Pandas中的数据转换[细节]
 今天我们看一下Pandas中的数据转换,话不多说直接开始🎇
今天我们看一下Pandas中的数据转换,话不多说直接开始🎇
目录
一、⭐️apply函数应用
apply是一个自由度很高的函数
对于Series,它可以迭代每一列的值操作:
二、⭐️矢量化字符串
为什么要用str属性
替换和分割
提取子串
提取第一个匹配的子串
测试是否包含子串
生成哑变量
⭐️方法摘要
函数应用
import pandas as pd
import numpy as np一、⭐️apply函数应用
apply是一个自由度很高的函数
对于Series,它可以迭代每一列的值操作:
df = pd.read_csv('data/table.csv')
df.head()
df['Math'].apply(lambda x:str(x)+'!').head() #可以使用lambda表达式,也可以使用函数 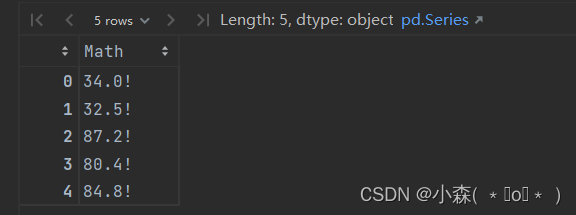
💥对于DataFrame,它在默认axis=0下可以迭代每一个列操作:
# def test(x):
# print(x)
# return x
# df.apply(test)#axis=0
# df.apply(lambda x:x.apply(lambda x:str(x)+'!')).head() #这是一个稍显复杂的例子,有利于理解apply的功能
temp_data = df[["Height", "Weight", "Math"]]
# temp_data# 生成一个表格,每列是原来列的最大值,最小值,以及均值def transfor(x):# x是Seriesresult = pd.Series()result["max"] = x.max()result["min"] = x.min()result["avg"] = x.mean()return resulttemp_data.apply(transfor, axis=0)
# 按列来传入,一列就是一个x 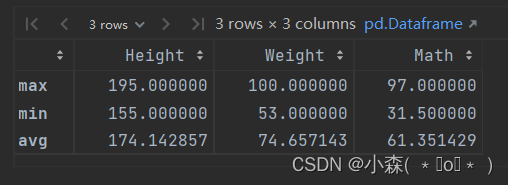
def transfor(x):# x -> seriesbmi = x["Weight"]/(x["Height"]/100)**2x["bmi"] = bmireturn xtemp_data.apply(transfor, axis=1)# BMI = # apply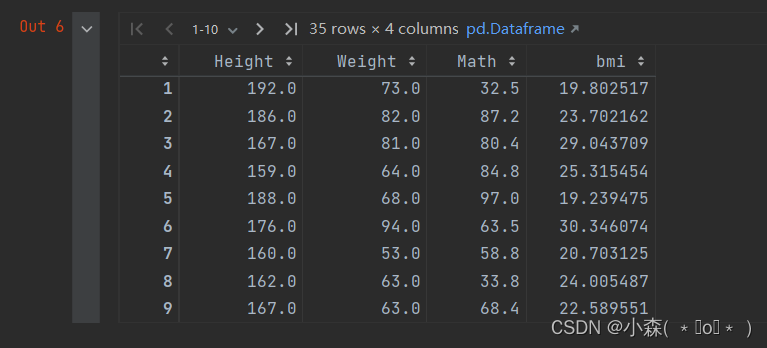
Pandas中的axis参数=0时,永远表示的是处理方向而不是聚合方向,当axis='index'或=0时,对列迭代对行聚合,行即为跨列,axis=1同理 💥
二、⭐️矢量化字符串
为什么要用str属性
文本数据也就是我们常说的字符串,Pandas 为 Series 提供了 str 属性,通过它可以方便的对每个元素进行操作。
index = pd.Index(data=["Tom", "Bob", "Mary", "James", "Andy", "Alice"], name="name")data = {"age": [18, 30, np.nan, 40, np.nan, 30],"city": ["Bei Jing ", "Shang Hai ", "Guang Zhou", "Shen Zhen", np.nan, " "],"sex": [None, "male", "female", "male", np.nan, "unknown"],"birth": ["2000-02-10", "1988-10-17", None, "1978-08-08", np.nan, "1988-10-17"]
}user_info = pd.DataFrame(data=data, index=index)# 将出生日期转为时间戳
user_info["birth"] = pd.to_datetime(user_info.birth)
user_info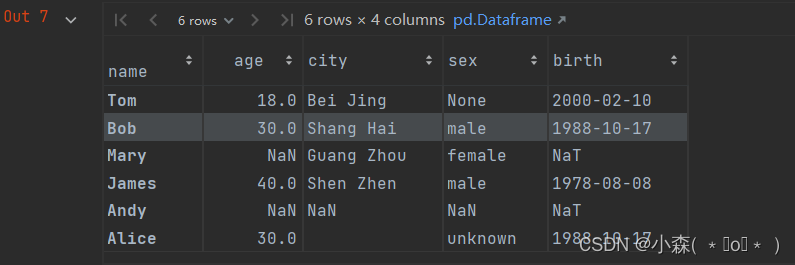
💯在对 Series 中每个元素处理时,我们可以使用apply 方法。
💯比如,我想要将每个城市都转为小写,可以使用如下的方式。
user_info.city.map(lambda x: x.lower())
AttributeError: 'float' object has no attribute 'lower'💯错误原因是因为 float 类型的对象没有 lower 属性。这是因为缺失值(np.nan)属于float 类型。这时候我们的str属性操作来了,来看看如何使用吧~
# 将文本转为小写
user_info.city.str.lower()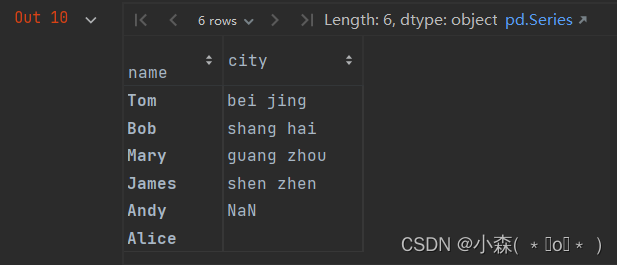
