【PYG】使用datalist定义数据集,创建一个包含多个Data对象的列表并使用DataLoader来加载这些数据
为了使用你提到的封装方式来创建一个包含多个 Data 对象的列表并使用 DataLoader 来加载这些数据,我们可以按照以下步骤进行:
- 创建数据:生成节点特征矩阵、边索引矩阵和标签。
- 封装数据:使用
Data对象将这些数据封装起来。 - 使用
DataLoader:确保批次数据的形状符合期望。
具体步骤
1. 创建数据
首先,我们创建节点特征矩阵、边索引矩阵和标签数据。
import torch
from torch_geometric.data import Data
from torch_geometric.loader import DenseDataLoader # 更新导入路径# 参数设置
num_samples = 100 # 样本数
num_nodes = 10 # 每个图中的节点数
num_node_features = 8 # 每个节点的特征数# 生成数据
features = [torch.randn((num_nodes, num_node_features)) for _ in range(num_samples)]
labels = [torch.randn((num_nodes, 1)) for _ in range(num_samples)]
adj_matrix = torch.zeros((num_nodes, num_nodes), dtype=torch.float)
for i in range(num_nodes):adj_matrix[i, (i + 1) % num_nodes] = 1adj_matrix[(i + 1) % num_nodes, i] = 1
print(adj_matrix)
2. 封装数据
使用 Data 对象将每个样本的数据封装起来。
data_list = [Data(x=features[i], adj=adj_matrix, y=labels[i]) for i in range(num_samples)]
3. 使用 DataLoader
# 创建 DataLoader
loader = DenseDataLoader(data_list, batch_size=32, shuffle=True)# 从 DenseDataLoader 中获取一个批次的数据并查看其形状
for data in loader:print("Batch node features shape:", data.x.shape) # 期望输出形状为 (32, 10, 8)print("Batch adjacency matrix shape:", data.adj.shape) # 期望输出形状为 (32, 10, 10)print("Batch labels shape:", data.y.shape) # 期望输出形状为 (32, 10, 1)break # 仅查看第一个批次的形状
总结
- 生成数据:我们生成了包含节点特征、边索引和标签的样本数据。
- 封装数据:我们使用
Data对象将每个样本的数据封装起来。
完整代码
import torch
from torch_geometric.data import Data
from torch_geometric.loader import DenseDataLoader # 更新导入路径# 参数设置
num_samples = 100 # 样本数
num_nodes = 10 # 每个图中的节点数
num_node_features = 8 # 每个节点的特征数# 生成数据
features = [torch.randn((num_nodes, num_node_features)) for _ in range(num_samples)]
labels = [torch.randn((num_nodes, 1)) for _ in range(num_samples)]
adj_matrix = torch.zeros((num_nodes, num_nodes), dtype=torch.float)
for i in range(num_nodes):adj_matrix[i, (i + 1) % num_nodes] = 1adj_matrix[(i + 1) % num_nodes, i] = 1
print(adj_matrix)data_list = [Data(x=features[i], adj=adj_matrix, y=labels[i]) for i in range(num_samples)]# 创建 DataLoader
loader = DenseDataLoader(data_list, batch_size=32, shuffle=True)# 从 DenseDataLoader 中获取一个批次的数据并查看其形状
for data in loader:print("Batch node features shape:", data.x.shape) # 期望输出形状为 (32, 10, 8)print("Batch adjacency matrix shape:", data.adj.shape) # 期望输出形状为 (32, 10, 10)print("Batch labels shape:", data.y.shape) # 期望输出形状为 (32, 10, 1)break # 仅查看第一个批次的形状
相关文章:

【PYG】使用datalist定义数据集,创建一个包含多个Data对象的列表并使用DataLoader来加载这些数据
为了使用你提到的封装方式来创建一个包含多个 Data 对象的列表并使用 DataLoader 来加载这些数据,我们可以按照以下步骤进行: 创建数据:生成节点特征矩阵、边索引矩阵和标签。封装数据:使用 Data 对象将这些数据封装起来。使用 D…...

