python API自动化(Pytest+Excel+Allure完整框架集成+yaml入门+大量响应报文处理及加解密、签名处理)
1.pytest数据参数化
假设你需要测试一个登录功能,输入用户名和密码后验证登录结果。可以使用参数化实现多组输入数据的测试:
测试正确的用户名和密码登录成功
测试正确的用户名和错误的密码登录失败
测试错误的用户名和正确的密码登录失败
测试错误的用户名和密码登录失败
在参数化中我们可以单参数、多参数、函数数据参数化
不管哪一种场景,它们都是数据不一样而产生的问题。核心步骤其实都是一样的---发送请求。
我们采取的思想就是进行数据分离--DDT数据驱动
# 1. 第一个情况:单数据
data = [值1,值2,值3...]
data = (值1,值2,值3...)单数据,通过对应的下标去进行获取【pytest会自己进行处理】# 2. 第一个情况:多数据,列表和元组嵌套
data = [("admin","123456"),("admin","123456"),("admin","123456"),...]
data = (["admin","123456"],["admin","123456"],...)
多数据,通过对应的下标去进行获取# 3.【重要】:列表嵌套字典
data = [{“name”:"admin","password":"123456"},
{“name”:"admin","password":"123456"},
{“name”:"admin","password":"123456"}
...]
多数据,通过对应的KEY去进行获取2. 引用对应的数据
在对应的方法上去加上一个装饰器即可引用:
@pytest.mark.parametrize(argnames,argvalues)
@pytest.mark.parametrize("变量名",引用的变量的值) # 引用上面的数据,并且取名加:变量名2. Pytest+Excel接口自动化框架
我们如何将对应的数据信息进行提取出来,我们如何使用python来读取Excel
读取excel的方法如下
import openpyxl
from collectionsFramework.P02_pytest_excel_allure.config import *class FileReader:"""专门用来读取和写入yaml、excel文件"""# 读取excel--openpyxl -- 文件格式:.xlsx@staticmethod # 直接通过类名进行调用def read_excel(file_path=CASEDATAURL, sheet_name=SHEETNAME):"""读取Excel文件,只支持 .xlsx文件:param file_path: 文件路径:return: excel文件数据,元组的格式"""# 打开现有的Excel文件或创建新的文件try:# 正常情况下直接打开workbook = openpyxl.load_workbook(file_path)except FileNotFoundError:workbook = openpyxl.Workbook()# 选择或创建指定的工作表if sheet_name in workbook.sheetnames:# 【正常】 判断有没有对应的shtttname ,有的话把对应的数据给我加载出来worksheet = workbook[sheet_name]else:# 没有的话,给我新建一个worksheet = workbook.create_sheet(sheet_name)# 获取列名 --- 把第2行的数据拿出来作为我们的key值headers = [cell.value for cell in worksheet[2]]# print("所有的key", headers)# 将数据存储为字典,并且放在我们data当中data = [] # 所有的数据# 把小的数据从第三行开始for row in worksheet.iter_rows(min_row=3, values_only=True):data.append(dict(zip(headers, row)))# data.append(dict(zip(headers, row)))# data.append()# dict(zip(headers, row)) # key 和 value 一一对应起来 ==={}workbook.close()# 所有的数据return dataif __name__ == '__main__':CaseData = FileReader.read_excel()print(CaseData)
EXCEL读取的方法封装
# -*- coding: utf-8 -*-
# @Time : 2023/11/8 20:55
# @Author : Hami
import json
import pytest
from collectionsFramework.P02_pytest_excel_allure.common.FileDataDriver import FileReader
from collectionsFramework.P02_pytest_excel_allure.api_keyword.api_key import ApiKeyclass TestCase:# 获取对应的数据 CaseData 需要从文档当中去进行读取CaseData = FileReader.read_excel()ak = ApiKey()@pytest.mark.parametrize("CaseData", CaseData)def testCase(self, CaseData):# 没一个对应的数据都来临,获取对应的接口请求的四要素# 1. 获取数据(四要素) 2. 发送请求 3.获取响应数据 4.断言# 1. 字典获取的方式依次拿到# url = CaseData["url"]+CaseData["path"]# params = eval(CaseData["params"])# headers = eval(CaseData["headers"])# data = eval(CaseData["data"])dict_data = {"url":CaseData["url"]+CaseData["path"],"params": eval(CaseData["params"]),"headers": eval(CaseData["headers"]),"data": eval(CaseData["data"])}if CaseData["type"] == "json":dict_data["data"] = json.dumps(dict_data["data"])# self.ak.post(url=url,....) # 不建议res = self.ak.post(**dict_data) # 不定长参数传值方式print(res)eval
eval() 函数是 Python 内置的一个函数,用于将字符串作为代码执行,并返回结果。
def add(a, b):
return a + b
result = eval("add(2, 3)")
print(result) # 输出: 5getattr()函数的应用
getattr() 函数是 Python 内置的一个函数,用于获取对象的属性或方法
getattr(object, name, default)
object : 表示要获取属性或方法的对象。
name : 表示要获取的属性或方法的名称。
default (可选): 表示当属性或方法不存在时的默认值
例子如下
"""
`getattr()` 函数是 Python 内置的一个函数,用于获取对象的属性或方法。
语法结构:
getattr(object, name, default)
- `object`: 表示要获取属性或方法的对象。
- `name`: 表示要获取的属性或方法的名称。
- `default` (可选): 表示当属性或方法不存在时的默认值。
"""
# 案例一:类当中只有属性
class MyClass:
name = "hami"
age = 18
obj = MyClass()
value = getattr(obj, "name")
print(value) # 输出: hami
# 案例二:类当中对应的属性不存在(有参数),如果直接参数不存在也没有给参数,报错
class MyClass:
name = "hami"
age = 18
obj = MyClass()
value = getattr(obj, "sex", "女")
print(value) # 输出: hami
# 案例三:类当中对应的方法,一定要记得调用(无参数)
class MyClass:
def greet(self):
print("Hello, world!")
obj = MyClass()
method = getattr(obj, "greet") # 返回对应的方法
method() # 输出: Hello, world!
# 案例四:类当中对应的方法,一定要记得调用(有参数)
class MyClass:
def greet(self,name,age):
print("您的姓名是: {},年龄是:{}".format(name,age))
obj = MyClass()
method = getattr(obj, "greet")("hami","25") # 您的姓名是hami,年龄是:25封装主函数
import json
import pytest
from collectionsFramework.P02_pytest_excel_allure.common.FileDataDriver import FileReader
from collectionsFramework.P02_pytest_excel_allure.api_keyword.api_key import ApiKey
from collectionsFramework.P02_pytest_excel_allure.config import *class TestCase:# 获取对应的数据 CaseData 需要从文档当中去进行读取# 1. 获取数据(四要素) 2. 发送请求 3.获取响应数据 4.断言CaseData = FileReader.read_excel()ak = ApiKey()@pytest.mark.parametrize("CaseData", CaseData)def testCase(self, CaseData):# -------------------------发送请求-------------------------------try:# 请求数据dict_data = {"url": CaseData["url"] + CaseData["path"],"params": eval(CaseData["params"]),"headers": eval(CaseData["headers"]),"data": eval(CaseData["data"])}if CaseData["type"] == "json":dict_data["data"] = json.dumps(dict_data["data"])except Exception:value = MSG_DATA_ERROR# ----待定----print("写入测试结果", value)else:# 得到对应的响应数据res = getattr(self.ak, CaseData["method"])(**dict_data)# -------------------------进行断言处理-------------------------------# 实际结果try:msg = self.ak.get_text(res.json(),CaseData["actualResult"])except Exception:value = MSG_EXDATA_ERROR# ----待定----print("写入测试结果", value)else:# 只会是一个分支语言,但是不会造成测试结果成功或者失败,所以必须无论如何都是需要断言if msg == CaseData["expectResult"]:value = MSG_ASSERT_OKelse:value = MSG_ASSERT_NO# ----待定----print("写入测试结果", value)finally:assert msg == CaseData["expectResult"],valueAllure报告日志及动态标题
import json
import pytest
from collectionsFramework.P02_pytest_excel_allure.common.FileDataDriver import FileReader
from collectionsFramework.P02_pytest_excel_allure.api_keyword.api_key import ApiKey
from collectionsFramework.P02_pytest_excel_allure.config import *import allureclass TestCase:# 获取对应的数据 CaseData 需要从文档当中去进行读取# 1. 获取数据(四要素) 2. 发送请求 3.获取响应数据 4.断言CaseData = FileReader.read_excel()ak = ApiKey()def __dynamic_title(self, CaseData):# # 动态生成标题# allure.dynamic.title(data[11])# 如果存在自定义标题if CaseData["caseName"] is not None:# 动态生成标题allure.dynamic.title(CaseData["caseName"])if CaseData["storyName"] is not None:# 动态获取story模块名allure.dynamic.story(CaseData["storyName"])if CaseData["featureName"] is not None:# 动态获取feature模块名allure.dynamic.feature(CaseData["featureName"])if CaseData["remark"] is not None:# 动态获取备注信息allure.dynamic.description(CaseData["remark"])if CaseData["rank"] is not None:# 动态获取级别信息(blocker、critical、normal、minor、trivial)allure.dynamic.severity(CaseData["rank"])@pytest.mark.parametrize("CaseData", CaseData)def testCase(self, CaseData):self.__dynamic_title(CaseData)# -------------------------发送请求-------------------------------try:# 请求数据dict_data = {"url": CaseData["url"] + CaseData["path"],"params": eval(CaseData["params"]),"headers": eval(CaseData["headers"]),"data": eval(CaseData["data"])}if CaseData["type"] == "json":dict_data["data"] = json.dumps(dict_data["data"])except Exception:value = MSG_DATA_ERROR# ----待定----print("写入测试结果", value)else:# 得到对应的响应数据res = getattr(self.ak, CaseData["method"])(**dict_data)# -------------------------进行断言处理-------------------------------# 实际结果try:msg = self.ak.get_text(res.json(),CaseData["actualResult"])except Exception:value = MSG_EXDATA_ERROR# ----待定----print("写入测试结果", value)else:# 只会是一个分支语言,但是不会造成测试结果成功或者失败,所以必须无论如何都是需要断言if msg == CaseData["expectResult"]:value = MSG_ASSERT_OKelse:value = MSG_ASSERT_NO# ----待定----print("写入测试结果", value)finally:assert msg == CaseData["expectResult"],value
3.Excel框架优化及Yaml入门
1.写入excel框架
我们在FileDataDriver.py, 增加一个写入excel的方法
@staticmethoddef writeDataToExcel(file_path=CASEDATAURL, sheet_name=SHEETNAME, row=None, column=None, value=None):# 打开现有的Excel文件或创建新的文件try:workbook = openpyxl.load_workbook(file_path)except FileNotFoundError:workbook = openpyxl.Workbook()# 选择或创建指定的工作表if sheet_name in workbook.sheetnames:worksheet = workbook[sheet_name]else:worksheet = workbook.create_sheet(sheet_name)# 写入数据到指定行和列worksheet.cell(row=row, column=column).value = value# 保存修改后的文件--- 所以执行过程当中excel是要关闭的状态workbook.save(file_path)
在config.py中写入对应的常量,我们就可以在对应的测试用例中修改代码如下
import json
import pytest
from YamlOptimization.P02_pytest_excel_allure.common.FileDataDriver import FileReader
from YamlOptimization.P02_pytest_excel_allure.api_keyword.api_key import ApiKey
from YamlOptimization.P02_pytest_excel_allure.config import *
import allureclass TestCase:# 获取对应的数据 CaseData 需要从文档当中去进行读取# 1. 获取数据(四要素) 2. 发送请求 3.获取响应数据 4.断言AllCaseData = FileReader.read_excel()ak = ApiKey()def __dynamic_title(self, CaseData):# # 动态生成标题# allure.dynamic.title(data[11])# 如果存在自定义标题if CaseData["caseName"] is not None:# 动态生成标题allure.dynamic.title(CaseData["caseName"])if CaseData["storyName"] is not None:# 动态获取story模块名allure.dynamic.story(CaseData["storyName"])if CaseData["featureName"] is not None:# 动态获取feature模块名allure.dynamic.feature(CaseData["featureName"])if CaseData["remark"] is not None:# 动态获取备注信息allure.dynamic.description(CaseData["remark"])if CaseData["rank"] is not None:# 动态获取级别信息(blocker、critical、normal、minor、trivial)allure.dynamic.severity(CaseData["rank"])@pytest.mark.parametrize("CaseData", AllCaseData)def testCase(self, CaseData):self.__dynamic_title(CaseData)# 写Excle的行和列row = CaseData["id"]column = 11# 初始化对应的值:res = Nonemsg = Nonevalue = None# -------------------------发送请求-------------------------------try:# 请求数据dict_data = {"url": CaseData["url"] + CaseData["path"],"params": eval(CaseData["params"]),"headers": eval(CaseData["headers"]),"data": eval(CaseData["data"])}if CaseData["type"] == "json":dict_data["data"] = json.dumps(dict_data["data"])except Exception:value = MSG_DATA_ERRORFileReader.writeDataToExcel(row=row,column=column,value=value)else:# 得到对应的响应数据res = getattr(self.ak, CaseData["method"])(**dict_data)# -------------------------进行断言处理-------------------------------# 实际结果try:msg = self.ak.get_text(res.json(), CaseData["actualResult"])except Exception:value = MSG_EXDATA_ERRORFileReader.writeDataToExcel(row=row,column=column,value=value)else:# 只会是一个分支语言,但是不会造成测试结果成功或者失败,所以必须无论如何都是需要断言if msg == CaseData["expectResult"]:value = MSG_ASSERT_OKelse:value = MSG_ASSERT_NOFileReader.writeDataToExcel(row=row,column=column,value=value)finally:assert msg == CaseData["expectResult"], value2.实现优化接口关联
思路:
- excel ---字段 {"key":"value"} ----{"变量名":"jsonpath值","变量名":"jsonpath值"}
{"token":"$..token","name":"$..name"}
2. 写一个方法:
循环遍历这个值 :{"token":"$..token","name":"$..name"}
遍历的过程当中,通过"$..token"提取具体的值:56465456456313521456 ---new_value
3. 定义一个全局变量:专门用来存放提取之后的数据。
all_val={"token":"56465456456313521456","name":"hami"}