可以看到,通过 `str` 属性来访问之后用到的方法名与 Python 内置的字符串的方法名一样。并且能够自动排除缺失值。我们再来试试其他一些方法。例如,统计每个字符串的长度。
user_info.city.str.len()替换和分割
使用 .srt 属性也支持替换与分割操作。
先来看下替换操作,例如:将空字符串替换成下划线。
user_info.city.str.replace(" ", "_")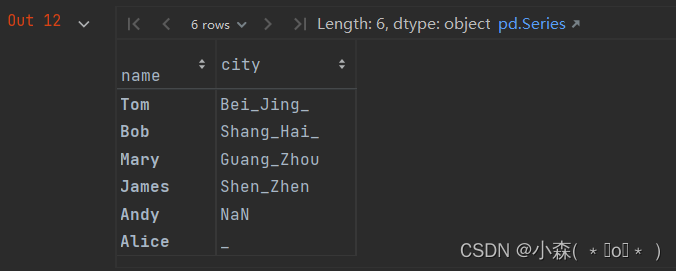
🏹replace 方法还支持正则表达式,例如将所有开头为 S 的城市替换为空字符串。
user_info.city.str.replace("^S.*", " ")🏹再来看下分割操作,例如根据空字符串来分割某一列
user_info.city.str.split(" ")🏹分割列表中的元素可以使用 get 或 [] 符号进行访问:
user_info.city.str.split(" ").str.get(1)🏹设置参数 expand=True 可以轻松扩展此项以返回 DataFrame。
user_info.city.str.split(" ", expand=True)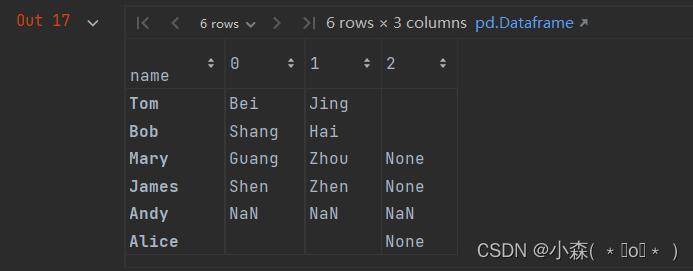
提取子串
既然是在操作字符串,很自然,你可能会想到是否可以从一个长的字符串中提取出子串。答案是可以的。
提取第一个匹配的子串
extract 方法接受一个正则表达式并至少包含一个捕获组,指定参数 expand=True 可以保证每次都返回 DataFrame。
例如,现在想要匹配空字符串前面的所有的字母,可以使用如下操作:
user_info.city.str.extract("(\w+)\s+", expand=True)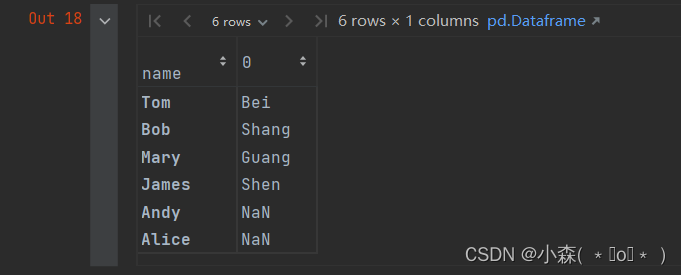
如果使用多个组提取正则表达式会返回一个 DataFrame,每个组只有一列。
例如,想要匹配出空字符串前面和后面的所有字母,操作如下:
user_info.city.str.extract("(\w+)\s+(\w+)", expand=True)测试是否包含子串
除了可以匹配出子串外,我们还可以使用 contains 来测试是否包含子串。例如,想要测试城市是否包含子串 “Zh”。
user_info.city.str.contains("Zh")当然了,正则表达式也是支持的。例如,想要测试是否是以字母 “S” 开头。
user_info.city.str.contains("^S")生成哑变量
这是一个神奇的功能,通过 get_dummies 方法可以将字符串转为哑变量,sep 参数是指定哑变量之间的分隔符。来看看效果吧。
user_info.city.str.get_dummies(sep=" ")
这样,它提取出了 Bei, Guang, Hai, Jing, Shang, Shen, Zhen, Zhou 这些哑变量,并对每个变量下使用 0 或 1 来表达。实际上与 One-Hot(狂热编码)是一回事。
⭐️方法摘要
这里列出了一些常用的方法摘要。
| 方法 | 描述 |
|---|---|
| cat() | 连接字符串 |
| split() | 在分隔符上分割字符串 |
| rsplit() | 从字符串末尾开始分隔字符串 |
| get() | 索引到每个元素(检索第i个元素) |
| join() | 使用分隔符在系列的每个元素中加入字符串 |
| get_dummies() | 在分隔符上分割字符串,返回虚拟变量的DataFrame |
| contains() | 如果每个字符串都包含pattern / regex,则返回布尔数组 |
| replace() | 用其他字符串替换pattern / regex的出现 |
| repeat() | 重复值(s.str.repeat(3)等同于x * 3 t2 >) |
| pad() | 将空格添加到字符串的左侧,右侧或两侧 |
| center() | 相当于str.center |
| ljust() | 相当于str.ljust |
| rjust() | 相当于str.rjust |
| zfill() | 等同于str.zfill |
| wrap() | 将长长的字符串拆分为长度小于给定宽度的行 |
| slice() | 切分Series中的每个字符串 |
| slice_replace() | 用传递的值替换每个字符串中的切片 |
| count() | 计数模式的发生 |
| startswith() | 相当于每个元素的str.startswith(pat) |
| endswith() | 相当于每个元素的str.endswith(pat) |
