LSH算法:高效相似性搜索的原理与Python实现I
局部敏感哈希(LSH)技术是快速近似最近邻(ANN)搜索中的一个关键方法,广泛应用于实现高效且准确的相似性搜索。这项技术对于许多全球知名的大型科技公司来说是不可或缺的,包括谷歌、Netflix、亚马逊、Spotify和Uber等。
亚马逊通过分析用户间的相似性,依据购买历史向用户推荐新产品。谷歌在用户进行搜索时,实际上是在执行一次相似性搜索,评估搜索词与谷歌索引的互联网内容之间的相似度。而Spotify之所以能够推荐符合用户口味的音乐,是因为它成功地通过相似性搜索算法将用户与品味相似的其他用户进行了匹配。
LSH技术的优势在于它能够在保证搜索速度的同时,提供高质量的搜索结果。这对于处理大规模数据集和实现实时搜索功能至关重要。在本文中,我们将深入探讨LSH算法背后的理论基础,并提供一个易于理解的Python实现示例,帮助读者更好地掌握这一技术。
搜索的复杂性
在处理包含数百万甚至数十亿条数据的数据集时,如何高效地进行样本间比较成为一个巨大挑战。
尝试逐一比较所有样本对是不切实际的,即便在最先进的硬件上。这种方法的时间复杂度为 O ( n 2 ) O(n^2) O(n2),意味着随着数据量的增加,所需的时间和资源将以平方级速度增长。即便是将单个查询与数十亿个样本进行比较,其复杂度也达到 O ( n ) O(n) O(n),这给大型数据集带来了巨大的计算负担。
此外,每个样本通常以高维向量的形式存储,这进一步加剧了计算的复杂性。高维空间中的相似性计算不仅成本高昂,而且效率低下。
面对这些挑战,一个自然的问题是:是否存在一种方法能够实现亚线性复杂度的搜索,即搜索时间不随数据量的线性增长而增长?答案是肯定的。
解决这一问题的关键在于采用近似搜索策略。不必对每个向量进行详尽的比较,而是可以通过近似方法缩小搜索范围,只关注那些最可能相关的向量。
局部敏感哈希(LSH)算法就是这样一种能够提供亚线性搜索时间的技术。它通过将相似的项映射到同一个“桶”或“哈希表”位置,从而快速识别出潜在的最近邻。在本文中,将详细介绍LSH算法,并深入探讨其背后的工作原理。
局部敏感哈希(Locality Sensitive Hashing)
在面对寻找相似向量对的计算复杂性问题时,即便是规模较小的数据集,其所需的计算量也可能变得难以处理。
考虑向量索引的场景,如果要为一个新向量找到一个最接近的匹配,就需要将它与数据库中的所有其他向量进行比较。这种方法的时间复杂度是线性的,这在大型数据集上意味着无法快速完成搜索。
理想情况下,我们只希望比较那些可能匹配的向量,也就是潜在的候选对。为了减少必要的比较次数,局部敏感哈希(LSH)算法应运而生。LSH是一种能够将相似项映射到同一个哈希桶中的技术。它包括多种不同的方法,本文将介绍一种传统方法,包括以下步骤:
- 文档分片(Shingling):将文档分割成多个片段。
- MinHashing:一种用于估计集合相似度的概率算法。
- 带状LSH函数(Banding):最终的LSH函数,用于将向量分割和哈希。
LSH算法的核心在于,当至少一次哈希操作导致两个向量映射到相同的值时,这两个向量就被认为是候选对,即可能是匹配的。
这个过程类似于Python字典中的哈希过程,其中键通过哈希函数处理并映射到特定的桶中,然后将相应的值与这个桶关联起来。
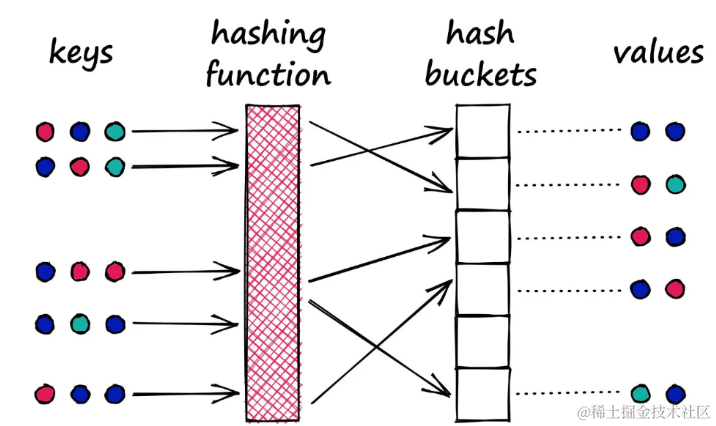
典型的哈希函数:旨在将不同的值(无论多么相似)放入不同的桶中
然而,LSH中使用的哈希函数与传统字典中的哈希函数有一个重要的区别:
在字典中,目标是尽量减少多个键映射到同一个桶的情况,以降低冲突。而LSH的理念恰恰相反,它希望最大化冲突,但这种冲突理想情况下只发生在相似的输入上。
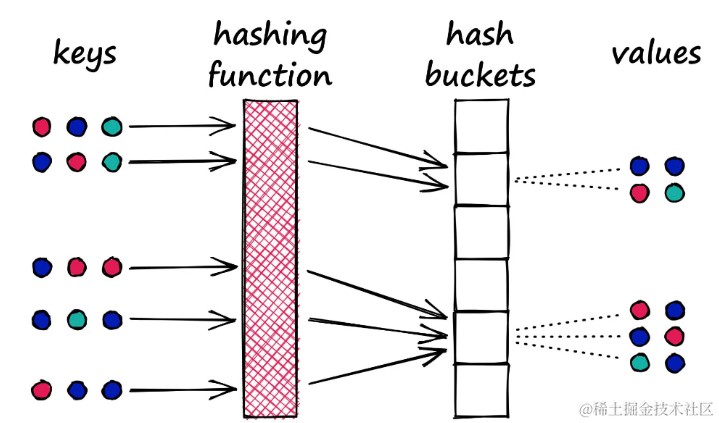
LSH的哈希函数:目标是将相似的值放入同一个桶中
LSH中的哈希方法并不是唯一的。尽管它们都遵循通过哈希函数将相似样本放入同一个桶的基本逻辑,但它们在具体实现上可以有很大的差异。在本文中介绍的是传统方法,它包括文档分片(shingling),MinHashing和带状划分(banding)这几个步骤。
Shingling, MinHashing, LSH
局部敏感哈希(LSH)方法涵盖了三个关键步骤,用于高效地识别大规模数据集中的相似项。
- 首先使用k-shingling将文本转换为稀疏向量
- 然后通过MinHashing创建“签名”
- 最后利用LSH过程筛选出候选对
本文将详细介绍这一流程
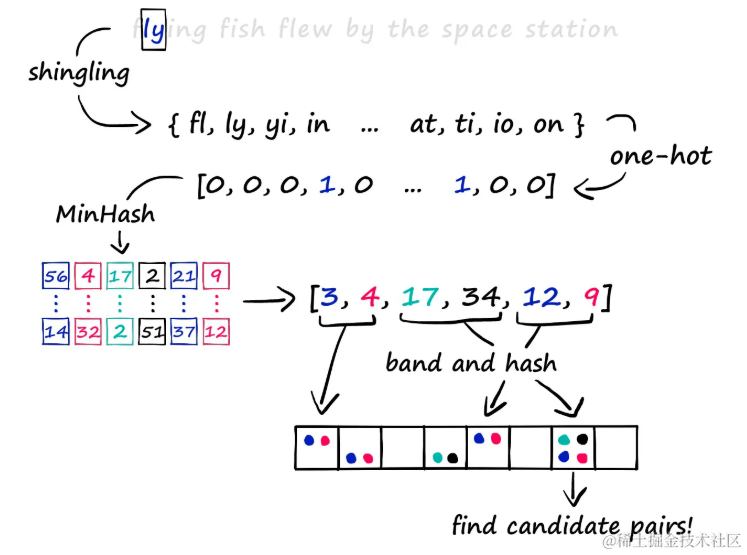
k-Shingling:文本到shingles的转换
k-Shingling 是一种将文本字符串转换为一组“shingles”(片段)的方法。这个过程类似于在文本上滑动一个长度为k的窗口,并在每一步记录下窗口内的内容。通过这种方法,可以得到文本的shingles集合。

在Python中,可以创建一个简单的k-shingling函数,如下所示:
a = "flying fish flew by the space station"
