哈希表(C++实现)
文章目录
- 写在前面
- 1. 哈希概念
- 2. 哈希冲突
- 3. 哈希函数
- 4.哈希冲突解决
- 4.1 闭散列
- 4.1.1 线性探测
- 4.1.2 采用线性探测的方式解决哈希冲突实现哈希表
- 4.1.3 二次探测
- 4.2 开散列
- 4.2.2 采用链地址法的方式解决哈希冲突实现哈希表
写在前面
在我们之前实现的所有数据结构中(比如:顺序结构以及平衡树中),要存储的元素与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过多次的比较。如顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( l o g 2 N log_2 N log2N),搜索的效率取决于搜索过程中元素的比较次数。
而我们理想的一种搜索方法为:可以不经过任何比较,一次直接从表中得到要搜索的元素。
下面我们来详细介绍一下这种方法:哈希(散列)方法。
1. 哈希概念
哈希(Hash):是一种通过特定函数(哈希函数,hash function)将数据映射到固定大小的存储空间的方法。其核心思想是将数据(通常是键值对)通过哈希函数将数据的关键码转换为哈希值,进而通过哈希值快速找到元素对应的存储位置。
ps:哈希函数 hashFunc,将元素的关键码(如字符串、数字等)转换成一个固定范围内的整数,这个整数就是哈希值。
如果利用哈希构造一种存储结构,使得元素的存储位置与它的关键码之间能够建立起一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
- 插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放。 - 搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功。
这种通过哈希方法构造出来的结构称为哈希表(Hash Table)(或者称散列表)。
例如:在哈希表中,存储以下关键字序列{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % size; size为存储元素的表的长度。

如果继续向表中插入14时,通过hash函数计算出其位置为:hash(14) = 4;与关键字4计算出的哈希地址相同,发生了冲突,这种现象叫做哈希冲突或哈希碰撞。
2. 哈希冲突
哈希冲突:对于两个数据元素的关键字 k i k_i ki和 k j k_j kj(i != j),有 k i k_i ki != k j k_j kj,但有:Hash( k i k_i ki) == Hash( k j k_j kj),即:不同关键字通过相同哈希函数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
ps:把具有不同关键码而具有相同哈希地址的数据元素称为“同义词。
而引起哈希冲突的一个原因可能是:哈希函数设计不够合理。下面我们来了解一下常见的hash函数。
3. 哈希函数
哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间。
- 哈希函数计算出来的地址能均匀分布在整个空间中。
- 哈希函数应该比较简单。
常见哈希函数:
- 直接定址法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B。
优点:简单、均匀。
缺点:需要事先知道关键字的分布情况。
使用场景:适合查找比较小且连续的情况。 - 除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址。 - 平方取中法–(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址。平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况。 - 折叠法–(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的况。 - 随机数法–(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。通常应用于关键字长度不等时采用此法。 - 数学分析法–(了解)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀的情况。
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突。
4.哈希冲突解决
解决哈希冲突两种常见的方法是:闭散列和开散列。
4.1 闭散列
闭散列,也叫开放定址法(Open Addressing),是一种处理哈希冲突的方法。当发生哈希冲突时,说明hash表没被填满,则表中必然存在空位置,因此我们可以通过探测算法在哈希表中寻找下一个空闲位置来存放元素。开放定址法的核心思想是通过一个探测算法在哈希表中一直探测,直到探测到空位置来解决冲突的。
常见的探测方法包括:线性探测、二次探测等。
4.1.1 线性探测
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
例如在上面的hash表中继续插入14时,通过hash函数计算出其位置为:hash(14) = 4;与关键字4计算出的哈希地址相同发生了冲突,因此我们使用线性探测找到下一个空位置,插入新元素。

