scatterlist的相关概念与实例分析
概念
scatterlist
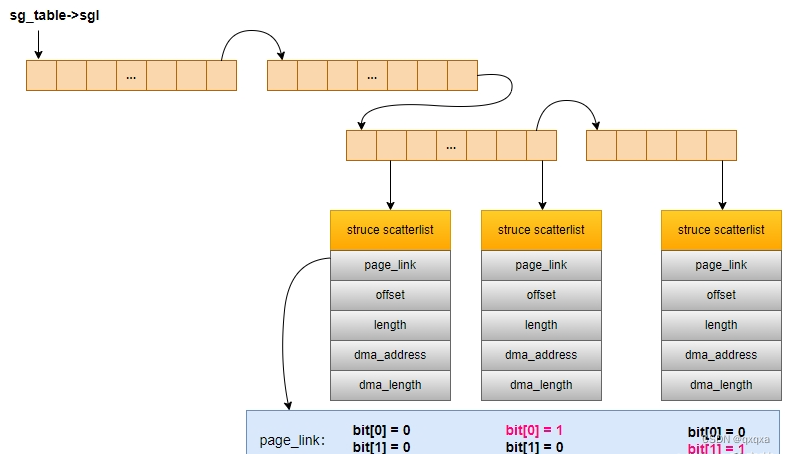
scatterlist用来描述一块内存,sg_table一般用于将物理不同大小的物理内存链接起来,一次性送给DMA控制器搬运
struct scatterlist {unsigned long page_link; //指示该内存块所在的页面unsigned int offset; //指示该内存块在页面中的偏移(起始位置)unsigned int length; //该内存块的长度dma_addr_t dma_address; //该内存块实际的物理起始地址
#ifdef CONFIG_NEED_SG_DMA_LENGTHunsigned int dma_length; //相应的长度信息
#endif
};page_link:
(1).对于chain sg 来说,记录下一个 SG 数组的首地址,并且用bit[0] 和 bit[1] 来表示是chain sg 还是 end sg;
(2).对于 end sg 来说,只有bit[1] 为1,其他无意义;
(3).对于普通 sg 来说,记录的是关联的内存页块的地址;
sg_table
既然链接起物理内存,那么就需要多个sg;内核给了个sg_table和一系列api便于操作sg;
struct sg_table {struct scatterlist *sgl; /* the list */unsigned int nents; //实际的内存块映射数量unsigned int orig_nents; ///内存块映射的数量
};sg_alloc_table一次可以分配page size / sizeof(scatterlist)个scatterlist结构体;如果超过这个数,就需要再通过sg_alloc_table分配scatterlist,并且通过sg_chain()来连接上一个sg_table和新的sg_table
sg_alloc_table
sg_kmalloc用以批量分配 sg 的内存;G_MAX_SINGLE_ALLOC:系统规定了每次sg_kmalloc的最大个数为4096/32 = 128个
int sg_alloc_table(struct sg_table *table, unsigned int nents, gfp_t gfp_mask)
{int ret;ret = __sg_alloc_table(table, nents, SG_MAX_SINGLE_ALLOC,NULL, 0, gfp_mask, sg_kmalloc);if (unlikely(ret))__sg_free_table(table, SG_MAX_SINGLE_ALLOC, 0, sg_kfree);return ret;
}
EXPORT_SYMBOL(sg_alloc_table);当申请的时候按照 SG_MAX_SINGLE_ALLOC,那么是一次性申请 4K 内存,系统直接调用 __get_free_page() 从buddy 中分配当没有达到 4K 内存,则通过kmalloc_array()申请 ;
static struct scatterlist *sg_kmalloc(unsigned int nents, gfp_t gfp_mask)
{if (nents == SG_MAX_SINGLE_ALLOC) {/** Kmemleak doesn't track page allocations as they are not* commonly used (in a raw form) for kernel data structures.* As we chain together a list of pages and then a normal* kmalloc (tracked by kmemleak), in order to for that last* allocation not to become decoupled (and thus a* false-positive) we need to inform kmemleak of all the* intermediate allocations.*/void *ptr = (void *) __get_free_page(gfp_mask);kmemleak_alloc(ptr, PAGE_SIZE, 1, gfp_mask);return ptr;} elsereturn kmalloc_array(nents, sizeof(struct scatterlist),gfp_mask);
}根据nents决定需不需要再次调用sg_kmalloc分配struct scatterlist数组,并返回首个scatterlist的地址,为什么叫数组,因为是在一个页面里面分配的,是连续的
int __sg_alloc_table(struct sg_table *table, unsigned int nents,unsigned int max_ents, struct scatterlist *first_chunk,unsigned int nents_first_chunk, gfp_t gfp_mask,sg_alloc_fn *alloc_fn)
