[吃瓜教程]南瓜书第4章决策树
1.决策树的算法原理
- 从逻辑角度,条件判断语句的组合;
- 从几何角度,根据某种准则划分特征空间;
是一种分治的思想,其最终目的是将样本约分约纯,而划分的核心是在条件的选择或者说是**特征空间的划分标准 **
2.信息熵
1)自信息:
I ( X ) = − l o g b p ( x ) I(X)=-log_bp(x) I(X)=−logbp(x)
当b=2时单位为bit,当b=e时单位为nat
2)信息熵(自信息的期望): 度量随机变量X的不确定性,信息熵越大越不确定
H ( X ) = E [ I ( X ) ] = − ∑ x p ( x ) l o g b p ( x ) H(X)=E[I(X)]=-\sum_xp(x)log_bp(x) H(X)=E[I(X)]=−x∑p(x)logbp(x)
信息熵计算时约定:若p(x)=0,则 p ( x ) l o g b p ( x ) = 0 p(x)log_bp(x)=0 p(x)logbp(x)=0.当X的某个取值的概率为1时信息熵最小,值为0,当X的各个取值的概率均等时信息熵最大,最不缺定,其值为 l o g b ∣ X ∣ log_b|X| logb∣X∣,其中 ∣ X ∣ |X| ∣X∣表示X可能的取值个数。这里可以想象一个例子,一个正常的筛子,它的信息熵最大,而特制的六面都是六的筛子,因为值确定了,所以信息熵最小。
这里的信息熵的最大值的简单的做个推导,在随机变量X的各个取值的概率均等的情况下:
− ∑ x p ( x ) l o g b p ( x ) − − − − − − − − − − − = − p ( x ) l o g b p ∣ X ∣ ( x ) − − − − − − − − − − − = − 1 ∣ X ∣ l o g b ∣ X ∣ − ∣ X ∣ − − − − − − − − − − − = l o g b ∣ X ∣ -\sum_xp(x)log_bp(x)\newline -----------\newline =-p(x)log_bp^{|X|}(x)\newline -----------\newline =-\frac{1}{|X|}log_b|X|^{-|X|}\newline -----------\newline =log_b|X| −x∑p(x)logbp(x)−−−−−−−−−−−=−p(x)logbp∣X∣(x)−−−−−−−−−−−=−∣X∣1logb∣X∣−∣X∣−−−−−−−−−−−=logb∣X∣
将样本类别标记y视作随机变量,各个类别在样本集合D中的占比 p k ( k = 1 , 2 , . . . , ∣ y ∣ ) p_k(k=1,2,...,|y|) pk(k=1,2,...,∣y∣)视作各个类别取值的概率,则样本集合D(随机变量y)的信息熵(底数取为2)为
E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k Ent(D)=-\sum^{|y|}_{k=1}p_klog_2p_k Ent(D)=−k=1∑∣y∣pklog2pk
此时的信息熵所代表的不确定性可以转换理解为集合内样本的纯度。理解一下,我们希望我们划分出来的空间内的样本的y的概率越大越好,这样我们就把各个y的不同值划分的很好了,这就对应了信息熵中的期望信息熵最小的情况,因此可以用信息熵来表示集合内样本的纯度,信息熵越小样本的纯度越高。
3)条件熵:
Y的信息熵关于概率分布X的期望,在已知X后Y的不确定性
H ( Y ∣ X ) = ∑ x p ( x ) H ( Y ∣ X = x ) H(Y|X)=\sum_xp(x)H(Y|X=x) H(Y∣X)=x∑p(x)H(Y∣X=x)
从单个属性(特征)a的角度来看,假设其可能取值为 a 1 , a 2 , . . . , a V {a^1,a^2,...,a^V} a1,a2,...,aV, D v D^v Dv表示属性a取值为 a v ∈ a 1 , a 2 , . . . , a V a^v\in{a^1,a^2,...,a^V} av∈a1,a2,...,aV的样本集合, ∣ D v ∣ ∣ D ∣ \frac{|D^v|}{|D|} ∣D∣∣Dv∣表示占比,那么在已知属性a的取值后,样本集合D的条件熵为
∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) \sum^V_{v=1}\frac{|D^v|}{|D|}Ent(D^v) v=1∑V∣D∣∣Dv∣Ent(Dv)