【设计模式】【创建型5-2】【工厂方法模式】
文章目录 工厂方法模式工厂方法模式的结构示例产品接口具体产品工厂接口具体工厂客户端代码 实际的使用 工厂方法模式 工厂方法模式的结构 产品(Product):定义工厂方法所创建的对象的接口。 具体产品(ConcreteProduct࿰…...

python API自动化(Pytest+Excel+Allure完整框架集成+yaml入门+大量响应报文处理及加解密、签名处理)
1.pytest数据参数化 假设你需要测试一个登录功能,输入用户名和密码后验证登录结果。可以使用参数化实现多组输入数据的测试: 测试正确的用户名和密码登录成功 测试正确的用户名和错误的密码登录失败 测试错误的用户名和正确的密码登录失败 测试错误的用户名和密码登…...

【Postman学习】
Postman是一个非常流行的API开发和测试工具,广泛用于Web服务的开发、测试和调试。它提供了一个图形界面,允许用户轻松地构建、发送和管理HTTP(S)请求,同时查看和分析响应。下面是对Postman接口测试工具的详细解释: 1. Postman简介…...
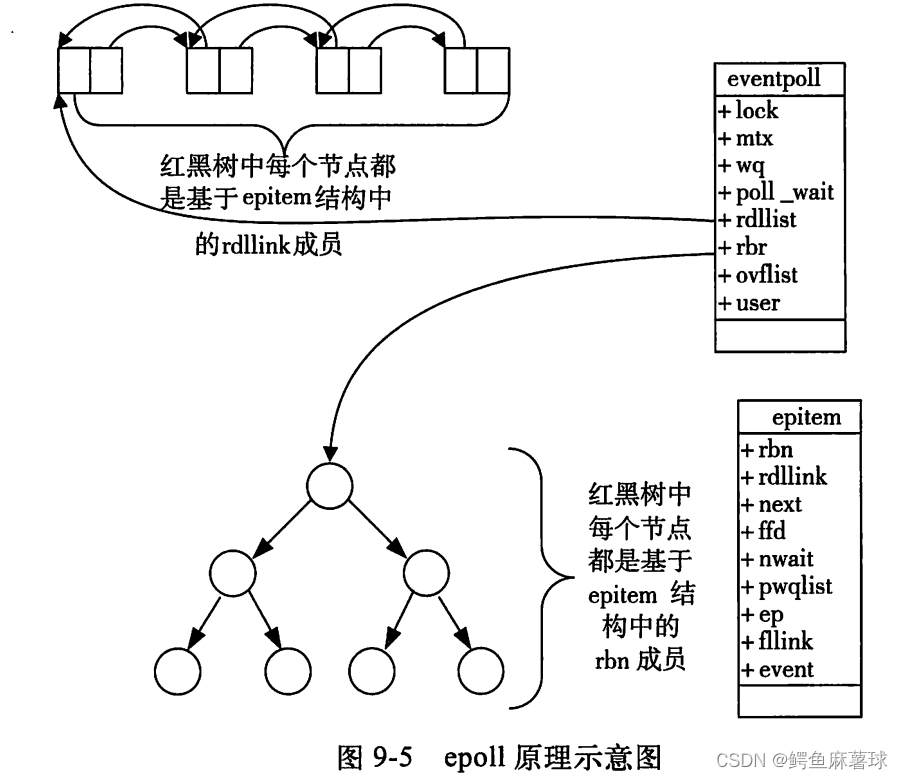
【Linux】IO多路复用——select,poll,epoll的概念和使用,三种模型的特点和优缺点,epoll的工作模式
文章目录 Linux多路复用1. select1.1 select的概念1.2 select的函数使用1.3 select的优缺点 2. poll2.1 poll的概念2.2 poll的函数使用2.3 poll的优缺点 3. epoll3.1 epoll的概念3.2 epoll的函数使用3.3 epoll的优点3.4 epoll工作模式 Linux多路复用 IO多路复用是一种操作系统的…...
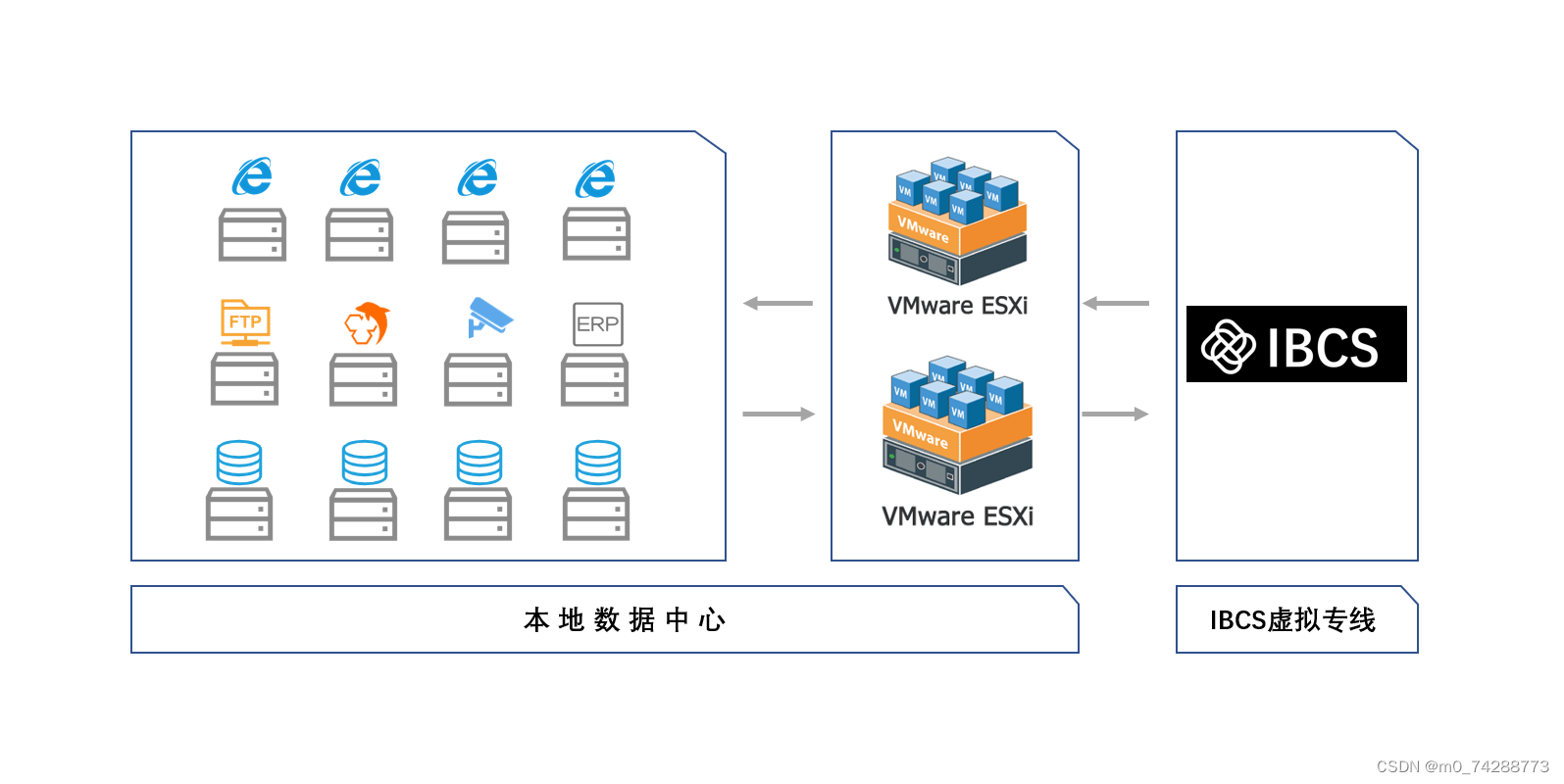
IBCS 虚拟专线——让企业用于独立IP
在当今竞争激烈的商业世界中,企业的数字化运营对网络和服务器的性能有着极高的要求。作为一家企业的 IT 主管,我深刻体会到了在网络和服务器配置方面所面临的种种挑战,以及 IBCS 虚拟专线带来的革命性改变。 我们企业在业务扩张的过程中&…...