代码如下:
def __json_extraction(self, CaseData, res):"""提取响应之后的数据:param CaseData: 当前的Case,主要获取需要提取数据的字段:jsonExData:param res:响应得到的对应的结果:return:"""try:if CaseData["jsonExData"]:Exdata = eval(CaseData["jsonExData"]) # {"VAR_TOKEN":"$..token","MSG":"$.msg"}print("需要提取的数据:>>>", Exdata)for key, value in Exdata.items():# 通过对应的jsonpath获取具体的数据new_value = self.ak.get_text(res.json(), value)self.all_var.update({key: new_value})print("提取出来的数据:>>>", self.all_var)else:print("需要提取的数据为空")except Exception:print("请检查你需要提取数据数据格式的正确性。")3.进行变量渲染
我们提取出来的casedata如下所示

我们可以看到此处的id和var_token没有具体的值,我们需要把具体的值渲染进去
all_val = {"VAR_TOKEN": "134324324324", "id": "158"}CaseData = {"id": 3,"url": "http://novel.hctestedu.com/book/queryBookDetail/{{id}}",'params': '{"application": "app",\n"application_client_type": "weixin",\n"token": "{{VAR_TOKEN}}"}'}CaseData = eval(Template(str(CaseData)).render(all_val))就用template来进行渲染
3.数据库操作(提取数据)
我们的思路如下:
- 框架能够连接数据库
- 执行SQL
- 把数据返回
思路:同json提取器
从数据库提取数据:Excle进行维护 ;思路:同json提取器
1.游标对象
在数据库中,游标是一个十分重要的概念。游标提供了一种从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条SQL 选择语句相关联因为游标由结果集(可以是零条,一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。当决定对结果进行处理时,必须声明一个指向该结果的游标
常用的方法:
cursor(): 创建游标对象
close(): 关闭游标对象
fetchone(): 得到结果集的下一行
fetchmany([size = cursor.arraysize]):得到结果集的下几行fetchall():得到结果集中剩下的所有行
excute(sql[,args]): 执行一个数据库查询或命令executemany(sql,args):执行多个数据库查询或命令
例子如下:
"""
在测试过程中偶然需要从数据库获取数据进行测试或者通过数据库的数据进行断言,这时候既要连接到数据库。python当中利用PySQL进行连接
安装:pip install pymysql
"""
import pymysql# 1. 配置数据库连接信息并连接
connection = pymysql.connect(host='shop-xo.hctestedu.com', # 数据库地址port=3306,user='api_test', # 数据库用户名password='Aa9999!', # 数据库密码db='shopxo_hctested', # 数据库名称
)# 2. 创建游标对象,使用它进行操作---人
cursor = connection.cursor()# 3. SQL语句---饭
sql = "SELECT username FROM sxo_user WHERE id = 75;"# 4. 使用游标对象去执行操作SQL
cursor.execute(sql)# 5. 得到结果集的下一行
result = cursor.fetchone()print(result) # 元组
# 6. 关闭数据库连接
cursor.close()2.我们继续优化代码 将数据库提取的操作写入api_key和测试用例当中
api中
@allure.step(">>>>>>:开始提取数据库的数据")def get_sqlData(self, sqlValue):""":param sqlValue: SQL,返回的数据是一个元组:return:"""import pymysql# 1. 配置数据库连接信息并连接connection = pymysql.connect(host=DB_HOST, # 数据库地址port=DB_PORT,user=DB_USER, # 数据库用户名password=DB_PASSWORD, # 数据库密码db=DB_NAME, # 数据库名称)# 2. 创建游标对象,使用它进行操作cursor = connection.cursor()# 4. 使用游标对象去执行操作SQLcursor.execute(sqlValue)# 5. 得到结果集的下一行result = cursor.fetchone()# 6. 关闭数据库连接cursor.close()return result[0]测试用例中
def __sql_extraction(self,CaseData):"""从数据库提取数据:param CaseData: 当前的Case,主要获取需要提取数据的字段:sqlExData:return:"""try:if CaseData["sqlExData"]:Exdata = eval(CaseData["sqlExData"]) # {"name":"SELECT username FROM sxo_user WHERE username='hami'","id":"SELECT id FROM sxo_user WHERE username='hami'"}print("SQL-需要提取的数据:>>>", Exdata)for key, value in Exdata.items():# 通过对应的sql获取具体的数据new_value = self.ak.get_sqlData(value)self.all_var.update({key: new_value})print("SQL-提取出来的数据:>>>", self.all_var)else:print("SQL-需要提取的数据为空")except Exception:print("SQL-请检查你需要提取数据数据格式的正确性。")4.数据库操作-数据库断言【一般是极为重要的接口我们去做】
- 检查数据库是否有这个用户? --- 数据库断言
- 是否能够正确的登录
思路:excel
- 期望结果:{"username":"yeye"}
- 实际结果:{"username":"SELECT username FROM sxo_user WHERE id=75"}
代码如下
def __sql_assertData(self, CaseData):res = Trueif CaseData["sqlAssertData"] and CaseData["sqlExpectRe ult"]:# 实际结果:从数据库读取出来的数据--字典的格式 # {"name":"SELECT username FROM sxo_user WHERE username='hami'","id":"SELECT id FROM sxo_user WHERE username='hami'"}realityData = eval(CaseData["sqlAssertData"])# 期望结果:{"name":"hami","id":75}expectData = json.loads(CaseData["sqlExpectResult"])realityDataDict = {}for key, value in realityData.items():# 通过对应的sql获取具体的数据new_value = self.ak.get_sqlData(value)realityDataDict.update({key: new_value})if expectData != realityDataDict:res = Falsereturn res整个侧事故用例代码如下
# -*- coding: utf-8 -*-
# @Time : 2023/11/8 20:55
# @Author : Hami
import json
import pytest
from YamlOptimization.P02_pytest_excel_allure.common.FileDataDriver import FileReader
from YamlOptimization.P02_pytest_excel_allure.api_keyword.api_key import ApiKey
from YamlOptimization.P02_pytest_excel_allure.config import *
import allure
from jinja2 import Template # 变量渲染class TestCase:# 获取对应的数据 CaseData 需要从文档当中去进行读取# 1. 获取数据(四要素) 2. 发送请求 3.获取响应数据 4.断言AllCaseData = FileReader.read_excel()ak = ApiKey()# 定义:all_val 存放提取出的数据all_var = {}def __dynamic_title(self, CaseData):# # 动态生成标题# allure.dynamic.title(data[11])# 如果存在自定义标题if CaseData["caseName"] is not None:# 动态生成标题allure.dynamic.title(CaseData["caseName"])if CaseData["storyName"] is not None:# 动态获取story模块名allure.dynamic.story(CaseData["storyName"])if CaseData["featureName"] is not None:# 动态获取feature模块名allure.dynamic.feature(CaseData["featureName"])if CaseData["remark"] is not None:# 动态获取备注信息allure.dynamic.description(CaseData["remark"])if CaseData["rank"] is not None:# 动态获取级别信息(blocker、critical、normal、minor、trivial)allure.dynamic.severity(CaseData["rank"])def __json_extraction(self, CaseData, res):"""提取响应之后的数据:param CaseData: 当前的Case,主要获取需要提取数据的字段:jsonExData:param res:响应得到的对应的结果:return:"""try:if CaseData["jsonExData"]:Exdata = eval(CaseData["jsonExData"]) # {"VAR_TOKEN":"$..token","MSG":"$.msg"}print("需要提取的数据:>>>", Exdata)for key, value in Exdata.items():# 通过对应的jsonpath获取具体的数据new_value = self.ak.get_text(res.json(), value)self.all_var.update({key: new_value})print("提取出来的数据:>>>", self.all_var)else:print("需要提取的数据为空")except Exception:print("请检查你需要提取数据数据格式的正确性。")