使用PyTorch高效读取二进制数据集进行训练
使用pickle制作类cifar10二进制格式的数据集
使用pytorc框架来训练(以猫狗大战数据集为例)
此方法是为了实现阿里云PAI studio上可视化训练模型时使用的数据格式。
一、制作类cifar10二进制格式数据
import os, cv2
from pickled import *
from load_data import *data_path = './data_n/test'
file_list = './data_n/test.txt'
save_path = './bin'if __name__ == '__main__':data, label, lst = read_data(file_list, data_path, shape=128)pickled(save_path, data, label, lst, bin_num=1)read_data模块
import cv2
import os
import numpy as npDATA_LEN = 49152
CHANNEL_LEN = 16384
SHAPE = 128def imread(im_path, shape=None, color="RGB", mode=cv2.IMREAD_UNCHANGED):im = cv2.imread(im_path, cv2.IMREAD_UNCHANGED)if color == "RGB":im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)# im = np.transpose(im, [2, 1, 0])if shape != None:assert isinstance(shape, int) im = cv2.resize(im, (shape, shape))return imdef read_data(filename, data_path, shape=None, color='RGB'):"""filename (str): a file data file is stored in such format:image_name labeldata_path (str): image data folderreturn (numpy): a array of image and a array of label""" if os.path.isdir(filename):print("Can't found data file!")else:f = open(filename)lines = f.read().splitlines()count = len(lines)data = np.zeros((count, DATA_LEN), dtype=np.uint8)#label = np.zeros(count, dtype=np.uint8)lst = [ln.split(' ')[0] for ln in lines]label = [int(ln.split(' ')[1]) for ln in lines]idx = 0s, c = SHAPE, CHANNEL_LENfor ln in lines:fname, lab = ln.split(' ')im = imread(os.path.join(data_path, fname), shape=s, color='RGB')'''im = cv2.imread(os.path.join(data_path, fname), cv2.IMREAD_UNCHANGED)im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)im = cv2.resize(im, (s, s))'''
# print(len(np.reshape(im[:,:,0], c))) # 1024data[idx, :c] = np.reshape(im[:, :, 0], c)data[idx, c:2*c] = np.reshape(im[:, :, 1], c)data[idx, 2*c:] = np.reshape(im[:, :, 2], c)label[idx] = int(lab)idx = idx + 1return data, label, lstpickled模块
import os
import pickleBIN_COUNTS = 5def pickled(savepath, data, label, fnames, bin_num=BIN_COUNTS, mode="train"):'''savepath (str): save pathdata (array): image data, a nx3072 arraylabel (list): image label, a list with length nfnames (str list): image names, a list with length nbin_num (int): save data in several filesmode (str): {'train', 'test'}'''assert os.path.isdir(savepath)total_num = len(fnames)samples_per_bin = total_num / bin_numassert samples_per_bin > 0idx = 0for i in range(bin_num): start = int(i*samples_per_bin)end = int((i+1)*samples_per_bin)print(start)print(end)if end <= total_num:dict = {'data': data[start:end, :],'labels': label[start:end],'filenames': fnames[start:end]}else:dict = {'data': data[start:, :],'labels': label[start:],'filenames': fnames[start:]}if mode == "train":dict['batch_label'] = "training batch {} of {}".format(idx, bin_num)else:dict['batch_label'] = "testing batch {} of {}".format(idx, bin_num)# with open(os.path.join(savepath, 'data_batch_'+str(idx)), 'wb') as fi:with open(os.path.join(savepath, 'batch_tt' + str(idx)), 'wb') as fi:pickle.dump(dict, fi)idx = idx + 1def unpickled(filename):#assert os.path.isdir(filename)assert os.path.isfile(filename)with open(filename, 'rb') as fo:dict = pickle.load(fo)return dict测试生成的二进制数据
import os
import pickle
import numpy as np
import cv2def load_batch(fpath):with open(fpath, 'rb') as f:d = pickle.load(f)data = d["data"]labels = d["labels"]return data, labelsdef load_data(dirname, one_hot=False):X_train = []Y_train = []for i in range(0):fpath = os.path.join(dirname, 'data_batch_' + str(i))print(fpath)data, labels = load_batch(fpath)if i == 0:X_train = dataY_train = labelselse:X_train = np.concatenate([X_train, data], axis=0)Y_train = np.concatenate([Y_train, labels], axis=0)ftpath = os.path.join(dirname, 'batch_tt0')X_test, Y_test = load_batch(ftpath)X_test = np.dstack((X_test[:, :16384], X_test[:, 16384:32768],X_test[:, 32768:]))X_test = np.reshape(X_test, [-1, 128, 128, 3])print(X_test.shape)xx_test = np.transpose(X_test,(0, 3, 1, 2))print(xx_test.shape)