{struct scatterlist *sg, *prv;unsigned int left;unsigned curr_max_ents = nents_first_chunk ?: max_ents;unsigned prv_max_ents;//准备初始化 sg_table,先memsetmemset(table, 0, sizeof(*table));//sg 条目数量不能为0if (nents == 0)return -EINVAL;
#ifdef CONFIG_ARCH_NO_SG_CHAINif (WARN_ON_ONCE(nents > max_ents))return -EINVAL;
#endif//初始化还没有申请的sg数目left = nents;prv = NULL;do {unsigned int sg_size, alloc_size = left;//确定此次需要申请的sg 个数//申请的sg超过最大值,将分多次分配if (alloc_size > curr_max_ents) {alloc_size = curr_max_ents;sg_size = alloc_size - 1; //申请的sg数组中,最后一个作为一个chain,不作为有效sg} elsesg_size = alloc_size;//还剩余多少sg没有申请left -= sg_size;if (first_chunk) {sg = first_chunk;first_chunk = NULL;} else {sg = alloc_fn(alloc_size, gfp_mask); //调用sg分配的回调函数}if (unlikely(!sg)) {/** Adjust entry count to reflect that the last* entry of the previous table won't be used for* linkage. Without this, sg_kfree() may get* confused.*/if (prv)table->nents = ++table->orig_nents;return -ENOMEM;}/** 初始化此次申请的sg 数组,这些sg 在物理上是连续的,所以可以直接memset* 另外,还会调用sg_mark_end() 初始化最后一个sg为 end sg*/sg_init_table(sg, alloc_size);//更新sg_table->nents,初始化时 nents和orig_nents相同table->nents = table->orig_nents += sg_size;/** 当再次进入循环时,说明需要的nents是大于max_nents的,那么上一次申请肯定是按照最大值* 申请.* 第一次申请时,会将sg数组放入sg_table的sgl* 当再进入循环时,需要连接新建的sg数组,所以要将prv的最后一个sg设为CHAIN*/if (prv)sg_chain(prv, prv_max_ents, sg);elsetable->sgl = sg;//如果没剩余sg需要分配了,将推出循环,此时将最新分配的sg数组的最后一个sg设为ENDif (!left)sg_mark_end(&sg[sg_size - 1]);prv = sg;prv_max_ents = curr_max_ents; //能进入下一个循环的话,上一个sg数组肯定按最大值申请的curr_max_ents = max_ents;} while (left);return 0;
}
EXPORT_SYMBOL(__sg_alloc_table);用以配置铰链 sg,offset 和 length 为0,通过该函数将当前的sg数组与下一个sg数组通过chain sg捆绑在一起。
static inline void sg_chain(struct scatterlist *prv, unsigned int prv_nents,struct scatterlist *sgl)
{/** offset and length are unused for chain entry. Clear them.*/prv[prv_nents - 1].offset = 0;prv[prv_nents - 1].length = 0;/** Set lowest bit to indicate a link pointer, and make sure to clear* the termination bit if it happens to be set.*/prv[prv_nents - 1].page_link = ((unsigned long) sgl | SG_CHAIN)& ~SG_END;
}sg跟buffer
常用api
sg_set_page函数用sg_assign_page以将当前sg与某个内存页进行关联;并设置大小和偏移
static inline void sg_set_page(struct scatterlist *sg, struct page *page,unsigned int len, unsigned int offset)
{sg_assign_page(sg, page);sg->offset = offset;sg->length = len;
}sg_set_buf传入buf,然后用sg_set_page将sg与这个buf的page关联
static inline void sg_set_buf(struct scatterlist *sg, const void *buf,unsigned int buflen)
{
#ifdef CONFIG_DEBUG_SGBUG_ON(!virt_addr_valid(buf));