b = "we will not allow you to bring your pet armadillo along"
c = "he figured a few sticks of dynamite were easier than a fishing pole to catch fish"def shingle(text: str, k: int=2):shingle_set = []for i in range(len(text) - k+1):shingle_set.append(text[i:i+k])return set(shingle_set)a = shingle(a, k)
b = shingle(b, k)
c = shingle(c, k)
print(a)# {'y ', 'pa', 'ng', 'yi', 'st', 'sp', 'ew', 'ce', 'th', 'sh', 'fe', 'e ', 'ta', 'fl', ' b', 'in', 'w ', ' s', ' t', 'he', ' f', 'ti', 'fi', 'is', 'on', 'ly', 'g ', 'at', 'by', 'h ', 'ac', 'io'}
有了的shingles后创建稀疏向量,需要将所有集合合并为一个包含所有集合中所有shingles的大集合词汇表(或vocab)。
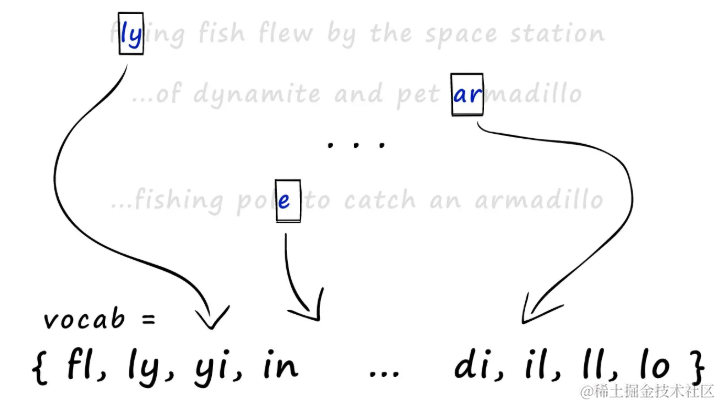
所有 shingle 集合合并后,创建了词汇表(vocab)。
使用这个词汇表,为每个集合创建稀疏向量。具体来说,在词汇表长度上创建一个全零向量,然后检查哪些 shingle 出现在集合中,将相应位置的值设为 1。
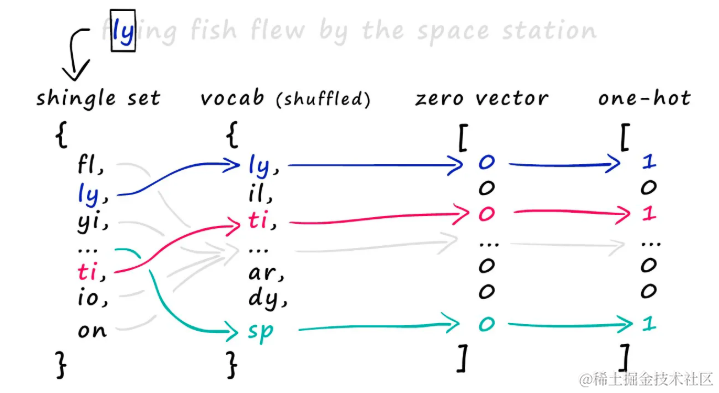
为了创建 one-hot 编码,将单个 shingle 集与词汇表匹配,确定在零向量中应该放置 1 的位置。 对于每个出现的 shingle,找到它在词汇表中的位置,并将对应的零向量位置设置为 1,这就是one-hot 编码的方式。
Minhashing
MinHashing签名是通过将稀疏向量转换为密集的数值向量来创建的。这个过程涉及到以下几个关键步骤:
- 生成随机排列的计数向量:首先,创建一个从1到词汇表长度的计数向量,并对其进行随机排列。这个排列的向量将用于后续的MinHashing计算。
- 对齐稀疏向量中的1:接着,对于稀疏向量中的每个1,需要找到与之对齐的最小排列数字。这个数字将作为签名中的一个值。
通过一个具体的例子来说明这个过程:
- 假设有一个较小的词汇表,包含6个值,这有助于可视化MinHashing的过程。
- 从词汇表中随机排列计数向量,例如:
[5, 1, 3, 2, 4, 6]。 - 然后,检查稀疏向量中的每个位置,看是否存在对应的shingle。如果存在,对应的稀疏向量值为1;如果不存在,则为0。
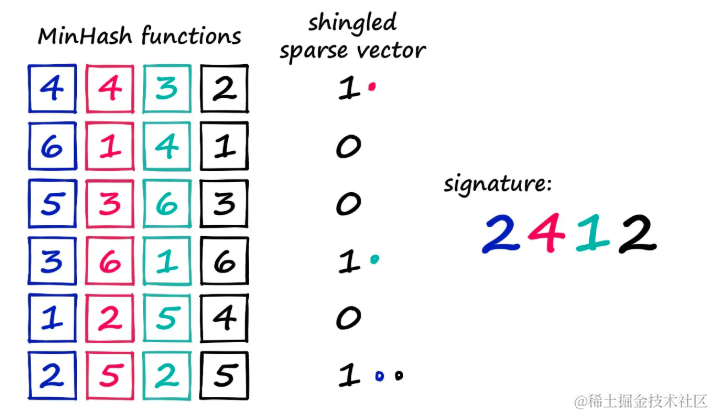
在这里,使用四个 minhash 函数/向量来创建一个四位数的签名向量。如果你在每个 minhash 函数中从 1 开始计数,并找出与稀疏向量中的 1 对齐的第一个值——你会得到 2412。通过这种方式,可以为稀疏向量中的每个1生成一个MinHash值。为了创建完整的MinHash签名,需要为签名中的每个位置分配一个不同的MinHash函数,并重复上述过程多次。下面用代码实现它。有三个步骤:
- 生成一个随机化的minhash向量
vocab = a.union(b).union(c)
hash_ex = list(range(1, len(vocab)+1))from random import shuffleshuffle(hash_ex)
- 遍历这个随机的 MinHash 向量(从 1 开始),将每个值的索引与稀疏向量 a_1hot 中的等效值进行匹配。如果找到 1,该索引就是签名值。
a_1hot = [1 if i in a else 0 for i in vocab]
b_1hot = [1 if i in b else 0 for i in vocab]
c_1hot = [1 if i in c else 0 for i in vocab]
print(f"7 -> {hash_ex.index(7)}")for i in range(1, 5):print(f"{i} -> {hash_ex.index(i)}")for i in range(1, len(vocab)+1):idx = hash_ex.index(i)signature_val = a_1hot[idx]print(f"{i} -> {idx} -> {signature_val}")if signature_val == 1:print('match!')break
1 -> 58 -> 0
2 -> 19 -> 0
3 -> 96 -> 0
4 -> 92 -> 0
5 -> 83 -> 0
6 -> 98 -> 1
match!
- 通过多次迭代构建签名
