C++学习全教程(Day2)
一、数组
在程序中为了处理方便,常常需要把具有相同类型的数据对象按有序的形式排列起来,形成“一组”数据,这就是“数组”(array)
数组中的数据,在内存中是连续存放的,每个元素占据相同大小的空间,就像排好队一样。
1、数组的定义
数组的定义形式如下:
![]()
首先需要声明类型r数组中所有元素必须具有相同的数据类型;
数组名是一个标识符;后面跟着中括号,里面定义了数组中元素的个数,也就是数组的“长度”;
元素个数也是类型的一部分,所以必须是确定的;

需要注意的是:
对数组做初始化,要使用花括号括起来的数值序列;
如果做了初始化,数组定义时的元素个数可以省略,编译器可以根据初始化列表自动推断出来;
初始值的个数,不能超过指定的元素个数;
初始值的个数,如果小于元素个数,那么会用列表中的值初始化靠前的元素;剩余元素用默认值填充,整型的默认值就是0;
如果没有做初始化,数组中元素的值都是未定义的;这一点和普通的局部变量一致;|
2、数组的访问
(1)访问数组元素
数组元素在内存中是连续存放的,它们排好了队之后就会有一个队伍中的编号,称为“索引”,也叫“下标”;通过下标就可以快速访问每个元素了,具体形式为:
![]()
这里也是用了中括号来表示元素下标位置,被称为“下标运算符”。比如 a[2]就表示数组a中下标为2的元素,可以取它的值输出,也可以对它赋值。

#include<iostream>using namespace std;int main()
{int a[] = {1,2,3,4,5,6};cout << "a[1] = " << a[1] << endl;a[1] = 666;cout << "a[1] = " << a[1] << endl;cin.get();
}运行结果:

需要注意的是:
数组的下标从o开始;
因此 a[2]访问的并不是数组 a的第2个元素,而是第三个元素;一个长度为10的数组,下标范围是o~9,而不是1~10;
合理的下标,不能小于o,也不能大于(数组长度-1);否则就会出现数组下标越界;
(2)数组的大小
所有的变量,都会在内存中占据一定大小的空间;而数据类型就决定了它具体的大小。而对于数组这样的“复合类型”,由于每个元素类型相同,因此占据空间大小的计算遵循下面的简单公式:

#include<iostream>using namespace std;int main()
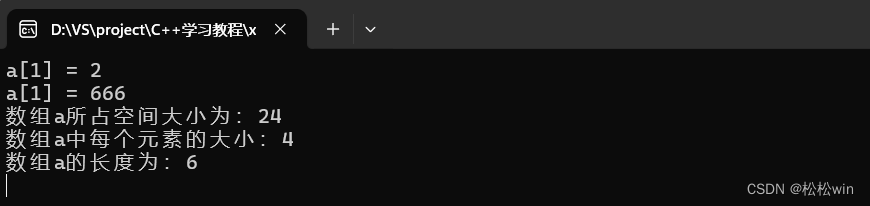
{int a[] = {1,2,3,4,5,6};cout << "a[1] = " << a[1] << endl;a[1] = 666;cout << "a[1] = " << a[1] << endl;//获取数组大小的长度cout << "数组a所占空间大小为:" << sizeof(a) << endl;cout << "数组a中每个元素的大小:" << sizeof(a[0]) << endl;int size;size = sizeof(a) / sizeof(a[0]);cout << "数组a的长度为:" << size << endl;cin.get();
}运行结果:
3、多维数组

C++中本质上没有“多维数组”这种东西,所谓的“多维数组”,其实就是“数组的数组”。
二维数组int arr[3][4]表示: arr是一个有三个元素的数组,其中的每个元素都是一个int 数组,包含4个元素;
三维数组int arr2[2][5][10]表示: arr2是一个长度为2的数组,其中每个元素都是一个二维数组;这个二维数组有5个元素,每个元素都是一个长度为10的int 数组;
一般最常见的就是二维数组。它有两个“维度”,第一个维度表示数组本身的长度,第二个表示每个元素的长度,一般分别把它们叫做“行”和“列”。
(1)多维数组的初始化
和普通的“一维”数组一样,多维数组初始化时,也可以用花括号括起来的一组数。使用嵌套的花括号可以让不同的维度更清晰:

需要注意:
内嵌的花括号不是必需的,因为数组中的元素在内存中连续存放,可以用一个花括号将所有数据括在一起;
初始值的个数,可以小于数组定义的长度,其它元素初始化为0值;这一点对整个二维数组和每一行的一维数组都适用;
如果省略嵌套的花括号,当初始值个数小于总元素个数时,会按照顺序依次填充(填满第一行,才填第二行);其它元素初始化为О值;
多维数组的维度,可以省略第一个,由编译器自动推断;即二维数组可以省略行数,但不能省略列数。
#include<iostream>using namespace std;int main()
{//初始化int a[3][4] = {1,2,3,4,5,6,7,8,9,10,11,12};int b[3][4] = { {1,2,3,4},{5,6,7,8},{9,10,11,12}};int c[3][4] = { 1,2,3,4 };int d[][4] = { 1,2,3,4,5,6 };//访问cout << "b[1][1] = " << b[1][1] << endl;b[1][1] = 666;cout << "b[1][1] = " << b[1][1] << endl;//遍历//计算二维数组中的行数和列数cout << "二维数组b的总大小:" << sizeof(b) << endl; //大小说的是字节cout << "二维数组每一行的大小:" << sizeof(b[0]) << endl;cout << "二维数组中每一个元素的大小:" << sizeof(b[0][0]) << endl;int rowCnt = sizeof(b) / sizeof(b[0]); //行数int colCnt = sizeof(b[0]) / sizeof(b[0][0]); //列数cout << "rowCnt = " << rowCnt << endl;cout << "colCnt = " << colCnt << endl;for (int i = 0; i < rowCnt; i++){for (int j = 0; j < colCnt; j++){cout << b[i][j] << "\t";}cout << endl;}cin.get();
}运行结果:

4、数组的排序
数组排序指的是给定一个数组,要求把其中的元素按照从小到大(或从大到小)顺序排列。
这是一个非常经典的需求,有各种不同的算法可以实现。我们这里介绍两种最基本、最简单的排序算法。
(1)选择排序
选择排序是一种简单直观的排序算法。
它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后追加到已排序序列的末尾。以此类推,直到所有元素均排序完毕。

#include<iostream>using namespace std;int main()
{int a[] = {2,5,8,4,9,1,6,3,7,0};//计算数组a的大小int size = sizeof(a) / sizeof(a[0]);//选择排序for (int i = 0; i < size; i++){for (int j = i + 1; j < size; j++){if (a[j] < a[i]){int temp = a[j];a[j] = a[i];a[i] = temp;}}}for (int num : a){cout << num << "\t";}cout << endl;cin.get();
}运行结果:
(2)冒泡排序
冒泡排序也是一种简单的排序算法。
它的基本原理是:重复地扫描要排序的数列,一次比较两个元素,如果它们的大小顺序错误,就把它们交换过来。这样,一次扫描结束,我们可以确保最大(小)的值被移动到序列末尾。这个算法的名字由来,就是因为越小的元素会经由交换,慢慢“浮”到数列的顶端。

#include<iostream>using namespace std;int main()
{int a[] = {2,5,8,4,9,1,6,3,7,0};//计算数组a的大小int size = sizeof(a) / sizeof(a[0]);//冒泡排序for (int i = 0; i < size; i++){for (int j = 0; j < size - i - 1; j++){if (a[j] > a[j + 1]){int temp = a[j + 1];a[j + 1] = a[j];a[j] = temp;}}}for (int num : a){cout << num << "\t";}cout << endl;cin.get();
}运行结果:

二、模板类vector
数组尽管很灵活,但使用起来还是很多不方便。为此,C++语言定义了扩展的“抽象数据类型”(Abstract Data Type,ADT),放在“标准库”中。
对数组功能进行扩展的一个标准库类型,就是“容器”vector。顾名思义,vector“容纳”着一堆数据对象,其实就是一组类型相同的数据对象的集合。
1、头文件和命名空间
vector是标准库的一部分。要想使用vector,必须在程序中包含<vector>头文件,并使用std命名空间。