#endifsg_set_page(sg, virt_to_page(buf), buflen, offset_in_page(buf));
}只初始化一个sg
void sg_init_table(struct scatterlist *sgl, unsigned int nents)
{memset(sgl, 0, sizeof(*sgl) * nents);sg_init_marker(sgl, nents);
}
EXPORT_SYMBOL(sg_init_table);
void sg_init_one(struct scatterlist *sg, const void *buf, unsigned int buflen)
{sg_init_table(sg, 1);sg_set_buf(sg, buf, buflen);
}
EXPORT_SYMBOL(sg_init_one);示例
int mmc_io_rw_extended(struct mmc_card *card, int write, unsigned fn,unsigned addr, int incr_addr, u8 *buf, unsigned blocks, unsigned blksz)
{struct mmc_request mrq = {NULL};struct mmc_command cmd = {0};struct mmc_data data = {0};struct scatterlist sg, *sg_ptr;struct sg_table sgtable;unsigned int nents, left_size, i;unsigned int seg_size = card->host->max_seg_size;......data.blksz = blksz;/* Code in host drivers/fwk assumes that "blocks" always is >=1 */data.blocks = blocks ? blocks : 1;data.flags = write ? MMC_DATA_WRITE : MMC_DATA_READ;left_size = data.blksz * data.blocks;nents = (left_size - 1) / seg_size + 1;if (nents > 1) {if (sg_alloc_table(&sgtable, nents, GFP_KERNEL))return -ENOMEM;data.sg = sgtable.sgl;data.sg_len = nents;for_each_sg(data.sg, sg_ptr, data.sg_len, i) {sg_set_page(sg_ptr, virt_to_page(buf + (i * seg_size)),min(seg_size, left_size),offset_in_page(buf + (i * seg_size)));left_size = left_size - seg_size;}} else {data.sg = &sg;data.sg_len = 1;sg_init_one(&sg, buf, left_size);}......
}sg跟DMA
常用api
判断当前sg是否为chain
#define sg_is_chain(sg) ((sg)->page_link & SG_CHAIN) 判断当前sg是否为last
#define sg_is_last(sg) ((sg)->page_link & SG_END)
chain sg用来获取下一个指向的sg数组
#define sg_chain_ptr(sg) \ ((struct scatterlist *) ((sg)->page_link & ~(SG_CHAIN | SG_END)))
获取下一个sg,可能在下一个sg_table里
struct scatterlist *sg_next(struct scatterlist *sg)
{if (sg_is_last(sg))return NULL;sg++;if (unlikely(sg_is_chain(sg)))sg = sg_chain_ptr(sg);return sg;
}
EXPORT_SYMBOL(sg_next);遍历sg
#define for_each_sg(sglist, sg, nr, __i) \for (__i = 0, sg = (sglist); __i < (nr); __i++, sg = sg_next(sg))获取sg关联的页块地址
static inline struct page *sg_page(struct scatterlist *sg)
{
#ifdef CONFIG_DEBUG_SGBUG_ON(sg_is_chain(sg));
#endifreturn (struct page *)((sg)->page_link & ~(SG_CHAIN | SG_END));
}示例
这是个支持sg的dma控制器;mmp_pdma_desc_hw用来dma描述符描述一个buf的信息,通过sg_dma_address将sg的总线物理地址,作为dma描述符的传输地址(源地址/目的地址),用来发送数据到设备,或者从设备接收数据
mmp_pdma_prep_slave_sg将下一个描述符的地址,给到上一个描述符的--下一个描述符地址的成员,以实现DMA控制器自动遍历描述符,来传输sg的多个数据块。
