Elasticsearch (1):ES基本概念和原理简单介绍
Elasticsearch(简称 ES)是一款基于 Apache Lucene 的分布式搜索和分析引擎。随着业务的发展,系统中的数据量不断增长,传统的关系型数据库在处理大量模糊查询时效率低下。因此,ES 作为一种高效、灵活和可扩展的全文检索解决方案,逐渐成为了企业的首选。本篇博客将深入探讨 Elasticsearch 的核心概念、使用方法以及优化技巧。
为什么要使用Elasticsearch?
系统中的数据,随着业务的发展和时间的推移,将会变得非常多,而业务中往往都是采用模糊查询的方式对数据进行搜索,而模糊查询会导致查询引擎放弃索引,导致系统查询数据的时候都是全表扫描,那么在百万级数据库中,这样的查询效率是非常低下的,而我们使用ES做一个全文索引,将经常查询的系统功能某些字段,比如说电商系统中的商品名,描述和价格这些字段放入到ES索引库中,就可以提高查询效率
并且ES具备以下几个优势
1.高性能:ES具有高性能的搜索和分析能力,其中涵盖了多种查询语言和数据结构
2.可拓展性:ES是分布式的,可以通过增加节点数量去拓展搜索和分析能力
3.灵活性:ES支持多种数据类型,支持多种语言,支持动态映射,允许快速地调整模型以适应不同地需求
4.实时分析:ES支持实时分析,可以对数据进行实时查询,这对于快速检索数据非常有用
5.ES具有可靠性和高可用性,它里面会有冗余备份这样一个设置支持数据备份和恢复。
正排索引与倒排索引
正排索引:类似于关系型数据库的存储方式,它按照文档顺序存储信息,便于按照文档查找内容。
倒排索引:适合全文检索,它记录了每个词条在哪些文档中出现。倒排索引由词条、词典和倒排表构成:
- 词条:最小存储和查询单元。
- 词典:词条的集合,通常实现为 B+ 树或哈希表。
- 倒排表:记录词条出现的文档 ID 列表。
倒排索引的设计使得 ES 能够快速定位和检索相关文档,提高查询效率。
早期的全文检索会为整个文档集合建立一个很大的倒排索引并且将其写入到磁盘,一旦新的索引就绪,旧的索引就会被替代,这样最近的变化就可以被检索到,倒排索引被写入到磁盘后是不可变的,它永远不会被修改,而是用更多的索引,通过增加补充索引的方式去反映新近的修改,而不是直接重写整个倒排索引,每一个倒排索引都会被轮流查询到,从最早的开始的查询,然后再进行合并
ES基本概念:
Near Realtime(NRT)
近实时:当我们说一个系统或数据库是近实时的,它意味着从数据被写入到这些数据可以被检索或查询之间有一个很短的延迟。在Elasticsearch中,这个延迟通常非常短,可能只有几毫秒到几秒(通常不超过1秒)。这意味着,当你向Elasticsearch中写入新的数据后,几乎可以立即查询这些数据,而不需要等待很长时间。
Index(索引)
索引库:你可以把索引库想象成一个巨大的文件柜,里面装满了许多不同类别的文件夹。在Elasticsearch中,这些“文件夹”就是索引,而文件夹里的“文件”就是文档(Documents)。每个索引都包含了一类相似的文档,比如所有的客户数据、商品数据或订单数据都可以分别存储在各自的索引中,一个索引就类似于关系型数据库中的一张表。
Type(类型)
类型:在早期的Elasticsearch版本中,每个索引内可以有多个类型,每个类型下的文档都有相同的字段结构。但随着时间的推移,Elasticsearch团队简化l了这个概念,因为多个类型可能会导致一些复杂性和性能问题。因此,在较新的Elasticsearch版本中,每个索引通常只包含一个类型,但出于兼容性考虑,仍然支持多个类型。但在实际应用中,现在更推荐每个索引只包含一种类型的数据。
Document & Field(文档 & 字段)
文档:在Elasticsearch中,文档是最小的数据单元。你可以把文档想象成一张表格的一行或一个数据库记录。每个文档都是一个JSON对象,包含了多个字段(Field)。
字段:字段就是文档中的一个数据项,比如一个文档可能有一个名为“title”的字段,其值为“The quick brown fox...”。你可以把字段想象成数据库表中的列。每个文档可以有不同的字段组合,但通常同一类型的文档会有相似的字段结构。
映射(Mapping)
mapping是对处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值分析器、是否被索引等等。这些都是映射里面可以设置的,其它就是处理ES 里面数据的些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射并且需要思考如何建立映射才能对性能更好。
分片(Shards)
可以理解为mysql中的分表,一个索引中的数据太多了需要进行分片,一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有 10 亿文档数据的索引占据 1TB 的磁盘空间,而任一节点都可能没有这样大的磁盘空间。或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力每一份就称之为分片。当你创建一个索引的时候,你可以指定你想要的分片的数量,。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上面去,分片很重要,主要有两方面的原因:
1.允许你水平分割/扩展你的内容容量
2.允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由 Elasticsearch 管理的,对于作为用户的你来说,这些都是透明的,无需过分关心。
副本
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elastigsearch允许你创建分片的一份或多份拷贝这些拷贝叫做复制分片(副本)。
复制分片之所以重要,有两个主要原因:
1.在分片/节点失败的情况下,提供了高可用性,因为这个原因,注意到复制分片从不与原/主要(origimalprimary)分片置于同一节点上是非常重要的。
2.扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行
路由计算/分片控制

