Kafka~特殊技术细节设计:分区机制、重平衡机制、Leader选举机制、高水位HW机制
分区机制
Kafka 的分区机制是其实现高吞吐和可扩展性的重要特性之一。
Kafka 中的数据具有三层结构,即主题(topic)-> 分区(partition)-> 消息(message)。一个 Kafka 主题可以包含多个分区,而每个分区又可以包含多条消息。
Topic和Partition是kafka中比较重要的概念。
- 主题:Topic是Kafka中承载消息的逻辑容器。可以理解为一个消息队列。生产者将消息发送到特定的Topic,消费者从Topic中读取消息。Topic可以被认为是逻辑上的消息流。在实际使用中多用来区分具体的业务。
- 分区:Partition。是Topic的物理分区。一个Topic可以被分成多个Partition,每个Partition是一个有序且持久化存储的日志文件。每个Partition都存储了一部分消息,并且有一个唯一的标识符(称为Partition ID)。
好处:
- 提升吞吐量:通过将一个Topic分成多个Partition,可以实现消息息的并行处理。每个Partition可以由不同的消费者组进行独立消费,这样就可以提高整个系统的吞吐量。
- 负载均衡:Partition的数量通常比消费者组的数量多,这样可以使每个消费者组中的消费者均匀地消费消息。当有新的消费者加入或离开消费者组时,可以通过重新分配Partition的方式进行负载均衡。
- 扩展性:通过增加Partition的数量,可以实现Kafka集群的广展性。更多的Partition可以提供更高的并发处理能力和更大的存储容量。
重平衡机制
Kafka的重平衡机制是指在消费者组中新增或删除消费者时,Kafka集群会重新分配主题分区给各个消费者,以保证每个消费者消费的分区数量尽可能均衡。
重平衡机制的目的是实现消费者的负载均衡和高可用性,以确保每个消费者都能够按照预期的方式消费到消息。
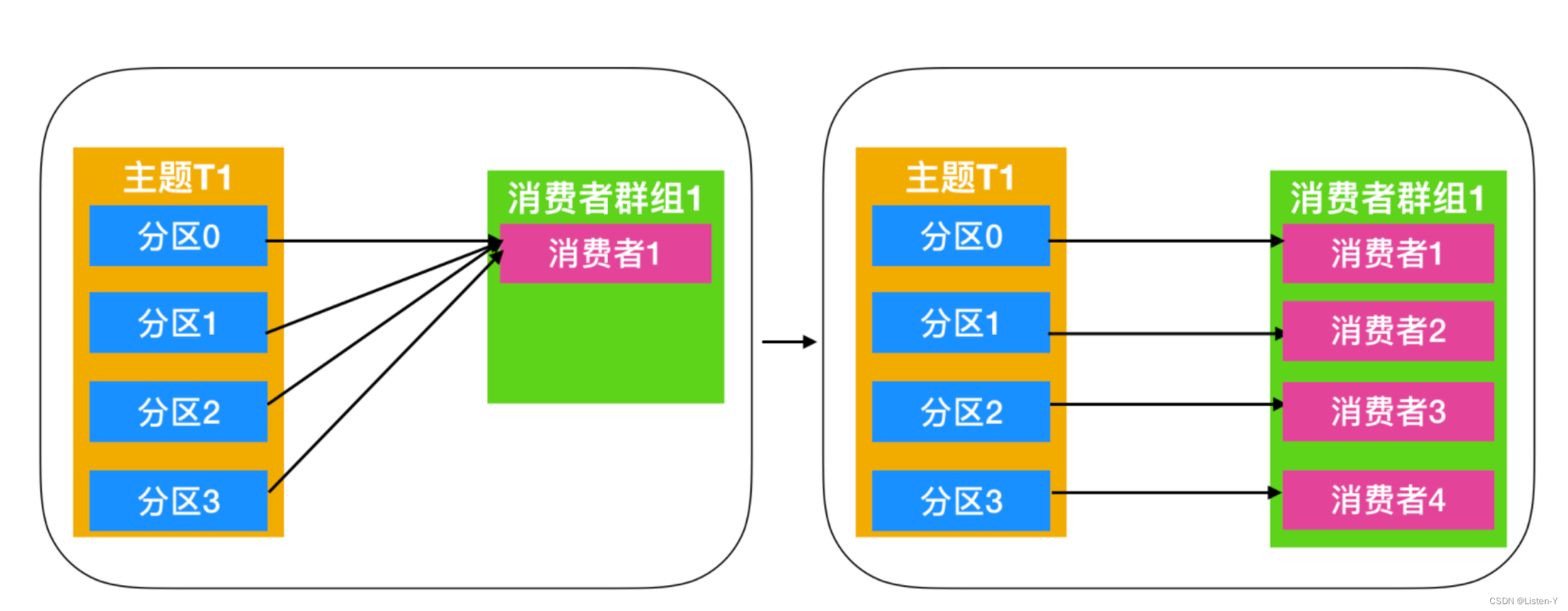
重平衡的3个触发条件:
- 消费者组成员数量发生变化。
- 消费者组成员订阅主题数量发生变化。
- 订阅主题的分区数发生变化。
平衡机制步骤:
- 暂停消费:在重平衡开始之前,Kafka会暂停所有消费者的拉取操作,以确保不会出现重平衡期间的消息丢失或重复消费。
- 计算分区分配方案:kafka集群会根据当前消费者组的消费者数量和主题分区数量,计算出每个消费者应该分配的分区列表,以实现分区的负载均衡。
- 通知消费者:一旦分区分配方案确定,Kafka集群会将分配方案发送给每个消费者,告诉它们需要消费的分区列表,并请求它们重新加入消费者组。
- 重新分配分区:在消费者重新加入消费者组后,Kafka集群会将分区分配方案应用到实际的分区分配中,重新分配主题分区给各个消费者。
- 恢复消费:最后,Kafka会恢复所有消费者的拉取操作,允许它们消费分配给自己的分区。
Kafka的重平衡机制能够有效地实现消费者的负载均衡和高可用性,提高消息的处理能力和可靠性。但是,由于重平衡会带来一定的性能开销和不确定性,例如:消息乱序、重复消费等问题,因此在设计应用时需要考虑到重平衡的影响,并采取一些措施来降低重平衡的频率和影响。
在重平衡过程中,所有Consumer实例都会停止消费。等待重平衡完成。但是目前并没有什么好的办法来解决重平衡带来的STW,只能尽量避免它的发生。
Consumer实例五种状态
- Empty:组内没有任何成员,但是消费者可能存在已提交的位移数据,而且这些位移尚未过期。
- Dead:同样是组内没有任何成员,但是组的元数据信息已经被协调者端移除,协调者保存着当前向他注册过的所有组信息。
- Preparing Rebalance:费者组准备开启重平衡,此时所有成员都需要重新加入消肖费者组
- Completing Rebalance:消费者组下所有成员已经加入,各个成员中等待分配方案
- Stable:消费者组的稳定状态,该状态表明重平衡已经完成,组内成员能够正常消费数据