4.1.2 采用线性探测的方式解决哈希冲突实现哈希表
关于哈希表结构的几点解释:
- 哈希表存储元素的底层是个顺序表,我们这里直接采用vector来充当顺序表。
- 底层存储的数据是存储的键值对,类型为 pair<K, V>,其中 K 是键的类型,V 是值的类型。
- 由于采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如在上面的哈希表中删除元素4,如果直接删除掉,14查找起来可能会受影响。
 因此,哈希表的每个位置不仅要存数据,还要存当前位置的状态,EMPTY此位置空, EXIST此位置已经有元素, DELETE元素已经删除。此时我们在删除掉4的同时将该位置的状态置为DELETE,后面再查找14的时候计算出14的存储位置为4,此时当前位置的状态为DELETE,需要继续往下一个位置查找,这样就可以保证删除元素不会影响其他元素的搜索。
因此,哈希表的每个位置不仅要存数据,还要存当前位置的状态,EMPTY此位置空, EXIST此位置已经有元素, DELETE元素已经删除。此时我们在删除掉4的同时将该位置的状态置为DELETE,后面再查找14的时候计算出14的存储位置为4,此时当前位置的状态为DELETE,需要继续往下一个位置查找,这样就可以保证删除元素不会影响其他元素的搜索。
存储结构的定义:
- 由于表中每个位置既要存储元素,又要存储当前位置的状态,因此我们定义一个结构体 HashData 来存储每个位置的状态和数据。
HashData定义如下:
//所有状态
enum state
{EXIST,EMPTY,DELETE
};
template<class K, class V>
struct HashData
{pair<K, V> _kv;//存储的键值对state _st;//状态//构造HashData(const pair<K, V>& kv = pair<K, V>()):_kv(kv),_st(EMPTY){}
};
哈希表的定义:
- 哈希表中不仅要有存储数据的顺序表,还要维护一个成员变量来记录当前表中的元素个数,这是因为它可以帮助计算装载因子,判断是否需要扩容。
- 装载因子(Load Factor)是哈希表中元素个数与哈希表大小的比值。当装载因子过高时,意味着哈希表中存储的元素数量接近了表的容量,此时在插入元素时可能会导致哈希冲突频繁,从而影响查找效率。为了避免装载因子过高导致的问题,我们因该在装载因子超过某个阈值(如0.7)时,自动扩展哈希表的容量(通常是原容量的两倍),并将现有元素重新分布到新的哈希表中。

哈希表的定义如下:
template<class K, class V, class Hash = HashFuc<K>>
class HastTable
{
public://默认构造HastTable(){//初始时表的长度为10_table.resize(10);_n = 0;}
private:vector<HashData<K, V>> _table;int _n;//当前表中元素个数
};
哈希表的插入:
步骤如下:
- 判断是否需要扩容,这里设定载荷因子超过0.7时要进行扩容操作,将现有元素重新映射到新的哈希表中。
- 通过哈希函数获取待插入元素在哈希表中的位置。
- 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素;同时将该位置的状态改为EXIST, 表中个数+1。
例如:在哈希表中,依次插入一下关键字序列{1,7,6,4,5,9,11,14};
画个图理解一下:

具体代码如下:
bool insert(const pair<K, V>& kv)
{//key已经存在 无法插入,不允许key相同if (find(kv.first)) return false;//负载因子超过0.7扩容if (_n * 10 / _table.size() == 7){//扩容HastTable<K, V> newHT;newHT._table.resize(_table.size() * 2);for (size_t i = 0; i < _table.size(); ++i){if (_table[i]._st == EXIST){newHT.insert(_table[i]._kv);}}_table.swap(newHT._table);}Hash h;//通过hash函数计算当前插入元素的位置size_t hashi = h(kv.first) % _table.size();while (_table[hashi]._st == EXIST){++hashi;hashi %= _table.size();}_table[hashi]._kv = kv;_table[hashi]._st = EXIST;++_n;return true;
}
哈希表的删除:
上面我们分析了,采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。因此在删除元素的时候采取伪删除,即要删除元素时,先去查找该元素,若找到了将该位置的标志改为DELETE即可。
具体代码如下:
bool erase(const K& k)
{//伪删除HashData<K, V>* ret = find(k);//找到了将该位置的标志改为DELETE,同时表中的元素个数-1if (ret){ret->_st = DELETE;--_n;return true;}return false;
}
哈希表的查找:
步骤如下:
- 计算哈希值:使用哈希函数对键 k 进行哈希计算,得到哈希值,并将其映射到哈希表的索引范围内。
- 检查当前位置:循环检查哈希表中的索引位置,直到找到目标元素或者确认元素不存在。当前位置为空(状态为 EMPTY):如果当前索引位置为空(状态为 EMPTY),表示该键不在哈希表中,可以直接返回 nullptr。当前位置已存在元素(状态为 EXIST)且键匹配:如果当前索引位置的状态为 EXIST 且键匹配,则找到了目标元素,返回该元素的指针。当前位置已存在元素但键不匹配:如果当前索引位置的状态为 EXIST 但键不匹配,继续检查下一个位置(线性探测)。
- 循环检查:继续检查下一个位置,直到找到目标元素或遇到一个空位置(状态为 EMPTY),表示该键不在哈希表中。
- 返回结果:如果找到了目标元素,返回该元素的指针;如果找不到,返回 nullptr。
具体代码如下:
HashData<K, V>* find(const K& k)
{Hash h;//计算哈希值size_t hashi = h(k) % _table.size();//循环检查:继续检查下一个位置,直到找到目标元素或遇到一个空位置while (_table[hashi]._st != EMPTY){//如果当前索引位置的状态为 EXIST 且键匹配,则找到了目标元素,返回该元素的指针。if (_table[hashi]._st == EXIST && _table[hashi]._kv.first == k){return &_table[hashi];}//如果当前索引位置的状态为 EXIST 但键不匹配,继续检查下一个位置(线性探测)。++hashi;hashi %= _table.size();}//遇到空位置(状态为 EMPTY),表示该键不在哈希表中,可以直接返回 nullptr。return nullptr;
}
总之,线性探测优点是实现非常简单;线性探测缺点是一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。 比如这组关键字序列:{4,5,14,15,24,6},会造成冲突连成一片,导致效率降低。
4.1.3 二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为: H i H_i Hi = ( H 0 H_0 H0 + i 2 i^2 i2 )% m, 或者: H i H_i Hi = ( H 0 H_0 H0 - i 2 i^2 i2 )% m。其中:i = 1,2,3…, H 0 H_0 H0是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。即每次探测不是往后探测一个位置,而是依次探测 1 2 1^2 12, 2 2 2^2 22, 3 2 3^2 32,…,这里就不在赘述,有兴趣的可以自己去实现一下。
4.2 开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
例如:在哈希表中,存储以下关键字序列{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % size; size为存储元素的表的长度。

