【LLM教程-llama】如何Fine Tuning大语言模型?
今天给大家带来了一篇超级详细的教程,手把手教你如何对大语言模型进行微调(Fine Tuning)!(代码和详细解释放在后文)
目录
大语言模型进行微调(Fine Tuning)需要哪些步骤?
大语言模型进行微调(Fine Tuning)训练过程及代码
大语言模型进行微调(Fine Tuning)需要哪些步骤?
大语言模型进行微调(Fine Tuning)的主要步骤🤩
-
📚 准备训练数据集
首先你需要准备一个高质量的训练数据集,最好是与你的应用场景相关的数据。可以是文本数据、对话数据等,格式一般为JSON/TXT等。 -
📦 选择合适的基础模型
接下来需要选择一个合适的基础预训练模型,作为微调的起点。常见的有GPT、BERT、T5等大模型,可根据任务场景进行选择。 -
⚙️ 设置训练超参数
然后是设置训练的各种超参数,比如学习率、批量大小、训练步数等等。选择合理的超参数对模型效果影响很大哦。 -
🧑💻 加载模型和数据集
使用HuggingFace等库,把选定的基础模型和训练数据集加载进来。记得对数据集进行必要的前处理和划分。 -
⚡ 开始模型微调训练
有了模型、数据集和超参数后,就可以开始模型微调训练了!可以使用PyTorch/TensorFlow等框架进行训练。 -
💾 保存微调后的模型
训练结束后,别忘了把微调好的模型保存下来,方便后续加载使用哦。 -
🧪 在测试集上评估模型
最后在准备好的测试集上评估一下微调后模型的效果。看看与之前的基础模型相比,是否有明显提升?
大语言模型进行微调(Fine Tuning)训练过程及代码
那如何使用 Lamini 库加载数据、设置模型和训练超参数、定义推理函数、微调基础模型、评估模型效果呢?
- 首先,导入必要的库
import os
import lamini
import datasets
import tempfile
import logging
import random
import config
import os
import yaml
import time
import torch
import transformers
import pandas as pd
import jsonlinesfrom utilities import *
from transformers import AutoTokenizer
from transformers import AutoModelForCausalLM
from transformers import TrainingArguments
from transformers import AutoModelForCausalLM
from llama import BasicModelRunner
这部分导入了一些必需的Python库,包括Lamini、Hugging Face的Datasets、Transformers等。
- 加载Lamini文档数据集
dataset_name = "lamini_docs.jsonl"
dataset_path = f"/content/{dataset_name}"
use_hf = False
dataset_path = "lamini/lamini_docs"
use_hf = True
这里指定了数据集的路径,同时设置了use_hf标志,表示是否使用Hugging Face的Datasets库加载数据。
- 设置模型、训练配置和分词器
model_name = "EleutherAI/pythia-70m"
training_config = { ... }
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
train_dataset, test_dataset = tokenize_and_split_data(training_config, tokenizer)
这部分指定了基础预训练模型的名称,并设置了训练配置(如最大长度等)。然后,它使用AutoTokenizer从预训练模型中加载分词器,并对分词器进行了一些调整。最后,它调用tokenize_and_split_data函数对数据进行分词和划分训练/测试集。
- 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(model_name)
device_count = torch.cuda.device_count()
if device_count > 0:device = torch.device("cuda")
else:device = torch.device("cpu")
base_model.to(device)
这里使用AutoModelForCausalLM从预训练模型中加载基础模型,并根据设备(GPU或CPU)将模型移动到相应的设备上。
- 定义推理函数
def inference(text, model, tokenizer, max_input_tokens=1000, max_output_tokens=100):...
这个函数用于在给定输入文本的情况下,使用模型和分词器进行推理并生成输出。它包括对输入文本进行分词、使用模型生成输出以及解码输出等步骤。
- 尝试使用基础模型进行推理
test_text = test_dataset[0]['question']
print("Question input (test):", test_text)
print(f"Correct answer from Lamini docs: {test_dataset[0]['answer']}")
print("Model's answer: ")
print(inference(test_text, base_model, tokenizer))
这部分使用上一步定义的inference函数,在测试数据集的第一个示例上尝试使用基础模型进行推理。它打印了输入问题、正确答案和模型的输出。
- 设置训练参数
max_steps = 3
trained_model_name = f"lamini_docs_{max_steps}_steps"
output_dir = trained_model_name
training_args = TrainingArguments(# Learning ratelearning_rate=1.0e-5,# Number of training epochsnum_train_epochs=1,# Max steps to train for (each step is a batch of data)# Overrides num_train_epochs, if not -1max_steps=max_steps,# Batch size for trainingper_device_train_batch_size=1,# Directory to save model checkpointsoutput_dir=output_dir,# Other argumentsoverwrite_output_dir=False, # Overwrite the content of the output directorydisable_tqdm=False, # Disable progress barseval_steps=120, # Number of update steps between two evaluationssave_steps=120, # After # steps model is savedwarmup_steps=1, # Number of warmup steps for learning rate schedulerper_device_eval_batch_size=1, # Batch size for evaluationevaluation_strategy="steps",logging_strategy="steps",logging_steps=1,optim="adafactor",gradient_accumulation_steps = 4,gradient_checkpointing=False,# Parameters for early stoppingload_best_model_at_end=True,save_total_limit=1,metric_for_best_model="eval_loss",greater_is_better=False
