游戏AI的创造思路-技术基础-深度学习(3)
继续填坑,本篇介绍深度学习中的长短期记忆网络~~~~

目录
3.3. 长短期记忆网络(LSTM)
3.3.1. 什么是长短期记忆网络
3.3.2. 形成过程与运行原理
3.3.2.1. 细胞状态与门结构
3.3.2.2. 遗忘门
3.3.2.3. 输入门
3.3.2.4. 细胞状态更新
3.3.2.5. 输出门
3.3.2.6. 以上各步骤的示例代码
3.3.3. 优缺点
3.3.4. 存在的问题及解决方法
3.3.5. 示例代码
3.3. 长短期记忆网络(LSTM)
3.3.1. 什么是长短期记忆网络
长短期记忆网络(LSTM,Long Short-Term Memory)算法是一种特殊的循环神经网络(RNN),它旨在解决传统RNN在处理长序列数据时遇到的梯度消失和梯度爆炸问题,从而更有效地学习序列中的长期依赖关系。
- 为了最小化训练误差,通常使用梯度下降法,如应用时序性倒传递算法,来依据错误修改每次的权重。此外,LSTM有多种变体,其中一个重要的版本是门控循环单元(GRU)。
- LSTM适合于处理和预测时间序列中间隔和延迟非常长的重要事件。其表现通常比时间递归神经网络及隐马尔科夫模型(HMM)更好。例如,在不分段连续手写识别上,LSTM模型曾赢得过ICDAR手写识别比赛冠军。此外,LSTM还广泛应用于自主语音识别,并在2013年使用TIMIT自然演讲数据库达成了17.7%的错误率纪录。
- LSTM的成功在很大程度上促进了深度学习和人工智能领域的发展。尽管近年来出现了新的模型结构,如基于注意力机制的Transformer,但LSTM仍然是许多序列建模任务的可靠选择。随着时间的推移,LSTM被广泛应用于自然语言处理、语音识别、文本生成、视频分析等多个领域
3.3.2. 形成过程与运行原理
LSTM通过引入“门”结构和“细胞状态”来更好地捕捉序列中的长期依赖关系。(通过借鉴脑神经学的知识来组建序列中的长期依赖关系)
3.3.2.1. 细胞状态与门结构
LSTM的核心是细胞状态,它像一条传送带,在整个链上运行,只有一些小的线性操作作用其上,信息在上面流传保持不变会很容易。LSTM通过精心设计的门结构来去除或增加信息到细胞状态,这些门结构包括遗忘门、输入门和输出门。
3.3.2.2. 遗忘门
决定从细胞状态中丢弃什么信息。它查看当前的输入和前一个时间步的隐藏状态,并为细胞状态中的每个数字输出一个在0到1之间的数字,1表示“完全保留”,0表示“完全舍弃”。
遗忘门决定了从上一个时间步的细胞状态中丢弃哪些信息。其计算公式为:
其中,表示输入门在时刻
的值,
是时刻 ( t ) 的输入,
是前一个时刻的隐藏状态,
和
是对应的权重矩阵,而
是偏置项。函数
表示sigmoid激活函数。
3.3.2.3. 输入门
决定什么新信息将被存储在细胞状态中。这包括两部分,一部分是输入门决定我们将更新哪些部分,另一部分是tanh层创建一个新的候选值向量,这个向量可能会被添加到细胞状态中。
类似地,表示遗忘门在时刻
的值,其他符号的含义与输入门公式中的相同,只是权重和偏置项是针对遗忘门的。
3.3.2.4. 细胞状态更新
首先,旧细胞状态与遗忘门相乘,丢弃掉需要丢弃的信息。然后,将输入门的输出与tanh层的输出相乘,得出新的候选细胞状态。最后,将这两个值相加,形成新的细胞状态。
- 旧细胞状态与遗忘门相乘:
这里,表示经过遗忘门处理后的旧细胞状态,
是前一个时刻的细胞状态,
是遗忘门在时刻
的输出,而
表示逐元素相乘(Hadamard乘积)。这一步的目的是丢弃掉不需要的信息。
- 计算新的候选细胞状态:
其中,是新的候选细胞状态,
是时刻
的输入,
是前一个时刻的隐藏状态,
和
是对应的权重矩阵,
是偏置项。函数
是双曲正切激活函数,它将输入值压缩到 ( -1 ) 到 ( 1 ) 的范围内。
- 将候选细胞状态与输入门相乘:
这里,是输入门在时刻
的输出,
表示逐元素相乘。这一步的目的是根据输入门的选择来决定哪些新的信息被加入到细胞状态中。
- 更新细胞状态:
最终,新的细胞状态是经过遗忘门处理后的旧细胞状态
与经过输入门处理后的新候选细胞状态
之和。这一步完成了细胞状态的更新,使得LSTM能够记住长期依赖关系。
3.3.2.5. 输出门
基于细胞状态来决定输出什么。首先,运行一个sigmoid层来确定细胞状态的哪个部分将输出,然后将细胞状态通过tanh进行处理(得到一个在-1到1之间的值),并将其与sigmoid门的输出相乘,最终得到输出。
在这里,是输出门在时刻
的值,其他参数和符号的意义与前面公式中的一致,但针对输出门。
3.3.2.6. 以上各步骤的示例代码
Python代码示例
import numpy as np def sigmoid(x): return 1 / (1 + np.exp(-x)) def tanh(x): return np.tanh(x) # LSTM Cell 参数初始化
input_size = 10
hidden_size = 20 Wf = np.random.randn(hidden_size, hidden_size + input_size) # 遗忘门权重
Wi = np.random.randn(hidden_size, hidden_size + input_size) # 输入门权重
Wc = np.random.randn(hidden_size, hidden_size + input_size) # 候选细胞状态权重
Wo = np.random.randn(hidden_size, hidden_size + input_size) # 输出门权重 # LSTM Cell 前向传播
