BN,LN,IN,GN的理解和用法
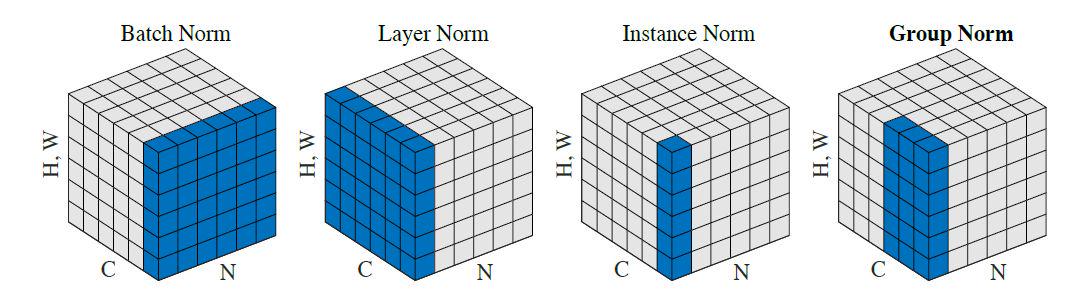
绿色区域表示将该区域作用域(四种方法都贯穿了w,h维度),即将该区域数值进行归一化,变为均值为0,标准差为1。BN的作用区域时N,W,H,表示一个batch数据的每一个通道均值为0,标准差为1;LN则是让每个数据的所有channel的均值为0,标准差为1。IN表示对每个数据的每个通道的均值为0,标准差为1.
BN,LN,IN,GN从学术化上解释差异:
BatchNorm:batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
LayerNorm:channel方向做归一化,算CHW的均值,主要对RNN作用明显;
InstanceNorm:一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束。
SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
BN的理解
Internal Covariate Shift定义
在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化的这一过程被称作Internal Covariate Shift。
Internal Covariate Shift引发的问题
1)上层网络需要不停调整来适应输入数据分布的变化,导致网络学习速度的降低
我们在上面提到了梯度下降的过程会让每一层的参数 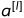 和
和 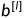 发生变化,进而使得每一层的线性与非线性计算结果分布产生变化。后层网络就要不停地去适应这种分布变化,这个时候就会使得整个网络的学习速率过慢。
发生变化,进而使得每一层的线性与非线性计算结果分布产生变化。后层网络就要不停地去适应这种分布变化,这个时候就会使得整个网络的学习速率过慢。
(2)网络的训练过程容易陷入梯度饱和区,减缓网络收敛速度
当我们在神经网络中采用饱和激活函数(saturated activation function)时,例如sigmoid,tanh激活函数,很容易使得模型训练陷入梯度饱和区(saturated regime)。随着模型训练的进行,我们的参数  会逐渐更新并变大,此时
会逐渐更新并变大,此时 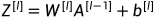 就会随之变大,并且
就会随之变大,并且 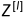 还受到更底层网络参数
还受到更底层网络参数 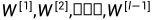 的影响,随着网络层数的加深, 很容易陷入梯度饱和区,此时梯度会变得很小甚至接近于0,参数的更新速度就会减慢,进而就会放慢网络的收敛速度。
的影响,随着网络层数的加深, 很容易陷入梯度饱和区,此时梯度会变得很小甚至接近于0,参数的更新速度就会减慢,进而就会放慢网络的收敛速度。
对于激活函数梯度饱和问题,有两种解决思路。第一种就是更为非饱和性激活函数,例如线性整流函数ReLU可以在一定程度上解决训练进入梯度饱和区的问题。另一种思路是,我们可以让激活函数的输入分布保持在一个稳定状态来尽可能避免它们陷入梯度饱和区,这也就是Normalization的思路。
BN的优点
(1)BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度
(2)BN使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定
(3)BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
(4)BN具有一定的正则化效果
BN的用法
对小批量(mini-batch)的2d或3d输入进行批标准化(Batch Normalization)操作
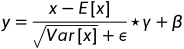