| findall() | 计算每个字符串的所有模式/正则表达式的列表 |
| match() | 在每个元素上调用re.match,返回匹配的组作为列表 |
| extract() | 在每个元素上调用re.search,为每个元素返回一行DataFrame,为每个正则表达式捕获组返回一列 |
| extractall() | 在每个元素上调用re.findall,为每个匹配返回一行DataFrame,为每个正则表达式捕获组返回一列 |
| len() | 计算字符串长度 |
| strip() | 相当于str.strip |
| rstrip() | 相当于str.rstrip |
| lstrip() | 相当于str.lstrip |
| partition() | 等同于str.partition |
| rpartition() | 等同于str.rpartition |
| lower() | 相当于str.lower |
| upper() | 相当于str.upper |
| find() | 相当于str.find |
| rfind() | 相当于str.rfind |
| index() | 相当于str.index |
| rindex() | 相当于str.rindex |
| capitalize() | 相当于str.capitalize |
| swapcase() | 相当于str.swapcase |
| normalize() | 返回Unicode标准格式。相当于unicodedata.normalize |
| translate() | 等同于str.translate |
| isalnum() | 等同于str.isalnum |
| isalpha() | 等同于str.isalpha |
| isdigit() | 相当于str.isdigit |
| isspace() | 等同于str.isspace |
| islower() | 相当于str.islower |
| isupper() | 相当于str.isupper |
| istitle() | 相当于str.istitle |
| isnumeric() | 相当于str.isnumeric |
| isdecimal() | 相当于str.isdecimal |
函数应用
虽说 Pandas 为我们提供了非常丰富的函数,有时候我们可能需要自己定制一些函数,并将它应用到 DataFrame 或 Series。常用到的函数有:map、apply、applymap。
map 是 Series 中特有的方法,通过它可以对 Series 中的每个元素实现转换。
如果我想通过年龄判断用户是否属于中年人(30岁以上为中年),通过 map 可以轻松搞定它。
# 接收一个 lambda 函数
user_info.age.map(lambda x: "yes" if x >= 30 else "no")又比如,我想要通过城市来判断是南方还是北方,我可以这样操作
user_info.citycity_map = {"BeiJing": "north","ShangHai": "south","GuangZhou": "south","ShenZhen": "south"
}# 传入一个 map
user_info.city.str.replace(" ","").map(city_map)apply 方法既支持 Series,也支持 DataFrame,在对 Series 操作时会作用到每个值上,在对 DataFrame 操作时会作用到所有行或所有列(通过 axis 参数控制)。
# 对 Series 来说,apply 方法 与 map 方法区别不大。
user_info.age.apply(lambda x: "yes" if x >= 30 else "no")applymap 方法针对于 DataFrame,它作用于 DataFrame 中的每个元素,它对 DataFrame 的效果类似于 apply 对 Series 的效果。
大家如果感觉可以的话,可以去做一些小练习~~
【练习一】 现有一份关于字符串的数据集,请解决以下问题:
(a)现对字符串编码存储人员信息(在编号后添加ID列),使用如下格式:“×××(名字):×国人,性别×,生于×年×月×日”
(b)将(a)中的人员生日信息部分修改为用中文表示(如一九七四年十月二十三日),其余返回格式不变。
(c)将(b)中的ID列结果拆分为原列表相应的5列,并使用equals检验是否一致。
相关文章:
Pandas中的数据转换[细节]
今天我们看一下Pandas中的数据转换,话不多说直接开始🎇 目录 一、⭐️apply函数应用 apply是一个自由度很高的函数 对于Series,它可以迭代每一列的值操作: 二、⭐️矢量化字符串 为什么要用str属性 替换和分割 提取子串 …...

