论文阅读_优化RAG系统的检索
英文名称: The Power of Noise: Redefining Retrieval for RAG Systems
中文名称: 噪声的力量:重新定义RAG系统的检索
链接: https://arxiv.org/pdf/2401.14887.pdf
作者: Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, Fabrizio Silvestri
机构: 罗马大学, 以色列海法技术创新研究所, 比萨大学日期: 1 May 2024(v4)读后感
在 RAG 系统中,检索和生成是独立进行的,使用的模型也不相同,检索和生成中任意一个部分效果不好都会影响最终结果。在检索部分,不一定必须使用稠密模型,因此作者考虑了密集和稀疏的情况;在生成部分,实验使用的是本地部署的较轻量级模型如 llama2 等,这也部分影响了效果。
作者的角度很有趣:查询所给出的答案可能是准确的、无关的或相关但不包含答案的。其中,相关但不包含答案的反而可能会导致最终结果偏差。在人的决策中也有类似情况:不怕完全不靠谱的信息,半真半假的更容易误导;如果只给我一个答案可能我还能不确定,如果附加一个完全不靠谱的答案与之对比,我反而更加确定。
粗看之下,在许多文档中定位与问题相关的文档,使用相似度方法似乎没有问题。至少它可以筛掉大多数完全无关的文档。然而,高相关性并不一定意味着包含正确答案。这可能需要生成模型来判断其中的逻辑关系,还需要考虑数据中根本不包含答案的情况。
摘要
目标:研究 RAG 系统中的检索策略,优化信息检索(IR)组件以提升生成式 AI 解决方案的效果。
方法:通过分析段落在提示上下文中的相关性、位置和数量等因素,评估不同检索策略对 RAG 系统中 LLM 表现的影响。
结果:发现检索时高得分但不包含答案的文档会降低 LLM 效果,而添加随机文档能将 LLM 准确性提高最多 35%。
1 引言
RAG 系统由两个基本组件组成:检索器和生成器。检索器负责调用外部信息检索(IR)系统,这些系统可以是密集型或稀疏型,并将选定的结果传递给生成器组件。本研究重点关注 RAG 的 IR 方面。
将查询返回的数据分为三类,并研究每个类别所带来的影响:
-
相关文档:包含可直接回答查询或提供相关信息的文档。
-
分散注意力的文档:虽然不直接回答查询,但在语义或上下文上与主题相关联。
-
随机文档:与查询没有任何关系,可以看作是检索过程中的信息噪音。
2 RAG
2.1 开放领域的问答
开放领域问答(OpenQA)是一项任务,旨在开发能够为自然语言中提出的各种问题提供准确且上下文相关答案的系统。这些系统不受特定领域或预定义数据集的限制。
常见的方法采用两步架构,通常包括检索器和推理器(通常是生成器)。首先,检索器找到与问题相关的文档,然后推理器生成答案。
2.2 检索器
检索器的目标是找到一个足够小的文档子集,以便推理者能正确回答查询。
密集检索需要将文本数据转化为向量表示,通常通过神经网络实现,常用的是基于 Transformer 的编码器,如 BERT。密集检索器处理查询 q 和潜在源文档 d,生成对应的查询嵌入和每个文档的嵌入。嵌入过程可以表示为:

其中,Encoderq 和 Encoderd 是基于神经网络的编码器,可能共享权重或架构,旨在将文本数据映射到向量空间中。一旦生成嵌入,检索过程就包括计算查询嵌入和每个文档嵌入之间的相似性。最常用的方法是使用点积得分。这个分数通过衡量嵌入向量空间中查询和文档的相似性来量化每个文档与查询的相关性,得分越高表示相关性越大。
2.3 推理器
推理器指的一般是生成器,它负责合成一个答案,通常通过调用 LLM 模型实现。在 RAG 中,生成语言模型将查询 q 和检索到的文档 Dr作为输入,通过顺序预测序列中的下一个词元来生成响应。

