【Python从入门到进阶】59、Pandas库中Series对象的操作(二)
接上篇《58、Pandas库中Series对象的操作(一)》
上一篇我们讲解了Pandas库中Series对象的基本概念、对象创建和操作,本篇我们来继续学习Series对象的运算、函数应用、时间序列操作,以及Series的案例实践。
一、Series对象的运算
1. 数值型数据的算术运算
Pandas的Series对象支持基本的算术运算,包括加法、减法、乘法和除法。这些运算可以在Series对象之间进行,也可以与标量(即单一数值)进行。在进行算术运算时,Pandas会尝试进行元素级别的对齐(element-wise alignment),如果Series对象的索引不同,Pandas会尝试基于索引进行匹配,或者在某些情况下使用NaN(Not a Number)来填充缺失的位置。
加法:通过+运算符或add()方法实现。
减法:通过-运算符或sub()方法实现。
乘法:通过*运算符或mul()方法实现。
除法:通过/运算符或div()方法实现。
代码示例:
import pandas as pd# 创建Series对象
s1 = pd.Series([1, 2, 3, 4])
s2 = pd.Series([10, 20, 30, 40])# 加法
s_add = s1 + s2
print("加法:", s_add)# 减法
s_sub = s1 - s2
print("减法:", s_sub)# 乘法
s_mul = s1 * s2
print("乘法:", s_mul)# 除法
s_div = s1 / s2
print("除法:", s_div)2. 布尔索引与数据筛选
Pandas的Series对象支持基于布尔索引(Boolean Indexing)的数据筛选。布尔索引允许你根据条件表达式的结果来选取Series中的元素。当条件表达式作用于Series对象时,会返回一个与原始Series具有相同索引的布尔型Series,其中True表示满足条件的元素,False表示不满足条件的元素。然后,你可以使用这个布尔型Series来索引原始Series,从而选取满足条件的元素。
条件表达式:使用比较运算符(如==、<、>等)创建条件表达式。
布尔索引:将条件表达式的结果用作索引,选取满足条件的元素。
代码示例:
import pandas as pd# 创建Series对象
s = pd.Series(['apple','banana','cherry','date'])# 布尔索引选以'a'开头的元素
filtered_s = s[s.str.startswith('a')]
print("筛选结果:", filtered_s)3. 排序操作
Pandas的Series对象提供了两种排序方法:sort_values()和sort_index()。
sort_values():根据Series中的值进行排序。默认情况下,数据按升序排序,但也可以指定ascending=False进行降序排序。
sort_index():根据Series的索引进行排序。同样地,也可以指定ascending参数来控制排序顺序。
这两种方法都会返回一个新的已排序的Series对象,原始Series对象保持不变。
代码示例:
import pandas as pd# 创建带有索引的Series对象
s = pd.Series([3, 1, 4, 1, 5], index=['d', 'b', 'a', 'c', 'e'])# 根据值排序
s_sorted_values = s.sort_values()
print("按值排序:", s_sorted_values)# 根据索引排序
s_sorted_index = s.sort_index()
print("按索引排序:", s_sorted_index)4. 统计信息
Pandas的Series对象提供了许多统计方法,用于计算数据的描述性统计量。这些统计方法包括:
mean():计算Series中元素的均值(平均值)。
std():计算Series中元素的标准差。
max():返回Series中的最大值。
min():返回Series中的最小值。
此外,还有其他一些常用的统计方法,如median()(中位数)、mode()(众数)、quantile()(分位数)等。这些方法可以帮助你快速了解数据的分布情况和特征。
代码示例:
import pandas as pd # 创建Series对象
s = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9]) # 计算统计信息
mean_value = s.mean()
std_value = s.std()
max_value = s.max()
min_value = s.min() print("均值:", mean_value)
print("标准差:", std_value)
print("最大值:", max_value)
print("最小值:", min_value)二、Series对象的函数应用
1. 使用apply()方法应用自定义函数
apply()方法是Pandas中Series对象的一个强大工具,它允许用户应用自定义函数到Series中的每个元素。通过apply()方法,用户可以轻松地执行复杂的元素级操作,这些操作可能无法通过内置的Pandas函数直接实现。
示例:定义一个函数,该函数将Series中的每个元素平方,并使用apply()方法将其应用到Series对象上。