驾驭巨龙:Perl中大型文本文件的处理艺术
驾驭巨龙:Perl中大型文本文件的处理艺术 Perl,这门被亲切称为“实用提取和报告语言”的编程语言,自从诞生之日起,就以其卓越的文本处理能力闻名于世。在面对庞大的文本文件时,Perl的强大功能更是得到了充分的体现。本…...

Kafka~特殊技术细节设计:分区机制、重平衡机制、Leader选举机制、高水位HW机制
分区机制 Kafka 的分区机制是其实现高吞吐和可扩展性的重要特性之一。 Kafka 中的数据具有三层结构,即主题(topic)-> 分区(partition)-> 消息(message)。一个 Kafka 主题可以包含多个分…...
springcloud-config 客户端启用服务发现client的情况下使用metadata中的username和password
为了让spring admin 能正确获取到 spring config的actuator的信息,在eureka的metadata中添加了metadata.user.user metadata.user.password eureka.instance.metadata-map.user.name${spring.security.user.name} eureka.instance.metadata-map.user.password${spr…...
)
云计算 | 期末梳理(中)
1. 经典虚拟机的特点 多态(Polymorphism):支持多种类型的OS。重用(Manifolding):虚拟机的镜像可以被反复复制和使用。复用(Multiplexing):虚拟机能够对物理资源时分复用。2. 系统接口 最基本的接口是微处理器指令集架构(ISA)。应用程序二进制接口(ABI)给程序提供使用硬件资源…...

pytest测试框架pytest-order插件自定义用例执行顺序
pytest提供了丰富的插件来扩展其功能,本章介绍插件pytest-order,用于自定义pytest测试用例的执行顺序。pytest-order是插件pytest-ordering的一个分支,但是pytest-ordering已经不再维护了,建议大家直接使用pytest-order。 官方文…...

吴恩达机器学习 第三课 week2 推荐算法(上)
目录 01 学习目标 02 推荐算法 2.1 定义 2.2 应用 2.3 算法 03 协同过滤推荐算法 04 电影推荐系统 4.1 问题描述 4.2 算法实现 05 总结 01 学习目标 (1)了解推荐算法 (2)掌握协同过滤推荐算法(Collabo…...

MySQL CASE 表达式
MySQL CASE表达式 一、CASE表达式的语法二、 常用场景1,按属性分组统计2,多条件统计3,按条件UPDATE4, 在CASE表达式中使用聚合函数 三、CASE表达式出现的位置 一、CASE表达式的语法 -- 简单CASE表达式 CASE sexWHEN 1 THEN 男WHEN 2 THEN 女…...

Unity3D 游戏数据本地化存储与管理详解
在Unity3D游戏开发中,数据的本地化存储与管理是一个重要的环节。这不仅涉及到游戏状态、玩家信息、游戏设置等关键数据的保存,还关系到游戏的稳定性和用户体验。本文将详细介绍Unity3D中游戏数据的本地化存储与管理的技术方法,并给出相应的代…...