vue2面试题——路由
1. 路由的模式和区别 路由的模式:history,hash 区别: 1. 表象不同 history路由:以/为结尾,localhost:8080——>localhost:8080/about hash路由:会多个#,localhost:8080/#/——>localhost:…...

【AI应用探讨】—朴素贝叶斯应用场景
目录 文本分类 推荐系统 信息检索 生物信息学 金融领域 医疗诊断 其他领域 文本分类 垃圾邮件过滤:朴素贝叶斯被广泛用于垃圾邮件过滤任务,通过邮件中的文本内容来识别是否为垃圾邮件。例如,它可以基于邮件中出现的单词或短语的概率来…...
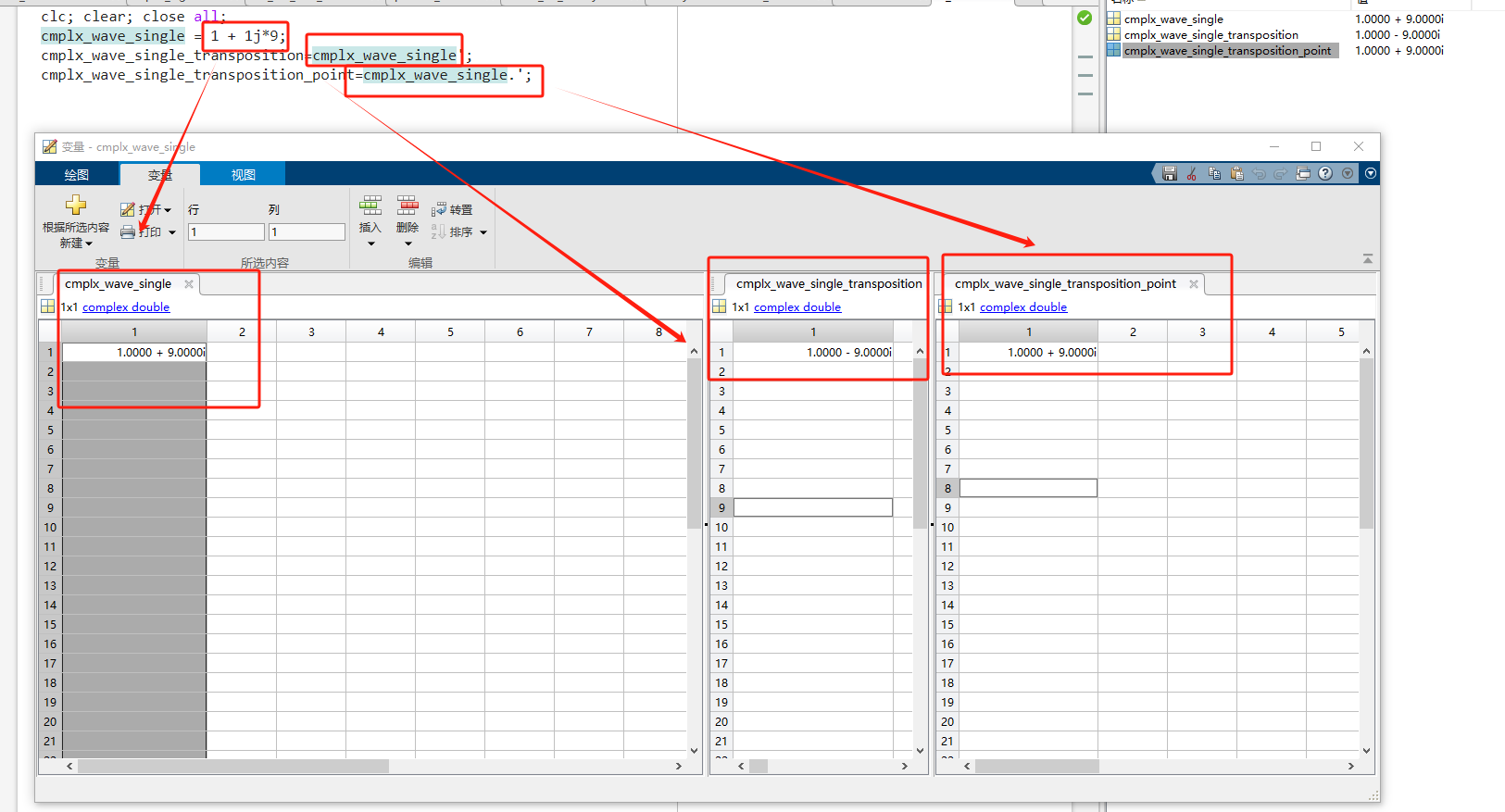
使用matlab的大坑,复数向量转置!!!!!变量区“转置变量“功能(共轭转置)、矩阵转置(默认也是共轭转置)、点转置
近期用verilog去做FFT相关的项目,需要用到matlab进行仿真然后和verilog出来的结果来做对比,然后计算误差。近期使用matlab犯了一个错误,极大的拖慢了项目进展,给我人都整emo了,因为怎么做仿真结果都不对,还…...