def lstm_cell_forward(xt, ht_prev, ct_prev, Wf, Wi, Wc, Wo): # 拼接前一个隐藏状态和当前输入 concat = np.concatenate((ht_prev, xt), axis=0) # 计算遗忘门 ft = sigmoid(np.dot(Wf, concat)) # 计算输入门 it = sigmoid(np.dot(Wi, concat)) # 计算候选细胞状态 cct = tanh(np.dot(Wc, concat)) # 细胞状态更新 ct = ft * ct_prev + it * cct # 计算输出门 ot = sigmoid(np.dot(Wo, concat)) # 计算隐藏状态 ht = ot * tanh(ct) return ht, ct # 示例使用
xt = np.random.randn(input_size) # 当前输入
ht_prev = np.zeros(hidden_size) # 前一个隐藏状态
ct_prev = np.zeros(hidden_size) # 前一个细胞状态 ht, ct = lstm_cell_forward(xt, ht_prev, ct_prev, Wf, Wi, Wc, Wo)
C++代码示例
#include <Eigen/Dense>
#include <cmath> using namespace Eigen; // 激活函数
double sigmoid(double x) { return 1.0 / (1.0 + std::exp(-x));
} double tanh(double x) { return std::tanh(x);
} // LSTM单元前向传播
void LSTMCellForward(const VectorXd& xt, const VectorXd& ht_prev, const VectorXd& ct_prev, const MatrixXd& Wf, const MatrixXd& Wi, const MatrixXd& Wc, const MatrixXd& Wo, VectorXd& ht, VectorXd& ct) { int input_size = xt.size(); int hidden_size = ht_prev.size(); VectorXd concat(input_size + hidden_size); concat << ht_prev, xt; // 计算遗忘门 VectorXd ft = concat.unaryExpr([](double elem) { return sigmoid(elem); }) * Wf.transpose(); // 计算输入门 VectorXd it = concat.unaryExpr([](double elem) { return sigmoid(elem); }) * Wi.transpose(); // 计算候选细胞状态 VectorXd cct = concat.unaryExpr([](double elem) { return tanh(elem); }) * Wc.transpose(); // 细胞状态更新 ct = ft.array() * ct_prev.array() + it.array() * cct.array(); // 计算输出门 VectorXd ot = concat.unaryExpr([](double elem) { return sigmoid(elem); }) * Wo.transpose(); // 计算隐藏状态 ht = ot.array() * ct.array().unaryExpr([](double elem) { return tanh(elem); });
} int main() { int input_size = 10; int hidden_size = 20; MatrixXd Wf = MatrixXd::Random(hidden_size, hidden_size + input_size); // 遗忘门权重 MatrixXd Wi = MatrixXd::Random(hidden_size, hidden_size + input_size); // 输入门权重 MatrixXd Wc = MatrixXd::Random(hidden_size, hidden_size + input_size); // 候选细胞状态权重 MatrixXd Wo = MatrixXd::Random(hidden_size, hidden_size + input_size); // 输出门权重 VectorXd xt = VectorXd::Random(input_size); // 当前输入 VectorXd ht_prev = VectorXd::Zero(hidden_size); // 前一个隐藏状态 VectorXd ct_prev = VectorXd::Zero(hidden_size); // 前一个细胞状态 VectorXd ht(hidden_size), ct(hidden_size); LSTMCellForward(xt, ht_prev, ct_prev, Wf, Wi, Wc, Wo, ht, ct); // Do something with ht and ct... return 0;
}这些代码是简化示例,实际应用中LSTM的实现会更加复杂,包括多个时间步的迭代、批处理支持、梯度计算和权重更新等。
在生产环境中,建议使用成熟的深度学习框架如TensorFlow或PyTorch来实现LSTM哦。
3.3.3. 优缺点
优点:
- 能够有效地解决传统RNN中的梯度消失和梯度爆炸问题。
- 能够更好地捕捉序列中的长期依赖关系。