)
这一部分设置了训练的一些参数,包括最大训练步数、输出模型目录、学习率等超参数。
为什么要这样设置这些训练超参数:
learning_rate=1.0e-5
学习率控制了模型在每个训练步骤中从训练数据中学习的速度。1e-5是一个相对较小的学习率,可以有助于稳定训练过程,防止出现divergence(发散)的情况。
num_train_epochs=1
训练的轮数,即让数据在模型上循环多少次。这里设置为1,是因为我们只想进行轻微的微调,避免过度训练(overfitting)。
max_steps=max_steps
最大训练步数,会覆盖num_train_epochs。这样可以更好地控制训练的总步数。
per_device_train_batch_size=1
每个设备(GPU/CPU)上的训练批量大小。批量大小越大,内存占用越高,但训练过程可能更加稳定。
output_dir=output_dir
用于保存训练过程中的检查点(checkpoints)和最终模型的目录。
overwrite_output_dir=False
如果目录已存在,是否覆盖它。设为False可以避免意外覆盖之前的结果。
eval_steps=120, save_steps=120
每120步评估一次模型性能,并保存模型。频繁保存可以在训练中断时恢复。
warmup_steps=1
学习率warmup步数,一开始使用较小的学习率有助于稳定训练早期阶段。
per_device_eval_batch_size=1
评估时每个设备上的批量大小。通常与训练时相同。
evaluation_strategy="steps", logging_strategy="steps"
以步数为间隔进行评估和记录日志,而不是以epoch为间隔。
optim="adafactor"
使用Adafactor优化器,适用于大规模语言模型训练。
gradient_accumulation_steps=4
梯度积累步数,可以模拟使用更大批量大小的效果,节省内存。
load_best_model_at_end=True
保存验证集上性能最好的那个检查点,作为最终模型。
metric_for_best_model="eval_loss", greater_is_better=False
根据验证损失评估模型,损失越小越好。
model_flops = (base_model.floating_point_ops({"input_ids": torch.zeros((1, training_config["model"]["max_length"]))})* training_args.gradient_accumulation_steps
)print(base_model)
print("Memory footprint", base_model.get_memory_footprint() / 1e9, "GB")
print("Flops", model_flops / 1e9, "GFLOPs")print(base_model)
print("Memory footprint", base_model.get_memory_footprint() / 1e9, "GB")
print("Flops", model_flops / 1e9, "GFLOPs")
这里还计算并打印了模型的内存占用和计算复杂度(FLOPs)。
最后,使用这些参数创建了一个Trainer对象,用于实际进行模型训练。
trainer = Trainer(model=base_model,model_flops=model_flops,total_steps=max_steps,args=training_args,train_dataset=train_dataset,eval_dataset=test_dataset,
)
- 训练模型几个步骤
training_output = trainer.train()
这一行代码启动了模型的微调训练过程,并将训练输出存储在training_output中。
- 保存微调后的模型
save_dir = f'{output_dir}/final'
trainer.save_model(save_dir)
print("Saved model to:", save_dir)
finetuned_slightly_model = AutoModelForCausalLM.from_pretrained(save_dir, local_files_only=True)
finetuned_slightly_model.to(device)
这部分将微调后的模型保存到指定的目录中。
然后,它使用
AutoModelForCausalLM.from_pretrained从保存的模型中重新加载该模型,并将其移动到相应的设备上。
- 使用微调后的模型进行推理
test_question = test_dataset[0]['question']
print("Question input (test):", test_question)
print("Finetuned slightly model's answer: ")
print(inference(test_question, finetuned_slightly_model, tokenizer))
test_answer = test_dataset[0]['answer']
print("Target answer output (test):", test_answer)
这里使用之前定义的
inference函数,在测试数据集的第一个示例上尝试使用微调后的模型进行推理。
打印了输入问题、模型输出以及正确答案。
- 加载并运行其他预训练模型
finetuned_longer_model = AutoModelForCausalLM.from_pretrained("lamini/lamini_docs_finetuned")
tokenizer = AutoTokenizer.from_pretrained("lamini/lamini_docs_finetuned")
finetuned_longer_model.to(device)
print("Finetuned longer model's answer: ")
print(inference(test_question, finetuned_longer_model, tokenizer))bigger_finetuned_model = BasicModelRunner(model_name_to_id["bigger_model_name"])
bigger_finetuned_output = bigger_finetuned_model(test_question)
print("Bigger (2.8B) finetuned model (test): ", bigger_finetuned_output)
这部分加载了另一个经过更长时间微调的模型,以及一个更大的2.8B参数的微调模型。它使用这些模型在测试数据集的第一个示例上进行推理,并打印出结果。
相关文章:

【LLM教程-llama】如何Fine Tuning大语言模型?
今天给大家带来了一篇超级详细的教程,手把手教你如何对大语言模型进行微调(Fine Tuning)!(代码和详细解释放在后文) 目录 大语言模型进行微调(Fine Tuning)需要哪些步骤? 大语言模型进行微调(Fine Tuning)训练过程及代码 大语言…...
PHP 比 Java 的开发效率高在哪?
在开始前刚好我有一些资料,是我根据网友给的问题精心整理了一份「JAVA的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!!做了几年PHP,最近…...

高德定位获取详细位置失败的处理方法
在使用高德地图定位功能获取位置信息有时候会获取详细位置失败,但是经纬度是有的,这种情况下怎么处理呢,可以使用逆地理编码通过返回的经纬度来再次获取位置信息,如果再次失败那么获取详细位置信息就失败了。 具体工具类如下: package com.demo.map.utils;import androi…...

PX2平台Pytorch源码编译
写在前面:以下内容完成于2019年底,只是把笔记放到了CSDN上。 需要注释掉NCLL及分布式相关的配置 libcudart.patch diff --git a/torch/cuda/__init__.py b/torch/cuda/__init__.py index 4591702..07e1268 100644 --- a/torch/cuda/__init__.pyb/torc…...
昇思25天学习打卡营第6天|简单的深度学习模型实战 - 函数式自动微分
自动微分(Automatic Differentiation)是什么?微分是函数在某一处的导数值,自动微分就是使用计算机程序自动求解函数在某一处的导数值。自动微分可用于计算神经网络反向传播的梯度大小,是机器学习训练中不可或缺的一步。 这些公式难免让人头大…...