def __sql_extraction(self, CaseData):"""从数据库提取数据:param CaseData: 当前的Case,主要获取需要提取数据的字段:sqlExData:return:"""try:if CaseData["sqlExData"]:Exdata = eval(CaseData["sqlExData"]) # {"name":"SELECT username FROM sxo_user WHERE username='hami'","id":"SELECT id FROM sxo_user WHERE username='hami'"}print("SQL-需要提取的数据:>>>", Exdata)for key, value in Exdata.items():# 通过对应的sql获取具体的数据new_value = self.ak.get_sqlData(value)self.all_var.update({key: new_value})print("SQL-提取出来的数据:>>>", self.all_var)else:print("SQL-需要提取的数据为空")except Exception:print("SQL-请检查你需要提取数据数据格式的正确性。")def __sql_assertData(self, CaseData):res = Trueif CaseData["sqlAssertData"] and CaseData["sqlExpectRe ult"]:# 实际结果:从数据库读取出来的数据--字典的格式 # {"name":"SELECT username FROM sxo_user WHERE username='hami'","id":"SELECT id FROM sxo_user WHERE username='hami'"}realityData = eval(CaseData["sqlAssertData"])# 期望结果:{"name":"hami","id":75}expectData = json.loads(CaseData["sqlExpectResult"])realityDataDict = {}for key, value in realityData.items():# 通过对应的sql获取具体的数据new_value = self.ak.get_sqlData(value)realityDataDict.update({key: new_value})if expectData != realityDataDict:res = Falsereturn res@pytest.mark.parametrize("CaseData", AllCaseData)def testCase(self, CaseData):self.__dynamic_title(CaseData)CaseData = eval(Template(str(CaseData)).render(self.all_var))print(CaseData)# 写Excle的行和列row = CaseData["id"]column = 11# 初始化对应的值:res = Nonemsg = Nonevalue = None# -------------------------发送请求-------------------------------try:# 请求数据dict_data = {"url": CaseData["url"] + CaseData["path"],"params": eval(CaseData["params"]),"headers": eval(CaseData["headers"]),"data": eval(CaseData["data"])}if CaseData["type"] == "json":dict_data["data"] = json.dumps(dict_data["data"])except Exception:value = MSG_DATA_ERRORFileReader.writeDataToExcel(row=row, column=column, value=value)else:# 得到对应的响应数据res = getattr(self.ak, CaseData["method"])(**dict_data)# -------------------------提取数据库的操作---------------------------self.__sql_extraction(CaseData)# -------------------------进行断言处理-------------------------------# 实际结果try:msg = self.ak.get_text(res.json(), CaseData["actualResult"])except Exception:value = MSG_EXDATA_ERRORFileReader.writeDataToExcel(row=row, column=column, value=value)else:# 只会是一个分支语言,但是不会造成测试结果成功或者失败,所以必须无论如何都是需要断言if msg == CaseData["expectResult"]:value = MSG_ASSERT_OK# 成功之后进行数据提取self.__json_extraction(CaseData, res)else:value = MSG_ASSERT_NOFileReader.writeDataToExcel(row=row, column=column, value=value)finally:assert msg == CaseData["expectResult"], value# -------------------------进行数据库断言处理-------------------------------try:res = self.__sql_assertData(CaseData) # False Trueexcept:print("SQL断言出现问题")value = "SQL断言出现问题"assert res, valueelse:assert resfinally:FileReader.writeDataToExcel(row=row, column=column, value=value)
5.yaml应用
yaml的概念:
YAML 的语法和其他高级语言类似,并且可以简单表达清单、散列表,标量等数据形态。它使用空白符号缩进和大量依赖外观的特色,特别适合用来表达或编辑数据结构、各种配置文件、倾印调试内容、文件大纲(例如:许多电子邮件标题格式和YAML非常接近)
YAML 的配置文件后缀为 .yml或.yaml,如:huace.yml
基本语法:
大小写敏感
使用缩进表示层级关系
缩进不允许使用tab,只允许空格
缩进的空格数不重要,只要相同层级的元素左对齐即可
'#' 表示注释
Yaml当中如果是数字字符的话,一定要加双引号(不加就是一个整型)
数据类型
纯量:字符串/数字 ,直接写就好了
列表:用符号去代替: -
字典:key : value
符号后面必须要有对应空格
我们的yaml中可以这样写
data:
-id: "0001"name: "qsdd"
-id: "0002"name: "yeyeyeye"
可以成功转换为json格式
也可以这样写:
data: [{ "id": "0001"},{ "id": "0002"}]也可以转换为json格式
excel格式的转换
方法一:
- {"id":"0001","name":"hami"}
-{"id":"0002","name":"hami"}
方法二:
- id: "0001"name: hami1
-id: 0002name: hami2效果:[{"id":"0001","name":"hami"},{"id":"0002","name":"hami"}]excel转换为yaml格式
代码如下
"""
YAML 是 "YAML Ain't a Markup Language" -- 数据格式
YAML 的配置文件后缀为 .yml或.yam,如:huace.yml 。1.1 基本语法
- 大小写敏感
- 使用缩进表示层级关系
- 缩进不允许使用tab,只允许空格
- 缩进的空格数不重要,只要相同层级的元素左对齐即可
- '#' 表示注释YAML 支持以下几种数据类型:
- 对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
- 数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
- 纯量(scalars):单个的、不可再分的值 -- 任意的数据类型对象格式: key: value
数组格式: -可以在在线网址先确定格式的正确性:https://tool.p2hp.com/tool-format-yaml/安装:pip install pyyaml
"""
# 1. 读取数据
import yaml# file_path = "yamlData/test_yaml_04.yaml"
file_path = "yamlData/x_testFavor.yaml"
with open(file_path, 'r', encoding="utf-8") as file:data = yaml.safe_load(file)
print(data)# # 2. 修改数据
# data[1]["res"] = "执行失败"
#
# # 3. 写入数据
# with open(file_path, 'w', encoding="utf-8") as file:
# # allow_unicode=True,避免将中文字符转换为 Unicode 转义序列
# yaml.dump(data, file, allow_unicode=True)
对yaml进行读写
我们在专门用来读写yaml和excel的py文件中新增一个方法
@staticmethoddef write_yaml(data, file_path=YAMLDATA):"""写入yaml文件,写入无序没有关系,通过key获取数据:param data: 需要写入的数据:param file_path: 文件路径:return:"""with open(file_path, 'w', encoding='utf-8') as file:# 可以结合异常处理进行封装try:yaml.dump(data, file, allow_unicode=True)print("YAML数据写入成功。")except yaml.YAMLError as e:print(f"YAML数据写入失败: {e}")对框架进行修改
我们改成读取yaml文件
对应的读取读取数据源的方法需要修改成: AllCaseData = FileReader.read_yaml()
写入到Yaml文件,所以无需行号去进行记录,可删除变量: row、cell
因为通过Yaml读取出来的本身就是json,所以 dict_data 这个变量值,有可能
是字典,也有可能是字符串,所以为了灵活起见,统一改成如下,同时也可以直接去掉eval方法即可
# 扩展:不做强制要求
# 字符串
# input_string = "{'name':'Alice', 'age':'25', 'city':'New York'}"
# 字典
input_string = {'name':'Alice', 'age':'25', 'city':'New York'}print("转之前:", type(input_string)) # 字符串
# 如果input_string类型是str 则 转成字典eval(input_string); 否则的话:直接输出 ( else input_string)
result = eval(input_string) if isinstance(input_string, str) else input_string
print("转之后:", type(result)) # 字典
print(result)
就是判断值是字典还是字符串 是字符串就转为字典
我们只需要在测试用例中修改读写的数据