分片控制:用户可以访问任何一个节点获取数据,这个节点称为协调节点 ,一般是轮询
模拟写数据:
用户发送请求给ES,但是用户在请求到达ES前是没办法获取到集群状态的,比如说先到达1002节点,但是1002节点可能会把它分发到其他节点上去
1.客户端请求集群节点(任意节点)——协调节点
2.协调节点把请求分发到指定节点
3.主分片需要将数据保存
4.主分片需要将数据发送给副本
5.副本保存后进行反馈
6.主分片进行反馈
7.客户端获取反馈
注意:主分片会要求在活跃的副本到一定数量的时候才进行写操作,为了避免在网络分区故障的时候进行写操作,导致数据不一致问题。
规定数量:int(primary+number_of_replicas)/2)+1
consistency参数的值可以设为one(只要主分片状态ok就允许执行写操作),或者quorum.默认为quorum,就是大多数的分片副本状态没有问题就允许执行写操作。
number_of_replicas指的是在索引设置中设置的副本分片数量,而不是指当前处理活动状态的副本分片数量
读数据

1.客户端首先会发送一个查询请求到协调节点
2.协调节点会计算数据所在的分片以及全部的副本位置
3.为了可以实现负载均衡,可以轮询所有节点
4.协调节点将请求转发给具体的目标节点
5.节点返回查询结果,将结果反馈给客户端
更新流程
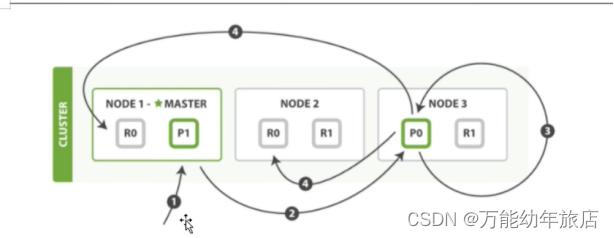
部分更新一个文档的步骤如下:
1.客户端向Node1发送更新请求。
2.将请求转发到主分片所在的Node3
3.Node3从主分片检索文档,修改_source字段中的JSON,并且尝试重新索引主分片的文档。如果文档已经被另外一个线程修改了,就会重试步骤3,超过rety_on_conflict次数后放弃
4.如果Note3成功更新了文档,他将新的版本文档并行转发到Node1和Node2上的副本分配,重新建立索引。一旦所有副本分片都返回成功后,Node3向协调节点也返回成功,协调节点向客户端返回成功。
注意:这里主版本把跟把更改转发到副本分片的时候,不会转发更新请求。相反,他转发的是完整的新版本文档。这些请求会异步的被转发到副本分片,但是不能保证它们按照相同的顺序到达。如果ES采用的是转发更改请求,就有可能会以错误的顺序去把应用更改,导致得到损坏的文档
新增词条
先进入 ES 根目录中的 plugins 文件夹下的ik文件夹,进入 config目录,创建 custom.dic文件,写入新增的词条。同时打开IAnalyzer.cfg.xml 文件,将新建的 custom.dic 配置其中重启 ES 服务器。
自定义分词器