# print(X_test[2])imgs = X_test[2:4]img = imgs[1]print(img.shape)img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)cv2.imshow('img', img)cv2.waitKey(0)if __name__ == '__main__':dirname = 'test'load_data(dirname)二、使用制作好的数据训练
import torch
import os
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from PIL import Image
import pickle
import numpy as np#device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")def load_batch(fpath):with open(fpath, 'rb') as f:d = pickle.load(f)data = d["data"]labels = d["labels"]return data, labelsdef load_data(dirname, one_hot=False, train=False):print(dirname)if train:X_train = []Y_train = []for i in range(1):fpath = os.path.join(dirname, 'data_batch_' + str(i))print(fpath)data, labels = load_batch(fpath)if i == 0:X_train = dataY_train = labelselse:X_train = np.concatenate([X_train, data], axis=0)Y_train = np.concatenate([Y_train, labels], axis=0)X_train = np.dstack((X_train[:, :16384], X_train[:, 16384:32768],X_train[:, 32768:]))X_train = np.reshape(X_train, [-1, 128, 128, 3])# X_train = np.transpose(X_train, (0, 3, 1, 2))return X_train, Y_trainelse:ftpath = os.path.join(dirname, 'test_batch_0')print(ftpath)X_test, Y_test = load_batch(ftpath)X_test = np.dstack((X_test[:, :16384], X_test[:, 16384:32768],X_test[:, 32768:]))X_test = np.reshape(X_test, [-1, 128, 128, 3])# 这里不需要转化数据格式[n, h, w, c]# X_test = np.transpose(X_test, (0, 3, 1, 2))return X_test, Y_testclass MyDataset(torch.utils.data.Dataset):def __init__(self, namedir, transform=None, train=False):super().__init__()self.namedir = namedirself.transform = transformself.train = trainself.datas, self.labels = load_data(self.namedir, train=self.train)def __getitem__(self, index):
# print(index)imgs = self.datas[index]
# print(imgs.shape)
# print(imgs)img_labes = int(self.labels[index])# print(img_labes)if self.transform is not None:imgs = self.transform(imgs)return imgs, img_labesdef __len__(self):return len(self.labels)class MyDataset_s(torch.utils.data.Dataset):def __init__(self, datatxt, transform=None):super().__init__()imgs = []fh = open(datatxt, 'r')for line in fh:line = line.rstrip()words = line.split()imgs.append((words[0], int(words[1])))self.imgs = imgsself.transform = transformdef __getitem__(self, index):fn, label = self.imgs[index]img = Image.open(fn).convert('RGB')if self.transform is not None:img = self.transform(img)return img, labeldef __len__(self):return len(self.imgs)mean = [0.5071, 0.4867, 0.4408]
stdv = [0.2675, 0.2565, 0.2761]transform = transforms.Compose([# transforms.Resize([224, 224]),# transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=mean, std=stdv)])train_data = MyDataset(namedir='data\\train\\', transform=transform, train=True)
trainloader = torch.utils.data.DataLoader(dataset=train_data, batch_size=4, shuffle=True)
test_data = MyDataset(namedir='data\\val\\', transform=transform, train=False)
testloader = torch.utils.data.DataLoader(dataset=test_data, batch_size=4, shuffle=True)classes = ('cat', 'dog')class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)self.conv3 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)self.conv4 = nn.Conv2d(64, 32, kernel_size=3, stride=1, padding=1)# self.conv5 = nn.Conv2d(32, 16, kernel_size=3, stride=1, padding=1)self.fc1 = nn.Linear(32 * 8 * 8, 256)self.fc2 = nn.Linear(256, 64)self.fc3 = nn.Linear(64, 2)def forward(self, x): # (n, 3, 128, 128)x = self.pool(F.relu(self.conv1(x))) # (n, 16, 64, 64)x = self.pool(F.relu(self.conv2(x))) # (n, 32, 32, 32)x = self.pool(F.relu(self.conv3(x))) # (n, 64, 16, 16)x = self.pool(F.relu(self.conv4(x))) # (n, 32, 8, 8)# x = self.pool(F.relu(self.conv5(x)))# print(x)x = x.view(-1, 32 * 8 * 8)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xclass VGG16(nn.Module):def __init__(self):super(VGG16, self).