本文的目标是找到最好的文档集 D 检索器应该为生成器提供材料,以最大限度地提高系统的有效性。
3 实验方法
3.1 自然问题数据集
自然问题(NQ)数据集是从 Google 搜索数据中派生的真实世界查询的大规模集合。数据集中的每个条目都包含一个用户查询和一个相应的维基百科页面,其中包括答案。NQ-open 数据集是 NQ 数据集的一个子集。不同之处在于,它取消了将答案链接到特定维基百科段落的限制,从而模仿了类似网络搜索的更通用的信息检索场景。最终的数据集包含 21,035,236 个文档,训练集有 72,209 个查询,测试集有 2,889 个查询。
3.2 文档类别
按文档与查询的相关性,将文档分为四种类型:
-
黄金文档:用星表示。这类文档是数据集中的原始上下文,包含答案的维基百科页面段落,并且与给定查询的上下文相关。
-
相关文档:用锁链图标表示。这些文档类似于黄金文档,它们包含正确答案,并在上下文中对回答查询有用。它们提供了与查询正确且相关的其他信息源。黄金文件也是一种相关文件。
-
分散注意力的文档:用断开的锁链表示。这类文档有高检索分数但不包含答案。
-
随机文档:用色子表示。随机文档既不与查询相关,也不包含答案。有助于评估模型处理完全不相关信息的能力。
3.3 文档检索
实验使用了 Contriever 作为默认的检索器。Contriever 是一种基于 BERT 的密集检索器,通过对比损失进行无监督训练。为了提高在包含约 2100 万文档的语料库中的相似性搜索效率,我们采用了 FAISS IndexFlatIP 索引系统。每个文档和查询的嵌入是通过对模型最后一层隐藏状态的平均值得到的。
3.4 LLM 的输入
收到查询后,检索器会根据相似度度量从语料库中选择排名前 的文档。这些文档连同任务说明和查询一起,构成了 LLM 生成响应的输入。LLM 的任务是从提供的文档中提取一个最多包含五个词元的查询响应。如图所示,这个问题回答不正确。

3.5 测试的 LLM
在生成部分,测试了 base 和 instruct 版本,最终选用 instruct 版本,测试模型包含:Llama2-7B,Falcon-7B,Phi-2-2.7B,MPT-7B。
3.6 预价正确性
在 NQ-open 数据集中,每个查询可能有多个潜在答案,这些答案通常是同一概念的不同变体。在评估 LLM 生成的响应准确性时,采用一种检查响应中是否包含预定义正确答案的方法。这种评估方式是二进制的:如果存在正确答案,则认为准确,否则不准确。然而,有时这种方法无法识别同义的不同短语。
4 结果
4.1 分散注意力的文档的影响
随着上下文中分散注意力的文档数量增加,准确性会明显下降。这种模式在所有大型语言模型(LLMs)的情况下都能观察到。即使仅仅添加一个分散注意力的文档,也会导致准确性的急剧下降。
在现实世界的信息检索(IR)环境中,相关但不包含答案的文档很常见。实证分析表明,引入语义一致但不相关的文档会增加复杂性,可能误导 LLMs 做出正确响应。
如图所示:I 表示任务指令,Q 表示问题,星号表示黄金文档,断开的锁链表示分散注意力的文档。

从注意力的热力图中也可以看出,文本相似但不包含答案的文档分走了黄金文档的注意力。

(小编的理解:如果深度学习作为检索器,检索和生成模型基本上是类似的。在检索过程中找到文档的逻辑,同样适用于生成模型的逻辑。也就是说,在生成过程中,这些文档也被重视,从而分散了对黄金文档的注意力。)
为了验证这一假设,作者使用了 ADORE(Zhan 等,2021),一种通过“动态困难负样本”训练的先进检索器,来选择干扰文档。结果显示,情况依然相同。因此可以得出结论,区分相关信息和分散注意力的信息是一个难题,无法简单地通过改变现有的密集检索方法来解决。
4.2 黄金文档位置的影响
通过在上下文中移动黄金文件的位置来研究其对模型有效性的影响。将黄金文件的位置定义为 Far、Mid 和 Near,具体示例见表中的图示。