Leader选举机制
Partition Leader 选举
Kafka中的每个Partition都有一个Leader,负责处理该Parttition的读写请求。在正常情况下。Leader和ISR集合中的所有副本保持同步,Leader接收到的消息也会被ISF集合中的副本所接收。当leader副本宕机或者无法正常工作时,需要选举新的leader副本来接管分区的工作。
Leader选举的过程如下:
- 每个参与选举的副本会尝试向ZooKeeper上写入一个临时节点,表示它们正在参与Leader选举
- 所有写入成功的副本会在ZooKeeper上创建一个序列号节点,并将自己的节点序列号写入该节点
- 节点序列号最小的副本会被选为新的Leader,并将自己的节点名称写入ZooKeeper上的/broker/…/leader节点中。
Controller选举
Kafka集群中只能有一个Controller节点,用于管理分区的副本分配、leader选举等任务。当一个Broker变成Controller后,会在Zookeeper的/controller节点中记录下来。然后其他的Broker会实时监听这个节点,主要就是避免当这个controller宕机的话,就需要进行重新选举。
Controller选举的过程如下:
- 所有可用的Broker向ZooKeeper注册自己的ID。并监听Zookeeper中/controller节点的变化。
- 当Controller节点出现故障时,ZooKeeper会删除/controller节点,这时所有的Broker都会监听到该事件,并开始争夺Controller的位置。为了避免出现多个Broker同时竞选Controller的情况,Kafka设计了一种基于ZooKeeper的Master-Slave机制,其中一个Broker成为Master,其它Broker成为为Slave。Master负责选举Controller,并将选举结果写入ZooKeeper中,而Slave则监听/controller节点的变化,一旦发现Master发生故障,则开始争夺Master的位置。
- 当一个Broker发现Controller失效时,它会向ZooKeeper写入自自己的ID,并尝试竞选Controller的位置。如果他创建临时节点成功,则该Broker成为新的Controller,并将选举结果写入ZooKeeper中。
- 其它的Broker会监听到ZooKeeper中/controller节点的变化,一旦发现选举结果发生变化,则更新自己的元数据信息,然后与新的Controller建立连接,进行后续的操作。
高水位HW机制
高水位(HW,HighWatermark)是Kafka中的一个重要的概念,主要是用于管理消费者的进度和保证数据的可靠性的。
高水位标识了一个特定的消息偏移量(offset),即一个分区中已提交(这里的已提交指的是ISR中的所有副本都记录了这条消息)消息的最高偏移量(offset),消费者只能拉取到这个offset之前的消息。消费者可以通过跟踪高水位来确定自己消费的位置。
在Kafka中,HW主要有两个作用:
- 消费进度管理:消费者可以通过记录上一次消费的偏移量,然后将其与分区的高水位进行比较,来确定自己的消费进度。消费者可以在和高水位对比之后继续消费新的消息,确保不会错过任何已提交的消息。这样,消费者可以按照自己的节奏进行消费,不受其他消费者的响。
- 数据的可靠性:高水位还用于确保数据的可靠性。在Kafka中,只有消息被写入主副本(Leader Replica)并被所有的同步副本(In-Sync Replicas,ISR)确认后,才被认为是是已提交的消息。高水位表示已经被提交的消息的边界。只有高水位之前的消息才能被认为是已经被确认的,其他的消息可能会因为副本故障或其他原因而丢失。当消费者消费消息,可以使用高水位作为参考点,只消费高水位之前的消息,以确保消费的是已经被确认的消息,从而保证数据的可靠性。

