【C命名规范】遵循良好的命名规范,提高代码的可读性、可维护性和可复用性
/********************************************************************
* @brief @param @return @author @date @version是代码书写的一种规范
* @brief :简介,简单介绍函数作用
* @param :介绍函数参数
* @return:函数返回类型说明
* @exception NSException 可能抛出的异常.
* @author zhangsan: 作者
* @date 2011-07-27 22:30:00 :时间
* @version 1.0 :版本
* @property :属性介绍
* *********************************************************************/【变量的命名习惯】
变量名是自定义的,严格遵循 标识符 命名规则。
- 见名知意
- 大驼峰:即每个单词首字母都大写,例如:
MyName - 小驼峰:即第二个(含)以后的单词首字母大写,例如:
myName - 小写+下划线:例如:
my_name
个人风格分享
1.变量
-
全局变量:小驼峰(小驼峰+下划线),例如
myName或my_Name -
局部变量: 全小写(小写+下划线),例如
index或my_name
2.常量: 全大写字母、下划线分隔单词和描述性名称
#define MAX_BUFFER_SIZE 1024
#define PI_VALUE 3.14159
#define DEFAULT_TIMEOUT 30
3.标志变量
- 全局:
g_+ 小驼峰 + 下划线,例如g_has_Err - 局部:
g_+ 全小写 + 下划线 , 例如g_has_err
4.函数名 大驼峰(大驼峰+下划线), 例如 GetValue, Get_Value()
动词+名词结构 ,例如
GetValue,Get_Value()
5.结构体 大驼峰(大驼峰 + 下划线),例如
// 定义结构体
typedef struct {int id; // 结构体成员局部的用小写char name[50];int age;
} StudentInfo;
// Student_Info
6.枚举 : 枚举成员名使用全大写字母, 前缀标识枚举成员
typedef enum {STATUS_SUCCESS, // 前缀标识枚举成员STATUS_ERROR, // 全大写字母STATUS_PENDING
} StatusCode;
// Status_Code;
总结就是凡是有带大写的都跟全局有关,凡是标志位够加g_,常量用全大写字母表示。
在C语言编程中,良好的命名规则有助于提高代码的可读性、可维护性和可扩展性。以下是一些值得学习和遵守的命名规则:
-
变量命名规则:
- 使用小写字母,单词之间用下划线分隔,例如:
student_age,total_sum,index。 - 变量名应具有描述性,反映其用途或含义。
- 使用小写字母,单词之间用下划线分隔,例如:
-
常量命名规则:
- 使用全大写字母,单词之间用下划线分隔,例如:
MAX_BUFFER_SIZE,PI_VALUE。 - 常量名通常使用
#define或const关键字定义。
- 使用全大写字母,单词之间用下划线分隔,例如:
-
函数命名规则:
- 使用动词或动词短语开头,后接名词,单词之间用下划线分隔,例如:
calculate_sum,print_student_info。 - 函数名应清晰描述其功能或操作。
- 使用动词或动词短语开头,后接名词,单词之间用下划线分隔,例如:
-
结构体和联合体命名规则:
- 结构体和联合体类型名使用大写字母开头,每个单词的首字母大写,例如:
StudentInfo,EmployeeRecord。 - 结构体变量名使用小写字母,单词之间用下划线分隔,例如:
student_info,employee_record。
- 结构体和联合体类型名使用大写字母开头,每个单词的首字母大写,例如:
-
枚举命名规则:
- 枚举类型名使用大写字母开头,每个单词的首字母大写,例如:
Color,Status。 - 枚举成员名使用全大写字母,单词之间用下划线分隔,例如:
RED,GREEN,SUCCESS,FAILURE。
- 枚举类型名使用大写字母开头,每个单词的首字母大写,例如:
-
文件名规则:
- 文件名应简洁且具有描述性,通常使用小写字母,单词之间用下划线分隔,例如:
main.c,student_info.h。
- 文件名应简洁且具有描述性,通常使用小写字母,单词之间用下划线分隔,例如:
-
缩写和简写:
- 尽量避免使用不常见的缩写和简写,如果使用缩写,确保其含义清晰并在代码中有解释。
-
命名长度:
- 命名长度应适中,过长的名字会影响可读性,过短的名字则可能不够描述性。一般推荐变量名长度在3-20个字符之间。
-
前缀和后缀:
- 使用前缀或后缀区分不同作用域或用途的变量,例如:全局变量使用
g_前缀,静态变量使用s_前缀,指针变量使用_ptr后缀。
- 使用前缀或后缀区分不同作用域或用途的变量,例如:全局变量使用
通过遵守这些命名规则,可以使代码更具可读性和可维护性,减少出错的概率。
全局变量的标志位变量命名时,应该遵循一些具体的规则,以确保代码的可读性和易维护性。以下是一些建议:
-
使用前缀标识全局变量:
- 以
g_前缀来标识全局变量。例如:g_flag_connected,g_flag_initialized。
- 以
-
清晰描述变量含义:
- 变量名应反映其用途或含义。使用描述性单词使其一目了然。例如:
g_flag_error_occurred,g_flag_data_ready。
- 变量名应反映其用途或含义。使用描述性单词使其一目了然。例如:
-