当黄金文档靠近查询时,准确性较高;当黄金文档离查询最远时,准确性较低;而当黄金文档位于上下文中间时,准确性最低。
(小编说:离得近更容易被注意到,而在中间时最不容易被忽略,这和长上下文模型的大海捞针结果也是一致的,可能由于训练数据的原因,让模型认为开头结尾的信息更为重要)
4.3 噪音的影响
评估 RAG 系统对噪声的鲁棒性。取黄金文件,并从语料库中随机挑选一定数量的文件添加到其中。性能没有下降,反而在最佳设置下有所改善。此外,不同模型表现出不同的行为。值得注意的是,与分散注意力的文档相比,这种性能下降的严重程度要低得多。
4.4 RAG 实践
给定一个查询,检索一组可能相关或分散注意力的文档。然后,我们将随机文档加入到这组检索到的文档中。使用 NQ 开放数据集的测试集。Llama2 的实验结果可以在表 3 左侧查看。

研究结果表明,无论检索到的文档数量如何,在填充上下文长度之前添加随机文档几乎总是有益的。特别是在检索到 4 个文档的情况下,准确率可提高 0.07(+35%)。
4.4.1 测试稀疏检索器
使用稀疏检索方法(特别是 BM25)复制了实验。相应的结果列在表 3 的右侧,随机文档也带来了提升。值得注意的是,使用 BM25 平均可使准确度提高 3-4 个百分点。这种改进归因于 BM25 检索到的文件质量。
(小编说:BM25 和 Contriever 各有优劣。BM25 是与数据集相关的,而 Contriever 虽然也是基于训练数据,但它的表示更通用。这至少表明,深度学习嵌入方法并不总是优于统计方法)。
4.4.2 提升随机性
随机文档从语气和风格截然不同的语料库中抽取,即 Reddit Webis-TLDR-17 数据集。观察到准确性有显著提高。即使将由随机单词组成的无意义句子视为随机文档,性能仍然有所提升。
4.5 权衡检索