这里上下两部分的关系,其实下面的部分再更加具体的解释上面的式子。这里第二部分假设X是只有一个维度,也就是特征a,而随机变量X的取值,这里就是a的具体的取值会影响到Y的信息熵,也就是说, D v D \frac{D^v}{D} DDv就是 p ( x ) p(x) p(x),而 H ( Y ∣ X = x ) H(Y|X=x) H(Y∣X=x)就是 E n t ( D v ) Ent(D^v) Ent(Dv)。这样可能好理解一点?
4)信息增益
在已知属性(特征)a的取值后y的不确定性减少的量,也即纯度的提升:
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 D ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a)=Ent(D)-\sum_{v=1}^D\frac{|D^v|}{|D|}Ent(D^v) Gain(D,a)=Ent(D)−v=1∑D∣D∣∣Dv∣Ent(Dv)
3.决策树
3.1ID3决策树
以信息增益为准则来选择划分属性的决策树
a ∗ = arg max a ∈ A G a i n ( D , a ) a_*=\argmax_{a\in A} Gain(D,a) a∗=a∈AargmaxGain(D,a)
ID3的问题:使用信息增益准则对可能取值数目较多的属性 有所偏好
代码:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt# 加载西瓜数据集
data = {"编号": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],"色泽": ["青绿", "乌黑", "乌黑", "青绿", "浅白", "青绿", "乌黑", "浅白", "青绿", "浅白", "乌黑", "浅白", "青绿"],"根蒂": ["蜷缩", "蜷缩", "蜷缩", "蜷缩", "蜷缩", "稍蜷", "稍蜷", "稍蜷", "硬挺", "硬挺", "硬挺", "蜷缩", "蜷缩"],"敲声": ["浊响", "沉闷", "浊响", "沉闷", "浊响", "浊响", "浊响", "浊响", "清脆", "清脆", "清脆", "浊响", "浊响"],"纹理": ["清晰", "清晰", "清晰", "清晰", "清晰", "稍糊", "稍糊", "稍糊", "清晰", "清晰", "稍糊", "模糊", "稍糊"],"脐部": ["凹陷", "凹陷", "凹陷", "凹陷", "凹陷", "稍凹", "稍凹", "稍凹", "平坦", "平坦", "平坦", "稍凹", "稍凹"],"触感": ["硬滑", "硬滑", "硬滑", "硬滑", "硬滑", "软粘", "硬滑", "硬滑", "软粘", "硬滑", "硬滑", "硬滑", "硬滑"],"好瓜": ["是", "是", "是", "是", "否", "否", "否", "否", "否", "否", "否", "否", "否"]
}# 转换为DataFrame
df = pd.DataFrame(data)# 将'好瓜'列转换为二进制值
df['好瓜'] = df['好瓜'].map({'是': 1, '否': 0})# 特征和目标变量
features = df.drop(['编号', '好瓜'], axis=1)
target = df['好瓜']# 使用get_dummies进行one-hot编码
features_encoded = pd.get_dummies(features)# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features_encoded, target, test_size=0.3, random_state=42)# 初始化决策树分类器(使用ID3算法)
clf = DecisionTreeClassifier(criterion='entropy', random_state=42)# 训练模型
clf.fit(X_train, y_train)# 预测测试集
y_pred = clf.predict(X_test)# 计算准确率
accuracy = clf.score(X_test, y_test)
print(f'模型的准确率是: {accuracy*100:.2f}%')# 可视化决策树
plt.figure(figsize=(20,10))
