Google 发布最新开放大语言模型 Gemma 2,现已登陆 Hugging Face Hub
Google 发布了最新的开放大语言模型 Gemma 2,我们非常高兴与 Google 合作,确保其在 Hugging Face 生态系统中的最佳集成。你可以在 Hub 上找到 4 个开源模型 (2 个基础模型和 2 个微调模型) 。发布的功能和集成包括:
Hub 上的模型https://hf.co/collections/google/g-667d6600fd5220e7b967f315
Hugging FaceTransformers 集成https://github.com/huggingface/transformers/releases/tag/v4.42.0
与 Google Cloud 和推理端点的集成
Gemma 2 是什么?
Gemma 2 是 Google 最新的开放大语言模型。它有两种规模:90 亿参数和 270 亿参数,分别具有基础 (预训练) 和指令调优版本。Gemma 基于 Google DeepMind 的 Gemini,拥有 8K Tokens 的上下文长度:
gemma-2-9bhttps://hf.co/google/gemma-2-9b90 亿基础模型。
gemma-2-9b-ithttps://hf.co/google/gemma-2-9b-it90 亿基础模型的指令调优版本。
gemma-2-27bhttps://hf.co/google/gemma-2-27b270 亿基础模型。
gemma-2-27b-ithttps://hf.co/google/gemma-2-27b-it270 亿基础模型的指令调优版本。
Gemma 2 模型的训练数据量约为其第一代的两倍,总计 13 万亿 Tokens (270 亿模型) 和 8 万亿 Tokens (90 亿模型) 的网页数据 (主要是英语) 、代码和数学数据。我们不知道训练数据混合的具体细节,只能猜测更大和更仔细的数据整理是性能提高的重要因素之一。
Gemma 2 与第一代使用相同的许可证,这是一个允许再分发、微调、商业用途和衍生作品的宽松许可证。
立刻在 Hugging Chat 里体验 Gemma2
https://hf.co/chat/models/google/gemma-2-27b-it
Gemma 2 的技术进展
Gemma 2 与第一代有许多相似之处。它有 8192 Tokens 的上下文长度,并使用旋转位置嵌入 (RoPE)。与原始 Gemma 相比,Gemma 2 的主要进展有四点:
滑动窗口注意力: 交替使用滑动窗口和全二次注意力以提高生成质量。
Logit 软上限: 通过将 logits 缩放到固定范围来防止其过度增长,从而改进训练。
知识蒸馏: 利用较大的教师模型来训练较小的模型(适用于 90 亿模型)。
模型合并: 将两个或多个大语言模型合并成一个新的模型。
Gemma 2 使用JAX和ML Pathways在Google Cloud TPU (27B on v5p和9B on TPU v4)上进行训练。Gemma 2 Instruct 已针对对话应用进行了优化,并使用监督微调 (SFT)、大模型蒸馏、人类反馈强化学习 (RLHF) 和模型合并 (WARP) 来提高整体性能。
JAXhttps://jax.readthedocs.io/en/latest/quickstart.html
ML Pathwayshttps://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
Google Cloud TPU 27B on v5phttps://cloud.google.com/blog/products/ai-machine-learning/introducing-cloud-tpu-v5p-and-ai-hypercomputer?hl=en
9B on TPU v4https://cloud.google.com/tpu/docs/v4
与预训练数据集混合类似,关于微调数据集或与 SFT 和RLHF相关的超参数的细节尚未共享。
RLHFhttps://hf.co/blog/rlhf
滑动窗口注意力
滑动窗口注意力是一种用于减少 Transformer 模型中注意力计算的内存和时间需求的方法,已在Mistral等模型中使用。Gemma 2 的新颖之处在于每隔一层应用滑动窗口 (局部 - 4096 Tokens) ,而中间层仍使用全局二次注意力 (8192 Tokens) 。我们推测这是为了在长上下文情况下提高质量 (半数层仍然关注所有 Tokens) ,同时部分受益于滑动注意力的优势。
滑动窗口注意力https://hf.co/papers/2004.05150
Mistralhttps://hf.co/papers/2310.06825
软上限和注意力实现
软上限是一种防止 logits 过度增长而不截断它们的技术。它通过将 logits 除以最大值阈值 (soft_cap),然后通过 tanh 层 (确保它们在 (-1, 1) 范围内) ,最后再乘以阈值。这确保了最终值在 (-soft_cap, +soft_cap) 区间内,不会丢失太多信息但稳定了训练。
综合起来,logits 的计算公式为:logits ← soft_cap ∗ tanh(logits/soft_cap)
Gemma 2 对最终层和每个注意力层都采用了软上限。注意力 logits 上限为 50.0,最终 logits 上限为 30.0。