使用布尔命名约定:
- 对于布尔类型的标志位变量,使用
is,has,can等前缀。例如:g_is_connected,g_has_error,g_can_read。
- 对于布尔类型的标志位变量,使用
-
统一命名风格:
- 保持命名的一致性,确保团队中所有开发者遵循相同的命名规范。例如:所有标志位变量都以
g_flag_开头,然后描述具体含义。
- 保持命名的一致性,确保团队中所有开发者遵循相同的命名规范。例如:所有标志位变量都以
-
避免使用缩写:
- 除非是非常常见和容易理解的缩写,否则尽量避免使用缩写,以防止误解。例如:
g_flag_buffer_overflow而不是g_flag_buf_ovf。
- 除非是非常常见和容易理解的缩写,否则尽量避免使用缩写,以防止误解。例如:
-
示例命名:
g_flag_initialized- 表示系统或模块是否已初始化。g_flag_error_occurred- 表示是否发生了错误。g_flag_data_ready- 表示数据是否已经准备好。g_is_connected- 表示是否已经连接。g_has_data- 表示是否有数据可用。
通过遵守这些命名规则,可以使代码更具可读性和一致性,方便团队协作和代码维护。
在单片机开发中,良好的编程习惯和命名规则可以极大地提高代码的可读性、可维护性和可靠性。以下是一些值得学习和遵守的编程习惯和命名规则:
编程习惯
-
注释代码:
- 在代码中添加必要的注释,解释代码的功能、逻辑和重要的变量或函数。确保注释清晰且有意义。
-
模块化编程:
- 将代码划分为多个模块或文件,每个模块负责特定的功能。这样可以提高代码的可维护性和可复用性。
-
使用常量和宏定义:
- 使用
#define或const定义常量,避免在代码中使用硬编码的数值。例如:#define MAX_BUFFER_SIZE 1024。
- 使用
-
初始化所有变量:
- 在使用变量之前进行初始化,以防止未定义行为和潜在的错误。
-
防御性编程:
- 编写健壮的代码,处理所有可能的错误情况和异常情况。使用断言(assert)来捕捉不应出现的条件。
-
合理使用中断:
- 中断服务程序(ISR)应该尽量短小精悍,避免在ISR中执行耗时操作。将复杂的处理移到主程序中完成。
-
遵循代码规范:
- 遵循团队或项目的编码规范,确保代码风格一致。常见的编码规范包括命名规则、缩进风格、括号位置等。
命名规则
-
变量命名:
- 使用描述性名称,避免使用单个字符或无意义的名称。变量名应反映其用途或含义。
- 使用小写字母,单词之间用下划线分隔。例如:
sensor_value,motor_speed。
-
常量命名:
- 使用全大写字母,单词之间用下划线分隔。例如:
MAX_BUFFER_SIZE,PI_VALUE。
- 使用全大写字母,单词之间用下划线分隔。例如:
-
函数命名:
- 使用动词或动词短语开头,后接名词,单词之间用下划线分隔。例如:
init_motor,read_sensor_value。
- 使用动词或动词短语开头,后接名词,单词之间用下划线分隔。例如:
-
结构体和枚举命名:
- 结构体和枚举类型名使用大写字母开头,每个单词的首字母大写,例如:
SensorData,ErrorCode。 - 结构体变量名使用小写字母,单词之间用下划线分隔,例如:
sensor_data,error_code。
- 结构体和枚举类型名使用大写字母开头,每个单词的首字母大写,例如:
-
宏定义命名:
- 使用全大写字母,单词之间用下划线分隔。例如:
#define LED_PIN 13,#define TIMER_PERIOD 1000。
- 使用全大写字母,单词之间用下划线分隔。例如:
-
文件命名:
- 文件名应简洁且具有描述性,通常使用小写字母,单词之间用下划线分隔,例如:
main.c,sensor_driver.h。
- 文件名应简洁且具有描述性,通常使用小写字母,单词之间用下划线分隔,例如:
代码示例
// 常量和宏定义
#define MAX_BUFFER_SIZE 1024
#define LED_PIN 13// 结构体定义
typedef struct {int sensor_value;float temperature;
} SensorData;// 函数声明
void init_motor(void);
int read_sensor_value(void);// 主函数
int main(void) {// 变量初始化SensorData sensor_data = {0, 0.0};int sensor_value = 0;// 初始化电机init_motor();// 读取传感器值sensor_value = read_sensor_value();// 处理传感器数据sensor_data.sensor_value = sensor_value;sensor_data.temperature = sensor_value * 0.1;return 0;
}// 函数定义
void init_motor(void) {// 初始化电机的代码
}int read_sensor_value(void) {// 读取传感器值的代码return 42;
}
这些编程习惯和命名规则可以帮助你编写更高质量、更易维护的代码,尤其是在团队协作和长期维护中显得尤为重要。
在编程中,断言(assert)是一种用于捕捉不应出现的条件的调试工具。断言可以在开发和调试过程中帮助检测程序中的逻辑错误和不一致性。当程序运行时,如果断言条件为假(false),程序会立即终止,并输出错误信息,方便开发者定位和修复问题。
使用断言的步骤
-
包含头文件:
- 使用断言前,需要包含头文件
<assert.h>。
- 使用断言前,需要包含头文件
-
使用
assert宏:- 使用