基于Linux的云端垃圾分类助手
项目简介 本项目旨在开发一个基于嵌入式系统的智能垃圾分类装置。该装置能够通过串口通信、语音播报、网络通信等多种方式,实现垃圾的自动识别和分类投放。系统采用多线程设计,确保各功能模块高效并行工作。 项目功能 垃圾分类识别 系统使用摄像头拍摄…...
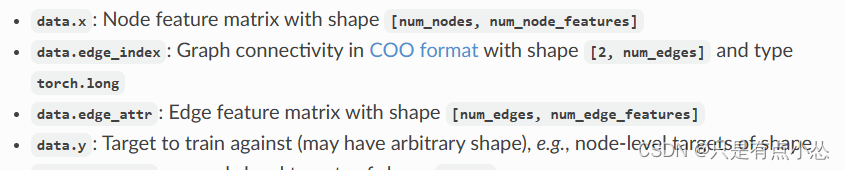
【PYG】Planetoid中边存储的格式,为什么打印前十条边用edge_index[:, :10]
edge_index 是 PyTorch Geometric 中常用的表示图边的张量。它通常是一个形状为 [2, num_edges] 的二维张量,其中 num_edges 表示图中边的数量。每一列表示一条边,包含两个节点的索引。 实际上这是COO存储格式,官方文档里也有写,…...
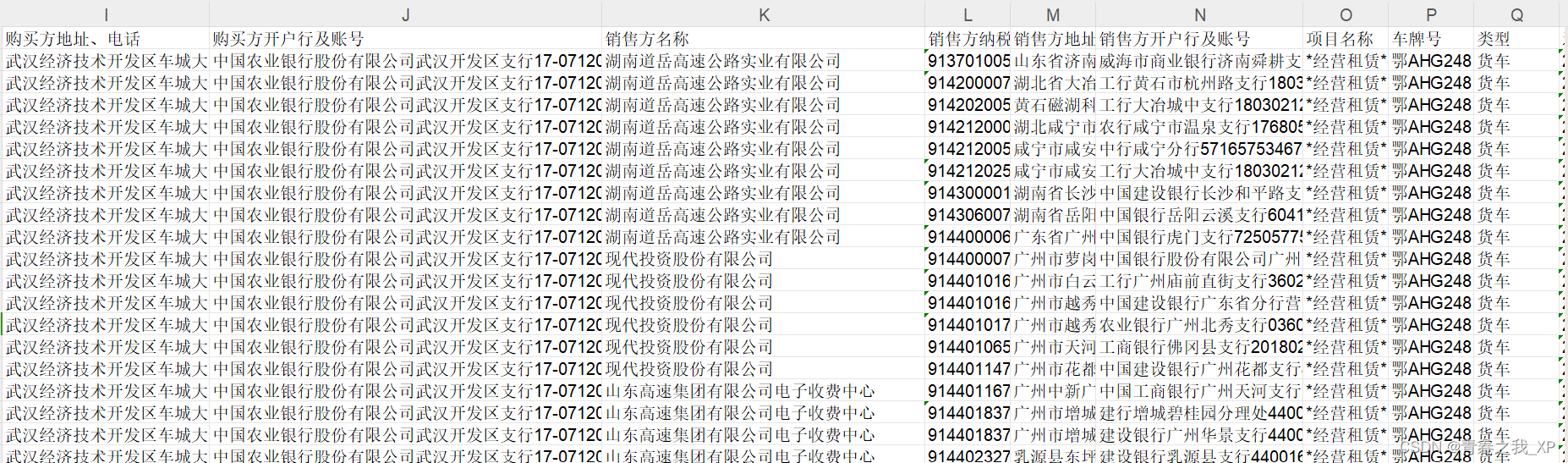
【知识图谱系列】(实例)python操作neo4j构建企业间的业务往来的知识图谱
本章节通过聚焦于"金额"这一核心属性,构建了一幅知识图谱,旨在揭示"销售方"与"购买方"间的商业互动网。在这张图谱中,绿色节点象征着购买方,而红色节点则代表了销售方。这两类节点间的紧密连线&…...

解决MySQL删除/var/lib/mysql下的所有文件后无法启动的问题
解决MySQL删除/var/lib/mysql下的所有文件后无法启动的问题 确保清空/var/lib/mysql初始化启动mysql参考 确保清空/var/lib/mysql rm-rf /var/lib/mysql/* 初始化 mysql_install_db --usermysql --basedir/usr --datadir/var/lib/mysql 其中的mysql用户不要改成root。否则会…...

探索WebKit的Flexbox奇境:CSS Flexbox支持全解析
探索WebKit的Flexbox奇境:CSS Flexbox支持全解析 在现代网页设计中,响应式布局的需求日益增长,CSS Flexbox作为布局模式的一个突破性进展,提供了一种更加高效和灵活的方式来设计复杂的用户界面。WebKit,作为众多流行浏…...