import pandas as pd # 自定义函数,计算平方
def square(x): return x ** 2 # 创建Series对象
s = pd.Series([1, 2, 3, 4, 5]) # 使用apply()方法应用自定义函数
s_squared = s.apply(square)
print(s_squared)2. 使用map()方法应用字典映射
map()方法允许用户将一个字典中的键-值对映射到Series中的元素。当Series中的元素是字典的键时,这些元素将被替换为对应的值。这对于数据转换和分类特别有用。
示例:创建一个字典,将一组数字映射到它们的字符串表示形式,并使用map()方法将其应用到Series对象上。
import pandas as pd # 创建字典映射
mapping = {1: 'one', 2: 'two', 3: 'three', 4: 'four', 5: 'five'} # 创建Series对象
s = pd.Series([1, 2, 3, 4, 5]) # 使用map()方法应用字典映射
s_mapped = s.map(mapping)
print(s_mapped)3. 使用str属性进行字符串操作
对于包含字符串的Series对象,Pandas提供了str属性,该属性包含了一系列用于字符串操作的方法。这些方法与Python内置的字符串方法类似,但可以在整个Series对象上高效地应用。
示例:使用str.upper()方法将Series中的字符串转换为大写,并使用str.contains()方法检查字符串是否包含特定的子字符串。
import pandas as pd # 创建包含字符串的Series对象
s = pd.Series(['apple', 'banana', 'cherry', 'Date', 'apple pie']) # 使用str.upper()方法转换为大写
s_upper = s.str.upper()
print(s_upper) # 使用str.contains()方法检查是否包含'apple'
contains_apple = s.str.contains('apple')
print(contains_apple)4.pct_change()函数
pct_change()函数是Pandas库中Series和DataFrame对象的一个方法,用于计算当前元素与前一元素之间的百分比变化。它对于时间序列数据特别有用,因为它可以帮助你快速了解数据是如何随时间变化的。
具体来说,pct_change()方法计算的是当前元素与前一个元素之间的差异,然后将其除以前一个元素(得到的结果是一个比率),再乘以100(将结果转换为百分比)。第一个元素的百分比变化通常是NaN(不是数字),因为没有前一个元素可以与之比较。下面是一个简单的例子来说明pct_change()是如何工作的:
import pandas as pd # 创建一个简单的 Series
s = pd.Series([100, 105, 102, 110, 108]) # 计算百分比变化
change = s.pct_change() print(change)输出是这样的:
0 NaN
1 0.050000
2 -0.028571
3 0.078431
4 -0.018182
dtype: float64解释:
第一个元素的百分比变化是 NaN,因为没有前一个元素可以与之比较。
第二个元素的百分比变化是 (105 - 100) / 100 * 100 = 5%。
第三个元素的百分比变化是 (102 - 105) / 105 * 100 = -2.8571%。
以此类推...
默认情况下,pct_change() 会计算与前一个元素的百分比变化,但你也可以通过传递一个整数参数来计算与前面多个元素的百分比变化。例如,s.pct_change(2)会计算当前元素与两个前面的元素的百分比变化。
三、Series对象的时间序列操作
1. 转换为日期时间格式
Pandas 提供了一个非常方便的函数 to_datetime(),可以将 Series 对象中的字符串或其他格式的数据转换为日期时间格式。这在进行时间序列分析时非常重要。
示例:将一个包含日期字符串的 Series 转换为日期时间格式。
import pandas as pd # 创建一个包含日期字符串的 Series
dates_str = pd.Series(['2023-01-01', '2023-01-02', '2023-01-03']) # 使用 to_datetime() 转换为日期时间格式
dates_dt = pd.to_datetime(dates_str)
print(dates_dt)2. 时间序列的日期组件提取
对于日期时间格式的 Series,Pandas 提供了 .dt 访问器,它允许你提取日期时间对象的各个组件,如年、月、日、小时等。
示例:从日期时间格式的 Series 中提取年份和月份。
# 假设 dates_dt 已经是日期时间格式的 Series # 提取年份
years = dates_dt.dt.year
print(years) # 提取月份
months = dates_dt.dt.month
print(months)3. 时间序列的位移
shift() 方法允许你沿着索引轴(通常是时间轴)移动数据。这对于时间序列分析中的滞后或领先分析非常有用。示例:将时间序列数据向前移动一个单位(例如,一天)。