assert宏来检查条件。语法如下:#include <assert.h>void some_function(int value) {assert(value > 0); // 如果 value <= 0,程序将终止并输出错误信息 }
- 使用
-
编译时控制:
- 断言在调试阶段非常有用,但在发布阶段可能不需要。可以通过定义
NDEBUG来禁用断言。#define NDEBUG #include <assert.h>
- 断言在调试阶段非常有用,但在发布阶段可能不需要。可以通过定义
示例代码
以下是一个使用断言的示例代码:
#include <assert.h>
#include <stdio.h>// 计算数组中元素的平均值
double calculate_average(int *array, int size) {// 断言数组指针不为空assert(array != NULL);// 断言数组大小大于0assert(size > 0);int sum = 0;for (int i = 0; i < size; i++) {sum += array[i];}return (double)sum / size;
}int main() {int values[] = {10, 20, 30, 40, 50};int size = sizeof(values) / sizeof(values[0]);// 调用函数前的断言assert(size > 0);double average = calculate_average(values, size);printf("Average: %.2f\n", average);return 0;
}
解释
-
包含头文件:
- 代码中首先包含了
<assert.h>头文件,这个头文件定义了assert宏。
- 代码中首先包含了
-
使用
assert宏:- 在
calculate_average函数中,使用了两个断言来确保输入的数组指针不为空且数组大小大于0。 - 在
main函数中,使用了一个断言来确保数组大小大于0。
- 在
-
断言失败:
- 如果
assert条件为假,程序将终止并输出错误信息,包括断言失败的条件和源代码文件中的行号。
- 如果
禁用断言
在发布阶段,可以通过定义 NDEBUG 来禁用断言。例如:
#define NDEBUG
#include <assert.h>
在定义 NDEBUG 后,所有 assert 语句将被预处理器移除,断言检查将不会在程序运行时执行。
总结
使用断言可以有效地捕捉程序中不应出现的条件,帮助开发者在调试阶段快速定位和修复逻辑错误。通过合理使用断言,可以提高代码的健壮性和可靠性。在发布阶段,可以通过定义 NDEBUG 来禁用断言,确保程序的性能和稳定性。
在项目中使用单片机的多个串口(如串口0、串口1、串口2)进行数据收发时,可以使用结构体来组织相关的变量,以便管理和操作这些串口。以下是一个示例,定义了一个结构体来表示三个串口的相关变量:
typedef struct {// 串口0相关变量volatile uint8_t uart0_rx_buffer[UART_RX_BUFFER_SIZE];volatile uint8_t uart0_tx_buffer[UART_TX_BUFFER_SIZE];volatile uint8_t uart0_rx_index;volatile uint8_t uart0_tx_index;volatile bool uart0_rx_complete;// 串口1相关变量volatile uint8_t uart1_rx_buffer[UART_RX_BUFFER_SIZE];volatile uint8_t uart1_tx_buffer[UART_TX_BUFFER_SIZE];volatile uint8_t uart1_rx_index;volatile uint8_t uart1_tx_index;volatile bool uart1_rx_complete;// 串口2相关变量volatile uint8_t uart2_rx_buffer[UART_RX_BUFFER_SIZE];volatile uint8_t uart2_tx_buffer[UART_TX_BUFFER_SIZE];volatile uint8_t uart2_rx_index;volatile uint8_t uart2_tx_index;volatile bool uart2_rx_complete;
} SerialPorts;// 定义一个实例化的结构体变量
SerialPorts serial_ports;
结构体成员说明:
- uartX_rx_buffer: 串口X接收缓冲区,用于存储从串口X接收到的数据。
- uartX_tx_buffer: 串口X发送缓冲区,用于存储待发送至串口X的数据。
- uartX_rx_index: 串口X接收缓冲区的索引,指示下一个接收数据的位置。
- uartX_tx_index: 串口X发送缓冲区的索引,指示下一个发送数据的位置。
- uartX_rx_complete: 串口X接收完成标志,用于指示是否完成了一次数据接收。
注意事项:
-
volatile 关键字:
- 在单片机编程中,通常使用
volatile关键字来声明这些变量,以确保编译器不会对它们进行优化,保证每次访问都是直接从内存中读取或写入。
- 在单片机编程中,通常使用
-
缓冲区大小定义:
UART_RX_BUFFER_SIZE和UART_TX_BUFFER_SIZE是根据实际需求定义的宏或常量,表示串口接收和发送缓冲区的大小。
-
多个串口的区分:
- 结构体中通过命名方式区分不同的串口变量,如
uart0_...、uart1_...、uart2_...。
- 结构体中通过命名方式区分不同的串口变量,如
通过这种方式,你可以方便地管理和操作多个串口的数据收发,使代码结构更清晰,易于维护和扩展。
相关文章:

【C命名规范】遵循良好的命名规范,提高代码的可读性、可维护性和可复用性
/******************************************************************** * brief param return author date version是代码书写的一种规范 * brief :简介,简单介绍函数作用 * param :介绍函数参数 * return:函数返回类型说明 * …...

Hbase面试题总结
一、介绍下HBase架构 --HMaster HBase集群的主节点,负责管理和协调整个集群的操作。它处理元数据和表的分区信息,控制RegionServer的负载均衡和故障恢复。--RegionServer HBase集群中的工作节点,负责存储和处理数据。每个RegionServer管理若…...

C语言部分复习笔记
1. 指针和数组 数组指针 和 指针数组 int* p1[10]; // 指针数组int (*p2)[10]; // 数组指针 因为 [] 的优先级比 * 高,p先和 [] 结合说明p是一个数组,p先和*结合说明p是一个指针 括号保证p先和*结合,说明p是一个指针变量,然后指…...
 : 用override set 设置工具链)
Rust学习笔记 (命令行命令) : 用override set 设置工具链
在cargo run某个项目时出现了如下错误:error: failed to run custom build command for ring v0.16.20(无法运行“Ring v0.16.20”的自定义构建命令),在PowerShell命令行运行命令 rustup override set stable-msvc后成功运行。 o…...

