由浅入深,走进深度学习(补充篇:转置卷积和FCN)
本期内容是针对神经网络层结构的一个补充,主要内容是:转置卷积和全连接卷积网络
相关内容:
由浅入深,走进深度学习(2)_卷积层-CSDN博客
由浅入深,走进深度学习(补充篇:神经网络结构层基础)-CSDN博客
由浅入深,走进深度学习(补充篇:神经网络基础)-CSDN博客
目录
转置卷积
填充、步幅和多通道
全连接卷积神经网络
正片开始!!!!
转置卷积
卷积不会增大输入的高宽 通常要么不变 要么减半
转置卷积则可以用来增大输入高宽
import torch
from torch import nn
from d2l import torch as d2l# 实现基本的转置卷积运算
# 定义转置卷积运算
def trans_conv(X, K):# 获取卷积核的宽度和高度h, w = K.shape # 卷积核的宽、高# 创建一个新的张量Y 其尺寸为输入X的尺寸加上卷积核K的尺寸减去1 在常规卷积中 输出尺寸通常是输入尺寸减去卷积核尺寸加1Y = torch.zeros((X.shape[0] + h -1, X.shape[1] + w - 1)) # 正常的卷积后尺寸为(X.shape[0] - h + 1, X.shape[1] - w + 1) # 遍历输入张量X的每一行for i in range(X.shape[0]):# 遍历输入张量X的每一列for j in range(X.shape[1]):# 对于输入X的每一个元素 我们将其与卷积核K进行元素级别的乘法 然后将结果加到输出张量Y的相应位置上Y[i:i + h, j:j + w] += X[i, j] * K # 按元素乘法 加回到自己矩阵# 返回转置卷积的结果return Y# 验证上述实现输出
# 定义输入张量X 这是一个2x2的矩阵
X = torch.tensor([[0.0, 1.0],[2.0, 3.0]])
# 定义卷积核K 也是一个2x2的矩阵
K = torch.tensor([[0.0, 1.0],[2.0, 3.0]])
# 调用上面定义的trans_conv函数 对输入张量X和卷积核K进行转置卷积操作 并打印结果
trans_conv(X, K)# 使用高级API获得相同的结果
# 将输入张量X和卷积核K进行形状变换 原来是2x2的二维张量 现在变成了1x1x2x2的四维张量
# 第一个1表示批量大小 第二个1表示通道数 2x2是卷积核的高和宽
X, K = X.reshape(1, 1, 2, 2), K.reshape(1, 1, 2, 2)
# 创建一个转置卷积层对象tconv 其中输入通道数为1 输出通道数为1 卷积核的大小为2 没有偏置项
tconv = nn.ConvTranspose2d(1, 1, kernel_size = 2, bias = False) # 输入通道数为1 输出通道数为1
# 将创建的转置卷积层对象tconv的权重设置为我们的卷积核K
tconv.weight.data = K
# 使用创建的转置卷积层tconv对输入张量X进行转置卷积操作 并返回结果
tconv(X)填充、步幅和多通道
填充在输出上 padding=1 之前输出3x3 现在上下左右都填充了1 那就剩下中心那个元素了
填充为1 就是把输出最外面的一圈当作填充
创建一个转置卷积层对象tconv 其中输入通道数为1 输出通道数为1 卷积核的大小为2 没有偏置项 同时设置填充大小为1
填充(padding)操作在输出上执行 原本输出为3x3 由于填充了大小为1的边框 结果就只剩下中心的元素
所以填充大小为1就相当于将输出矩阵最外面的一圈当作填充并剔除
tconv = nn.ConvTranspose2d(1, 1, kernel_size = 2, padding = 1, bias = False)
# 将创建的转置卷积层对象tconv的权重设置为我们的卷积核K
tconv.weight.data = K
# 使用创建的转置卷积层tconv对输入张量X进行转置卷积操作 并返回结果
tconv(X)# 创建一个转置卷积层对象tconv 其中输入通道数为1 输出通道数为1 卷积核的大小为2 步幅(stride)为2 没有偏置项
# 步幅为2表示在进行卷积时 每次移动2个单位 相较于步幅为1 这样会使得输出尺寸增大
tconv = nn.ConvTranspose2d(1, 1, kernel_size = 2, stride = 2, bias = False)
# 将创建的转置卷积层对象tconv的权重设置为我们的卷积核K
tconv.weight.data = K
# 使用创建的转置卷积层tconv对输入张量X进行转置卷积操作 并返回结果
tconv(X)# 多通道
# 创建一个四维张量X 批量大小为1 通道数为10 高和宽都为16
X = torch.rand(size = (1, 10, 16, 16))
# 创建一个二维卷积层对象conv 其中输入通道数为10 输出通道数为20 卷积核大小为5 填充为2 步幅为3
# 这会将输入的10个通道的图像转换为20个通道的特征图
conv = nn.Conv2d(10, 20, kernel_size = 5, padding = 2, stride = 3)
# 创建一个转置卷积层对象tconv 其中输入通道数为20 输出通道数为10 卷积核大小为5 填充为2 步幅为3
# 这会将输入的20个通道的特征图转换回10个通道的图像
tconv = nn.ConvTranspose2d(20, 10, kernel_size = 5, padding = 2, stride = 3)
# 首先对输入张量X进行卷积操作 然后再对卷积的结果进行转置卷积操作
# 然后检查这个结果的形状是否和原始输入张量X的形状相同
# 如果相同 说明转置卷积操作成功地还原了原始输入的形状
tconv(conv(X)).shape == X.shape# 与矩阵变换的联系
# 创建一个一维张量 其中包含从0.0到8.0的连续数字
# 然后将这个一维张量重塑为3x3的二维张量
X = torch.arange(9.0).reshape(3, 3)
# 创建一个2x2的卷积核K 其中包含四个元素:1.0,2.0,3.0,4.0
K = torch.tensor([[1.0, 2.0],[3.0, 4.0]])
# 使用自定义的二维卷积函数corr2d对输入张量X和卷积核K进行卷积操作
# corr2d函数需要在引入d2l(深度学习库)之后才能使用
Y = d2l.corr2d(X, K) # 卷积