在每一个小批量(mini-batch)数据中,计算输入各个维度的均值和标准差。gamma与beta是可学习的大小为C的参数向量(C为输入大小)
在训练时,该层计算每次输入的均值与方差,并进行移动平均。移动平均默认的动量值为0.1。
在验证时,训练求得的均值/方差将用于标准化验证数据。
参数:
num_features: 来自期望输入的特征数,该期望输入的大小为'batch_size x num_features x width
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 一个布尔值,当设为true,给该层添加可学习的仿射变换参数。
Shape: - 输入:(N, C)或者(N, C, L) - 输出:(N, C)或者(N,C,L)(输入输出相同)
example:
>>> # With Learnable Parameters
>>> m = nn.BatchNorm1d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm1d(100, affine=False)
>>> input = autograd.Variable(torch.randn(20, 100))
>>> output = m(input)Shape: - 输入:(N, C,H, W) - 输出:(N, C, H, W)(输入输出相同)
归一化维度:[N,H,W],计算C次均值方差
>>> # With Learnable Parameters
>>> m = nn.BatchNorm2d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm2d(100, affine=False)
>>> input = autograd.Variable(torch.randn(20, 100, 35, 45))
>>> output = m(input)LN的用法
# NLP Example
batch, sentence_length, embedding_dim = 20, 5, 10
embedding = torch.randn(batch, sentence_length, embedding_dim)
layer_norm = nn.LayerNorm(embedding_dim)
# Activate module
layer_norm(embedding)
# Image Example
N, C, H, W = 20, 5, 10, 10
input = torch.randn(N, C, H, W)
# Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
# as shown in the image below
layer_norm = nn.LayerNorm([C, H, W])
output = layer_norm(input)IN的用法
# Without Learnable Parameters
m = nn.InstanceNorm2d(100)
# With Learnable Parameters
m = nn.InstanceNorm2d(100, affine=True)
input = torch.randn(20, 100, 35, 45)
output = m(input)GN的用法
input = torch.randn(20, 6, 10, 10)
# Separate 6 channels into 3 groups
m = nn.GroupNorm(3, 6)
# Separate 6 channels into 6 groups (equivalent with InstanceNorm)
m = nn.GroupNorm(6, 6)
# Put all 6 channels into a single group (equivalent with LayerNorm)
m = nn.GroupNorm(1, 6)
# Activating the module
output = m(input)BN和LN的用法差异