- 在处理长序列数据时具有优势。
缺点:
- LSTM模型相对复杂,计算成本较高。
- 对于输入序列长度较长时,可能会出现过拟合现象,导致泛化能力下降。
3.3.4. 存在的问题及解决方法
过拟合问题:可以通过正则化、dropout等技术来减轻过拟合现象。
无法有效捕捉时间上下文关系:可以引入双向LSTM(Bidirectional LSTM)结构来提高对于时间上下文之间关系的建模能力。
对输入数据序列顺序敏感:在实际应用中,可以通过数据增强、序列颠倒等方法来减轻模型对输入数据序列顺序的敏感性。
3.3.5. 示例代码
Python代码
由于篇幅限制,这里提供一个简化的Python示例,使用PyTorch库实现LSTM:
import torch
import torch.nn as nn # 定义一个简单的LSTM模型
class SimpleLSTM(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(SimpleLSTM, self).__init__() self.hidden_size = hidden_size self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x, hidden): lstm_out, hidden = self.lstm(x, hidden) output = self.fc(lstm_out[:, -1, :]) # 取最后一个时间步的输出进行分类 return output, hidden def init_hidden(self, batch_size): return (torch.zeros(1, batch_size, self.hidden_size), torch.zeros(1, batch_size, self.hidden_size)) # 模型参数
input_size = 10
hidden_size = 20
output_size = 2
batch_size = 1
sequence_length = 5 # 创建模型实例
model = SimpleLSTM(input_size, hidden_size, output_size) # 创建虚拟输入数据和初始隐藏状态
x = torch.randn(batch_size, sequence_length, input_size)
hidden = model.init_hidden(batch_size) # 前向传播
output, hidden = model(x, hidden)
print(output)C++代码
在C++中使用LSTM,我们通常会借助PyTorch的C++ API,也称为LibTorch。以下是一个简单的示例:
#include <torch/script.h> // 包含TorchScript的头文件
#include <iostream> int main() { // 加载一个预先训练好的LSTM模型(这里假设你已经有一个用PyTorch训练的模型并导出了TorchScript) torch::jit::script::Module module; try { module = torch::jit::load("lstm_model.pt"); // 加载模型 } catch (const c10::Error& e) { std::cerr << "模型加载错误\n"; return -1; } // 创建一个输入张量,假设输入大小为[1, 5, 10](batch_size, sequence_length, input_size) torch::Tensor input = torch::randn({1, 5, 10}); // 执行模型前向传播 std::vector<torch::jit::IValue> inputs; inputs.push_back(input); torch::Tensor output = module.forward(inputs).toTensor(); std::cout << output << std::endl; return 0;
}请注意,C++ 示例中的模型需要是预先训练好并导出为TorchScript的模型。TorchScript是PyTorch的一个子集,允许模型在没有Python运行时的环境中执行。
在C++中直接使用LSTM而不依赖预先训练的模型会更复杂,因为你需要手动实现LSTM的所有细节。这通常不是推荐的做法,除非你有特定的性能要求或需要深度定制LSTM的行为。
在大多数情况下,使用PyTorch等高级库会更加方便和高效。
相关文章:
游戏AI的创造思路-技术基础-深度学习(3)
继续填坑,本篇介绍深度学习中的长短期记忆网络~~~~ 目录 3.3. 长短期记忆网络(LSTM) 3.3.1. 什么是长短期记忆网络 3.3.2. 形成过程与运行原理 3.3.2.1. 细胞状态与门结构 3.3.2.2. 遗忘门 3.3.2.3. 输入门 3.3.2.4. 细胞状态更新 3.…...
)
贪心算法练习题(2024/6/24)
1K 次取反后最大化的数组和 给你一个整数数组 nums 和一个整数 k ,按以下方法修改该数组: 选择某个下标 i 并将 nums[i] 替换为 -nums[i] 。 重复这个过程恰好 k 次。可以多次选择同一个下标 i 。 以这种方式修改数组后,返回数组 可能的最…...
大厂程序员上班猝死成常态?
大家好,我是瑶琴呀,拥有一头黑长直秀发的女程序员。 近日,连续看到大厂程序员猝死、低血糖晕倒的新闻,同为程序员感到很难受。互联网加班成常态这是既定事实,尤其在这个内卷严重、经济不景气的环境中,加班…...