tree.plot_tree(clf, filled=True, feature_names=features_encoded.columns, class_names=['否', '是'])
plt.show()# 存储决策树模型
import joblib
joblib.dump(clf, 'decision_tree_model.pkl')# 加载模型并进行预测(示例)
loaded_model = joblib.load('decision_tree_model.pkl')
sample_data = X_test.iloc[0].values.reshape(1, -1)
prediction = loaded_model.predict(sample_data)
print(f'预测结果: {"是" if prediction[0] == 1 else "否"}')
可视化决策树:
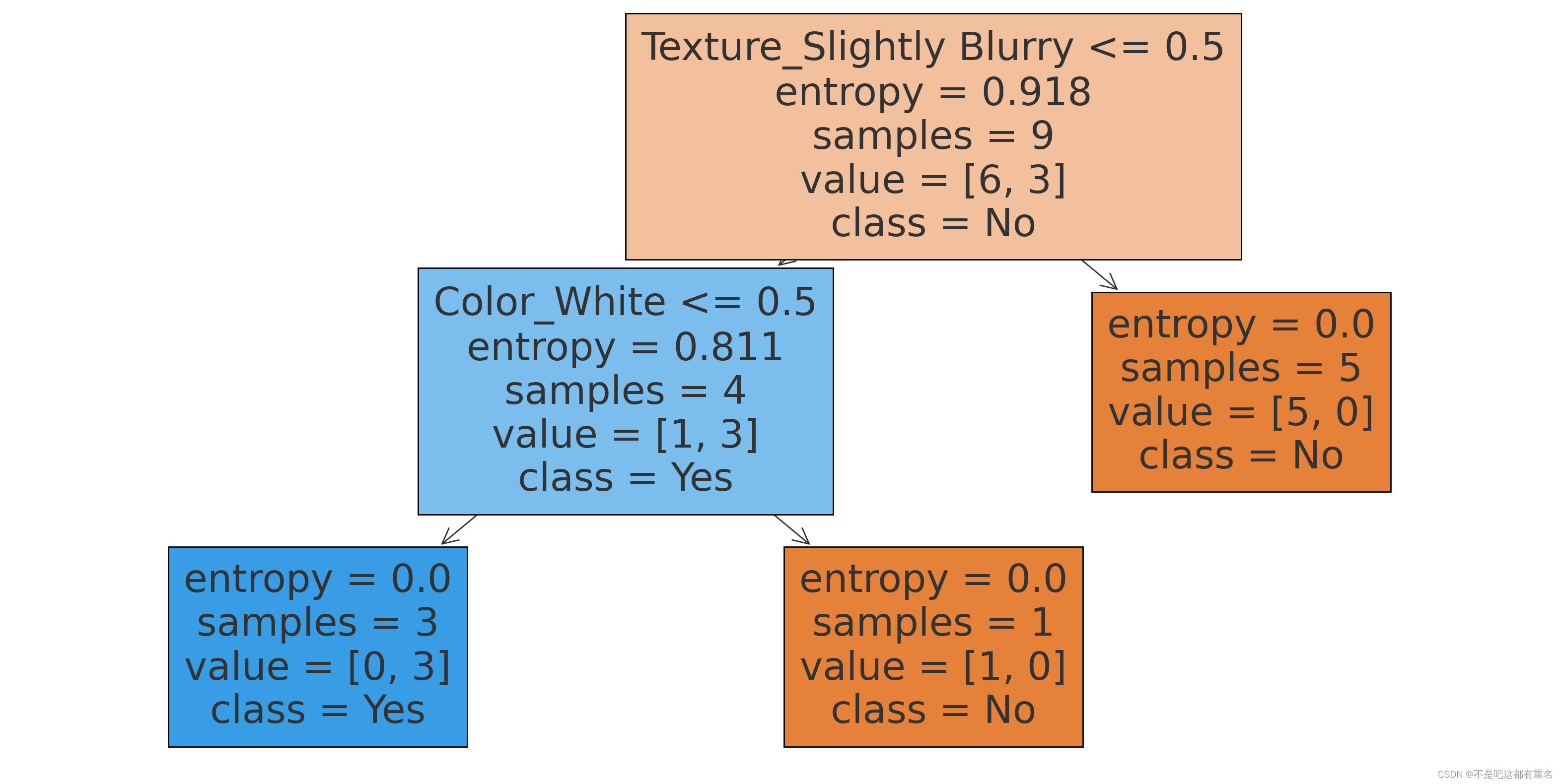
3.2 C4.5决策树
为了解决ID3的问题,C4.5使用增益率代替信息增益,增益率的定义如下:
G a i n r a t e ( D , a ) = G a i n ( D , a ) I V ( a ) Gain_rate(D,a)=\frac{Gain(D,a)}{IV(a)} Gainrate(D,a)=IV(a)Gain(D,a)
其中,
I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ l o g 2 ∣ D v ∣ ∣ D ∣ IV(a)=-\sum_{v=1}^V\frac{|D^v|}{|D|}log_2\frac{|D^v|}{|D|} IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
称为属性a的固有值,a的可能取值个数V越大,通常其固有值也越大。
C4.5的问题: 增益率对可能取值数目较少的属性有所偏好
因此,C4.5采用启发式方法:先选出信息增益高于平均水平的属性,然后再从中选择增益率最高的。
代码:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt# 创建西瓜数据集
data = {"Number": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],"Color": ["Green", "Black", "Black", "Green", "White", "Green", "Black", "White", "Green", "White", "Black", "White", "Green"],"Root": ["Curled", "Curled", "Curled", "Curled", "Curled", "Slightly Curled", "Slightly Curled", "Slightly Curled", "Stiff", "Stiff", "Stiff", "Curled", "Curled"],"Knock": ["Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Clear", "Clear", "Clear", "Dull", "Dull"],"Texture": ["Clear", "Clear", "Clear", "Clear", "Clear", "Slightly Blurry", "Slightly Blurry", "Slightly Blurry", "Clear", "Clear", "Slightly Blurry", "Blurry", "Slightly Blurry"],"Navel": ["Indented", "Indented", "Indented", "Indented", "Indented", "Slightly Indented", "Slightly Indented", "Slightly Indented", "Flat", "Flat", "Flat", "Slightly Indented", "Slightly Indented"],"Touch": ["Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Soft and Sticky", "Hard and Smooth", "Hard and Smooth", "Soft and Sticky", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth"],"Good": ["Yes", "Yes", "Yes", "Yes", "No", "No", "No", "No", "No", "No", "No", "No", "No"]
