cube-studio开源一站式机器学习平台,在线ide,jupyter,vscode,matlab,rstudio,ssh远程连接,tensorboard
全栈工程师开发手册 (作者:栾鹏)
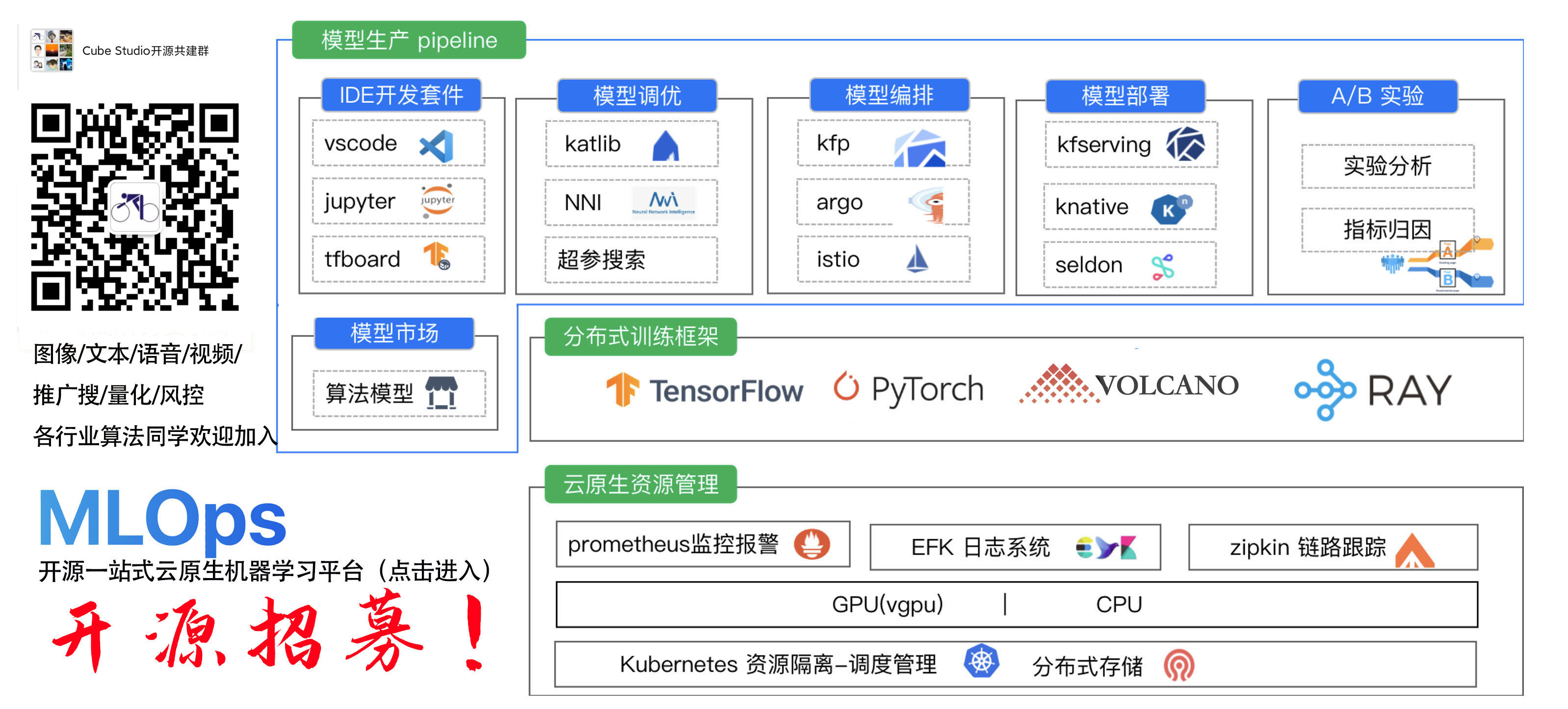
一站式云原生机器学习平台
前言
开源地址:https://github.com/tencentmusic/cube-studio
cube studio 腾讯开源的国内最热门的一站式机器学习mlops/大模型训练平台,支持多租户,sso单点登录,支持在线镜像调试,在线ide开发,数据集管理,图文音标注和自动化标注,任务模板自定义,拖拉拽任务流,模型分布式多机多卡训练,超参搜索,模型管理,推理服务弹性伸缩,支持ml/tf/pytorch/onnx/tensorrt/llm模型0代码服务发布,以及配套资源监控和算力,存储资源管理。支持机器学习,深度学习,大模型 开发训练推理发布全链路。支持元数据管理,维表,指标,sqllab,数据etl等数据中台对接功能。支持多集群,边缘集群,serverless集群方式部署。支持计量计费,资源额度限制,支持vgpu,rdma,国产gpu,arm64架构。
aihub模型市场:支持AI hub模型市场,支持400+开源模型应用一键开发,一键微调,一键部署。
gpt大模型:支持40+开源大模型部署一键部署,支持ray,volcano,spark等分布式计算框架,支持tf,pytorch,mxnet,mpi,paddle,mindspre分布式多机多卡训练框架,支持deepspeed,colossalai,horovod分布式加速框架,支持llama chatglm baichuan qwen系列大模型微调。支持llama-factory 100+llm微调,支持大模型vllm推理加速,支持智能体私有知识库,智能机器人。
在线开发是一个很重要的功能,对于大部分用户来说,在线的IDE比命令vim是要方便很多。cube主要提供了vscode和jupyter两种在线ide。并没有将代码和数据进行分割存储。所以在notebok中打开的就是完全用户自己的代码和数据,可以方便的进行调试。
vscode
theia是一个在线vscode,更像本地IDE,主要服务纯代码开发(多实例,一个人可以同时开多个theia)
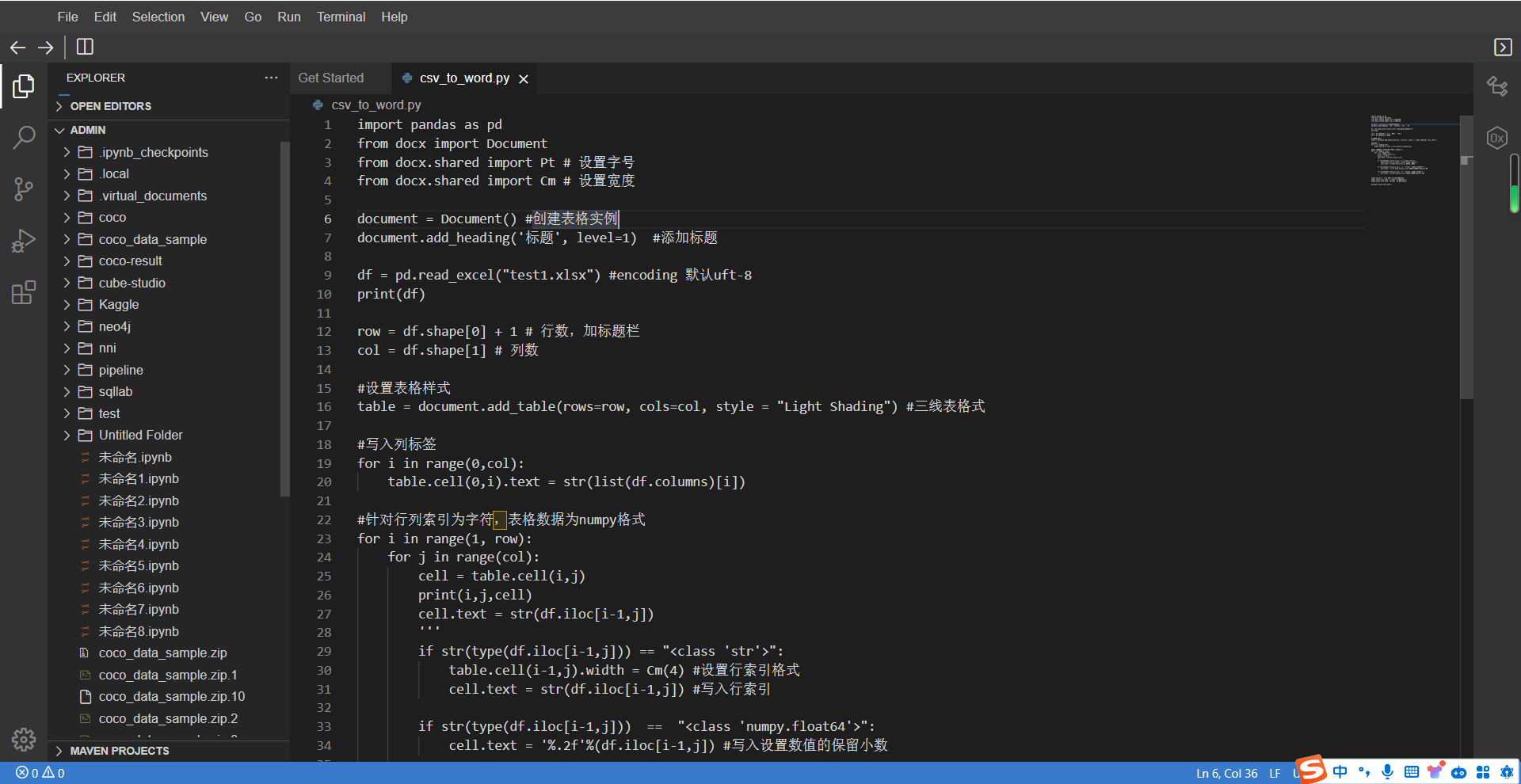
工作目录默认是/mnt,归档目录是/archives,可以把一些想永久保存,不易被误删的文件放在归档目录。
在vscode里面(本质为theia),用户跟本地vscode基本一致,上传下载文件/文件夹,也可以在theia中打开命令行终端。并且在其中封装了用户的基本环境需求,比如python。
需要说明的是,由于theia的功能中有些进程,例如rg进程,会不停的搜索扫描目录下的所有文件。由于个人目录下包含了用户的代码和用户的数据,文件可能非常多(千万到亿级别的文件数量)。这些进程扫描会严重拖慢分布式存储的性能。所以cube做了定时检杀的功能,能够及时检杀rg和git进程,提高在线vscode的响应速度。
jupyter