在相关和完全不相关的文件数量之间似乎存在权衡。具体来说,实验发现,当最初检索到一组最少的文档,然后用随机文档补充,直到达到上下文限制时,可以获得最佳效果。检索 3 到 5 个文档是最有效的选择。添加更多文档会增加包含过多分散注意力内容的风险,从而适得其反。
对于如何解释加入噪声反而会提升模型效果,先前的研究提出,在某些情况下,过低的注意力熵会导致 LLM 产生退化输出,从而导致性能急剧下降。这些事件被称为熵坍缩。这里对比了加入随机文档前后的熵情况。引入随机文档时,系统的熵增加了 3 倍。
相关文章:
论文阅读_优化RAG系统的检索
英文名称: The Power of Noise: Redefining Retrieval for RAG Systems 中文名称: 噪声的力量:重新定义RAG系统的检索 链接: https://arxiv.org/pdf/2401.14887.pdf 作者: Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campag…...
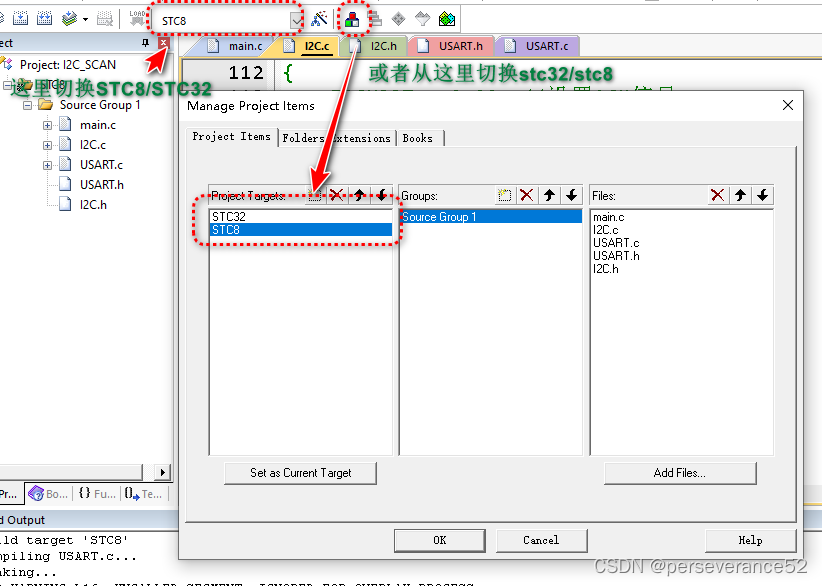
STC8/32 软硬件I2C通讯方式扫描I2C设备地址
STC8/32 软硬件I2C通讯方式扫描I2C设备地址 📄主要用于检测挂载在I2C总线上的设备。在驱动I2C设备之前,如果能扫描到该设备,说明通讯设备可以连接的上,在提前未知I2C地址的情况下,可以方便后面的驱动代码的完善。 🔬扫描测试效果:(测试mpu6050以及ssd1306 i2c oled )…...
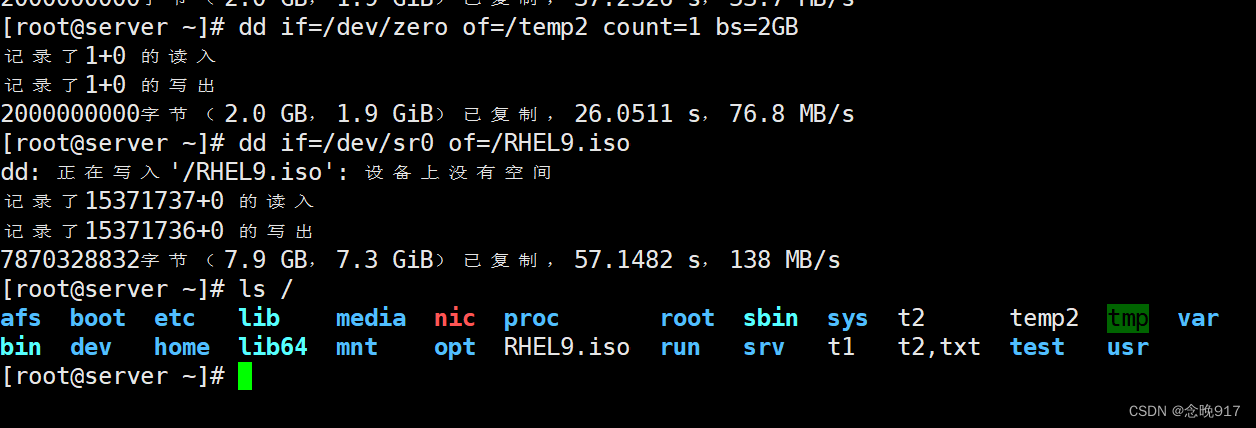
Linux——数据流和重定向,制作镜像
1. 数据流 标准输入( standard input ,简称 stdin ):默认情况下,标准输入指从键盘获取的输入 标准输出( standard output ,简称 stdout ):默认情况下,命令…...