在vector头文件中,对vector这种类型做了定义;使用#include引入它之后,并指定命名空间std之后,我们就可以在代码中直接使用vector了。
2、 vector的基本用法
vector其实是C++中的一个“类模板”,是用来创建类的“模子”。所以在使用时还必须提供具体的类型信息,也就是说,这个容器中到底要容纳什么类型的数据对象;具体的形式是在vector后面跟一个尖括号<>,里面填入具体类型信息。
![]()
#include<iostream>
#include<vector>using namespace std;int main()
{//默认初始化vector<int> v1; //定义了整型的容器,容器名:v1//列表初始化vector<char> v2 = { 'a','b','c' };vector<char> v3{ 'a','b','c' };//直接初始化vector<short> v4(5); //定义了大小为5的短整型容器vector<double> v5(5,100);//定义了大小为5的double容器,且每个值都为100//访问元素cout << v5[2] << endl;v5[2] = 666;cout << v5[2] << endl;//遍历所有元素for (int i = 0; i < v5.size(); i++){cout << v5[i] << "\t";}cout << endl;//添加元素v5.push_back(69);for (int num : v5){cout << num << "\t";}cout << endl;//向容器中添加倒序的元素for (int i = 10; i > 0; i--){v1.push_back(i);}//遍历容器v1for (int num : v1){cout << num << "\t";}cout << endl;cin.get();
}运行结果:

2、vector和数组的区别
数组是更加底层的数据类型;长度固定,功能较少,安全性没有保证;但性能更好,运行更高效;
vector是模板类,是数组的上层抽象;长度不定,功能强大;缺点是运行效率较低;
除了vector之外,C++ 11还新增了一个array模板类,它跟数组更加类似,长度是固定的,但更加方便、更加安全。所以在实际应用中,一般推荐对于固定长度的数组使用array,不固定长度的数组使用vector。
三、字符串
字符串我们并不陌生。之前已经介绍过,一串字符连在一起就是一个“字符串”,比如用双引号引起来的“Hello World !”就是一个字符串字面值。
字符串其实就是所谓的“纯文本”,就是各种文字、数字、符号在一起表达的一串信息;所以字符串就是C++中用来表达和处理文本信息的数据类型。
1、标准库类型string
C++的标准库中,提供了一种用来表示字符串的数据类型string,这种类型能够表示长度可变的字符序列。和 vector类似,Istring 类型也定义在命名空间std中,使用它必须包含string头文件。

(1)定义和初始化 string
我们已经接触过C++中几种不同的初始化方式, string 也是一个标准库类型,它的初始化与vector非常相似。
#include<iostream>
#include<string>using namespace std;int main()
{//初始化string s1;//拷贝初始化string s2 = s1;string s3 = "hello world";//直接初始化string s4("hello world");string s5(8, 'h');cout << s5 << endl;//访问字符cout << "s4[1] = " << s4[1] << endl;s4[0] = 'H';cout << s4 << endl;cin.get();
}运行结果:

字符串内字符的访问,跟vector内元素的访问类似,需要注意:
string内字符的索引,也是从o开始;
string 同样有一个成员函数size,可以获取字符串的长度;
索引最大值为字符串长度- 1),不能越界访问;如果直接越界访问并赋值,有可能导致非常严重的后果,出现安全问题;
如果希望遍历字符串的元素,也可以使用普通for 循环和范围for 循环,依次获取每个字符
#include<iostream>
#include<string>using namespace std;int main()
{//初始化string s1;//拷贝初始化string s2 = s1;string s3 = "hello world";//直接初始化string s4("hello world");string s5(8, 'h');cout << s5 << endl;//访问字符cout << "s4[1] = " << s4[1] << endl;s4[0] = 'H';cout << s4 << endl;//遍历for (int i = 0; i < s4.size(); i++){s4[i] = toupper(s4[i]); //toupper:小写转换大写}cout << s4 << endl;cin.get();
}运行结果:

(2)字符串相加
string本身的长度是不定的,可以通过“相加”的方式扩展一个字符串。

需要注意:
字符串相加使用加号“E”来表示,这是算术运算符“+”的运算符重载,含义是“字符串拼接”;
两个string对象,可以直接进行字符串相加;结果是将两个字符串拼接在一起,得到一个新的string对象返回;
一个string对象和一个字符串字面值常量,可以进行字符串相加,同样是得到一个拼接后的string对象返回;
两个字符串字面值常量,不能相加;
多个string 对象和多个字符串字面值常量,可以连续相加;前提是按照左结合律,每次相加必须保证至少有一个string对象;
(3)比较字符串

字符串比较的规则为:
如果两个字符串长度相同,每个位置包含的字符也都相同,那么两者“相等”;否则“不相等";
如果两个字符串在某一位置上开始不同,那么就比较这两个字符的 ASCIl码,比较结果就代表两个字符串的大小关系
如果两个字符串在某一位置上开始不同,那么就比较这两个字符的 ASCIl码,比较结果就代表两个字符串的大小关系
2、字符数组
通过对string的介绍可以发现,字符串就是一串字符的集合,本质上其实就是一个“字符的数组”。
在C语言中,确实是用char[]类型来表示字符串的;不过为了区分纯粹的“字符数组”和“字符串”,C语言规定:字符串必须以空字符结束。空字符的ASClI码为o,专门用来标记字符串的结尾,在程序中写作\0'。

#include<iostream>using namespace std;int main()
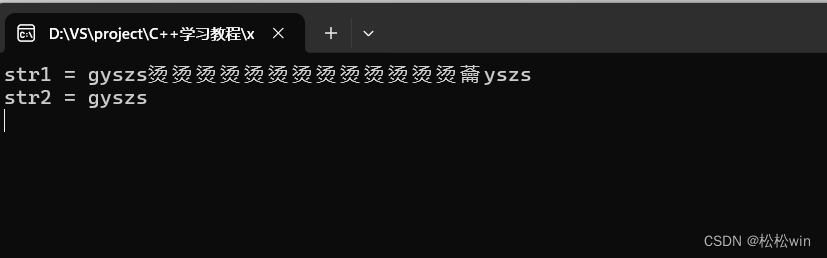
{char str1[5] = { 'g','y','s','z','s' };//str1不是一个字符串char str2[6] = { 'g','y','s','z','s','\0'};//str2是一个字符串cout << "str1 = " << str1 << endl;cout << "str2 = " << str2 << endl;cin.get();
}
运行结果:
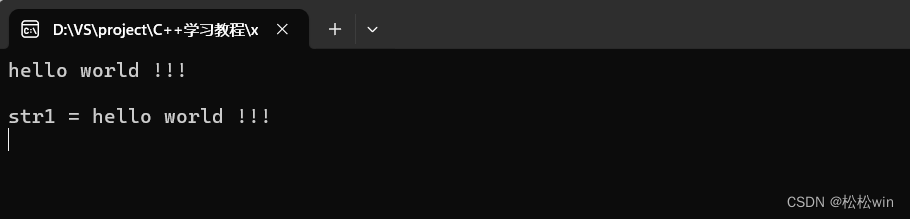
3、读取输入的字符串
(1)使用输入操作符读取单词
标准库中提供了iostream,可以使用内置的 cin对象,调用重载的输入操作符>>来读取键盘输入。

这种方式的特点是:忽略开始的空白符,遇到下一个空白符(空格、回车、制表等)就会停止。所以如果我们输入“"hello world”,那么读取给str的只有“hello"这相当于读取了一个“单词”。
剩下的内容“world”其实也没有丢,而是保存在了输入流的“输入队列”里。如果我们想读取更多的输入信息,就需要使用更多的string对象来获取:

(2〉使用getline读取一行
如果希望直接读取一整行输入信息,可以使用getline函数来替代输入操作符。

getline函数有两个参数:一个是输入流对象cin,另一个是保存字符串的string 对象;它会一直读取输入流中的内容,直到遇到换行符为止,然后把所有内容保存到string 对象中。所以现在可以完整读取一整行信息了。
#include<iostream>
#include<string>using namespace std;int main()
{//使用getline读取一行信息string str1;getline(cin, str1);cin.get();cout << "str1 = " << str1 << endl;cin.get();
}
运行结果:
(3)使用get读取字符
还有一种方法,是调用cin 的 get函数读取一个字符。