# 假设 dates_dt 及其对应的值 series 是我们的时间序列数据
values = pd.Series([56, 44, 79], index=dates_dt)# 值向前移动一个单位(日期)
shifted_values = values.shift(1)
print(shifted_values)# 计算数据的变动情况(当前数据 - 前一天数据)
value_changes = values - shifted_values# 打印数据变动情况
print("数据变动情况:")
print(value_changes)注意:位移后的第一个值将会是 NaN,因为没有前一天的数据可供参考。
4. 时间序列的重采样
resample() 方法允许你根据指定的频率重新采样时间序列数据。这对于将高频数据转换为低频数据(如每日数据转换为每月数据)或将低频数据转换为高频数据(通过插值或填充)非常有用。示例:将每日数据重采样为每月数据,并计算每月的平均值。
# 假设 values 是每日数据的时间序列# 重采样为每月数据,并计算平均值
monthly_mean = values.resample('ME').mean()
# 这里应该是前面56, 44, 79这一月份书所有数据的平均值
# (56+44+79)/3 = 59.666667
print(monthly_mean)在这个例子中,'M' 表示月份,'MS' 通常用来表示月份的开始,'MD' 通常用来表示月份的结束。Pandas 支持多种频率代码,如 'D'(天)、'H'(小时)等。重采样后,你会得到一个具有新频率的时间序列数据。
四、Series案例实践:股票数据分析
在本案例实践中,我们将展示如何使用Pandas的Series对象对股票数据进行分析和处理。我们将分析一个假设的股票数据集,该数据集包含了某只股票在一段时间内的每日收盘价。
1. 数据准备
假设我们已经有了一个简单的字典,它包含了某只股票几天的收盘价。
import pandas as pd # 假设的收盘价数据
stock_data = { '2023-01-01': 100, '2023-01-02': 102, '2023-01-03': 101, '2023-01-04': 103, '2023-01-05': 105
} # 将字典转换为Pandas Series对象,并设置日期为索引
stock_prices = pd.Series(stock_data)
stock_prices.index = pd.to_datetime(stock_prices.index)2. 数据可视化
使用Matplotlib库来绘制收盘价的时间序列图。
import matplotlib.pyplot as plt # 绘制收盘价的时间序列图
# 调用matplotlib.pyplot模块的figure函数创建一个新的图形窗口,并设置其大小
plt.figure(figsize=(10, 5)) # 调用Series对象的plot方法绘制时间序列图
# 这里的title参数设置了图形的标题
stock_prices.plot(title='Stock Price Over Time', grid=True) # 设置x轴的标签,即日期
plt.xlabel('Date') # 设置y轴的标签,即收盘价
plt.ylabel('Close Price') # 调用plt.show()函数显示图形
plt.show()这段代码的主要目的是使用matplotlib库来绘制一个表示股票收盘价的时间序列图。通过plt.figure()创建一个新的图形窗口,并设置其大小。然后,通过stock_prices.plot()调用Series对象的plot方法,绘制出时间序列图,并设置图形的标题为“Stock Price Over Time”。接着,使用plt.xlabel()和plt.ylabel()分别设置x轴和y轴的标签。最后,调用plt.show()来显示图形。
3. 数据分析
计算每日的收益率(即相对于前一日的百分比变化)。
# 计算每日收益率
returns = stock_prices.pct_change() # 显示前几日的收益率
print("Daily Returns:")
print(returns.head())效果: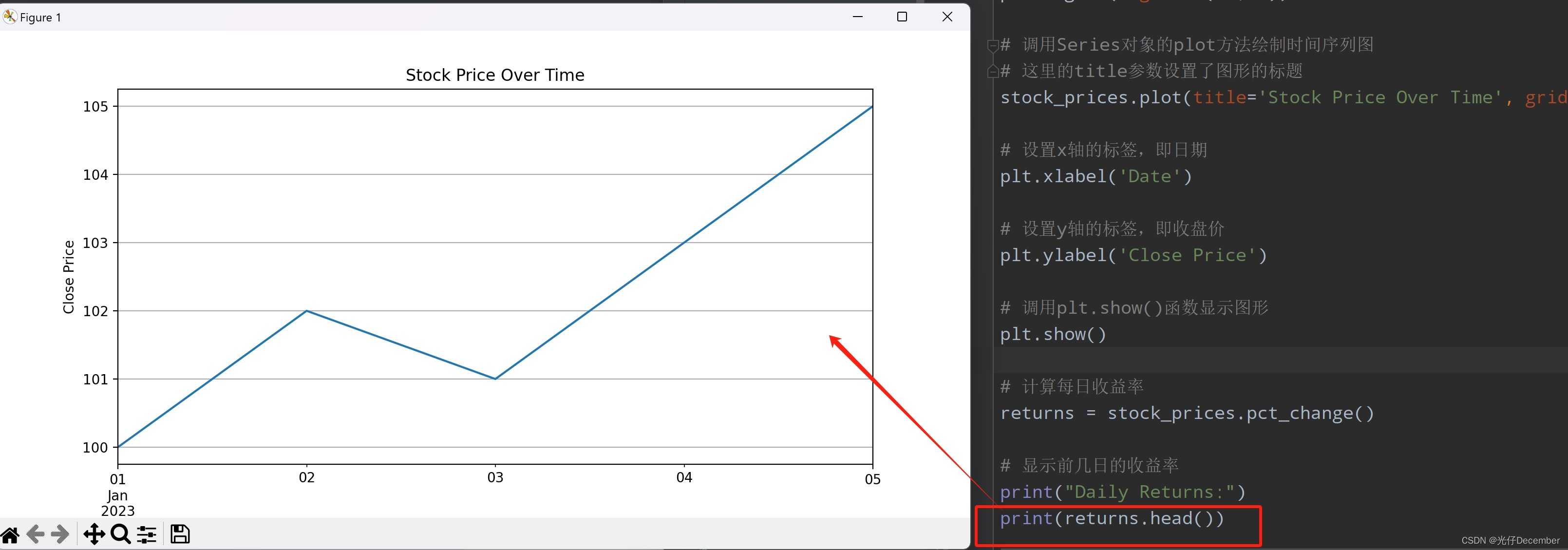
4. 结论
通过上面的代码,我们展示了如何使用Pandas Series对象来表示和分析简单的股票数据。我们首先创建了一个包含收盘价的Series对象,并使用Matplotlib绘制了时间序列图。接着,我们计算了每日的收益率,并打印了前几日的收益率。这个案例简洁明了,展示了Series对象在数据分析中的基本用法。
至此,我们完成了Series对象的所有讲解。下一篇我们来讲解Pandas库中DataFrame对象的操作。
转载请注明出处:https://guangzai.blog.csdn.net/article/details/140084333
相关文章:
【Python从入门到进阶】59、Pandas库中Series对象的操作(二)
接上篇《58、Pandas库中Series对象的操作(一)》 上一篇我们讲解了Pandas库中Series对象的基本概念、对象创建和操作,本篇我们来继续学习Series对象的运算、函数应用、时间序列操作,以及Series的案例实践。 一、Series对象的运算 1. 数值型数据的算术运…...

