Pytorch实战(一):LeNet神经网络
文章目录
- 一、模型实现
- 1.1数据集的下载
- 1.2加载数据集
- 1.3模型训练
- 1.4模型预测
LeNet神经网络是第一个卷积神经网络(CNN),首次采用了卷积层、池化层这两个全新的神经网络组件,接收灰度图像,并输出其中包含的手写数字,在手写字符识别任务上取得了瞩目的准确率。LeNet网络的一系列的版本,以LeNet-5版本最为著名,也是LeNet系列中效果最佳的版本。LeNet神经网络输入图像大小必须为32x32,且所用卷积核大小固定为5x5,模型结构如下:
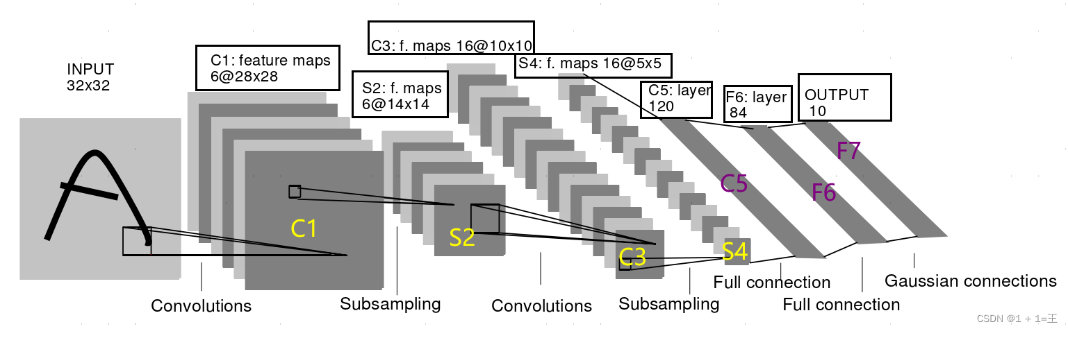
模型参数:
- INPUT(输入层):输入图像尺寸为32x32,且是单通道灰色图像。
- C1(卷积层):使用6个5x5大小的卷积核,步长为1,卷积后得到6张28×28的特征图。
- S2(池化层):使用了6个2×2 的平均池化,池化后得到6张14×14的特征图。
- C3(卷积层):使用了16个大小为5×5的卷积核,步长为1,得到 16 张10×10的特征图。
- S4(池化层):使用16个2×2的平均池化,池化后得到16张5×5 的特征图。
- C5(卷积层):使用120个大小为5×5的卷积核,步长为1,卷积后得到120张1×1的特征图。
- F6(全连接层):输入维度120,输出维度是84(对应7x12 的比特图)。
- OUTPUT(输出层):使用高斯核函数,输入维度84,输出维度是10(对应数字 0 到 9)。
该模型有如下特点:
- 1.首次提出卷积神经网络基本框架: 卷积层,池化层,全连接层。
- 2.卷积层的权重共享,相较于全连接层使用更少参数,节省了计算量与内存空间。
- 3.卷积层的局部连接,保证图像的空间相关性。
- 4.使用映射到空间均值下采样,减少特征数量。
- 5.使用双曲线(tanh)或S型(sigmoid)形式的非线性激活函数。
一、模型实现
1.1数据集的下载
使用torchversion内置的MNIST数据集,训练集大小60000,测试集大小10000,图像大小是1×28×28,包括数字0~9共10个类。
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torchvision
# 下载训练、测试数据集
mnist_train = torchvision.datasets.MNIST(root='./dataset/',train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./dataset/',train=False, download=True, transform=transforms.ToTensor())
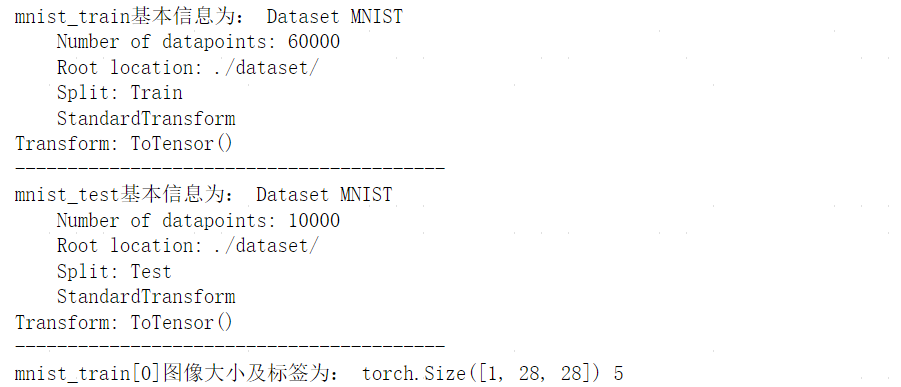
print('mnist_train基本信息为:',mnist_train)
print('-----------------------------------------')
print('mnist_test基本信息为:',mnist_test)
print('-----------------------------------------')
img,label=mnist_train[0]
print('mnist_train[0]图像大小及标签为:',img.shape,label)
1.2加载数据集
trainDataLoader = DataLoader(mnist_train, batch_size=64, num_workers=5, shuffle=True)
testDataLoader = DataLoader(mnist_test, batch_size=64, num_workers=0, shuffle=True)
write = SummaryWriter('./log')
step = 0
for images, labels in testDataLoader:write.add_images(tag='train', images, global_step=step)step += 1
write.close()
注意不能使用for images, labels in testDataLoader.dataset,testDataLoader.dataset[0]是保存图像(28
,28)和对应标签的元组,而Tensorboard的add_images只能输入NCHW格式对象,使用该代码会报错:
size of input tensor and input format are different. tensor shape: (1, 28, 28), input_format: NCHW
数据加载器按batch_size对数据及标签进行封装名,可直接作为输入。查看封装的元组:
for data in testDataLoader:print('type(data):',type(data))img,label=dataprint('type(img):',type(img),'img.shape:',img.shape)print('type(label):',type(label),'label.shape:',label.shape)