}# 转换为DataFrame
df = pd.DataFrame(data)# 将'Good'列转换为二进制值
df['Good'] = df['Good'].map({'Yes': 1, 'No': 0})# 特征和目标变量
features = df.drop(['Number', 'Good'], axis=1)
target = df['Good']# 使用get_dummies进行one-hot编码
features_encoded = pd.get_dummies(features)# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features_encoded, target, test_size=0.3, random_state=42)# 初始化决策树分类器(使用C4.5算法,即使用信息增益比)
clf = DecisionTreeClassifier(criterion='entropy', random_state=42, splitter='best')# 训练模型
clf.fit(X_train, y_train)# 可视化决策树
plt.figure(figsize=(20,10))
tree_plot = tree.plot_tree(clf, filled=True, feature_names=features_encoded.columns, class_names=['No', 'Yes'])
plt.show()可视化决策树:
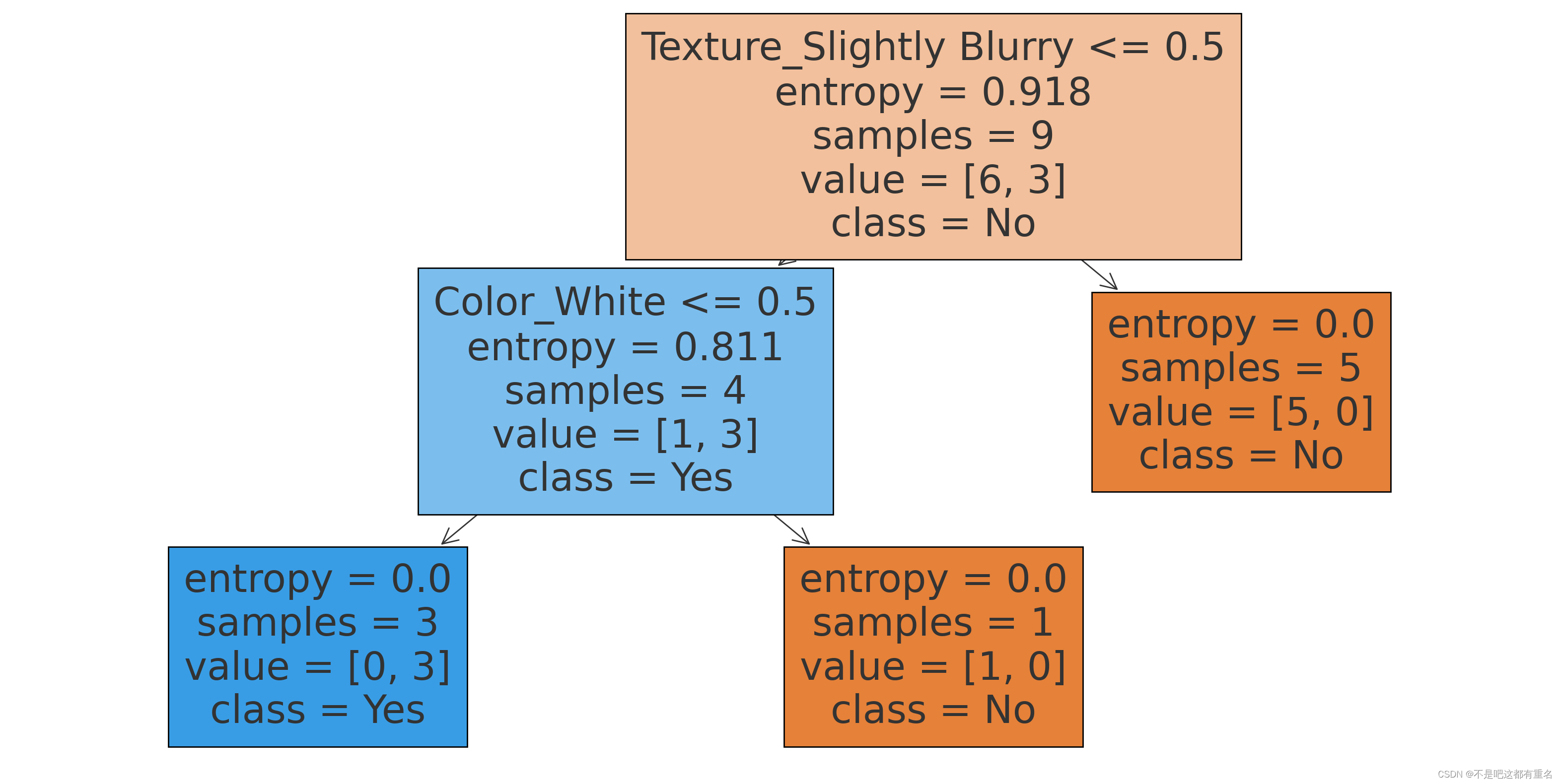
3.3CART决策树
基尼值: 从样本集合D中随机抽取两个样本,其类别标记不一致的概率。因此,基尼值越小,碰到异类的概率就越小,纯度自然越高。(对应信息熵)
G i n i ( D ) = ∑ k = 1 ∣ y ∣ ∑ k ′ ≠ k p k p k ′ = ∑ k = 1 ∣ y ∣ p k ( 1 − p k ) = 1 − ∑ k = 1 ∣ y ∣ p k 2 Gini(D)=\sum_{k=1}^{|y|}\sum_{k'\neq k}p_kp_{k'}=\sum_{k=1}^{|y|}p_k(1-p_k)=1-\sum^{|y|}_{k=1}p_k^2 Gini(D)=k=1∑∣y∣k′=k∑pkpk′=k=1∑∣y∣pk(1−pk)=1−k=1∑∣y∣pk2
基尼指数: 属性a的基尼指数(对应条件熵):
G i n i i n d e x ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ G i n i ( D v ) Gini_index(D,a)=\sum_{v=1}^V\frac{|D^v|}{|D|}Gini(D^v) Giniindex(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
CART决策树: 选择基尼指数最小的属性作为最优划分属性,最后构造了一个二叉树。
a ∗ = arg max a ∈ A G i n i _ i n d e x ( D , a ) a_*=\argmax_{a\in A} Gini\_index(D,a) a∗=a∈AargmaxGini_index(D,a)
CART决策树的实际构造算法如下:
- 对每个属性a的每个可能取值v,将数据集D分为a=v和a≠v两部分计算基尼指数,即
G i n i i n d e x ( D , a ) = ∣ D a = v ∣ ∣ D ∣ G i n i ( D a = v ) + ∣ D a ≠ v ∣ ∣ D ∣ G i n i ( D a ≠ v ) Gini_index(D,a)=\frac{|D^{a=v}|}{|D|}Gini(D^{a=v})+\frac{|D^{a\neq v}|}{|D|}Gini(D^{a\neq v}) Giniindex(D,a)=∣D∣∣Da=v∣Gini(Da=v)+∣D∣∣Da=v∣Gini(Da=v) - 选择基尼指数最小的属性及其对应取值作为最优划分属性和最优划分点;
- 重复上述步骤,直至满足停止条件
代码:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt# 创建西瓜数据集
