【机器学习】机器学习的重要方法——强化学习:理论,方法与实践
目录
一、强化学习的核心概念
二、强化学习算法的分类与示例代码
三.强化学习的优势
四.强化学习的应用与挑战
五、总结与展望
强化学习:理论,方法和实践

在人工智能的广阔领域中,强化学习(Reinforcement Learning, RL)是一个备受瞩目的分支。它通过让智能体(Agent)在环境中进行试错学习,以最大化累积奖励为目标。本文将带您深入探索强化学习算法的魅力与奥秘,并通过一些代码示例来展示其工作原理和应用场景。
一、强化学习的核心概念
强化学习的核心概念包括状态(State)、动作(Action)、奖励(Reward)和策略(Policy)。智能体通过不断尝试动作,并根据环境返回的奖励来更新策略,以期望在未来获得更大的累积奖励。
二、强化学习算法的分类与示例代码
(省略之前的分类和伪代码部分,直接展示应用场景代码)
应用场景:FrozenLake环境
FrozenLake是一个经典的强化学习环境,其中智能体需要在一个4x4的网格世界中移动,目标是到达目标位置,同时避免掉进冰洞。
首先,我们需要安装必要的库(如果尚未安装):
pip install gym然后,我们可以使用Python和Gym库来编写一个简单的强化学习示例,使用Q-learning算法解决FrozenLake问题:
import numpy as np
import gym
from collections import deque # 初始化环境
env = gym.make('FrozenLake-v0', is_slippery=False) # Q-learning参数
learning_rate = 0.8
discount_factor = 0.95
epsilon = 1.0 # 探索率,随训练过程逐渐减小
epsilon_decay = 0.995
epsilon_min = 0.01 # 初始化Q表
q_table = np.zeros([env.observation_space.n, env.action_space.n]) # 训练过程
num_episodes = 2000
for episode in range(num_episodes): state = env.reset() done = False total_reward = 0 while not done: # 选择动作:epsilon-greedy策略 if np.random.rand() < epsilon: action = env.action_space.sample() else: action = np.argmax(q_table[state, :]) # 执行动作,观察新的状态和奖励 next_state, reward, done, _ = env.step(action) # 更新Q表 old_value = q_table[state, action] next_max = np.max(q_table[next_state, :]) new_value = (1 - learning_rate) * old_value + learning_rate * (reward + discount_factor * next_max * (not done)) q_table[state, action] = new_value # 更新状态 state = next_state total_reward += reward # 减小探索率 epsilon = max(epsilon_min, epsilon * epsilon_decay) # 打印每轮的奖励 if episode % 100 == 0: print(f"Episode {episode}, Total reward: {total_reward}") # 测试训练后的智能体
state = env.reset()
while True: env.render() # 渲染环境 action = np.argmax(q_table[state, :]) # 选择最佳动作 next_state, reward, done, _ = env.step(action) state = next_state if done: break
env.close()在这个示例中,我们使用了Gym库提供的FrozenLake环境,并使用Q-learning算法训练了一个智能体。通过epsilon-greedy策略进行探索和利用,智能体逐渐学会了如何安全地到达目标位置。