再根据情况修改上述的转换格式的代码 即可
回写数据到yaml
首先我们写入的时候是写入所有的数据到data 当中
如,我们所有读取出来的数据是AllCaseData,比如如下格式
[{id":0,"caseName":"登录接口","result":nall},
{id":1,"caseName":"加入购物车","result":nall}]
通过参数化方式我们每次能够拿到一条数据,比如你要修改第一个这条数据,可以
CaseData["result"] = value重点:但是你修改的只是这一条数据,直接写入就会不正确(覆盖其它的数据)。
所以,正确的做法是:这里的CaseData["id"] 代表下标。
AllCaseData[CaseData["id"] ] = valueyaml+allure+pytest框架如下所示:
import json
import pytest
from YamlOptimization.pytest_yaml_allure.common.FileDataDriver import FileReader
from YamlOptimization.pytest_yaml_allure.api_keyword.api_key import ApiKey
from YamlOptimization.pytest_yaml_allure.config import *
import allure
from jinja2 import Template # 变量渲染class TestCase:# 获取对应的数据 CaseData 需要从文档当中去进行读取# 1. 获取数据(四要素) 2. 发送请求 3.获取响应数据 4.断言AllCaseData = FileReader.read_yaml()ak = ApiKey()# 定义:all_val 存放提取出的数据all_var = {}def __dynamic_title(self, CaseData):# # 动态生成标题# allure.dynamic.title(data[11])# 如果存在自定义标题if CaseData["caseName"] is not None:# 动态生成标题allure.dynamic.title(CaseData["caseName"])if CaseData["storyName"] is not None:# 动态获取story模块名allure.dynamic.story(CaseData["storyName"])if CaseData["featureName"] is not None:# 动态获取feature模块名allure.dynamic.feature(CaseData["featureName"])if CaseData["remark"] is not None:# 动态获取备注信息allure.dynamic.description(CaseData["remark"])if CaseData["rank"] is not None:# 动态获取级别信息(blocker、critical、normal、minor、trivial)allure.dynamic.severity(CaseData["rank"])def __json_extraction(self, CaseData, res):"""提取响应之后的数据:param CaseData: 当前的Case,主要获取需要提取数据的字段:jsonExData:param res:响应得到的对应的结果:return:"""try:if CaseData["jsonExData"]:Exdata = CaseData["jsonExData"] # {"VAR_TOKEN":"$..token","MSG":"$.msg"}print("需要提取的数据:>>>", Exdata)for key, value in Exdata.items():# 通过对应的jsonpath获取具体的数据new_value = self.ak.get_text(res.json(), value)self.all_var.update({key: new_value})print("提取出来的数据:>>>", self.all_var)else:print("需要提取的数据为空")except Exception:print("请检查你需要提取数据数据格式的正确性。")def __sql_extraction(self, CaseData):"""从数据库提取数据:param CaseData: 当前的Case,主要获取需要提取数据的字段:sqlExData:return:"""try:if CaseData["sqlExData"]:Exdata = CaseData["sqlExData"] # {"name":"SELECT username FROM sxo_user WHERE username='hami'","id":"SELECT id FROM sxo_user WHERE username='hami'"}print("SQL-需要提取的数据:>>>", Exdata)for key, value in Exdata.items():# 通过对应的sql获取具体的数据new_value = self.ak.get_sqlData(value)self.all_var.update({key: new_value})print("SQL-提取出来的数据:>>>", self.all_var)else:print("SQL-需要提取的数据为空")except Exception:print("SQL-请检查你需要提取数据数据格式的正确性。")def __sql_assertData(self, CaseData):res = Trueif CaseData["sqlAssertData"] and CaseData["sqlExpectResult"]:# 实际结果:从数据库读取出来的数据--字典的格式 # {"name":"SELECT username FROM sxo_user WHERE username='hami'","id":"SELECT id FROM sxo_user WHERE username='hami'"}realityData = CaseData["sqlAssertData"]# 期望结果:{"name":"hami","id":75}expectData = CaseData["sqlExpectResult"]realityDataDict = {}for key, value in realityData.items():# 通过对应的sql获取具体的数据new_value = self.ak.get_sqlData(value)realityDataDict.update({key: new_value})if expectData != realityDataDict:res = Falsereturn res@pytest.mark.parametrize("CaseData", AllCaseData)def testCase(self, CaseData):self.__dynamic_title(CaseData)CaseData = eval(Template(str(CaseData)).render(self.all_var))print(CaseData)# 写Yaml的下标row = CaseData["id"]# 初始化对应的值:res = Nonemsg = Nonevalue = None# 知识:是否断言# is_assert = True# -------------------------发送请求-------------------------------try:# 请求数据params = eval(CaseData["params"]) if isinstance(CaseData["params"], str) else CaseData["params"]dict_data = {"url": CaseData["url"] + CaseData["path"],"params": params,"headers": CaseData["headers"],"data": CaseData["data"]}if CaseData["type"] == "json":dict_data["data"] = json.dumps(dict_data["data"])except Exception:value = MSG_DATA_ERRORCaseData["result"] = valueelse:# 得到对应的响应数据res = getattr(self.ak, CaseData["method"])(**dict_data)# -------------------------提取数据库的操作---------------------------self.__sql_extraction(CaseData)# -------------------------进行断言处理-------------------------------# 实际结果try:msg = self.ak.get_text(res.json(), CaseData["actualResult"])except Exception:value = MSG_EXDATA_ERRORCaseData["result"] = valueelse:# 只会是一个分支语言,但是不会造成测试结果成功或者失败,所以必须无论如何都是需要断言if msg == CaseData["expectResult"]:value = MSG_ASSERT_OK# 成功之后进行数据提取self.__json_extraction(CaseData, res)else:# is_assert = Falsevalue = MSG_ASSERT_NOCaseData["result"] = valuefinally:assert msg == CaseData["expectResult"], value# -------------------------进行数据库断言处理-------------------------------try:res = self.__sql_assertData(CaseData) # False Trueexcept:print("SQL断言出现问题")value = "SQL断言出现问题"assert res, valueelse:assert resfinally:CaseData["result"] = value# -------------------------把当前的CaseData值写入:可以通过后置处理方法去处理-------------------------------self.AllCaseData[row] = CaseDataFileReader.write_yaml(self.AllCaseData)
4.大量响应报文处理及加解密、签名处理
1.全字段断言-DeepDiff
deepdiff 是一个Python库,用于比较Python数据结构(例如字典、列表、JSON等)之间的差异。它不仅可以比较简单的Python数据类型,还可以比较任意深度或复杂度的数据结构。
在Python中,我们经常需要比较两个JSON对象的异同。例如测试中,我们需要比较预期输出和实际输出是否相同。而在开发中,我们也需要比较两个JSON对象的差异以便维护。使用 deepdiff 库,可以轻松处理这些场景
DeepDiff库的主要模块如下:
1. deepdiff.DeepDiff :这是DeepDiff库的核心模块,提供了比较两个对象之间差异的功能。它可以比较字典、列表、集合等复杂对象,并返回差异的详细信息。
2. deepdiff.DeepSearch :这是一个工具类,用于在复杂对象中搜索指定值。它可以深度遍历对象,并返回找到的匹配项的路径信息。
3. deepdiff.DeepHash :这个模块用于生成复杂对象的哈希值。它可以递归地计算对象的哈希值,并考虑对象中的差异
2.deepdiff常用操作
如果实际请求结果和预期值的json数据都一致,那么会返回 {} 空字典,否则会返回对比差异的结果,接口测试中我们也可以根据这个特点进行断言
如果对比结果不同,将会给出下面对应的返回
1. type_changes:类型改变的key=
2. values_changed:值发生变化的key
3. dictionary_item_added:字典key添加
4. dictionary_item_removed:字段key删除
案例如下
from deepdiff import DeepDiff
"""
总结:
1. 当数据没有差异的时候: 返回是一个空字典 {}
2. 当数据有差异的情况,会根据实际情况显示:1. type_changes:类型改变的key2. values_changed:值发生变化的key3. dictionary_item_added:字典key添加4. dictionary_item_removed:字段key删除
"""# 期望结果
exjson = {'code': 0,"message": "成功","data": {"total": 28,"id": 123}
}# 实际结果
sjjson= {'code': 0,"message": "成功","data": {"total": 28,"id": 123}
}# 1. 如果两个json 是一样的情况下,返回的值是一个空字典
res = DeepDiff(exjson,sjjson)
print(res)实际结果
sjjson = {'code': "0", # 类型不一样"message": "成功","data": {"total": 28,"id": 123}
}# 2. 类型错误会提示:{'type_changes':XXXXXXXXX},root代表的是根节点
res = DeepDiff(exjson, sjjson)
print(res) # {'type_changes':XXXXXXXXX}
sjjson = {'code': 100, # 类型一样,数据不一样"message": "成功","data": {"total": 28,"id": 123}
}
3. 当你的值有改变,会显示 :values_changed
res = DeepDiff(exjson, sjjson)
print(res) # 'values_changed': {"root['code']": {'new_value': 100, 'old_value': 0}}}sjjson = {'code': 0, # 类型一样,数据不一样"message": "成功","data": {"total": 28,"id": 123},"add": "长沙"
}
res = DeepDiff(exjson, sjjson)
print(res) # {'dictionary_item_added': [root['add']]}sjjson = {"message": "成功","data": {"total": 28,"id": 123}
}
res = DeepDiff(exjson, sjjson)
print(res) # {'dictionary_item_removed': [root['code']]}
忽略排序、大小写及某个字段\
其实,在实际接口断言中,可能需要校验的字段顺序不一样,又或者有一些字段值不需要,为了解决这类问题,Deepdiff也提供了相信的参数,只需要在比较的时候加入,传入对应参数即可
例如 我们遇到一个相应数据:
期望结果:
{"code":"200","ordeid":"OR567456415645646",data:"241523415361123132132"}
实际结果:【未定】--- ID 是不确定的,是后端自动生成的,过滤字段。
{"code":"200","ordeid":"OR567456415645646",data:"241523415361123132132"}
ignore_order(忽略排序)
ignore_string_case(忽略大小写)
exclude_paths排除指定的字段
from deepdiff import DeepDiff"""
总结:
1. 当数据没有差异的时候: 返回是一个空字典 {}
2. 当数据有差异的情况,会根据实际情况显示:1. type_changes:类型改变的key2. values_changed:值发生变化的key3. dictionary_item_added:字典key添加4. dictionary_item_removed:字段key删除
"""
from deepdiff import DeepDiff# 1. 字典是以key,顺序没有关系
# json1 = {"name": "hami", "age": 18}
# json2 = {"age": 18, "name": "hami"}# res = DeepDiff(json1,json2)
# print(res)# 2. 定义两个列表进行比较,列表有序的,按照顺序去进行对比
# list1 = [1, 2, 3]
# list2 = [3, 2, 1]# 有序列表,会返回对应的数据: {'values_changed': {'root[0]': {'new_value': 3, 'old_value': 1}, 'root[2]': {'new_value': 1, 'old_value': 3}}}
# res = DeepDiff(list1, list2)
# print(res)
# # 过滤对应的顺序: ignore_order=True ------{}
# res = DeepDiff(list1, list2, ignore_order=True)
# print(res)# 3. 过滤大小写的操作: ignore_string_case=True
# json1 = {"name": "hami", "age": 18}
# json2 = {"age": 18, "name": "Hami"}
#
# res = DeepDiff(json1, json2)
# print(res)
# # 过滤字符的大小写(不区分)
# res = DeepDiff(json1, json2, ignore_string_case=True)
# print(res)# 4. 忽略某个字段 exclude_paths={"age"} --- 用的最多
json1 = {"code": "200", "name": "hami", "usercode": "431123456789", "age": 18}
json2 = {"code": "200", "name": "hami", "usercode": "431123456789", "age": 20}
res = DeepDiff(json1, json2)
print(res)
res = DeepDiff(json1, json2, exclude_paths={"age"})
# res = DeepDiff(json1, json2, exclude_paths={"root['age']"})
print(res)
其他参数:
from deepdiff import DeepDiff"""
总结:
1. 当数据没有差异的时候: 返回是一个空字典 {}
2. 当数据有差异的情况,会根据实际情况显示:1. type_changes:类型改变的key2. values_changed:值发生变化的key3. dictionary_item_added:字典key添加4. dictionary_item_removed:字段key删除
"""
from deepdiff import DeepDiff# 忽略数字
from decimal import Decimal
# 高精度的十进制计算,避免了浮点数运算中的精度丢失问题。
t1 = Decimal('10.01') # 数字类型
t2 = 10.01# print(DeepDiff(t1, t2))
# print(DeepDiff(t1, t2, ignore_numeric_type_changes=True))# 忽略字符串
res = DeepDiff(b'hello', 'hello', ignore_string_type_changes=True)
# print(res)# 打印出来的格式可以指定:
# TREE_VIEW = 'tree'
# TEXT_VIEW = 'text' # 默认
t1 = {"name": "yanan", "pro": {"sh": "shandong", "city": ["zibo", "weifang"]}}
t2 = {"name": "yanan", "pro": {"sh": "shandong", "city": ["taian", "weifang"]}}
# 显示格式:tree
diff1 = DeepDiff(t1, t2, view='tree')
print(diff1)
# 默认为text # 可读性
diff2 = DeepDiff(t1, t2, view='text')
print(diff2)
搜索模块
我们使用deepdiff还可以用来搜索
from deepdiff import DeepSearchobj = ["long somewhere", "string", 0, "somewhere great!"]
item = 'some' # 大小写敏感的
ds = DeepSearch(obj, item, case_sensitive=True)
print(ds) 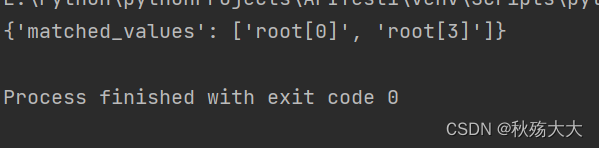
返回的结果就是其下标值
哈希模块-DeepHash
DeepHash模块是DeepDiff库中的一个模块,用于生成复杂对象的哈希值。它可以递归地计算对象的哈希值,并考虑对象中的差异。可以方便地计算复杂对象的哈希值,并在需要时用于对象的唯一标识或数据校验等用途
from deepdiff import DeepHash
# 可以把对应的Value 转成对应的Hasht1 = {"name": "yanan", "pro": {"sh": "shandong", "city": ["zibo", "weifang"]}}
res = DeepHash(t1)
print(res)