# 打印卷积操作的结果
Y# 定义一个函数kernel2matrix 用于将给定的卷积核K转换为一个稀疏矩阵W
def kernel2matrix(K):# 创建长度为5的零向量k和4x9的零矩阵Wk, W = torch.zeros(5), torch.zeros((4,9))# 打印初始状态的kprint(k) # 打印初始状态的Wprint(W)# 打印输入的卷积核Kprint(K)# 将卷积核K的元素填充到向量k中的适当位置 形成一个稀疏向量k[:2], k[3:5] = K[0, :], K[1,:]# 打印填充后的向量kprint(k)# 将稀疏向量k填充到矩阵W中的适当位置 形成一个稀疏矩阵W[0, :5], W[1, 1:6], W[2, 3:8], W[3, 4:] = k, k, k, k# 返回转换后的稀疏矩阵Wreturn W# 每一行向量表示在一个位置的卷积操作 0填充表示卷积核未覆盖到的区域。
# 输入大小为 3 * 3 的图片 拉长一维向量后变成 1 * 9 的向量
# 输入大小为 3 * 3 的图片 卷积核为 2 * 2 则输出图片为 2 * 2 拉长后变为 4 * 1 的向量
# kernel2matrix函数将卷积核改为稀疏矩阵C后矩阵情况# 使用kernel2matrix函数将卷积核K转换为一个稀疏矩阵W
# 这个矩阵的每一行表示在一个特定位置进行的卷积操作 其中的0表示卷积核没有覆盖的区域
# 如果输入是一个3x3的图像 并被拉平为一个1x9的向量
# 而卷积核是2x2的 那么输出图像的大小为2x2 拉平后变为一个4x1的向量
# kernel2matrix函数实际上就是在构建这种转换关系
W = kernel2matrix(K)
W# 打印输入张量X的内容
print(X)
# 使用reshape函数将输入张量X拉平为一个一维向量 并打印结果
# 这是为了将X与稀疏矩阵W进行矩阵乘法操作
print(X.reshape(-1))
# 判断卷积操作的结果Y是否等于稀疏矩阵W与拉平的输入张量X的矩阵乘法的结果 并将结果重塑为2x2的形状
# 这是一种检查卷积操作是否等价于某种矩阵变换的方式
Y == torch.matmul(W, X.reshape(-1)).reshape(2, 2)# 使用自定义的转置卷积函数trans_conv对卷积操作的结果Y和卷积核K进行转置卷积操作
Z = trans_conv(Y, K)
# 判断转置卷积操作的结果Z是否等于稀疏矩阵W的转置与拉平的卷积结果Y的矩阵乘法的结果 并将结果重塑为3x3的形状
# 这是一种检查转置卷积操作是否等价于某种特定的矩阵变换的方式
# 注意这里得到的结果并不是原图像 尽管它们的尺寸是一样的
Z == torch.matmul(W.T, Y.reshape(-1)).reshape(3, 3) # 由卷积后的图像乘以转置卷积后 得到的并不是原图像 而是尺寸一样 全连接卷积神经网络
1 * 1 卷积层来降低维度
转置卷积层把图片扩大,k是通道有多少类,通道数为类别数,则导致可以对每一个像素分类
FCN是用深度神经网络来做语义分割的奠基性工作
其用转置卷积层来替换CNN最后的全连接层 从而可以实现每个像素的预测
# 全连接卷积神经网络
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l# 使用在ImageNet数据集上预训练的ResNet18模型来提取图像特征
pretrained_net = torchvision.models.resnet18(pretrained=True)
# 使用list函数和children方法列出预训练模型的所有子层(这些子层通常是神经网络的层)
# 然后使用Python的切片语法来取出最后三层
# 这可以帮助我们理解模型的结构 特别是在我们打算对模型进行微调或者使用模型的某些层来提取特征时
list(pretrained_net.children())[-3:] # 查看最后三层长什么样子# 创建一个全卷积网络实例net
# 使用预训练的ResNet18模型创建一个新的神经网络
# 其中 "*list(pretrained_net.children())[:-2]"这段代码将ResNet18模型的所有子层(除了最后两层)作为新网络的层
# 这样 新网络实际上是ResNet18模型去掉最后两层后的版本
# 这种方法常常用于迁移学习 即利用一个在大型数据集上训练过的模型的特征提取部分 来帮助我们处理新的任务
net = nn.Sequential(*list(pretrained_net.children())[:-2]) # 去掉ResNet18最后两层
# 创建一个形状为(1, 3, 320, 480)的随机张量 这可以看作是一张形状为(320, 480) 有三个颜色通道的图片
# 这里的3代表图片的颜色通道数量(红、绿、蓝) 320和480分别代表图片的高度和宽度
# 随机张量的所有元素都是在[0, 1)之间随机生成的 可以看作是随机图片的像素值
X = torch.rand(size=(1,3,320,480)) # 卷积核与输入大小无关 全连接层与输入大小有关
# 将随机生成的图片输入到网络中 通过调用net(X) 进行前向传播
# 打印输出张量的形状 输出的形状通常可以用于检查网络的结构是否正确
# 对于全卷积网络 输出的宽度和高度通常会比输入的小 这是由于卷积和池化操作造成的
# 在这个例子中 输出的宽度和高度应该是输入的1/32 这是由ResNet18的结构决定的
net(X).shape # 缩小32倍# 使用1X1卷积层将输出通道数转换为Pascal VOC2012数据集的类数(21类)
# 将要素地图的高度和宽度增加32倍
# 定义目标数据集中的类别数量 这里的21表示Pascal VOC2012数据集中有21个类别 包括20个物体类别和一个背景类别
num_classes = 21
# 在网络末尾添加一个新的卷积层 这是一个1x1的卷积层 输入通道数为512(这是由前面的ResNet18模型决定的)
# 输出通道数为我们定义的类别数量,即21
# 1x1卷积层常用于改变通道数 即可以将前一层的特征图投影到一个新的空间 这个新的空间的维度即为卷积层的输出通道数
net.add_module('final_conv',nn.Conv2d(512,num_classes,kernel_size=1))