__init__()# 3 * 224 * 224self.conv1_1 = nn.Conv2d(3, 64, 3) # 64 * 222 * 222self.conv1_2 = nn.Conv2d(64, 64, 3, padding=(1, 1)) # 64 * 222 * 222self.maxpool1 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 64 * 112 * 112self.conv2_1 = nn.Conv2d(64, 128, 3) # 128 * 110 * 110self.conv2_2 = nn.Conv2d(128, 128, 3, padding=(1, 1)) # 128 * 110 * 110self.maxpool2 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 128 * 56 * 56self.conv3_1 = nn.Conv2d(128, 256, 3) # 256 * 54 * 54self.conv3_2 = nn.Conv2d(256, 256, 2, padding=(1, 1)) # 256 * 54 * 54self.conv3_3 = nn.Conv2d(256, 256, 3, padding=(1, 1)) # 256 * 54 * 54self.maxpool3 = nn.MaxPool2d((2, 2), padding=(1, 1)) # 256 * 28 * 28self.conv4_1 = nn.Conv2d(256, 512, 3) # 512 * 26 * 26self.conv4_2 = nn.Conv2d(512, 512, 3, padding=(1, 1)) # 512 * 26 * 26self.conv4_3 = nn.Conv2d(512, 512, 3, padding=(1, 1)) # 512 * 26 * 26self.maxpool4 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 512 * 14 * 14self.conv5_1 = nn.Conv2d(512, 512, 3) # 512 * 12 * 12self.conv5_2 = nn.Conv2d(512, 512, 3, padding=(1, 1)) # 512 * 12 * 12self.conv5_3 = nn.Conv2d(512, 512, 3, padding=(1, 1)) # 512 * 12 * 12self.maxpool5 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 512 * 7 * 7# viewself.fc1 = nn.Linear(512 * 7 * 7, 512)self.fc2 = nn.Linear(512, 64)self.fc3 = nn.Linear(64, 2)def forward(self, x):# x.size(0)即为batch_sizein_size = x.size(0)out = self.conv1_1(x) # 222out = F.relu(out)out = self.conv1_2(out) # 222out = F.relu(out)out = self.maxpool1(out) # 112out = self.conv2_1(out) # 110out = F.relu(out)out = self.conv2_2(out) # 110out = F.relu(out)out = self.maxpool2(out) # 56out = self.conv3_1(out) # 54out = F.relu(out)out = self.conv3_2(out) # 54out = F.relu(out)out = self.conv3_3(out) # 54out = F.relu(out)out = self.maxpool3(out) # 28out = self.conv4_1(out) # 26out = F.relu(out)out = self.conv4_2(out) # 26out = F.relu(out)out = self.conv4_3(out) # 26out = F.relu(out)out = self.maxpool4(out) # 14out = self.conv5_1(out) # 12out = F.relu(out)out = self.conv5_2(out) # 12out = F.relu(out)out = self.conv5_3(out) # 12out = F.relu(out)out = self.maxpool5(out) # 7# 展平out = out.view(in_size, -1)out = self.fc1(out)out = F.relu(out)out = self.fc2(out)out = F.relu(out)out = self.fc3(out)# out = F.log_softmax(out, dim=1)return outclass VGG8(nn.Module):def __init__(self):super(VGG8, self).__init__()# 3 * 224 * 224self.conv1_1 = nn.Conv2d(3, 64, 3) # 64 * 222 * 222self.maxpool1 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 64 * 112 * 112self.conv2_1 = nn.Conv2d(64, 128, 3) # 128 * 110 * 110self.maxpool2 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 128 * 56 * 56self.conv3_1 = nn.Conv2d(128, 256, 3) # 256 * 54 * 54self.maxpool3 = nn.MaxPool2d((2, 2), padding=(1, 1)) # 256 * 28 * 28self.conv4_1 = nn.Conv2d(256, 512, 3) # 512 * 26 * 26self.maxpool4 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 512 * 14 * 14self.conv5_1 = nn.Conv2d(512, 512, 3) # 512 * 12 * 12self.maxpool5 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 512 * 7 * 7# viewself.fc1 = nn.Linear(512 * 7 * 7, 512)self.fc2 = nn.Linear(512, 64)self.fc3 = nn.Linear(64, 2)def forward(self, x):# x.size(0)即为batch_sizein_size = x.size(0)out = self.conv1_1(x) # 222out = F.relu(out)out = self.maxpool1(out) # 112out = self.conv2_1(out) # 110out = F.relu(out)out = self.maxpool2(out) # 56out = self.conv3_1(out) # 54out = F.relu(out)out = self.maxpool3(out) # 28out = self.conv4_1(out) # 26out = F.relu(out)out = self.maxpool4(out) # 14out = self.conv5_1(out) # 12out = F.relu(out)out = self.maxpool5(out) # 7# 展平out = out.view(in_size, -1)out = self.fc1(out)out = F.relu(out)out = self.fc2(out)out = F.relu(out)out = self.fc3(out)# out = F.log_softmax(out, dim=1)return outnet = Net()#net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.005, momentum=0.9)if __name__ == '__main__':for epoch in range(11):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data
# inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()if i % 100 == 99:print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))running_loss = 0.0if epoch % 2 == 0:correct = 0total = 0with torch.no_grad():for data in testloader:images, labels = data# images, labels = images.to(device), labels.to(device)outputs = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy of the network on the 1000 test images: %d %%' % (100 * correct / total))print('finished !!!')相关文章:

使用PyTorch高效读取二进制数据集进行训练
使用pickle制作类cifar10二进制格式的数据集 使用pytorc框架来训练(以猫狗大战数据集为例) 此方法是为了实现阿里云PAI studio上可视化训练模型时使用的数据格式。 一、制作类cifar10二进制格式数据 import os, cv2 from pickled import * from load_da…...
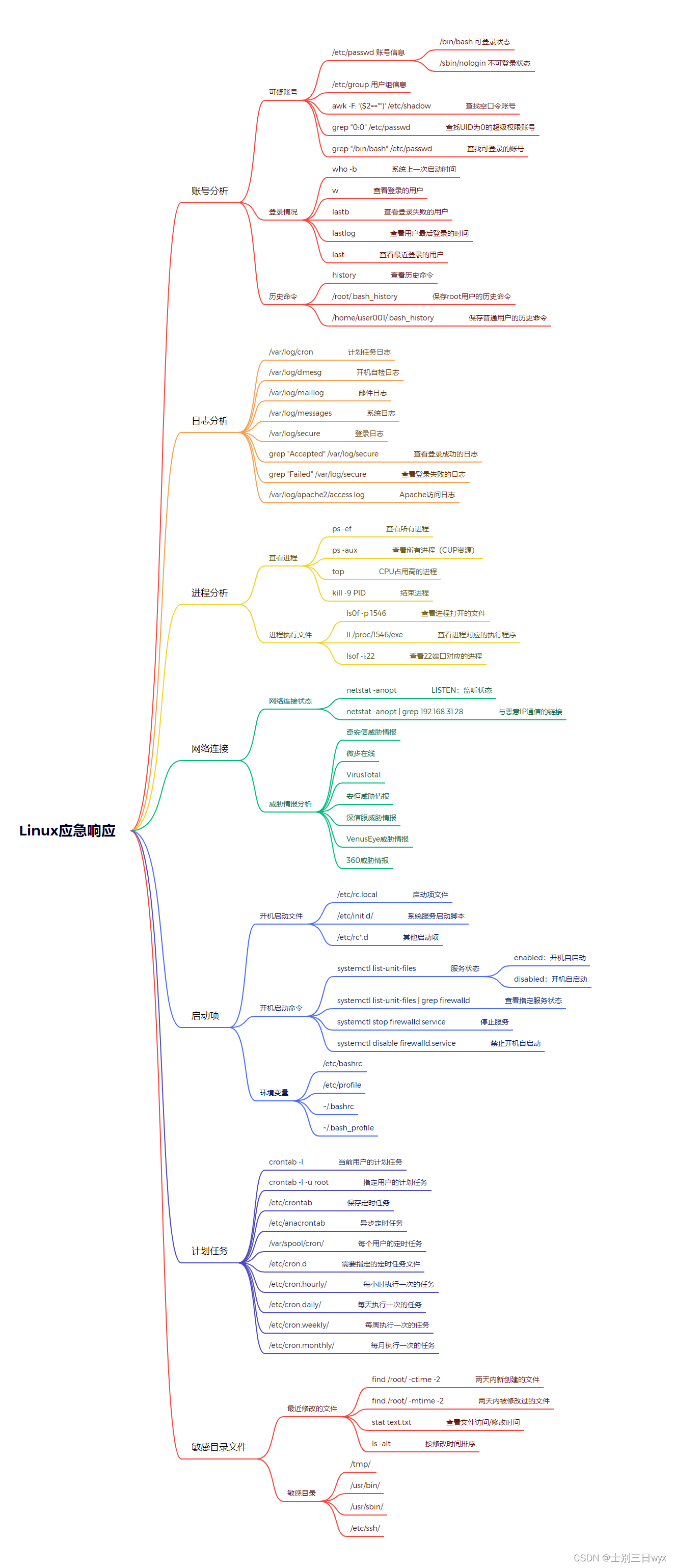
应急响应:应急响应流程,常见应急事件及处置思路
「作者简介」:冬奥会网络安全中国代表队,CSDN Top100,就职奇安信多年,以实战工作为基础著作 《网络安全自学教程》,适合基础薄弱的同学系统化的学习网络安全,用最短的时间掌握最核心的技术。 这一章节我们需…...