如图显示,输出的结果就是一串hash值
3.全字段对比
deepdiff的封装
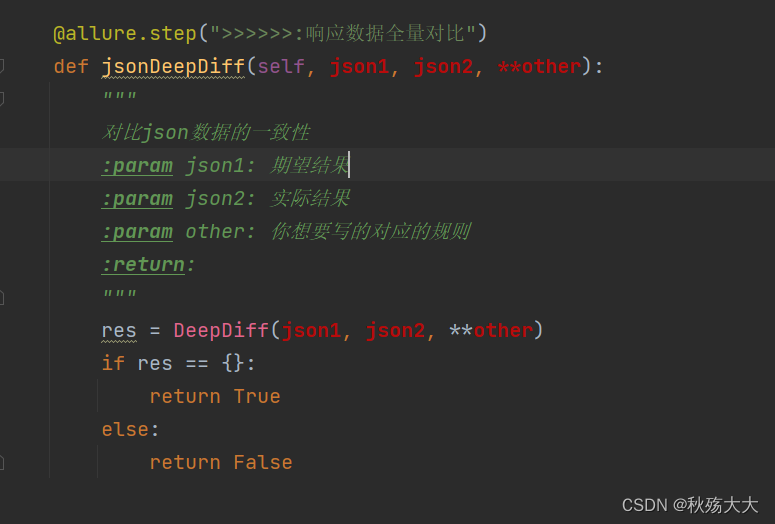
from deepdiff import DeepDiffdef jsonDeepDiff(json1, json2, **other):"""对比json数据的一致性:param json1: 期望结果:param json2: 实际结果:param other: 你想要写的对应的规则:return:"""res = DeepDiff(json1, json2, **other)if res == {}:return Trueelse:return False
将deepdiff结果之前的框架
我们在deepdiff封装在关键字封装的类之中和对应的测试用例中
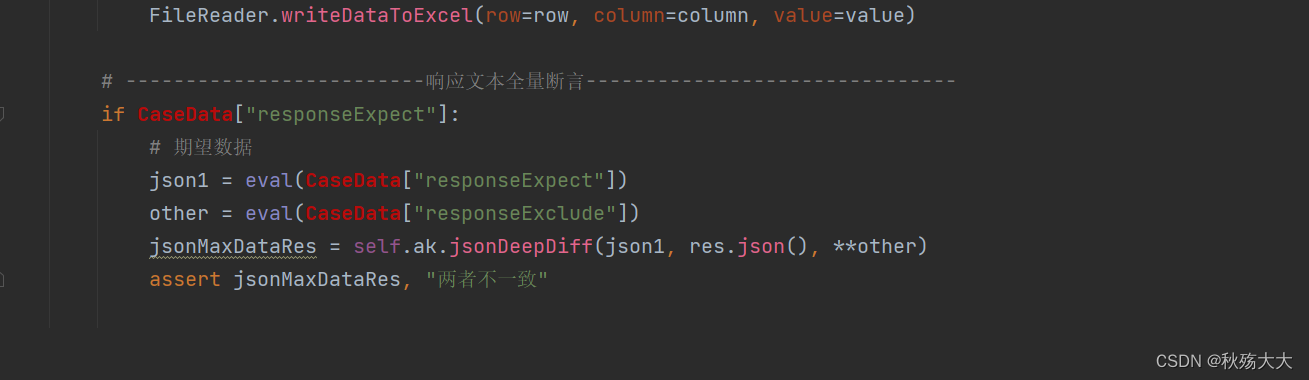
另外我们还要避免excel表中的值为空的情况,因此,我们需要再请求数据的地方进行修改