# 图片放大32倍 所以stride为32
# padding根据kernel要保证高宽不变的最小值 16 * 2 = 32 图片左右各padding
# kernel为64 原本取图片32大小的一半 再加上padding的32 就相当于整个图片
# 再添加一个转置卷积层 转置卷积也被称为反卷积 通常用于将小尺寸的特征图放大到原来的大小
# 这里的输入和输出通道数都是num_classes 表示我们希望在放大的过程中保持通道数不变
# kernel_size是64 stride是32 这意味着这一层将特征图的宽度和高度放大了32倍
# padding是16 它用于在特征图的边缘添加额外的区域 使得输出的大小正好是输入的32倍
net.add_module('transpose_conv', nn.ConvTranspose2d(num_classes,num_classes,kernel_size=64,padding=16,stride=32)) # 初始化转置卷积层# 双线性插值核的实现
# 定义一个函数 用于初始化双线性插值核
# 这个函数接受三个参数:输入通道数、输出通道数和核大小
def bilinear_kernel(in_channels, out_channels, kernel_size):# 计算双线性插值核中心点位置# 计算双线性插值核的尺寸的一半 由于我们希望中心点位于核的中心 所以需要先计算核的一半大小# 我们使用 // 运算符进行整数除法 确保结果为整数factor = (kernel_size + 1) // 2# 根据核的大小是奇数还是偶数 确定中心点的位置# 如果核的大小是奇数 则中心点位于尺寸的一半减去1的位置 因为Python的索引从0开始 所以减去1# 例如 如果核的大小是3 那么中心点应该位于1的位置 (3+1)//2 - 1 = 1if kernel_size % 2 == 1:center = factor - 1# 如果核的大小是偶数 则中心点位于尺寸的一半减去0.5的位置# 这是因为偶数大小的核没有明确的中心点 所以我们取中间两个元素的平均位置作为中心点# 例如 如果核的大小是4 那么中心点应该位于1.5的位置 (4+1)//2 - 0.5 = 1.5else:center = factor - 0.5# 创建一个矩阵 其元素的值等于其与中心点的距离og = (torch.arange(kernel_size).reshape(-1,1),torch.arange(kernel_size).reshape(1,-1))# 计算双线性插值核 其值由中心点出发 向外线性衰减filt = (1 - torch.abs(og[0] - center) / factor) * (1 - torch.abs(og[1] - center) / factor) # 初始化一个权重矩阵 大小为 (输入通道数, 输出通道数, 核大小, 核大小)weight = torch.zeros((in_channels, out_channels, kernel_size, kernel_size)) # 将双线性插值核的值赋给对应位置的权重weight[range(in_channels),range(out_channels),:,:] = filt# 返回初始化的权重矩阵 这个权重矩阵可以直接用于初始化转置卷积层的权重return weight# 双线性插值的上采样实验
# 创建一个转置卷积层 输入和输出通道数都是3 这是因为我们处理的是RGB图片 每个颜色通道都需要进行处理
# 核大小是4 步长是2 这意味着这个层将输入的宽度和高度放大了2倍
# 设置bias为False 因为我们不需要偏置项
conv_trans = nn.ConvTranspose2d(3,3,kernel_size=4,padding=1,stride=2,bias=False)
# 使用双线性插值核初始化转置卷积层的权重
# 这里我们使用了copy_方法 这是一种就地操作 直接修改了原始张量的值
conv_trans.weight.data.copy_(bilinear_kernel(3,3,4)) # 双线性核初始化权重
# 使用torchvision.transforms.ToTensor()将一张JPEG格式的图片转换为张量
img = torchvision.transforms.ToTensor()(d2l.Image.open('01_Data/03_catdog.jpg'))
# 增加一个批次维度
X = img.unsqueeze(0)
# 将图片张量输入到转置卷积层中 得到上采样的结果
Y = conv_trans(X)
# 将输出结果转换为可以展示的格式 即(高度, 宽度, 颜色通道)的格式 并从计算图中分离出来 这样就可以转换为NumPy数组
out_img = Y[0].permute(1,2,0).detach()
# 设置展示图片的大小
d2l.set_figsize()
# 打印输入图片的形状
print('input image shape:', img.permute(1,2,0).shape)
# 展示图片
d2l.plt.imshow(img.permute(1,2,0))
# 打印输出图片的形状并展示图片
# 可以看到 输出图片的宽度和高度都是输入的2倍 这正是我们设置的步长
print('output image shape:',out_img.shape) # 输出被拉大了2倍
# 并展示图片
d2l.plt.imshow(out_img)# 用双线性插值的上采样初始化转置卷积层
# 对于1X1卷积层 我们使用Xavier初始化参数
# 使用双线性插值核初始化转置卷积层的权重
# num_classes是目标数据集中的类别数量 这里使用双线性插值核的尺寸为64
W = bilinear_kernel(num_classes, num_classes, 64)
# 将初始化的权重W复制给转置卷积层的权重
# 使用copy_方法进行就地操作 直接修改原始张量的值
net.transpose_conv.weight.data.copy_(W)注:上述内容参考b站up主“我是土堆”的视频,参考吴恩达深度学习,机器学习内容,参考李沐动手学深度学习!!!
相关文章:
)
由浅入深,走进深度学习(补充篇:转置卷积和FCN)
本期内容是针对神经网络层结构的一个补充,主要内容是:转置卷积和全连接卷积网络 相关内容: 由浅入深,走进深度学习(2)_卷积层-CSDN博客 由浅入深,走进深度学习(补充篇:…...