def create_hash_func(size: int):# 创建哈希向量/函数hash_ex = list(range(1, len(vocab)+1))shuffle(hash_ex)return hash_exdef build_minhash_func(vocab_size: int, nbits: int):# 创建多个minhash向量hashes = []for _ in range(nbits):hashes.append(create_hash_func(vocab_size))return hashes# 创建20个minhash向量
minhash_func = build_minhash_func(len(vocab), 20)def create_hash(vector: list):# 用于创建签名的函数signature = []for func in minhash_func:for i in range(1, len(vocab)+1):idx = func.index(i)signature_val = vector[idx]if signature_val == 1:signature.append(idx)breakreturn signature# 创建签名
b_1hot = [1 if i in b else 0 for i in vocab]
c_1hot = [1 if i in c else 0 for i in vocab]a_sig = create_hash(a_1hot)
b_sig = create_hash(b_1hot)
c_sig = create_hash(c_1hot)print(a_sig)
print(b_sig)
# [70, 19, 84, 88, 112, 46, 54, 75, 68, 15, 15, 85, 94, 93, 51, 29, 75, 68, 110, 108]
# [62, 14, 106, 80, 57, 114, 62, 12, 127, 39, 121, 104, 14, 23, 2, 127, 12, 33, 45, 45]
MinHashing的原理并不复杂,通过上述步骤已经将稀疏向量压缩成一个包含 20 个数字的密集签名。
从稀疏向量到签名的信息传递
一个关键问题是,当我们从原始的稀疏向量转换到MinHash签名时,是否保留了足够的信息以进行有效的相似性比较。为了验证这一点,我们可以计算原始向量和签名向量之间的Jaccard相似性。Jaccard 相似性是通过比较两个集合的交集与并集的大小来衡量它们之间的相似度的指标。可以首先使用原始的shingle集合来计算Jaccard相似性,然后对相应的MinHash签名进行相同的计算。
def jaccard(a: set, b: set):return len(a.intersection(b)) / len(a.union(b))print(jaccard(a, b), jaccard(set(a_sig), set(b_sig)))
# 0.02531645569620253, 0.0print(jaccard(a, c), jaccard(set(a_sig), set(c_sig)))
# 0.10309278350515463, 0.030303030303030304print(jaccard(b, c), jaccard(set(b_sig), set(c_sig)))
# 0.043478260869565216, 0.03225806451612903
通过比较原始shingle集合和MinHash签名集合的Jaccard相似性,可以评估信息在转换过程中的保留程度。如果签名集合的相似性与原始集合的相似性相近,则表明MinHash签名有效地保留了原始稀疏向量中的相似性信息。
带状划分和哈希
在局部敏感哈希(LSH)的最后阶段,采用带状划分的方法来处理签名向量。这种方法将签名划分为多个片段,并对每个片段进行哈希处理,以寻找哈希冲突。

带状划分通过将向量分割成称为“带”的子部分来解决直接哈希整个向量可能带来的问题。这种方法允许识别向量之间的匹配子向量,即使整个向量并不完全相同。
直接对整个向量进行哈希可能难以构建能准确识别它们相似性的哈希函数。不需要整个向量相等,只需要部分相似即可。带状划分提供了一种灵活的条件——只要有任何两个子向量碰撞,就将相应的全向量视为候选对。
带状划分的工作原理
带状方法通过将向量分割成称为带(b)的子部分来解决这个问题,然后将每个子向量通过哈希函数处理。
假设将一个100维的向量分成20个带,这提供了20次机会来识别向量之间的匹配子向量。每个子向量通过哈希函数处理并映射到一个哈希桶中。
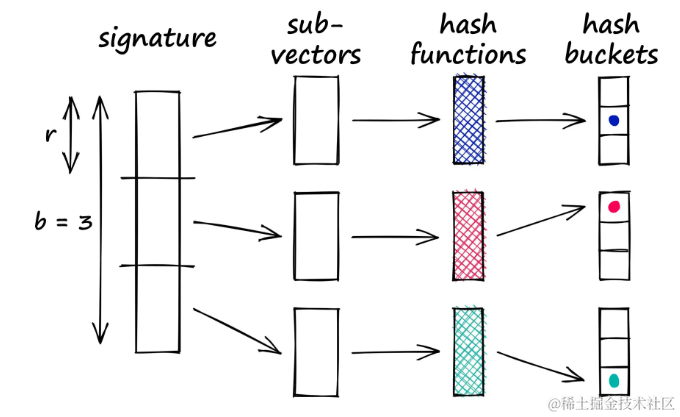
将签名分割成b个子向量,每个子向量通过哈希函数处理并映射到一个哈希桶中,只要有任何两个子向量碰撞,就将相应的全向量视为候选对。
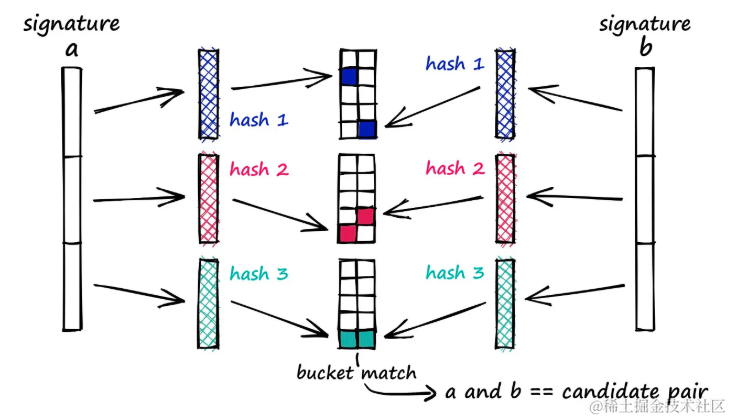