1.3模型训练
LeNet模型的输入为(32,32)的图片,而MNIST数据集为(28,28)的图片,故需对原图片进行填充。搭建模型:
class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.model = nn.Sequential( #MNIST数据集图像大小为28x28,而LeNet输入为32x32,故需填充nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2), #C1层共六个卷积核,故out_channels=6nn.AvgPool2d(kernel_size=2, stride=2), #C2层使用平均池化nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Conv2d(in_channels=16 * 5 * 5, out_channels=120),nn.Linear(in_features=120, out_features=84),nn.Linear(in_features=84, out_features=10))def forward(self, x):return self.model(x)# 初始化模型对象
myLeNet = LeNet()
设置损失函数、优化器并训练模型:
# 设置损失函数为交叉熵损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 设置优化器,使用Adam优化算法
learning_rate = 1e-2
optimizer = torch.optim.Adam(myLeNet.parameters(), lr=learning_rate)
total_train_step = 0 # 总训练次数
epoch = 10 # 训练轮数
writer = SummaryWriter(log_dir='./runs/LeNet/')
for i in range(epoch):print("-----第{}轮训练开始-----".format(i + 1))myLeNet.train() # 训练模式train_loss = 0for data in trainDataLoader:imgs, labels = dataimgs = imgs.to(device) # 适配GPU/CPUlabels = labels.to(device)outputs = myLeNet(imgs)loss = loss_fn(outputs, labels)#计算损失函数optimizer.zero_grad() # 清空之前梯度loss.backward() # 反向传播optimizer.step() # 更新参数total_train_step += 1 # 更新步数train_loss += loss.item()writer.add_scalar("train_loss_detail", loss.item(), total_train_step)writer.add_scalar("train_loss_total", train_loss, i + 1)writer.close()
1.4模型预测
myLeNet.eval()
total_test_loss = 0 # 当前轮次模型测试所得损失
total_accuracy = 0 # 当前轮次精确率
with torch.no_grad(): # 关闭梯度反向传播for data in testDataLoader:imgs, targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = myLeNet(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracy
writer.add_scalar("test_loss", total_test_loss, i+1)
writer.add_scalar("test_accuracy", total_accuracy/len(mnist_test), i+1)
https://blog.csdn.net/qq_43307074/article/details/126022041?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171938503416800186515588%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=171938503416800186515588&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_click~default-2-126022041-null-null.142v100pc_search_result_base3&utm_term=LeNet&spm=1018.2226.3001.4187
https://blog.csdn.net/hellocsz/article/details/80764804?ops_request_misc=&request_id=&biz_id=102&utm_term=LeNet&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1-80764804.142v100pc_search_result_base3&spm=1018.2226.3001.4187
https://blog.csdn.net/qq_45034708/article/details/128319241?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171936257316800222847105%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=171936257316800222847105&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-128319241-null-null.142v100pc_search_result_base3&utm_term=LeNet&spm=1018.2226.3001.4187
相关文章:
Pytorch实战(一):LeNet神经网络
文章目录 一、模型实现1.1数据集的下载1.2加载数据集1.3模型训练1.4模型预测 LeNet神经网络是第一个卷积神经网络(CNN),首次采用了卷积层、池化层这两个全新的神经网络组件,接收灰度图像,并输出其中包含的手写数字&…...
RabbitMq的基础及springAmqp的使用
RabbitMq 官网:RabbitMQ: One broker to queue them all | RabbitMQ 什么是MQ? mq就是消息队列,消息队列遵循这先入先出原则。一般用来解决应用解耦,异步消息,流量削峰等问题,实现高性能,高可用…...
uniapp uniCloud云开发
uniCloud概述 uniCloud 是 DCloud 联合阿里云、腾讯云、支付宝云,为开发者提供的基于 serverless 模式和 js 编程的云开发平台。 uniCloud 的 web控制台地址:https://unicloud.dcloud.net.cn 文档:https://doc.dcloud.net.cn/uniCloud/ un…...