cv::Mat类的矩阵内容输出的各种格式的例子
操作系统:ubuntu22.04OpenCV版本:OpenCV4.9IDE:Visual Studio Code编程语言:C11 功能描述 我们可以这样使用:cv::Mat M(…); cout << M;,直接将矩阵内容输出到控制台。 输出格式支持多种风格,包括O…...

Redis--注册中心集群 Cluster 集群-单服务器
与“多服务器集群”一致需要创建redis配置模板 参照以下链接 CSDN 创建redis容器 node01服务器上创建容器 docker run -d --name redis-6381 --net host --privilegedtrue \ -v /soft/redis-cluster/6381/conf/redis.conf:/etc/redis/redis.conf \ -v /soft/redis-cluster/6…...
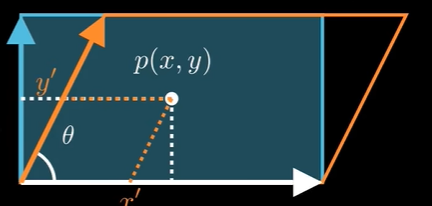
CV01_相机成像原理与坐标系之间的转换
目录 0.引言:小孔成像->映射表达式 1. 相机自身的运动如何表征?->外参矩阵E 1.1 旋转 1.2 平移 2. 如何投影到“像平面”?->内参矩阵K 2.1 图像平面坐标转换为像素坐标系 3. 三维到二维的维度是如何丢失的?…...
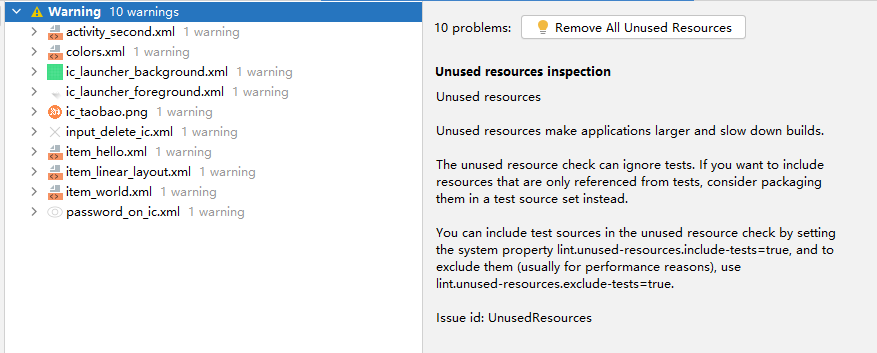
Android Lint
文章目录 Android Lint概述工作流程Lint 问题问题种类警告严重性检查规则 用命令运行 LintAndroidStudio 使用 Lint忽略 Lint 警告gradle 配置 Lint查找无用资源文件 Android Lint 概述 Lint 是 Android 提供的 代码扫描分析工具,它可以帮助我们发现代码结构/质量…...