【PYG】使用datalist定义数据集,创建一个包含多个Data对象的列表并使用DataLoader来加载这些数据
为了使用你提到的封装方式来创建一个包含多个 Data 对象的列表并使用 DataLoader 来加载这些数据,我们可以按照以下步骤进行: 创建数据:生成节点特征矩阵、边索引矩阵和标签。封装数据:使用 Data 对象将这些数据封装起来。使用 D…...

【设计模式】【创建型5-2】【工厂方法模式】
文章目录 工厂方法模式工厂方法模式的结构示例产品接口具体产品工厂接口具体工厂客户端代码 实际的使用 工厂方法模式 工厂方法模式的结构 产品(Product):定义工厂方法所创建的对象的接口。 具体产品(ConcreteProduct࿰…...

python API自动化(Pytest+Excel+Allure完整框架集成+yaml入门+大量响应报文处理及加解密、签名处理)
1.pytest数据参数化 假设你需要测试一个登录功能,输入用户名和密码后验证登录结果。可以使用参数化实现多组输入数据的测试: 测试正确的用户名和密码登录成功 测试正确的用户名和错误的密码登录失败 测试错误的用户名和正确的密码登录失败 测试错误的用户名和密码登…...

【Postman学习】
Postman是一个非常流行的API开发和测试工具,广泛用于Web服务的开发、测试和调试。它提供了一个图形界面,允许用户轻松地构建、发送和管理HTTP(S)请求,同时查看和分析响应。下面是对Postman接口测试工具的详细解释: 1. Postman简介…...
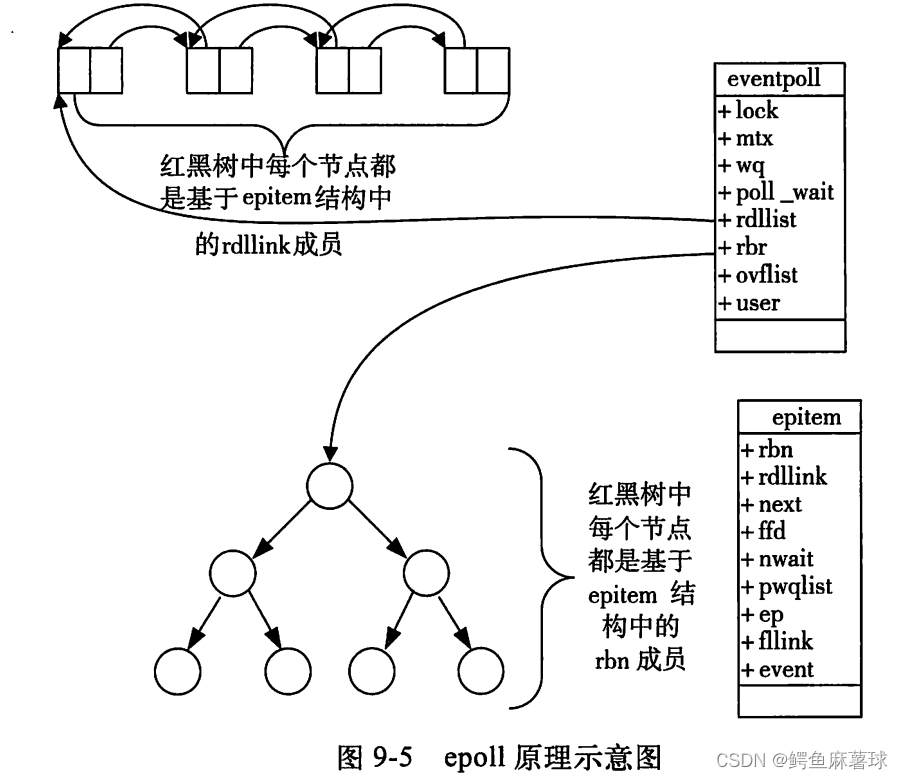
【Linux】IO多路复用——select,poll,epoll的概念和使用,三种模型的特点和优缺点,epoll的工作模式
文章目录 Linux多路复用1. select1.1 select的概念1.2 select的函数使用1.3 select的优缺点 2. poll2.1 poll的概念2.2 poll的函数使用2.3 poll的优缺点 3. epoll3.1 epoll的概念3.2 epoll的函数使用3.3 epoll的优点3.4 epoll工作模式 Linux多路复用 IO多路复用是一种操作系统的…...
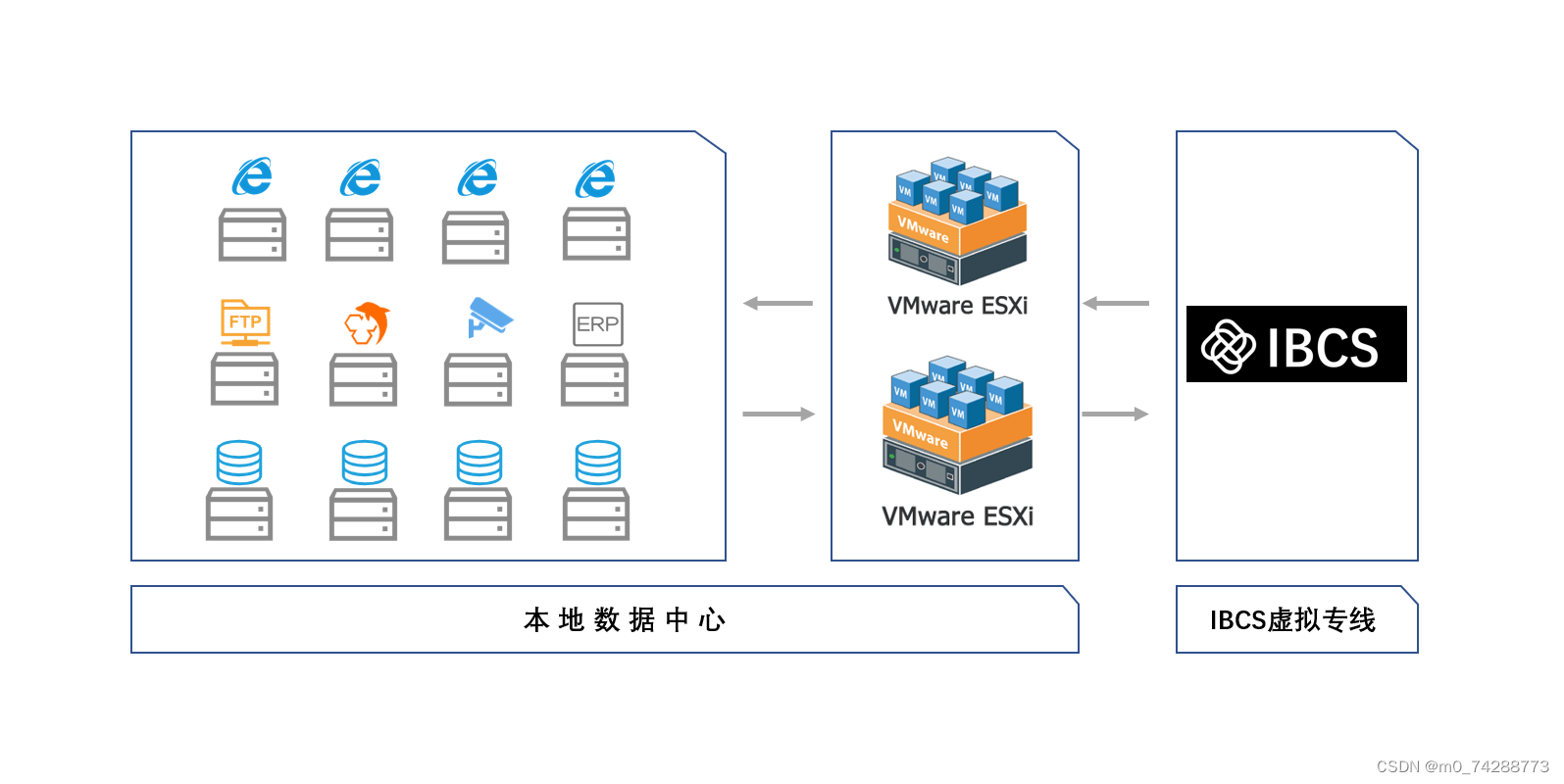
IBCS 虚拟专线——让企业用于独立IP
在当今竞争激烈的商业世界中,企业的数字化运营对网络和服务器的性能有着极高的要求。作为一家企业的 IT 主管,我深刻体会到了在网络和服务器配置方面所面临的种种挑战,以及 IBCS 虚拟专线带来的革命性改变。 我们企业在业务扩张的过程中&…...