Linux基础篇——目录结构
基本介绍 Linux的文件系统是采用级层式的树状目录结构,在此结构中的最上层是根目录"/",然后在根目录下再创建其他的目录 在Linux中,有一句经典的话:在Linux世界里,一切皆文件 Linux中根目录下的目录 具体的…...

星际编码:Swifter.Json,.NET宇宙中的数据处理新星
概述 在数字化的星辰大海中,数据是宇宙的通用语言。在.NET这一广袤的星系中,JSON作为信息交换的媒介,扮演着至关重要的角色。今天,我们要探索的是一颗新星——Swifter.Json,一个功能全面且性能卓越的JSON序列化和反序列…...

python 压缩数据
requests 是 Python 中一个非常流行的 HTTP 库,用于发送各种 HTTP 请求。下面是一个使用 requests 库发送简单 GET 请求和 POST 请求的示例: 首先,确保你已经安装了 requests 库。如果还没有安装,可以使用 pip 进行安装ÿ…...

nacos在k8s上的集群安装实践
目录 概述实践nfs安装使用 k8s持久化nacos安装创建角色部署数据库执行数据库初始化语句部署nacos ingress效果展示问题修复 结束 概述 本文主要对 nacos 在k8s上的集群安装 进行说明与实践。主要版本信息,k8s: 1.27.x,nacos: 2.0.3。运行环境为 centos 7…...

数据结构—判断题
1.数据的逻辑结构说明数据元素之间的顺序关系,它依赖于计算机的存储结构。 答案:错误 2.(neuDS)在顺序表中逻辑上相邻的元素,其对应的物理位置也是相邻的。 答案:正确 3.若一个栈的输入序列为{1, 2, 3, 4, 5},则不…...

