安装CentOS、OpenEuler、Ubuntu的一些版本,都没有安装成功。最近开始研究Linux/Unix系统编程,迫切需要通过VMware Fusion安装一台Linux操作系统的虚拟机。 Linux安…...

ERP收费模式是怎样的?SAP ERP是如何收费的?
一、购置SAP ERP系统的费用组成 1、软件费用 传统的ERP系统大多为许可式,即企业在购买ERP服务时付清所有费用,将ERP系统部署于自己的服务器中。根据所购买ERP系统品牌的不同,价格上也有一定的差异。采购ERP系统许可后,后续维护、…...

登录系统发现CPU飙升100%、接口全量503
一、变更治理的核心目标与一句话结论 变更治理不是为了限制开发效率,而是为了在速度和稳定性之间找到最佳平衡点。它的核心目标只有四个: 可追溯:谁在什么时间改了什么,影响了哪些范围可回滚:任何变更都能在秒级内撤销…...

跨平台的Web应用快速开发框架
跨平台的Web应用快速开发框架。该框架提供了一套标准化的项目结构规范、统一的API接口命名规则、规范化的前后端代码,支持基于同一套设计规范Python(Flask/Django)、PHP、Java(SpringBoot/SSM)等多种后端语言代码 &…...

关键词覆盖不足,图标点击率低于行业均值18.7%?Gemini ASO深度调优全链路拆解
更多请点击: https://intelliparadigm.com 第一章:Gemini App Store优化的现状与挑战 生态碎片化加剧分发效率瓶颈 当前 Gemini App Store 尚未建立统一的开发者认证、审核策略与版本兼容性规范,导致应用在不同 Gemini 原生设备(…...

为什么你的Agent总在Adobe全家桶前卡死?:独家披露Adobe UXP沙箱逃逸+DOM Bridge双向通信协议逆向成果
更多请点击: https://intelliparadigm.com 第一章:Adobe UXP沙箱机制与Agent操作失能的根源诊断 Adobe UXP(Unified Extensibility Platform)为插件提供了强隔离的运行时沙箱环境,其核心设计目标是保障宿主应用&#…...

从夏普IGZO技术授权看显示面板产业的技术转移与战略博弈
1. 从一则旧闻看显示产业的全球棋局:技术、资本与生存的博弈2013年夏天,一则来自日本的消息在科技产业圈,特别是显示面板和半导体供应链领域,激起了不小的涟漪。全球知名的消费电子品牌夏普公司,宣布了一项与中国国有企…...

百度首页网页图片更多当AI开始写测试用例,手工测试工程师的护城河在哪里?
一、 第一道护城河:从“用例执行者”到“策略设计者”AI可以基于需求文档和历史数据,瞬间生成海量测试用例。但它无法回答一个根本性的问题:我们究竟应该测试什么?测试策略的设计,是在有限的时间和资源下,对…...

RevokeMsgPatcher实战指南:Windows微信QQ防撤回的终极秘籍
RevokeMsgPatcher实战指南:Windows微信QQ防撤回的终极秘籍 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcod…...

3步快速上手:用dupeGuru轻松清理重复文件,释放宝贵磁盘空间
3步快速上手:用dupeGuru轻松清理重复文件,释放宝贵磁盘空间 【免费下载链接】dupeguru Find duplicate files 项目地址: https://gitcode.com/gh_mirrors/du/dupeguru 你是否经常为电脑中堆积如山的重复文件而烦恼?照片、文档、音乐文…...

PX4倾转垂起固定翼混控配置与硬件适配实战
1. PX4倾转垂起固定翼的核心概念解析 第一次接触倾转垂起固定翼的朋友可能会被这个名词吓到,其实它的原理并不复杂。简单来说,这是一种既能像多旋翼一样垂直起降,又能像固定翼飞机一样高效巡航的混合飞行器。我经手过的项目中,这种…...

Windows安卓应用安装器:快速轻量级解决方案终极指南
Windows安卓应用安装器:快速轻量级解决方案终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上轻松安装安卓应用吗?厌倦…...