数据挖掘常见算法(分类算法)
K-近邻算法(KNN)
K-近邻分类法的基本思想:通过计算每个训练数据到待分类元组Zu的距离,取和待分类元组距离最近的K个训练数据,K个数据中哪个类别的训练数据占多数,则待分类元组Zu就属于哪个类别。
KNN算法描述:
- 对新的数据集中的每一个数据点,计算其到已知分类信息的数据集中所有数据点的距离。
- 将计算得到的所有距离进行排序,一般是升序排序。
- 选取其中前K个与未知点离得最近的点。
- 统计这K个已知分类信息中各个类别出现的频数,
- 选取上述K个点中类别频数最高的,作为未知点的类别。
eg:设某公司现有8名员工的基本信息,包括其个子为高个,中等,矮个的分类标识
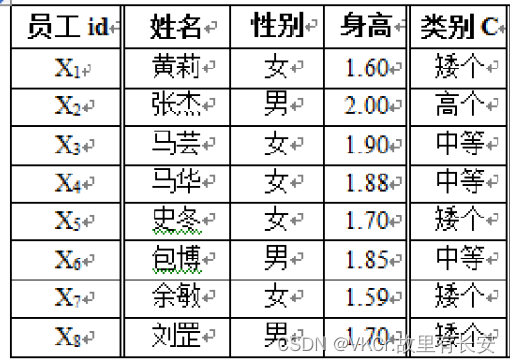
公司现刚招进一位名叫刘萍的新员工Z1,令k=5,试采用 k-NN分类算法判断员工刘萍的个子属于哪一类?
解:

决策树
决策树是通过一系列规则对数据进行分类的过程。它提供一种在什么条件下会得到什么值的类似规则的方法。通常决策树主要有三种实现,分别是ID3算法,CART算法和C4.5算法
决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树。
决策树分类方法采用自顶向下的递归方式
一棵决策树的生成过程主要分为以下3个部分:
- 特征选择
- 决策树生成
- 剪枝
研究结果表明,一般情况下, 树越小则树的预测能力越强。
理论上讲,后剪枝好于预先剪枝,但计算复杂度大。
典型决策树算法
-
ID3
ID3算法用信息增益作为属性测试条件,且信息增益值越大以该属性作为分支结点越好。
ID3算法的核心在于使用"信息熵"作为衡量标准,通过计算每个属性的信息增益,选择信息增益最高的属性作为划分标准,重复这个过程直至生成一个能完美分类训练的决策树,采用贪心算法,不能保证全局最优.
递归终止条件:①当分到某个类时,目标属性全是一个值. OR ②当分到某个类时,某个值的比例达到给定的阈值.
信息熵E,一个系统越是有序,信息熵越低;反之,一个系统越混乱,信息熵越高.
info信息量
若存在n个相同概率的消息,则每个消息的概率p=1/n,一个消息传递的信息量为: -Log2(1/n)=Log2n (使用以2为底的对数函数,是因为计算机中的信息用二进位编码。)
gain信息增益 ,选择gain(max)作为结点
| 序号 | 天气 | 气温 | 湿度 | 风 | 打网球 |
| 1 | 晴 | 热 | 高 | 无 | N |
| 2 | 晴 | 热 | 高 | 有 | N |
| 3 | 多云 | 热 | 高 | 无 | Y |
| 4 | 雨 | 温暖 | 高 | 无 | Y |
| 5 | 雨 | 凉爽 | 正常 | 无 | Y |
| 6 | 雨 | 凉爽 | 正常 | 有 | N |
| 7 | 多云 | 凉爽 | 正常 | 有 | Y |
| 8 | 晴 | 温暖 | 高 | 无 | N |
| 9 | 晴 | 凉爽 | 正常 | 无 | Y |
| 10 | 雨 | 温暖 | 正常 | 无 | Y |
| 11 | 晴 | 温暖 | 正常 | 有 | Y |
| 12 | 多云 | 温暖 | 高 | 有 | Y |
| 13 | 多云 | 热 | 正常 | 无 | Y |
| 14 | 雨 | 温暖 | 高 | 有 | N |