智能扫地机,让生活电器更加便民-NV040D扫地机语音方案
一、语音扫地机开发背景: 随着人工智能和物联网技术的飞速发展,智能家居设备已成为现代家庭不可或缺的一部分。其中,扫地机作为家庭清洁的重要工具,更是得到了广泛的关注和应用。 然而,传统的扫地机在功能和使用上仍存…...
【后端面试题】【中间件】【NoSQL】ElasticSearch索引机制和高性能的面试思路
Elasticsearch的索引机制 Elasticsearch使用的是倒排索引,所谓的倒排索引是相对于正排索引而言的。 在一般的文件系统中,索引是文档映射到关键字,而倒排索引则相反,是从关键字映射到文档。 如果没有倒排索引的话,想找…...

【漏洞复现】时空智友ERP updater.uploadStudioFile接口处存在任意文件上传
0x01 产品简介 时空智友ERP是一款基于云计算和大数据技术的企业资源计划管理系统。该系统旨在帮助企业实现数字化转型,提高运营效率、降低成本、增强决策能力和竞争力,时空智友ERP系统涵盖了企业的各个业务领域,包括财务管理、供应链管理、生…...

[leetcode hot 150]第五百三十题,二叉搜索树的最小绝对差
题目: 给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。 差值是一个正数,其数值等于两值之差的绝对值。 解析: minDiffInBST 方法是主要方法。创建一个 ArrayList 来存储树的节点值。inorderTrave…...

【Docker】可视化平台Portainer
文章目录 Portainer的特点Portainer的安装步骤注意事项 Docker的可视化工具Portainer是一个轻量级的容器管理平台,它为用户提供了一个直观的图形界面来管理Docker环境。以下是关于Portainer的详细介绍和安装步骤: Portainer的特点 轻量级:P…...