BN是把除了轴C外的所有轴的元素放在一起,取平均值和方差的,然后对每个元素进行归一化,最后再乘以对应的γ和β(共享)。BN共有num_features个mean和var,(假设输入数据的维度为(N,C, H, W))。
而LN是把normalized_shape这几个轴的元素都放在一起,取平均值和方差的,然后对每个元素进行归一化,最后再乘以对应的γ和β (每个元素不同)。LN共有N1*N2个mean和var(假设输入数据的维度为(N,normalized_shape(C, H, W),normalized_shape表示多个维度)
思考题1:为什么Layer Norm是对每个单词的Embedding做归一化?
因为每个序列(每个样本)的单词个数不一样,但在代码实现的时候会进行padding,比如一个序列原始单词数为30个,另一个序列原始单词数是8,然后你统一padding成了30个单词,那如果按照相同维度,进行归一化,norm的信息就会被无意义的padding的embedding冲淡的!这显然是不合理的。
思考题2:为什么BN训练和测试时有区别,而LN没区别?
BatchNorm的统计量是一个batch算出来的,在线测试时,不太可能累计一个batch资料后再进行测试的。所以在训练的时候要记录统计量running mean和running var,作为预测时的均值和方差。
而LayerNorm训练和测试的时候不需要model.train()和model.eval(),是因为它只针对一个样本,不是针对一个batch,所以LayerNorm只有参数gamma和beta,没有统计量,因此LN训练和预测没有区别。
参考文献:
https://zhuanlan.zhihu.com/p/34879333
https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-nn/#normalization-layers-source
https://blog.csdn.net/fksfdh/article/details/124750629
https://liumin.blog.csdn.net/article/details/85075706
https://blog.csdn.net/qq_43827595/article/details/121877901
https://pytorch.org/docs/stable/generated/torch.nn.LayerNorm.html#torch.nn.LayerNorm
相关文章:
BN,LN,IN,GN的理解和用法
绿色区域表示将该区域作用域(四种方法都贯穿了w,h维度),即将该区域数值进行归一化,变为均值为0,标准差为1。BN的作用区域时N,W,H,表示一个batch数据的每一个通道均值为0,标准差为1;LN则是让每个数据的所有channel的均值…...
Linux:epoll模式web服务器代码,代码debug
源码: https://blog.csdn.net/weixin_44718794/article/details/107206136 修改的地方: 修改后代码: #include <stdio.h> #include <unistd.h> #include <stdlib.h> //#include “epoll_server.h” #ifndef _EPOLL_SER…...
SpringSecurity学习(四)密码加密、RememberMe记住我
文章目录密码加密一、简介密码为什么要加密常见的加密解决方案PasswordEncoder详解DelegatingPasswordEncoder二、自定义加密方式1. 使用灵活的密码加密方案(BCryptPasswordEncoder)加密验证(推荐)需要在密码前指定加密类型{bcryp…...
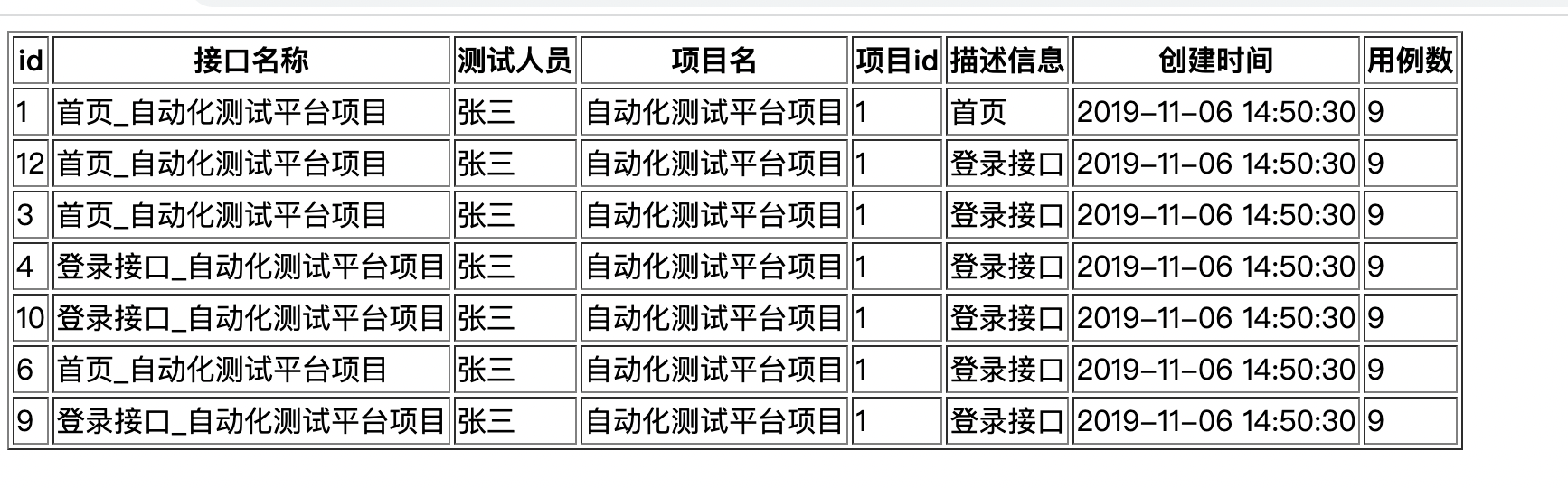
vue专项练习
一、循环实现一个列表的展示及删除功能 1.1 列表展示 1、背景: 完成一个这样的列表展示。使用v-for 循环功能 id接口名称测试人员项目名项目ID描述信息创建时间用例数1首页喵酱发财项目a1case的描述信息2019/11/6 14:50:30102个人中心张三发财项目a1case的描述信…...