当继续插入元素14时,通过哈希函数计算出其存储位置为:hash(14) = 14 % 10 = 4;直接将其插入在位置为4的那个链表中即可。

4.2.2 采用链地址法的方式解决哈希冲突实现哈希表
存储结构的定义:
- 由于每个桶都是一个单链表,因此哈希表里面存储的是每个桶的首节点的地址,所以存储底层为指针数组。而每个节点不仅要存储数据还要存储下一个节点的地址,因此我们定义一个结构体 HashNode。
HashNode定义如下:
template<class K, class V>
struct HashNode
{typedef HashNode<K, V> Node;pair<K, V> _kv;Node* _next;//构造HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};
哈希表的定义:
- 采用链地址法的方式解决哈希冲突实现哈希表也要维护一个成员变量来记录当前表中的元素个数,来帮助计算装载因子,判断是否需要扩容。
哈希表的定义如下:
template<class K, class V, class Hash = HashFuc<K>>
class HastTable
{typedef HashNode<K, V> Node;
public://默认构造HastTable(){_table.resize(10);_n = 0;}
private:vector<Node*> _table;int _n;//当前表中元素个数
};
哈希表的插入:
步骤如下:
- 判断是否需要扩容,这里设定载荷因子超过1时要进行扩容操作,将现有元素重新映射到新的哈希表中。
ps:关于这里的载荷因子为啥可以到1才进行扩容:桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希表进行增容,那该条件怎么确认呢?开散列最好的情况是:每个哈希桶中刚好挂一个节点,再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可以给哈希表增容。 - 通过哈希函数获取待插入元素在哈希表中的位置。
- 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素;同时将该位置的状态改为EXIST, 表中个数+1。
例如:在哈希表中,依次插入一下关键字序列{1,7,6,4,5,9,11,14, ,2 ,12,17};
画个图理解一下:

具体代码如下:
bool insert(const pair<K, V>& kv)
{Hash h;if (find(kv.first)) return false;if (_n / _table.size() == 1){//扩容HastTable<K, V, Hash> ht;ht._table.resize(_table.size() * 2);//遍历旧哈希表中的所有元素,将每个元素重新映射到新哈希表中。for (int i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* next = cur->_next;int hashi = h(cur->_kv.first) % ht._table.size();cur->_next = ht._table[hashi];ht._table[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(ht._table);}//扩容完成后,将新元素插入到新的哈希表中。Node* newnode = new Node(kv);int hashi = h(kv.first) % _table.size();newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return true;
}
ps: 在扩完容后,将现有元素重新映射到新的哈希表时,要依次取旧表中的节点重新进行映射。这是因为重新链接节点通常比创建和插入新节点更高效,因为创建新节点涉及分配新的内存,而重新链接只需要调整指针。重新链接的开销较低,可以更快地完成扩容操作。
哈希表的删除:
删除步骤如下:
- 计算哈希值:使用哈希函数计算要删除元素的哈希值,并取模计算出其在哈希表中的索引。
- 查找元素:从计算出的索引开始,遍历链表,查找目标元素。
- 删除元素:如果找到目标元素,根据其在链表中的位置,调整链表指针以删除该节点。如果目标元素是链表中的第一个节点,将哈希表该位置指向下一个节点。如果目标元素在链表中间或末尾,将前一个节点的指针指向当前节点的下一个节点。释放被删除节点的内存,减少元素计数。
- 返回结果:如果找到并删除了目标元素,返回 true;否则,遍历结束后返回 false,表示未找到目标元素。
具体代码如下:
bool erase(const K& k)
{Hash h;int hashi = h(k) % _table.size();Node* prev = nullptr;Node* cur = _table[hashi];while (cur){if (cur->_kv.first == k){//删除if (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;
}
哈希表的查找:
步骤如下:
- 计算哈希值:使用哈希函数计算键的哈希值,并取模计算出其在哈希表中的索引位置。
- 遍历链表: 从计算出的索引位置开始,遍历链表,查找目标元素。
- 检查节点:如果当前节点不为空,检查当前节点的键是否等于目标键。
如果找到目标键,返回 true,表示键存在。如果当前节点的键不等于目标键,继续遍历下一个节点。 - 返回结果:如果遍历链表结束后未找到目标键,返回 false,表示键不存在。
具体代码如下:
bool find(const K& k)
{Hash h;int hashi = h(k) % _table.size();Node* cur = _table[hashi];while (cur){if (cur->_kv.first == k){return true;}cur = cur->_next;}return false;
}
思考: 哈希函数采用处理余数法,被模的key必须要为整形才可以处理,而上面实现的hash表只能存储key为整形的元素,其他类型怎么解决?
要解决哈希表存储非整型键的问题,常见的做法是设计适用于各种键类型的哈希函数。这可以通过定义模板类和泛型哈希函数来实现,允许哈希表存储不同类型的键(如字符串、对象等)。
解决方案
- 模板类和泛型哈希函数:使用模板类定义哈希表,使其能够接受不同类型的键。为不同类型的键定义特定的哈希函数。模板特化和偏特化:对于标准类型(如整数、字符串等),可以定义特化的哈希函数。
- 对于自定义对象,可以重载哈希函数或者提供自定义哈希函数对象。
可以看到上面实现的hash表的第三个类模板参数可以接收使用者传的自定义哈希函数对象,来将key转换成整型。这个是字符串哈希算法(点击即可跳转)有兴趣的可以自己研究一下。
这里直接给出我的解决方案代码:
template<class K>
struct HashFuc
{unsigned long operator()(const K& K){return (unsigned long)K;}
};
//模板特化 string版本
template<>
struct HashFuc<string>
{unsigned long operator()(const string& s){unsigned long h = 0, g;for (auto e : s){h = (h << 4) + e;if (g = h & 0xF0000000){h ^= g >> 24;}h &= ~g;}return h;}
};
至此,本片文章就结束了,若本篇内容对您有所帮助,请三连点赞,关注,收藏支持下。
创作不易,白嫖不好,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !!!

相关文章:
哈希表(C++实现)
文章目录 写在前面1. 哈希概念2. 哈希冲突3. 哈希函数4.哈希冲突解决4.1 闭散列4.1.1 线性探测4.1.2 采用线性探测的方式解决哈希冲突实现哈希表4.1.3 二次探测 4.2 开散列4.2.2 采用链地址法的方式解决哈希冲突实现哈希表 写在前面 在我们之前实现的所有数据结构中(比如&…...
及其实际应用)
深入理解代理模式(Proxy Pattern)及其实际应用
引言 在软件开发中,有时候我们需要在不改变现有代码的情况下添加一些功能,比如延迟初始化、访问控制、日志记录等。代理模式(Proxy Pattern)通过代理对象控制对原对象的访问,为现有代码添加了额外的功能。本篇文章将详…...

Elasticsearch (1):ES基本概念和原理简单介绍
Elasticsearch(简称 ES)是一款基于 Apache Lucene 的分布式搜索和分析引擎。随着业务的发展,系统中的数据量不断增长,传统的关系型数据库在处理大量模糊查询时效率低下。因此,ES 作为一种高效、灵活和可扩展的全文检索…...
【Python爬虫】Python爬取喜马拉雅,爬虫教程!
一、思路设计 (1)分析网页 在喜马拉雅主页找到自己想要的音频,得到目标URL:https://www.ximalaya.com/qinggan/321787/ 通过分析页面的网络抓包,最终的到一个比较有用的json数据包 通过分析,得到了发送json…...