Windows 11的市场份额越来越大了,推荐你升级!
7月1日,系统之家发布最新数据,显示Windows 11操作系统的市场份额正在稳步上升。自2021年10月Windows 11发布以来,Windows 10一直占据着市场主导地位,当时其市场份额高达81.44%。然而,随着时间的推移,Window…...

微服务架构中的调试难题与分布式事务解决方案
微服务架构作为现代软件开发的一种主要趋势,因其灵活性、高可维护性和易于扩展的特点,得到了广泛的应用。然而,在享受微服务架构带来的诸多优点的同时,开发者也面临着一些新的挑战。调试的复杂性和分布式事务的处理是其中两个较为…...

银行家算法-操作系统中避免死锁的最著名算法
背景 有很多文章都会介绍银行家算法。在百度和CSDN上搜一搜能搜出很多来。很多同学会觉得这个算法很深奥,有些文章写的又很复杂,其实真的很简单。这里简单记录一下基本原理,然后大家再配合其他文章看,就能加深理解。 算法原理 …...

PCL 基于点云RGB颜色的区域生长算法
RGB颜色的区域生长算法 一、概述1.1 算法定义1.2 算法特点1.3 算法实现二、代码示例三、运行结果🙋 结果预览 一、概述 1.1 算法定义 点云RGB区域生长算法: 是一个基于RGB颜色信息的区域生长算法,用于点云分割。该算法利用了点云中相邻点之间的颜色相似性来将点云分割成…...

cube-studio开源一站式机器学习平台,在线ide,jupyter,vscode,matlab,rstudio,ssh远程连接,tensorboard
全栈工程师开发手册 (作者:栾鹏) 一站式云原生机器学习平台 前言 开源地址:https://github.com/tencentmusic/cube-studio cube studio 腾讯开源的国内最热门的一站式机器学习mlops/大模型训练平台,支持多租户&…...
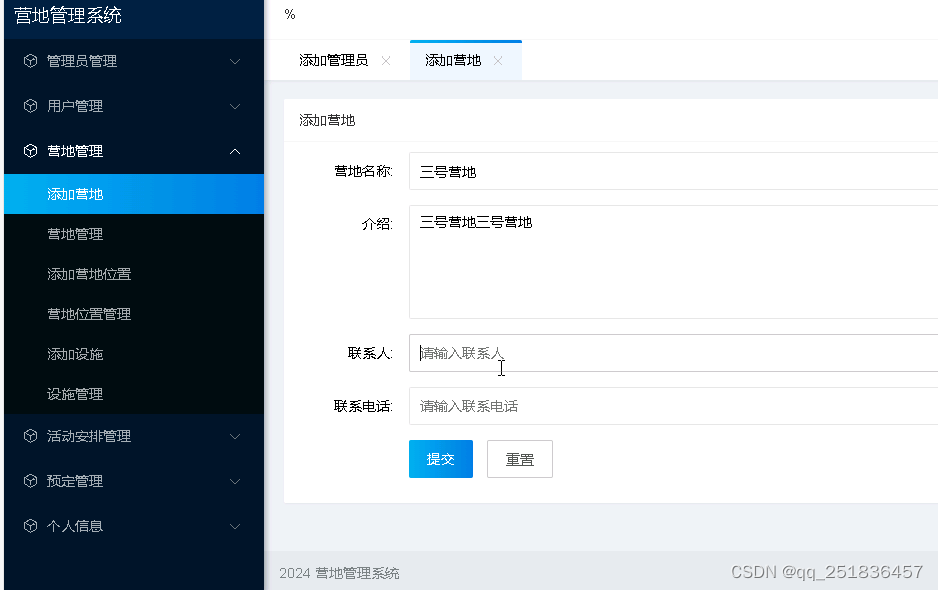
1976 ssm 营地管理系统开发mysql数据库web结构java编程计算机网页源码Myeclipse项目
一、源码特点 ssm 营地管理系统是一套完善的信息系统,结合springMVC框架完成本系统,对理解JSP java编程开发语言有帮助系统采用SSM框架(MVC模式开发),系统具有完整的源代码和数据库,系统主要采用B/S模式开…...

技术派全局异常处理
前言 全局的异常处理是Java后端不可或缺的一部分,可以提高代码的健壮性和可维护性。 在我们的开发中,总是难免会碰到一些未经处理的异常,假如没有做全局异常处理,那么我们返回给用户的信息应该是不友好的,很抽象的&am…...

对于mysql 故障的定位和排查
故障表现 他的执行时间超过规定的限制(比如1000ms)CPU使用率高大量业务失败,数据连接异常执行sql越来越慢,失败越来越多 解决方案 定位 应急 故障恢复 定位 查询慢sql的日志查看mysql 的performance schena(里面…...

什么是电航空插头插座连接器有什么作用
航空插头概述 定义与功能 航空插头,又称航空连接器,是一种专门用于航空领域的电连接器,因其最初在航空领域得到广泛应用而得名。航空插头的主要功能是实现电源或信号的连接,尤其适用于芯数较多、结构复杂的线束连接,…...

数据挖掘常见算法(分类算法)
K-近邻算法(KNN) K-近邻分类法的基本思想:通过计算每个训练数据到待分类元组Zu的距离,取和待分类元组距离最近的K个训练数据,K个数据中哪个类别的训练数据占多数,则待分类元组Zu就属于哪个类别…...