在发布时,软上限与 Flash Attention / SDPA 不兼容,但它们仍可用于推理以实现最高效率。Gemma 2 团队观察到,在推理过程中不使用软上限机制时,差异非常小。
注意:对于稳定的微调运行,仍需启用软上限,因此我们建议使用 eager 注意力进行微调,而不是 SDPA。
知识蒸馏
知识蒸馏是一种常用技术,用于训练较小的 学生 模型以模仿较大但表现更好的 教师 模型的行为。这是通过将大语言模型的下一个 Token 预测任务与教师提供的 Token 概率分布 (例如 GPT-4、Claude 或 Gemini) 结合起来,从而为学生提供更丰富的学习信号。
根据 Gemma 2 技术报告,知识蒸馏用于预训练 90 亿模型,而 270 亿模型则是从头开始预训练的。
在后期训练中,Gemma 2 团队生成了来自教师 (报告中未指定,但可能是 Gemini Ultra) 的多样化补全集,然后使用这些合成数据通过 SFT 训练学生模型。这也是许多开源模型的基础,如Zephyr和OpenHermes,它们完全基于较大大语言模型的合成数据进行训练。
Zephyrhttps://hf.co/HuggingFaceH4/zephyr-7b-beta
OpenHermeshttps://hf.co/teknium/OpenHermes-2.5-Mistral-7B
尽管有效,但这种方法存在缺点,因为学生和教师之间的模型容量不匹配可能导致 训练-推理不匹配,即学生在推理期间生成的文本与训练期间看到的文本不同。
为解决这个问题,Gemma 2 团队采用了“在线蒸馏”,其中学生从 SFT 提示生成补全。这些补全用于计算教师和学生 logits 之间的 KL 散度。通过在整个训练过程中最小化 KL 散度,学生能够准确地模拟教师的行为,同时最小化训练-推理不匹配。
“在线蒸馏”https://arxiv.org/pdf/2306.13649
这种方法非常有趣,正如我们在社区中看到的那样,在线 DPO 等在线方法会产生更强的模型,而在线蒸馏的一个优势在于只需要教师的 logits,因此无需依赖奖励模型或大语言模型作为评审员来改进模型。我们期待看到这种方法在未来几个月中是否会在微调人员中变得更受欢迎!
模型合并
模型合并是一种将两个或多个大语言模型合并成一个新模型的技术。这是相对较新和实验性的,可以不使用加速器进行。Mergekit是一个流行的开源工具包,用于合并大语言模型。它实现了线性、SLERP、TIES、DARE 和其他合并技术。
模型合并https://hf.co/blog/mlabonne/merge-models
Mergekithttps://github.com/arcee-ai/mergekit
根据技术报告,Gemma 2 使用了Warp,这是一种新型合并技术,分三个独特阶段进行合并:
Warphttps://arxiv.org/abs/2406.16768
指数移动平均 (EMA):在强化学习 (RL) 微调过程中应用。
球形线性插值 (SLERP):在多个策略的 RL 微调后应用。
向初始化线性插值 (LITI):在 SLERP 阶段之后应用。
Gemma 2 的评估
Gemma 模型的表现如何?以下是根据技术报告和新版开源 LLM 排行榜对其他开源开放模型的性能比较。
开源 LLM 排行榜https://hf.co/spaces/HuggingFaceH4/open_llm_leaderboard
技术报告结果
Gemma 2 的技术报告比较了不同开源 LLM 在之前开源 LLM 排行榜基准上的性能。
| Llama 3 (70B) | Qwen 1.5 (32B) | Gemma 2 (27B) | |
|---|---|---|---|
| MMLU | 79.2 | 74.3 | 75.2 |
| GSM8K | 76.9 | 61.1 | 75.1 |
| ARC-c | 68.8 | 63.6 | 71.4 |
| HellaSwag | 88.0 | 85.0 | 86.4 |
| Winogrande | 85.3 | 81.5 | 83.7 |
该报告还比较了小型语言模型的性能。
| Benchmark | Mistral (7B) | Llama 3 (8B) | Gemma (8B) | Gemma 2 (9B) |
|---|---|---|---|---|
| MMLU | 62.5 | 66.6 | 64.4 | 71.3 |
| GSM8K | 34.5 | 45.7 | 50.9 | 62.3 |
| ARC-C | 60.5 | 59.2 | 61.1 | 68.4 |
| HellaSwag | 83.0 | 82.0 | 82.3 | 81.9 |
| Winogrande | 78.5 | 78.5 | 79.0 | 80.6 |
开源 LLM 排行榜结果
注意:我们目前正在新的开源 LLM 排行榜基准上单独评估 Google Gemma 2,并将在今天晚些时候更新此部分。
如何提示 Gemma 2
基础模型没有提示格式。像其他基础模型一样,它们可以用于继续输入序列的合理延续或零样本/少样本推理。指令版本有一个非常简单的对话结构:
<start_of_turn>user
knock knock<end_of_turn>
<start_of_turn>model
who is there<end_of_turn>
<start_of_turn>user
LaMDA<end_of_turn>
<start_of_turn>model
LaMDA who?<end_of_turn><eos>必须精确地复制此格式才能有效使用。稍后我们将展示如何使用 transformers 中的聊天模板轻松地复制指令提示。