有两种方式:
调用cin.get()函数,不传参数,得到一个字符赋给char类型变量;
将char类型变量作为参数传入,将捕获的字符赋值给它,返回的是istream对象
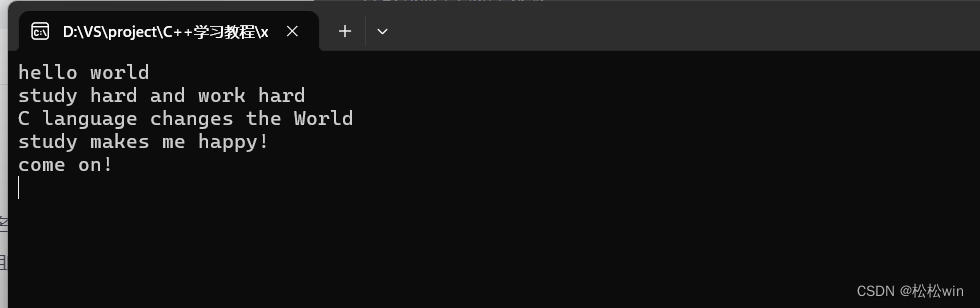
(4)读写文件
C++的lo库中提供了专门用于文件输入的 ifstream类和用于文件输出的ofstream类,要使用它们需要引入头文件 fstream。ifstream 用于读取文件内容,跟istream 的用法类似;也可以通过输入操作符>>来读“单词”(空格分隔),通过getline 函数来读取一行,通过get函数来读取一个字符:
#include<iostream>
#include<fstream>
#include<string>using namespace std;int main()
{ifstream input("1.txt"); //通过input对象来从文件中读取数据ofstream output("2.txt");//1.按照单词逐个读取/*string word;while (input >> word){cout << word << endl;}*///2.逐行读取string line;while (getline(input, line)){cout << line << endl;//output << line << endl;}cin.get();
}
运行结果:
四、结构体
C/C++中提供了另一种更加灵活的数据结构——结构体。结构体是用户自定义的复合数据结构,里面可以包含多个不同类型的数据对象。
1、结构体的定义和声明
声明一个结构体需要使用struct关键字,具体形式如下:

#include<iostream>using namespace std;//定义1个结构体
struct student
{string name;int age;double score;
};int main()
{//创建对象并初始化student s1 = { "ljl",18,99 };cin.get();
}
2、访问结构体中数据
访问结构体变量中的数据成员,可以使用成员运算符点号.),后面跟上数据成员的名称。例如stu.name就可以访问stu对象的name成员。

#include<iostream>using namespace std;//定义1个结构体
struct student
{string name;int age;double score;
};//输出一个数据对象的完整信息
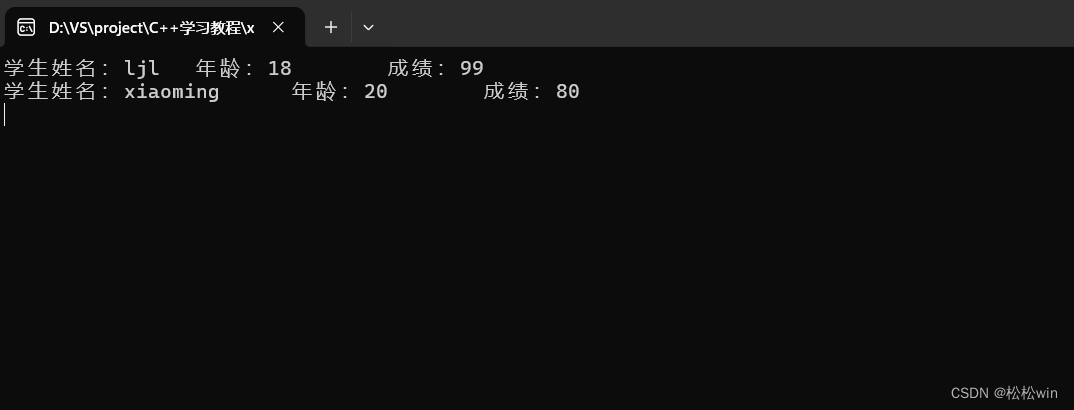
void pintinfo(student s)
{//访问数据cout << "学生姓名:" << s.name << "\t年龄:" << s.age << "\t成绩:" << s.score << endl;
}int main()
{//创建对象并初始化student s1 = { "ljl",18,99 };student s2;s2.age = 20;s2.name = "xiaoming";s2.score = 80;pintinfo(s1);pintinfo(s2);cin.get();
}
运行结果:
3、结构体数组
可以把结构体和数组结合起来,创建结构体的数组。顾名思义,结构体数组就是元素为结构体的数组,它的定义和访问跟普通的数组完全一样。

#include<iostream>using namespace std;//定义1个结构体
struct student
{string name;int age;double score;
};//输出一个数据对象的完整信息
void pintinfo(student s)
{//访问数据cout << "学生姓名:" << s.name << "\t年龄:" << s.age << "\t成绩:" << s.score << endl;
}int main()
{//创建对象并初始化student s1 = { "ljl",18,99 };student s2;s2.age = 20;s2.name = "xiaoming";s2.score = 80;pintinfo(s1);pintinfo(s2);//结构体数组student s3[3] = {{"小王",18,88},{"小张",19,66},{"小钱",20,99}};pintinfo(s3[0]);cin.get();
}
运行结果:

五、枚举
枚举类型的定义和结构体非常像,需要使用enum关键字。

与结构体不同的是,枚举类型内只有有限个名字,它们都各自代表一个常量,被称为“枚举量”。
需要注意的是:
默认情况下,会将整数值赋给枚举量;
枚举量默认从0开始,每个枚举量依次加1;所以上面week枚举类型中,一周七天枚举量分别对应着0~6的常量值;
可以通过对枚举量赋值,显式地设置每个枚举量的值;
#include<iostream>using namespace std;//定义1个枚举类型
enum Week {Mon, Tue, Wed, Thu, Fri, Sta, Sun
};int main()
{Week w1 = Mon, w2 = Tue;cout << "w1 = " << w1 << endl;cout << "w2 = " << w2 << endl;cin.get();
}
运行结果:

六、指针 ---存放是地址
指针顾名思义,是“指向”另外一种数据类型的复合类型。指针是C/C++中一种特殊的数据类型,它所保存的信息,其实是另外一个数据对象在内存中的“地址”。通过指针可以访问到指向的那个数据对象,所以这是一种间接访问对象的方法。

1、指针的定义

这里的类型就是指针所指向的数据类型,后面加上星号“*”,然后跟指针变量的名称。指针在定义的时候可以不做初始化。相比一般的变量声明,看起来指针只是多了一个星号“*”而已。例如:

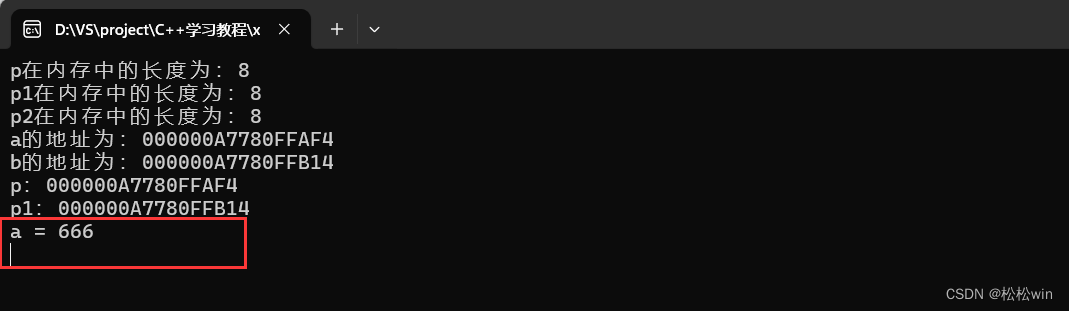
#include<iostream>using namespace std;int main()
{int* p;long* p1;long long* p2;cout << "p在内存中的长度为:" << sizeof(p) << endl;cout << "p1在内存中的长度为:" << sizeof(p1) << endl;cout << "p2在内存中的长度为:" << sizeof(p2) << endl;cin.get();
}
运行结果:

指针在64位系统下占据8个字节,在32位系统下占4个字节。
2、指针的用法
(1)获取对象地址给指针赋值
指针保存的是数据对象的内存地址,所以可以用地址给指针赋值;获取对象地址的方式是使用“取地址操作符”((&)。
#include<iostream>using namespace std;int main()
{int* p;long* p1;long long* p2;cout << "p在内存中的长度为:" << sizeof(p) << endl;cout << "p1在内存中的长度为:" << sizeof(p1) << endl;cout << "p2在内存中的长度为:" << sizeof(p2) << endl;//指针的使用int a = 10;long b = 20;p = &a;p1 = &b;cout << "a的地址为:" << &a << endl;cout << "b的地址为:" << &b << endl;cout << "p:" << p << endl;cout << "p1:" << p1 << endl;cin.get();
}
运行结果:

(2)通过指针访问对象
指针指向数据对象后,可以通过指针来访问对象。访问方式是使用“解引用操作符”(*):

在这里由于p指向了a,所以*p可以等同于a。
#include<iostream>using namespace std;int main()
{int* p;long* p1;long long* p2;cout << "p在内存中的长度为:" << sizeof(p) << endl;cout << "p1在内存中的长度为:" << sizeof(p1) << endl;cout << "p2在内存中的长度为:" << sizeof(p2) << endl;//指针的使用int a = 10;long b = 20;p = &a;p1 = &b;cout << "a的地址为:" << &a << endl;cout << "b的地址为:" << &b << endl;cout << "p:" << p << endl;cout << "p1:" << p1 << endl;*p = 666;cout << "a = " << a << endl;cin.get();
}
运行结果:
3、无效指针、空指针和 void*指针
(1)无效指针
定义一个指针之后,如果不进行初始化,那么它的内容是不确定的(比如Oxcccc)。如果这时把它的内容当成一个地址去访问,就可能访问的是不存在的对象;更可怕的是,如果访问到的是系统核心内存区域,修改其中内容会导致系统崩溃。这样的指针就是“无效指针”,也被叫做“野指针”。

指针非常灵活非常强大,但野指针非常危险。所以建议使用指针的时候,一定要先初始化,让它指向真实的对象。
(2)空指针
如果先定义了一个指针,但确实还不知道它要指向哪个对象,这时可以把它初始化为“空指针”。空指针不指向任何对象。

(3)void* 指针
一般来说,指针的类型必须和指向的对象类型匹配,否则就会报错。不过有一种指针比较特殊,可以用来存放任意对象的地址,这种指针的类型是void*。
 4、指向指针的指针
4、指向指针的指针
指针本身也是一个数据对象,也有自己的内存地址。所以可以让一个指针保存另一个指针的地址,这就是“指向指针的指针”,有时也叫“二级指针”;形式上可以用连续两个的星号**来表示。类似地,如果是三级指针就是***,表示“指向二级指针的指针”。

#include<iostream>using namespace std;int main()
{int* p;long* p1;long long* p2;cout << "p在内存中的长度为:" << sizeof(p) << endl;cout << "p1在内存中的长度为:" << sizeof(p1) << endl;cout << "p2在内存中的长度为:" << sizeof(p2) << endl;//指针的使用int a = 10;long b = 20;p = &a;p1 = &b;cout << "a的地址为:" << &a << endl;cout << "b的地址为:" << &b << endl;cout << "p:" << p << endl;cout << "p1:" << p1 << endl;*p = 666;cout << "a = " << a << endl;cout << "--------------------------------" << endl;//二级指针int i = 100;int* pi = &i;int** ppi = πcout << "i = " << i << endl;cout << "pi = " << pi << endl;cout << "ppi = " << ppi << endl;cout << "*pi = " << *pi << endl;cout << "*ppi = " << *ppi << endl;cout << "**ppi = " << **ppi << endl;cin.get();
}
运行结果:

5、指针和const
指针可以和 const 修饰符结合,这可以有两种形式:一种是指针指向的是一个常量;另一种是指针本身是一个常量。
(1)指向常量的指针
指针指向的是一个常量,所以只能访问数据,不能通过指针对数据进行修改。不过指针本身是变量,可以指向另外的数据对象。这时应该把const加在类型前。

这里发现,pc是一个指向常量的指针,但其实把一个变量i的地址赋给它也是可以的;编译器只是不允许通过指针pc去间接更改数据对象。
(2)指针常量(const 指针)
指针本身是一个数据对象,所以也可以区分变量和常量。如果指针本身是一个常量,就意味它保存的地址不能更改,也就是它永远指向同一个对象;而数据对象的内容是可以通过指针改变的。这种指针一般叫做“指针常量”。
指针常量在定义的时候,需要在星号*后、标识符前加上 const。

6、指针和数组
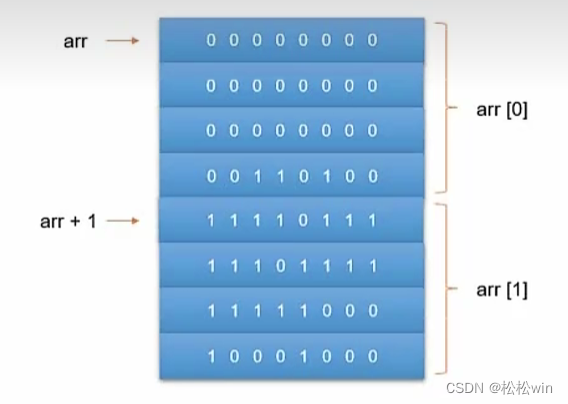
(1)数组名
用到数组名时,编译器一般都会把它转换成指针,这个指针就指向数组的第一个元素。所以我们也可以用数组名来给指针赋值。

运行结果:
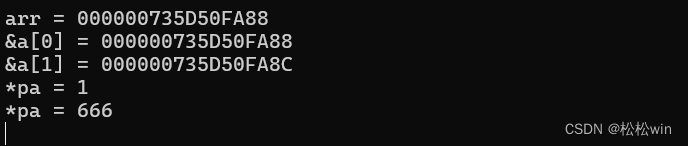
(2)指针运算
如果对指针pia 做加1操作,我们会发现它保存的地址直接加了4,这其实是指向了下一个int类型数据对象:

所谓的“指针运算”,就是直接对一个指针加/减一个整数值,得到的结果仍然是指针。新指针指向的数据元素,跟原指针指向的相比移动了对应个数据单位。
(3)指针数组和数组指针
指针和数组这两种类型可以结合在一起,这就是“指针数组”和“数组指针”。
指针数组:一个数组,它的所有元素都是相同类型的指针;
数组指针:一个指针,指向一个数组的指针;

运行结果:

七、引用
1、引用的用法
在做声明时,我们可以在变量名前加上“&”符号,表示它是另一个变量的引用。引用必须被初始化。
#include<iostream>using namespace std;int main()
{int a = 888, b = 666;int& ref = a;cout << "ref = " << ref << endl;cout << "a的地址为: " << &a << endl;cout << "ref的地址为: " << &ref << endl;cin.get();
}
运行结果:

引用本质上就是一个“别名”,它本身不是数据对象,所以本身不会存储数据,而是和初始值“绑定”(bind)在一起,绑定之后就不能再绑定别的对象了。
2、对常量的引用
可以把引用绑定到一个常量上,这就是“对常量的引用”。很显然,对常量的引用是常量的别名,绑定的对象不能修改,所以也不能做赋值操作:

对常量的引用有时也会直接简称“常量引用”。因为引用只是别名,本身不是数据对象;所以这只能代表“对一个常量的引用”,而不会像“常量指针”那样引起混淆。
常量引用和普通变量的引用不同,它的初始化要求宽松很多,只要是可以转换成它指定类型的所有表达式,都可以用来做初始化。