Kotlin/Android中执行HTTP请求
如何在Kotlin/Android中执行简单的HTTP请求 okhttp官网 okhttp3 github地址 打开build.gradle.kts文件加入依赖 dependencies {implementation("com.squareup.okhttp3:okhttp:4.9.0") }在IDEA的Gradle面板点击reload按钮便会自动下载jar...

哈希表(C++实现)
文章目录 写在前面1. 哈希概念2. 哈希冲突3. 哈希函数4.哈希冲突解决4.1 闭散列4.1.1 线性探测4.1.2 采用线性探测的方式解决哈希冲突实现哈希表4.1.3 二次探测 4.2 开散列4.2.2 采用链地址法的方式解决哈希冲突实现哈希表 写在前面 在我们之前实现的所有数据结构中(比如&…...
及其实际应用)
深入理解代理模式(Proxy Pattern)及其实际应用
引言 在软件开发中,有时候我们需要在不改变现有代码的情况下添加一些功能,比如延迟初始化、访问控制、日志记录等。代理模式(Proxy Pattern)通过代理对象控制对原对象的访问,为现有代码添加了额外的功能。本篇文章将详…...

Elasticsearch (1):ES基本概念和原理简单介绍
Elasticsearch(简称 ES)是一款基于 Apache Lucene 的分布式搜索和分析引擎。随着业务的发展,系统中的数据量不断增长,传统的关系型数据库在处理大量模糊查询时效率低下。因此,ES 作为一种高效、灵活和可扩展的全文检索…...
【Python爬虫】Python爬取喜马拉雅,爬虫教程!
一、思路设计 (1)分析网页 在喜马拉雅主页找到自己想要的音频,得到目标URL:https://www.ximalaya.com/qinggan/321787/ 通过分析页面的网络抓包,最终的到一个比较有用的json数据包 通过分析,得到了发送json…...

基于Jmeter的分布式压测环境搭建及简单压测实践
写在前面 平时在使用Jmeter做压力测试的过程中,由于单机的并发能力有限,所以常常无法满足压力测试的需求。因此,Jmeter还提供了分布式的解决方案。本文是一次利用Jmeter分布式对业务系统登录接口做的压力测试的实践记录。按照惯例࿰…...