数据挖掘的用户使用jupyter会更多一些。在jupyter里面跟vscode里面相同,也安装了一些实用的插件,比如tensorboard,使用jupyter pro版本可以在jupyter里面打开。
比如我们在pipeline/example/tensorboard中有一个示例文件demo.py,运行这个文件,会生成一个fit_logs文件夹,这就是tf的log目录,进入这个目录,然后使用tensorboard按钮启动tensorboard,就可以查看该训练的情况。
大数据版本
大数据版本的Jupyter notebook,创建notebook时选择Jupyter(bigdata)镜像,集成了大数据常用的基础包,比如spark、flink等。支持爬虫、数据分析、数据挖掘和可视化等常用Python包的使用。
机器学习版本
机器学习版本的Jupyter notebook,创建notebook时选择Jupyter(machinelearning)镜像,集成了机器学习常用的基础包,比如sklearn、scipy等。
深度学习版本
深度学习版本的Jupyter notebook,创建notebook时选择Jupyter(DeepLearning)镜像,集成了深度学习常用的基础包,比如TensorFlow、Keras等。
rstudio
R版本的notebook,创建notebook时选择rstudio(bigdata)镜像,集成了R语言的在线IDE,IDE名称为Rstudio。
matlab
MATLAB版本的notebook,创建notebook时选择matlab(DeepLearning)镜像,集成了MATLAB的在线IDE。
pro版本
Pro版本的Jupyter中使用不同版本的Python内核,从python2.7到python3.9均可支持。
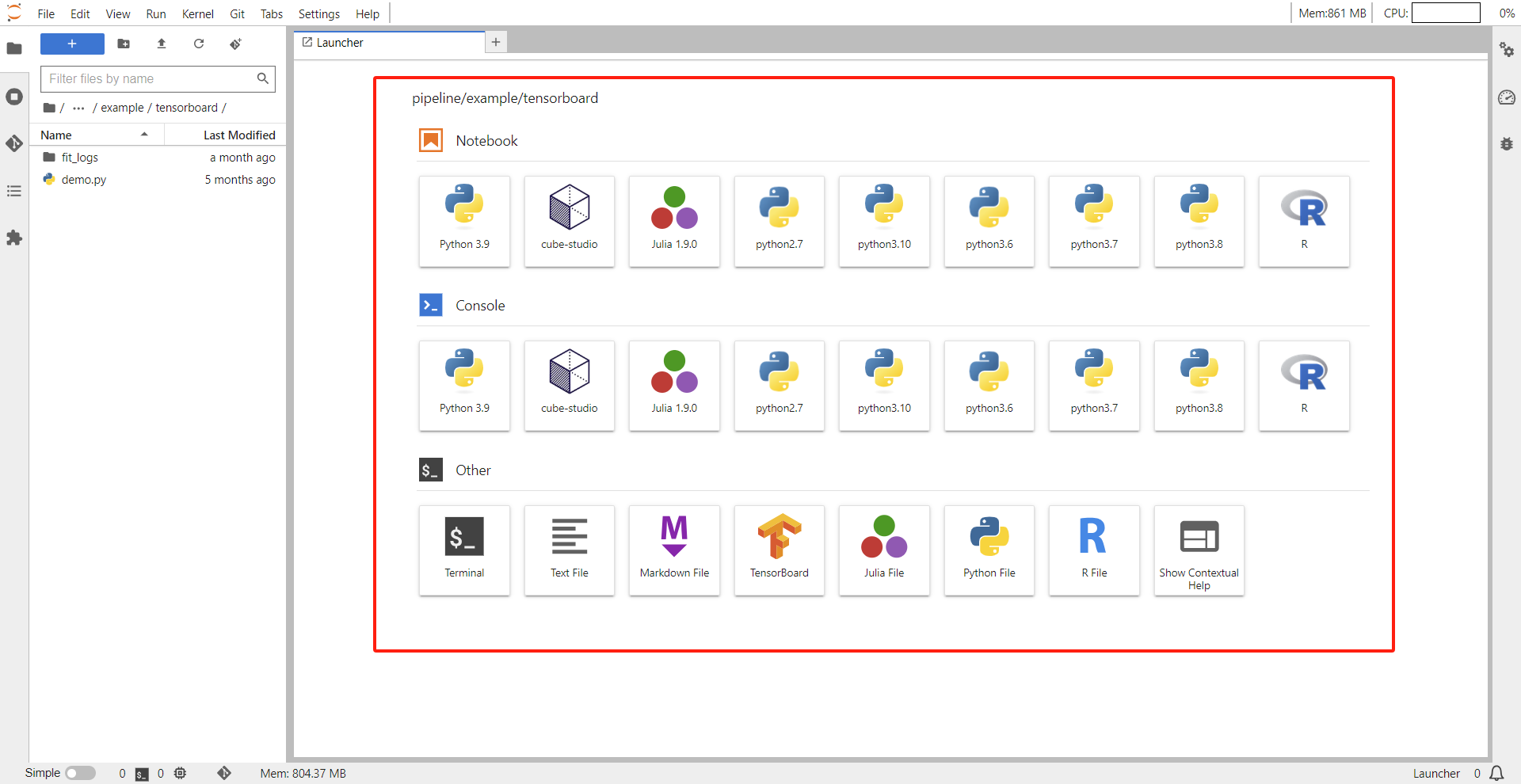
tensorboard可视化训练
pro版本的Jupyter有tensorboard,创建notebook时镜像选择jupyter-conda-pro(cpu),创建一个pro版本的jupyter,运行/mnt/$username/pipeline/example/tensorboard/demo.py,运行结束会产生结果文件。进入结果文件夹,此时点击“+”符号,打开tensorboard,再选择需要进行可视化的文件,即可查看可视化结果,如下图所示。
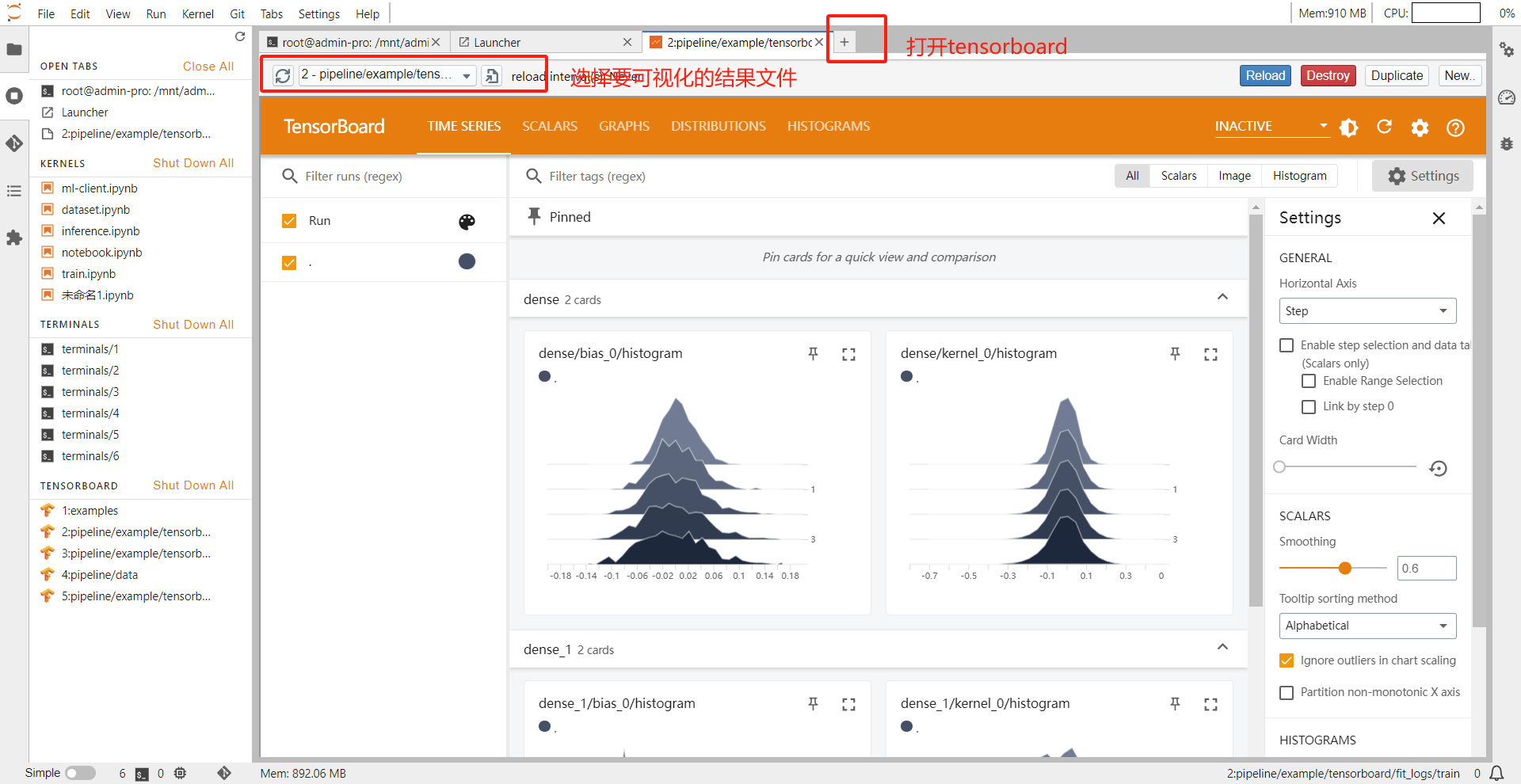
需要注意的是,集成了tensorboard的notebook是CPU版本的,因此,如果我们需要用GPU来训练模型,并且用tensorboard做可视化,可以用GPU版本的notebook来做模型训练,把需要可视化的结果文件写到分布式存储中,再在pro版本的notebook中打开tensorboard。
密码保护
需要修改config.py配置文件中ENABLE_JUPYTER_PASSWORD设置为True并更新到线上,重启后端,则会在每个jupyter后面会自动生成密码,每次进入jupyter要使用这个密码。