data = {"Number": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],"Color": ["Green", "Black", "Black", "Green", "White", "Green", "Black", "White", "Green", "White", "Black", "White", "Green"],"Root": ["Curled", "Curled", "Curled", "Curled", "Curled", "Slightly Curled", "Slightly Curled", "Slightly Curled", "Stiff", "Stiff", "Stiff", "Curled", "Curled"],"Knock": ["Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Clear", "Clear", "Clear", "Dull", "Dull"],"Texture": ["Clear", "Clear", "Clear", "Clear", "Clear", "Slightly Blurry", "Slightly Blurry", "Slightly Blurry", "Clear", "Clear", "Slightly Blurry", "Blurry", "Slightly Blurry"],"Navel": ["Indented", "Indented", "Indented", "Indented", "Indented", "Slightly Indented", "Slightly Indented", "Slightly Indented", "Flat", "Flat", "Flat", "Slightly Indented", "Slightly Indented"],"Touch": ["Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Soft and Sticky", "Hard and Smooth", "Hard and Smooth", "Soft and Sticky", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth"],"Good": ["Yes", "Yes", "Yes", "Yes", "No", "No", "No", "No", "No", "No", "No", "No", "No"]
}# 转换为DataFrame
df = pd.DataFrame(data)# 将'Good'列转换为二进制值
df['Good'] = df['Good'].map({'Yes': 1, 'No': 0})# 特征和目标变量
features = df.drop(['Number', 'Good'], axis=1)
target = df['Good']# 使用get_dummies进行one-hot编码
features_encoded = pd.get_dummies(features)# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features_encoded, target, test_size=0.3, random_state=42)# 初始化决策树分类器(使用CART算法,即使用Gini系数)
clf_cart = DecisionTreeClassifier(criterion='gini', random_state=42)# 训练模型
clf_cart.fit(X_train, y_train)# 预测测试集
y_pred_cart = clf_cart.predict(X_test)# 计算准确率
accuracy_cart = clf_cart.score(X_test, y_test)
print(f'模型的准确率是: {accuracy_cart*100:.2f}%')# 可视化决策树
plt.figure(figsize=(20,10))
tree_plot_cart = tree.plot_tree(clf_cart, filled=True, feature_names=features_encoded.columns, class_names=['No', 'Yes'])
plt.show()可视化决策树:

相关文章:
[吃瓜教程]南瓜书第4章决策树
1.决策树的算法原理 从逻辑角度,条件判断语句的组合;从几何角度,根据某种准则划分特征空间; 是一种分治的思想,其最终目的是将样本约分约纯,而划分的核心是在条件的选择或者说是**特征空间的划分标准 ** …...

Redis 面试题完整指南:深度解析基础、进阶与高级功能
基础知识 1. 什么是Redis? Redis(Remote Dictionary Server)是一个开源的、基于内存的数据结构存储系统,既可以用作数据库、缓存,也可以用作消息中间件。它支持多种数据结构,如字符串、哈希、列表、集合、…...

spring 枚举、策略模式、InitializingBean初使化组合使用示例
实现一个简单的文本处理系统。 在这个系统中,我们将定义不同类型的文本处理策略,比如大小写转换、添加前缀后缀等,并使用工厂模式来管理这些策略。 1 定义一个枚举来标识不同的文本处理类型 public enum TextProcessTypeEnum {UPPER_CASE,LO…...

嵌入式学习——硬件(IIC、ADC)——day56
1. IIC 1.1 定义(同步串行半双工通信总线) IIC(Inter-Integrated Circuit)又称I2C,是是IICBus简称,所以中文应该叫集成电路总线。是飞利浦公司在1980年代为了让主板、嵌入式系统或手机用以连接低速周边设备…...