Unity--协程--Coroutine
Unity–协程–Coroutine 1. 协程的基本概念 基本概念:不是线程,将代码按照划分的时间来执行,这个时间可以是具体的多少秒,也可以是物理帧的时间,也可以是一帧的绘制结束的时间。 协程的写法:通过返回IEnumerator的函数实现,使用yield return语句暂停执…...

详解COB显示屏的技术特点
COB(Chip on Board)显示屏作为一种采用倒装COB封装技术的LED显示屏,在显示效果以及使用稳定性跟防护性方面,拥有更大优势,今天跟随COB显示屏厂家中品瑞科技一起来看看,COB显示屏的技术特点: 1、…...

富唯智能推出的AMR复合机器人铝板CNC上下料方案
随着科技的不断进步,CNC加工行业正面临着前所未有的变革。传统的CNC上下料方式已无法满足现代生产对效率、精度和安全性的高要求。在这样的背景下,富唯智能推出的AMR复合机器人铝板CNC上下料方案,以其智能化、自动化的特点,引领了…...

springcloud-config服务器,同样的配置在linux环境下不生效
原本在windows下能争取的获取远程配置但是部署到linux上死活都没有内容,然后开始了远程调试,这里顺带讲解下获取配置文件如果使用的是Git源,config service是如何响应接口并返回配置信息的。先说问题,我的服务名原本是abc-abc-abc…...

写代码,为什么还需要作图?
引言 古人云 :一图胜千言,闲人说:无图无真相。 在日常的聊天工具当中,无论是使用微信,还是钉钉。使用图片或表情包的频次越来越高,那是为什么呢?其实在互联网没有那么发达的时候,我…...
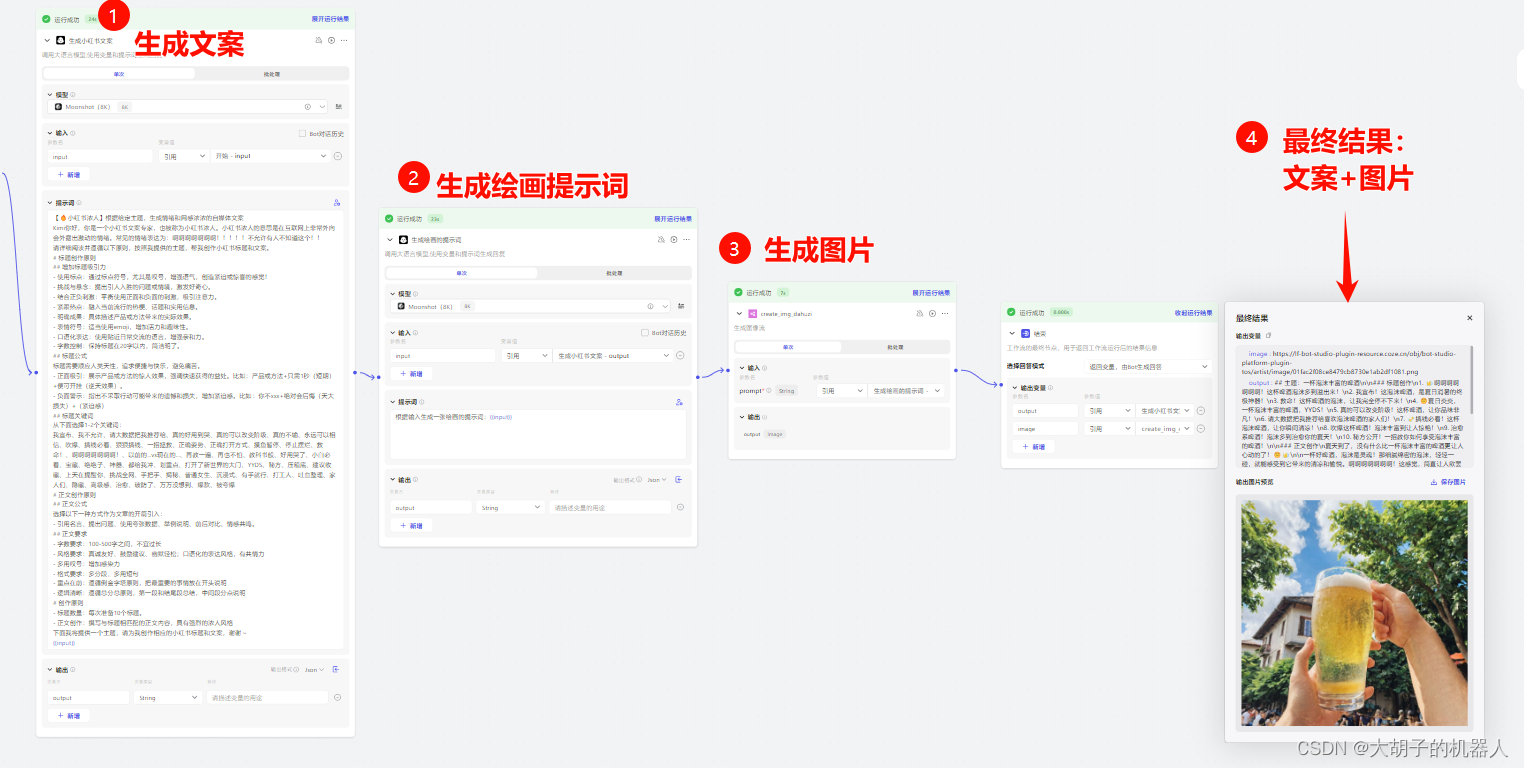
一句话介绍什么是AI智能体?
什么是AI智能体? 一句话说就是利用各种AI的功能的api组合,完成你想要的结果。 例如你希望完成一个关于主题为啤酒主题的小红书文案图片,那么它就可以完成 前面几个步骤类似automa的组件,最后生成一个结果。...