【笔试题】百度+美团
发工资 链接:https://www.nowcoder.com/questionTerminal/e47cffeef25d43e3b16c11c9b28ac7e8 来源:牛客网 小度新聘请了一名员工牛牛, 每个月小度需要给牛牛至少发放m元工资(给牛牛发放的工资可以等于m元或者大于m元, 不能低于m)。 小度有一些钞票资金…...

【8.索引篇】
索引分类 索引和数据就是位于存储引擎中: 按「数据结构」分类:Btree索引、Hash索引、Full-text索引。按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。按「字段特性」分类&#…...
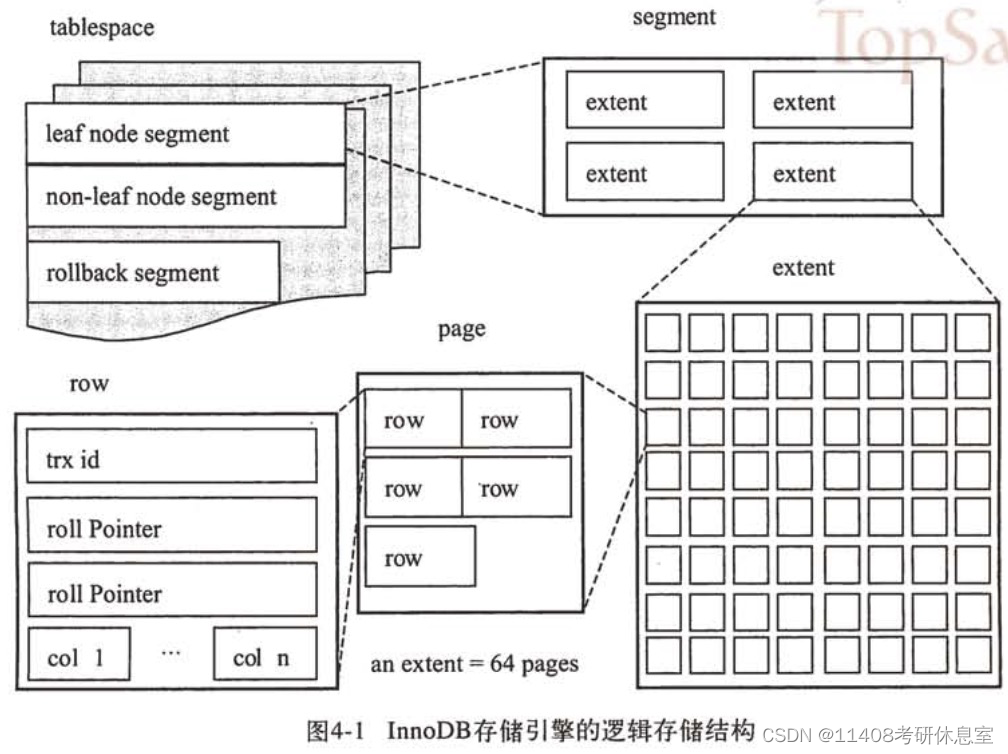
MySQL InnoDB存储引擎锁与事务实现原理解析(未完成)
InnoDB MySQL存储引擎是基于表的,也就是说每张表可以选择不同的存储引擎。 InnoDB存储引擎的表是索引组织的,也就是数据即索引。 存储引擎文件 InnoDB引擎会包含RedoLog重做日志文件和TableSpace表空间文件。 表空间文件 默认表空间文件(…...
JAVA)
P1683 入门(洛谷)JAVA
题目描述: 不是任何人都可以进入桃花岛的,黄药师最讨厌像郭靖一样呆头呆脑的人。所以,他在桃花岛的唯一入口处修了一条小路,这条小路全部用正方形瓷砖铺设而成。有的瓷砖可以踩,我们认为是安全的,而有的瓷砖…...