昇思25天学习打卡营第8天|保存与加载
1. 学习内容复盘 1.1 保存与加载 上一章节主要介绍了如何调整超参数,并进行网络模型训练。在训练网络模型的过程中,实际上我们希望保存中间和最后的结果,用于微调(fine-tune)和后续的模型推理与部署,本章…...

【vueUse库Animation模块各函数简介及使用方法】
vueUse库是一个专门为Vue打造的工具库,提供了丰富的功能,包括监听页面元素的各种行为以及调用浏览器提供的各种能力等。其中的Browser模块包含了一些实用的函数,以下是这些函数的简介和使用方法: vueUse库Sensors模块各函数简介及使用方法 vueUseAnimation函数1. useInter…...
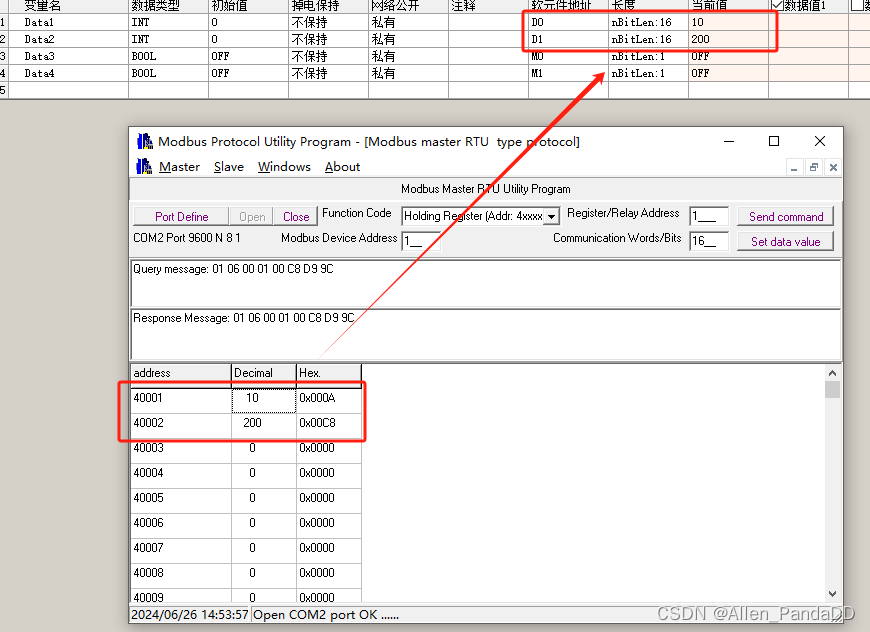
汇川H5u小型PLC作modbusRTU从站设置及测试
目录 新建工程COM通讯参数配置协议选择协议配置 查看手册Modbus地址对应关系仿真测试 新建工程 新建一个H5U工程,不使用临时工程 系列选择H5U即可 COM通讯参数配置 协议选择 选择ModbusRTU从站 协议配置 端口号默认不可选择 波特率这里使用9600 数据长度&…...
基于Java的多元化智能选课系统-计算机毕业设计源码040909
摘 要 多元化智能选课系统使用Java语言的Springboot框架,采用MVVM模式进行开发,数据方面主要采用的是微软的Mysql关系型数据库来作为数据存储媒介,配合前台技术完成系统的开发。 论文主要论述了如何使用JAVA语言开发一个多元化智能选课系统&a…...
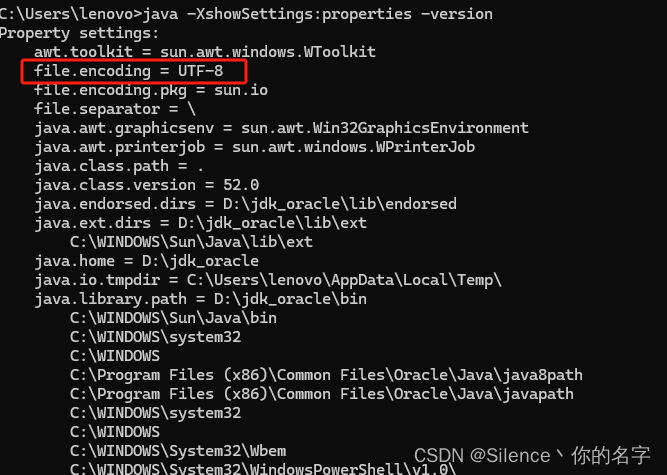
idea使用maven打包报错GBK不可映射字符
方法一:设置环境变量 打开“控制面板” > “系统和安全” > “系统”。点击“高级系统设置”。在“系统属性”窗口中,点击“环境变量”。在“系统变量”部分,点击“新建”,创建一个新的变量: 变量名:…...