所有签名中的等效子向量必须通过相同的哈希函数处理,可以为所有子向量使用一个哈希函数。
可以用Python实现一个简单的版本。首先,从分割签名向量a, b, 和c开始:
def split_vector(signature, b):assert len(signature) % b == 0r = int(len(signature) / b)# code splitting signature in b partssubvecs = []for i in range(0, len(signature), r):subvecs.append(signature[i : i+r])return subvecsband_a = split_vector(a_sig, 10)
band_b = split_vector(b_sig, 10)
band_c = split_vector(c_sig, 10)
print(band_c)
[[30, 60],[84, 125],[135, 90],[130, 107],[76, 16],[44, 119],[109, 135],[30, 76],[95, 33],[41, 32]]
然后循环遍历列表来识别子向量之间的匹配。如果找到匹配项,会将这些向量作为候选对。
for b_rows, c_rows in zip(band_b, band_c):if b_rows == c_rows:print(f"Candidate pair: {b_rows} == {c_rows}")breakfor a_rows, b_rows in zip(band_a, band_b):if a_rows == b_rows:print(f"Candidate pair: {a_rows} == {b_rows}")breakfor a_rows, c_rows in zip(band_a, band_c):if a_rows == c_rows:print(f"Candidate pair: {b_rows} == {c_rows}")break
测试LSH
目前构建的实现非常低效。如果要实现LSH,应该使用专为相似性搜索设计的库,比如Faiss等。
尽管如此,通过编写代码的方式可以更清楚地了解LSH的工作原理。接下来,将使用更多的数据来重复这个过程,并使用NumPy重写代码。
获取数据
首先,需要获取数据。
import requests
import pandas as pd
import iourl = "https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/sick2014/SICK_train.txt"text = requests.get(url).textdata = pd.read_csv(io.StringIO(text), sep='\t')
data.head()def build_shingles(sentence: str, k: int):shingles = []for i in range(len(sentence) - k):shingles.append(sentence[i:i+k])return set(shingles)def build_vocab(shingle_sets: list):# convert list of shingle sets into single setfull_set = {item for set_ in shingle_sets for item in set_}vocab = {}for i, shingle in enumerate(list(full_set)):vocab[shingle] = ireturn vocabdef one_hot(shingles: set, vocab: dict):vec = np.zeros(len(vocab))for shingle in shingles:idx = vocab[shingle]vec[idx] = 1return veck = 8 # shingle size# build shingles
shingles = []
for sentence in sentences:shingles.append(build_shingles(sentence, k))# build vocab
vocab = build_vocab(shingles)# one-hot encode our shingles
shingles_1hot = []
for shingle_set in shingles:shingles_1hot.append(one_hot(shingle_set, vocab))
# stack into single numpy array
shingles_1hot = np.stack(shingles_1hot)
shingles_1hot.shape
# (4500, 36466)
转换成独热编码, shingles_1hot 数组包含500个稀疏向量,其中每个向量的长度为词汇表的大小。
MinHashing