【算法刷题 | 动态规划14】6.28(最大子数组和、判断子序列、不同的子序列)
文章目录 35.最大子数组和35.1题目35.2解法:动规35.2.1动规思路35.2.2代码实现 36.判断子序列36.1题目36.2解法:动规36.2.1动规思路36.2.2代码实现 37.不同的子序列37.1题目37.2解法:动规37.2.1动规思路37.2.2代码实现 35.最大子数组和 35.1…...
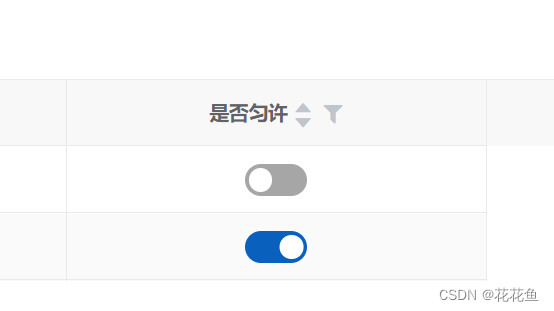
vue3 vxe-grid列中绑定vxe-switch实现数据更新
1、先上一张图: <template #valueSlot"{ row }"><vxe-switch :value"getV(row.svalue)" change"changeSwitch(row)" /></template>function getV(value){return value 1;};function changeSwitch(row) {console.l…...

Hive SQL:实现炸列(列转行)以及逆操作(行转列)
目录 列转行行转列 列转行 函数: EXPLODE(ARRAY):将ARRAY中的每一元素转换为每一行 EXPLODE(MAP):将MAP中的每个键值对转换为两行,其中一行数据包含键,另一行数据包含值 数据样例: 1、将每天的课程&#…...

MD5算法详解
哈希函数 是一种将任意输入长度转变为固定输出长度的函数。 一些常见哈希函数有:MD5、SHA1、SHA256。 MD5算法 MD5算法是一种消息摘要算法,用于消息认证。 数据存储方式:小段存储。 数据填充 首先对我们明文数据进行处理,使其…...

ES6的代理模式-Proxy
语法 target 要使用 Proxy 包装的目标对象(可以是任何类型的对象,包括原生数组,函数,甚至另一个代理handler 一个通常以函数作为属性的对象,用来定制拦截行为 const proxy new Proxy(target, handle)举个例子 <s…...

排序(堆排序、快速排序、归并排序)-->深度剖析(二)
前言 前面介绍了冒泡排序、选择排序、插入排序、希尔排序,作为排序中经常用到了算法,还有堆排序、快速排序、归并排序 堆排序(HeaSort) 堆排序的概念 堆排序是一种有效的排序算法,它利用了完全二叉树的特性。在C语言…...

七一建党节|热烈庆祝中国共产党成立103周年!
时光荏苒,岁月如梭。 在这热情似火的夏日, 我们迎来了中国共产党成立103周年的重要时刻。 这是一个值得全体中华儿女共同铭记和庆祝的日子, 也是激励我们不断前进的重要时刻。 103年, 风雨兼程,砥砺前行。 从嘉兴…...

Spring Boot应用知识梳理
一.简介 Spring Boot 是一个用于快速开发基于 Spring 框架的应用程序的工具。它简化了基于 Spring 的应用程序的配置和部署过程,提供了一种快速、便捷的方式来构建独立的、生产级别的 Spring 应用程序。 Spring Boot 的一些主要优点包括: 1. 简化配置…...

Spring中利用重载与静态分派
Spring中利用重载与静态分派 在Java和Spring框架中,重载(Overloading)和静态分派(Static Dispatch)是两个非常重要的概念,它们在处理类方法选择和执行过程中扮演着关键角色。本文旨在深入探讨Spring环境下…...

文本三剑客之awk:
文本三剑客awk: grep 查 sed 增删改查 主要:增改 awk 按行取列 awk awk默认的分隔符:空格,tab键,多个空格自动压缩为一个。 awk的工作原理:根据指令信息,逐行的读取文本内容,然…...

SpringSecurity-授权示例
用户基于权限进行授权 定义用户与权限 authorities()。 package com.cms.config;import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.security.core.userdetails.User; import…...

选哪个短剧系统源码好:全面评估与决策指南
在短剧内容创作和分享日益流行的今天,选择合适的短剧系统源码对于构建一个成功的短剧平台至关重要。短剧系统源码不仅关系到平台的稳定性和用户体验,还直接影响到内容创作者和观众的互动质量。本文将提供一份全面的评估指南,帮助您在众多短剧…...