4.加密
核心思路:如果说对应的参数需要进行加密的话,在传参的时候在key当中通过 @ 符号进行标识
对我们的data对进行遍历,判断key的[0] == @
例如:{"@name":"tony","@password":"123456"}
我们先把加密方法进行封装
"""
对称加密:加密和解密使用的是同一把钥匙,即:使用相同的密匙对同一密码进行加密和解密。
常用的加密方法:DES、3DES、AES...(AES算法是目前最常用的对称加密算法)
"""
import base64
from Crypto.Cipher import AESclass EncryptDate:# 构造方法def __init__(self, key):# 类属性self.key = key.encode("utf-8") # 初始化密钥self.length = AES.block_size # 初始化数据块大小 :16位self.aes = AES.new(self.key, AES.MODE_ECB) # 初始化AES,ECB模式的实例# 截断函数,去除填充的字符self.unpad = lambda date: date[0:-ord(date[-1])]# 缺几位数据就补齐多少位数据:16的倍数def pad(self, text): # text == tony"""#填充函数,使被加密数据的字节码长度是block_size的整数倍"""count = len(text.encode('utf-8')) # count = 4add = self.length - (count % self.length) # 求它们相差的位数# add = 16- (4%16) === 16 - 4 == 12entext = text + (chr(add) * add)# entext = “tony” + (chr(add) * 12 ) === entext == tony# print("entext的数据是:",entext)return entext# 加密函数def encrypt(self, encrData): # 加密函数 encrData == tony (16位)res = self.aes.encrypt(self.pad(encrData).encode("utf8")) # self.aes.encrypt(tony)msg = str(base64.b64encode(res), encoding="utf8")return msg# 解密函数def decrypt(self, decrData): # 解密函数 XbXHJrNLwoTVcyfqM9eTgQ==# 从base64编码转回来res = base64.decodebytes(decrData.encode("utf8"))# 将数据进行对应的解密:XbXHJrNLwoTVcyfqM9eTgQ==msg = self.aes.decrypt(res).decode("utf8")# print("msg的值:",msg)# 把转回来的数据后面的字符去掉。return self.unpad(msg)key = "1234567812345678"
ENCRYPTAES = EncryptDate(key)
然后我们再进行加密处理
在excel和yaml的处理py文件中 写上对应的方法:
@staticmethoddef data_EncryptDateAES(data):newdata = {} # 去掉前面@符号同时数据进行加密for key in data:if key[0] == "@":# 需要加密处理newdata[key[1:]] = ENCRYPTAES.encrypt(data[key])else:# 不需要加密处理newdata[key] = data[key]return newdata
5.接口签名Sign封装
数字签名是一种用于验证数据完整性和身份认证的密码学技术。它通过使用私钥对数据进行加密来创建一个唯一的数字标识,该标识称为签名。验证者可以使用相应的公钥对签名进行解密和验证,以确认数据的完整性和真实性
token \ session \ cookie \ 签名(sign) --- 都是用来鉴权的
它们的区别是什么?
token \ session \ cookie
token 其实用来代表是系统当中的某个用户 --- 一般正常情况下是写在header
session \ cookie 是你发送请求的时候自带的.浏览器会自带这个对应的数据
session \ cookie 区别是什么?
存储位置不同: cookie -客户端 ; session--服务端(会话)
大小限制不同: cookie - 有大小限制; session 没有大小限制
安全隐患不同: cookie 存在安全隐患,可以拦截或找你本地文件得到你存储的信息
时效性不同: cookie 是时效性, session关闭浏览器时就消失
签名(sign) --- 是接口当中的一个字段. 发送消息\发送文档\保证安全性\需要在接口传一波数据.
通过算法得到一串数据(类似于token)
相关文章:
python API自动化(Pytest+Excel+Allure完整框架集成+yaml入门+大量响应报文处理及加解密、签名处理)
1.pytest数据参数化 假设你需要测试一个登录功能,输入用户名和密码后验证登录结果。可以使用参数化实现多组输入数据的测试: 测试正确的用户名和密码登录成功 测试正确的用户名和错误的密码登录失败 测试错误的用户名和正确的密码登录失败 测试错误的用户名和密码登…...