ID3优点:算法的理论清晰,方法简单,学习能力较强。
决策树ID3算法的主要问题:过拟合,对数据中的噪声敏感以及不稳定.只能处理离散属性数据,不能处理有缺失的数据。
改进策略:使用决策树的改进版本,如随机森林何梯度提升.
-
C4.5
C4.5和ID3都是利用贪心算法进行求解,不同的是分类决策的依据不同.
C4.5算法在结构和递归上与ID3完全相同,区别在于选取决断特征时选择信息增益比最大的.
C4.5既可以处理离散型属性,也可以处理连续型属性.
-
CART
CART算法构成的是一个二叉树,它在每一步的决策时只能是“是”或者“否”,即使一个feature有多个取值,也是把数据分为两部分。选择Gini系数最小值作为结点
| ID | 有房者 | 婚姻 | 年收入 | 拖欠贷款 |
| 1 | 是 | 单身 | 125K | 否 |
| 2 | 否 | 已婚 | 100K | 否 |
| 3 | 否 | 单身 | 70K | 否 |
| 4 | 是 | 已婚 | 120K | 否 |
| 5 | 否 | 离异 | 95K | 是 |
| 6 | 否 | 已婚 | 60K | 否 |
| 7 | 是 | 离异 | 220K | 否 |
| 8 | 否 | 单身 | 85K | 是 |
| 9 | 否 | 已婚 | 75K | 否 |
| 10 | 否 | 单身 | 90K | 是 |
解: 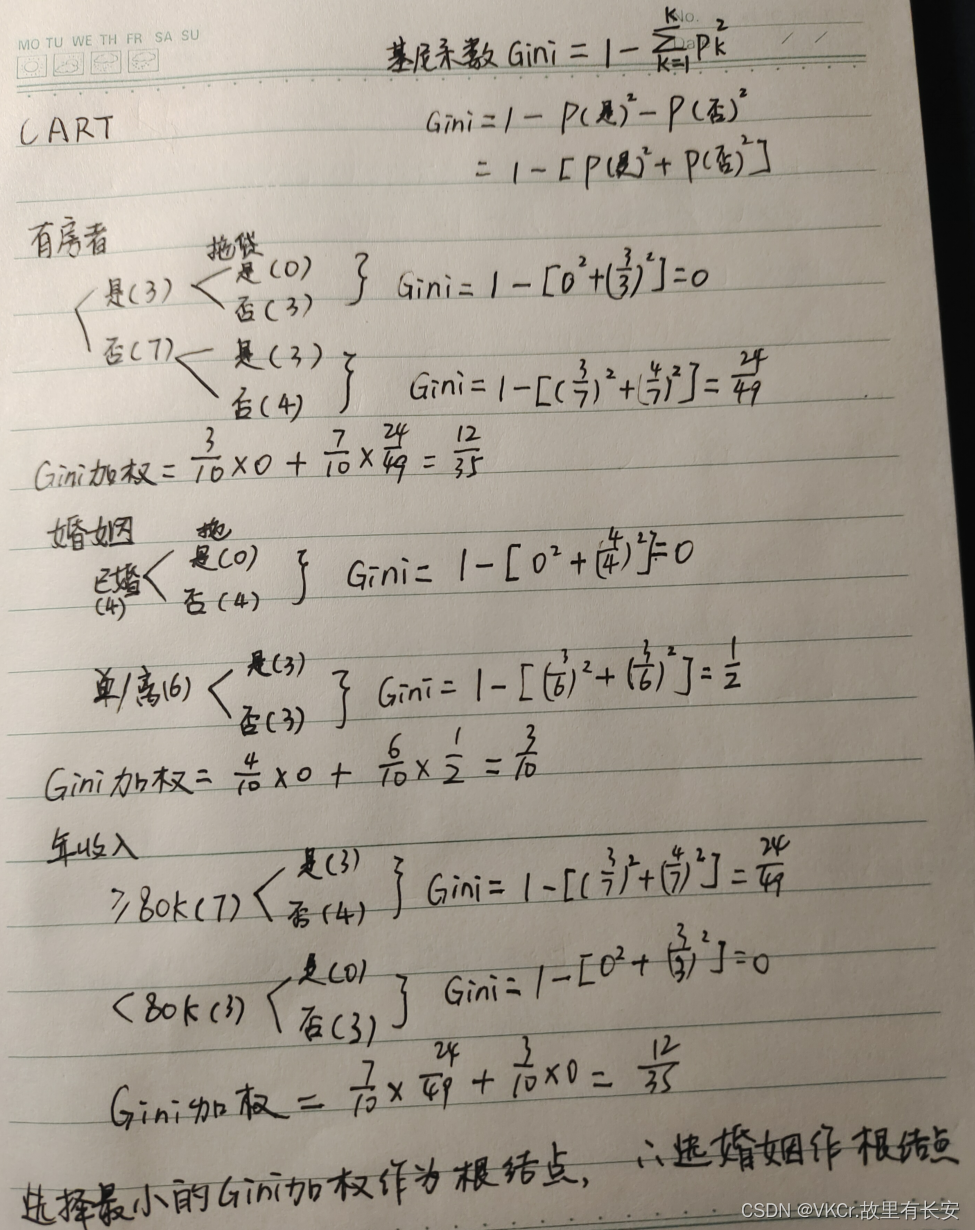