IDEA常用代码模板
在 IntelliJ IDEA 中,常用代码模板可以帮助你快速生成常用的代码结构和模式。以下是一些常用的代码模板及其使用方法: 动态模板(Live Templates) psvm:生成 public static void main(String[] args) 方法。sout:生成 System.out.println(); 语句。soutv:生成 System.ou…...
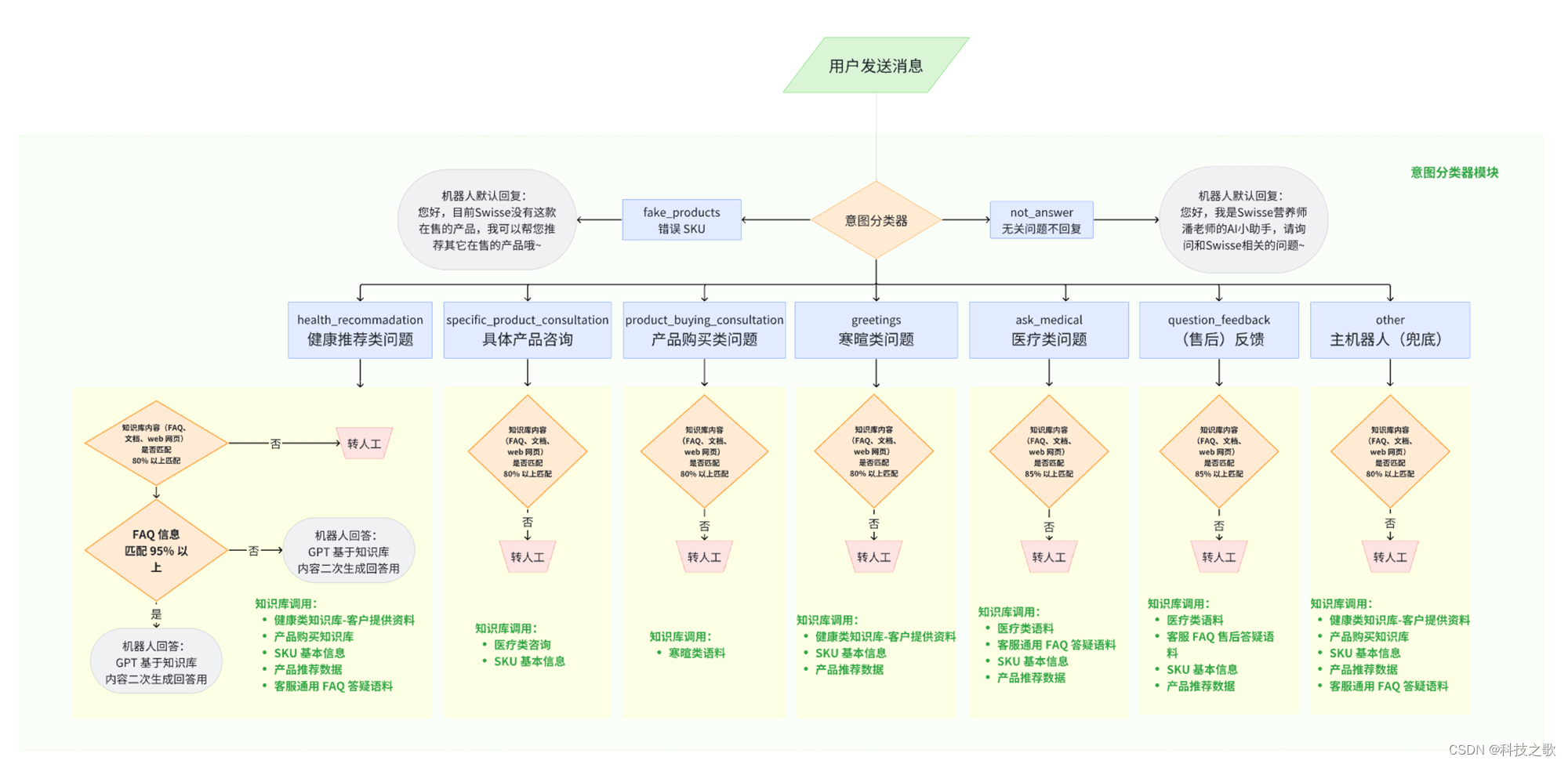
基于大语言模型的多意图增强搜索
随着人工智能技术的蓬勃发展,大语言模型(LLM)如Claude等在多个领域展现出了卓越的能力。如何利用这些模型的语义分析能力,优化传统业务系统中的搜索性能是个很好的研究方向。 在传统业务系统中,数据匹配和检索常常面临…...
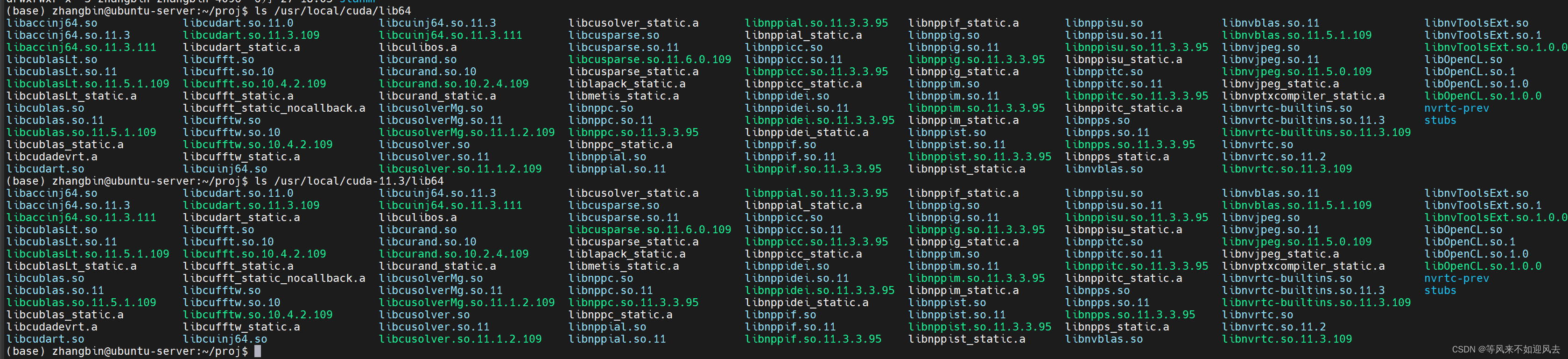
【ai】ubuntu18.04 找不到 nvcc --version问题
nvcc --version显示command not found问题 这个是cuda 库: windows安装了12.5 : 参考大神:解决nvcc --version显示command not found问题 原文链接:https://blog.csdn.net/Flying_sfeng/article/details/103343813 /usr/local/cuda/lib64 与 /usr/local/cuda-11.3/lib64 完…...