三.强化学习的优势
为了展示强化学习的优势,我们可以对比一个使用随机策略的智能体和一个使用强化学习算法(如Q-learning)训练过的智能体在相同环境中的性能。下面,我们将扩展前面的FrozenLake示例,包括一个随机策略的智能体,并比较两者的表现。
import numpy as np
import gym # 初始化环境
env = gym.make('FrozenLake-v0', is_slippery=False) # 随机策略函数
def random_policy(env): return env.action_space.sample() # Q-learning参数
learning_rate = 0.8
discount_factor = 0.95
epsilon = 1.0 # 探索率
epsilon_decay = 0.995
epsilon_min = 0.01 # 初始化Q表
q_table = np.zeros([env.observation_space.n, env.action_space.n]) # 训练Q-learning智能体
num_episodes = 2000
for episode in range(num_episodes): state = env.reset() done = False total_reward = 0 # 使用epsilon-greedy策略选择动作 while not done: if np.random.rand() < epsilon: action = env.action_space.sample() else: action = np.argmax(q_table[state, :]) next_state, reward, done, _ = env.step(action) # 更新Q表(省略了具体的更新逻辑,与前面的示例相同) # ... # 更新状态和其他变量 state = next_state total_reward += reward # 减小探索率 epsilon = max(epsilon_min, epsilon * epsilon_decay) # 测试Q-learning智能体
def test_qlearning_agent(env, q_table, num_episodes=10): rewards = [] for _ in range(num_episodes): state = env.reset() total_reward = 0 while True: action = np.argmax(q_table[state, :]) next_state, reward, done, _ = env.step(action) total_reward += reward state = next_state if done: break rewards.append(total_reward) return np.mean(rewards) # 测试随机策略智能体
def test_random_agent(env, num_episodes=10): rewards = [] for _ in range(num_episodes): state = env.reset() total_reward = 0 while True: action = random_policy(env) next_state, reward, done, _ = env.step(action) total_reward += reward state = next_state if done: break rewards.append(total_reward) return np.mean(rewards) # 测试两个智能体并比较结果
ql_score = test_qlearning_agent(env, q_table)
random_score = test_random_agent(env) print(f"Q-learning agent average reward: {ql_score}")
print(f"Random agent average reward: {random_score}") # 通常情况下,Q-learning智能体的表现会优于随机策略智能体在这个扩展示例中,我们定义了两个函数test_qlearning_agent和test_random_agent来分别测试Q-learning智能体和随机策略智能体在FrozenLake环境中的表现。我们运行了多个测试回合(num_episodes),并计算了平均奖励来评估智能体的性能。
通常,使用强化学习算法(如Q-learning)训练过的智能体会比随机策略的智能体表现得更好,因为它能够通过学习和优化策略来最大化累积奖励。这个示例展示了强化学习在决策制定方面的优势,特别是在处理复杂环境和任务时。

四.强化学习的应用与挑战
强化学习在游戏、机器人、自动驾驶等领域有着广泛的应用。然而,强化学习也面临着一些挑战,如数据稀疏性、探索与利用的平衡、高维状态空间等问题。为了克服这些挑战,研究者们不断提出新的算法和技术。
五、总结与展望
强化学习为机器赋予了自我学习和优化的能力,使得机器能够在复杂环境中进行智能决策。随着算法的不断优化和应用场景的不断拓展,强化学习将在更多领域展现出其独特的魅力和价值。让我们共同期待强化学习在未来的发展和应用吧!

相关文章:
【机器学习】机器学习的重要方法——强化学习:理论,方法与实践
目录 一、强化学习的核心概念 二、强化学习算法的分类与示例代码 三.强化学习的优势 四.强化学习的应用与挑战 五、总结与展望 强化学习:理论,方法和实践 在人工智能的广阔领域中,强化学习(Reinforcement Learning, RL&…...