【Postman学习】
Postman是一个非常流行的API开发和测试工具,广泛用于Web服务的开发、测试和调试。它提供了一个图形界面,允许用户轻松地构建、发送和管理HTTP(S)请求,同时查看和分析响应。下面是对Postman接口测试工具的详细解释: 1. Postman简介…...
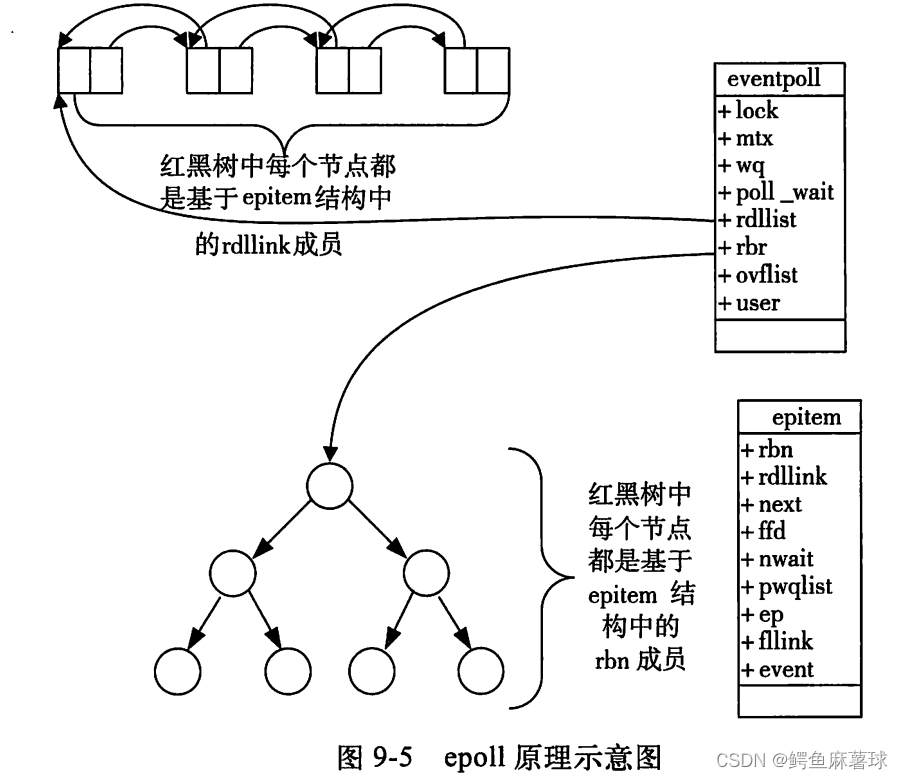
【Linux】IO多路复用——select,poll,epoll的概念和使用,三种模型的特点和优缺点,epoll的工作模式
文章目录 Linux多路复用1. select1.1 select的概念1.2 select的函数使用1.3 select的优缺点 2. poll2.1 poll的概念2.2 poll的函数使用2.3 poll的优缺点 3. epoll3.1 epoll的概念3.2 epoll的函数使用3.3 epoll的优点3.4 epoll工作模式 Linux多路复用 IO多路复用是一种操作系统的…...
IBCS 虚拟专线——让企业用于独立IP
在当今竞争激烈的商业世界中,企业的数字化运营对网络和服务器的性能有着极高的要求。作为一家企业的 IT 主管,我深刻体会到了在网络和服务器配置方面所面临的种种挑战,以及 IBCS 虚拟专线带来的革命性改变。 我们企业在业务扩张的过程中&…...

驾驭巨龙:Perl中大型文本文件的处理艺术
驾驭巨龙:Perl中大型文本文件的处理艺术 Perl,这门被亲切称为“实用提取和报告语言”的编程语言,自从诞生之日起,就以其卓越的文本处理能力闻名于世。在面对庞大的文本文件时,Perl的强大功能更是得到了充分的体现。本…...

Kafka~特殊技术细节设计:分区机制、重平衡机制、Leader选举机制、高水位HW机制
分区机制 Kafka 的分区机制是其实现高吞吐和可扩展性的重要特性之一。 Kafka 中的数据具有三层结构,即主题(topic)-> 分区(partition)-> 消息(message)。一个 Kafka 主题可以包含多个分…...
springcloud-config 客户端启用服务发现client的情况下使用metadata中的username和password
为了让spring admin 能正确获取到 spring config的actuator的信息,在eureka的metadata中添加了metadata.user.user metadata.user.password eureka.instance.metadata-map.user.name${spring.security.user.name} eureka.instance.metadata-map.user.password${spr…...
)
云计算 | 期末梳理(中)
1. 经典虚拟机的特点 多态(Polymorphism):支持多种类型的OS。重用(Manifolding):虚拟机的镜像可以被反复复制和使用。复用(Multiplexing):虚拟机能够对物理资源时分复用。2. 系统接口 最基本的接口是微处理器指令集架构(ISA)。应用程序二进制接口(ABI)给程序提供使用硬件资源…...

pytest测试框架pytest-order插件自定义用例执行顺序
pytest提供了丰富的插件来扩展其功能,本章介绍插件pytest-order,用于自定义pytest测试用例的执行顺序。pytest-order是插件pytest-ordering的一个分支,但是pytest-ordering已经不再维护了,建议大家直接使用pytest-order。 官方文…...

吴恩达机器学习 第三课 week2 推荐算法(上)
目录 01 学习目标 02 推荐算法 2.1 定义 2.2 应用 2.3 算法 03 协同过滤推荐算法 04 电影推荐系统 4.1 问题描述 4.2 算法实现 05 总结 01 学习目标 (1)了解推荐算法 (2)掌握协同过滤推荐算法(Collabo…...

MySQL CASE 表达式
MySQL CASE表达式 一、CASE表达式的语法二、 常用场景1,按属性分组统计2,多条件统计3,按条件UPDATE4, 在CASE表达式中使用聚合函数 三、CASE表达式出现的位置 一、CASE表达式的语法 -- 简单CASE表达式 CASE sexWHEN 1 THEN 男WHEN 2 THEN 女…...

Unity3D 游戏数据本地化存储与管理详解
在Unity3D游戏开发中,数据的本地化存储与管理是一个重要的环节。这不仅涉及到游戏状态、玩家信息、游戏设置等关键数据的保存,还关系到游戏的稳定性和用户体验。本文将详细介绍Unity3D中游戏数据的本地化存储与管理的技术方法,并给出相应的代…...