MySQL高级-MVCC-原理分析(RR级别)
文章目录 1、RR隔离级别下,仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView2、总结 1、RR隔离级别下,仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView 而RR 是可重复读,在一个事务中&…...

压力测试Monkey命令参数和报告分析
目录 常用参数 -p <测试的包名列表> -v 显示日志详细程度 -s 伪随机数生成器的种子值 --throttle < 毫秒> --ignore-crashes 忽略崩溃 --ignore-timeouts 忽略超时 --monitor-native-crashes 监视本地崩溃代码 --ignore-security-exceptions 忽略安全异常 …...
C# Benchmark
创建控制台项目(或修改现有项目的Main方法代码),Nget导入Benchmark0.13.12,创建测试类: public class StringBenchMark{int[] numbers;public StringBenchMark() {numbers Enumerable.Range(1, 20000).ToArray();}[Be…...
算法金 | 协方差、方差、标准差、协方差矩阵
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 抱个拳,送个礼 1. 方差 方差是统计学中用来度量一组数据分散程度的重要指标。它反映了数据点与其均值之间的偏离程度。在…...
FastAPI教程II
本文参考FastAPI教程https://fastapi.tiangolo.com/zh/tutorial Cookie参数 定义Cookie参数与定义Query和Path参数一样。 具体步骤如下: 导入Cookie:from fastapi import Cookie声明Cookie参数,声明Cookie参数的方式与声明Query和Path参数…...

Facebook的投流技巧有哪些?
相信大家都知道Facebook拥有着巨大的用户群体和高转化率,在国外社交推广中的影响不言而喻。但随着Facebook广告的竞争越来越激烈,在Facebook广告上获得高投资回报率也变得越来越困难。IPIDEA代理IP今天就教大家如何在Facebook上投放广告的技巧࿰…...

Spring Boot 中的微服务监控与管理
微服务的概述 微服务架构的优点和挑战 优点: 灵活性和可扩展性:微服务架构允许每个服务单独部署和扩展,这使得系统可以更灵活地适应不同的业务需求和负载变化。 使团队更加聚焦:每个微服务都有明确的职责,这使得开发团队可以更加聚焦,专注于开发他们的服务。 技术和框…...
模拟卷)
【计算机网络】期末复习(1)模拟卷
一、选择题 1. 电路交换的三个阶段是建立连接、()和释放连接 A. Hello包探测 B. 通信 C. 二次握手 D. 总线连接 2. 一下哪个协议不属于C/S模式() A. SNMP…...

【软件工程中的演化模型及其优缺点】
文章目录 1. 增量模型什么是增量模型?优点缺点 2. 增量-迭代模型什么是增量-迭代模型?优点缺点 3. 螺旋模型什么是螺旋模型?优点缺点 1. 增量模型 什么是增量模型? 增量模型是一种逐步增加功能和特性的开发方法。项目被划分为多…...

Oracle 数据库详解:概念、结构、使用场景与常用命令
1. 引言 Oracle 数据库作为全球领先的关系型数据库管理系统(RDBMS),在企业级应用中占据了重要地位。本文将详细介绍Oracle数据库的核心概念、架构、常用操作及其广泛的使用场景,旨在为读者提供全面而深入的理解。 2. Oracle 数据…...

FreeRTOS的裁剪与移植
文章目录 1 FreeRTOS裁剪与移植1.1 FreeRTOS基础1.1.1 RTOS与GPOS1.1.2 堆与栈1.1.3 FreeRTOS核心文件1.1.4 FreeRTOS语法 1.2 FreeRTOS移植和裁剪 1 FreeRTOS裁剪与移植 1.1 FreeRTOS基础 1.1.1 RTOS与GPOS 实时操作系统(RTOS):是指当…...