Linux磁盘监控思路分析
磁盘监控原理 设备又名I/O设备,泛指计算机系统中除主机以外的所有外部设备。 1.1 计算机分类 1.1.1 按照信息传输速度分: 1.低速设备:每秒传输信息仅几个字节或者百个字节,如:键盘、鼠标等 2.中速设备:…...
pc端制作一个顶部固定的菜单栏
效果 hsl颜色 hsl颜色在css中比较方便 https://www.w3school.com.cn/css/css_colors_hsl.asp 色相(hue)是色轮上从 0 到 360 的度数。0 是红色,120 是绿色,240 是蓝色。饱和度(saturation)是一个百分比值…...
ONLYOFFICE 8.1版本桌面编辑器深度体验:创新功能与卓越性能的结合
ONLYOFFICE 8.1版本桌面编辑器深度体验:创新功能与卓越性能的结合 随着数字化办公的日益普及,一款高效、功能丰富的办公软件成为了职场人士的必备工具。ONLYOFFICE团队一直致力于为用户提供全面而先进的办公解决方案。最新推出的ONLYOFFICE 8.1版本桌面编…...
)
使用Java连接数据库并且执行数据库操作和创建用户登录图形化界面(2)
(1)在student数据库上创建一个用户表tb_account,该表包含用户id,用户名和密码。 字段名称 数据类型 注释 约束 user_id Char(8) 用户id 主键 user_name char(10) 用户名 不能为空 password char(10) 密码 默认值&a…...
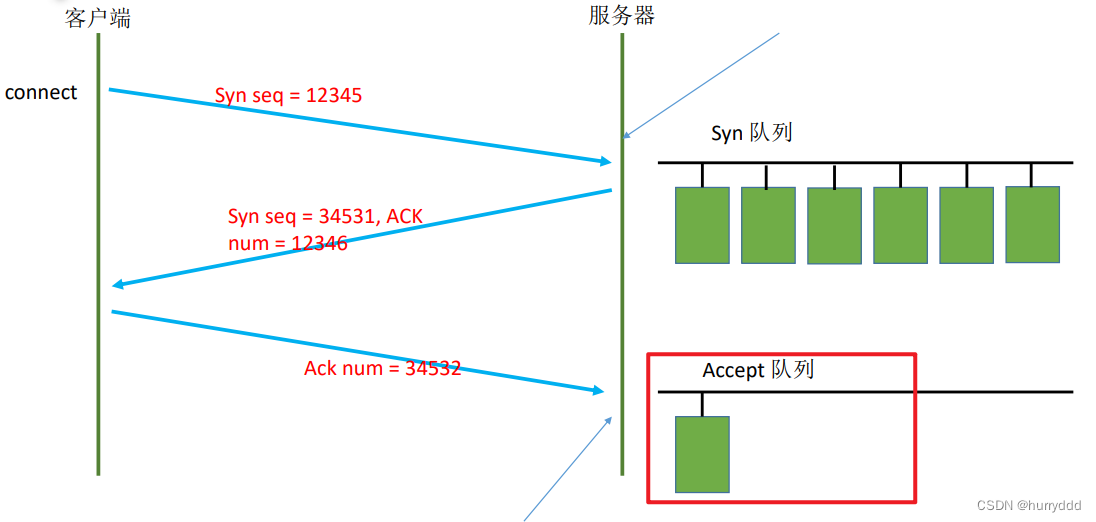
socket编程常见操作
1、连接的建立 分为两种:服务端处理接收客户端的连接;服务端作为客户端连接第三方服务 //作为服务端 int listenfd socket(AF_INET, SOCK_STREAM, 0); bind(listenfd, (struct sockaddr*)&servaddr, sizeof(servaddr))) listen(listenfd, 10); //…...
)
springcloud-config git配置源加载(部署公钥问题)
使用gitUrl作为配置源 gitee 或者github 中有类似于发布密钥的功能,允许通过私钥只读访问指定的仓库,文档中说的是 限制了git的操作为pull 和 clone。生成私钥的方式文档连接在此 https://gitee.com/help/articles/4181#article-header0 spring config只…...

华为OD机考题HJ24 合唱队
前言 应广大同学要求,开始以OD机考题作为练习题,看看算法和数据结构掌握情况。有需要练习的可以关注下。 描述 N 位同学站成一排,音乐老师要请最少的同学出列,使得剩下的 K 位同学排成合唱队形。 设𝐾K位同学从左到…...

基于bootstrap的12种登录注册页面模板
基于bootstrap的12种登录注册页面模板,分三种类型,默认简单的登录和注册,带背景图片的登录和注册,支持弹窗的登录和注册页面html下载。 微信扫码下载...

【劳德巴赫 Trace32 高阶系列 3.1 -- trace32 svf 文件操作与 InitState】
文章目录 SVF InitStateJTAG 状态机JTAG Test-Logic-ResetJTAG Run-Test-IdleSVF InitState Format: JTAG.PROGRAM.SVF <file> [/<option>] <option>: IRPRE <value>IRPOST <value>DRPRE <value>DRPOST <value<...

爬虫知识:补环境相关知识
学习目标:知道为什么要补环境,知道要补什么环境(使用Proxy检测)。没有讲解怎么补 本章没有动手去实操,只是纯理论知识 补环境介绍 DOM与BOM DOM主要关注文档内容和结构,而BOM关注浏览器窗口和功能。在浏…...

Crontab命令详解:轻松驾驭Linux定时任务,提升系统效率
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》《MYSQL》 💪🏻 制定明确可量化的目标,坚持默默的做事。 引言: crond是Linux系统中用来定期执行命令或指定程序任务的一种服务或软件…...