树莓派挂载的移动硬盘badblocks坏道屏蔽,以这个为准
!!!use 这里要设置块大小和磁盘相同 badblocks -b 4096 -s -c 512 -v -o /a/2/bads4.txt /dev/sda5 检测完重新检测跳过之前的记录 badblocks -i /a/2/bads4.txt -b 4096 -s -c 512 -v -o /a/2/bads5.txt /dev/sda5 可以查看磁盘具体block总数和大小 sudo dumpe2fs /dev/sda5 …...
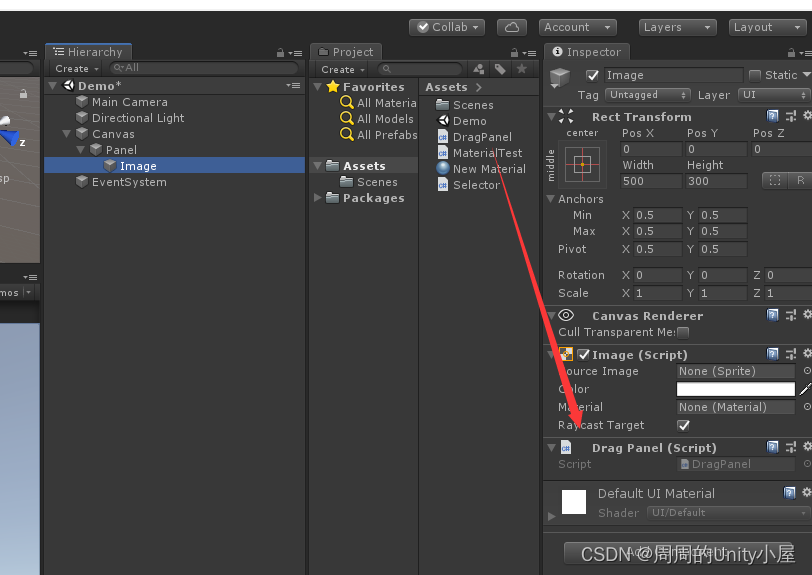
Unity开箱即用的UGUI面板的拖拽移动功能
文章目录 👉一、背景👉二、效果图👉三、原理👉四、核心代码👉五,总结 👉一、背景 之前做PC项目时常常有面板拖拽移动的需求,今天总结封装一下,做成一个随时随地可复用的…...
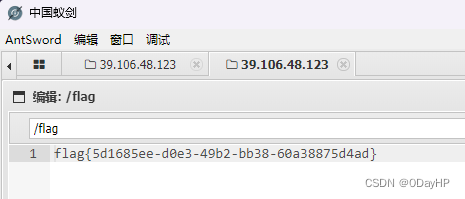
春秋云境:CVE-2022-25411[漏洞复现]
根据题目提示和CNNVD优先寻找后台管理地址 靶机启动后,使用AWVS进行扫描查看网站结构 在这里可以看到后台管理的登录地址:/admin/,根据题目提示可知是弱口令 尝试admin、123456、admin666、admin123、admin888...等等常见弱口令 正确的账户…...
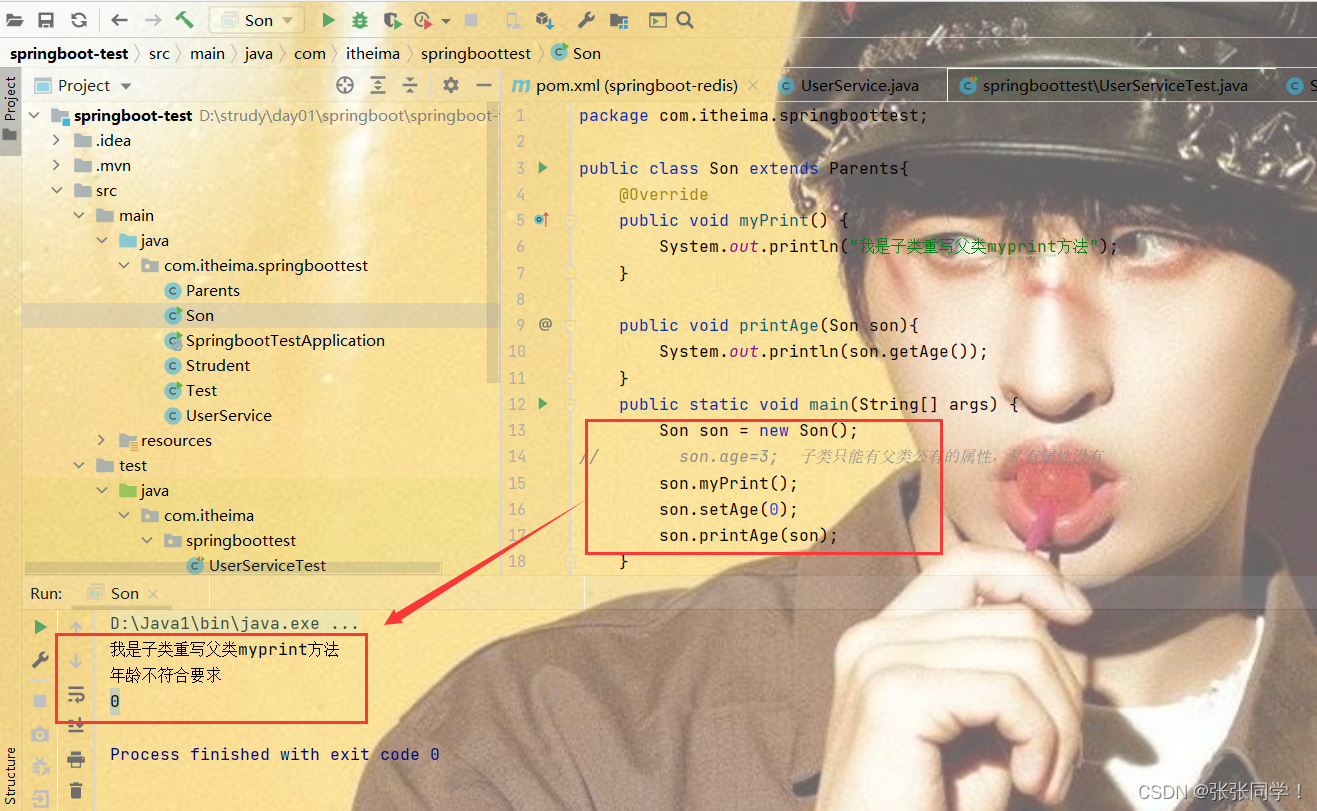
java基础知识点全集
JAVA的所有知识点 一、基础的数组、数据类型、输入输出二、类与对象1. 三大特征(1) 封装(2)继承(3)多态 2. 类的实例化(1) 类通过NEW来创建(2) 类的继承&…...
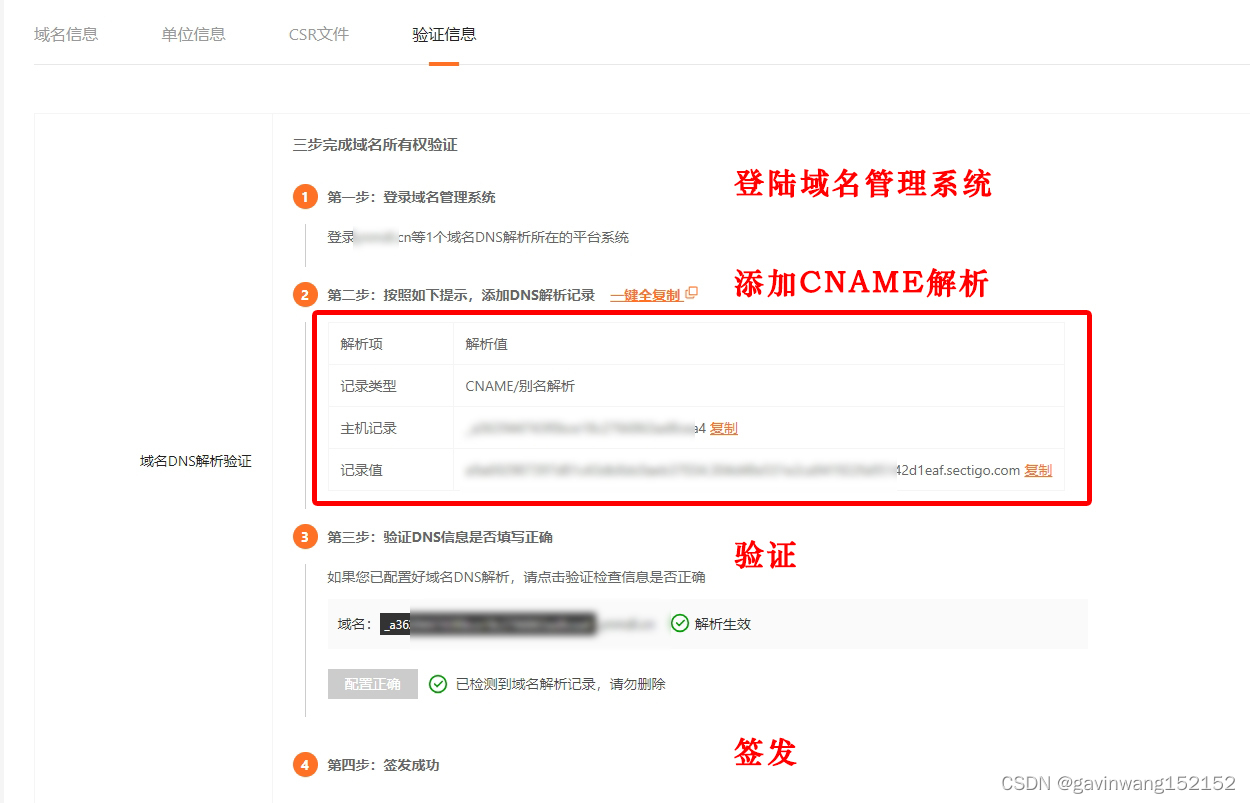
如何完成域名解析验证
一:什么是DNS解析: DNS解析是互联网上将人类可读的域名(如www.example.com)转换为计算机可识别的IP地址(如192.0.2.1)的过程,大致遵循以下步骤: 查询本地缓存:当用户尝…...