解决Linux系统Root不能远程SSH登录
问题描述 在使用Linux主机或者开发板的时候远程SSH一直登录不上Root账户,只能登录其他账户。 问题解决 使用文本编辑器修改SSH的配置文件sshd_config。这个文件通常位于/etc/ssh/目录下。 sudo nano /etc/ssh/sshd_config在sshd_config文件中,找到Pe…...
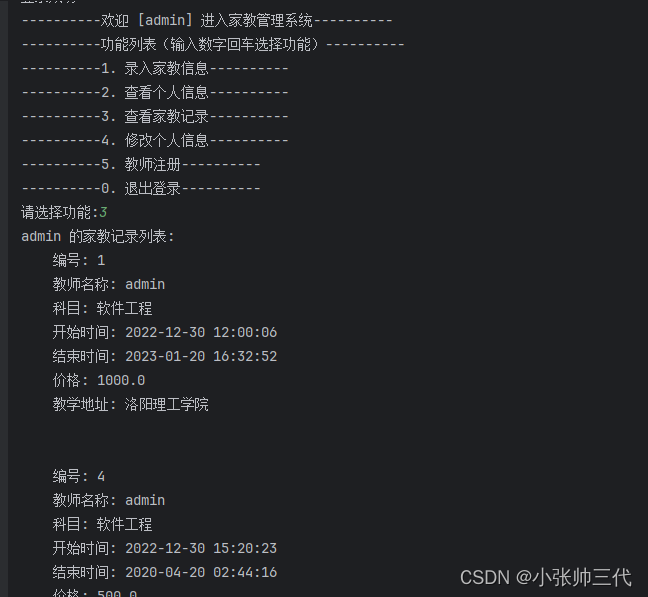
【java】【控制台】【javaSE】 初级java家教管理系统控制台命令行程序项目
更多项目点击👆👆👆完整项目成品专栏 【java】【控制台】【javaSE】 初级java家教管理系统控制台命令行程序项目 获取源码方式项目说明:功能点数据库涉及到: 项目文件包含:项目运行环境 :截图其…...
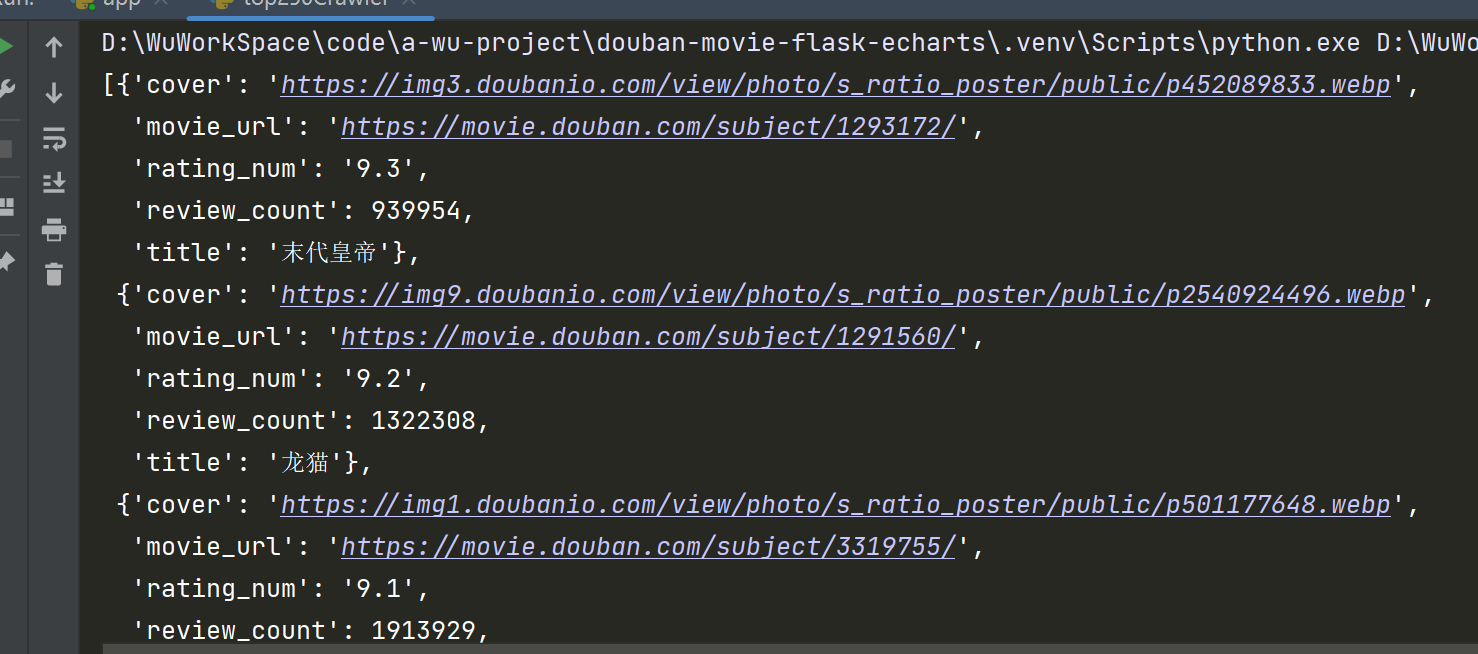
(2024)豆瓣电影TOP250爬虫详细讲解和代码
(2024)豆瓣电影TOP250爬虫详细讲解和代码 爬虫目的 获取 https://movie.douban.com/top250 电影列表的所有电影的属性。并存储起来。说起来很简单就两步。 第一步爬取数据第二步存储 爬虫思路 总体流程图 由于是分页的,要先观察分页的规…...