演示
你可以在 Hugging Chat 上与 Gemma 27B 指令模型聊天!查看此链接:
https://hf.co/chat/models/google/gemma-2-27b-it
使用 Hugging Face Transformers
随着 Transformers版本 4.42的发布,你可以使用 Gemma 并利用 Hugging Face 生态系统中的所有工具。要使用 Transformers 使用 Gemma 模型,请确保使用最新的 transformers 版本:
版本 4.42https://github.com/huggingface/transformers/releases/tag/v4.42.0
pip install "transformers==4.42.1" --upgrade以下代码片段展示了如何使用 transformers 使用 gemma-2-9b-it。它需要大约 18 GB 的 RAM,适用于许多消费者 GPU。相同的代码片段适用于 gemma-2-27b-it,需要 56GB 的 RAM,使其非常适合生产用例。通过加载 8-bit 或 4-bit 模式,可以进一步减少内存消耗。
from transformers import pipeline
import torchpipe = pipeline("text-generation",model="google/gemma-2-9b-it",model_kwargs={"torch_dtype": torch.bfloat16},device="cuda",
)messages = [{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
outputs = pipe(messages,max_new_tokens=256,do_sample=False,
)
assistant_response = outputs[0]["generated_text"][-1]["content"]
print(assistant_response)啊哈,船长!我是数字海洋上的一艘谦卑的词语之船。他们叫我 Gemma,是 Google DeepMind 的杰作。我被训练在一堆文本宝藏上,学习如何像一个真正的海盗一样说话和写作。
问我你的问题吧,我会尽力回答,啊哈!🦜📚
我们使用 bfloat16 因为这是指令调优模型的参考精度。在你的硬件上运行 float16 可能会更快,90 亿模型的结果应该是相似的。然而,使用 float16 时,270 亿指令调优模型会产生不稳定的输出:对于该模型权重,你必须使用 bfloat16。
你还可以自动量化模型,以 8-bit 甚至 4-bit 模式加载。加载 4-bit 模式的 270 亿版本需要大约 18 GB 的内存,使其兼容许多消费者显卡和 Google Colab 中的 GPU。这是你在 4-bit 模式下加载生成管道的方式:
pipeline = pipeline("text-generation",model=model,model_kwargs={"torch_dtype": torch.bfloat16,"quantization_config": {"load_in_4bit": True}},
)有关使用 Transformers 模型的更多详细信息,请查看模型卡。
模型卡https://hf.co/gg-hf/gemma-2-9b
与 Google Cloud 和推理端点的集成
注意:我们目前正在为 GKE 和 Vertex AI 添加新的容器,以高效运行 Google Gemma 2。我们将在容器可用时更新此部分。
其他资源
Hub 上的模型https://hf.co/collections/google/g-667d6600fd5220e7b967f315
开放 LLM 排行榜https://hf.co/spaces/HuggingFaceH4/open_llm_leaderboard
Hugging Chat 上的聊天演示https://hf.co/chat/models/google/gemma-2-27b-it
Google 博客https://blog.google/technology/developers/google-gemma-2/
Google Notebook 即将推出
Vertex AI 模型花园 即将推出
致谢
在生态系统中发布此类模型及其支持和评估离不开许多社区成员的贡献,包括Clémentine和Nathan对 LLM 的评估;Nicolas对文本生成推理的支持;Arthur、Sanchit、Joao和Lysandre对 Gemma 2 集成到 Transformers 中的支持;Nathan和Victor使 Gemma 2 在 Hugging Chat 中可用。
Clémentinehttps://hf.co/clefourrier
Nathanhttps://hf.co/SaylorTwift
Nicolashttps://hf.co/Narsil
Arthurhttps://hf.co/ArthurZ
Sanchithttps://hf.co/sanchit-gandhi
Joaohttps://hf.co/joaogante
Lysandrehttps://hf.co/lysandre
Nathanhttps://hf.co/nsarrazin
Victorhttps://hf.co/victor
感谢 Google 团队发布 Gemma 2!
相关文章:

Google 发布最新开放大语言模型 Gemma 2,现已登陆 Hugging Face Hub
Google 发布了最新的开放大语言模型 Gemma 2,我们非常高兴与 Google 合作,确保其在 Hugging Face 生态系统中的最佳集成。你可以在 Hub 上找到 4 个开源模型 (2 个基础模型和 2 个微调模型) 。发布的功能和集成包括: Hub 上的模型https://hf.…...

智能分析赋能等保:大数据技术在安全审计记录中的应用
随着信息技术的飞速发展,大数据技术在各行各业中的应用愈发广泛,特别是在网络安全领域,大数据技术为安全审计记录提供了强有力的支撑。本文将深入探讨智能分析如何赋能等保(等级保护),以及大数据技术在安全…...
)
Django中,update_or_create()
在Django中,可以使用update_or_create()方法来更新现有记录或创建新记录。该方法接受一个字典作为参数,用于指定要更新或创建的字段和对应的值。 update_or_create()方法的语法如下: 代码语言:python obj, created Model.obje…...

每日一学(1)
目录 1、ConCurrentHashMap为什么不允许key为null? 2、ThreadLocal会出现内存泄露吗? 3、AQS理解 4、lock 和 synchronized的区别 1、ConCurrentHashMap为什么不允许key为null? 底层 putVal方法 中 如果key || value为空 抛出…...
SpringMVC(1)——入门程序+流程分析
MVC都是哪三层?在Spring里面分别对应什么?SpringMVC的架构是什么? 我们使用Spring开发JavaWeb项目,一般都是BS架构,也就是Browser(浏览器)-Server(服务器)架构 这种架构…...

成绩发布背后:老师的无奈与痛点
在教育的广阔天地里,教师这一角色承载着无数的期望与责任。他们不仅是知识的传播者,更是学生心灵的引路人。而对于班主任老师来说,他们的角色更加多元,他们不仅是老师,还必须是“妈妈”。除了像其他老师一样备课、上课…...

MySQL 索引之外的相关查询优化总结
在这之前先说明几个概念: 1、驱动表和被驱动表:驱动表是主表,被驱动表是从表、非驱动表。驱动表和被驱动表并非根据 from 后面表名的先后顺序而确定,而是根据 explain 语句查询得到的顺序确定;展示在前面的是驱动表&am…...

EE trade:贵金属投资的优点及缺点
贵金属(如黄金、白银、铂金和钯金)一直以来都是重要的投资和避险工具。它们具有独特的物理和化学特性,广泛应用于各种行业,同时也被视为财富储备。在进行贵金属投资时,了解其优点和缺点对于做出明智的投资决策至关重要。 一、贵金属投资的优…...

python工作目录与文件目录
工作目录 文件目录:文件所在的目录 工作目录:执行python命令所在的目录 D:. | main.py | ---data | data.txt | ---model | | model.py | | train.py | | __init__.py | | | ---nlp | | | bert.py | …...

可信和可解释的大语言模型推理-RoG
大型语言模型(LLM)在复杂任务中表现出令人印象深刻的推理能力。然而,LLM在推理过程中缺乏最新的知识和经验,这可能导致不正确的推理过程,降低他们的表现和可信度。知识图谱(Knowledge graphs, KGs)以结构化的形式存储了…...

秋招季的策略与行动指南:提前布局,高效备战,精准出击
6月即将进入尾声,一年一度的秋季招聘季正在热火进行中。对于即将毕业的学生和寻求职业发展的职场人士来说,秋招是一个不容错过的黄金时期。 秋招的序幕通常在6月至9月间拉开,名企们纷纷开启网申的大门。在此期间,求职备战是一个系…...