struct mmp_pdma_desc_hw {u32 ddadr; /* Points to the next descriptor + flags */u32 dsadr; /* DSADR value for the current transfer */u32 dtadr; /* DTADR value for the current transfer */u32 dcmd; /* DCMD value for the current transfer */
} __aligned(32);mmp_pdma_prep_slave_sg(struct dma_chan *dchan, struct scatterlist *sgl,unsigned int sg_len, enum dma_transfer_direction dir,unsigned long flags, void *context)
{struct mmp_pdma_chan *chan = to_mmp_pdma_chan(dchan);struct mmp_pdma_desc_sw *first = NULL, *prev = NULL, *new = NULL;size_t len, avail;struct scatterlist *sg;dma_addr_t addr;int i;if ((sgl == NULL) || (sg_len == 0))return NULL;chan->byte_align = true;mmp_pdma_config_write(dchan, &chan->slave_config, dir);for_each_sg(sgl, sg, sg_len, i) {addr = sg_dma_address(sg);avail = sg_dma_len(sg);do {len = min_t(size_t, avail, PDMA_MAX_DESC_BYTES);if (addr & 0x7)chan->byte_align = true;/* allocate and populate the descriptor */new = mmp_pdma_alloc_descriptor(chan);if (!new) {dev_err(chan->dev, "no memory for desc\n");goto fail;}new->desc.dcmd = chan->dcmd | (DCMD_LENGTH & len);if (dir == DMA_MEM_TO_DEV) {new->desc.dsadr = addr;new->desc.dtadr = chan->dev_addr;} else {new->desc.dsadr = chan->dev_addr;new->desc.dtadr = addr;}if (!first)first = new;elseprev->desc.ddadr = new->async_tx.phys; //将下一个描述符的地址,给到上一个描述符的--下一个描述符地址的成员;以实现控制器自动遍历描述符,来传输sg的多个数据块new->async_tx.cookie = 0;async_tx_ack(&new->async_tx);prev = new;/* Insert the link descriptor to the LD ring */list_add_tail(&new->node, &first->tx_list);/* update metadata */addr += len;avail -= len;} while (avail);}first->async_tx.cookie = -EBUSY;first->async_tx.flags = flags;/* last desc and fire IRQ */new->desc.ddadr = DDADR_STOP;new->desc.dcmd |= DCMD_ENDIRQEN;chan->dir = dir;chan->cyclic_first = NULL;return &first->async_tx;fail:if (first)mmp_pdma_free_desc_list(chan, &first->tx_list);return NULL;
}
相关文章:
scatterlist的相关概念与实例分析
概念 scatterlist scatterlist用来描述一块内存,sg_table一般用于将物理不同大小的物理内存链接起来,一次性送给DMA控制器搬运 struct scatterlist {unsigned long page_link; //指示该内存块所在的页面unsigned int offset; //指示该内存块在页面中的…...
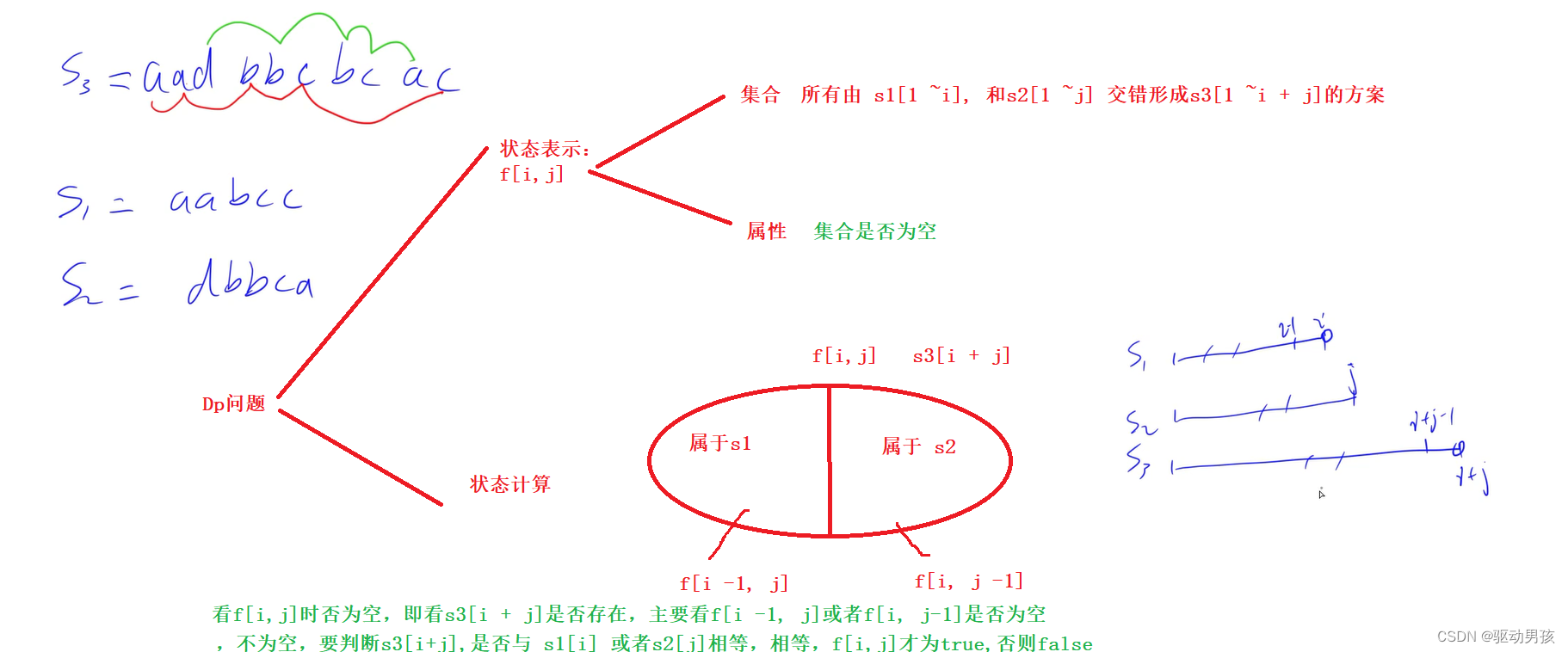
leetCode.97. 交错字符串
leetCode.97. 交错字符串 题目思路 代码 class Solution { public:bool isInterleave(string s1, string s2, string s3) {int n s1.size(), m s2.size();if ( s3.size() ! n m ) return false;vector<vector<bool>> f( n 1, vector<bool> (m 1));s1 …...