文档冲突
当我们使用IdnexAPI更新文档的时候,可以一次性读取原始文档,去做我们的修改,然后重新索引整个文档,最近的索引请求将会获胜,不管最后哪一个文档被索引了,都会被唯一存储在ES中。如果其他人同时更改这个索引,那么他们的更改将会丢失。
很多时候这是没有问题的,也许我们的主数据存储是一个关系型数据库,我们只是把数据 复制到了ES中让他可以被检索,也许两个人同时更改相同文档的概率很小,或者对于业务来说偶尔丢失更改并不是很严重的问题,但有时候局部更新出错是不能接受的
怎么防止数据更新丢失呢?
悲观锁
这种方法被关系型数据库广泛使用,它认为冲突必然发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
乐观锁
Elasticsearch 中使用的这种方法假定冲突不是必然发生的,并且不会阻塞正在尝试的操作,然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何作。解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
Elasticsearch 是分布式的。当文档创建、更新或删除时, 新版本的文档必须复制到集群中的其他节点。Elasticsearch 也是异步和并发的,这意味着这些复制请求被并行发送,并且到达目的地时也许 顺序是乱的。 Elasticsearch 需要一种方法确保文档的旧版本不会覆盖新的版本。
当我们之前讨论 index ,GET 和 delete 请求时,我们指出每个文档都有一个 version(版本)号,当文档被修改时版本号递增。Elasticsearch 使用这个version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
外部系统版本控制
一个常见的设置是使用其它数据库作为主要的数据存储,使用 Elasticsearch 做数据检索, 这意味着主数据库的所有更改发生时都需要被复制到 Elasticsearch ,如果多个进程负责这一数据同步,你可能遇到类似于之前描述的并发问题。
如果你的主数据库已经有了版本号-或一个能作为版本号的字段值比如 timestamp那么你就可以在 Elasticsearch 中通过增加 version type=extemmal 到查询字符串的方式重用这些相同的版本号, 版本号必须是大于零的整数,且小于 9.2E+18-一个 Java 中 long类型的正值。
相关文章:
Elasticsearch (1):ES基本概念和原理简单介绍
Elasticsearch(简称 ES)是一款基于 Apache Lucene 的分布式搜索和分析引擎。随着业务的发展,系统中的数据量不断增长,传统的关系型数据库在处理大量模糊查询时效率低下。因此,ES 作为一种高效、灵活和可扩展的全文检索…...
【Python爬虫】Python爬取喜马拉雅,爬虫教程!
一、思路设计 (1)分析网页 在喜马拉雅主页找到自己想要的音频,得到目标URL:https://www.ximalaya.com/qinggan/321787/ 通过分析页面的网络抓包,最终的到一个比较有用的json数据包 通过分析,得到了发送json…...

基于Jmeter的分布式压测环境搭建及简单压测实践
写在前面 平时在使用Jmeter做压力测试的过程中,由于单机的并发能力有限,所以常常无法满足压力测试的需求。因此,Jmeter还提供了分布式的解决方案。本文是一次利用Jmeter分布式对业务系统登录接口做的压力测试的实践记录。按照惯例࿰…...