Java并发编程-wait与notify详解及案例实战
文章目录 概述wait()notify()作用注意事项用wait与notify手写一个内存队列wait与notify的底层原理:monitor以及wait_setMonitor(监视器)Wait Set(等待集合)Wait() 原理Notify() / NotifyAll() 原理注意事项wait与notify在代码中使用时的注意事项总结案例实战:基于wait与not…...
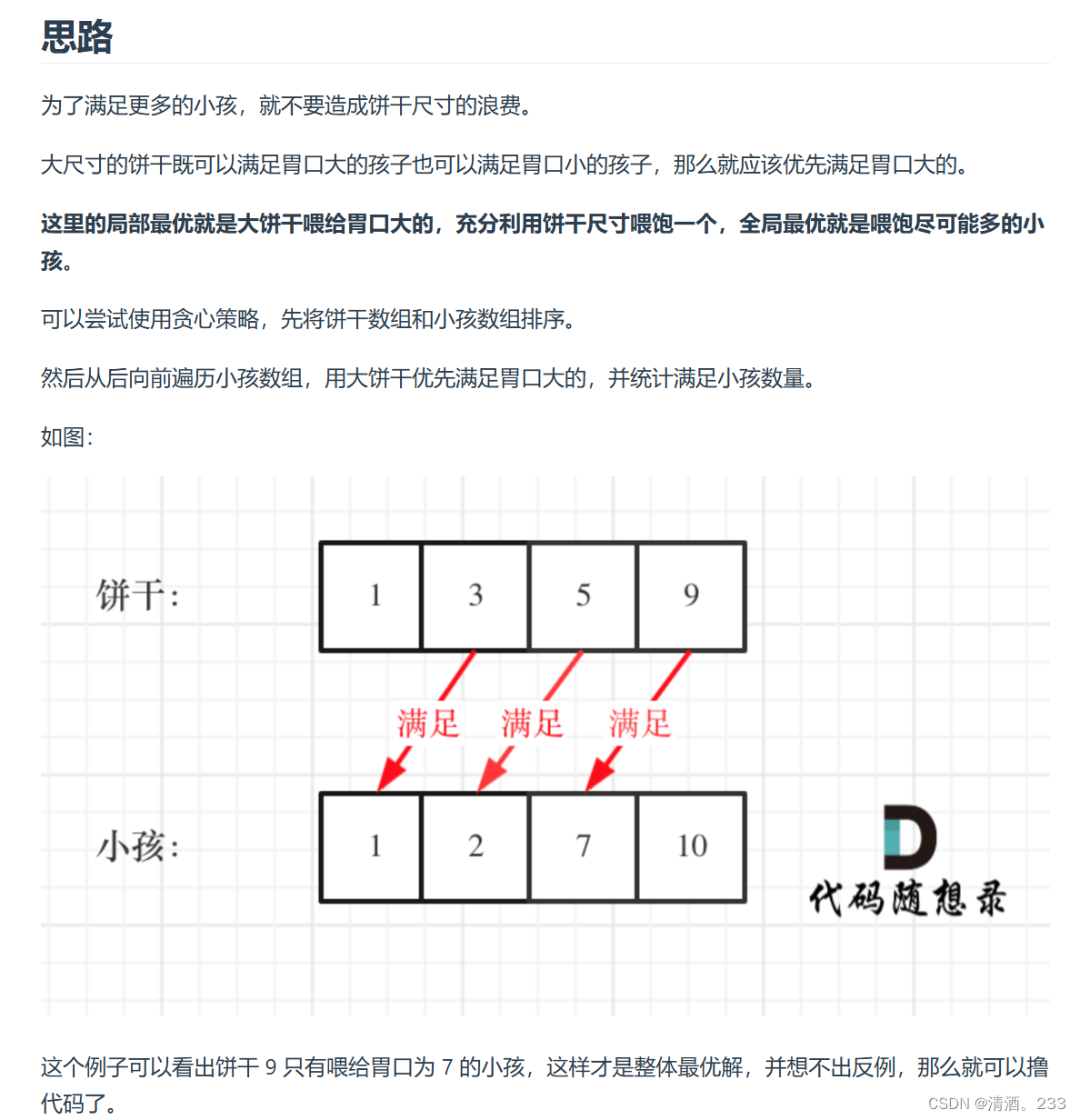
204.贪心算法:分发饼干(力扣)
以下来源于代码随想录 class Solution { public:int findContentChildren(vector<int>& g, vector<int>& s) {// 对孩子的胃口进行排序sort(g.begin(), g.end());// 对饼干的尺寸进行排序sort(s.begin(), s.end());int index s.size() - 1; // 从最大的饼…...
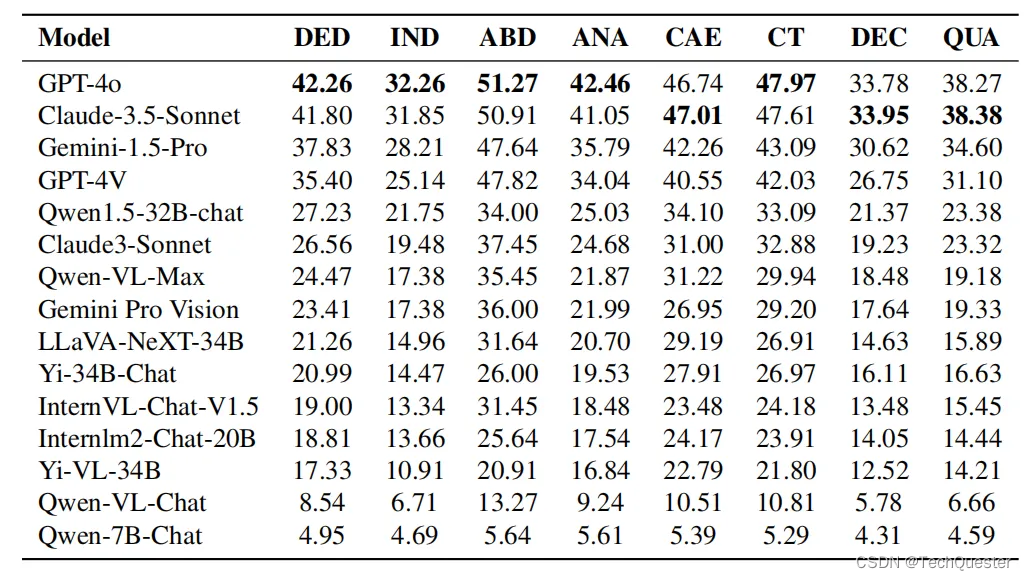
AI奥林匹克竞赛:Claude-3.5-Sonnet对决GPT-4o,谁是最聪明的AI?
目录 实验设置 评估对象 评估方法 结果与分析 针对学科的细粒度分析 GPT-4o vs. Claude-3.5-Sonnet GPT-4V vs. Gemini-1.5-Pro 结论 AI技术日新月异,Anthropic公司最新发布的Claude-3.5-Sonnet因在知识型推理、数学推理、编程任务及视觉推理等任务上设立新…...