深入了解DDoS攻击及其防护措施
深入了解DDoS攻击及其防护措施 分布式拒绝服务(Distributed Denial of Service,DDoS)攻击是当今互联网环境中最具破坏性和普遍性的网络威胁之一。DDoS攻击不仅危及企业的运营,还可能损害其声誉,造成客户信任度的下降。…...

【面试系列】产品经理高频面试题及详细解答
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、…...

前端特殊字符数据,后端接收产生错乱,前后端都需要处理
前端: const data {createTime: "2024-06-11 09:58:59",id: "1800346960914579456",merchantId: "1793930010750218240",mode: "DEPOSIT",channelCode: "if(amount > 50){iugu2pay;} else if(amount < 10){iu…...

力扣热100 哈希
哈希 1. 两数之和49.字母异位词分组128.最长连续序列 1. 两数之和 题目:给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。…...
[图解]SysML和EA建模住宅安全系统-05-参数图
1 00:00:01,140 --> 00:00:03,060 这是实数没错,这是分钟 2 00:00:03,750 --> 00:00:07,490 但是你在这里选,选不了的 3 00:00:07,500 --> 00:00:09,930 因为它这里不能够有那个 4 00:00:11,990 --> 00:00:13,850 但是我们前面这里 5 00…...

JavaScript——对象的创建
目录 任务描述 相关知识 对象的定义 对象字面量 通过关键字new创建对象 通过工厂方法创建对象 使用构造函数创建对象 使用原型(prototype)创建对象 编程要求 任务描述 本关任务:创建你的第一个 JavaScript 对象。 相关知识 JavaScript 是一种基于对象&a…...

大二暑假 + 大三上
希望,暑假能早睡早起,胸围达到 95,腰围保持 72,大臂 36,小臂 32,小腿 38🍭🍭 目录 🍈暑假计划 🌹每周进度 🤣寒假每日进度😂 &…...