还有一个概念,叫做LEO,即LogEnd Offset,,他是日志最后消息的偏移量。它标识当前日志文件中下一条待写入消息的offset。
它有以下特点和作用:
- 用于表示副本写入下一条消息的位置。
- 每个副本(包括 leader 副本和 follower 副本)都有自己的 LEO。
- LEO 的值会随着消息的写入而增加,每当有新消息写入底层日志成功时,相应副本的 LEO 就会加 1。
- LEO 主要用于跟踪副本的同步进度。
需要注意的是,在 0.11.0.0 版本之前,HW 的更新可能存在一些问题,例如在特定情况下可能导致消息丢失。0.11.0.0 及之后的版本使用 leader epoch,与 HW 值结合,从而更好地保证了数据的一致性和顺序性。
- 每个分区都有一个初始的LeaderEpoch,通常为0。
- 当Leader副本发生故障或需要进行切换时,Kafka会触发副本切换过程。
- 副本切换过程中,Kafka会从ISR(In-Sync Replicas,同步副本)中选择一个新的Follower副本作为新的Leader副本。
- 新的Leader副本会增加自己的Leader Epoch,使其大于之前的Leader Epoch。这表示进入了一个新的任期。
- 新的Leader副本会验证旧Leader副本的状态以确保数据的一致性。它会检查旧Leader副本的Leader Epoch和高水位。
- 如果旧Leader副本的Leader Epoch小于等于新Leader副本的Leadder Epoch,并且旧Leader副本的高水位小于等于新Leader副本的高水位,则验证通过。
- 一旦验证通过,新的Leader副本会开始从ISR中的一部分副本中寻找最大的LEO副本进行复制数据,以确保新Leader上的数据与旧Leader-致。
- 一旦新的Leader副本复制了旧Leader副本的所有数据,并达到了与旧Leader副本相同的高水位,副本切换过程就完成了。
通过使用Leader Epoch、高水位、LEO的验证,Kafka可以避免新的Leader副本接受旧Leader副本之后的消息,从而避免数据回滚和丢失。Leader Epoch 为 Kafka 提供了一种更可靠和一致的副本管理机制,确保了在 Leader 副本切换等情况下数据的完整性和正确性。
相关文章:
Kafka~特殊技术细节设计:分区机制、重平衡机制、Leader选举机制、高水位HW机制
分区机制 Kafka 的分区机制是其实现高吞吐和可扩展性的重要特性之一。 Kafka 中的数据具有三层结构,即主题(topic)-> 分区(partition)-> 消息(message)。一个 Kafka 主题可以包含多个分…...
springcloud-config 客户端启用服务发现client的情况下使用metadata中的username和password
为了让spring admin 能正确获取到 spring config的actuator的信息,在eureka的metadata中添加了metadata.user.user metadata.user.password eureka.instance.metadata-map.user.name${spring.security.user.name} eureka.instance.metadata-map.user.password${spr…...
)
云计算 | 期末梳理(中)
1. 经典虚拟机的特点 多态(Polymorphism):支持多种类型的OS。重用(Manifolding):虚拟机的镜像可以被反复复制和使用。复用(Multiplexing):虚拟机能够对物理资源时分复用。2. 系统接口 最基本的接口是微处理器指令集架构(ISA)。应用程序二进制接口(ABI)给程序提供使用硬件资源…...