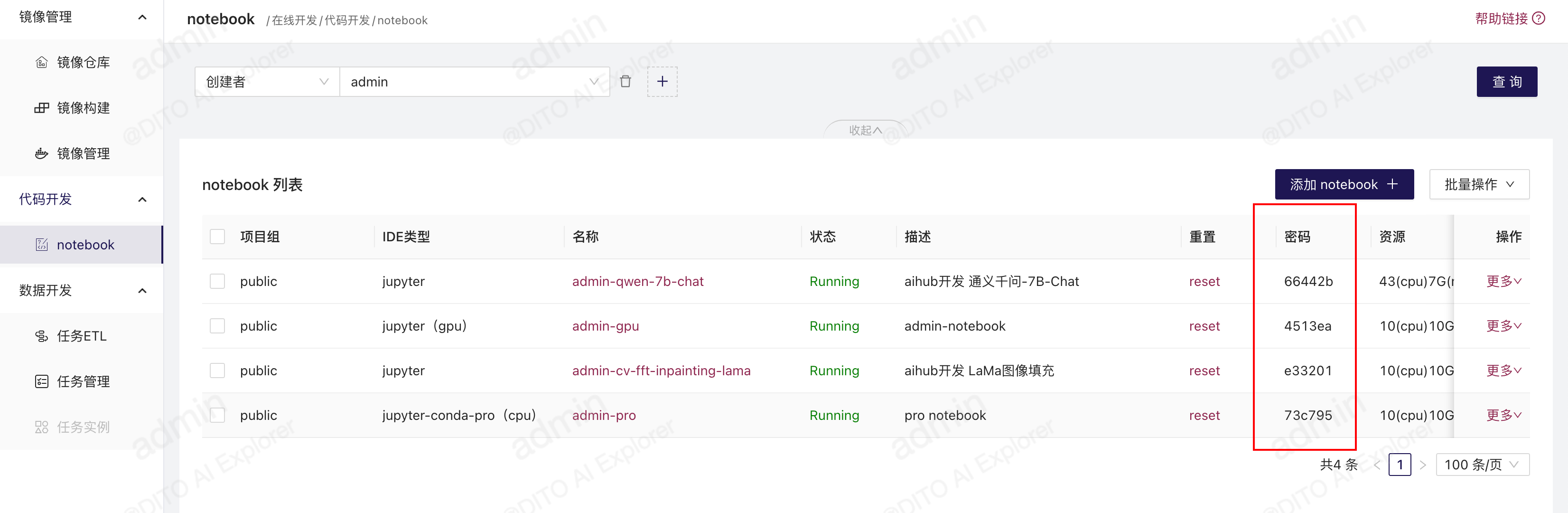
登录jupyter时需要密码
ssh远程连接jupyter功能
实现原理
jupyter版本的notebook中提供了sshd,会在notebook创建时自动启动ssh-server,并且会自动生成配置文件example/ssh链接
并为每个notebook的pod配置一个单独的service,service使用ip和端口的形式对外暴漏,每个notebook使用的端口为10000+10*id+1
需要公司网络能通过ip+端口的形式访问notebook的服务
操作方法
按照example/ssh链接 文件中的描述,在本地~/.ssh/config中添加链接配置文件
# 将此文件内容追加到~/.ssh/config ssh root登录密码 cube-studio
# ssh-copy-id -p PORT root@HOST 本地设置免密登录Host cube-studioHostName xx.xx.xx.xxPort xxUser rootIdentityFile ~/.ssh/id_rsaServerAliveInterval 10ControlMaster autoControlPath ~/.ssh/master-%r@%h:%pForwardAgent yes
然后就可以ssh链接远程notebook了,并且可以在本地将文件拖拽到本地vscode,这样文件就是自动同步到在线notebook中
单端口代理jupyter内部ssh server
要实现这个目标,您可以使用SSH端口转发功能。具体来说,您可以在内网中设置一个跳板机(也称为SSH代理服务器),并通过它连接到其他内网SSH服务器。以下是如何实现这个目标的步骤:
-
首先,确保您可以从本地客户端访问内网中的跳板机。例如,假设跳板机的IP地址为192.168.1.1,端口号为22,用户为user1。
-
在本地客户端上设置SSH代理隧道。这将允许您通过跳板机访问其他内网SSH服务器。例如,假设您希望连接到内网中的SSH服务器A(IP地址:192.168.1.2,端口:10022,用户:user2)和SSH服务器B(IP地址:192.168.1.3,端口:10023,用户:user3)。在本地客户端上,运行以下命令以创建SSH隧道:
ssh -L 10022:192.168.1.2:10022 -L 10023:192.168.1.3:10023 user1@192.168.1.1 -p 22user1是您在跳板机上的用户名。这将在您的本地客户端上创建两个端口转发(10022和10023),分别连接到内网中的SSH服务器A和B。 -
现在,您可以通过本地客户端上的端口10022和10023来访问内网中的SSH服务器A和B。例如,要连接到SSH服务器A,您可以运行以下命令:
ssh user2@127.0.0.1 -p 10022要连接到SSH服务器B,您可以运行以下命令:
ssh user3@127.0.0.1 -p 10023在这两个命令中,
user2,user3是您在SSH服务器A和B上的用户名。
通过这种方法,您可以通过仅可以访问的内网IP和端口来访问内网中的不同SSH服务器。
jupyter里面链接spark
对于需要连接数据中台的场景,例如连接Hive或Spark集群,我们可以在自定义Notebook中预先配置好相关的XML文件,以便用户直接使用。这样,开发者只需要配置一次,普通用户就可以直接使用,无需再次配置。
在jupyter中启动提交spark任务,作为driver端需要监听端口,每个notebook在创建的时候会预留 P O R T 1 和 PORT1和 PORT1和PORT2两个环境变量代表的端口来对外监听,同时在$SERVICE_EXTERNAL_IP环境变量代表的主机上进行监听,所以需要告诉spark的master,driver的服务监听地址,这样能让master返回数据到driver端
# 创建 SparkSession
spark = SparkSession.builder \.appName("PythonPi") \.master('spark://myspark-master-0.myspark-headless.kubeflow.svc.cluster.local:7077') \.config("spark.executor.memory", "2g") \.config("spark.executor.cores", "2") \.config("spark.cores.max", "8") \.config("spark.driver.memory", "2g") \.config("spark.ui.enabled", False) \.config("spark.driver.port", os.getenv('PORT1')) \.config("spark.blockManager.port", os.getenv('PORT2')) \.config("spark.driver.bindAddress", '0.0.0.0') \.config("spark.driver.host", os.getenv('SERVICE_EXTERNAL_IP')) \.getOrCreate()
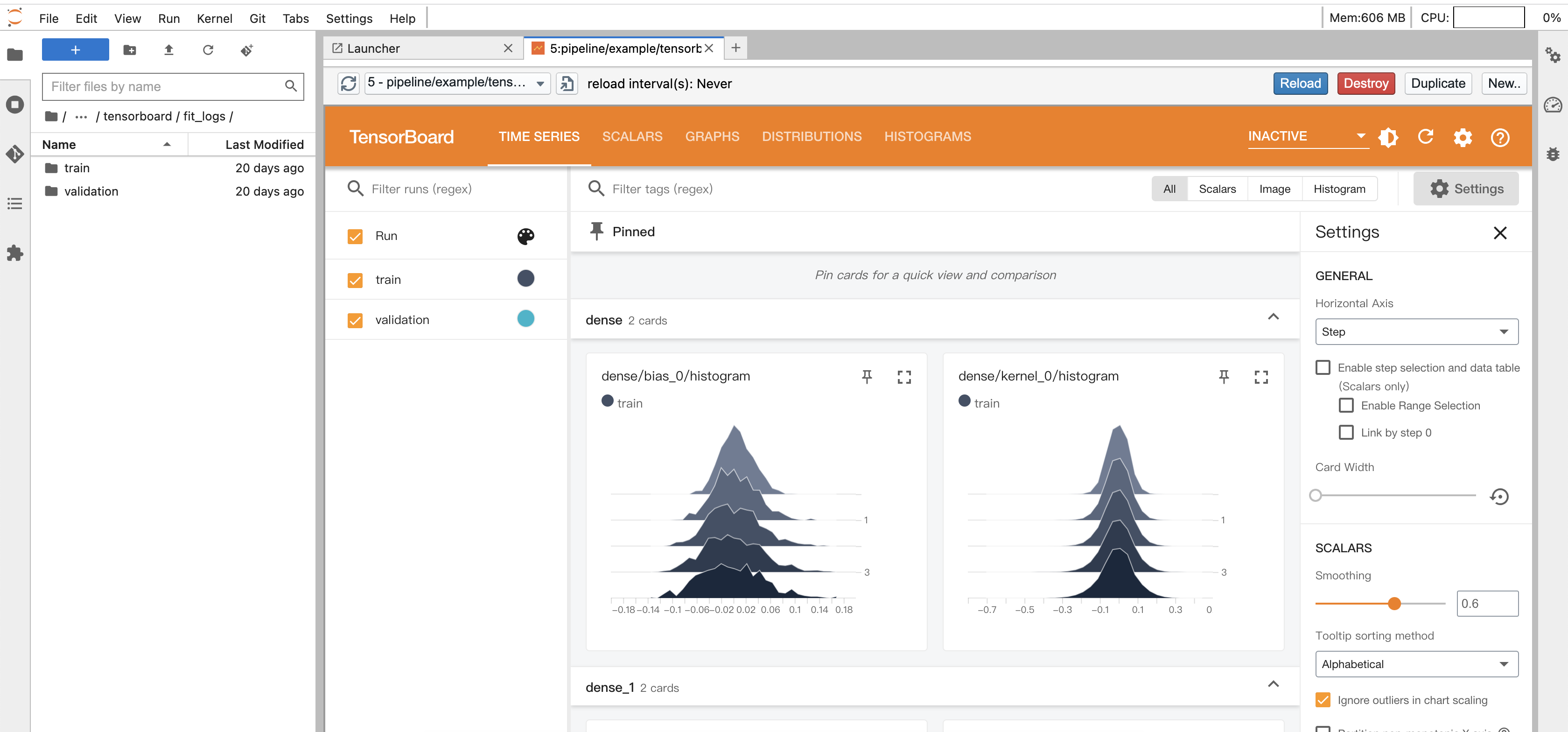
tensorboard
使用pro版本的jupyter,在左侧目录树,进入到tensorboard对应的日志目录,再打开右侧的tensorboard按钮
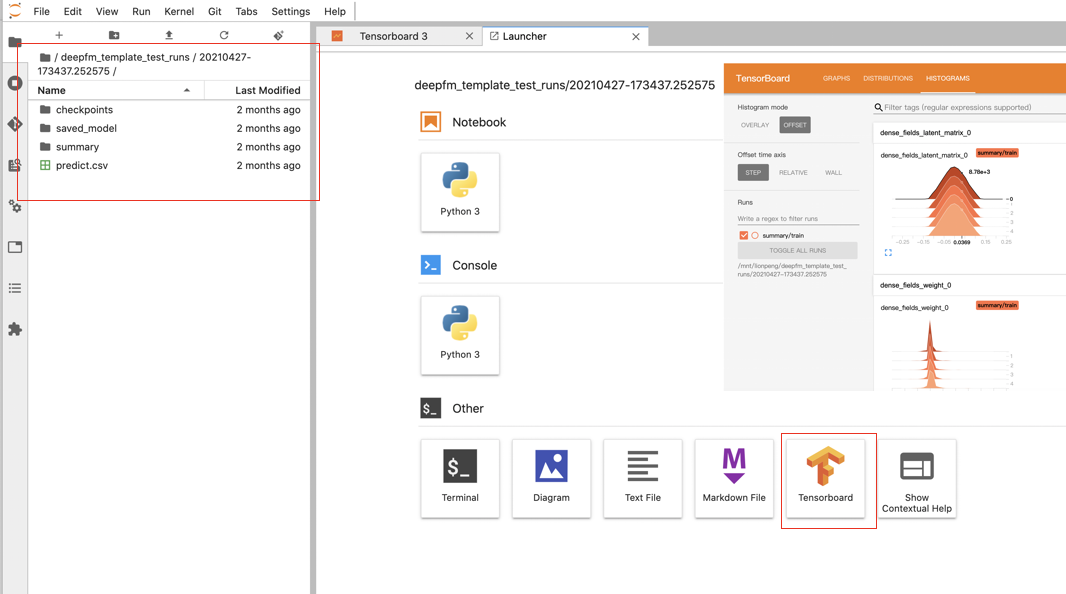
就可以查看日志目录中所包含的记录的训练过程中的信息和模型的信息
git功能
pro版本的notebook中,可以直接使用git。比如直接clone一个项目到notebook中,修改文件,点击git图标,就能直接看到原文件和修改后文件的对比。