算力时代,算能(SOPHGO)的算力芯片/智算板卡/服务器选型
数字经济时代,算力成为支撑经济社会发展新的关键生产力,全球主要经济体都在加快推进算力战略布局。随着大模型持续选代,模型能力不断增强,带来算力需求持续增长。算力对数字经济和GDP的提高有显著的带动作用,根据IDC、…...

ManageEngine连续荣登Gartner 2024年安全信息和事件管理魔力象限
我们很高兴地宣布,ManageEngine再次在Gartner的安全信息和事件管理(SIEM)魔力象限中榜上有名,这是我们连续第七年获得这一认可。 Gartner ManageEngine Log360是一款全面的SIEM解决方案,旨在帮助组织有效处理日志数据…...

51单片机第11步_在C语言中插入汇编语言
本章重点介绍如何在C语言中插入汇编语言。要不是有记录,真不知道怎么搞。 /* 你在 Project Workspace窗口中,将光标移到DELAY.c处,点下鼠标右键,选择"Options for file DELAY.c", 点击右边的"Generate Assembler SRC File"和“Assemble SRC …...

【Qt+opencv】图片与视频的操作
文章目录 前言图片的操作图片的读取图片的写入示例代码 视频的操作打开视频关闭视频 总结 前言 在现代计算机视觉应用中,图像和视频处理起着至关重要的作用。这些应用范围广泛,包括图像识别、物体跟踪、3D建模等。为了实现这些功能,我们需要…...

Kubernetes面试整理-PersistentVolumes和PersistentVolumeClaims的使用和配置
在 Kubernetes 中,PersistentVolumes (PV) 和 PersistentVolumeClaims (PVC) 提供了一种分离存储和使用存储的机制。PV 是集群中存储资源的抽象表示,而 PVC 是用户对存储资源的请求。通过这种机制,用户可以动态地申请和管理存储资源。 PersistentVolumes (PV) PersistentVol…...

C++学习全教程(Day2)
一、数组 在程序中为了处理方便,常常需要把具有相同类型的数据对象按有序的形式排列起来,形成“一组”数据,这就是“数组”(array) 数组中的数据,在内存中是连续存放的,每个元素占据相同大小的空间,就像排…...