pytest测试框架pytest-order插件自定义用例执行顺序
pytest提供了丰富的插件来扩展其功能,本章介绍插件pytest-order,用于自定义pytest测试用例的执行顺序。pytest-order是插件pytest-ordering的一个分支,但是pytest-ordering已经不再维护了,建议大家直接使用pytest-order。 官方文…...

吴恩达机器学习 第三课 week2 推荐算法(上)
目录 01 学习目标 02 推荐算法 2.1 定义 2.2 应用 2.3 算法 03 协同过滤推荐算法 04 电影推荐系统 4.1 问题描述 4.2 算法实现 05 总结 01 学习目标 (1)了解推荐算法 (2)掌握协同过滤推荐算法(Collabo…...

MySQL CASE 表达式
MySQL CASE表达式 一、CASE表达式的语法二、 常用场景1,按属性分组统计2,多条件统计3,按条件UPDATE4, 在CASE表达式中使用聚合函数 三、CASE表达式出现的位置 一、CASE表达式的语法 -- 简单CASE表达式 CASE sexWHEN 1 THEN 男WHEN 2 THEN 女…...

Unity3D 游戏数据本地化存储与管理详解
在Unity3D游戏开发中,数据的本地化存储与管理是一个重要的环节。这不仅涉及到游戏状态、玩家信息、游戏设置等关键数据的保存,还关系到游戏的稳定性和用户体验。本文将详细介绍Unity3D中游戏数据的本地化存储与管理的技术方法,并给出相应的代…...