IDEA常用代码模板
在 IntelliJ IDEA 中,常用代码模板可以帮助你快速生成常用的代码结构和模式。以下是一些常用的代码模板及其使用方法: 动态模板(Live Templates) psvm:生成 public static void main(String[] args) 方法。sout:生成 System.out.println(); 语句。soutv:生成 System.ou…...
基于大语言模型的多意图增强搜索
随着人工智能技术的蓬勃发展,大语言模型(LLM)如Claude等在多个领域展现出了卓越的能力。如何利用这些模型的语义分析能力,优化传统业务系统中的搜索性能是个很好的研究方向。 在传统业务系统中,数据匹配和检索常常面临…...
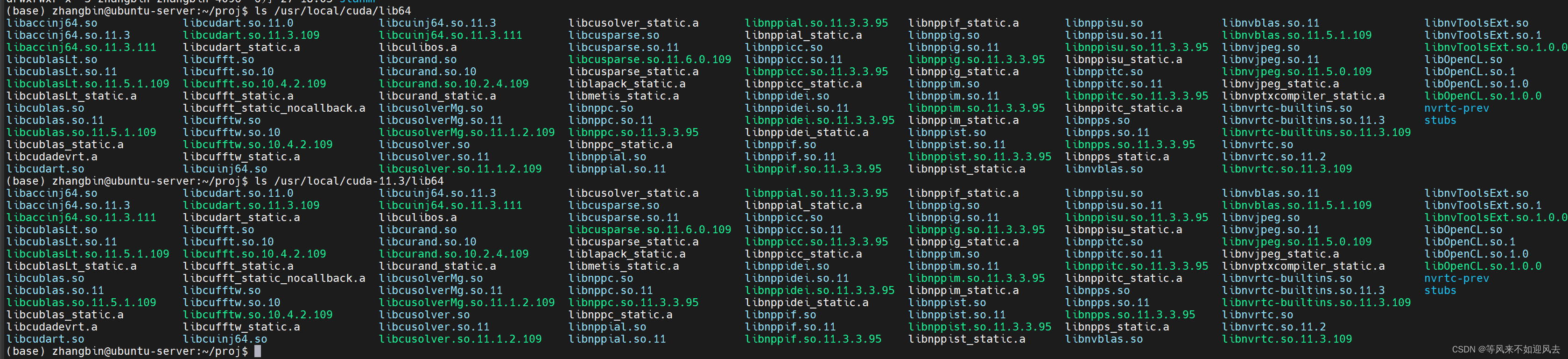
【ai】ubuntu18.04 找不到 nvcc --version问题
nvcc --version显示command not found问题 这个是cuda 库: windows安装了12.5 : 参考大神:解决nvcc --version显示command not found问题 原文链接:https://blog.csdn.net/Flying_sfeng/article/details/103343813 /usr/local/cuda/lib64 与 /usr/local/cuda-11.3/lib64 完…...

深入了解DDoS攻击及其防护措施
深入了解DDoS攻击及其防护措施 分布式拒绝服务(Distributed Denial of Service,DDoS)攻击是当今互联网环境中最具破坏性和普遍性的网络威胁之一。DDoS攻击不仅危及企业的运营,还可能损害其声誉,造成客户信任度的下降。…...

【面试系列】产品经理高频面试题及详细解答
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、…...

前端特殊字符数据,后端接收产生错乱,前后端都需要处理
前端: const data {createTime: "2024-06-11 09:58:59",id: "1800346960914579456",merchantId: "1793930010750218240",mode: "DEPOSIT",channelCode: "if(amount > 50){iugu2pay;} else if(amount < 10){iu…...