接下来,使用minhashing将稀疏向量压缩为密集向量“签名”。
def minhash_arr(vocab: dict, resolution: int):length = len(vocab.keys())arr = np.zeros((resolution, length))for i in range(resolution):permutation = np.random.permutation(len(vocab)) + 1arr[i, :] = permutation.copy()return arr.astype(int)def get_signature(minhash, vector):# get index locations of every 1 value in vectoridx = np.nonzero(vector)[0].tolist()# use index locations to pull only +ve positions in minhashshingles = minhash[:, idx]# find minimum value in each hash vectorsignature = np.min(shingles, axis=1)return signaturearr = minhash_arr(vocab, 100)signatures = []for vector in shingles_1hot:signatures.append(get_signature(arr, vector))# merge signatures into single array
signatures = np.stack(signatures)
signatures.shape
# (4500, 100)
将稀疏向量从长度缩短到长度为100的签名,尽管这种压缩是大幅度的,但它很好地保留了相似性信息。
LSH
在这里使用 Python 字典来散列并存储候选对:
from itertools import combinationsclass LSH:buckets = []counter = 0def __init__(self, b):self.b = bfor i in range(b):self.buckets.append({})def make_subvecs(self, signature):l = len(signature)assert l % self.b == 0r = int(l / self.b)# break signature into subvectorssubvecs = []for i in range(0, l, r):subvecs.append(signature[i:i+r])return np.stack(subvecs)def add_hash(self, signature):subvecs = self.make_subvecs(signature).astype(str)for i, subvec in enumerate(subvecs):subvec = ','.join(subvec)if subvec not in self.buckets[i].keys():self.buckets[i][subvec] = []self.buckets[i][subvec].append(self.counter)self.counter += 1def check_candidates(self):candidates = []for bucket_band in self.buckets:keys = bucket_band.keys()for bucket in keys:hits = bucket_band[bucket]if len(hits) > 1:candidates.extend(combinations(hits, 2))return set(candidates)b = 20lsh = LSH(b)for signature in signatures:lsh.add_hash(signature)
lsh.buckets 为每个带包含一个单独的字典,不同带之间不会混合存储桶。在存储桶中存储向量 ID(行号),因此提取候选对时,只需遍历所有存储桶并提取对。
candidate_pairs = lsh.check_candidates()
len(candidate_pairs)
# 7327list(candidate_pairs)[:5]
# [(1063, 1582), (112, 1503), (114, 2393), (2685, 2686), (3197, 3198)]
识别出候选对后,将仅对这些对进行相似性计算,发现有些对会落在相似性阈值内,而其他的则不会。
目标是缩小搜索范围并降低复杂度,同时保持高准确性。可以通过测量候选对分类(1或0)与实际余弦(或杰卡德)相似性来可视化性能。
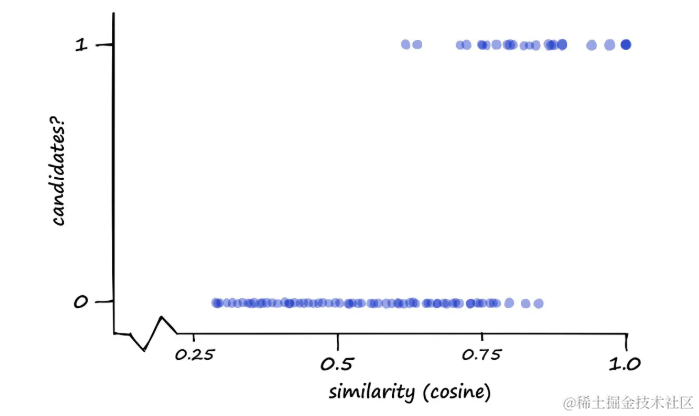
图表显示了候选对(1)和非候选对(0)相对于成对签名的余弦相似性的分布