昇思25天学习打卡营第1天|初学教程
文章目录 背景创建环境熟悉环境打卡记录学习总结展望未来 背景 参加了昇思的25天学习记录,这里给自己记录一下所学内容笔记。 创建环境 首先在平台注册账号,然后登录,按下图操作,创建环境即可 创建好环境后进入即可࿰…...
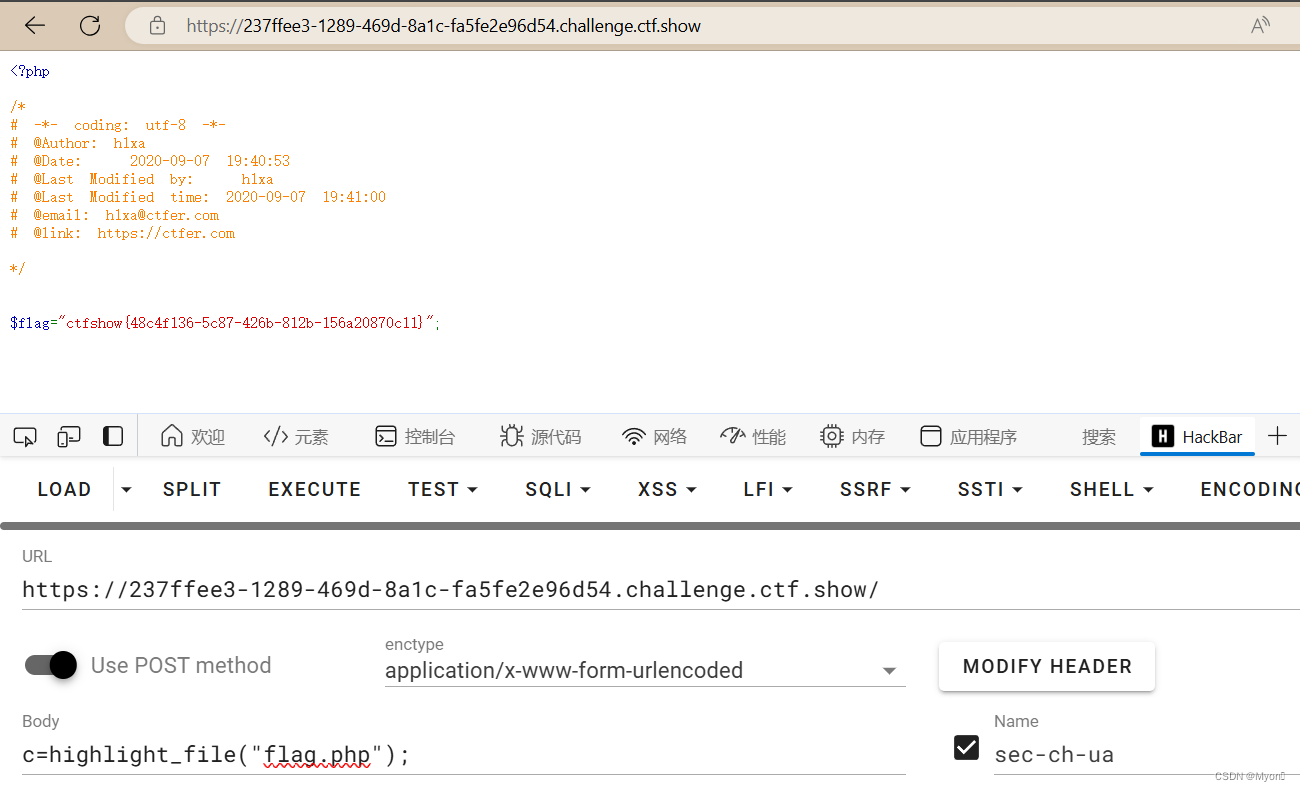
ctfshow-web入门-命令执行(web59-web65)
目录 1、web59 2、web60 3、web61 4、web62 5、web63 6、web64 7、web65 都是使用 highlight_file 或者 show_source 1、web59 直接用上一题的 payload: cshow_source(flag.php); 拿到 flag:ctfshow{9e058a62-f37d-425e-9696-43387b0b3629} 2、w…...
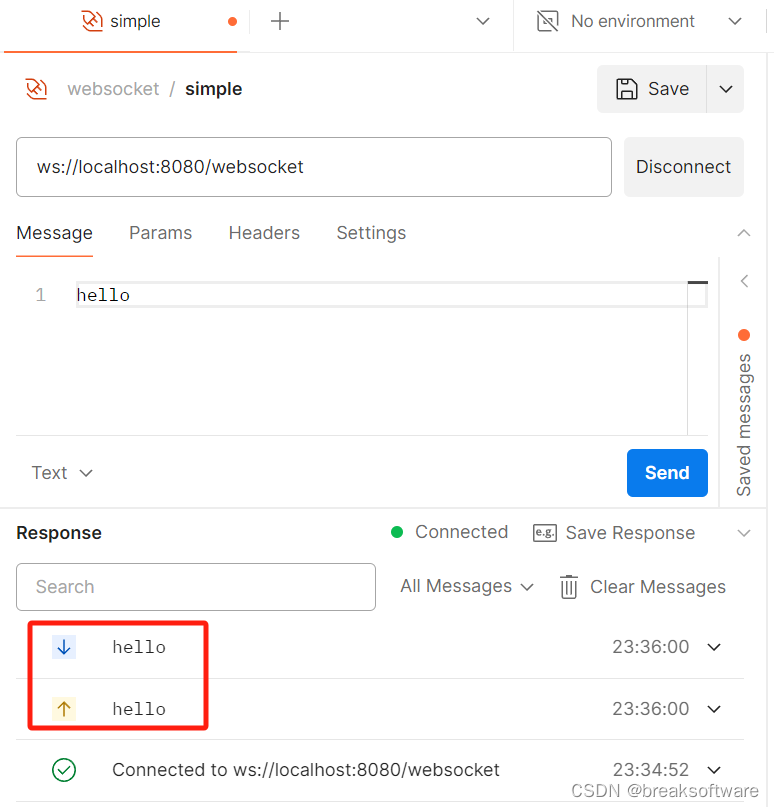
Websocket在Java中的实践——最小可行案例
大纲 最小可行案例依赖开启Websocket,绑定路由逻辑类 测试参考资料 WebSocket是一种先进的网络通信协议,它允许在单个TCP连接上进行全双工通信,即数据可以在同一时间双向流动。WebSocket由IETF标准化为RFC 6455,并且已被W3C定义为…...