【Python】探索 Pandas 中的 where 方法:条件筛选的利器
那年夏天我和你躲在 这一大片宁静的海 直到后来我们都还在 对这个世界充满期待 今年冬天你已经不在 我的心空出了一块 很高兴遇见你 让我终究明白 回忆比真实精彩 🎵 王心凌《那年夏天宁静的海》 在数据分析中,Pandas 是一个强大且…...
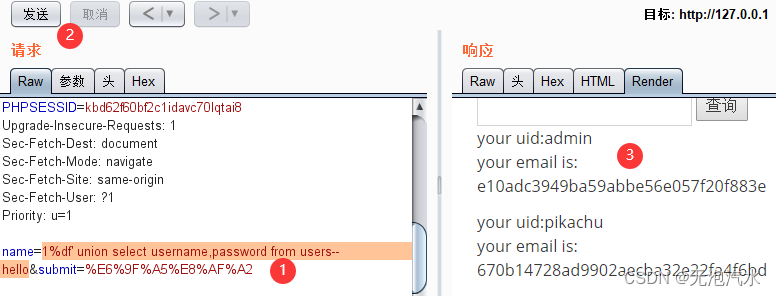
Pikachu靶场--Sql Inject
参考借鉴 pikachu靶场练习(详细,完整,适合新手阅读)-CSDN博客 数字型注入(post) 这种类型的SQL注入利用在用户输入处插入数值,而不是字符串。攻击者试图通过输入数字来修改SQL查询的逻辑,以执行恶意操作。…...
【Python从入门到进阶】59、Pandas库中Series对象的操作(二)
接上篇《58、Pandas库中Series对象的操作(一)》 上一篇我们讲解了Pandas库中Series对象的基本概念、对象创建和操作,本篇我们来继续学习Series对象的运算、函数应用、时间序列操作,以及Series的案例实践。 一、Series对象的运算 1. 数值型数据的算术运…...

【PYG】使用datalist定义数据集,创建一个包含多个Data对象的列表并使用DataLoader来加载这些数据
为了使用你提到的封装方式来创建一个包含多个 Data 对象的列表并使用 DataLoader 来加载这些数据,我们可以按照以下步骤进行: 创建数据:生成节点特征矩阵、边索引矩阵和标签。封装数据:使用 Data 对象将这些数据封装起来。使用 D…...

【设计模式】【创建型5-2】【工厂方法模式】
文章目录 工厂方法模式工厂方法模式的结构示例产品接口具体产品工厂接口具体工厂客户端代码 实际的使用 工厂方法模式 工厂方法模式的结构 产品(Product):定义工厂方法所创建的对象的接口。 具体产品(ConcreteProduct࿰…...

python API自动化(Pytest+Excel+Allure完整框架集成+yaml入门+大量响应报文处理及加解密、签名处理)
1.pytest数据参数化 假设你需要测试一个登录功能,输入用户名和密码后验证登录结果。可以使用参数化实现多组输入数据的测试: 测试正确的用户名和密码登录成功 测试正确的用户名和错误的密码登录失败 测试错误的用户名和正确的密码登录失败 测试错误的用户名和密码登…...

【Postman学习】
Postman是一个非常流行的API开发和测试工具,广泛用于Web服务的开发、测试和调试。它提供了一个图形界面,允许用户轻松地构建、发送和管理HTTP(S)请求,同时查看和分析响应。下面是对Postman接口测试工具的详细解释: 1. Postman简介…...
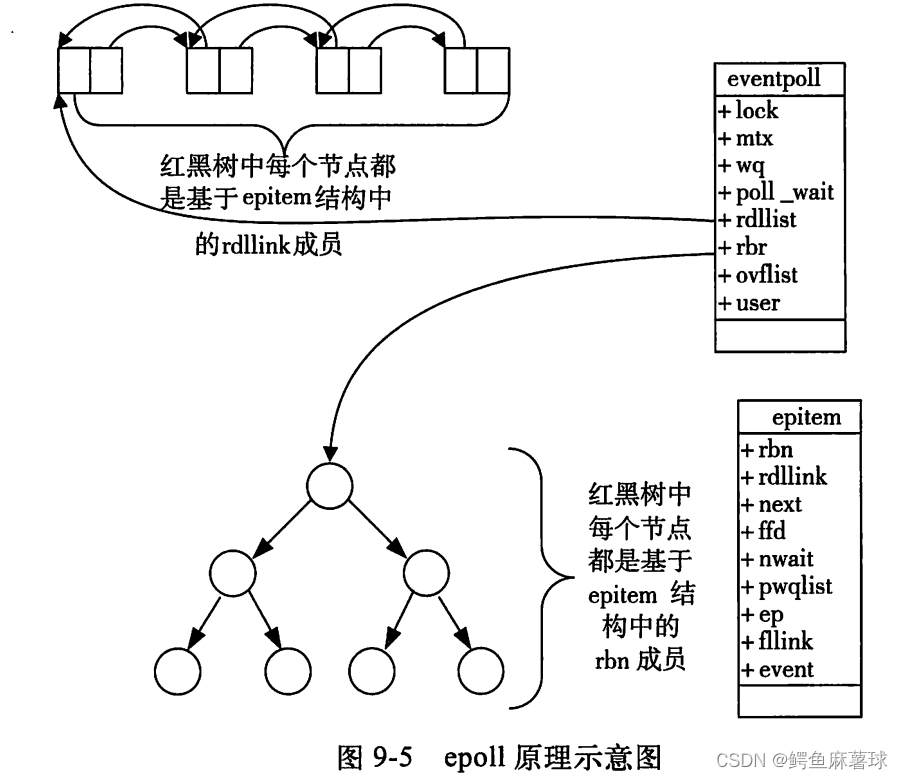
【Linux】IO多路复用——select,poll,epoll的概念和使用,三种模型的特点和优缺点,epoll的工作模式
文章目录 Linux多路复用1. select1.1 select的概念1.2 select的函数使用1.3 select的优缺点 2. poll2.1 poll的概念2.2 poll的函数使用2.3 poll的优缺点 3. epoll3.1 epoll的概念3.2 epoll的函数使用3.3 epoll的优点3.4 epoll工作模式 Linux多路复用 IO多路复用是一种操作系统的…...