3、指针和引用
(1)引用和指针常量
事实上,引用的行为,非常类似于“指针常量”,也就是只能指向唯一的对象、不能更改的指针。
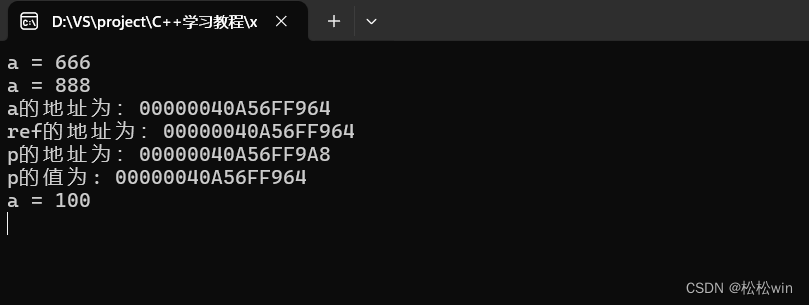
#include<iostream>using namespace std;int main()
{int a = 66;//引用和指针常量int& ref = a;int* const p = &a;ref = 666;cout << "a = " << a << endl;*p = 888;cout << "a = " << a << endl;cout << "a的地址为:" << &a << endl;cout << "ref的地址为:" << &ref << endl;cout << "p的地址为:" << &p << endl;cout << "p的值为: " << p << endl;//绑定指针的引用int* ptr = &a;int*& pref = ptr; //pref是ptr指针的别名*ptr = 100;cout << "a = " << a << endl;cin.get();
}
运行结果:
八、函数
8.1、函数的定义
一个完整的函数定义主要包括以下部分:
返回类型:调用函数之后,返回结果的数据类型;
函数名:用来命名代码块的标识符,在当前作用域内唯一;
参数列表:参数表示函数调用时需要传入的数据,一般叫做“形参”;放在函数名后的小括号里,可以有o个或多个,用逗号隔开;
函数体:函数要执行的语句块,用花括号括起来。
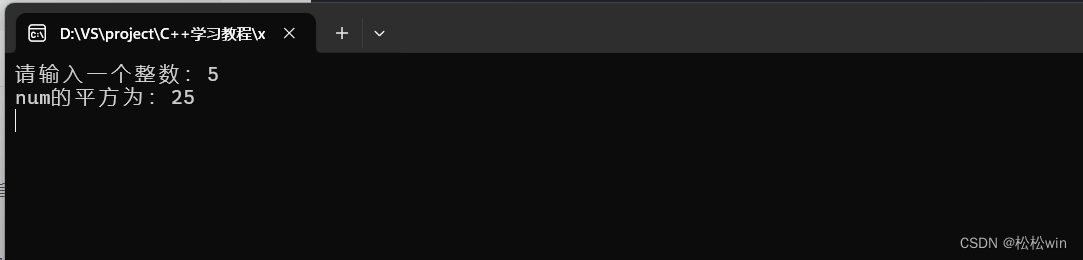
#include<iostream>using namespace std;//定义一个平方函数
int square(int x)
{int y = x * x;return y;
}int main()
{cout << "请输入一个整数:";int num;cin >> num;cin.get();cout << "num的平方为:" << square(num) << endl;cin.get();
}运行结果:
8.1.2、局部变量的生命周期
对于花括号内定义的变量,具有“块作用域”,在花括号外就不可见了。函数体都是语句块,而主函数main本身也是一个函数;所以在main 中定义的所有变量、所有函数形参和在函数体内部定义的变量,都具有块作用域,统称为“局部变量”。局部变量仅在函数作用域内部可见。

在C++中,作用域指的是变量名字的可见范围;变量不可见,并不代表变量所指代的数据对象就销毁了。这是两个不同的概念:
作用域:针对名字而言,是程序文本中的一部分,名字在这部分可见;
生命周期:针对数据对象而言,是程序在执行过程中,对象从创建到销毁的时间段
基于作用域,变量可以分为“局部变量”和“全局变量”。对于全局变量而言,名字全局可见,对象也只有在程序结束时才销毁。
而对于局部变量代表的数据对象,基于生命周期,又可以分为“自动对象”和“静态对象”。
(1)自动对象
平常代码中定义的普通局部变量,生命周期为:在程序执行到变量定义语句时创建,在程序运行到当前块末尾时销毁。这样的对象称为“自动对象”。
形参也是一种自动对象。形参定义在函数体作用域内,一旦函数终止,形参也就被销毁了。
对于自动对象来说,它的生命周期和作用域是一致的。
(2)静态对象
如果希望延长一个局部变量的生命周期,让它在作用域外依然保留,可以在定义局部变量时加上static关键字;这样的对象叫做“局部静态对象”。
局部静态对象只有局部的作用域,在块外依然是不可见的;但是它的生命周期贯穿整个程序运行过程,只有在程序结束时才被销毁,这一点与全局变量类似。
8.1.3、分离式编译和头文件
(1)分离式编译
当程序越来越复杂,我们就会希望代码分散到不同的文件中来做管理。C++支持分离式编译,这就可以把函数单独放在一个文件,独立编译之后链接运行。
比如可以把复制字符串的函数单独保存成一个文件 copy_string.cpp:
(2)编写头文件
对于一个项目而言,有些定义可能是所有文件共用的,比如一些常量、结构体/类,以及功能性的函数。于是每次需要引入时,都得做一堆声明——这显然太麻烦了。
一个好方法是,把它们定义在同一个文件中,需要时用一句#include 统一引入就可以了,就像使用库一样。这样的文件以.h作为后缀,被称为“头文件”。
8.2、参数传递
参数传递和变量的初始化类似,根据形参的类型可以分为两种方式:传值(value)和传引用(reference)。


8.2.1、传引用参数
(1)传引用方便函数调用
C++新增了引用的概念,可以替换必须使用指针的场景。采用引用作为函数形参,可以使函数调用更加方便。这种传参方式叫做“传引用参数”。之前的例子就可以改写成:
#include<iostream>using namespace std;//使用引用作为形参
void increase(int& x)
{++x;
}int main()
{int num = 0;increase(num);cout << "num = " << num << endl;cin.get();
}运行结果:

(2)传引用避免拷贝
使用引用还有一个非常重要的场景,就是不希望进行值拷贝的时候。实际应用中,很多时候函数要操作的对象可能非常庞大,如果做值拷贝会使得效率大大降低;这时使用引用就是一个好方法。
比如,想要定义一个函数比较两个字符串的长度,需要将两个字符串作为参数传入。因为字符串有可能非常长,直接做值拷贝并不是一个好选择,最好的方式就是传递引用:

8.2.2、数组形参
数组是不允许做直接拷贝的,所以如果想要把数组作为函数的形参,使用值传递的方式是不可行的。与此同时,数组名可以解析成一个指针,所以可以用传递指针的方式来处理数组。|
比如一个简单的函数,需要遍历int类型数组所有元素并输出,就可以这样声明:

#include<iostream>using namespace std;//遍历数组
void printArray(const int* arr, int size)
{for (int i = 0; i < size; i++){cout << arr[i] << "\t";}cout << endl;
}int main()
{int arr[5] = { 1,2,3,4,5 };printArray(arr, 5);cin.get();
}运行结果:

8.2.3、数组引用作为形参
#include<iostream>using namespace std;//遍历数组
void printArray(const int* arr, int size)
{for (int i = 0; i < size; i++){cout << arr[i] << "\t";}cout << endl;
}void printArray(const int(& arr)[5])
{for (int num : arr){cout << num << "\t";}cout << endl;
}int main()
{int arr[5] = { 1,2,3,4,5 };printArray(arr, 5);printArray(arr);cin.get();
}运行结果:
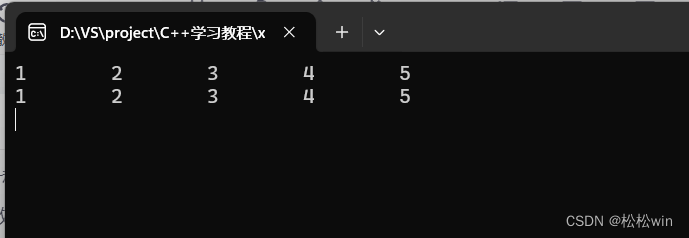
8.3.1、无返回值
#include<iostream>using namespace std;void swap(int& x, int& y)
{int temp = x;x = y;y = temp;
}int main()
{int a = 66, b = 88;swap(a, b);cout << "a = " << a << endl;cout << "b = " << b << endl;cin.get();
}运行结果:

8.3.2、有返回值
#include<iostream>using namespace std;void swap(int& x, int& y)
{int temp = x;x = y;y = temp;
}//有返回值的函数,返回较长的字符串
string longstr(const string& str1, const string& str2)
{return str1.size() >= str2.size() ? str1 : str2;
}int main()
{int a = 66, b = 88;swap(a, b);cout << "a = " << a << endl;cout << "b = " << b << endl;string str1 = "hello";string str2 = "hello world";cout << longstr(str1, str2) << endl;cin.get();
}运行结果:

8.3.3、返回数组指针

这里对于函数fun的声明,我们可以进行层层解析:
fun(int x):函数名为fun,形参为int类型的x;
(*fun(int 炳 ):函数返回的结果,可以执行解引用操作,说明是一个指针;
( *fun(int x))[5]:函数返回结果解引用之后是一个长度为5的数组,说明返回类型是数组指针;
int ( * fun(int x) )[5]:数组中元素类型为int

九、递归
如果一个函数调用了自身,这样的函数就叫做“递归函数”(recursivefunction)。
1、递归的实现
递归是调用自身,如果不加限制,这个过程是不会结束的;函数永远调用自己下去,最终会导致程序栈空间耗尽。所以在递归函数中,一定会有某种“基准情况”,这个时候不会调用自身,而是直接返回结果。基准情况的处理保证了递归能够结束。|
递归是不断地自我重复,这一点和循环有相似之处。事实上,递归和循环往往可以实现同样的功能。
#include<iostream>using namespace std;//用递归实现阶乘
int factorial(int n)
{if (n == 1)return 1;return factorial(n - 1) * n;
}int main()
{cout << "5! = " << factorial(5) << endl;cin.get();
}运行结果:
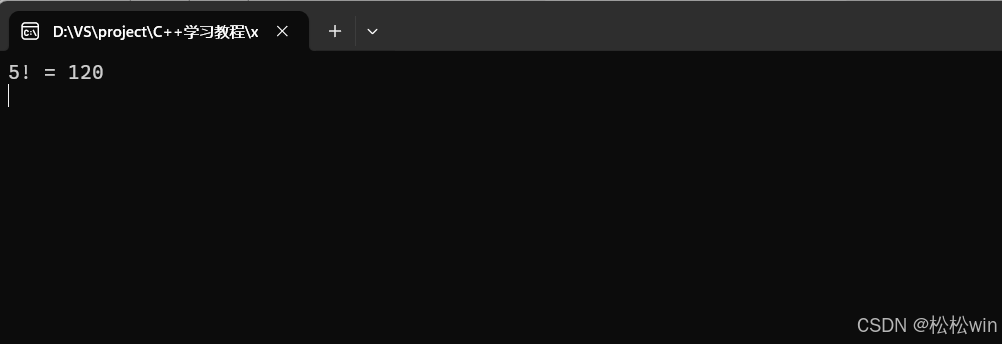
这里我们的基准情况是n ==1,也就是当n不断减小,直到1时就结束递归直接返回。5的阶乘具体计算流程如下:

因为递归至少需要额外的栈空间开销,所以递归的效率往往会比循环低一些。不过在很多数学问题上,递归可以让代码非常简洁。
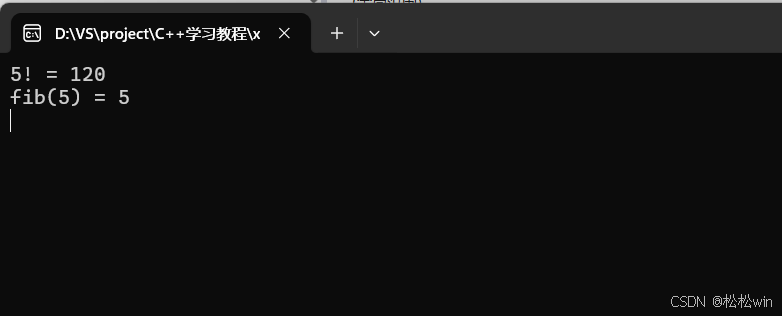
2、经典递归-------斐波那契数列

#include<iostream>using namespace std;//用递归实现阶乘
int factorial(int n)
{if (n == 1)return 1;return factorial(n - 1) * n;
}//斐波那契数列
int fib(int n)
{if (n == 1 || n == 2)return 1;return fib(n - 1) + fib(n - 2);
}int main()
{cout << "5! = " << factorial(5) << endl;cout << "fib(5) = " << fib(5) << endl;cin.get();
}运行结果:
十、函数高阶
1、内联函数
内联函数是C++为了提高运行速度做的一项优化。
函数让代码更加模块化,可重用性、可读性大大提高;不过函数也有一个缺点:函数调用需要执行一系列额外操作,会降低程序运行效率。
为了解决这个问题,C++引入了“内联函数”的概念。使用内联函数时,编译器不再去做常规的函数调用,而是把它在调用点上“内联”展开,也就是直接用函数代码替换了函数调用。
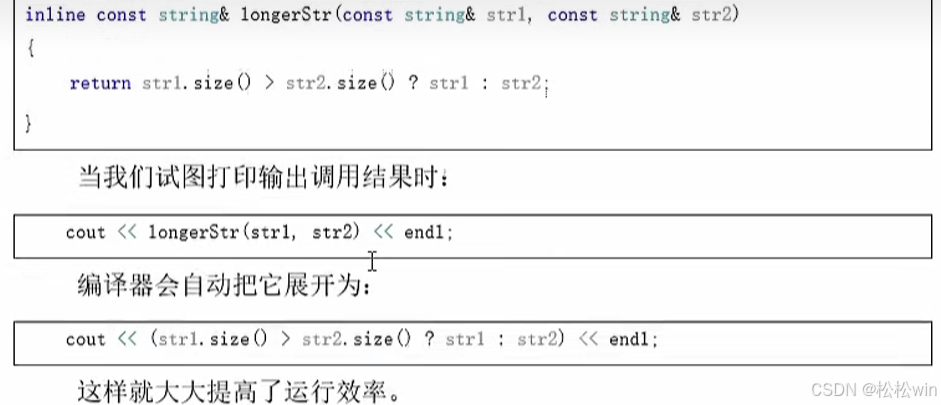
1.1内联函数的定义
定义内联函数,只需要在函数声明或者函数定义前加上 inline关键字。
1.2内联函数和宏
内联函数是C++新增的特性。在C语言中,类似功能是通过预处理语句和#define定义“宏”来实现的。
然而c中的宏本身并不是函数,无法进行值传递;它的本质是文本替换,我们一般只用宏来定义常量。用宏实现函数的功能会比较麻烦,而且可读性较差。所以在C++中,一般都会用内联函数来取代C中的宏。
2、函数重载
在C++中,同一作用域下,同一个函数名是可以定义多次的,前提是形参列表不同。这种名字相同但形参列表不同的函数,叫做“重载函数”。这是C++相对c语言的重大改进,也是面向对象的基础。
2.1定义重装函数
重载的函数,应该在形参的数量或者类型上有所不同;
形参的名称在类型中可以省略,所以只有形参名不同的函数是一样的;
调用函数时,编译器会根据传递的实参个数和类型,自动推断使用哪个函数;
主函数不能重载
2.2函数匹配

确定到底调用哪个函数的过程,叫做“函数匹配”。

#include<iostream>using namespace std;void f() { cout << "1" << endl; }
void f(int x) { cout << "2" << endl; }
void f(int x, int y) { cout << "3" << endl; }
void f(double x, double y = 1.5) { cout << "4" << endl; }int main()
{f(3.14);cin.get();
}运行结果:



2.3函数重装和作用域
重载是否生效,跟作用域是有关系的。如果在内层、外层作用域分别声明了同名的函数,那么内层作用域中的函数会覆盖外层的同名实体,让它隐藏起来。
不同的作用域中,是无法重载函数名的。
3、函数指针
一类特殊的指针,指向的不是数据对象而是函数,这就是“函数指针”
3.1声明函数指针
函数指针本质还是指针,它的类型和所指向的对象类型有关。现在指向的是函数,函数的类型是由它的返回类型和形参类型共同决定的,跟函数名、形参名都没有关系。

3.2使用函数指针
当一个函数名后面跟调用操作符(小括号),表示函数调用;而单独使用函数名作为一个值时,函数会自动转换成指针。这一点跟数组名类似。
所以我们可以直接使用函数名给函数指针赋值:

也可以加上取地址符&,这和不加&是等价的。
3.3函数指针作为形参
有了指向函数的指针,就给函数带来了更加丰富灵活的用法。比如,可以将函数指针作为形参,定义在另一个函数中。也就是说,可以定义一个函数,它以另一个函数类型作为形参。当然,函数本身不能作为形参,不过函数指针完美地填补了这个空缺。这一点上,函数跟数组非常类似。
3.4函数指针作为返回值

相关文章:
C++学习全教程(Day2)
一、数组 在程序中为了处理方便,常常需要把具有相同类型的数据对象按有序的形式排列起来,形成“一组”数据,这就是“数组”(array) 数组中的数据,在内存中是连续存放的,每个元素占据相同大小的空间,就像排…...

Transformer详解encoder
目录 1. Input Embedding 2. Positional Encoding 3. Multi-Head Attention 4. Add & Norm 5. Feedforward Add & Norm 6.代码展示 (1)layer_norm (2)encoder_layer1 最近刚好梳理了下transformer,今…...

ISO 19110操作要求类/req/operation/signature的详细解释
/req/operation/signature 要求: 每个要素操作实体必须有且仅有一个在要素目录范围内唯一的“signature”属性。 附注: 签名(signature)指定了操作的名称和调用该操作所需的参数名称。 具体解释 定义 要素操作实体(feature operation …...

理解GPT2:无监督学习的多任务语言模型
目录 一、背景与动机 二、卖点与创新 三、几个问题 四、具体是如何做的 1、更多、优质的数据,更大的模型 2、大数据量,大模型使得zero-shot成为可能 3、使用prompt做下游任务 五、一些资料 一、背景与动机 基于 Transformer 解码器的 GPT-1 证明…...

深度学习11-20
1.神经元的个数对结果的影响: (http://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html) (1)神经元3个的时候 (2)神经元是10个的时候 神经元个数越多,可能会产生…...

耐磨材料元宇宙:探索未来科技的无限可能
随着科技的不断发展,我们正逐渐进入一个全新的时代——元宇宙。在这个虚拟世界中,人们可以自由地创造、探索和交流。而在元宇宙中,耐磨材料作为一种重要的基础资源,将为我们的虚拟世界带来更多的可能性。 一、耐磨材料在元宇宙中…...

力扣2874.有序三元组中的最大值 II
力扣2874.有序三元组中的最大值 II 遍历j –> 找j左边最大数 和右边最大数 class Solution {public:long long maximumTripletValue(vector<int>& nums) {int n nums.size();vector<int> suf_max(n1,0);//右边最大数for(int in-1;i>1;i--){suf_max[i…...

Linux-笔记 嵌入式gdb远程调试
目录 前言 实现 1、内核配置 2、GDB移植 3、准备调试程序 4、开始调试 前言 gdb调试器是基于命令行的GNU项目调试器,通过gdb工具我们可以实现许多调试手段,同时gdb支持多种语言,兼容性很强。 在桌面 Linux 系统(如 Ubuntu、Cent…...

观测云产品更新 | Pipelines、智能监控、日志数据访问等
观测云更新 Pipelines 1、Pipelines:支持选择中心 Pipeline 执行脚本。 2、付费计划与账单:新增中心 Pipeline 计费项,统计所有命中中心 Pipeline 处理的原始日志的数据大小。 监控 1、通知对象管理:新增权限控制。配置操作权…...

docker 拉取不到镜像的问题:拉取超时
如果每次拉取的时候遇到超时 error pulling image configuration: download failed after attempts6: dial tcp 31.13.94.10:443: i/o timeout 解决方法如下: 设置国内镜像源: sudo mkdir -p /etc/docker 然后 sudo gedit /etc/docker/daemon.json 或…...
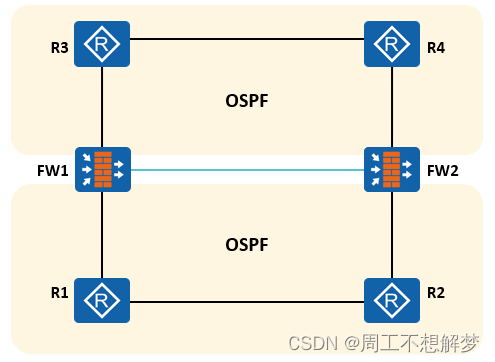
防火墙双机热备
防火墙双机热备 随着移动办公、网上购物、即时通讯、互联网金融、互联网教育等业务蓬勃发展,网络承载的业务越来越多,越来越重要。所以如何保证网络的不间断传输成为网络发展过程中急需解决的一个问题。 防火墙部署在企业网络出口处,内外网之…...

30分钟学习如何搭建扩散模型的运行环境【pytorch版】【B站视频教程】【解决环境搭建问题】
30分钟学习如何搭建扩散模型的运行环境【B站视频教程】【解决环境搭建问题】 动手学习扩散模型 点击以下链接即可进入学习: B站视频教程附赠:环境配置安装(配套讲解文档) 视频 讲解主要内容 一、环境设置 1.本地安装…...
)
使用Java连接数据库并且执行数据库操作和创建用户登录图形化界面(1)
创建一个Java程序,建立与本机mysql服务器上student数据库的连接,实现在tb_student学生表上插入一条学生信息:学号21540118,姓名王五,性别男,出生日期2003-12-10,所在学院5。 使用JDBC连接数据库…...

HarmonyOS Next开发学习手册——弹性布局 (Flex)
概述 弹性布局( Flex )提供更加有效的方式对容器中的子元素进行排列、对齐和分配剩余空间。常用于页面头部导航栏的均匀分布、页面框架的搭建、多行数据的排列等。 容器默认存在主轴与交叉轴,子元素默认沿主轴排列,子元素在主轴…...
centOS7网络配置_NAT模式设置
第一步:查看电脑网卡 nat模式对应本地网卡的VMnet 8 ,查看对应的IP地址。 第二步:虚拟网络编辑器 打开VMWare,编辑--虚拟网络编辑器,整个都默认设置好了,只需要查看对应的DHCP设置中对应的IP的起始&#…...

喜报 | 极限科技获得北京市“创新型”中小企业资格认证
2024年6月20日,北京市经济和信息化局正式发布《关于对2024年度4月份北京市创新型中小企业名单进行公告的通知》,极限数据(北京)科技有限公司凭借其出色的创新能力和卓越的企业实力,成功获得“北京市创新型中小企业”的…...