am62x芯片安全类型确认(HS-SE, HS-FS or GP)
文章目录 芯片安全类型设置启动方式获取串口信息下载脚本运行脚本示例sk-am62x板卡参考芯片安全类型 AM62x 芯片有三个安全级别。 • GP:通用版本 • HS-FS:高安全性 - 现场安全型 • HS-SE:高安全性 - 强制安全型 在SD卡启动文件中,可以查看到, 但板上的芯片,到底是那…...

高通安卓12-在源码中查找应用的方法
1.通过搜索命令查找app 一般情况下,UI上看到的APP名称会在xml文件里面定义出来,如 搜索名字为WiGig的一个APP 执行命令 sgrep "WiGig" 2>&1|tee 1.log 将所有的搜索到的内容打印到log里面 Log里面会有一段内容 在它的前面是这段内…...

民用无人驾驶航空器运营合格证怎么申请
随着科技的飞速发展,无人机已经从遥不可及的高科技产品飞入了寻常百姓家。越来越多的人想要亲自操纵无人机,探索更广阔的天空。但是,飞行无人机可不是简单的事情,你需要先获得无人机许可证,也就是今天所要讲的叫民用无…...

[SD必备知识18]修图扩图AI神器:ComfyUI+Krita加速修手抽卡,告别低效抽卡还原光滑细腻双手,写真无需隐藏手势
🌹大家好!我是安琪!感谢大家的支持与鼓励。 krita-ai-diffusion简介 在AIGC图像生成领域的迅猛发展下,当前的AI绘图工具如Midjourney、Stable Diffusion都能够近乎完美的生成逼真富有艺术视觉效果的图像质量。然而,针…...