python请求报错::requests.exceptions.ProxyError: HTTPSConnectionPool
在发送网页请求时,发现很久未响应,最后报错: requests.exceptions.ProxyError: HTTPSConnectionPool(hostsvr-6-9009.share.51env.net, port443): Max retries exceeded with url: /prod-api/getInfo (Caused by ProxyError(Unable to conne…...
【Unity】Excel配置工具
1、功能介绍 通过Excel表配置表数据,一键生成对应Excel配置表的数据结构类、数据容器类、已经二进制数据文件,加载二进制数据文件获取所有表数据 需要使用Excel读取的dll包 2、关键代码 2.1 ExcelTool类 实现一键生成Excel配置表的数据结构类、数据…...
)
001 线性查找(lua)
文章目录 迭代器主程序 迭代器 -- 定义一个名为 linearSearch 的函数,它接受两个参数:data(一个数组)和 target(一个目标值) function linearSearch(data, target) -- 使用 for 循环遍历数组 data&…...

数据结构之链表
储备知识: 线性表 :一对一的数据所组成的关系称为线性表。 线性表是一种数据内部的逻辑关系,与存储形式无关线性表既可以采用连续的顺序存储(数组),也可以采用离散的链式存储(链表)顺序表和链表都称为线性表 顺序存储就是将数据存…...

【小工具】 Unity相机宽度适配
相机默认是根据高度适配的,但是在部分游戏中需要根据宽度进行适配 实现步骤 定义标准屏幕宽、高判断标准屏幕宽高比与当前的是否相等通过**(标准宽度/当前宽度) (标准高度 / 当前高度)**计算缩放调整相机fieldOfView即…...

centos误删yum和python
在下载pkdg时,因为yum报错坏的解释器,然后误删了yum和python。 在下载各种版本,创建各种软连接,修改yum文件都不好使后,发现了这样一个方法:Centos: 完美解决python升级导致的yum报错问题(相信…...