优化波段值
在局部敏感哈希(LSH)中,波段值b是一个关键参数,它决定了相似性阈值,即LSH函数将数据点从非候选对转换为候选对的界限。通过调整b,可以改变LSH函数的敏感度,从而影响搜索结果的质量和召回率。
可以通过以下公式来形式化概率与相似性之间的关系:
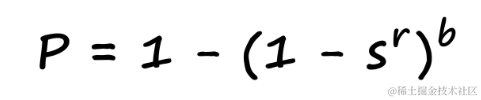
其中,s表示相似性得分,b表示波段数量,r表示每个波段中的行数。这个公式帮助我们理解在给定的b和r值下,一对数据点被识别为候选对的概率。
通过可视化概率-相似性关系,可以观察到一个明显的模式:
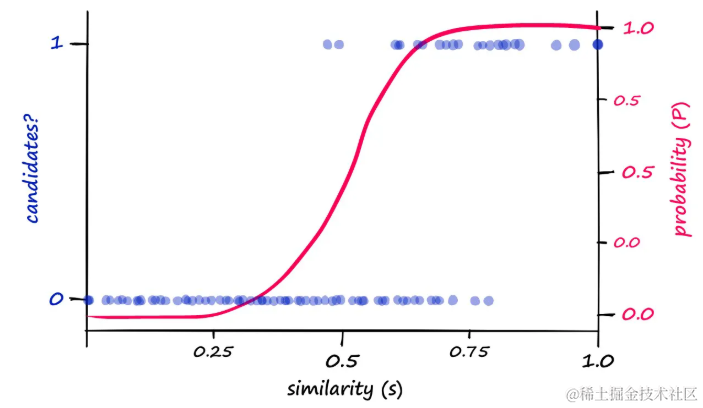
- 候选分类(左侧y轴)和计算出的概率P(右侧y轴)相对于相似性(计算出的或归一化的余弦相似性)。
- 在
b和r值分别为20和5的情况下,可以看到计算出的概率P和相似性s值指示了候选/非候选对的一般分布
尽管理论计算出的概率与真正的候选对结果之间存在相关性,但对齐并不完美。通过修改b值,可以推动在不同相似性得分下返回候选对的概率向左或向右移动。
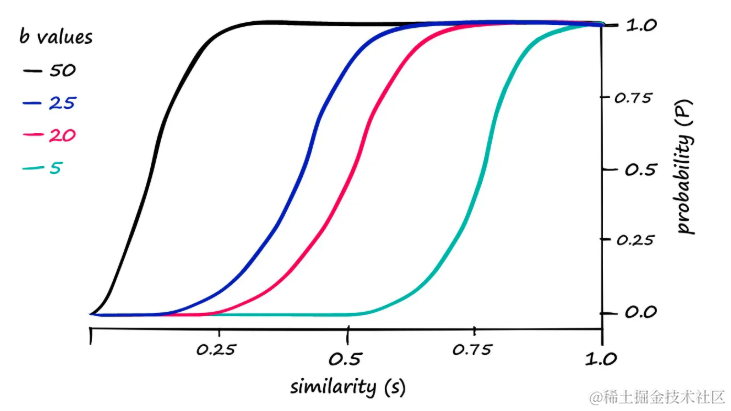
计算出的概率P相对于不同b值的相似性s。r是len(signature) / b(在这种情况下len(signature) == 100)。
例如,如果发现当b == 20时,需要较高的相似性才能将对计算为候选对,可以尝试增加b值以降低相似性阈值。当b值调整为25时,可以观察到以下变化:
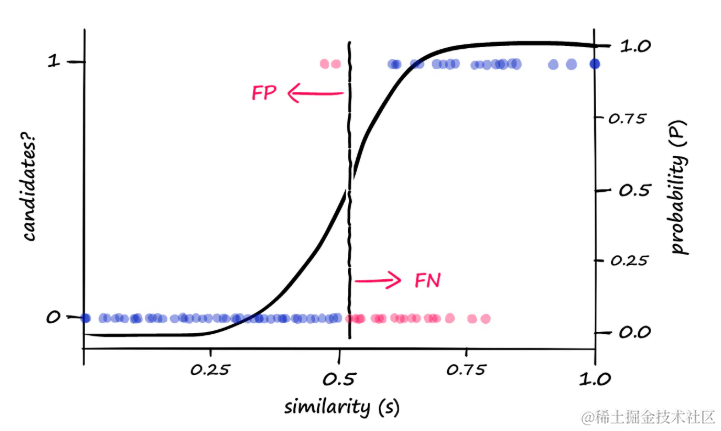
当b == 25时,真实结果和模拟结果分别用蓝色和洋红色显示。与之前的LSH结果相比,增加
b值导致产生了更多的候选对
由于返回了更多的候选对,这会在不相似的向量上产生更多误报。可以将其可视化为:
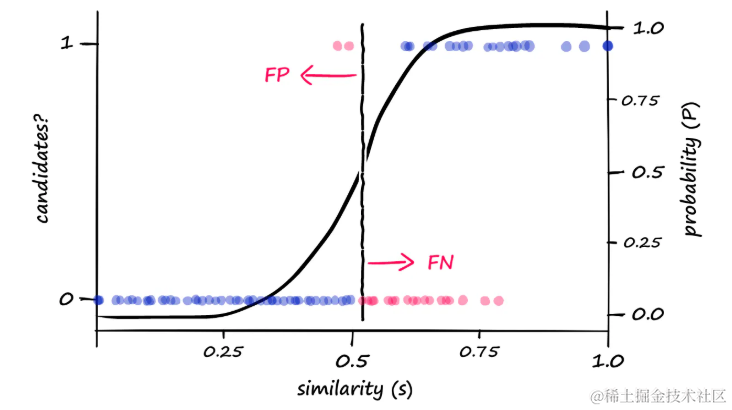
增加
b值会自然地导致更多的候选对被返回,这可能会增加误报(FP)的数量,同时减少漏报(FN)
通过从头开始构建LSH流程并调整相似性阈值,能够优化搜索结果的质量和召回率。本文不仅介绍了LSH的基本原理,还涵盖了分片(shingling)和MinHash函数的概念。在实际应用中,我们可能会倾向于使用专门为相似性搜索设计的库来实现LSH,以提高效率和准确性。
总结
本文介绍了局部敏感哈希(LSH)技术,这是一种在相似性搜索中实现快速且准确搜索的关键技术。LSH被广泛应用于谷歌、Netflix等大型科技公司。文章详细探讨了LSH的工作原理,包括shingling、MinHashing以及带状划分和哈希等步骤。通过这些技术,LSH能够在保持搜索速度的同时,提供高质量的搜索结果。最后,通过Python示例展示了LSH的实现过程,并讨论了如何通过调整波段值来优化LSH函数的相似性阈值。
参考
- https://youtu.be/e_SBq3s20M8
- locality-sensitive-hashing
- jupyter notebook
- Mining of Massive Datasets
相关文章:
LSH算法:高效相似性搜索的原理与Python实现I
局部敏感哈希(LSH)技术是快速近似最近邻(ANN)搜索中的一个关键方法,广泛应用于实现高效且准确的相似性搜索。这项技术对于许多全球知名的大型科技公司来说是不可或缺的,包括谷歌、Netflix、亚马逊、Spotify…...

cesium 添加 Echarts图层(人口迁徒图)
cesium 添加 Echarts 人口迁徒图(下面附有源码) 1、实现思路 1、在scene上面新增一个canvas画布 2、通坐标转换,将经纬度坐标转为屏幕坐标来实现 3、将ecarts 中每个series数组中元素都加 coordinateSystem: ‘cesiumEcharts’ 2、示例代码 <!DOCTYPE html> <ht…...

Windows下快速安装Open3D-0.18.0(python版本)详细教程
目录 一、Open3D简介 1.1主要用途 1.2应用领域 二、安装Open3D 2.1 激活环境 2.2 安装open3d 2.3测试安装是否成功 三、测试代码 3.1 代码 3.2 显示效果 一、Open3D简介 Open3D 是一个强大的开源库,专门用于处理和可视化3D数据,如点云、网格和…...
无法下载 https://mirrors./ubuntu/dists/bionic/main/binary-arm64/Packages
ubuntu系统执行sudo apt update命令的时候,遇到如下问题: 忽略:82 https://mirrors.tuna.tsinghua.edu.cn/ubuntu bionic-backports/universe arm64 Packages 错误:81 https://mirrors.tuna.tsinghua.edu.cn/ubuntu bionic-backports/main arm64 Packa…...