【C++】const修饰成员函数
const修饰成员函数 常函数: 成员函数后加const后我们称为这个函数为常函数 常函数内不可以修改成员属性 成员属性声明时加关键字mutable后,在常函数中依然可以修改 class Animal { public:void fun1(){//这是一个普通的成员函数 }void fun2…...
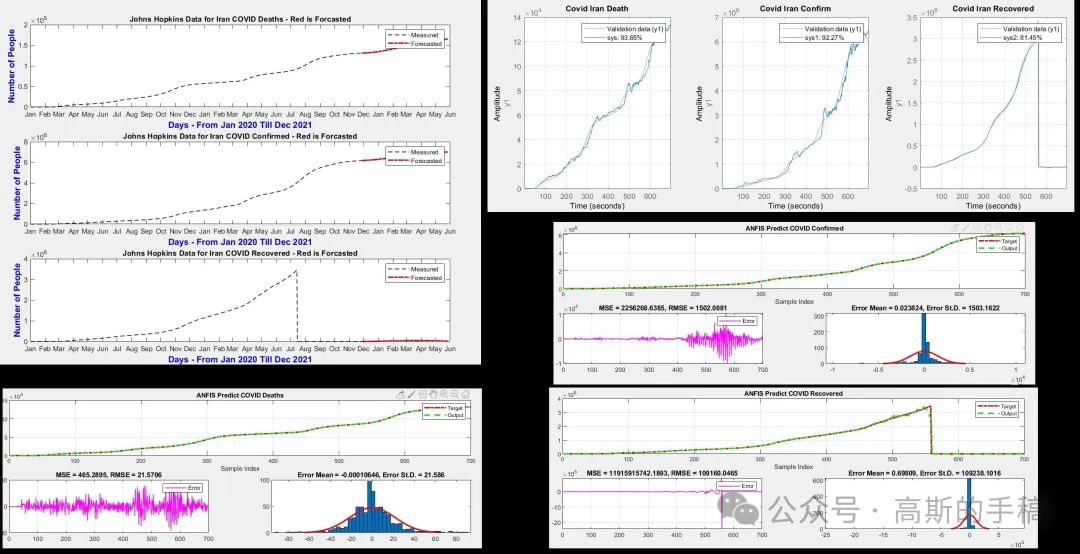
基于模糊神经网络的时间序列预测(以hopkinsirandeath数据集为例,MATLAB)
模糊神经网络从提出发展到今天,主要有三种形式:算术神经网络、逻辑模糊神经网络和混合模糊神经网络。算术神经网络是最基本的,它主要是对输入量进行模糊化,且网络结构中的权重也是模糊权重;逻辑模糊神经网络的主要特点是模糊权值可…...
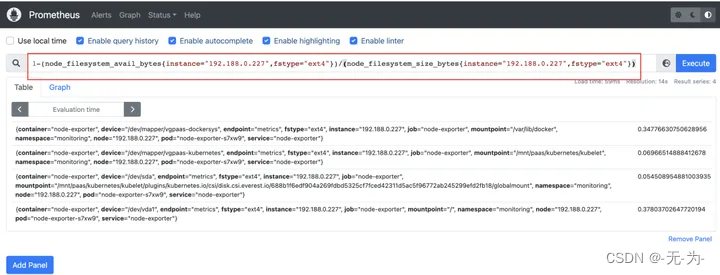
Java web应用性能分析之【prometheus监控K8s指标说明】
常规k8s的监控指标 单独 1、集群维度 集群状态集群节点数节点状态(正常、不可达、未知)节点的资源使用率(CPU、内存、IO等) 2、应用维度 应用响应时间 应用的错误率 应用的请求量 3、系统和集群组件维度 API服务器状态控…...