朴素贝叶斯
整个朴素贝叶斯分类可分为三个阶段:
第一阶段是准备工作阶段
第二阶段是分类器训练阶段
第三阶段是应用阶段
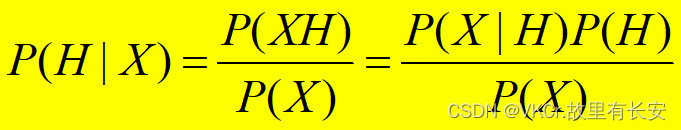

相关文章:
数据挖掘常见算法(分类算法)
K-近邻算法(KNN) K-近邻分类法的基本思想:通过计算每个训练数据到待分类元组Zu的距离,取和待分类元组距离最近的K个训练数据,K个数据中哪个类别的训练数据占多数,则待分类元组Zu就属于哪个类别…...

【深度学习】调整加/减模型用于体育运动评估
摘要 一种基于因果关系的创新模型,名为调整加/减模型,用于精准量化个人在团队运动中的贡献。该模型基于明确的因果逻辑,将个体运动员的价值定义为:在假设情景下,用一名价值为零的球员替换该球员后,预期比赛…...
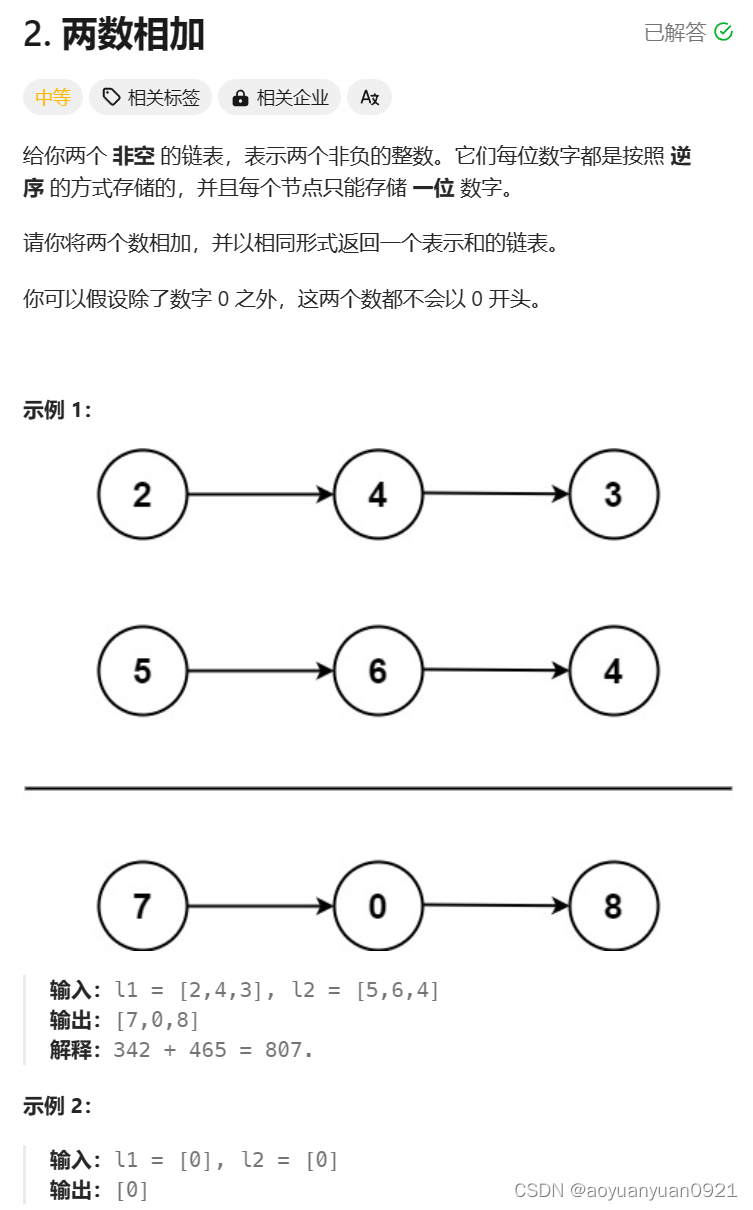
重生之算法刷题之路之链表初探(三)
算法刷题之路之链表初探(三) 今天来学习的算法题是leecode2链表相加,是一道简单的入门题,但是原子在做的时候其实是有些抓耳挠腮,看了官解之后才恍然大悟! 条件 项目解释 有题目可以知道,我们需…...