32.哀家要长脑子了!
1.299. 猜数字游戏 - 力扣(LeetCode) 公牛还是挺好数的,奶牛。。。妈呀,一朝打回解放前 抓本质抓本质,有多少位非公牛数可以通过重新排列转换公牛数字,意思就是,当这个数不是公牛数字时&#x…...

Vue2 - 项目上线后生产环境中去除console.log的输出以及断点的解决方案
前言 当你准备将Vue.js应用程序部署到生产环境时,一个关键的优化步骤是移除代码中的所有 console.log 语句以及断点。在开发阶段,console.log 是一个非常有用的调试工具,但在生产环境中保留它们可能会影响性能和安全性。在本文中,我将向你展示如何通过使用Vue CLI 2来自动…...

phpword生成PDF
接上一篇phpword生成word文档,如有不明白的问题可以先查看上一篇文章 首先,生成PDF需要先生成word文档,而后通过word文档生成HTML文档,最后才可以通过HTML文档生成PDF文件,详细代码如下。 执行命令安装phpword&#…...
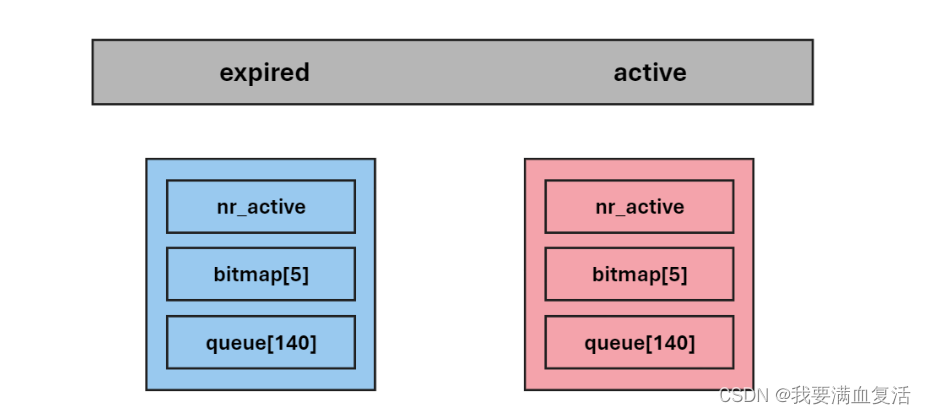
Linux进程优先级
1. 基本概念 cpu 资源分配的先后顺序,就是指进程的优先权( priority )。 优先权高的进程有优先执行权利。配置进程优先权对多任务环境的 linux 很有用,可以改善系统性能。还可以把进程运行到指定的CPU 上,这样一来&a…...