力扣热100 哈希
哈希 1. 两数之和49.字母异位词分组128.最长连续序列 1. 两数之和 题目:给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。…...
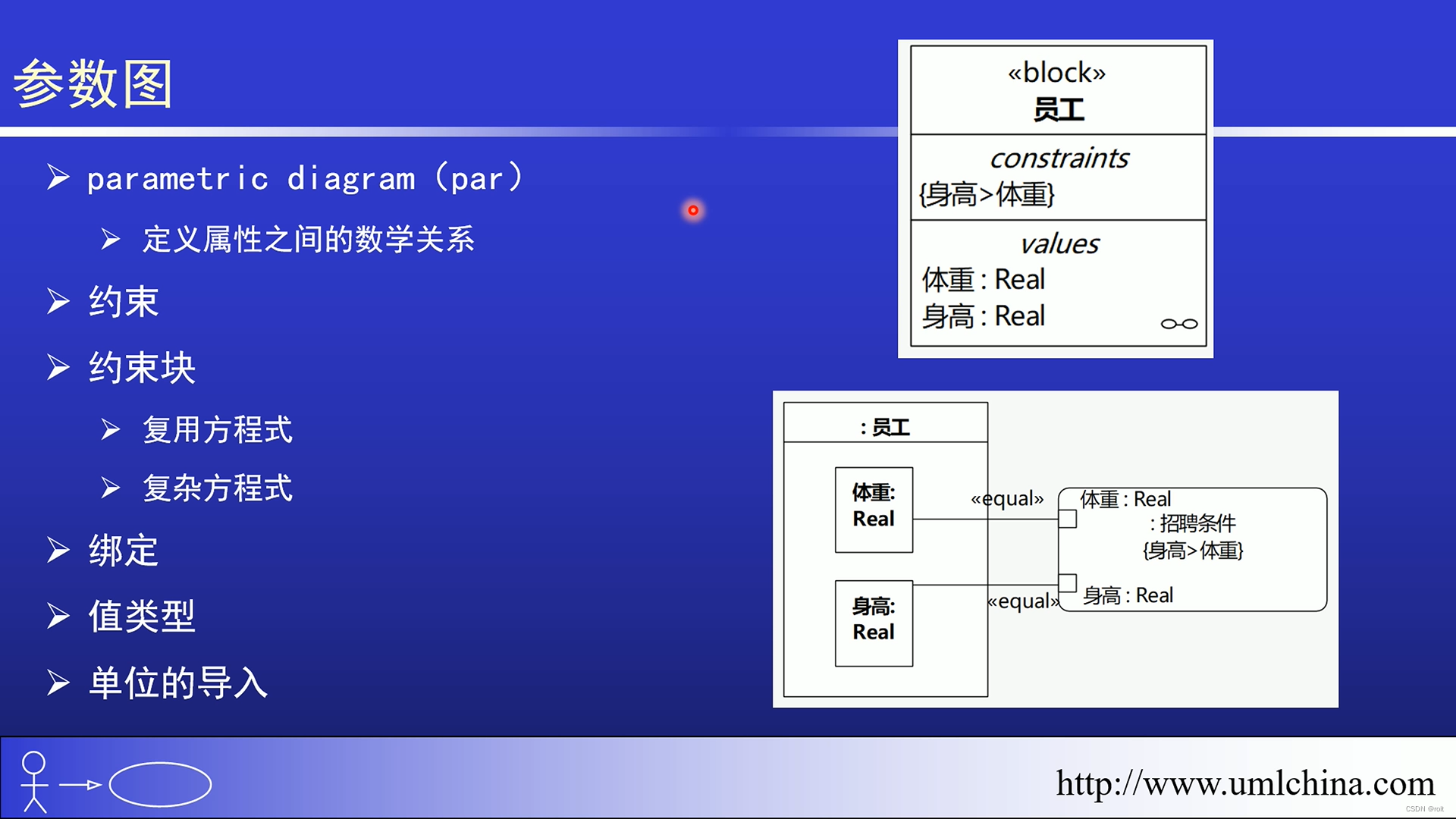
[图解]SysML和EA建模住宅安全系统-05-参数图
1 00:00:01,140 --> 00:00:03,060 这是实数没错,这是分钟 2 00:00:03,750 --> 00:00:07,490 但是你在这里选,选不了的 3 00:00:07,500 --> 00:00:09,930 因为它这里不能够有那个 4 00:00:11,990 --> 00:00:13,850 但是我们前面这里 5 00…...

JavaScript——对象的创建
目录 任务描述 相关知识 对象的定义 对象字面量 通过关键字new创建对象 通过工厂方法创建对象 使用构造函数创建对象 使用原型(prototype)创建对象 编程要求 任务描述 本关任务:创建你的第一个 JavaScript 对象。 相关知识 JavaScript 是一种基于对象&a…...

大二暑假 + 大三上
希望,暑假能早睡早起,胸围达到 95,腰围保持 72,大臂 36,小臂 32,小腿 38🍭🍭 目录 🍈暑假计划 🌹每周进度 🤣寒假每日进度😂 &…...

C语言使用先序遍历创建二叉树
#include<stdio.h> #include<stdlib.h>typedef struct node {int data;struct node * left;struct node * right; } Node;Node * createNode(int val); Node * createTree(); void freeTree(Node * node);void preOrder(Node * node);// 先序创建二叉树 int main()…...

如何在服务器中安装anaconda
文章目录 Step1: 下载 Anaconda方法1:下载好sh文件上传到服务器安装方法2:在线下载 Step2: 安装AnacondaStep3: 配置环境变量Step 4: 激活AnacondaStep4: 检验安装是否成功 Step1: 下载 Anaconda 方法1:下载好sh文件上传到服务器安装 在浏览…...