2024年6月个人工作生活总结
title: 2024年6月个人工作生活总结 urlname: code-for-2024-06 tags: 代码积累知识总结 categories:我的程序代码 date: 2024-06-30 00:00:00 photos:gallery/tech/c2.jpg 本文为 2024年6月工作生活总结。 研发编码 编码和注释 因某些需要,重拾了2019年的工程代码…...
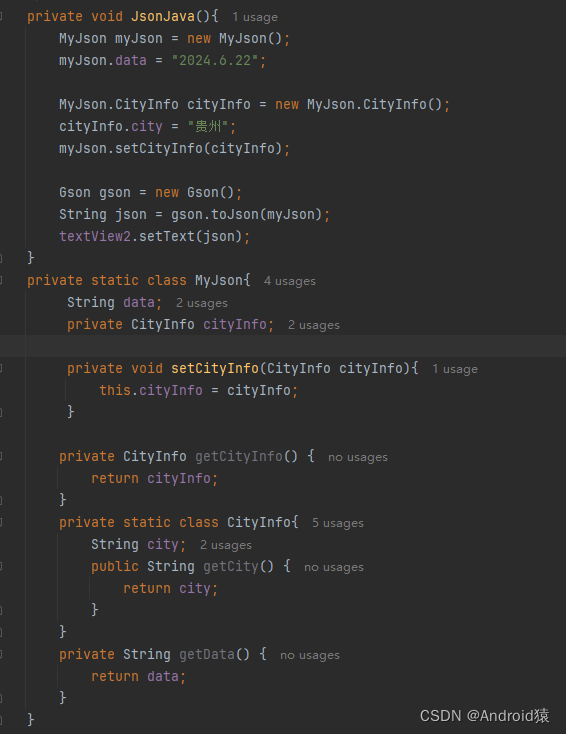
Json与Java类
简介 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。JSON数据由键值对构成,并以易于阅读的文本形式展现,支持数组、对象、字符串、数字、布尔值…...