yocto编译烧录和脚本解析
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、初始化构建目录二、imx-setup-release.sh脚本解析三、编译单独编译内核四、烧录总结前言 本篇文章主要讲解如何在下载好源码之后进行编译和yocto的脚本解析…...

Proteus 8.15安装包安装教程
Proteus介绍Proteus的介绍Proteus8.15安装包Proteus8.15安装教程Proteus的介绍 Proteus是英国著名的EDA工具(仿真软件),从原理图布图、代码调试到单片机与外围电路协同仿真,一键切换到PCB设计,真正实现了从概念到产品的完整设计。是世界上唯…...

Spring——AOP工作流程
AOP就是代理模式的开发简化 1.Spring容器启动 因为AOP是要将通知类作为一个bean对象交给spring进行管理的,还有经过通知类被增强的类。 此时还没有创建bean对象 2.读取所有切面配置中的切入点 在下面这段代码中,定义了两个切入点,但是只…...
、notify_one()、notify_all()的使用。)
c++11多线程之condition_variable、wait()、notify_one()、notify_all()的使用。
系列文章目录 文章目录系列文章目录前言一、基本概念1.1 std::condition_variable1.2 wait()函数1.2.1 wait()带第二个参数1.2.2 wait()不带第二个参数1.2.3 当其他线程用notify_one()或notify_all()1.3 notify函数二、代码实例总结前言 C11多线程&…...

skywalking扩展实现 —— 监控数据的动态上报
把标题名整高大上一些,来掩盖需求的奇葩。 0. 目录1. 需求背景2. 需求描述3. 优势4. 实现4.1 扩展点4.2 配置项5. 优化6. 提醒7. 补充 - 关于微服务8. 参考1. 需求背景 过去一段时间,接手了一个迭代了数年的"基于微服务架构"搭建的产品。 自…...

【GoF 23】23种设计模式与OOP七大原则概述
1. 什么是GoF 23? GoF 23也就是23种设计模式。1995年GoF(Gang of Four,四人组/四人帮)合作出版了《设计模式:可复用面向对象软件的基础》一书,一共收录了23种设计模式,从此梳理了软件设计模式领…...

Java 日期时间
Java 日期时间是 Java 标准库中一个非常重要的部分,它提供了丰富的 API 来处理日期、时间以及日期时间。在 Java 应用程序中,我们经常需要处理日期时间相关的操作,例如计算两个日期之间的差、将日期时间转换为不同的时区等。在本篇文章中&…...
Face Forgery Suvery
文章目录Face ForgeryFace Forgery classAttribute ManipulationExpression SwapIdentity SwapEntire Face SynthesisFace Forgery DetectionLow-levelOn the Detection of Digital Face Manipulation(CVPR2020)High-levelProtecting World Leaders Against Deep FakesDetectin…...

案例学习--016 消息队列作用和意义
简介MQ全称为Message Queue, 是一种分布式应用程序的的通信方法,它是消费-生产者模型的一个典型的代表,producer往消息队列中不断写入消息,而另一端consumer则可以读取或者订阅队列中的消息。主要产品有:ActiveMQ、RocketMQ、Rabb…...

【MySQL】MySQL的锁机制
目录 概述 MyISAM 表锁 InnoDB行锁 概述 锁是计算机协调多个进程或线程并发访问某一资源的机制(避免争抢)。 在数据库中,除传统的 计算资源(如 CPU、RAM、I/O 等)的争用以外,数据也是一种供许多用户共…...

HTML 背景
一个富有美感的背景会让站点看上去更加高级、更有吸引力。本篇为大家来的是 HTML 背景相关内容。 背景(Backgrounds) <body> 拥有两个配置背景的标签。背景可以是颜色或者图像。 背景颜色(Bgcolor) 背景颜色属性将背景设…...