昇思25天学习打卡营第1天|初学教程
文章目录 背景创建环境熟悉环境打卡记录学习总结展望未来 背景 参加了昇思的25天学习记录,这里给自己记录一下所学内容笔记。 创建环境 首先在平台注册账号,然后登录,按下图操作,创建环境即可 创建好环境后进入即可࿰…...
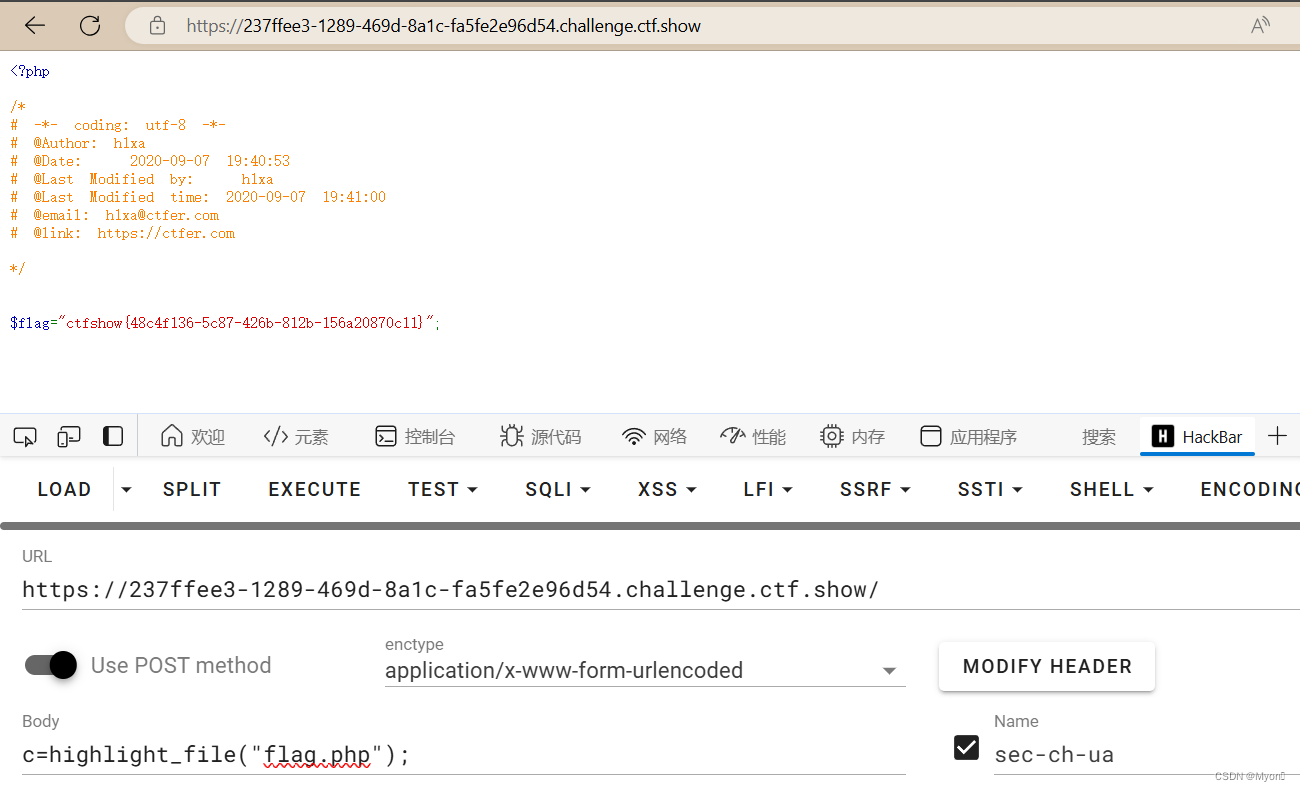
ctfshow-web入门-命令执行(web59-web65)
目录 1、web59 2、web60 3、web61 4、web62 5、web63 6、web64 7、web65 都是使用 highlight_file 或者 show_source 1、web59 直接用上一题的 payload: cshow_source(flag.php); 拿到 flag:ctfshow{9e058a62-f37d-425e-9696-43387b0b3629} 2、w…...
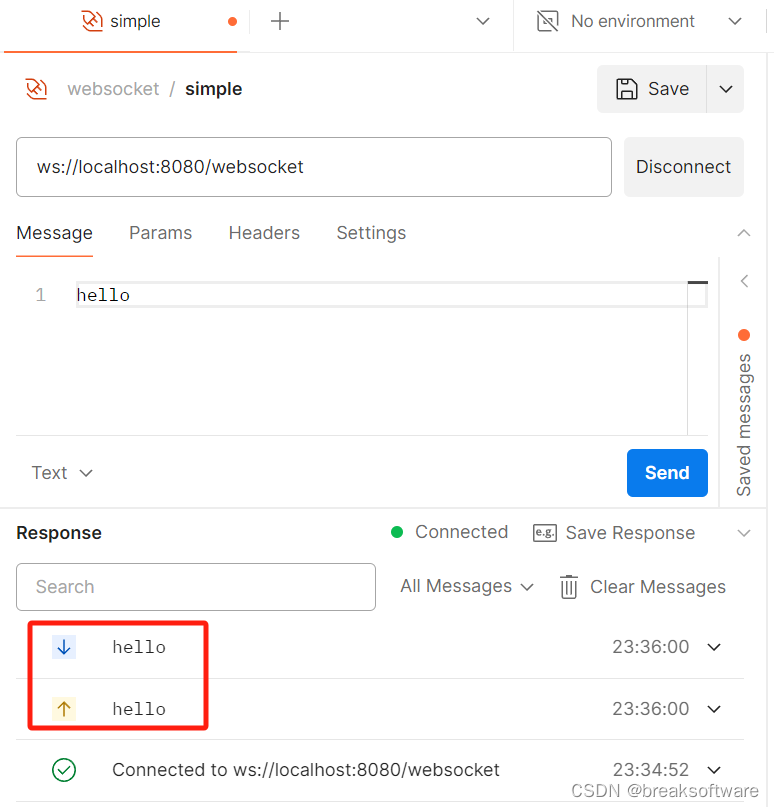
Websocket在Java中的实践——最小可行案例
大纲 最小可行案例依赖开启Websocket,绑定路由逻辑类 测试参考资料 WebSocket是一种先进的网络通信协议,它允许在单个TCP连接上进行全双工通信,即数据可以在同一时间双向流动。WebSocket由IETF标准化为RFC 6455,并且已被W3C定义为…...