哪吒汽车,正在等待“太乙真人”的拯救
文丨刘俊宏 在360创始人、哪吒汽车股东周鸿祎近日连续且着急的“督战”中,哪吒汽车(下简称哪吒)终究还是顶不住了。 6月26日,哪吒通过母公司合众新能源在港交所提交了IPO文件,急迫地希望成为第五家登陆港股的造车新势力…...

HDC Cloud 2024 | CodeArts加速软件智能化开发,携手HarmonyOS重塑企业应用创新体验
2024年6月21~23日,华为开发者大会HDC 2024在东莞溪流背坡村隆重举行。期间华为云主办了以“CodeArts加速软件智能化开发,携手HarmonyOS重塑企业应用创新体验”为主题的分论坛。论坛汇聚了各行各业的专家学者、技术领袖和开发者,共同探讨Harmo…...
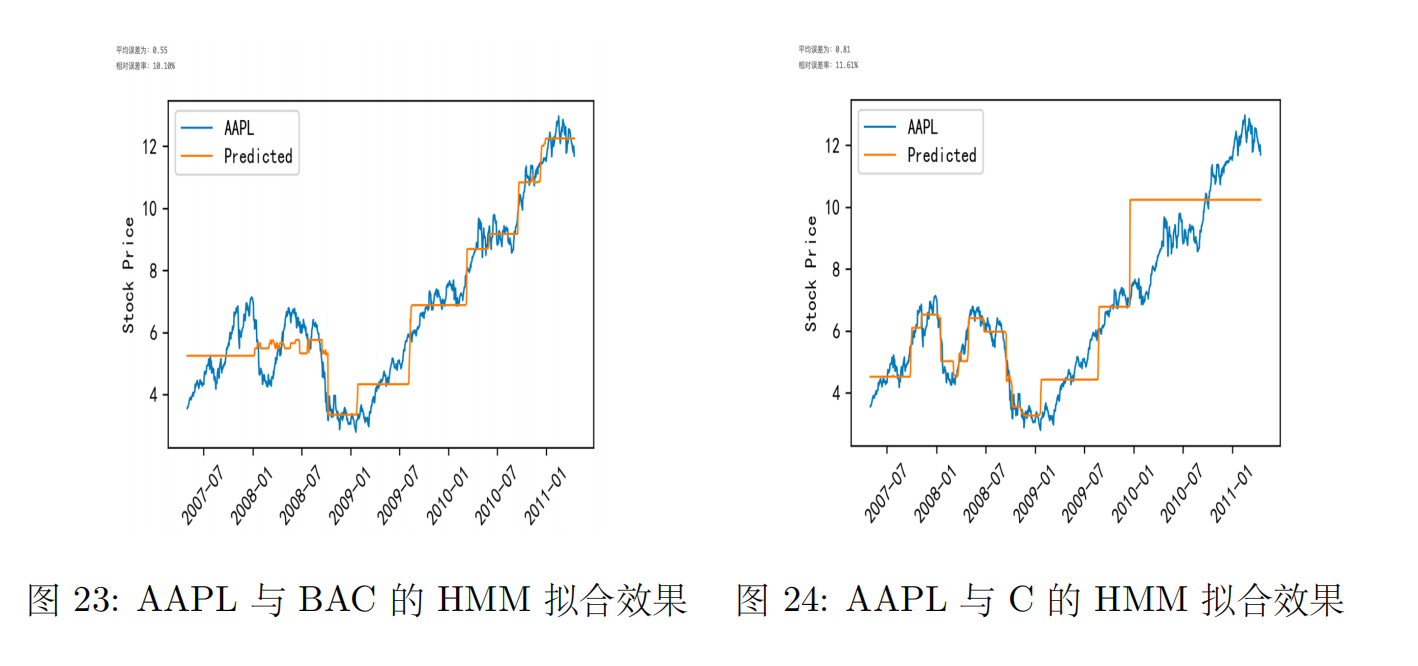
基于隐马尔可夫模型的股票预测【HMM】
基于机器学习方法的股票预测系列文章目录 一、基于强化学习DQN的股票预测【股票交易】 二、基于CNN的股票预测方法【卷积神经网络】 三、基于隐马尔可夫模型的股票预测【HMM】 文章目录 基于机器学习方法的股票预测系列文章目录一、HMM模型简介(1)前向后…...