最新CRMEB商城多商户java版源码v1.6版本+前端uniapp
CRMEB 开源商城系统Java版,基于JavaVueUni-app开发,在微信公众号、小程序、H5移动端都能使用,代码全开源无加密,独立部署,二开很方便,还支持免费商用,能满足企业新零售、分销推广、拼团、砍价、…...
【开发环境】MacBook M2安装git并拉取gitlab项目,解决gitlab出现Access Token使用无效的方法
文章目录 安装Homebrew安装git打开IDEA配置git打开IDEA拉取项目 安装Homebrew /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"在iTerm等命令行工具打开后,输入上面的命令 之后根据中文提示完成Homebrew的下载…...

Flask-Session使用Redis
Flask-Session使用Redis 一、介绍 在Flask中,session数据默认是以加密的cookie形式存储在用户的浏览器中的。但是,真正的session数据应该存储在服务器端。Django框架会将session数据存储在数据库的djangosession表中,而Flask则可以通过第三…...
Redis缓存管理机制
在当今快节奏的数字世界中,性能优化对于提供无缝的用户体验至关重要。缓存在提高应用程序性能方面发挥着至关重要的作用,它通过将经常使用或处理的数据存储在临时高速存储中来减少数据库负载并缩短响应时间,从而减少系统的延迟。Redis 是一种…...
初学嵌入式是弄linux还是单片机?
在开始前刚好我有一些资料,是我根据网友给的问题精心整理了一份「单片机的资料从专业入门到高级教程」, 点个关注在评论区回复“666”之后私信回复“666”,全部无偿共享给大家!!!1、先入门了51先学了89c52…...
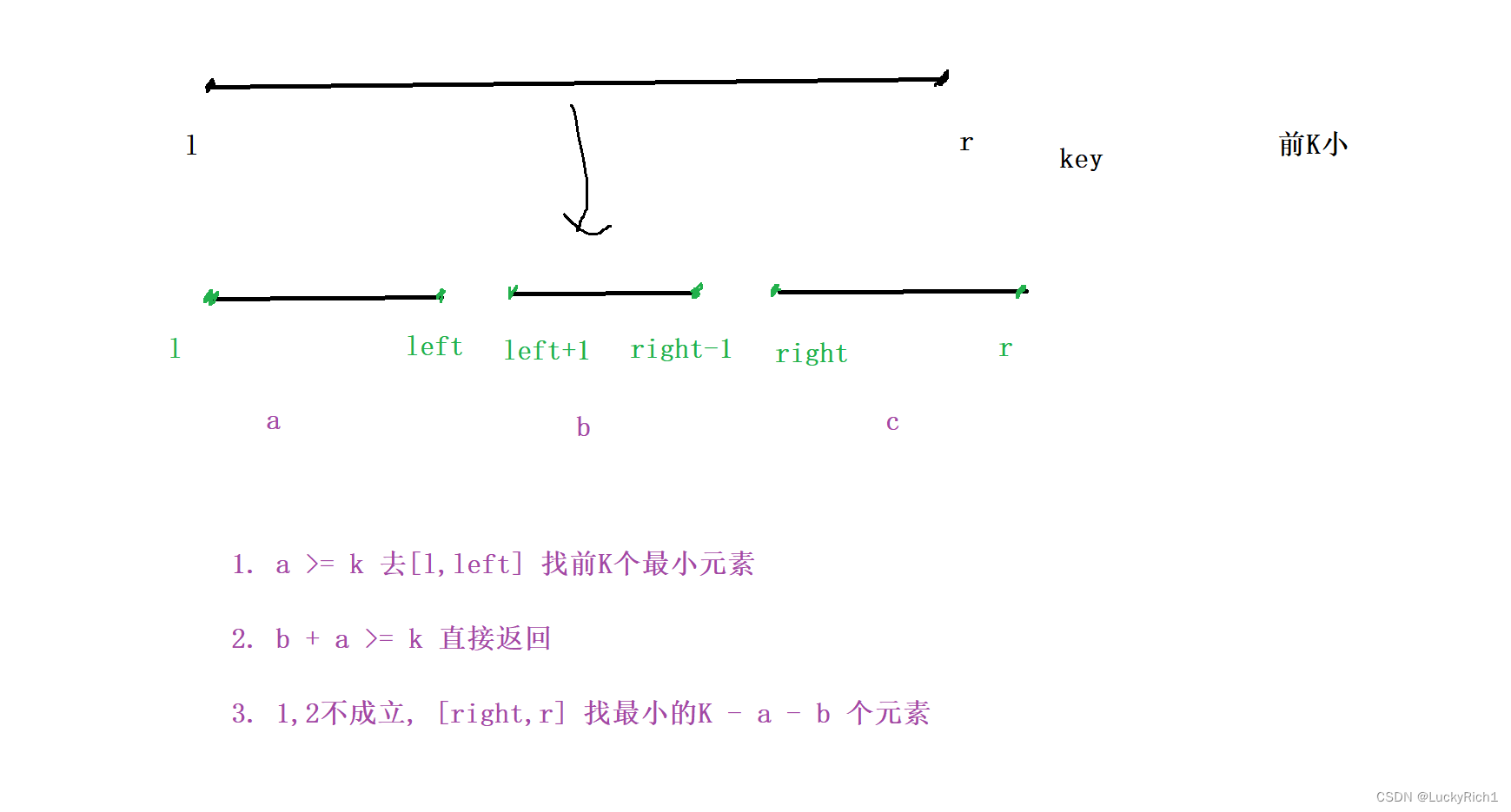
【基础算法总结】分治—快排
分治—快排 1.分治2.颜色分类3.排序数组4.数组中的第K个最大元素5.库存管理 III 点赞👍👍收藏🌟🌟关注💖💖 你的支持是对我最大的鼓励,我们一起努力吧!😃😃 1.分治 分治…...