Whisky完整指南:在macOS上运行Windows应用的终极解决方案
Whisky完整指南:在macOS上运行Windows应用的终极解决方案 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想要在Apple Silicon Mac上流畅运行Windows专属软件和游戏&…...

Ren`Py 引擎初探:从零搭建你的Python视觉小说项目
1. 为什么选择RenPy开发视觉小说? 第一次听说RenPy是在三年前,当时我正在寻找能用Python开发的游戏引擎。试过Unity、Unreal这些主流引擎后,发现它们要么需要学习C#,要么对2D支持不够友好。直到偶然在论坛看到有人用RenPy做文字冒…...

AI写专著高效途径:选对工具,一键生成20万字专著不是梦!
一、新手研究者撰写学术专著的困境 对于首次尝试撰写学术专著的研究者来说,写作的过程就像是在“摸石头过河”,其中充满了各种未知的障碍。选题上常常感到迷茫,难以在“有意义”与“可行性”之间找到合适的平衡,选题要么过于宏大…...
)
保姆级教程:从NCBI下载序列到MEGA7构建进化树(附拟南芥SPL15基因实战)
生物信息学实战:从基因检索到进化树构建的全流程解析 在分子生物学研究中,系统进化分析是理解基因家族演化关系的重要工具。对于刚接触生物信息学的学生来说,从零开始完成一个完整的进化树分析项目往往面临诸多挑战——如何获取目标基因序列…...

MAA助手:解放双手的明日方舟全自动游戏管理工具实战指南
MAA助手:解放双手的明日方舟全自动游戏管理工具实战指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://g…...

Git GitLab介绍
Git 是工具,GitLab 是使用这个工具的“工厂”或“协作平台”。它们是完全不同层面的东西,但紧密相关。下面是详细的对比:1. Git - 版本控制系统(核心工具)本质:一个开源的分布式版本控制软件,由…...
Translumo终极指南:3个简单技巧掌握实时屏幕翻译
Translumo终极指南:3个简单技巧掌握实时屏幕翻译 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾在游…...

终极指南:如何为yt-dlp-gui扩展新的视频平台支持
终极指南:如何为yt-dlp-gui扩展新的视频平台支持 【免费下载链接】yt-dlp-gui Windows GUI for yt-dlp 项目地址: https://gitcode.com/gh_mirrors/yt/yt-dlp-gui 你是否曾遇到过想要下载某个小众视频平台的视频,却发现yt-dlp-gui无法识别链接&am…...

基于龙芯2K1000LA的可信计算在工业边缘安全中的实践
1. 项目概述:当“可信计算”遇上工业边缘 最近在做一个工业数据采集与边缘处理的项目,客户对数据安全的要求提到了前所未有的高度。他们不仅担心数据在传输过程中被窃取,更担心边缘设备本身被恶意篡改,导致采集的数据在源头就“失…...

Beyond Compare 5密钥生成终极指南:快速激活与完全使用教程
Beyond Compare 5密钥生成终极指南:快速激活与完全使用教程 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare是一款广受欢迎的文件对比工具,但当30天试用期…...