【深度学习】调整加/减模型用于体育运动评估
摘要 一种基于因果关系的创新模型,名为调整加/减模型,用于精准量化个人在团队运动中的贡献。该模型基于明确的因果逻辑,将个体运动员的价值定义为:在假设情景下,用一名价值为零的球员替换该球员后,预期比赛…...
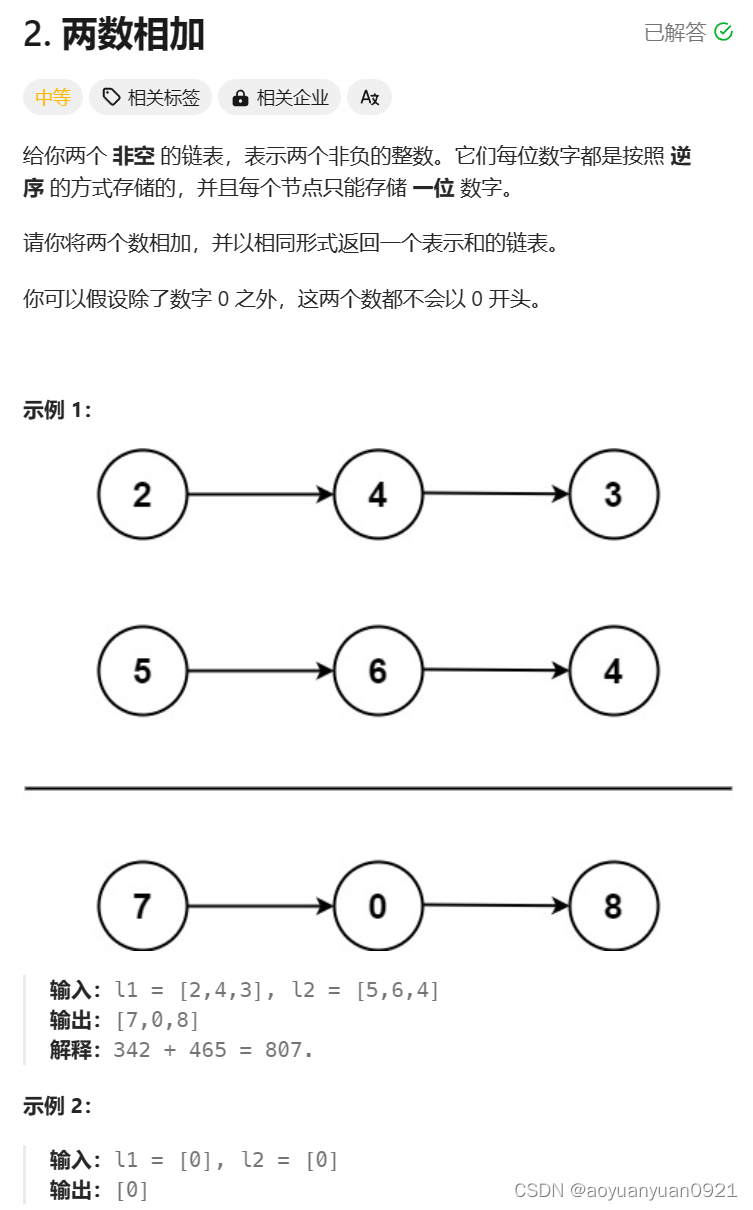
重生之算法刷题之路之链表初探(三)
算法刷题之路之链表初探(三) 今天来学习的算法题是leecode2链表相加,是一道简单的入门题,但是原子在做的时候其实是有些抓耳挠腮,看了官解之后才恍然大悟! 条件 项目解释 有题目可以知道,我们需…...

哪吒汽车,正在等待“太乙真人”的拯救
文丨刘俊宏 在360创始人、哪吒汽车股东周鸿祎近日连续且着急的“督战”中,哪吒汽车(下简称哪吒)终究还是顶不住了。 6月26日,哪吒通过母公司合众新能源在港交所提交了IPO文件,急迫地希望成为第五家登陆港股的造车新势力…...