PostgreSQL Replication Slots
一、PostgreSQL的网络测试 安装PostgreSQL客户端 sudo yum install postgresql 进行网络测试主要是验证客户端是否能够连接到远程的PostgreSQL服务器。以下是使用psql命令进行网络测试的基本步骤: 连接到数据库: 使用psql命令连接到远程的PostgreSQL数据库服务器…...

centos7搭建zookeeper 集群 1主2从
centos7搭建zookeeper 集群 准备前提规划防火墙开始搭建集群192.168.83.144上传安装包添加环境变量修改zookeeper 的配置 192.168.83.145 和 192.168.83.146 配置 启动 集群 准备 vm 虚拟机centos7系统zookeeper 安装包FinalShell或者其他shell工具 前提 虚拟机安装好3台cen…...

Arrays.asList 和 java.util.ArrayList 区别
理解 Java 中的 Arrays.asList 和 java.util.ArrayList 的区别 在 Java 编程中,Arrays.asList 方法和 java.util.ArrayList 是两种常用的处理列表数据的方式。虽然它们在功能上看起来相似,但在内部实现和使用上有着本质的不同。本文将探讨这两种方式的区…...
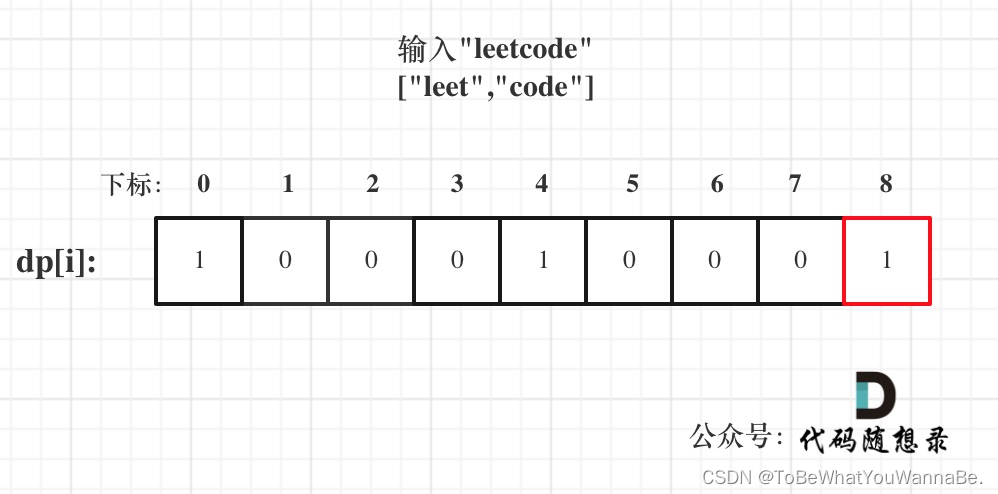
代码随想录-Day44
322. 零钱兑换 给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。 你可以认为每种硬币的数…...