Transformer详解encoder
目录 1. Input Embedding 2. Positional Encoding 3. Multi-Head Attention 4. Add & Norm 5. Feedforward Add & Norm 6.代码展示 (1)layer_norm (2)encoder_layer1 最近刚好梳理了下transformer,今…...

ISO 19110操作要求类/req/operation/signature的详细解释
/req/operation/signature 要求: 每个要素操作实体必须有且仅有一个在要素目录范围内唯一的“signature”属性。 附注: 签名(signature)指定了操作的名称和调用该操作所需的参数名称。 具体解释 定义 要素操作实体(feature operation …...

理解GPT2:无监督学习的多任务语言模型
目录 一、背景与动机 二、卖点与创新 三、几个问题 四、具体是如何做的 1、更多、优质的数据,更大的模型 2、大数据量,大模型使得zero-shot成为可能 3、使用prompt做下游任务 五、一些资料 一、背景与动机 基于 Transformer 解码器的 GPT-1 证明…...

深度学习11-20
1.神经元的个数对结果的影响: (http://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html) (1)神经元3个的时候 (2)神经元是10个的时候 神经元个数越多,可能会产生…...

耐磨材料元宇宙:探索未来科技的无限可能
随着科技的不断发展,我们正逐渐进入一个全新的时代——元宇宙。在这个虚拟世界中,人们可以自由地创造、探索和交流。而在元宇宙中,耐磨材料作为一种重要的基础资源,将为我们的虚拟世界带来更多的可能性。 一、耐磨材料在元宇宙中…...

力扣2874.有序三元组中的最大值 II
力扣2874.有序三元组中的最大值 II 遍历j –> 找j左边最大数 和右边最大数 class Solution {public:long long maximumTripletValue(vector<int>& nums) {int n nums.size();vector<int> suf_max(n1,0);//右边最大数for(int in-1;i>1;i--){suf_max[i…...

Linux-笔记 嵌入式gdb远程调试
目录 前言 实现 1、内核配置 2、GDB移植 3、准备调试程序 4、开始调试 前言 gdb调试器是基于命令行的GNU项目调试器,通过gdb工具我们可以实现许多调试手段,同时gdb支持多种语言,兼容性很强。 在桌面 Linux 系统(如 Ubuntu、Cent…...

观测云产品更新 | Pipelines、智能监控、日志数据访问等
观测云更新 Pipelines 1、Pipelines:支持选择中心 Pipeline 执行脚本。 2、付费计划与账单:新增中心 Pipeline 计费项,统计所有命中中心 Pipeline 处理的原始日志的数据大小。 监控 1、通知对象管理:新增权限控制。配置操作权…...

docker 拉取不到镜像的问题:拉取超时
如果每次拉取的时候遇到超时 error pulling image configuration: download failed after attempts6: dial tcp 31.13.94.10:443: i/o timeout 解决方法如下: 设置国内镜像源: sudo mkdir -p /etc/docker 然后 sudo gedit /etc/docker/daemon.json 或…...
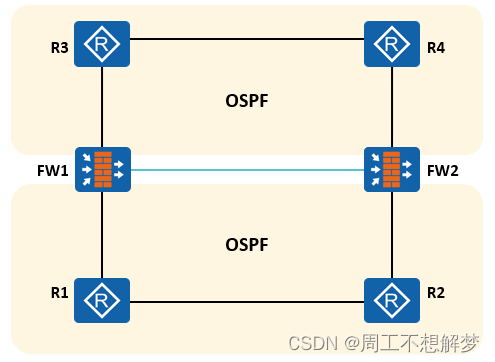
防火墙双机热备
防火墙双机热备 随着移动办公、网上购物、即时通讯、互联网金融、互联网教育等业务蓬勃发展,网络承载的业务越来越多,越来越重要。所以如何保证网络的不间断传输成为网络发展过程中急需解决的一个问题。 防火墙部署在企业网络出口处,内外网之…...