vCenter VXR01405C ALARM Certificate is about to expire
vCenter VXR01405C ALARM Certificate is about to expire 需要更新证书 步骤如下 ===vCenter=== root@vc [ ~ ]# for i in $(/usr/lib/vmware-vmafd/bin/vecs-cli store list); do echo STORE $i; sudo /usr/lib/vmware-vmafd/b STORE MACHINE_SSL_CERT Alias : __MACHINE…...
安装和微调大模型(基于LLaMA-Factory)
打开终端(在Unix或macOS上)或命令提示符/Anaconda Prompt(在Windows上)。 创建一个名为lora的虚拟环境并指定Python版本为3.9。 https://github.com/echonoshy/cgft-llm/blob/master/llama-factory/README.mdGitHub - hiyouga/…...

使用docker搭建squid和ss5
docker run -d --name squid-container -e TZAsia/Shanghai -p 自定义端口并记得开放:3128 ubuntu/squid docker exec -it squid-container /bin/bash apt update && apt install vim # 修改 http_port 3128 为 http_port 0.0.0.0:3128 # 修改 http_access deny all 为…...
)
大数据面试题之Flink(1)
目录 Flink架构 Flink的窗口了解哪些,都有什么区别,有哪几种?如何定义? Flink窗口函数,时间语义相关的问题 介绍下Flink的watermark(水位线),watermark需要实现哪个实现类,在何处定义?有什么作用? Flink的…...

策略模式、工厂模式和模板模式的应用
1、策略模式、工厂模式解决if else Cal package com.example.dyc.cal;import org.springframework.beans.factory.InitializingBean;public interface Cal extends InitializingBean {public Integer cal(Integer a, Integer b); }Cal工厂 package com.example.dyc.cal;impo…...
在postman中调试supabase的API接口
文章目录 在supabase中获取API地址和key知道它的restfull风格在postman中进行的设置1、get请求调试2、post新增用户调试3、使用patch更新数据,不用put!4、delete删除数据 总结 在supabase中获取API地址和key 首先登录dashboard后台,首页- 右…...

微信小程序毕业设计-英语互助系统项目开发实战(附源码+论文)
大家好!我是程序猿老A,感谢您阅读本文,欢迎一键三连哦。 💞当前专栏:微信小程序毕业设计 精彩专栏推荐👇🏻👇🏻👇🏻 🎀 Python毕业设计…...
【WEB前端2024】3D智体编程:乔布斯3D纪念馆-第49课-机器人自动跳舞
【WEB前端2024】3D智体编程:乔布斯3D纪念馆-第49课-机器人自动跳舞 使用dtns.network德塔世界(开源的智体世界引擎),策划和设计《乔布斯超大型的开源3D纪念馆》的系列教程。dtns.network是一款主要由JavaScript编写的智体世界引擎…...

【LLM教程-llama】如何Fine Tuning大语言模型?
今天给大家带来了一篇超级详细的教程,手把手教你如何对大语言模型进行微调(Fine Tuning)!(代码和详细解释放在后文) 目录 大语言模型进行微调(Fine Tuning)需要哪些步骤? 大语言模型进行微调(Fine Tuning)训练过程及代码 大语言…...
PHP 比 Java 的开发效率高在哪?
在开始前刚好我有一些资料,是我根据网友给的问题精心整理了一份「JAVA的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!!做了几年PHP,最近…...

高德定位获取详细位置失败的处理方法
在使用高德地图定位功能获取位置信息有时候会获取详细位置失败,但是经纬度是有的,这种情况下怎么处理呢,可以使用逆地理编码通过返回的经纬度来再次获取位置信息,如果再次失败那么获取详细位置信息就失败了。 具体工具类如下: package com.demo.map.utils;import androi…...

PX2平台Pytorch源码编译
写在前面:以下内容完成于2019年底,只是把笔记放到了CSDN上。 需要注释掉NCLL及分布式相关的配置 libcudart.patch diff --git a/torch/cuda/__init__.py b/torch/cuda/__init__.py index 4591702..07e1268 100644 --- a/torch/cuda/__init__.pyb/torc…...
昇思25天学习打卡营第6天|简单的深度学习模型实战 - 函数式自动微分
自动微分(Automatic Differentiation)是什么?微分是函数在某一处的导数值,自动微分就是使用计算机程序自动求解函数在某一处的导数值。自动微分可用于计算神经网络反向传播的梯度大小,是机器学习训练中不可或缺的一步。 这些公式难免让人头大…...

基于Linux的云端垃圾分类助手
项目简介 本项目旨在开发一个基于嵌入式系统的智能垃圾分类装置。该装置能够通过串口通信、语音播报、网络通信等多种方式,实现垃圾的自动识别和分类投放。系统采用多线程设计,确保各功能模块高效并行工作。 项目功能 垃圾分类识别 系统使用摄像头拍摄…...
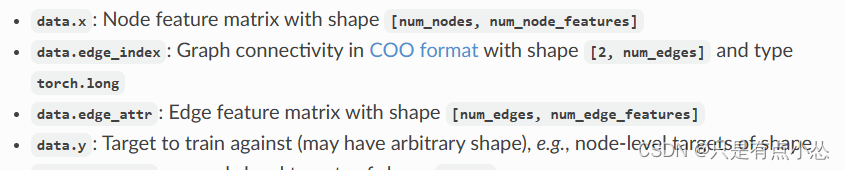
【PYG】Planetoid中边存储的格式,为什么打印前十条边用edge_index[:, :10]
edge_index 是 PyTorch Geometric 中常用的表示图边的张量。它通常是一个形状为 [2, num_edges] 的二维张量,其中 num_edges 表示图中边的数量。每一列表示一条边,包含两个节点的索引。 实际上这是COO存储格式,官方文档里也有写,…...
【知识图谱系列】(实例)python操作neo4j构建企业间的业务往来的知识图谱
本章节通过聚焦于"金额"这一核心属性,构建了一幅知识图谱,旨在揭示"销售方"与"购买方"间的商业互动网。在这张图谱中,绿色节点象征着购买方,而红色节点则代表了销售方。这两类节点间的紧密连线&…...