基于Jmeter的分布式压测环境搭建及简单压测实践
写在前面 平时在使用Jmeter做压力测试的过程中,由于单机的并发能力有限,所以常常无法满足压力测试的需求。因此,Jmeter还提供了分布式的解决方案。本文是一次利用Jmeter分布式对业务系统登录接口做的压力测试的实践记录。按照惯例࿰…...

IDEA常用代码模板
在 IntelliJ IDEA 中,常用代码模板可以帮助你快速生成常用的代码结构和模式。以下是一些常用的代码模板及其使用方法: 动态模板(Live Templates) psvm:生成 public static void main(String[] args) 方法。sout:生成 System.out.println(); 语句。soutv:生成 System.ou…...
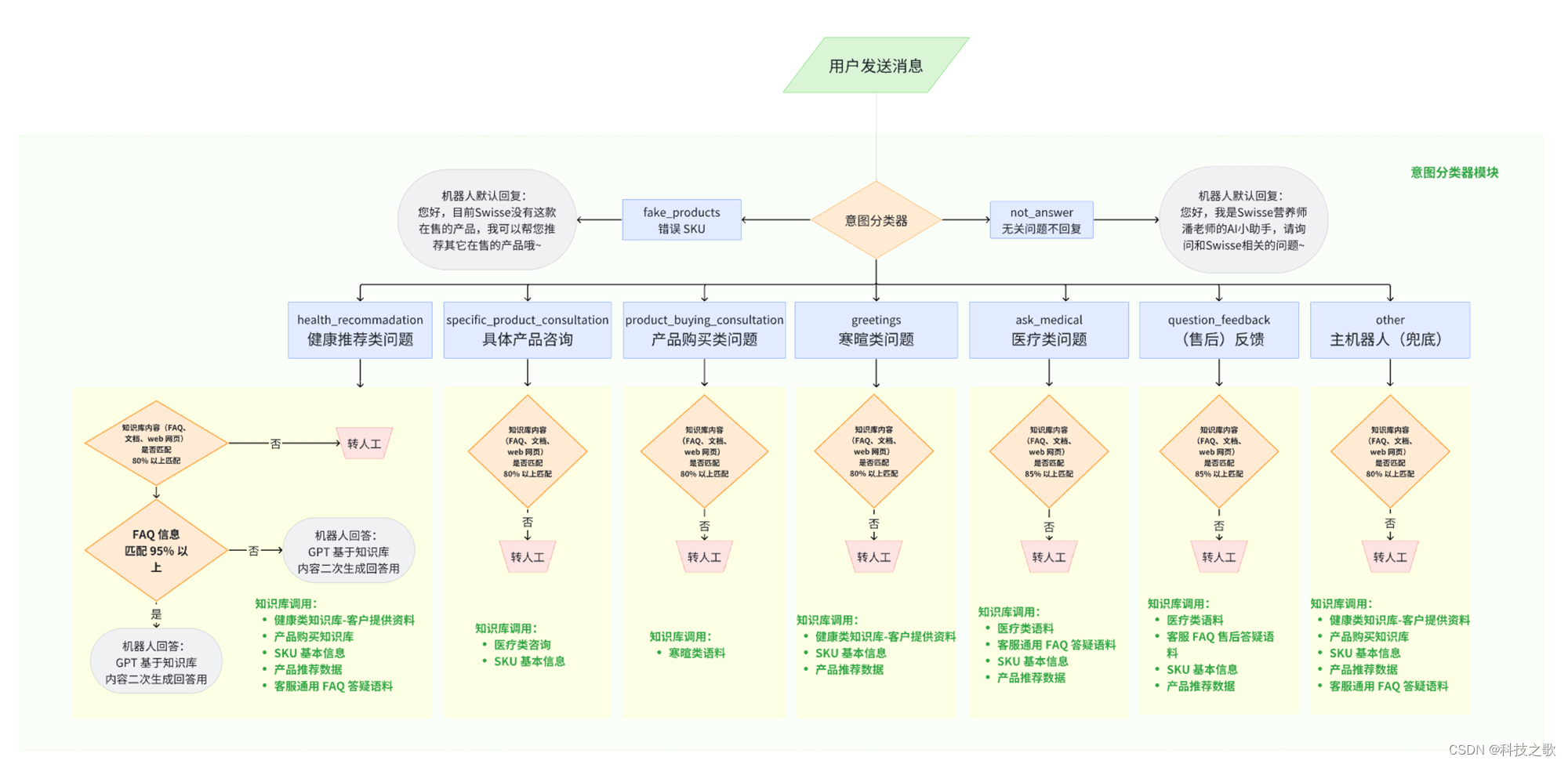
基于大语言模型的多意图增强搜索