深度学习 —— 1.单一神经元
深度学习初级课程 1.单一神经元2.深度神经网络3.随机梯度下降法4.过拟合和欠拟合5.剪枝、批量标准化6.二分类 前言 本套课程仍为 kaggle 课程《Intro to Deep Learning》,仍按之前《机器学习》系列课程模式进行。前一系列《Keras入门教程》内容,与本系列…...

Android 12.0 通知发送过程源码分析-Framework
以下NotificationManagerService简称 NMS 1. 通知的发送: NotificationManager.notify(int id, Notification notification) 开始. 源码路径: /frameworks/base/core/java/android/app/NotificationManager.java/***发布通知以显示在状态栏中。 如果通知带有* 相同的 ID 已被…...

提防远程攻击:了解正向 Shell 和反向 Shell 确保服务器安全
前言 在当今网络安全形势日益复杂的环境中,了解正向 Shell 和反向 Shell 的工作原理和使用场景,对于保护你的服务器免受远程攻击至关重要。本文不仅深入解析这两种常见的远程控制技术,还将提供有效的防护建议,帮助你提升服务器的…...

RabbitMQ中CorrelationData 与DeliveryTag的区别
在RabbitMQ中,CorrelationData是一个用于封装业务ID信息的类,它主要在消息确认机制中发挥作用。以下是关于CorrelationData在RabbitMQ中的详细作用: 封装业务ID信息: 当发送消息时,可以将业务ID信息封装在Correlation…...

数据恢复篇:如何在Android上恢复删除的短信
如果您不小心删除了Android设备上的短信并想要检索它们,则可以尝试以下方法: 如何在Android上恢复删除的短信 检查您的备份: 如果您之前备份了Android设备,则可以从备份中恢复已删除的短信。检查您设备的内部存储空间或 Google 云…...

花了大几万的踩坑经验!宠物空气净化器哪个牌子好:希喂、小米、有哈PK
我的闺蜜最近向我大吐苦水,自从家里养了猫之后,她发现家里的空气质量大不如前。宠物的浮毛和排泄物的气味在空气中飘散,让她非常怀念以前没有养猫时家里清新的呼吸环境。她觉得这些漂浮的毛发和异味大大降低了居家的舒适度。 还引起了身体上…...