HDC Cloud 2024 | CodeArts加速软件智能化开发,携手HarmonyOS重塑企业应用创新体验
2024年6月21~23日,华为开发者大会HDC 2024在东莞溪流背坡村隆重举行。期间华为云主办了以“CodeArts加速软件智能化开发,携手HarmonyOS重塑企业应用创新体验”为主题的分论坛。论坛汇聚了各行各业的专家学者、技术领袖和开发者,共同探讨Harmo…...
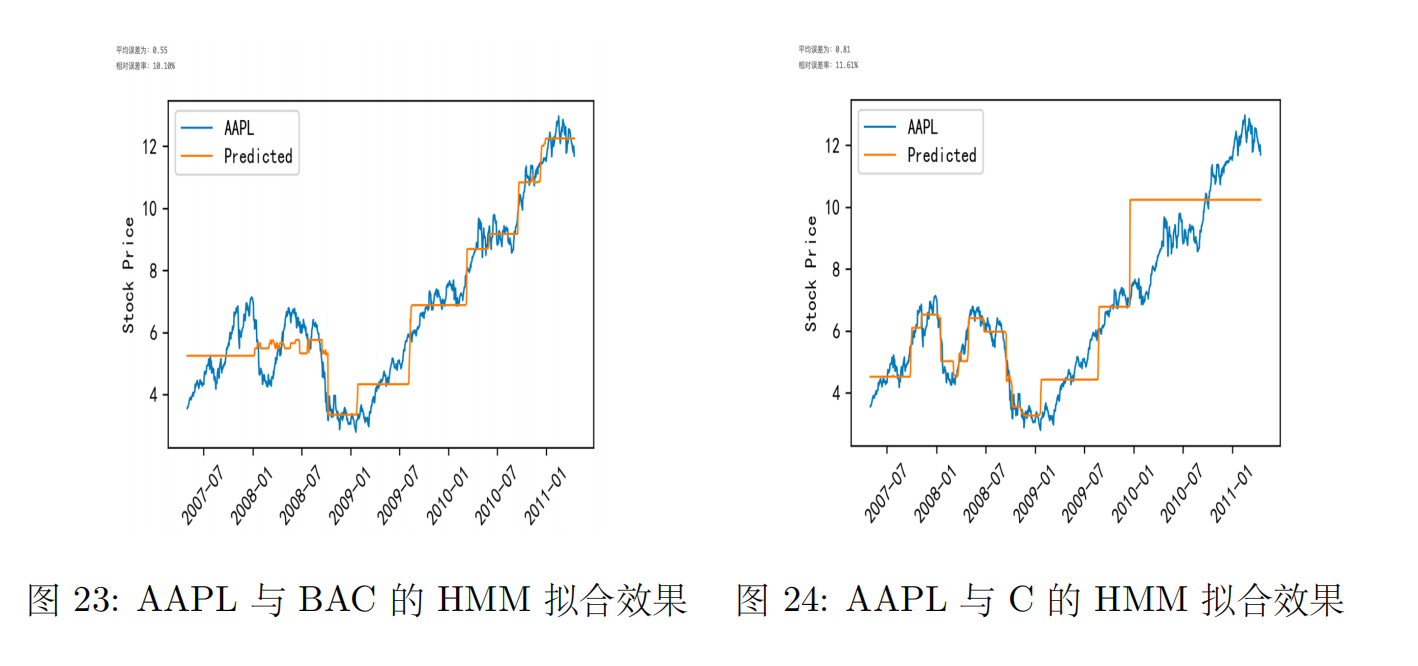
基于隐马尔可夫模型的股票预测【HMM】
基于机器学习方法的股票预测系列文章目录 一、基于强化学习DQN的股票预测【股票交易】 二、基于CNN的股票预测方法【卷积神经网络】 三、基于隐马尔可夫模型的股票预测【HMM】 文章目录 基于机器学习方法的股票预测系列文章目录一、HMM模型简介(1)前向后…...

PostgreSQL Replication Slots
一、PostgreSQL的网络测试 安装PostgreSQL客户端 sudo yum install postgresql 进行网络测试主要是验证客户端是否能够连接到远程的PostgreSQL服务器。以下是使用psql命令进行网络测试的基本步骤: 连接到数据库: 使用psql命令连接到远程的PostgreSQL数据库服务器…...

centos7搭建zookeeper 集群 1主2从
centos7搭建zookeeper 集群 准备前提规划防火墙开始搭建集群192.168.83.144上传安装包添加环境变量修改zookeeper 的配置 192.168.83.145 和 192.168.83.146 配置 启动 集群 准备 vm 虚拟机centos7系统zookeeper 安装包FinalShell或者其他shell工具 前提 虚拟机安装好3台cen…...