夸克网盘拉新暑期大涨价!官方授权渠道流程揭秘
夸克网盘拉新暑期活动来袭,价格大涨!从7月1日开始持续两个月,在这两个月里夸克网盘拉新的移动端用户,一个从原来的5元涨到了10元。这对做夸克网盘拉新的朋友来说,真的是福利的。趁着暑期时间多,如果有想做夸…...
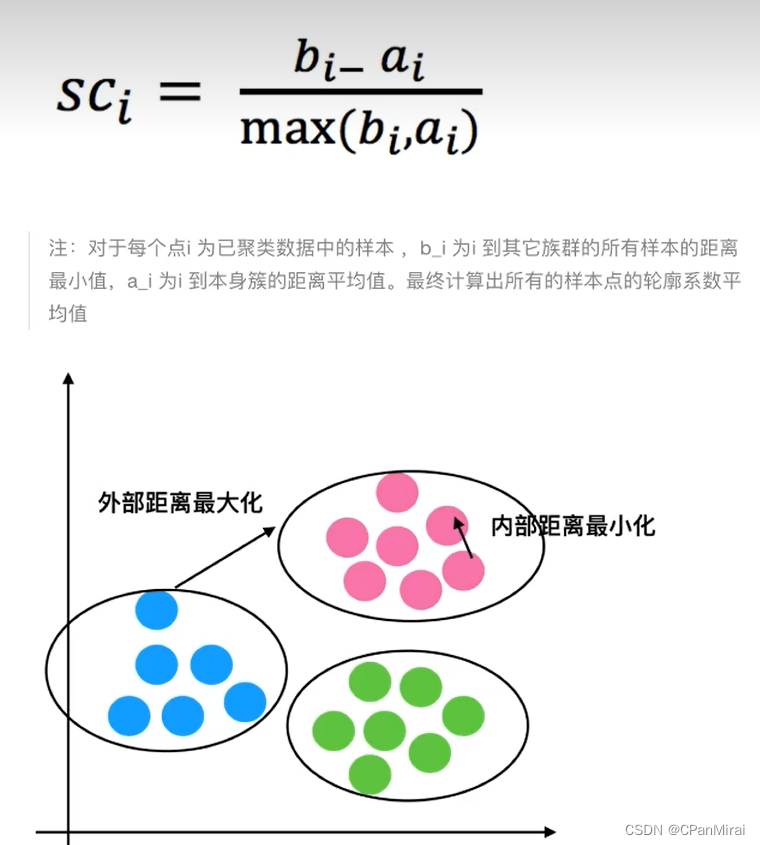
机器学习(三)
机器学习 4.回归和聚类算法4.1 线性回归4.1.1 线性回归的原理4.1.2 线性回归的损失和优化原理 4.2 欠拟合与过拟合4.2.1 定义4.2.2 原因以及解决方法4.2.3 正则化 4.3 线性回归改进-岭回归4.3.1 带L2正则化的线性回归-岭回归4.3.2 API 4.4 分类算法-逻辑回归与二分类4.4.1 定义…...
)
PostgreSQL 基本SQL语法(二)
1. SELECT 语句 1.1 基本 SELECT 语法 SELECT 语句用于从数据库中检索数据。基本语法如下: SELECT column1, column2, ... FROM table_name; 例如,从 users 表中检索所有列的数据: SELECT * FROM users; 1.2 使用 WHERE 条件 WHERE 子…...

linux 控制台非常好用的 PS1 设置
直接上代码 IP$(/sbin/ifconfig eth0 | awk /inet / {print $2}) export PS1"\[\e[35m\]^o^\[\e[0m\]$ \[\e[31m\]\t\[\e[0m\] [\[\e[36m\]\w\[\e[0m\]] \[\e[32m\]\u\[\e[0m\]\[\e[33m\]\[\e[0m\]\[\e[34m\]\h(\[\e[31m\]$IP\[\e[m\])\[\e[0m\]\n\[\e[35m\].O.\[\e[0m\]…...
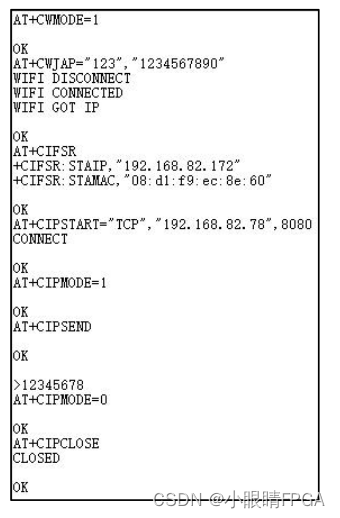
【紫光同创盘古PGX-Nano教程】——(盘古PGX-Nano开发板/PG2L50H_MBG324第十二章)Wifi透传实验例程说明
本原创教程由深圳市小眼睛科技有限公司创作,版权归本公司所有,如需转载,需授权并注明出处(www.meyesemi.com) 适用于板卡型号: 紫光同创PG2L50H_MBG324开发平台(盘古PGX-Nano) 一:…...