4.Spring Context 装载过程源码分析
Spring的ApplicationContext是Spring框架中的核心接口之一,它扩展了BeanFactory接口,提供了更多的高级特性,如事件发布、国际化支持、资源访问等。ApplicationContext的装载过程是Spring框架中非常重要的一个环节。以下是ApplicationContext装…...

mysql之数据存储单元
简介 在MySQL中,单行数据存储单元的大小并不是固定的,它取决于多种因素,如表结构中使用的数据类型以及所使用的存储引擎。 但是我们可以提供一些关于MySQL中典型行数据存储单元大小的一般性指引: 存储引擎 InnoDB(默认存储引擎) InnoDB中单行数据存储单元的大小通常在8-16…...

未来20年人工智能将如何塑造社会
照片由Brian McGowan在Unsplash上拍摄 更多资讯,请访问 2img.ai “人工智能会成为我们的救星还是我们的末日?” 几十年来,这个问题一直困扰着哲学家、科学家和科幻爱好者。 当我们踏上技术革命的边缘时,是时候透过水晶球&#x…...
Maven的依赖传递、依赖管理、依赖作用域
在Maven项目中通常会引入大量依赖,但依赖管理不当,会造成版本混乱冲突或者目标包臃肿。因此,我们以SpringBoot为例,从三方面探索依赖的使用规则。 1、 依赖传递 依赖是会传递的,依赖的依赖也会连带引入。例如在项目中…...

3步打造你的专属游戏串流服务器:Sunshine终极指南
3步打造你的专属游戏串流服务器:Sunshine终极指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 还在为无法在客厅大电视上玩PC游戏而烦恼吗?想在平板上继…...

Jira、ONES、ClickUp 对比:哪款研发管理软件更适合中国研发团队?
快速迭代的互联网和软件行业,研发团队的效率管理工具几乎决定了产品交付的速度与质量。研发管理软件不仅是“任务分派”的工具,更是团队 需求管理、版本迭代、缺陷跟踪、研发效能度量 的基础设施。 目前市面上主流的研发管理软件众多,不同工…...

GraphQL在后端开发中的应用与优势
在现代后端开发领域,GraphQL作为一种新兴的API查询语言,正迅速改变着开发者构建和交互数据的方式。与传统的RESTful API相比,GraphQL提供了一种更灵活、高效的数据获取机制,使前端能够精准地请求所需数据,避免了过度获…...

基于RAG架构的私有知识库问答系统:从原理到部署实战
1. 项目概述:一个为LLM应用量身定制的开源知识库 如果你正在尝试构建一个基于大语言模型(LLM)的问答机器人、智能客服或者文档分析工具,那么你大概率会遇到一个核心难题:如何高效、稳定地将你自己的知识库(…...

如何在Windows上免费获得流畅的B站观影体验:BiliBili-UWP第三方客户端终极指南
如何在Windows上免费获得流畅的B站观影体验:BiliBili-UWP第三方客户端终极指南 【免费下载链接】BiliBili-UWP BiliBili的UWP客户端,当然,是第三方的了 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBili-UWP 还在为网页版B站卡顿…...

革新Mac软件管理体验:Applite智能图形化工具深度解析
革新Mac软件管理体验:Applite智能图形化工具深度解析 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为繁琐的命令行安装而烦恼?是否曾因复杂的Hom…...

5分钟完全指南:roop-unleashed AI换脸神器从入门到精通
5分钟完全指南:roop-unleashed AI换脸神器从入门到精通 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 想要在几分钟内制作专业级的AI换脸视频吗…...

AI开发者实战指南:从工具全景到本地知识库搭建
1. 从Awesome List到实战地图:一份AI开发者工具全景解析如果你是一名AI开发者、研究者,或者只是对构建AI应用充满好奇的技术爱好者,面对浩如烟海的工具、框架和平台,最头疼的恐怕就是“我该从哪里开始?”这个问题。网上…...

Gemini3.1Pro轻松搞定文献综述难题
对很多学生党来说,论文开题最难的地方,不是选题本身,而是文献综述。 题目定下来了,方向也有了,但一翻到文献就发现:资料很多、观点很多、结构却很乱,不知道怎么归纳,更不知道怎么写得…...

告别数据焦虑:WeChatExporter如何重塑你的数字记忆管理体验
告别数据焦虑:WeChatExporter如何重塑你的数字记忆管理体验 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 当你深夜翻看三年前的聊天记录,却发现…...