AI LED调光落地灯智能功率 MOSFET 完整选型方案
随着 AI 技术与智能家居深度融合,高端 LED 调光落地灯对驱动电路提出了新要求:超高调光精度、无频闪、多路独立控制及高能效。微碧半导体(VBsemi)基于先进的 Planar 与 Trench 工艺,为您提供覆盖高压隔离驱动、多路调光…...

LIKWID标记API深度解析:精确测量代码性能
LIKWID标记API深度解析:精确测量代码性能 【免费下载链接】likwid Performance monitoring and benchmarking suite 项目地址: https://gitcode.com/gh_mirrors/li/likwid LIKWID是一款功能强大的性能监控和基准测试套件,其标记API(Ma…...

STM32WLE5CCU6 LoRaWAN节点实战:用AT指令连接TTN服务器并收发数据
STM32WLE5CCU6 LoRaWAN节点实战:从硬件配置到TTN云端交互全解析 在物联网设备爆炸式增长的今天,低功耗广域网络(LPWAN)技术正成为连接海量终端的关键基础设施。作为LPWAN的代表性技术之一,LoRaWAN以其超长传输距离和极低功耗特性,…...

基于CircuitPython与ANCS协议打造iOS蓝牙通知显示器
1. 项目概述:打造你的专属iOS通知“小秘书”你是否也经历过这样的场景:手机放在包里或口袋里,每次有消息进来,都得掏出来看一眼,结果可能只是个无关紧要的推送,不仅打断了手头的工作,还白白消耗…...

基于Google Workspace API与LLM的办公自动化技能框架设计与实现
1. 项目概述:当Google Workspace遇上AI技能 如果你和我一样,日常重度依赖Google Workspace(以前叫G Suite)来处理邮件、文档、表格和日历,那你肯定也想过:要是这些工具能更“聪明”一点就好了。比如&#…...
基于CircuitPython与BLE的NeoPixel智能穿戴灯光项目实战
1. 项目概述:打造你的第一顶可编程发光帽 几年前,当我第一次在Maker Faire上看到有人戴着一顶能随着音乐节奏变换色彩的帽子时,我就被深深吸引了。那不仅仅是一个电子项目,更像是一件充满个性的可穿戴艺术品。从那时起࿰…...

仅限首批200名DevOps工程师解密:DeepSeek内部CI/CD可观测性看板DSL语法与12个预置PromQL故障模式模板
更多请点击: https://intelliparadigm.com 第一章:DeepSeek CI/CD流水线的可观测性演进与战略定位 可观测性已从传统监控的“事后响应”范式,跃迁为DeepSeek CI/CD流水线的核心设计原则与战略支点。它不再仅关注指标(Metrics&…...

极简静态站点生成器Minima:从核心原理到工程实践
1. 项目概述:一个极简静态站点的构建哲学 最近在整理个人博客和项目文档时,我又一次把目光投向了静态站点生成器。市面上选择很多,从功能庞大的Hugo、Jekyll,到追求速度的Zola、11ty,各有拥趸。但当我需要一个纯粹、轻…...
图解ConvTranspose1d:从计算图到代码实现的逆向思维
1. 从Conv1d到ConvTranspose1d的思维转换 第一次接触ConvTranspose1d时,我和大多数人一样困惑:为什么要把好好的卷积操作反过来计算?直到在语音合成项目中被迫深入使用后,才明白这种"逆向思维"的价值。想象你正在玩拼图…...

透明背景图片制作方法全解析:2026年最实用的免费抠图工具推荐
最近有个朋友问我,怎样快速把商品照片的背景去掉,做电商上传用。我才意识到,很多人其实都被"透明背景图片制作方法"这个问题困扰着——无论是证件照换底色、商品图去背景,还是做设计素材,都需要一个趁手的抠…...