查普曼大学团队使用惯性动捕系统制作动画短片
道奇电影和媒体艺术学院是查普曼大学的知名学院,同时也是美国首屈一指的电影学院之一,拥有一流电影制作工作室。 最近,道奇学院的一个学生制作团队接手了一个项目,该项目要求使用真人动作、视觉效果以及真人演员和CG角色之间的互动…...
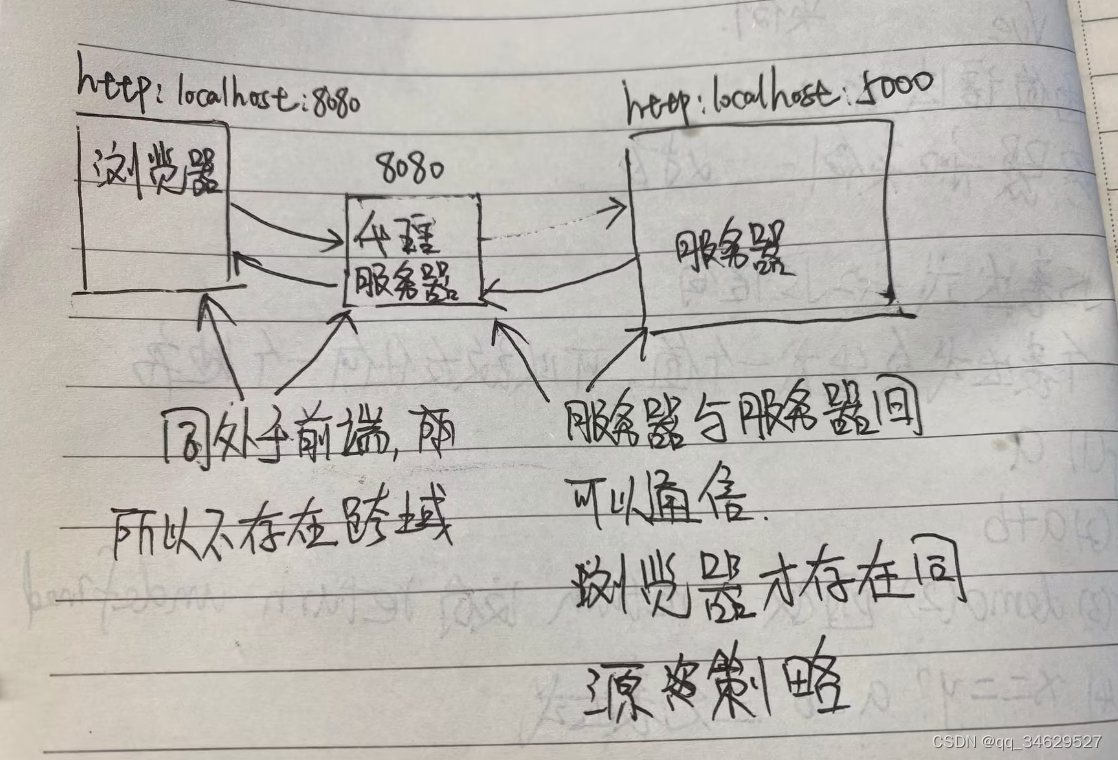
vue 代理
一、常用的发送一个ajax请求: 1、xhr new XMLHttpRequest(),真正开发中不常用 2、jq,jq主要功能是获取dom,周边才是请求接口 3、axios(大名鼎鼎的) axios.get("url").then(response>{},error>{} )4、…...

[leetcode]24-game
. - 力扣(LeetCode) class Solution { public:static constexpr int TARGET 24;static constexpr double EPSILON 1e-6;static constexpr int ADD 0, MULTIPLY 1, SUBTRACT 2, DIVIDE 3;bool judgePoint24(vector<int> &nums) {vector&l…...

网络爬虫的原理
网络爬虫的原理 网络爬虫,作为信息检索和数据分析的重要工具,其原理的核心在于模拟人类浏览网页的行为,通过自动化的方式从互联网上收集所需的数据。在了解了网络爬虫的基本原理后,我们可以进一步探讨其在实际应用中的工作机制以…...

游戏AI的创造思路-技术基础-机器学习(2)
本篇存在大量的公式,数学不好的孩子们要开始恶补数学了,尤其是统计学和回归方程类的内容。 小伙伴们量力而行~~~~~ 游戏呢,其实最早就是数学家、元祖程序员编写的数学游戏,一脉相承传承至今,囊括了更多的设计师、美术…...

【深度学习】记录为什么没有调用GPU
排查CLIP为什么评测推理没有调用GPU,主要是这个代码:https://github.com/OFA-Sys/Chinese-CLIP/blob/master/cn_clip/eval/extract_features.py 第一次认为:因为model并没有to.cuda()。 但是又发现,model.cuda(args.gpu) # 已经加…...

vite 创建vue3项目 集成 ESLint、Prettier、Sass等
在网上找了一大堆vue3脚手架的东西,无非就是vite或者vue-cli,在vue2时代,vue-cli用的人挺多的,也很好用,然而vue3大多是和vite搭配搭建的,而且个人感觉vite这个脚手架并没有那么的好用,搭建项目时只能做两个…...

计算机系统基础知识(上)
目录 计算机系统的概述 计算机的硬件 处理器 存储器 总线 接口 外部设备 计算机的软件 操作系统 数据库 文件系统 计算机系统的概述 如图所示计算机系统分为软件和硬件:硬件包括:输入输出设备、存储器,处理器 软件则包括系统软件和…...

[深度学习]循环神经网络RNN
RNN(Recurrent Neural Network,即循环神经网络)是一类用于处理序列数据的神经网络,广泛应用于自然语言处理(NLP)、时间序列预测、语音识别等领域。与传统的前馈神经网络不同,RNN具有循环结构&am…...