ThreadLocal原理与内存泄漏防范
前言 在现代软件开发中,ThreadLocal原理与内存泄漏防范是一个非常重要的技术点。本文将从原理到实践,带你深入理解这一技术,并通过完整的代码示例帮助你快速掌握核心知识点。 核心概念 基本原理 ThreadLocal原理与内存泄漏防范的核心在于理解…...

下载视频不如用Via,一分都不花
找了很长时间,没想到竟然这么简单,为啥早没发现呢! 工具的名称叫Via浏览器是个App,没错在安卓手机或平板运行的工具。 缺点:pc下用不了,有些视频下不了,如爱奇艺等。苹果手机是否能用不知道,自己试吧。 优点:操作方便、简单,即使你是小白也能熟练操作。免费,一分…...

DLSS Swapper完整指南:如何5分钟提升游戏性能50%?
DLSS Swapper完整指南:如何5分钟提升游戏性能50%? 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 您是否曾经为游戏卡顿而烦恼?是否在寻找提升帧率的方法却不知从何入手?…...

低成本搭建BLE嗅探器:基于nRF52840与Wireshark的物联网协议分析实战
1. 项目概述与核心价值如果你正在开发或调试基于蓝牙低功耗(BLE)的物联网设备,比如智能手环、传感器节点或者任何通过蓝牙通信的小玩意儿,那么你肯定遇到过这样的困境:设备明明发了数据,手机App却没收到&am…...

高性能缓冲管理中的数组翻译技术解析
1. 高性能缓冲管理中的数组翻译技术解析在现代数据库系统中,缓冲管理器是连接内存与持久化存储的关键组件,其核心任务是将逻辑页ID映射到物理内存帧。传统方案如哈希表或指针交换存在三个根本性缺陷:内存开销随数据集线性增长、并行访问时的锁…...

基于数据科学的宠物性格分析:从行为量化到性格画像的工程实践
1. 项目概述与核心价值最近在逛GitHub的时候,发现了一个挺有意思的项目,叫petsonality。光看名字,你大概就能猜到它和“宠物”(Pets)以及“性格”(Personality)有关。没错,这是一个通…...

UPS 蓄电池在线监控系统是什么?工业 UPS 电源有必要安装吗?
在机房、工业生产、医疗设备等依赖 UPS 不间断电源的场景中,蓄电池往往被视为设备的 “心脏”。很多用户配置了优质 UPS 电源,却忽略了对蓄电池的实时管理,等到突发停电才发现电池亏电、失效,导致 UPS 无法正常供电,引…...

中文文本人性化:从NLP原理到cn-humanizer工程实践
1. 项目概述:为什么我们需要一个中文“人性化”工具?在数字时代,我们与机器生成的文本打交道的机会越来越多。无论是AI助手生成的回复、自动化脚本输出的日志,还是数据清洗后得到的报告,这些文本常常带着一种难以言喻的…...
)
DeepSeek MMLU 86.7分是怎么炼成的?从提示工程、校准策略到知识蒸馏链路(内部训练日志首次公开)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek MMLU 86.7分的里程碑意义与基准解读 MMLU 基准的本质与挑战 MMLU(Massive Multitask Language Understanding)是一项覆盖57个学科领域的综合性评测基准,涵…...

为什么92%的AIGC剪辑师仍在用手动导出?揭秘Sora 2直连Premiere的7大底层优化与3个避坑红线
更多请点击: https://intelliparadigm.com 第一章:Sora 2与Premiere直连整合的行业悖论与破局起点 当OpenAI正式释放Sora 2的API文档并开放有限开发者预览时,Adobe Premiere Pro团队内部立即启动了“Project Lumen”——一项旨在实现双向帧级…...