python请求报错::requests.exceptions.ProxyError: HTTPSConnectionPool
在发送网页请求时,发现很久未响应,最后报错: requests.exceptions.ProxyError: HTTPSConnectionPool(hostsvr-6-9009.share.51env.net, port443): Max retries exceeded with url: /prod-api/getInfo (Caused by ProxyError(Unable to conne…...
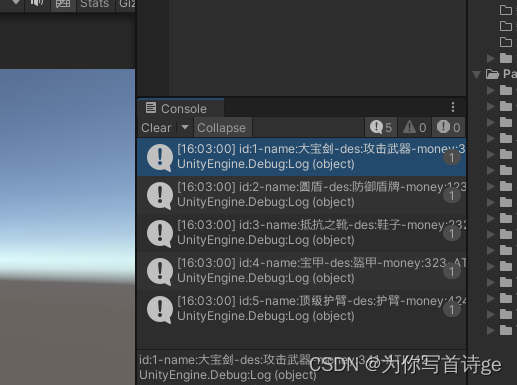
【Unity】Excel配置工具
1、功能介绍 通过Excel表配置表数据,一键生成对应Excel配置表的数据结构类、数据容器类、已经二进制数据文件,加载二进制数据文件获取所有表数据 需要使用Excel读取的dll包 2、关键代码 2.1 ExcelTool类 实现一键生成Excel配置表的数据结构类、数据…...
)
001 线性查找(lua)
文章目录 迭代器主程序 迭代器 -- 定义一个名为 linearSearch 的函数,它接受两个参数:data(一个数组)和 target(一个目标值) function linearSearch(data, target) -- 使用 for 循环遍历数组 data&…...

告别电脑“飞机起飞“噪音:FanControl风扇控制终极指南
告别电脑"飞机起飞"噪音:FanControl风扇控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tr…...

声明式工作流编排框架:从计划到执行的自动化实践
1. 项目概述:从“计划清单”到“框架”的蜕变如果你和我一样,在职业生涯中经历过从零到一构建复杂应用,或者维护过多个技术栈各异、需求多变的项目,那你一定对“计划”和“清单”这两个词深有感触。我们每天都在做计划,…...

MA730/MT6835/MT6825/MT6709磁编码器SPI通信实战:从寄存器配置到角度解析
1. 磁编码器SPI通信基础与选型指南 磁编码器作为现代电机控制和机器人系统中的核心传感器,其精度和响应速度直接影响整个系统的性能。MA730、MT6835、MT6825和MT6709这几款磁编码器在工业界应用广泛,它们都采用SPI接口进行通信,但在具体实现上…...

在高校科研项目中采用 Taotoken 实现多模型对比实验的便捷方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在高校科研项目中采用 Taotoken 实现多模型对比实验的便捷方案 高校科研团队在进行大模型相关的对比实验时,常常面临一…...

Cytoscape美化进阶:用cytoNCA等5款核心插件深度分析你的生物网络
Cytoscape美化进阶:用cytoNCA等5款核心插件深度分析你的生物网络 生物网络分析早已超越了简单的可视化阶段。当你在Cytoscape中绘制出第一个蛋白质相互作用网络时,那种成就感很快会被一个更迫切的问题取代:这些连接背后隐藏着怎样的生物学故事…...

Visual C++运行库终极指南:如何一键修复所有Windows程序依赖问题
Visual C运行库终极指南:如何一键修复所有Windows程序依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时突然弹出&…...

Claude代码生成Token预算管理实战:成本控制与智能优化策略
1. 项目概述与核心价值最近在折腾大模型应用开发,特别是围绕Claude这类顶尖的代码生成模型时,一个绕不开的痛点就是成本控制。模型调用是按Token计费的,而一个复杂的代码生成任务,动辄消耗成千上万个Token,账单不知不觉…...

终极指南:如何用免费软件完全掌控Windows电脑风扇噪音与散热平衡
终极指南:如何用免费软件完全掌控Windows电脑风扇噪音与散热平衡 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_T…...

告别硬盘数据丢失焦虑!电脑专属5种恢复方法,无踩坑,速存
日常使用电脑时,文件误删是高频突发状况——辛苦整理的办公文档、珍藏的生活影像、重要的程序安装包,一旦不小心删除,难免让人手足无措。好在2026年,随着数据存储技术的迭代与恢复工具的升级,电脑误删文件的恢复成功率…...

NHSE完整指南:动物森友会存档编辑器的终极使用手册
NHSE完整指南:动物森友会存档编辑器的终极使用手册 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》中收集稀有物品而烦恼吗?想快速…...