昇思25天学习打卡营第1天|初学教程
文章目录 背景创建环境熟悉环境打卡记录学习总结展望未来 背景 参加了昇思的25天学习记录,这里给自己记录一下所学内容笔记。 创建环境 首先在平台注册账号,然后登录,按下图操作,创建环境即可 创建好环境后进入即可࿰…...
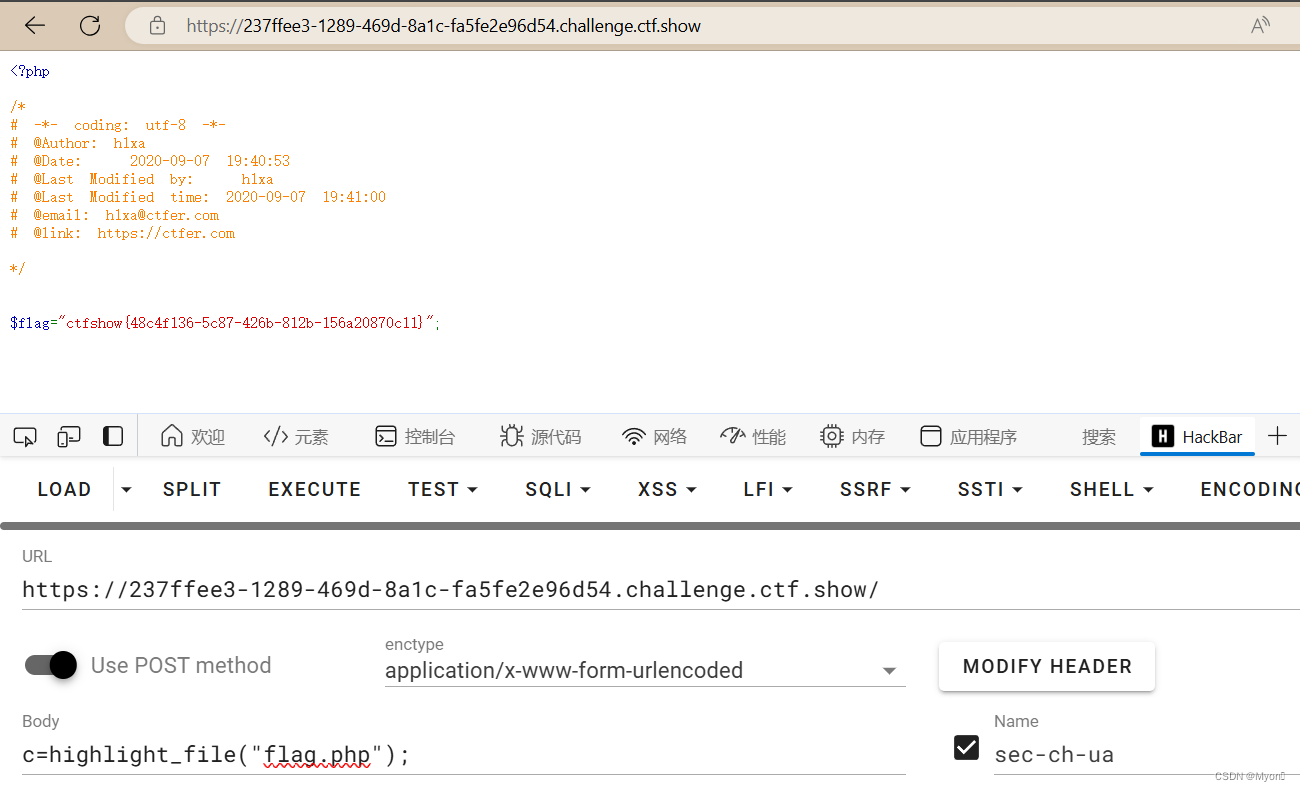
ctfshow-web入门-命令执行(web59-web65)
目录 1、web59 2、web60 3、web61 4、web62 5、web63 6、web64 7、web65 都是使用 highlight_file 或者 show_source 1、web59 直接用上一题的 payload: cshow_source(flag.php); 拿到 flag:ctfshow{9e058a62-f37d-425e-9696-43387b0b3629} 2、w…...
Websocket在Java中的实践——最小可行案例
大纲 最小可行案例依赖开启Websocket,绑定路由逻辑类 测试参考资料 WebSocket是一种先进的网络通信协议,它允许在单个TCP连接上进行全双工通信,即数据可以在同一时间双向流动。WebSocket由IETF标准化为RFC 6455,并且已被W3C定义为…...

python请求报错::requests.exceptions.ProxyError: HTTPSConnectionPool
在发送网页请求时,发现很久未响应,最后报错: requests.exceptions.ProxyError: HTTPSConnectionPool(hostsvr-6-9009.share.51env.net, port443): Max retries exceeded with url: /prod-api/getInfo (Caused by ProxyError(Unable to conne…...
【Unity】Excel配置工具
1、功能介绍 通过Excel表配置表数据,一键生成对应Excel配置表的数据结构类、数据容器类、已经二进制数据文件,加载二进制数据文件获取所有表数据 需要使用Excel读取的dll包 2、关键代码 2.1 ExcelTool类 实现一键生成Excel配置表的数据结构类、数据…...
)
001 线性查找(lua)
文章目录 迭代器主程序 迭代器 -- 定义一个名为 linearSearch 的函数,它接受两个参数:data(一个数组)和 target(一个目标值) function linearSearch(data, target) -- 使用 for 循环遍历数组 data&…...

数据结构之链表
储备知识: 线性表 :一对一的数据所组成的关系称为线性表。 线性表是一种数据内部的逻辑关系,与存储形式无关线性表既可以采用连续的顺序存储(数组),也可以采用离散的链式存储(链表)顺序表和链表都称为线性表 顺序存储就是将数据存…...

【小工具】 Unity相机宽度适配
相机默认是根据高度适配的,但是在部分游戏中需要根据宽度进行适配 实现步骤 定义标准屏幕宽、高判断标准屏幕宽高比与当前的是否相等通过**(标准宽度/当前宽度) (标准高度 / 当前高度)**计算缩放调整相机fieldOfView即…...
蓝牙Mesh、Beacon都靠它:深入浅出图解蓝牙广播帧的8种类型与应用场景
蓝牙广播帧全解析:从Beacon到Mesh的8种通信范式 当你在商场收到精准的优惠推送,当智能灯泡自动组网完成,当无线耳机实现多人共享音频——这些场景背后都藏着一个低调的通信英雄:蓝牙广播帧。不同于需要"握手"的连接通信…...

Canvas动画实战:从入门到精通
Canvas动画实战:从入门到精通 前言 各位前端小伙伴,不知道你们有没有想过在浏览器中实现复杂的动画效果?Canvas可以让你实现各种炫酷的动画! 我曾经开发过一个在线绘图应用,使用Canvas实现了流畅的画笔效果和动画回放功…...

硬件工程师的‘第一板’:从最小系统设计到PCB Layout的STM32实战指南
STM32最小系统设计实战:从原理到PCB的工程化思维 作为一名硬件工程师,第一次独立完成PCB设计时的忐忑至今记忆犹新。那块承载着STM32最小系统的绿色电路板,不仅是我职业生涯的"第一板",更是一次从理论到实践的完整跨越。…...

SLO-Warden:基于错误预算的智能SLO守护平台设计与实践
1. 项目概述:一个面向SLO的智能守护者在云原生和微服务架构成为主流的今天,服务的稳定性和可靠性不再是“锦上添花”,而是“生死攸关”的底线。作为一线的运维工程师或SRE,我们每天都在和各种监控指标、告警风暴作斗争。传统的监控…...
怎么选,告别‘卖家秀’惨案)
从LED灯珠到手机屏幕:一文搞懂色温、显色指数(CRI)怎么选,告别‘卖家秀’惨案
从LED灯珠到手机屏幕:色温与显色指数的科学选购指南 深夜伏案工作时,你是否总觉得眼睛干涩疲劳?网购衣物到手后颜色总与屏幕显示相差甚远?餐厅美食拍出来总是暗淡无光?这些困扰的根源往往在于——光源质量。当我们面对…...

终极B站缓存视频转换指南:快速将m4s无损转换为MP4
终极B站缓存视频转换指南:快速将m4s无损转换为MP4 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经因为B站视频突然下架而感…...

Unity GLTF模型导入终极教程:5分钟掌握GLTFUtility完整指南
Unity GLTF模型导入终极教程:5分钟掌握GLTFUtility完整指南 【免费下载链接】GLTFUtility Simple GLTF importer for Unity 项目地址: https://gitcode.com/gh_mirrors/gl/GLTFUtility GLTFUtility是Unity开发者必备的GLTF模型导入工具,能够让你在…...
)
Midjourney V6树胶重铬酸盐输出崩溃?紧急修复指南(含--sref自定义光敏响应曲线参数实测数据)
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6树胶重铬酸盐输出崩溃现象与本质溯源 现象复现与触发条件 Midjourney V6 在启用 --style raw 且 prompt 中包含化学术语(如“重铬酸盐”、“树胶”、“potassium dichromate”…...

Cool-Request全局请求头配置终极指南:告别重复配置的API测试新体验
Cool-Request全局请求头配置终极指南:告别重复配置的API测试新体验 【免费下载链接】cool-request IDEA API、Java Method debug tools 项目地址: https://gitcode.com/gh_mirrors/co/cool-request 你是否厌倦了在每个API请求中重复配置相同的认证Token、内容…...

ArcMap栅格图像平滑滤波实战:从焦点统计到重采样的多工具对比与应用
1. 栅格图像平滑滤波基础概念与应用场景 当你拿到一张遥感影像时,可能会发现图像上存在一些"瑕疵"——比如拼接产生的条带痕迹、传感器噪声或者不自然的过渡区域。这时候就需要用到栅格图像平滑滤波技术了。简单来说,这就像给照片做"美颜…...