Spring Boot中的应用配置文件管理
Spring Boot中的应用配置文件管理 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨Spring Boot中的应用配置文件管理。在现代的软件开发中&am…...
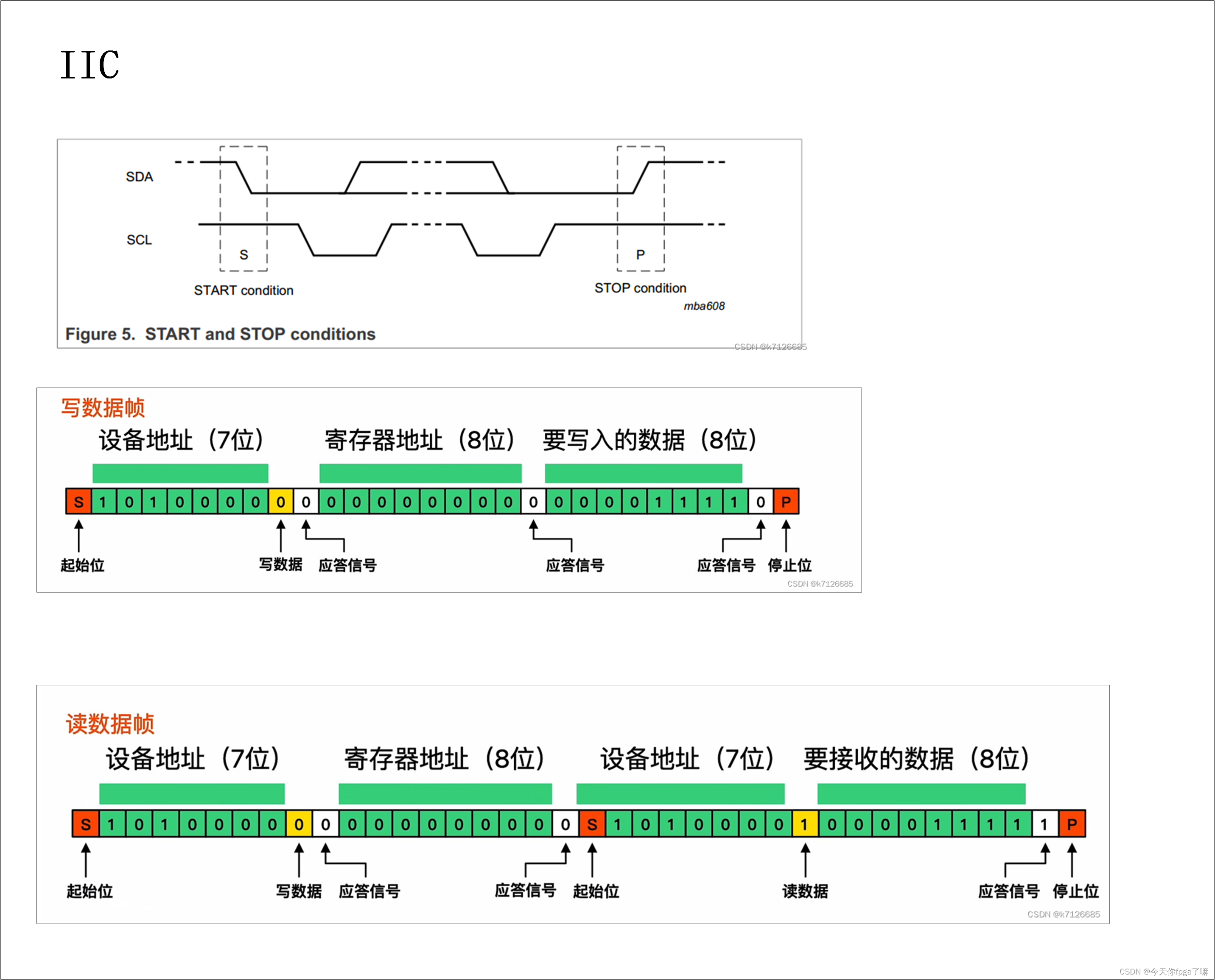
SCCB协议介绍,以及与IIC协议对比
在之前的文章里已经介绍了IIC协议:iic通信协议 这篇内容主要介绍一下SCCB协议。 文章目录 SCCB协议:SCCB时序图iic时序图SCCB时序 VS IIC时序 总:SCCB协议常用在摄像头配置上面,例如OV5640摄像头,和IIC协议很相似&…...
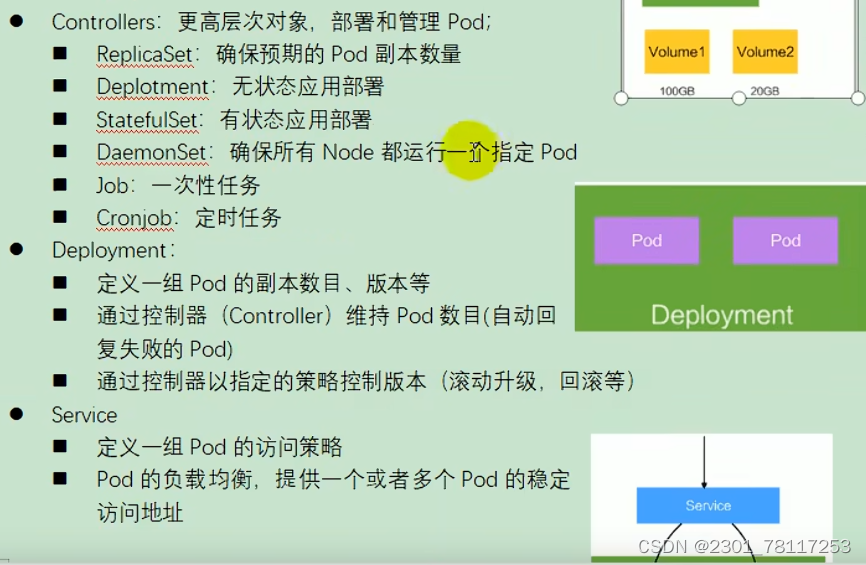
K8S基础简介
用于自动部署,扩展和管理容器化应用程序的开源系统。 功能: 服务发现和负载均衡; 存储编排; 自动部署和回滚; 自动二进制打包; 自我修复; 密钥与配置管理; 1. K8S组件 主从方式架…...