WP黑格导航主题BlackCandy
BlackCandy-V2.0全新升级!首推专题区(推荐分类)更多自定义颜色!选择自己喜欢的色系,焕然一新的UI设计,更加扁平和现代化! WP黑格导航主题BlackCandy...

elasticsearch底层核心组件
Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎,它基于Apache Lucene构建,并添加了分布式特性。以下是Elasticsearch的一些底层核心组件: 1. **Lucene**: - Elasticsearch基于Apache Lucene,一个高性能的…...
EasyExcel数据导入
前言: 我先讲一种网上信息的获取方式把,虽然我感觉和后面的EasyExcel没有什么关系,可能是因为这个项目这个操作很难实现,不过也可以在此记录一下,如果需要再拆出来也行。 看上了网页信息,怎么抓到&#x…...

20240630 每日AI必读资讯
📚全美TOP 5机器学习博士发帖吐槽:实验室H100数量为0! - 普林斯顿、哈佛「GPU豪门」,手上的H100至少三四百块,然而绝大多数ML博士一块H100都用不上 - 年轻的研究者们纷纷自曝自己所在学校或公司的GPU情况:…...

别再手动改防火墙了!用这条组策略,一键修复AD域强制更新时的RPC报错
自动化运维实战:用组策略统一管理AD域防火墙规则 在混合Windows环境的IT运维中,手动配置每台终端设备的防火墙规则无异于一场噩梦。想象一下,当您面对数百台运行不同Windows版本的计算机时,每次组策略更新都因为防火墙拦截RPC通信…...

免费Minecraft基岩版启动器终极指南:突破官方限制的完整解决方案
免费Minecraft基岩版启动器终极指南:突破官方限制的完整解决方案 【免费下载链接】BedrockLauncher 项目地址: https://gitcode.com/gh_mirrors/be/BedrockLauncher 还在为Minecraft基岩版官方启动器的功能限制而困扰吗?想要像Java版那样自由管理…...

ROFL-Player:打破英雄联盟回放观看壁垒的革命性工具
ROFL-Player:打破英雄联盟回放观看壁垒的革命性工具 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 你是否曾经因为游戏版本…...

Julia语言深度解析:高性能科学计算与机器学习实战指南
1. Julia语言:是技术革命还是营销泡沫? 最近几年,技术圈里关于Julia的讨论热度一直没降下来过。每次有朋友问我“该不该学Julia”或者“Julia是不是要取代Python了”,我都得先让他们冷静一下,然后从我的实际体验出发&…...

如何在Windows 11上完美运行经典游戏:DDrawCompat终极兼容性解决方案
如何在Windows 11上完美运行经典游戏:DDrawCompat终极兼容性解决方案 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mir…...
CMS 7.5 恶意文件上传-CVE-2018-18086)
Empire(帝国)CMS 7.5 恶意文件上传-CVE-2018-18086
登录管理员页面:这里经过多次测试,直接上传一句话样本文件的话不生效(避坑),并且$符需要做转义(避坑),否则:方式1:<?php file_put_contents("getshell.php"…...

模型哈密顿量构建:从第一性原理到可计算有效模型的实践指南
1. 项目概述:从“黑箱”到“白箱”的化学计算桥梁 在计算化学和材料科学领域,我们常常面临一个核心矛盾:一方面,我们希望模型足够精确,能够捕捉到电子结构最细微的相互作用,比如使用密度泛函理论࿰…...

通过curl命令快速测试Taotoken多模型API的响应
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken多模型API的响应 在开发调试或服务器环境部署初期,有时你可能需要一种轻量、直接的方式来…...

反向海淘代购集运系统三种搭建路径对比:自研、开源二开、SaaS
「技术、数据、接口、系统问题欢迎留言私信沟通」引言:标准业务架构# 系统演示、API测试控制台:http://console.open.onebound.cn/console/?iRookie用户层(Web / App / 小程序)↓ 网关层(Nginx / Gateway)…...

STM32的RTC掉电还能走时?深入聊聊后备域和纽扣电池那点事
STM32的RTC掉电还能走时?深入聊聊后备域和纽扣电池那点事 当你在深夜调试STM32的RTC功能时,是否曾好奇过这个小巧的实时时钟为何能在主电源断开后依然精准走时?这背后隐藏着STM32芯片设计中一个精妙的电源管理机制——后备域(Back…...