Lombok
文章目录简介原理安装常用Getter、SetterToStringEqualsAndHashCodeNonNullNoArgsConstructor、RequiredArgsConstructor、AllArgsConstructorDATABuilderLogvalCleanup简介 Project Lombok is a java library that automatically plugs into your editor and build tools, spi…...

如何准确计算宏基因组覆盖率?CoverM工具的全方位技术解析
如何准确计算宏基因组覆盖率?CoverM工具的全方位技术解析 【免费下载链接】CoverM Read alignment statistics for metagenomics 项目地址: https://gitcode.com/gh_mirrors/co/CoverM 在宏基因组研究中,覆盖率计算是评估测序深度、估算物种丰度和…...

Vivado 2023.1 与 Questasim 2024.1 协同仿真环境搭建全攻略
1. 环境准备:安装与版本确认 在开始搭建Vivado 2023.1与QuestaSim 2024.1的协同仿真环境前,首先要确保两个软件都已正确安装。我最近在搭建这个环境时发现,新版本对系统环境的要求比旧版本更严格。建议使用Windows 10 64位专业版或企业版&…...

工程师视角:从生物钟原理到实战,系统化解决跨时区时差问题
1. 时差反应的本质与挑战:为什么我们会被“时差”困扰?作为一名常年需要跨时区协作的硬件工程师,我对“时差”这个词有着切肤之痛。无论是为了一个紧急的客户会议飞往硅谷,还是参加一年一度的慕尼黑电子展,跨越多个时区…...

如何利用本地自动化工具提升英雄联盟游戏体验:3个核心功能详解
如何利用本地自动化工具提升英雄联盟游戏体验:3个核心功能详解 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 在英雄联盟的激烈对…...

从标注到部署:用LabelImg和MaixHub,在K210上跑通你的第一个“汽车识别”模型全流程
从零构建汽车识别模型:LabelImg标注与K210部署实战指南 在智能硬件开发领域,K210芯片以其高效的AI推理能力成为边缘计算的热门选择。本文将带您完整走通一个汽车识别项目的全流程——从数据标注到模型部署。不同于市面上泛泛而谈的教程,我们聚…...

Python实战:三大曲线平滑技术对比与场景选型指南
1. 曲线平滑处理的必要性 当你处理传感器数据、金融时间序列或任何带有噪声的曲线时,原始数据往往像一条暴躁的蚯蚓——上下乱窜让人抓狂。我在处理工业传感器数据时就遇到过这种情况:一条本该平滑的温度曲线,因为电磁干扰变成了"心电图…...

揭秘SITS 2026调度内核:如何用1个轻量CRD替代3类Operator+2个Admission Webhook,实现离线推理任务零配置交付?
更多请点击: https://intelliparadigm.com 第一章:AI原生批处理优化:SITS 2026离线推理任务调度策略 SITS 2026(Scalable Intelligent Task Scheduler)是专为AI原生工作负载设计的离线推理调度引擎,其核心…...

HC32F4A0 ADC+DMA实战:8通道模拟量采集,从时钟配置到数据搬运的保姆级避坑指南
HC32F4A0 ADCDMA实战:8通道模拟量采集全流程精解与典型问题排查 在工业控制、智能家居和物联网设备开发中,多通道模拟信号采集是嵌入式系统的基础功能。HC32F4A0作为华大半导体推出的高性能MCU,其ADC模块配合DMA控制器可实现高效的数据采集方…...

新手父母必备:开源婴儿护理知识库架构与核心技能解析
1. 项目概述:一个为新手父母量身定制的技能宝库如果你是一位即将迎来新生命,或者刚刚升级为父母的朋友,面对那个软软糯糯的小家伙,除了满心的喜悦,是不是也时常感到一丝手足无措?喂奶、拍嗝、哄睡、洗澡、抚…...

ROFL Player终极指南:英雄联盟回放分析工具完整使用教程
ROFL Player终极指南:英雄联盟回放分析工具完整使用教程 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟回放…...