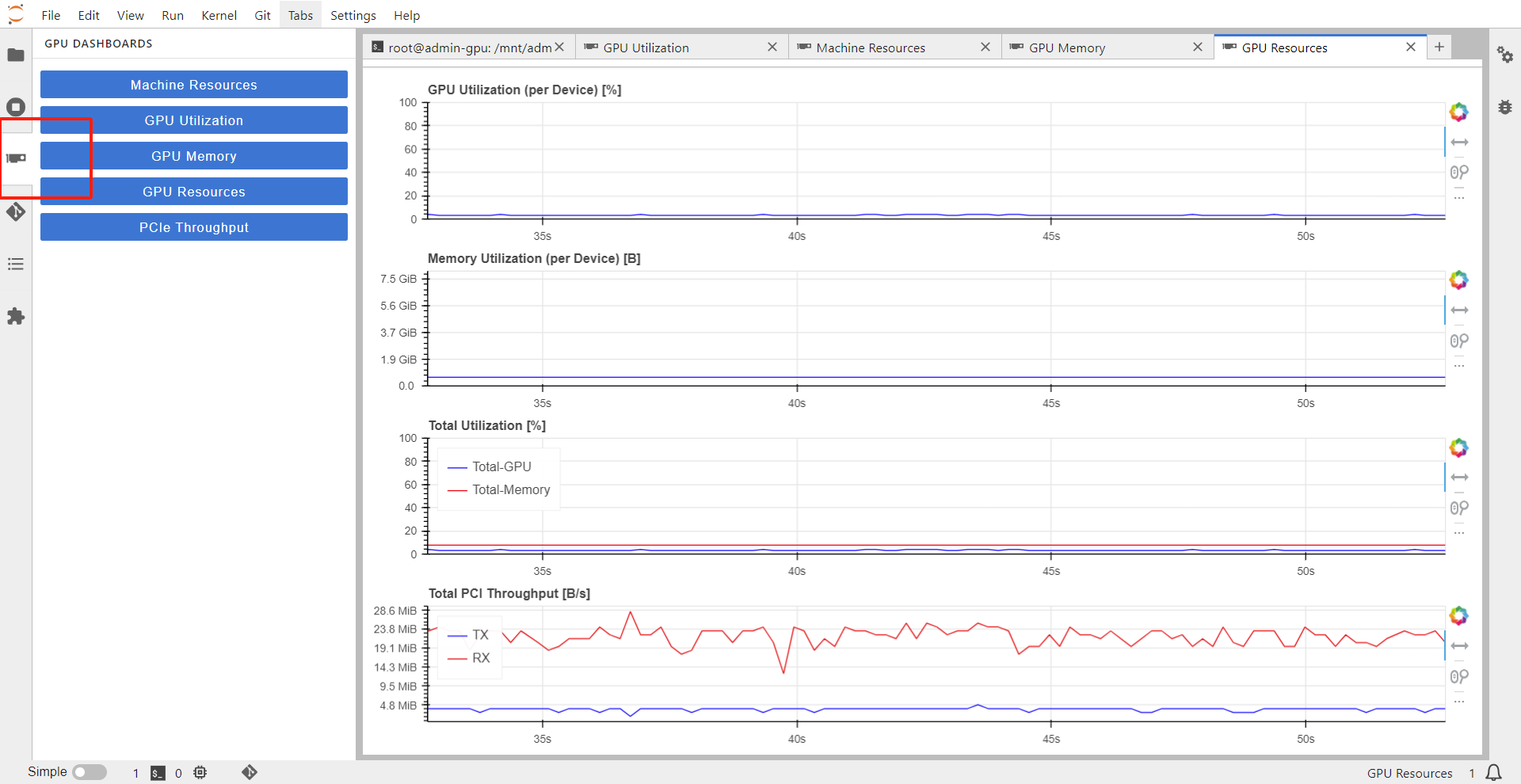
gpu监控,cpu,内存监控
图示按钮,可帮助用户在notebook中查看资源的使用情况。需要注意的是,只有GPU版本的notebook可以在notebook中查看GPU监控,其他版本的notebook即使调用了GPU,也只能在grafana中统一查看GPU资源的监控。
jupyter多内核态
在使用自定义Notebook时,需要注意的是,安装包时应该先激活对应的环境,然后再进行安装。这是因为Jupyter的内核和conda环境是两个不同的概念,需要分别进行管理。
在线ide的资源占用问题
cube采用的方案是只设置notebook的pod的limit,而不设置request,这种方案就对不资源进行独占,这样也就不用清理notebook,只是允许了notebook中的资源干扰。
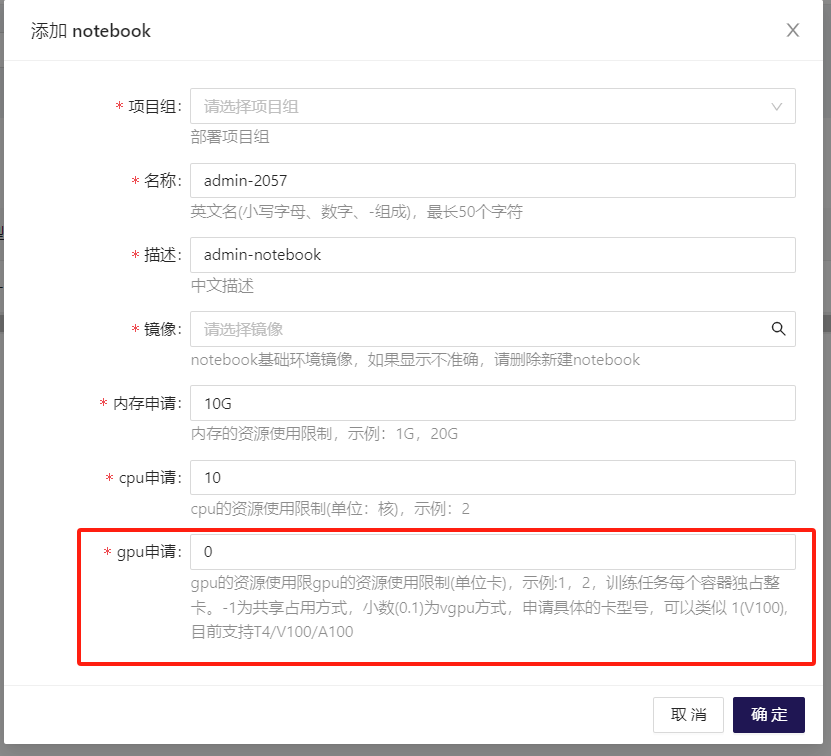
GPU的占用方式上,允许独占、共享、VGPU三种方式,gpu申请(单位卡),示例:填写1,2,表示训练任务每个容器独占整卡。填写-1为共享占用方式,填写小数(0.1)为vgpu方式,申请具体的卡型号,可以类似 1(V100),目前支持T4/V100/A100。
在线ide的环境重置问题
如果notebook因为oom,定时清理,机器故障,主动reset等可能原因而重启,notebook中的环境就会丢失,但分布式存储下的内容都会保留,也就是/mnt/$username文件夹下的内容都会保留。
所以我们如果需要环境保存,有两个方案:
-
cube添加了notebook启动后自动执行/mnt/$username/init.sh脚本,用户只需要在init.sh中定义notebook特定的环境,就可以在启动notebook后拥有自己独特的环境了。
-
在notebook中有一个“镜像保存”按钮,每次notebook环境更改之后,都可以点击这个按钮,保存环境,下次重启就会自动用这个镜像来启动notebook,如下图所示。