驾驭巨龙:Perl中大型文本文件的处理艺术
驾驭巨龙:Perl中大型文本文件的处理艺术 Perl,这门被亲切称为“实用提取和报告语言”的编程语言,自从诞生之日起,就以其卓越的文本处理能力闻名于世。在面对庞大的文本文件时,Perl的强大功能更是得到了充分的体现。本…...

Kafka~特殊技术细节设计:分区机制、重平衡机制、Leader选举机制、高水位HW机制
分区机制 Kafka 的分区机制是其实现高吞吐和可扩展性的重要特性之一。 Kafka 中的数据具有三层结构,即主题(topic)-> 分区(partition)-> 消息(message)。一个 Kafka 主题可以包含多个分…...
springcloud-config 客户端启用服务发现client的情况下使用metadata中的username和password
为了让spring admin 能正确获取到 spring config的actuator的信息,在eureka的metadata中添加了metadata.user.user metadata.user.password eureka.instance.metadata-map.user.name${spring.security.user.name} eureka.instance.metadata-map.user.password${spr…...
)
云计算 | 期末梳理(中)
1. 经典虚拟机的特点 多态(Polymorphism):支持多种类型的OS。重用(Manifolding):虚拟机的镜像可以被反复复制和使用。复用(Multiplexing):虚拟机能够对物理资源时分复用。2. 系统接口 最基本的接口是微处理器指令集架构(ISA)。应用程序二进制接口(ABI)给程序提供使用硬件资源…...

pytest测试框架pytest-order插件自定义用例执行顺序
pytest提供了丰富的插件来扩展其功能,本章介绍插件pytest-order,用于自定义pytest测试用例的执行顺序。pytest-order是插件pytest-ordering的一个分支,但是pytest-ordering已经不再维护了,建议大家直接使用pytest-order。 官方文…...

吴恩达机器学习 第三课 week2 推荐算法(上)
目录 01 学习目标 02 推荐算法 2.1 定义 2.2 应用 2.3 算法 03 协同过滤推荐算法 04 电影推荐系统 4.1 问题描述 4.2 算法实现 05 总结 01 学习目标 (1)了解推荐算法 (2)掌握协同过滤推荐算法(Collabo…...

MySQL CASE 表达式
MySQL CASE表达式 一、CASE表达式的语法二、 常用场景1,按属性分组统计2,多条件统计3,按条件UPDATE4, 在CASE表达式中使用聚合函数 三、CASE表达式出现的位置 一、CASE表达式的语法 -- 简单CASE表达式 CASE sexWHEN 1 THEN 男WHEN 2 THEN 女…...

Unity3D 游戏数据本地化存储与管理详解
在Unity3D游戏开发中,数据的本地化存储与管理是一个重要的环节。这不仅涉及到游戏状态、玩家信息、游戏设置等关键数据的保存,还关系到游戏的稳定性和用户体验。本文将详细介绍Unity3D中游戏数据的本地化存储与管理的技术方法,并给出相应的代…...