随着人工智能技术的蓬勃发展,大语言模型(LLM)如Claude等在多个领域展现出了卓越的能力。如何利用这些模型的语义分析能力,优化传统业务系统中的搜索性能是个很好的研究方向。 在传统业务系统中,数据匹配和检索常常面临…...
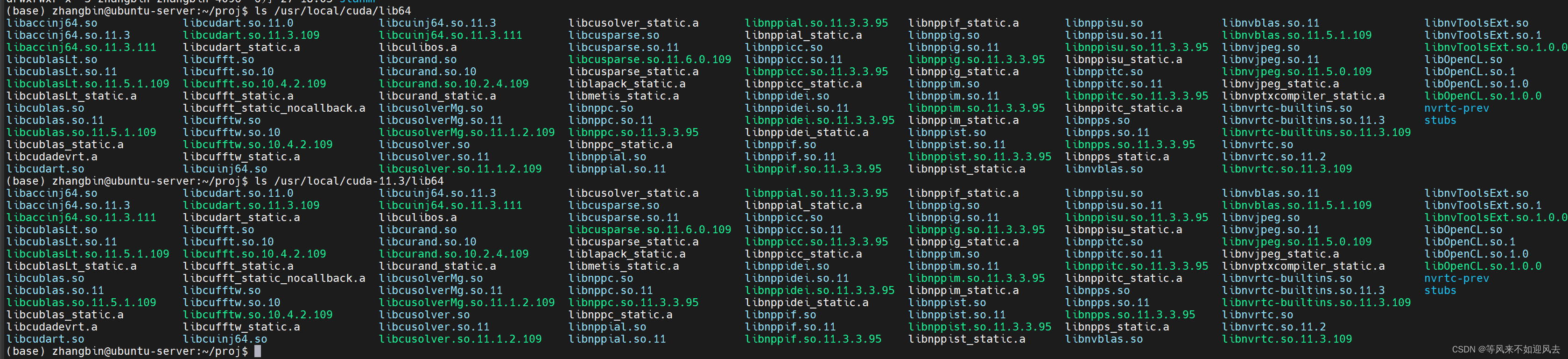
【ai】ubuntu18.04 找不到 nvcc --version问题
nvcc --version显示command not found问题 这个是cuda 库: windows安装了12.5 : 参考大神:解决nvcc --version显示command not found问题 原文链接:https://blog.csdn.net/Flying_sfeng/article/details/103343813 /usr/local/cuda/lib64 与 /usr/local/cuda-11.3/lib64 完…...