动手学深度学习(Pytorch版)代码实践 -计算机视觉-39实战Kaggle比赛:狗的品种识别(ImageNet Dogs)
39实战Kaggle比赛:狗的品种识别(ImageNet Dogs) 比赛链接:Dog Breed Identification | Kaggle 1.导入包 import torch from torch import nn import collections import math import os import shutil import torchvision from…...

在Linux系统中挂载硬盘
目录 1. 查看硬盘信息 2. 分区硬盘(如果硬盘没有分区) 3. 格式化分区 4. 创建挂载点 5. 挂载分区 6. 验证挂载 7.设置开机自动挂载(可选) 1. 查看硬盘信息 lsblk 这个命令会列出所有的块设备,包括硬盘 2.…...
安卓短视频去水印v1.7 简洁好用
各大平台视频无水印提取,登录即永久会员! 无水印提取,图片无水印提取 视频旋转,倒放,转gif等功能。 链接:https://pan.baidu.com/s/1UgO4V16ZM34tG5uDog74Pg?pwdcn0u 提取码:cn0u...
【征服数据结构】:期末通关秘籍
【征服数据结构】:期末通关秘籍 💘 数据结构的基本概念😈 数据结构的基本概念😈 逻辑结构和存储结构的区别和联系😈 算法及其特性😈 简答题 💘 线性表(链表、单链表)&…...

GIT 基于master分支创建hotfix分支的操作
基于master分支创建hotfix分支的操作通常遵循以下步骤: 切换到master分支: 首先,确保你的工作区是最新的,并且你在master分支上。如果不在master分支,你需要先切换过去。 Bash git checkout master 拉取最新的master…...
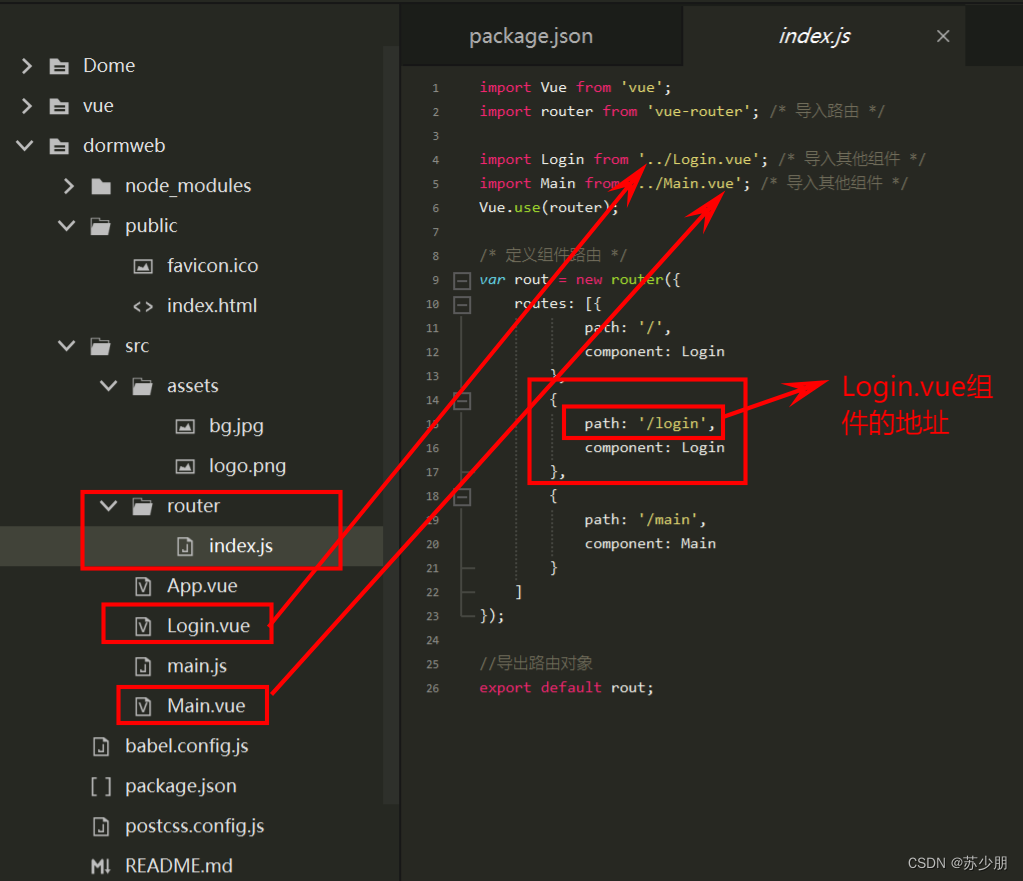
Vue-CLI脚手架与node.js安装
前言: Vue-CLI 是一个基于 Vue.js 快速开发单页应用的官方脚手架工具,能够帮助开发者快速搭建前端项目的基础结构。在开始使用 Vue-CLI 前,首先需要安装 Node.js,因为 Vue-CLI 是基于 Node.js 构建的。 Node.js 是一个基于 Chrom…...
自适应站长跑路单页网站源码
跑路单页HTML源码自行修改文字就行了,上传到服务器里面运行即可,本地运行的话音乐会加载不出来,涉及到跨域问题 自适应站长跑路单页网站源码...

窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧
窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的应用程序窗口而束手无策吗?是…...

Arm Iris调试接口:架构设计与工程实践详解
1. Iris调试与追踪接口深度解析调试与追踪技术是嵌入式系统开发的核心支柱,而Arm的Iris接口代表了这一领域的最新进展。作为一名长期从事嵌入式调试工具开发的工程师,我将带您深入剖析这套接口的设计哲学与实战应用。1.1 接口架构设计理念Iris的架构设计…...

【Midjourney图像生成黑科技】:树胶重铬酸盐工艺原理、复刻难点与AI艺术胶片质感还原全流程指南
更多请点击: https://intelliparadigm.com 第一章:树胶重铬酸盐工艺的历史溯源与数字时代复兴意义 树胶重铬酸盐工艺(Gum Bichromate Process)诞生于19世纪中叶,是人类最早实现光敏图像复制的化学摄影术之一。其核心原…...

面试鸭:程序员面试备战工作台,构建结构化知识图谱与智能复习系统
1. 项目概述:一个面向求职者的“面试鸭”最近在技术社区里,看到不少朋友在讨论一个叫“mianshiya”的开源项目。乍一看这个名字,还以为是哪个美食博主分享的菜谱。点进去才发现,这其实是一个为程序员,特别是正在准备面…...

CC2530与ESP8266物联网网关:ZigBee转Wi-Fi通信协议转换实战
1. 项目概述:当ZigBee遇上Wi-Fi最近在折腾一个智能家居的传感器节点,核心是TI的CC2530 ZigBee芯片。这玩意儿功耗低、组网方便,是很多低功耗传感网络的绝佳选择。但问题来了,ZigBee网络的数据最终怎么方便地送到我们手机上去看呢&…...

Carapace:统一跨Shell命令行补全的Go语言引擎
1. 项目概述:一个为Shell而生的全能补全引擎 如果你和我一样,每天有超过一半的工作时间是在终端里度过的,那你一定对命令行补全这件事又爱又恨。爱的是,一个恰到好处的补全能让你行云流水,效率倍增;恨的是…...

从单体智能到组织智能:AgentOrg多智能体系统架构与实战
1. 项目概述:从单体智能到组织智能的范式跃迁最近在AI Agent领域,一个名为“AgentOrg”的开源项目引起了我的注意。这个由Angelopvtac发起的项目,其核心思想非常吸引人:它不再将AI Agent视为一个孤立的、执行单一任务的智能体&…...

ARM架构寄存器与参数管理核心技术解析
1. ARM架构寄存器与参数管理基础解析 在ARM架构的底层开发中,寄存器与参数管理是系统控制和调试的核心机制。作为嵌入式开发者,我经常需要与这两种资源打交道,它们虽然都用于存储数据,但在使用场景和特性上存在本质差异。 寄存器…...

【c++面向对象编程】第24篇:类型转换运算符:自定义隐式转换与explicit
目录 一、一个自然的想法 二、类型转换运算符的基本语法 写法 使用 三、隐式转换的风险 问题1:意外的不希望发生的转换 问题2:多个转换路径的歧义 问题3:与构造函数隐式转换叠加导致混乱 四、explicit:禁止隐式转换 语法…...

本地大模型Web API桥梁:llm-web-api部署与OpenAI兼容实践
1. 项目概述:一个为本地大语言模型提供Web API的轻量级桥梁如果你和我一样,热衷于在本地部署各种开源大语言模型(LLM),比如Llama、Qwen、Mistral,那么你一定遇到过这样的痛点:模型本身跑起来了&…...