30分钟学习如何搭建扩散模型的运行环境【pytorch版】【B站视频教程】【解决环境搭建问题】
30分钟学习如何搭建扩散模型的运行环境【B站视频教程】【解决环境搭建问题】 动手学习扩散模型 点击以下链接即可进入学习: B站视频教程附赠:环境配置安装(配套讲解文档) 视频 讲解主要内容 一、环境设置 1.本地安装…...
)
使用Java连接数据库并且执行数据库操作和创建用户登录图形化界面(1)
创建一个Java程序,建立与本机mysql服务器上student数据库的连接,实现在tb_student学生表上插入一条学生信息:学号21540118,姓名王五,性别男,出生日期2003-12-10,所在学院5。 使用JDBC连接数据库…...

RimWorld模组管理终极指南:如何用RimSort轻松解决模组冲突问题
RimWorld模组管理终极指南:如何用RimSort轻松解决模组冲突问题 【免费下载链接】RimSort RimSort is an open source mod manager for the video game RimWorld. There is support for Linux, Mac, and Windows, built from the ground up to be a reliable, commun…...

泛微E-Office V10 OfficeServer 文件上传漏洞深度剖析与实战复现
1. 漏洞背景与影响范围 泛微E-Office作为国内广泛使用的协同办公系统,其V10版本中的OfficeServer.php组件存在高危文件上传漏洞。这个漏洞的本质在于服务端未对上传文件的类型、内容及路径进行严格校验,导致攻击者可以绕过常规防护机制,直接上…...

星露谷物语SMAPI模组加载器:5分钟快速上手指南与完整使用教程
星露谷物语SMAPI模组加载器:5分钟快速上手指南与完整使用教程 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否曾经因为星露谷物语模组安装复杂、冲突不断而感到困扰?今…...

IRISMAN:解锁PS3游戏管理的全能备份管理器,如何让它成为你的终极游戏管家?
IRISMAN:解锁PS3游戏管理的全能备份管理器,如何让它成为你的终极游戏管家? 【免费下载链接】IRISMAN All-in-one backup manager for PlayStation3. Fork of Iris Manager. 项目地址: https://gitcode.com/gh_mirrors/ir/IRISMAN IRIS…...
3个步骤让你的外文漫画秒变中文:BallonsTranslator零门槛入门指南
3个步骤让你的外文漫画秒变中文:BallonsTranslator零门槛入门指南 【免费下载链接】BallonsTranslator 深度学习辅助漫画翻译工具, 支持一键机翻和简单的图像/文本编辑 | Yet another computer-aided comic/manga translation tool powered by deeplearning 项目地…...

如何用Xenia Canary模拟器重温Xbox 360经典游戏?终极配置与优化指南
如何用Xenia Canary模拟器重温Xbox 360经典游戏?终极配置与优化指南 【免费下载链接】xenia-canary Xbox 360 Emulator Research Project 项目地址: https://gitcode.com/gh_mirrors/xe/xenia-canary Xenia Canary是一款免费开源的Xbox 360游戏模拟器&#…...

Claude代码生成Token预算管理实战:成本控制与智能优化策略
1. 项目概述与核心价值最近在折腾大模型应用开发,特别是围绕Claude这类顶尖的代码生成模型时,一个绕不开的痛点就是成本控制。模型调用是按Token计费的,而一个复杂的代码生成任务,动辄消耗成千上万个Token,账单不知不觉…...

在 Vue 2 与 Vue 3 中使用 markdown-it-vue 渲染 Markdown 和数学公式
markdown-it-vue 是一个功能强大的 Markdown 渲染 Vue 组件,它基于 markdown-it 解析引擎,集成了多种插件,开箱即用地支持GitHub风格的Markdown、代码高亮、图表(Mermaid, ECharts)、表情符号(emoji&#x…...

3步构建跨平台AI自动化测试:Midscene.js视觉驱动解决方案
3步构建跨平台AI自动化测试:Midscene.js视觉驱动解决方案 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene Midscene.js是一款基于视觉语言模型的跨平台…...

基于CircuitPython的红外遥控发射器:从原理到实现的万能控制方案
1. 项目概述:打造你的万能红外遥控发射器搞嵌入式开发的朋友,对红外遥控肯定不陌生。家里电视、空调、风扇的遥控器,本质上都是一个红外信号发射器。你有没有想过,自己动手做一个能模拟所有遥控器的“万能发射器”?今天…...