昇思25天学习打卡营第1天|初学教程
文章目录 背景创建环境熟悉环境打卡记录学习总结展望未来 背景 参加了昇思的25天学习记录,这里给自己记录一下所学内容笔记。 创建环境 首先在平台注册账号,然后登录,按下图操作,创建环境即可 创建好环境后进入即可࿰…...
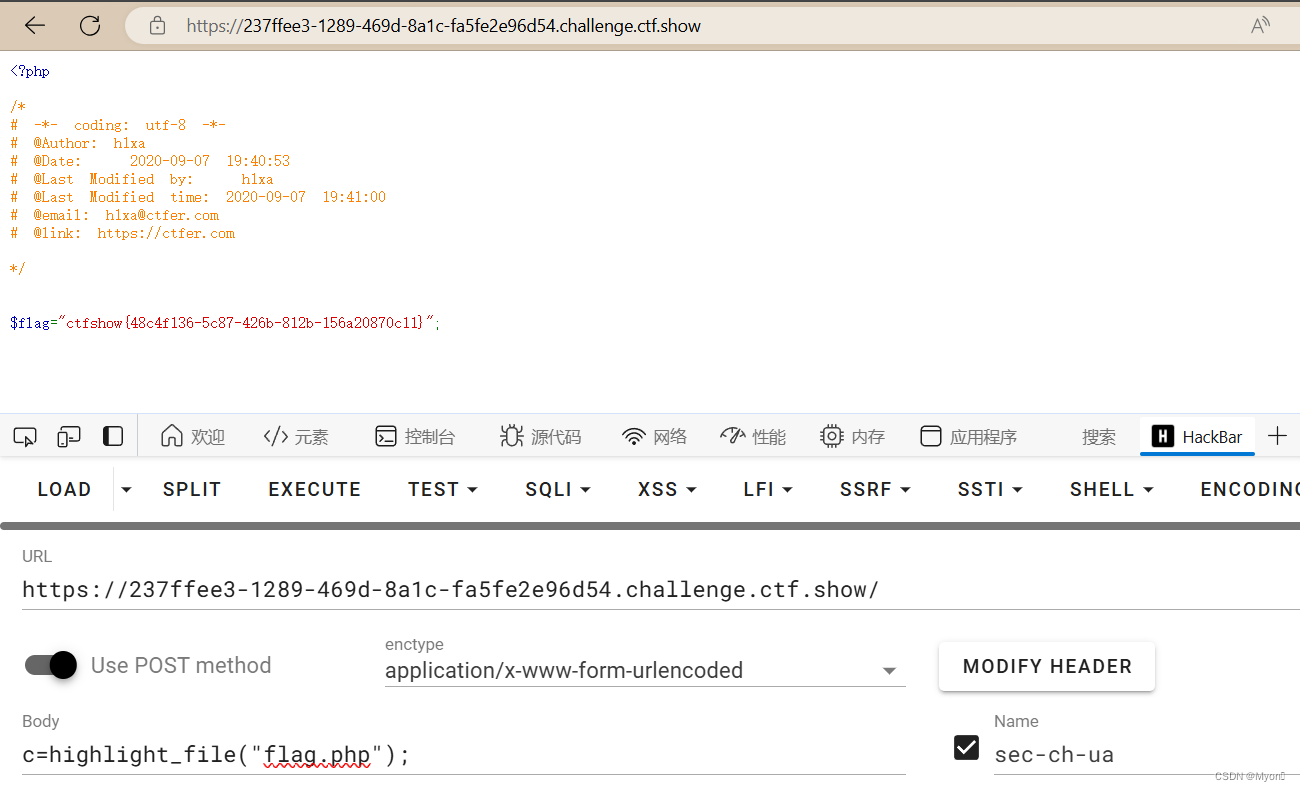
ctfshow-web入门-命令执行(web59-web65)
目录 1、web59 2、web60 3、web61 4、web62 5、web63 6、web64 7、web65 都是使用 highlight_file 或者 show_source 1、web59 直接用上一题的 payload: cshow_source(flag.php); 拿到 flag:ctfshow{9e058a62-f37d-425e-9696-43387b0b3629} 2、w…...
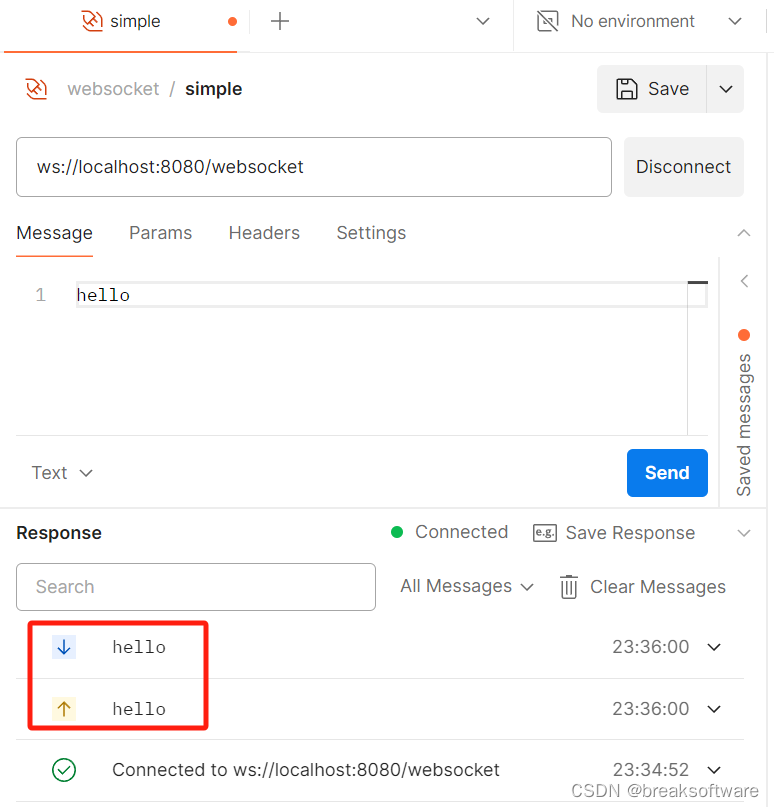
Websocket在Java中的实践——最小可行案例
大纲 最小可行案例依赖开启Websocket,绑定路由逻辑类 测试参考资料 WebSocket是一种先进的网络通信协议,它允许在单个TCP连接上进行全双工通信,即数据可以在同一时间双向流动。WebSocket由IETF标准化为RFC 6455,并且已被W3C定义为…...