VTube Studio终极指南:30分钟快速打造专业虚拟主播形象
VTube Studio终极指南:30分钟快速打造专业虚拟主播形象 【免费下载链接】VTubeStudio VTube Studio API Development Page 项目地址: https://gitcode.com/gh_mirrors/vt/VTubeStudio 想要开启虚拟主播之旅,却被复杂的技术门槛吓退?VT…...
)
告别复制粘贴!用Keil MDK 5.27为GD32F450搭建专属工程模板(附完整文件结构)
打造高效嵌入式开发工作流:基于Keil MDK 5.27的GD32F450工程模板设计指南 在嵌入式开发领域,重复劳动是效率的最大敌人。每次启动新项目时,开发者往往需要花费大量时间在基础环境搭建、文件结构组织和编译配置上。这种低效的工作模式不仅消耗…...

Sekai Stickers:如何用这款开源工具快速创建个性化Discord表情包
Sekai Stickers:如何用这款开源工具快速创建个性化Discord表情包 【免费下载链接】sekai-stickers Project Sekai sticker maker 项目地址: https://gitcode.com/gh_mirrors/se/sekai-stickers 在Discord社区交流中,表情包已经成为表达情感、活跃…...

别再只盯着网线了!从双绞线到光纤,聊聊家庭网络布线选材的实战避坑指南
家庭网络布线实战指南:从铜缆到光缆的智能选择 装修新房或升级旧宅网络时,面对琳琅满目的网线规格和新兴的光纤方案,普通消费者往往陷入选择困境。Cat5e、Cat6、Cat7这些数字背后究竟意味着什么?光纤是否真的高不可攀?…...

从RC电路到传递函数:一个实例讲透自动控制原理的建模核心
从RC电路到传递函数:一个实例讲透自动控制原理的建模核心 在自动控制原理的学习中,许多初学者常常陷入理论与实际脱节的困境。他们能够背诵拉氏变换的定义,却不知道如何将一个简单的电路转化为数学模型;他们熟悉传递函数的公式&am…...

终极指南:Diablo Edit2暗黑破坏神2存档修改器完整使用教程
终极指南:Diablo Edit2暗黑破坏神2存档修改器完整使用教程 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾为暗黑破坏神2中重复刷装备而烦恼?是否因为技能点分配失…...

【实战避坑】从清华源手动下载到权限修复:一站式解决d2l安装疑难杂症
1. 为什么你的d2l安装总是失败?从下载到权限的全流程避坑指南 每次看到"动手学深度学习"课程里那些酷炫的案例,你是不是也迫不及待想动手试试?但现实往往很骨感——光是安装d2l这个入门包就能卡住80%的新手。我见过太多人在第一步就…...

Python应用性能监控实战:New Relic APM代理原理与部署指南
1. 项目概述:一个现代应用性能的“听诊器”如果你正在用Python构建Web服务、后台任务或者任何需要7x24小时稳定运行的应用,那么“性能”和“可观测性”这两个词,一定是你日常工作中绕不开的焦点。当线上服务突然变慢,用户投诉接踵…...

雷达系统原理与脉冲测量技术详解
1. 雷达系统基础原理与核心方程雷达(RADAR)是Radio Detection And Ranging的缩写,其基本原理是通过发射电磁波并接收目标反射信号来实现探测和测距。雷达方程是理解雷达系统性能的基础数学表达式:Pr (Pt * G * λ * σ) / ((4π)…...

四旋翼无人机安全控制:CBF与双相对度系统实践
1. 四旋翼无人机安全控制的核心挑战四旋翼无人机在复杂环境中的自主飞行面临诸多安全挑战。当无人机在充满障碍物的空间执行任务时,传统控制方法往往难以同时满足轨迹跟踪精度和实时避障需求。我曾参与过一个物流仓库巡检项目,无人机在狭窄货架间穿行时&…...