Tetrazine-amine HCl salt,CAS:1416711-59-5,四嗪-氨基盐酸盐的描述
Tetrazine-amine HCl salt(四嗪-氨基盐酸盐)是一种结合了四嗪基团和氨基盐酸盐结构的化合物,在化学、生物医药和材料科学等领域具有广泛应用。一、基本信息中文名称:四嗪-氨基盐酸盐英文名称:Tetrazine-amine HCl salt…...

Phi-4-mini-reasoning开源大模型教程:免配置镜像+128K长文本推理实战
Phi-4-mini-reasoning开源大模型教程:免配置镜像128K长文本推理实战 1. 模型简介 Phi-4-mini-reasoning是一个轻量级开源大语言模型,专注于高质量推理任务。作为Phi-4模型家族成员,它具备以下核心特点: 推理能力突出࿱…...

解密Wallpaper Engine资源宝库:RePKG工具完全实战指南
解密Wallpaper Engine资源宝库:RePKG工具完全实战指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg RePKG是一款专为Wallpaper Engine设计的开源资源处理工具…...

Wan2.2-I2V-A14B企业级部署案例:单卡24GB显存实现高并发视频API服务
Wan2.2-I2V-A14B企业级部署案例:单卡24GB显存实现高并发视频API服务 1. 企业级视频生成解决方案概述 在数字内容创作领域,视频生成技术正经历革命性变革。Wan2.2-I2V-A14B作为新一代文生视频模型,通过私有化部署方案,为企业提供…...

Wan2.2-I2V-A14B效果展示:复杂提示词‘雨夜霓虹街道行人撑伞行走’生成效果
Wan2.2-I2V-A14B效果展示:复杂提示词雨夜霓虹街道行人撑伞行走生成效果 1. 模型能力概览 Wan2.2-I2V-A14B是一款专为高质量视频生成设计的先进模型,能够将文字描述转化为生动的动态画面。这款模型特别擅长处理复杂场景和细腻氛围的渲染,在以…...

智能转换驱动科研效率:DeTikZify重构学术图表自动化新范式
智能转换驱动科研效率:DeTikZify重构学术图表自动化新范式 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研成果可视化的关键环节…...

Nordic Power Profiler Kit II 保姆级教程:从硬件连接到软件操作全流程
Nordic Power Profiler Kit II 实战指南:从开箱到精准功耗分析 第一次拿到Power Profiler Kit II(PPK2)时,我正为一个蓝牙低功耗项目的电池寿命问题头疼不已。这款由Nordic Semiconductor推出的专业功耗分析工具,凭借其…...
)
5分钟搞定OpenCV摄像头实时监控(附Jupyter避坑指南)
5分钟搞定OpenCV摄像头实时监控(附Jupyter避坑指南) 在计算机视觉领域,实时摄像头监控是最基础也最实用的功能之一。无论是安防监控、人脸识别还是简单的视频采集,OpenCV都提供了简洁高效的接口。但对于Python初学者和Jupyter Not…...

GLM-4.1V-9B-Base模型微调入门:使用accelerate库进行高效参数优化
GLM-4.1V-9B-Base模型微调入门:使用accelerate库进行高效参数优化 1. 引言 想为特定业务场景定制一个强大的多模态AI模型?GLM-4.1V-9B-Base作为支持图文理解与生成的大模型,通过微调可以快速适配各种下游任务。本文将带你从零开始ÿ…...

Java调用C/C++/Rust的5种方式:FFI vs JNI vs JNA vs JNR vs Panama——2024权威对比评测
第一章:Java外部函数接口概述与技术演进脉络Java外部函数接口(Foreign Function & Memory API),即Project Panama的核心成果,是Java平台为高效、安全地与本地代码(如C/C库)及非堆内存交互而…...