python请求报错::requests.exceptions.ProxyError: HTTPSConnectionPool
在发送网页请求时,发现很久未响应,最后报错: requests.exceptions.ProxyError: HTTPSConnectionPool(hostsvr-6-9009.share.51env.net, port443): Max retries exceeded with url: /prod-api/getInfo (Caused by ProxyError(Unable to conne…...
【Unity】Excel配置工具
1、功能介绍 通过Excel表配置表数据,一键生成对应Excel配置表的数据结构类、数据容器类、已经二进制数据文件,加载二进制数据文件获取所有表数据 需要使用Excel读取的dll包 2、关键代码 2.1 ExcelTool类 实现一键生成Excel配置表的数据结构类、数据…...

为什么你的电脑风扇总是“抽风“?3个简单步骤彻底解决Windows风扇控制难题
为什么你的电脑风扇总是"抽风"?3个简单步骤彻底解决Windows风扇控制难题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://git…...

Android跨平台文件同步技术实现:WebDAV桥接工具架构深度解析
Android跨平台文件同步技术实现:WebDAV桥接工具架构深度解析 【免费下载链接】webdav-provider An Android app that can expose WebDAV storage to other apps through Androids Storage Access Framework (SAF) 项目地址: https://gitcode.com/gh_mirrors/we/we…...
)
V型槽有灰还是镜头花了?三步排查图像模糊的真凶(工地实测版)
夏天的老旧小区弱电井,或者秋天刚刮过西北风的马路边,可以说是装维师傅们的"噩梦主场"。你蹲在逼仄的角落里,熟练地剥线、切割,把光纤小心翼翼地放入机器,按下防风盖。结果伴随着几声急促的"滴滴"…...

RocketMQ 5.1.1 Topic管理:从创建到删除,一份完整的mqadmin命令行实战手册
RocketMQ 5.1.1 Topic全生命周期管理实战指南 接手一个新的RocketMQ集群时,Topic管理往往是日常运维中最频繁的操作之一。不同于简单的命令堆砌,本文将带您深入理解Topic从创建到销毁的完整生命周期,通过真实生产环境中的典型场景,…...
的完整旅程)
Zephyr 启动流程:从复位向量到main()的完整旅程
1. 从复位向量开始的奇妙旅程 当你按下嵌入式设备的电源按钮时,芯片内部就开始了一场精心编排的启动芭蕾。对于使用Zephyr RTOS的系统来说,这个旅程从复位向量(Reset Vector)开始,就像火车从始发站出发一样。Cortex-M架…...

iOS 26.4-26.5终极越狱指南:安全解锁iPhone隐藏功能与高级定制方案
iOS 26.4-26.5终极越狱指南:安全解锁iPhone隐藏功能与高级定制方案 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇…...

构建多模型备选策略以提升AI应用服务稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多模型备选策略以提升AI应用服务稳定性 在将大模型能力集成到生产应用时,服务可用性是核心考量之一。依赖单一模型…...

Bili2Text:3分钟将B站视频转为文字稿,AI语音识别提升学习效率10倍
Bili2Text:3分钟将B站视频转为文字稿,AI语音识别提升学习效率10倍 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为无法快速获取…...

draw.io桌面版终极指南:免费跨平台图表编辑解决方案
draw.io桌面版终极指南:免费跨平台图表编辑解决方案 【免费下载链接】drawio-desktop Official electron build of draw.io 项目地址: https://gitcode.com/GitHub_Trending/dr/drawio-desktop 还在为不同操作系统间的图表兼容性问题而烦恼吗?&am…...

告别混乱!用EPLAN高效管理端子连接图的5个实战技巧与常见坑点复盘
告别混乱!用EPLAN高效管理端子连接图的5个实战技巧与常见坑点复盘 在电气工程设计领域,端子连接图的质量直接影响着生产效率和调试准确性。许多工程师在项目后期常常陷入反复修改端子图表的泥潭,不仅耗费宝贵时间,还可能因疏忽导致…...