C语言使用先序遍历创建二叉树
#include<stdio.h> #include<stdlib.h>typedef struct node {int data;struct node * left;struct node * right; } Node;Node * createNode(int val); Node * createTree(); void freeTree(Node * node);void preOrder(Node * node);// 先序创建二叉树 int main()…...

如何在服务器中安装anaconda
文章目录 Step1: 下载 Anaconda方法1:下载好sh文件上传到服务器安装方法2:在线下载 Step2: 安装AnacondaStep3: 配置环境变量Step 4: 激活AnacondaStep4: 检验安装是否成功 Step1: 下载 Anaconda 方法1:下载好sh文件上传到服务器安装 在浏览…...

从手机拍照到工业质检:聊聊自适应白平衡算法在实际项目里的那些‘坑’
从手机拍照到工业质检:自适应白平衡算法的实战避坑指南 在工业视觉检测线上,一台价值百万的自动化设备突然频繁误判产品颜色——原因竟是车间顶灯老化导致色温偏移,而算法团队引以为傲的"完美反射"白平衡模型完全失效。类似场景每天…...

PowerToys Awake:3种模式彻底解决Windows电脑意外休眠的烦恼
PowerToys Awake:3种模式彻底解决Windows电脑意外休眠的烦恼 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_Trending/po/Pow…...
)
别再手动敲表格了!用Python+PaddleOCR,5分钟搞定图片转Excel(附完整代码)
智能表格提取革命:用PaddleOCR实现图片转Excel的工业级解决方案 在数据驱动的商业环境中,每天有数百万份纸质表格、扫描文档和截图等待被数字化处理。传统的手动录入不仅效率低下,错误率高达18%-22%(国际数据公司2023年办公自动化…...
)
保姆级教程:在Win10上用VS2022搞定TensorRT 8.5.2.2(含zlibwapi.dll缺失等常见坑点)
从零到一:Windows 10 VS2022 深度集成 TensorRT 8.5 全流程实战 TensorRT 作为 NVIDIA 推出的高性能深度学习推理引擎,能够显著提升模型在 NVIDIA GPU 上的执行效率。但对于 Windows 平台的新手开发者来说,从环境配置到第一个示例程序成功运…...

用Fiddler和Proxifier抓包分析易游网络验证API,手把手教你模拟合法请求
网络验证API抓包与模拟请求实战指南 在当今数字化产品生态中,网络验证机制已成为软件授权管理的核心组件。不同于传统的本地验证方式,网络验证通过远程API交互实现更高安全性的许可控制,这也使得协议层分析成为理解其工作原理的关键切入点。对…...

Poppins几何无衬线字体:9种字重与多语言支持的技术实现深度解析
Poppins几何无衬线字体:9种字重与多语言支持的技术实现深度解析 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins Poppins几何无衬线字体是一款由Indian Type Foundry…...

Adobe Illustrator智能填充神器:Fillinger脚本的终极使用指南
Adobe Illustrator智能填充神器:Fillinger脚本的终极使用指南 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 你是否曾经在Adobe Illustrator中面对数百个需要均匀分布的…...
)
保姆级教程:用COMSOL 5.6搞定房间声学模态分析(附网格划分避坑指南)
保姆级教程:用COMSOL 5.6实现高精度房间声学模态分析 当你第一次尝试用COMSOL分析房间的声学特性时,是否曾被复杂的参数设置和网格划分搞得晕头转向?本文将带你一步步攻克声学模态分析中最关键的环节——特征频率求解与网格优化。不同于泛泛而…...

Cangaroo:开源CAN总线分析软件架构解析与深度优化指南
Cangaroo:开源CAN总线分析软件架构解析与深度优化指南 【免费下载链接】cangaroo Open source can bus analyzer software - with support for CANable / CANable2, CANFD, and other new features 项目地址: https://gitcode.com/gh_mirrors/ca/cangaroo Ca…...

开源协作平台Octopal:整合Git、文档与任务的项目管理利器
1. 项目概述:一个为开发者量身定制的开源协作平台如果你是一名开发者,或者是一个小型技术团队的负责人,那么你一定对这样的场景不陌生:手头有几个并行的项目,团队成员分散,沟通主要靠即时通讯工具ÿ…...