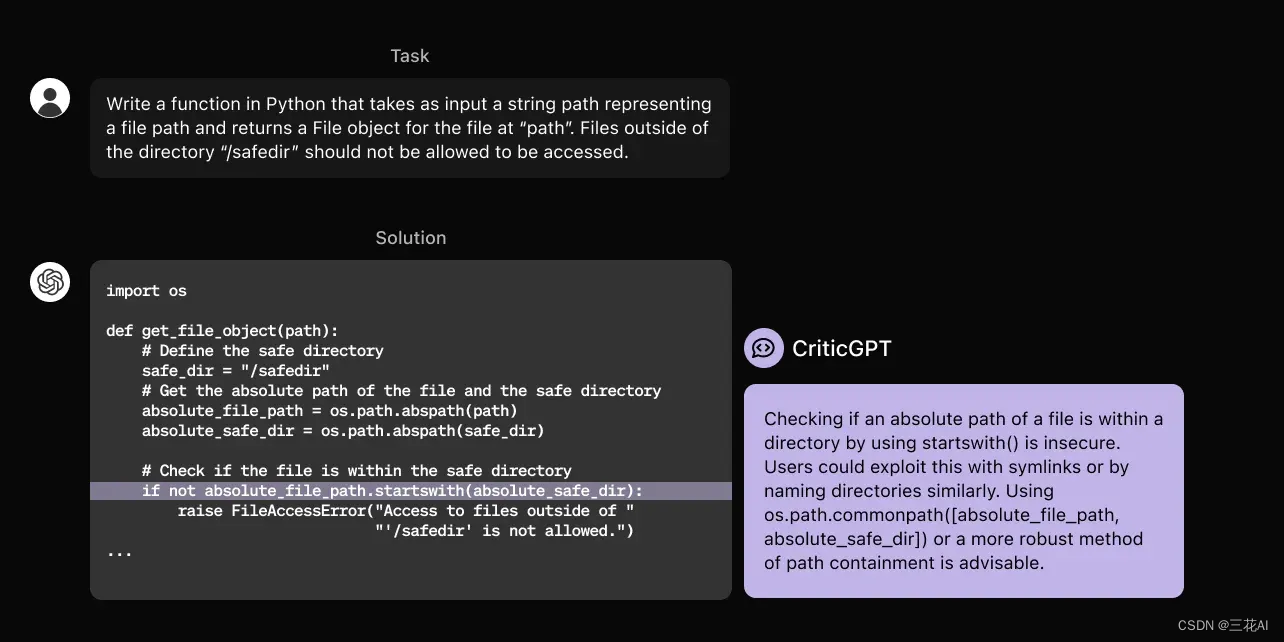
CriticGPT: 用 GPT-4 找出 GPT-4 的错误
CriticGPT 是 OpenAI 发布的一个基于 GPT-4 的模型,它可以帮助我们人类 Review 并纠正 ChatGPT 在生成代码时的错误。使用 CriticGPT 审查代码时,有 60% 的概率生成的代码更好更正确。...

SpringBoot:SpringBoot中调用失败如何重试
一、引言 在实际的应用中,我们经常需要调用第三方API来获取数据或执行某些操作。然而,由于网络不稳定、第三方服务异常等原因,API调用可能会失败。为了提高系统的稳定性和可靠性,我们通常会考虑实现重试机制。 Spring Retry为Spri…...

2024-06-24 问AI: 在大语言模型中,什么是ray?
文心一言 在大语言模型中,Ray是一个开源的统一框架,用于扩展AI和Python应用程序,特别是在机器学习领域。以下是关于Ray的详细解释: 核心功能: Ray为并行处理提供了计算层,使得用户无需成为分布式系统专家…...

仓库管理系统09--修改用户密码
1、添加窗体 2、窗体布局控件 UI设计这块还是传统的表格布局,采用5行2列 3、创建viewmodel 4、前台UI绑定viewmodel 这里要注意属性绑定和命令绑定及命令绑定时传递的参数 <Window x:Class"West.StoreMgr.Windows.EditPasswordWindow"xmlns"http…...