深入了解DDoS攻击及其防护措施
深入了解DDoS攻击及其防护措施 分布式拒绝服务(Distributed Denial of Service,DDoS)攻击是当今互联网环境中最具破坏性和普遍性的网络威胁之一。DDoS攻击不仅危及企业的运营,还可能损害其声誉,造成客户信任度的下降。…...

【面试系列】产品经理高频面试题及详细解答
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、…...

前端特殊字符数据,后端接收产生错乱,前后端都需要处理
前端: const data {createTime: "2024-06-11 09:58:59",id: "1800346960914579456",merchantId: "1793930010750218240",mode: "DEPOSIT",channelCode: "if(amount > 50){iugu2pay;} else if(amount < 10){iu…...

力扣热100 哈希
哈希 1. 两数之和49.字母异位词分组128.最长连续序列 1. 两数之和 题目:给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。…...
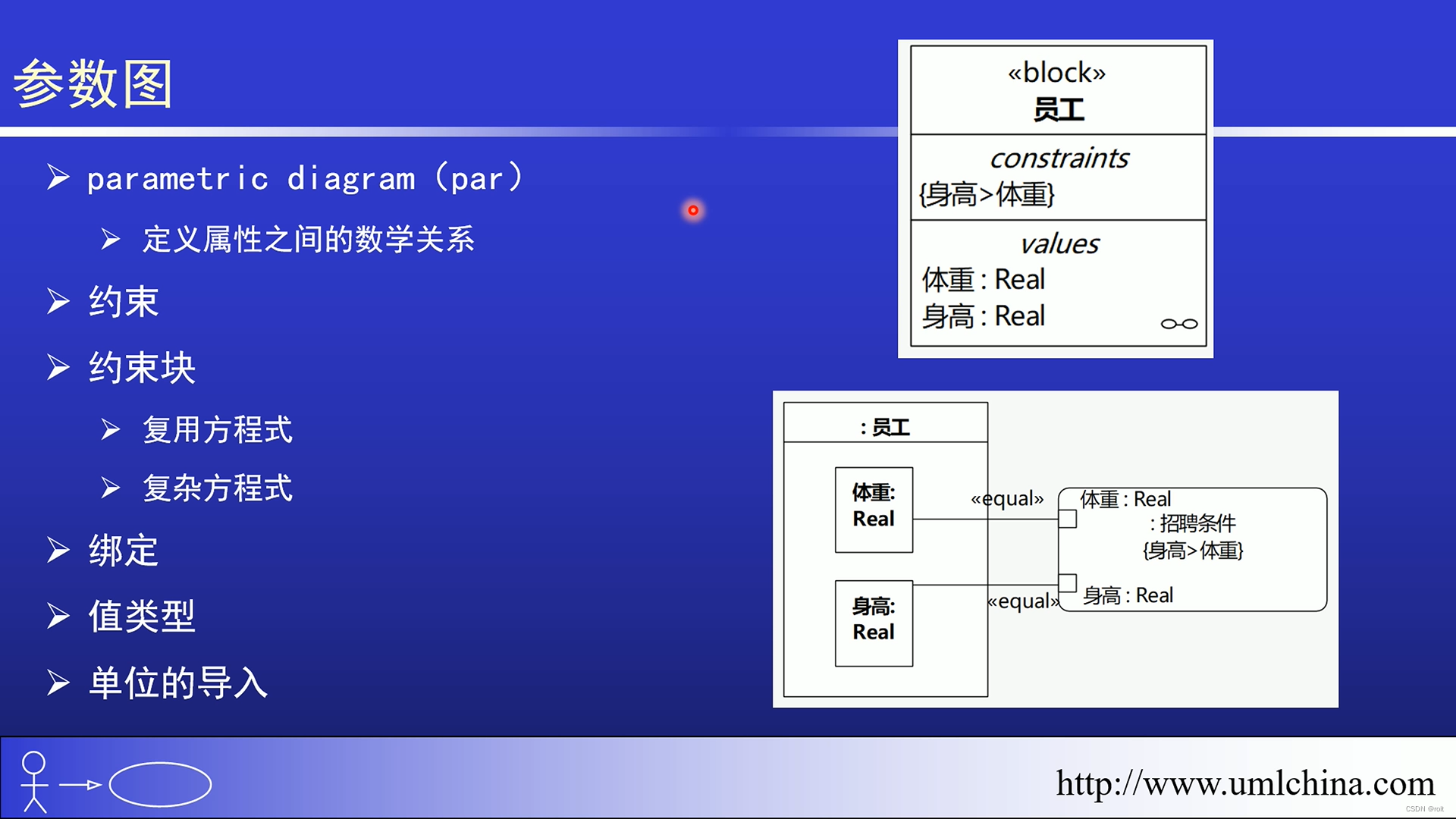
[图解]SysML和EA建模住宅安全系统-05-参数图
1 00:00:01,140 --> 00:00:03,060 这是实数没错,这是分钟 2 00:00:03,750 --> 00:00:07,490 但是你在这里选,选不了的 3 00:00:07,500 --> 00:00:09,930 因为它这里不能够有那个 4 00:00:11,990 --> 00:00:13,850 但是我们前面这里 5 00…...

JavaScript——对象的创建
目录 任务描述 相关知识 对象的定义 对象字面量 通过关键字new创建对象 通过工厂方法创建对象 使用构造函数创建对象 使用原型(prototype)创建对象 编程要求 任务描述 本关任务:创建你的第一个 JavaScript 对象。 相关知识 JavaScript 是一种基于对象&a…...

大二暑假 + 大三上
希望,暑假能早睡早起,胸围达到 95,腰围保持 72,大臂 36,小臂 32,小腿 38🍭🍭 目录 🍈暑假计划 🌹每周进度 🤣寒假每日进度😂 &…...

C语言使用先序遍历创建二叉树
#include<stdio.h> #include<stdlib.h>typedef struct node {int data;struct node * left;struct node * right; } Node;Node * createNode(int val); Node * createTree(); void freeTree(Node * node);void preOrder(Node * node);// 先序创建二叉树 int main()…...

如何在服务器中安装anaconda
文章目录 Step1: 下载 Anaconda方法1:下载好sh文件上传到服务器安装方法2:在线下载 Step2: 安装AnacondaStep3: 配置环境变量Step 4: 激活AnacondaStep4: 检验安装是否成功 Step1: 下载 Anaconda 方法1:下载好sh文件上传到服务器安装 在浏览…...