多实例的virtualservice代理
多实例在线IDE图示

每个用户可以配置多个在线IDE,可以自己配置资源,镜像,类型。每个在线IDE都是通过istio virtualservice来代理的。所以只要在线IDE的镜像启动的web服务支持url prefix,就可以被加进来作为在线IDE,比如matlab,rstudio。每个在线IDE实例,都有独立的以名称为prefix的url地址,在virtualservice配置绑定istio ingressgateway,这样来实现多实例。
名为admin-9d3d的在线IDE的url prefix:

名为admin-e00f的在线IDE的url prefix:

在线ide镜像保存
如果想保存自己notebook中的环境,可以在notebook列表中点击"镜像保存"的按钮,平台将自动将该notebook的pod通过docker commit成镜像,镜像名称为jupyter-user:$notebook-name,并推送到仓库,所以还需要管理员提前配置自己内网的仓库地址和账号密码
在线ide清理和需求
默认情况下在线ide每天晚上会清理三天前的,清理只是关闭容器,不会清理文件,重启容器,环境会丢失。
定时清理任务的配置
在config.py的task_delete_notebook,注释这个任务,可以停止定时清理notebook,每次notebook有效期为3天,清理前一天会提醒用户进行续期。
任务续期
点击对应notebook后的续期按钮,可以为当前notebook续期三天使用时间。

相关文章:
cube-studio开源一站式机器学习平台,在线ide,jupyter,vscode,matlab,rstudio,ssh远程连接,tensorboard
全栈工程师开发手册 (作者:栾鹏) 一站式云原生机器学习平台 前言 开源地址:https://github.com/tencentmusic/cube-studio cube studio 腾讯开源的国内最热门的一站式机器学习mlops/大模型训练平台,支持多租户&…...
1976 ssm 营地管理系统开发mysql数据库web结构java编程计算机网页源码Myeclipse项目
一、源码特点 ssm 营地管理系统是一套完善的信息系统,结合springMVC框架完成本系统,对理解JSP java编程开发语言有帮助系统采用SSM框架(MVC模式开发),系统具有完整的源代码和数据库,系统主要采用B/S模式开…...

技术派全局异常处理
前言 全局的异常处理是Java后端不可或缺的一部分,可以提高代码的健壮性和可维护性。 在我们的开发中,总是难免会碰到一些未经处理的异常,假如没有做全局异常处理,那么我们返回给用户的信息应该是不友好的,很抽象的&am…...

对于mysql 故障的定位和排查
故障表现 他的执行时间超过规定的限制(比如1000ms)CPU使用率高大量业务失败,数据连接异常执行sql越来越慢,失败越来越多 解决方案 定位 应急 故障恢复 定位 查询慢sql的日志查看mysql 的performance schena(里面…...

什么是电航空插头插座连接器有什么作用
航空插头概述 定义与功能 航空插头,又称航空连接器,是一种专门用于航空领域的电连接器,因其最初在航空领域得到广泛应用而得名。航空插头的主要功能是实现电源或信号的连接,尤其适用于芯数较多、结构复杂的线束连接,…...

数据挖掘常见算法(分类算法)
K-近邻算法(KNN) K-近邻分类法的基本思想:通过计算每个训练数据到待分类元组Zu的距离,取和待分类元组距离最近的K个训练数据,K个数据中哪个类别的训练数据占多数,则待分类元组Zu就属于哪个类别…...

【深度学习】调整加/减模型用于体育运动评估
摘要 一种基于因果关系的创新模型,名为调整加/减模型,用于精准量化个人在团队运动中的贡献。该模型基于明确的因果逻辑,将个体运动员的价值定义为:在假设情景下,用一名价值为零的球员替换该球员后,预期比赛…...
重生之算法刷题之路之链表初探(三)
算法刷题之路之链表初探(三) 今天来学习的算法题是leecode2链表相加,是一道简单的入门题,但是原子在做的时候其实是有些抓耳挠腮,看了官解之后才恍然大悟! 条件 项目解释 有题目可以知道,我们需…...