Zabbix监控扩展实战:zbx-openclaw开源模板深度解析与应用指南
1. 项目概述与核心价值最近在折腾监控告警系统,发现一个挺有意思的开源项目,叫zbx-openclaw。这名字乍一看有点抽象,但拆开来看就明白了——zbx指的是 Zabbix,那个老牌的监控系统;openclaw直译是“开放的爪子”&#x…...

基于CRICKIT与CircuitPython的蛇形机器人避障项目实践
1. 项目概述与核心思路最近在捣鼓一个挺有意思的创客项目:用Adafruit的CRICKIT扩展板和CircuitPython,做一个能自己溜达、遇到障碍会躲开的蛇形机器人。这玩意儿听起来复杂,其实拆解开来,核心就是“感知-决策-执行”这个经典的控制…...

STM32F429IGT6项目实战:基于STM32CubeMX的SDRAM配置与性能优化
1. 为什么需要SDRAM配置 在嵌入式开发中,尤其是使用STM32F429IGT6这类高性能MCU时,SDRAM(同步动态随机存取存储器)的配置往往成为项目成败的关键。我曾在多个图形界面项目中深刻体会到,当需要处理高分辨率图像或大量数…...

热门的牙齿矫正正畸李杨哪个好
在社交媒体上,关于“牙齿矫正哪家好”、“李杨医生靠谱吗”的讨论热度居高不下。许多粉丝在评论区留言,想知道这位在网络红人榜上经常出现的正畸专家,是否真的值得托付那长达一两年的矫正周期。作为一个长期关注口腔健康领域的观察者…...

轻量化目标检测实战:基于Pytorch的Mobilenet-YOLOv4融合架构设计与性能调优
1. 为什么需要轻量化目标检测模型 在移动端和嵌入式设备上运行目标检测模型时,我们常常面临两个关键挑战:计算资源有限和功耗约束。传统的YOLOv4虽然检测精度高,但其基于CSPDarknet53的主干网络参数量大、计算复杂度高,难以在资源…...

基于MCP与Apify构建自动化特许经营尽职调查智能体
1. 项目概述与核心价值最近在梳理一些自动化数据采集和商业智能分析的项目时,我遇到了一个非常有意思的工具:apifyforge/franchise-due-diligence-mcp。这个项目名字听起来有点长,但拆解一下就能明白它的核心价值——它是一个基于MCP…...

如何在IDEA中打造你的私人阅读空间:3个实用技巧提升编程效率与阅读体验
如何在IDEA中打造你的私人阅读空间:3个实用技巧提升编程效率与阅读体验 【免费下载链接】thief-book-idea IDEA插件版上班摸鱼看书神器 项目地址: https://gitcode.com/gh_mirrors/th/thief-book-idea 在快节奏的编程工作中,如何有效利用碎片化时…...

BilibiliDown完整使用教程:三步搞定B站视频批量下载
BilibiliDown完整使用教程:三步搞定B站视频批量下载 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/…...

ARM CoreSight ROM Tables解析与调试实践
1. ARM CoreSight ROM Tables基础解析在嵌入式调试领域,ARM CoreSight架构提供了一套完整的调试与追踪解决方案。作为该架构的关键组成部分,ROM Tables扮演着系统调试资源的"目录"角色。想象一下走进一个巨大的图书馆,ROM Tables就…...

【模块化设计-13】OAM 线程模块详解
该模块是基于 RT-Thread 实时操作系统实现的一个 OAM(Operation, Administration and Maintenance,操作、管理和维护)专用线程模块,核心功能是提供独立的 OAM 业务处理线程、消息队列机制和定时器管理能力,适用于嵌入式…...