基于Claude API的全栈AI应用开发框架:从架构设计到生产部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想把手头的一些想法快速落地成可交互的Web应用。相信很多开发者都有类似的痛点:大模型API调用起来简单,但要把想法变成一个功能完整、界面友好、还能稳定部署的应用,中间隔着一道…...
)
Vivado工程文件太大?三步教你用Tcl脚本实现源码“瘦身”与备份(附完整命令)
Vivado工程瘦身实战:Tcl脚本驱动的源码管理与协作优化 在FPGA开发领域,Vivado工程文件的体积膨胀问题一直是开发者面临的痛点。一个中等规模的项目经过几次综合与实现后,工程目录轻松突破数百MB并不罕见。这不仅占用宝贵的存储空间ÿ…...

在Windows电脑上畅享酷安社区的完整指南:桌面端酷安客户端终极教程
在Windows电脑上畅享酷安社区的完整指南:桌面端酷安客户端终极教程 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 想要在大屏幕上舒适地浏览酷安社区吗?厌倦了手机…...

Bash脚本集成AI:实现自然语言到命令行的自动化运维工具
1. 项目概述:当Bash脚本遇见AI,自动化运维的新范式最近在GitHub上看到一个挺有意思的项目,叫“Hezkore/bash-ai”。光看名字,你可能会有点懵:Bash脚本和AI,这两个看似八竿子打不着的玩意儿,怎么…...
:Offload、Flow、NUMA、IOVA 与性能剖析)
DPDK 教程(四):Offload、Flow、NUMA、IOVA 与性能剖析
DPDK 教程(四):Offload、Flow、NUMA、IOVA 与性能剖析 本文对应学习路径第四步:在已能跑通 多队列转发 后,把系统从“能跑”推到“可解释、可优化”。重点放在:硬件卸载的正确语义、Flow 与 RSS 的分工、NU…...

Kimi代码授权与自动化工具:逆向工程与协议模拟实践
1. 项目概述:一个面向Kimi的代码授权与自动化工具最近在GitHub上看到一个挺有意思的项目,叫FelipeOFF/openclaw-kimi-code-auth。光看名字,可能有点摸不着头脑,但如果你正在研究如何与Kimi这类大型语言模型进行更稳定、更自动化的…...
)
别再手动输数据了!手把手教你用Fluent的Profile功能导入实验数据(附CSV文件模板)
别再手动输数据了!手把手教你用Fluent的Profile功能导入实验数据(附CSV文件模板) 在计算流体力学(CFD)分析中,准确导入实验数据或第三方软件的计算结果作为边界条件,往往是确保仿真可靠性的关键…...

北京明光云振铎数据科技Java面经
Nacos、OpenFeign、Gateway 三个组件的作用及协作流程首先:Nacos 主要负责服务注册发现和配置中心Gateway 作为统一网关入口,负责路由、鉴权、限流OpenFeign 负责服务之间的远程调用用户请求先进入 GatewayGateway 会先做 JWT 鉴权,比如校验 …...

立体仓库WMS深度解析
立体仓库WMS深度解析📌 封面语:立体仓库失败案例中,80% 不是硬件问题,而是 WMS 和 WCS “对话” 失败。想避坑,先搞懂这套软件怎么运转。 ✍️ 作者:这是「物流自动化软件内参」WMS 深度解析系列的第一篇。…...

年度名场面!黄仁勋逛胡同被投喂豆汁,眉头紧锁。网友:弥补了没有喝过 XX 的遗憾
5 月 15 日,「黄仁勋 南锣鼓巷」话题突然在多平台引爆热议。谁能想到,手握 5 万亿美刀市值的科技大佬,私下里竟是胡同干饭人。昨天在大会堂还是西装革履,今天老黄换上他的经典皮肤套装,带几名随行人员低调逛南锣鼓巷和…...