哪吒汽车,正在等待“太乙真人”的拯救
文丨刘俊宏 在360创始人、哪吒汽车股东周鸿祎近日连续且着急的“督战”中,哪吒汽车(下简称哪吒)终究还是顶不住了。 6月26日,哪吒通过母公司合众新能源在港交所提交了IPO文件,急迫地希望成为第五家登陆港股的造车新势力…...

HDC Cloud 2024 | CodeArts加速软件智能化开发,携手HarmonyOS重塑企业应用创新体验
2024年6月21~23日,华为开发者大会HDC 2024在东莞溪流背坡村隆重举行。期间华为云主办了以“CodeArts加速软件智能化开发,携手HarmonyOS重塑企业应用创新体验”为主题的分论坛。论坛汇聚了各行各业的专家学者、技术领袖和开发者,共同探讨Harmo…...
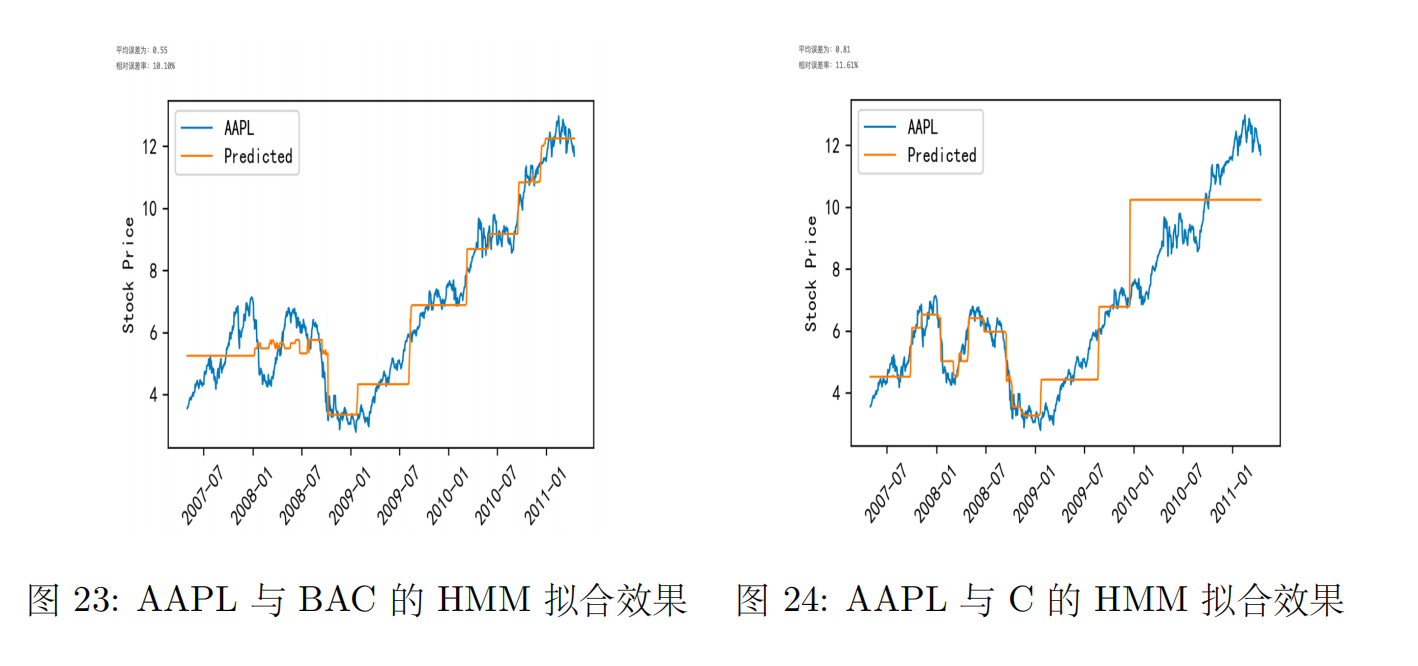
基于隐马尔可夫模型的股票预测【HMM】
基于机器学习方法的股票预测系列文章目录 一、基于强化学习DQN的股票预测【股票交易】 二、基于CNN的股票预测方法【卷积神经网络】 三、基于隐马尔可夫模型的股票预测【HMM】 文章目录 基于机器学习方法的股票预测系列文章目录一、HMM模型简介(1)前向后…...

PostgreSQL Replication Slots
一、PostgreSQL的网络测试 安装PostgreSQL客户端 sudo yum install postgresql 进行网络测试主要是验证客户端是否能够连接到远程的PostgreSQL服务器。以下是使用psql命令进行网络测试的基本步骤: 连接到数据库: 使用psql命令连接到远程的PostgreSQL数据库服务器…...

centos7搭建zookeeper 集群 1主2从
centos7搭建zookeeper 集群 准备前提规划防火墙开始搭建集群192.168.83.144上传安装包添加环境变量修改zookeeper 的配置 192.168.83.145 和 192.168.83.146 配置 启动 集群 准备 vm 虚拟机centos7系统zookeeper 安装包FinalShell或者其他shell工具 前提 虚拟机安装好3台cen…...

Arrays.asList 和 java.util.ArrayList 区别
理解 Java 中的 Arrays.asList 和 java.util.ArrayList 的区别 在 Java 编程中,Arrays.asList 方法和 java.util.ArrayList 是两种常用的处理列表数据的方式。虽然它们在功能上看起来相似,但在内部实现和使用上有着本质的不同。本文将探讨这两种方式的区…...
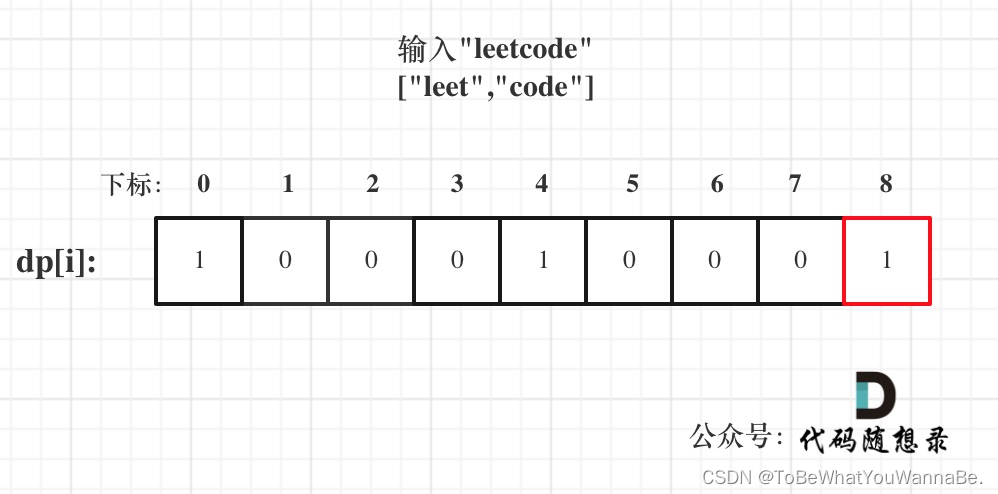
代码随想录-Day44
322. 零钱兑换 给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。 你可以认为每种硬币的数…...
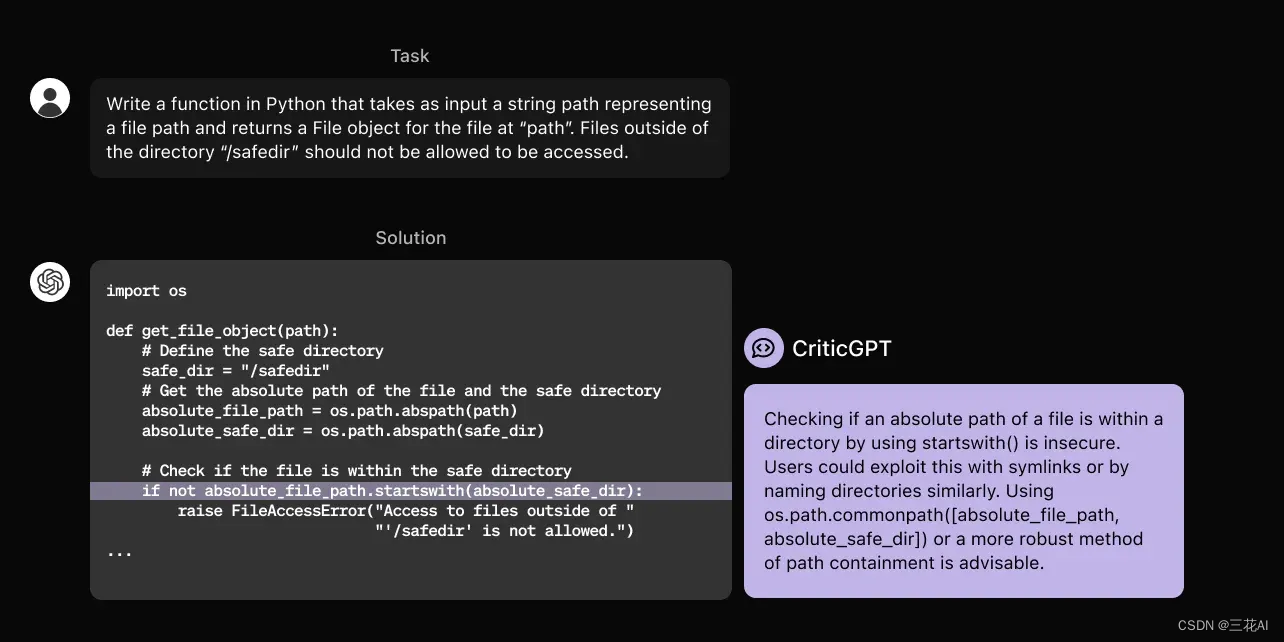
CriticGPT: 用 GPT-4 找出 GPT-4 的错误
CriticGPT 是 OpenAI 发布的一个基于 GPT-4 的模型,它可以帮助我们人类 Review 并纠正 ChatGPT 在生成代码时的错误。使用 CriticGPT 审查代码时,有 60% 的概率生成的代码更好更正确。...