【C++:list】
list概念 list是一个带头的双向循环链表,双向循环链表的特色:每一个节点拥有两 个指针进行维护,俩指针分别为prev和next,prev指该节点的前一个节点,next为该节点的后一个节点 list的底层实现中为什么对迭代器单独写一个结构体进行…...

解锁 Apple M1/M2 上的深度学习力量:安装 TensorFlow 完全指南
前言 随着 Apple M1 和 M2 芯片的问世,苹果重新定义了笔记本电脑和台式机的性能标准。这些强大的芯片不仅适用于日常任务,还能处理复杂的机器学习和深度学习工作负载。本文将详细介绍如何在 Apple M1 或 M2 芯片上安装和配置 TensorFlow,助你…...

直播人力成本居高不下?2026十大AI数字人直播平台推荐实现长效运营
引文: 2026年,直播电商的竞争早已从“拼人设”转向了“拼夜间值守效率”。据公开数据显示,AI数字人核心市场规模预计在2026年逼近千亿大关,其中“降本”和“长效运营”是众多商家投身高频无人直播的核心诉求。事实上,…...

深度解析开源AI工具库:OpenAI API封装库的设计与实战应用
1. 项目概述:一个开源AI工具库的深度解构最近在GitHub上看到一个名为“anasfik/openai”的项目,这个标题乍一看有点意思。它不像官方SDK那样直接叫“openai”,而是带上了个人或组织的命名空间前缀“anasfik/”。这通常意味着这是一个第三方封…...

内存数据库eXtremeDB核心技术解析与实践指南
1. 内存数据库技术概述在传统数据库系统中,磁盘I/O往往是性能瓶颈所在。每次数据查询都需要从磁盘读取数据到内存缓冲区,这个过程中涉及机械寻道、旋转延迟等物理限制。而内存数据库(IMDS)通过直接在内存中存储和处理数据,彻底绕过了这个瓶颈…...

ACE Awards:电子行业年度创新风向标与工程师成长指南
1. 项目概述:一场属于电子工程师的年度庆典如果你在半导体或电子设计行业待过几年,肯定对“EE Times”和“EDN”这两个名字不陌生。它们就像是电子工程师的“行业圣经”,每天刷一刷,看看又有哪些新芯片发布、哪些技术路线在争论&a…...

PC市场转型:从性能竞赛到价值回归的产业变革
1. 市场格局的深层演变:从“性能至上”到“够用就好”如果你在2012年前后关注过PC市场,应该能清晰地感受到一股寒流。那几年,行业里最热门的话题不再是英特尔又发布了多快的处理器,或者英伟达的显卡性能提升了多少百分比ÿ…...

【Midjourney×Photoshop黄金工作流】:20年Adobe+AI实战专家亲授5步无缝整合法,97%设计师尚未掌握的智能修图新范式
更多请点击: https://intelliparadigm.com 第一章:MidjourneyPhotoshop黄金工作流的范式革命 传统图像创作正经历一场静默却深刻的重构——当 Midjourney 生成的高语义图像与 Photoshop 的像素级控制能力深度耦合,工作流不再只是“AI出图→人…...

gogoclaw:基于文件与技能的自主智能体运行时设计与实践
1. 项目概述:一个以文件为基石的自主智能体运行时如果你和我一样,对市面上那些“黑盒”式的AI智能体框架感到厌倦,总觉得它们把太多逻辑和状态藏在运行时深处,调试和扩展起来像在拆盲盒,那么gogoclaw这个项目可能会让你…...

GDScript Mod Loader:为Godot游戏打造专业模组生态的完整指南
1. 项目概述:为你的Godot游戏注入社区活力如果你是一名使用Godot引擎的独立游戏开发者,或者是一位热衷于为喜爱的游戏创造新内容的玩家,那么“模组”这个概念你一定不陌生。模组,或者说Mod,是游戏社区生命力的重要源泉…...

5分钟彻底解决Windows软件DLL缺失问题:VisualCppRedist AIO完整修复方案
5分钟彻底解决Windows软件DLL缺失问题:VisualCppRedist AIO完整修复方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过新安装的软…...

memrok:专为开发者设计的命令行记忆管理工具,提升项目效率
1. 项目概述:一个面向开发者的记忆管理工具最近在整理个人知识库和项目代码时,我常常被一个问题困扰:那些零散但关键的代码片段、临时的配置参数、一闪而过的调试思路,到底应该记在哪里?用笔记软件太笨重,用…...