在Spring Data JPA中使用@Query注解
目录 前言示例简单示例只查询部分字段,映射到一个实体类中只查询部分字段时,也可以使用List<Object[]>接收返回值再复杂一些 前言 在以往写过几篇spring data jpa相关的文章,分别是 Spring Data JPA 使用JpaSpecificationExecutor实现…...
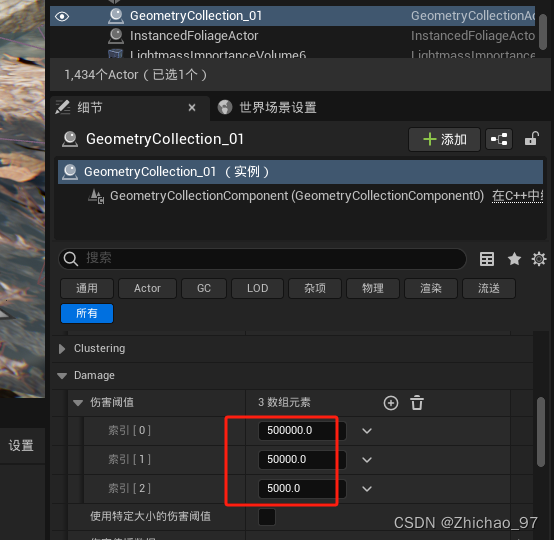
【UE5.1】Chaos物理系统基础——01 创建可被破坏的物体
目录 步骤 一、通过笔刷创建静态网格体 二、破裂静态网格体 三、“统一” 多层级破裂 四、“簇” 群集化的破裂 五、几何体集的材质 六、防止几何体集自动破碎 步骤 一、通过笔刷创建静态网格体 1. 可以在Quixel Bridge中下载两个纹理,用于表示石块的内外纹…...

Linux下SUID提权学习 - 从原理到使用
目录 1. 文件权限介绍1.1 suid权限1.2 sgid权限1.3 sticky权限 2. SUID权限3. 设置SUID权限4. SUID提权原理5. SUID提权步骤6. 常用指令的提权方法6.1 nmap6.2 find6.3 vim6.4 bash6.5 less6.6 more6.7 其他命令的提权方法 1. 文件权限介绍 linux的文件有普通权限和特殊权限&a…...

Redis主从复制搭建一主多从
1、创建/myredis文件夹 2、复制redis.conf配置文件到新建的文件夹中 3、配置一主两从,创建三个配置文件 ----redis6379.conf ----redis6380.conf ----redis6381.conf 4、在三个配置文件写入内容 redis6379.conf里面的内容 include /myredis/redis.conf pidfile /va…...
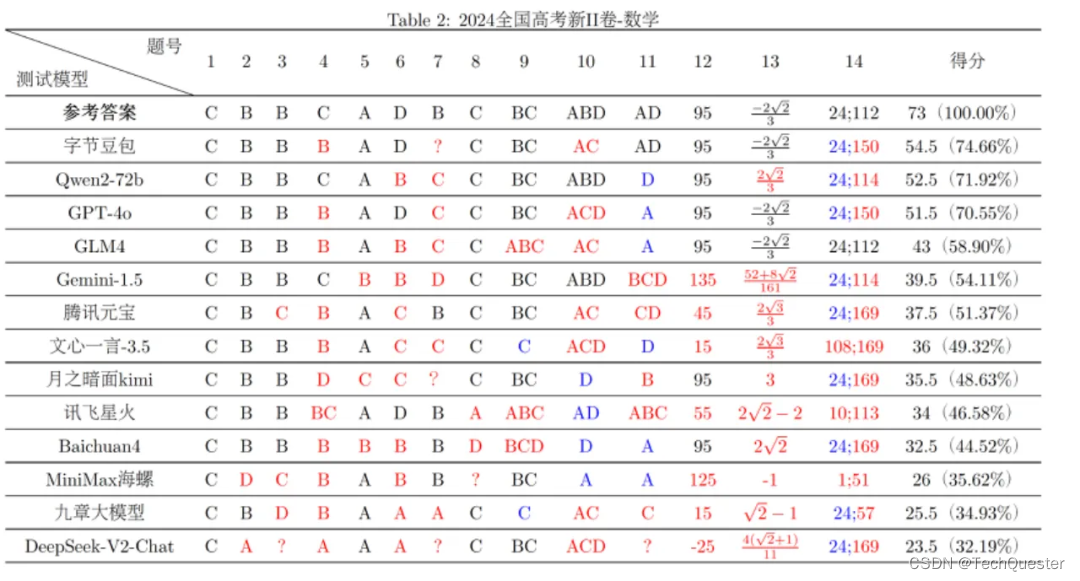
GPT-4o文科成绩超一本线,理科为何表现不佳?
目录 01 评测榜单 02 实际效果 什么?许多大模型的文科成绩竟然超过了一本线,还是在竞争激烈的河南省? 没错,最近有一项大模型“高考大摸底”评测引起了广泛关注。 河南高考文科今年的一本线是521分,根据这项评测&…...