能求一个数字的字符数量的程序
目录 开头程序程序的流程图程序输入与打印的效果例1输入输出 例2输入输出 关于这个程序的一些实用内容结尾 开头 大家好,我叫这是我58,今天,我们先来看一下下面的程序。 程序 #define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h>…...

Token工厂:从“卖流量”到“卖Token”:中国移动砸百亿建Token生态,三大运营商的AI战争升级,阿里,百度,华为,字节跟进
5月9日,2026移动云大会上,中国移动市场经营部总经理邱宝华扔出一个新概念——"Token运营体系"。未来3-5年,中国移动将投入百亿级Token生态资源,建设千亿级算力基础设施,携手共创万亿级AI产业价值。"百亿…...

Cursor IDE事件日志分析工具:Python实现开发者行为可视化与效率洞察
1. 项目概述:一个为开发者“把脉”的智能分析工具如果你是一名开发者,尤其是深度使用Cursor这类AI编程助手的开发者,你肯定有过这样的体验:面对一个复杂的项目,你向AI助手提了无数个问题,生成了大量代码片段…...
)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战(含ifconfig与DHCP详解)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战 当你第一次看到QNX Neutrino RTOS的Photon桌面时,那种兴奋感可能很快会被一个现实问题冲淡——这个看起来酷炫的系统怎么连上网?作为实时操作系统领域的标杆,QNX在车载系…...

基于Sovereign-MCP-Servers构建私有AI工具链:从协议原理到Docker化部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给Claude、Cursor这类工具加上“联网”和“执行”能力时,绕不开一个概念:MCP(Model Context Protocol)。简单说,MCP就是一套标准协议,它能让…...

基于 Next.js 的无头电商架构实战:从 Vercel Commerce 看现代全栈开发
1. 项目概述:一个面向未来的全栈电商起点如果你最近在琢磨着用 Next.js 搞一个电商网站,或者想找一个现代、开箱即用的全栈电商模板来启动项目,那你大概率已经听说过vercel/commerce这个仓库了。它不是某个具体的电商平台,而是一个…...

从零构建专属大语言模型:Self-LLM开源项目全流程实践指南
1. 项目概述与核心价值最近在开源社区里,一个名为datawhalechina/self-llm的项目引起了我的注意。乍一看,这像是一个关于大语言模型(LLM)的仓库,但“self”这个前缀又让人浮想联翩。经过一段时间的深入研究和实践&…...

Pro Trinket:Arduino UNO的紧凑型替代方案与双模编程实战
1. Pro Trinket:当Arduino遇上“口袋工程学”如果你和我一样,在创客圈子里摸爬滚打多年,肯定经历过这样的场景:一个基于Arduino UNO的酷炫原型在面包板上运行得风生水起,但当你试图把它塞进一个精致的3D打印外壳&#…...
)
旁遮普语内容出海迫在眉睫!ElevenLabs+AWS Polly双引擎容灾方案(含Failover切换SLA 99.99%保障协议模板)
更多请点击: https://intelliparadigm.com 第一章:旁遮普语内容出海的战略紧迫性与本地化语音缺口 旁遮普语是全球使用人数超1.2亿的语言,主要分布在印度旁遮普邦、巴基斯坦旁遮普省及庞大的海外侨民社群(如加拿大、英国、美国&…...

OpenClaw-Subcortex:轻量级自动化任务编排与执行框架详解
1. 项目概述与核心价值最近在折腾一些自动化工具,发现一个挺有意思的项目叫openclaw-subcortex。乍一看这个名字,可能有点摸不着头脑,又是“爪子”又是“皮层下”的,感觉像是什么生物或者神经科学的东西。但实际上,这是…...

ctfileGet:城通网盘直连地址解析工具的技术原理与实用指南
ctfileGet:城通网盘直连地址解析工具的技术原理与实用指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet ctfileGet是一个基于Web的开源工具,专门用于解析城通网盘分享链接并获…...