SpringBoot:SpringBoot中调用失败如何重试
一、引言 在实际的应用中,我们经常需要调用第三方API来获取数据或执行某些操作。然而,由于网络不稳定、第三方服务异常等原因,API调用可能会失败。为了提高系统的稳定性和可靠性,我们通常会考虑实现重试机制。 Spring Retry为Spri…...

2024-06-24 问AI: 在大语言模型中,什么是ray?
文心一言 在大语言模型中,Ray是一个开源的统一框架,用于扩展AI和Python应用程序,特别是在机器学习领域。以下是关于Ray的详细解释: 核心功能: Ray为并行处理提供了计算层,使得用户无需成为分布式系统专家…...

仓库管理系统09--修改用户密码
1、添加窗体 2、窗体布局控件 UI设计这块还是传统的表格布局,采用5行2列 3、创建viewmodel 4、前台UI绑定viewmodel 这里要注意属性绑定和命令绑定及命令绑定时传递的参数 <Window x:Class"West.StoreMgr.Windows.EditPasswordWindow"xmlns"http…...

在Spring Data JPA中使用@Query注解
目录 前言示例简单示例只查询部分字段,映射到一个实体类中只查询部分字段时,也可以使用List<Object[]>接收返回值再复杂一些 前言 在以往写过几篇spring data jpa相关的文章,分别是 Spring Data JPA 使用JpaSpecificationExecutor实现…...

终极指南:如何用Reset-Windows-Update-Tool快速修复Windows更新故障
终极指南:如何用Reset-Windows-Update-Tool快速修复Windows更新故障 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool …...

小白程序员看过来!TS同学半年逆袭AI大模型产品经理,收藏这份转行避坑指南!
TS同学从景观设计转行AI大模型产品经理的经历分享。他经历了离职、脱产学习、国企子公司项目被裁等波折,最终以20%薪资涨幅加入AI公司。文章重点介绍了他的心态调整、求职策略变化以及对“稳定”的新理解,同时探讨了AI时代教育孩子的思考。 本期嘉宾TS同…...

基于RAG的个人知识库AI助手:从原理到部署实战
1. 项目概述:当RAG遇上个人知识库最近几年,大语言模型(LLM)的能力边界不断被拓展,但一个核心痛点始终存在:它无法记住你私有的、非公开的、不断更新的知识。比如,你想让AI助手帮你分析上周的团队…...

基于LLM与LangChain的智能项目管理Agent:架构设计与工程实践
1. 项目概述:一个面向项目管理的智能体框架 最近在开源社区里,我注意到一个名为 gannonh/agent-pm 的项目开始受到一些关注。乍一看这个名字,你可能会联想到“项目经理”或者“项目管理”,没错,这个项目的核心定位&…...

北京明光云振铎数据科技Java面经
Nacos、OpenFeign、Gateway 三个组件的作用及协作流程首先:Nacos 主要负责服务注册发现和配置中心Gateway 作为统一网关入口,负责路由、鉴权、限流OpenFeign 负责服务之间的远程调用用户请求先进入 GatewayGateway 会先做 JWT 鉴权,比如校验 …...

书成紫微动,律定凤凰驯:从无心创作到天命显化的海棠山铁哥之路
书成紫微动,律定凤凰驯。 ——南北朝庾信一、千古谶语,千年未解诗句天道逻辑千年误读书成紫微动先著书立道,撼动文脉附会玄学,强行造神律定凤凰驯再定规立序,祥瑞归宁脑会剧情,虚妄狂欢 无人真正落地&#…...

基于RK3568的边缘AIoT实战:多模态行为识别系统设计与优化
1. 项目概述:从赛题到全国一等奖的实战复盘去年,我们团队抱着“试试看”的心态参加了瑞芯微与飞凌嵌入式联合举办的全国大学生嵌入式设计大赛,最终捧回了全国一等奖的奖杯。现在比赛尘埃落定,我想把整个项目从破题、选型、开发到最…...

Dell R630服务器RAID实战:8块硬盘如何混搭RAID1和RAID0?保姆级图文教程
Dell R630服务器混合RAID配置实战:系统盘与数据盘的黄金分割方案 在企业级IT基础设施中,存储配置的灵活性与可靠性往往决定着整个系统的稳定边界。当一台Dell PowerEdge R630服务器配备8块硬盘时,如何通过RAID技术的组合拳实现系统安全与数据…...

Botty:暗黑2重制版自动化助手,告别重复刷图的终极方案
Botty:暗黑2重制版自动化助手,告别重复刷图的终极方案 【免费下载链接】botty D2R Pixel Bot 项目地址: https://gitcode.com/gh_mirrors/bo/botty 你是否厌倦了在《暗黑破坏神2:重制版》中反复刷图、手动拾取、机械操作?每…...

基于SpringBoot的门禁与访客管理系统毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot框架的门禁与访客管理系统以解决传统门禁系统在智能化管理方面存在的局限性。当前多数门禁系统仍采用封闭式架构设计导致数据…...