Lombok的hashCode方法
Lombok对于重写hashCode的算法真的是很经典,但是目前而言有一个令人难以注意到的细节。在继承关系中,父类的hashCode针对父类的所有属性进行运算,而子类的hashCode却只是针对子类才有的属性进行运算,立此贴提醒自己。 目前重写ha…...
)
用Wireshark抓包实战,手把手教你读懂LwIP里的TCP/IP数据帧(附真实数据解析)
Wireshark与LwIP实战:从抓包数据到协议栈实现的深度解析 当你第一次在Wireshark中看到那些密密麻麻的十六进制数据时,是否感到无从下手?作为嵌入式开发者,理解网络数据包的底层结构不仅是调试网络问题的关键,更是优化L…...

为什么你需要Scroll Reverser?macOS滚动方向独立控制的终极解决方案
为什么你需要Scroll Reverser?macOS滚动方向独立控制的终极解决方案 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 在macOS上使用触控板和鼠标时,你是否…...

基于MCP协议与RAG技术构建智能聊天应用:架构解析与实战指南
1. 项目概述:一个基于MCP协议的RAG聊天应用最近在开源社区里,一个名为gogabrielordonez/mcp-ragchat的项目引起了我的注意。乍一看标题,它融合了当下两个非常热门的技术概念:MCP和RAG。对于从事AI应用开发,特别是希望构…...

从AwesomeCursorPrompt看提示工程:构建高效AI编程协作工作流
1. 项目概述:从“AwesomeCursorPrompt”看提示工程的演进最近在GitHub上看到一个挺有意思的项目,叫“AwesomeCursorPrompt”。光看名字,可能很多朋友会有点懵——“Cursor”是那个AI代码编辑器,“Prompt”是提示词,那这…...

PhonePi-MCP:基于MCP协议实现AI智能体自动化操控Android手机
1. 项目概述:当你的手机成为AI的“眼睛”与“双手” 最近在折腾AI智能体(Agent)时,我一直在思考一个问题:如何让这些运行在云端或本地电脑上的“大脑”真正地与现实世界互动?比如,让它帮我查一…...

性能巨兽:基于AMD EPYC 9755与RTX 5090D的UltraLAB GA660M仿真工作站深度解析
在高端制造、能源勘探和前沿科学计算领域,算力永远是稀缺资源。每一次CPU与GPU的代际更迭,都意味着仿真效率的指数级提升。今天,我们解析的这款UltraLAB GA660M241256-MBD工作站,正是集成了2026年顶级硬件技术的算力平台。它不仅是…...

使用 Taotoken 后模型 API 响应延迟与稳定性效果实测观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 后模型 API 响应延迟与稳定性效果实测观察 作为一名需要频繁调用大模型 API 的开发者,模型服务的响应速…...

AI Agent Harness Engineering 的安全攻防:你的智能体如何被欺骗、劫持与利用
AI Agent Harness Engineering 安全攻防深度解析:你的智能体如何被欺骗、劫持与利用 关键词 AI Agent安全、Harness工程、Prompt注入、工具劫持、智能体攻防、LLM安全、权限逃逸 摘要 随着AI Agent从概念验证走向大规模产业落地,作为智能体控制平面的Harness层已成为攻防…...

开源智能体框架xbrain:模块化设计与工程实践指南
1. 项目概述:一个面向开发者的开源智能体框架最近在开源社区里,一个名为xbrain的项目引起了我的注意。它由开发者yuruotong1发起,定位是一个“开源智能体框架”。简单来说,它试图为开发者提供一个工具箱,让构建、管理和…...

告别加密日志:MTK平台离线调试利器SpOffineDebugSuite v3.4安装与使用全攻略
MTK平台离线调试实战:SpOffineDebugSuite v3.4与GAT工具链深度解析 在移动设备开发领域,联发科技(MTK)平台因其高性价比和丰富功能而广受欢迎。然而,当系统出现崩溃或异常时,传统的在线调试方式往往受限于设备连接状态和实时性要求…...