夸克网盘拉新暑期大涨价!官方授权渠道流程揭秘
夸克网盘拉新暑期活动来袭,价格大涨!从7月1日开始持续两个月,在这两个月里夸克网盘拉新的移动端用户,一个从原来的5元涨到了10元。这对做夸克网盘拉新的朋友来说,真的是福利的。趁着暑期时间多,如果有想做夸…...
机器学习(三)
机器学习 4.回归和聚类算法4.1 线性回归4.1.1 线性回归的原理4.1.2 线性回归的损失和优化原理 4.2 欠拟合与过拟合4.2.1 定义4.2.2 原因以及解决方法4.2.3 正则化 4.3 线性回归改进-岭回归4.3.1 带L2正则化的线性回归-岭回归4.3.2 API 4.4 分类算法-逻辑回归与二分类4.4.1 定义…...
)
PostgreSQL 基本SQL语法(二)
1. SELECT 语句 1.1 基本 SELECT 语法 SELECT 语句用于从数据库中检索数据。基本语法如下: SELECT column1, column2, ... FROM table_name; 例如,从 users 表中检索所有列的数据: SELECT * FROM users; 1.2 使用 WHERE 条件 WHERE 子…...

如何用4个步骤构建你的开源六轴机械臂:完整DIY指南
如何用4个步骤构建你的开源六轴机械臂:完整DIY指南 【免费下载链接】Faze4-Robotic-arm All files for 6 axis robot arm with cycloidal gearboxes . 项目地址: https://gitcode.com/gh_mirrors/fa/Faze4-Robotic-arm Faze4-Robotic-arm是一个开源六轴机械臂…...

Arm Neoverse CMN-650时钟与电源管理架构解析
1. Arm Neoverse CMN-650时钟与电源管理架构解析在现代SoC设计中,时钟与电源管理子系统如同城市的水电供应网络,其设计优劣直接决定了系统性能与能耗效率的平衡。Arm Neoverse CMN-650作为新一代互连架构,通过创新的时钟域划分和电源域管理机…...

基于MCP协议构建Python文档智能查询服务器,提升AI编程助手准确性
1. 项目概述:一个为Python开发者量身定制的文档智能助手如果你和我一样,每天大部分时间都在和Python代码打交道,那你肯定也经历过这样的场景:为了查一个函数的参数顺序,或者确认某个库的版本兼容性,不得不频…...

基于USB HID与CircuitPython的交互式硬件开发实战
1. 项目概述:一个需要你“手摇发电”才能保持屏幕亮度的硬件装置如果你觉得每天盯着手机屏幕的时间太长,想找个物理方式来“惩罚”一下自己的拖延症,或者单纯想体验一下用硬件直接“操控”手机的感觉,那么这个项目正对你的胃口。这…...

ARM JTAG-DP调试端口架构与工程实践解析
1. ARM JTAG-DP调试端口架构解析JTAG调试端口(JTAG-DP)作为ARM CoreSight调试架构的核心组件,为芯片调试提供了标准化访问接口。其设计基于IEEE 1149.1标准,但针对调试场景进行了专门优化。在实际工程中,理解JTAG-DP的工作原理对嵌入式系统调…...

AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册
AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

高光谱图像分类避坑指南:Hughes现象、同物异谱,这些坑你踩过吗?
高光谱图像分类实战避坑手册:从Hughes现象到模型优化的深度解析 当你的高光谱分类模型在验证集上表现优异,却在真实场景中频频失误时,或许正遭遇着这个领域特有的"暗礁"。不同于常规RGB图像分类,高光谱数据特有的图谱合…...

Six Degrees of Wikipedia技术解析:广度优先搜索算法如何连接百万页面
Six Degrees of Wikipedia技术解析:广度优先搜索算法如何连接百万页面 【免费下载链接】sdow Six Degrees of Wikipedia 项目地址: https://gitcode.com/gh_mirrors/sd/sdow Six Degrees of Wikipedia(简称sdow)是一个基于维基百科页面…...

终极指南:如何在Jetson/Raspberry Pi上快速部署CLIP-as-service边缘AI搜索服务 [特殊字符]
终极指南:如何在Jetson/Raspberry Pi上快速部署CLIP-as-service边缘AI搜索服务 🚀 【免费下载链接】clip-as-service 🏄 Scalable embedding, reasoning, ranking for images and sentences with CLIP 项目地址: https://gitcode.com/gh_mi…...

【职场】那些把公司当家的人,最先被扫地出门
那些把公司当家的人,最先被扫地出门“你爱公司爱得越深,离开的时候就摔得越惨。因为公司从一开始,就没打算和你谈感情。”一、那种人,你一定见过 他是第一个到公司的,也是最后一个离开的。 他的工位永远是最乱的那个&a…...