整合Spring Boot和Pulsar实现可扩展的消息处理
整合Spring Boot和Pulsar实现可扩展的消息处理 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在现代分布式系统中,消息队列是实现异步通信和解耦…...
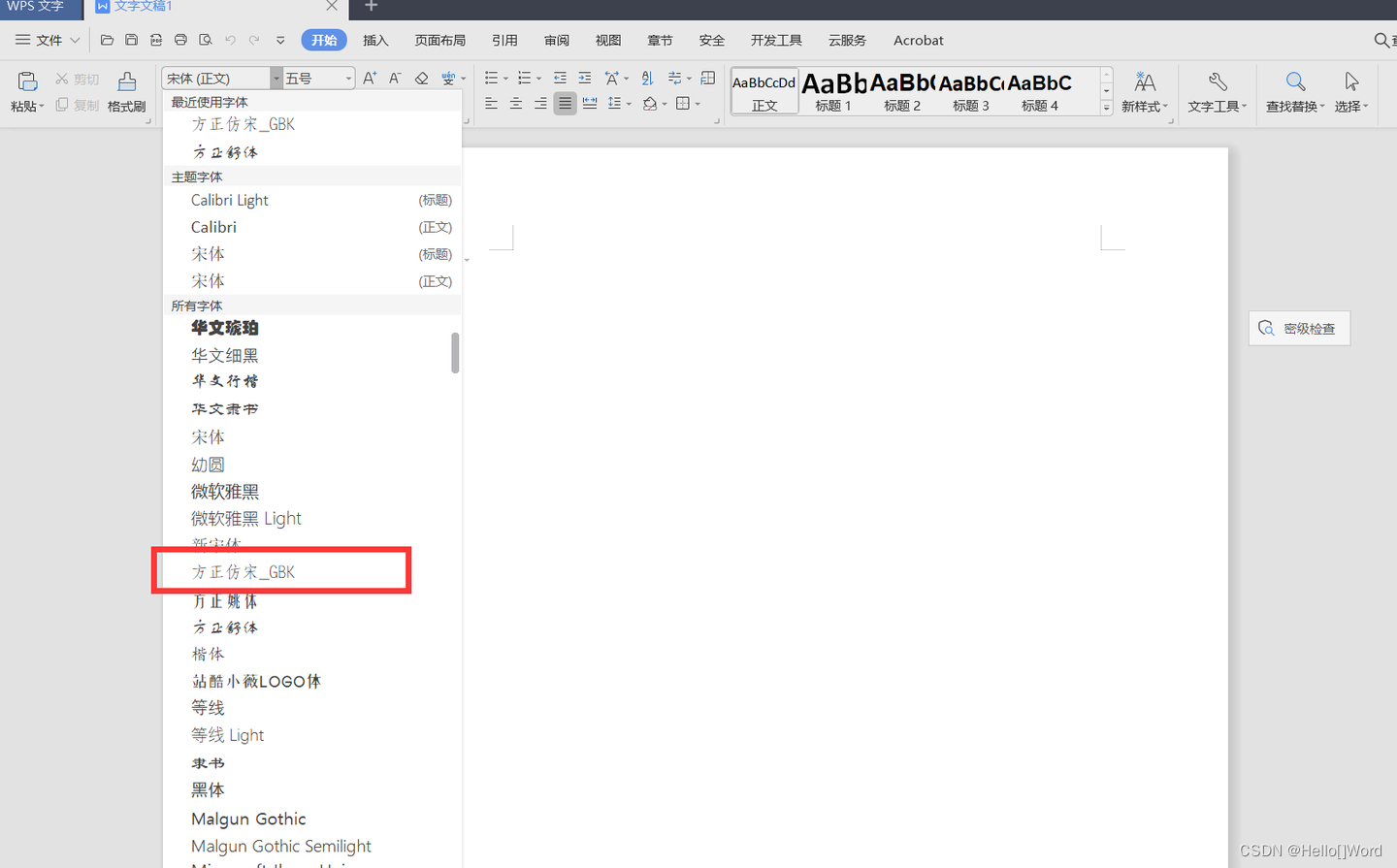
如何给WPS、Word、PPT等办公三件套添加收费字体---方正仿宋GBK
1.先下载需要的字体。 下载字体的网站比较多,基本上都是免费的。随便在网上搜索一个就可以了,下面是下载的链接。 方正仿宋GBK字体免费下载和在线预览-字体天下 www.fonts.net.cn/font-31602268591.html 注意:切记不要商用,以免…...
《重构》读书笔记【第1章 重构,第一个示例,第2章 重构原则】
文章目录 第1章 重构,第一个示例1.1 重构前1.2 重构后 第2章 重构原则2.1 何谓重构2.2 两顶帽子2.3 为何重构2.4 何时重构2.5 重构和开发过程 第1章 重构,第一个示例 我这里使用的IDE是IntelliJ IDEA 1.1 重构前 plays.js export const plays {&quo…...
学会整理电脑,基于小白用户(无关硬件升级)
如果你不想进行硬件升级,就要学会进行整理维护电脑 基于小白用户,每一个操作点我都会在后续整理出流程,软件推荐会选择占用小且实用的软件 主要从三个角度去讨论【如果有新的内容我会随时修改,也希望有补充告诉我,我…...
配时钟,实测24MHz APIS_SLOW_CLK怎么设)
S32K3开发避坑:用EB tresos给GPT定时器(PIT)配时钟,实测24MHz APIS_SLOW_CLK怎么设
S32K3开发实战:EB tresos中GPT定时器时钟配置深度解析 引言 在嵌入式系统开发中,精确的定时器配置往往是项目成功的关键因素之一。对于使用NXP S32K3系列MCU的开发者而言,EB tresos工具链提供了强大的MCAL配置能力,但同时也带来了…...
)
为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败?——2024最新L10n兼容性白皮书首发(附实测RTT延迟对比数据)
更多请点击: https://intelliparadigm.com 第一章:为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败? ElevenLabs 官方文档明确声明支持僧伽罗文(Sinhala),但实际部署中,斯里兰卡本地政…...
告别‘鬼影重重’:ENVI Pixel Based Mosaicking工具处理无坐标影像的完整流程与色彩均衡技巧
告别‘鬼影重重’:ENVI Pixel Based Mosaicking工具处理无坐标影像的完整流程与色彩均衡技巧 在遥感影像处理领域,影像镶嵌是基础却至关重要的环节。当面对多源、无坐标的影像数据时,传统的地理参考镶嵌工具往往束手无策,而ENVI的…...

RimWorld模组管理终极指南:如何用RimSort轻松解决模组冲突问题
RimWorld模组管理终极指南:如何用RimSort轻松解决模组冲突问题 【免费下载链接】RimSort RimSort is an open source mod manager for the video game RimWorld. There is support for Linux, Mac, and Windows, built from the ground up to be a reliable, commun…...

动力电池技术迭代:从能量密度到系统集成的多维竞争
1. 动力电池行业的“肌肉”意味着什么最近,行业里关于宁德时代又推出新产品的消息传得沸沸扬扬。作为在这个行业里摸爬滚打了十几年的老兵,每次看到这样的新闻,我的第一反应不是“又来了”,而是“这次他们想解决什么问题ÿ…...

Kubernetes 安全加固清单:从 RBAC 到 etcd 加密的生产实践
在云原生时代,Kubernetes 已成为容器编排的事实标准,但默认配置下的 K8s 并不安全。一次错误的 RBAC 权限配置、一个暴露的 etcd 端口、或者一个特权模式的 Pod,都可能成为攻击者的入口。本文从认证授权、Pod 安全、网络隔离、数据加密四个维…...

矩阵中的“对角线强迫症”:如何优雅地判断Toeplitz矩阵?
举个栗子 🌰 例子1: 矩阵: [6, 7, 8] [4, 6, 7] [1, 4, 6]它的对角线分别是:[6,6,6], [7,7], [8], [4,4], [1],每条对角线上的数字都相同,所以它是Toeplitz矩阵 ✅ 例子2: 矩阵: …...

2026 免费GEO监测:AI搜索优化实用工具推荐
2026年AI搜索优化(GEO)已经成为企业数字营销的核心环节。当前GEO工具市场呈现明显的国内外分化格局,国内工具和海外工具在功能支持、适用场景上存在巨大差异。本文选取目前市场上主流的5款GEO工具,从功能完整性、AI模型支持、易用…...
如何快速掌握终极鼠标悬停翻译神器:MouseTooltipTranslator完整使用指南
如何快速掌握终极鼠标悬停翻译神器:MouseTooltipTranslator完整使用指南 【免费下载链接】MouseTooltipTranslator Mouseover Translate Any Language At Once - Chrome Extension: PDF Translator, EBOOK, EPUB, OCR, TTS, NETFLIX, YOUTUBE DUAL SUBTITLES, GOOGL…...

【M1 Mac实战】MATLAB R2021b 安装与优化全攻略
1. M1 Mac安装MATLAB R2021b前的准备工作 第一次在M1芯片的Mac上安装MATLAB R2021b时,我遇到了不少坑。这里分享下必须做好的几项准备工作,能帮你节省至少2小时的折腾时间。 首先确认你的系统版本。实测在macOS Monterey(12.0)到V…...