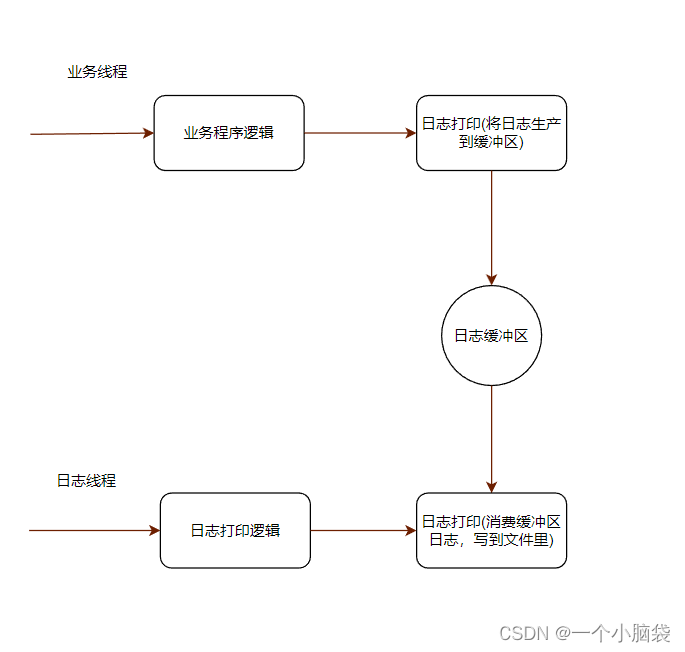
[C++]——同步异步日志系统(1)
同步异步日志系统 一、项⽬介绍二、开发环境三、核心技术四、环境搭建五、日志系统介绍5.1 为什么需要日志系统5.2 日志系统技术实现5.2.1 同步写日志5.2.2 异步写日志 日志系统: 日志:程序在运行过程中,用来记录程序运行状态信息。 作用&…...

python 第6册 辅助excel 002 批量创建非空白的 Excel 文件
---用教授的方式学习 此案例主要通过使用 while 循环以及 openpyxl. load_workbook()方法和 Workbook 的 save()方法,从而实现在当前目录中根据已经存在的Excel 文件批量创建多个非空白的Excel 文件。当运行此案例的Python 代码(A002.py 文件࿰…...
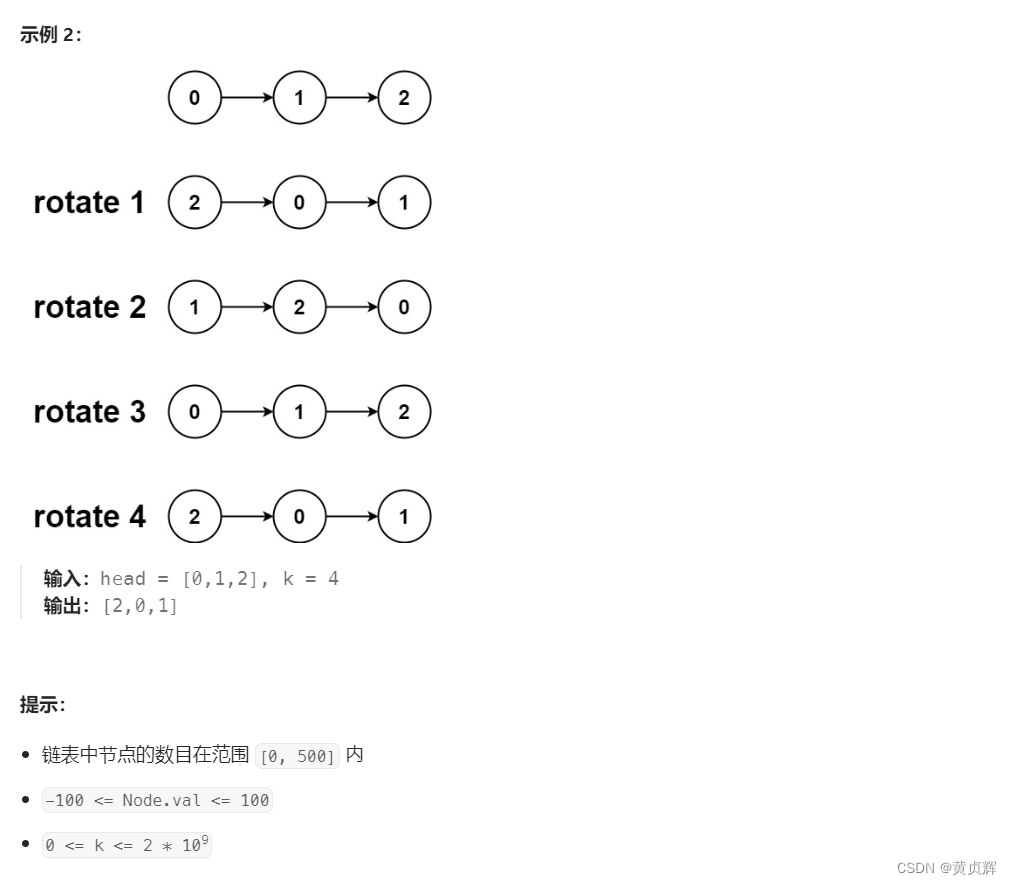
力扣61. 旋转链表(java)
思路:用快慢指针找到最后链表k个需要移动的节点,然后中间断开节点,原尾节点连接原头节点,返回新的节点即可; 但因为k可能比节点数大,所以需要先统计节点个数,再取模,看看k到底需要移…...
智慧园区综合平台解决方案PPT(75页)
## 智慧园区的理解 ### 从园区1.0到园区4.0的演进 1. 园区1.0:以土地经营为主,成本驱动,提供基本服务。 2. 园区2.0:服务驱动,关注企业成长,提供增值服务。 3. 园区3.0:智慧型园区ÿ…...

Python只读取Excel文件的一部分数据,比如特定范围的行和列?
如何只读取Excel文件的一部分数据,比如特定范围的行和列? 在Python中,如果你只想读取Excel文件的特定范围,可以使用以下方法: pandas: Pandas是一个强大的数据处理库,它有一个内置函数read_excel()用于读…...
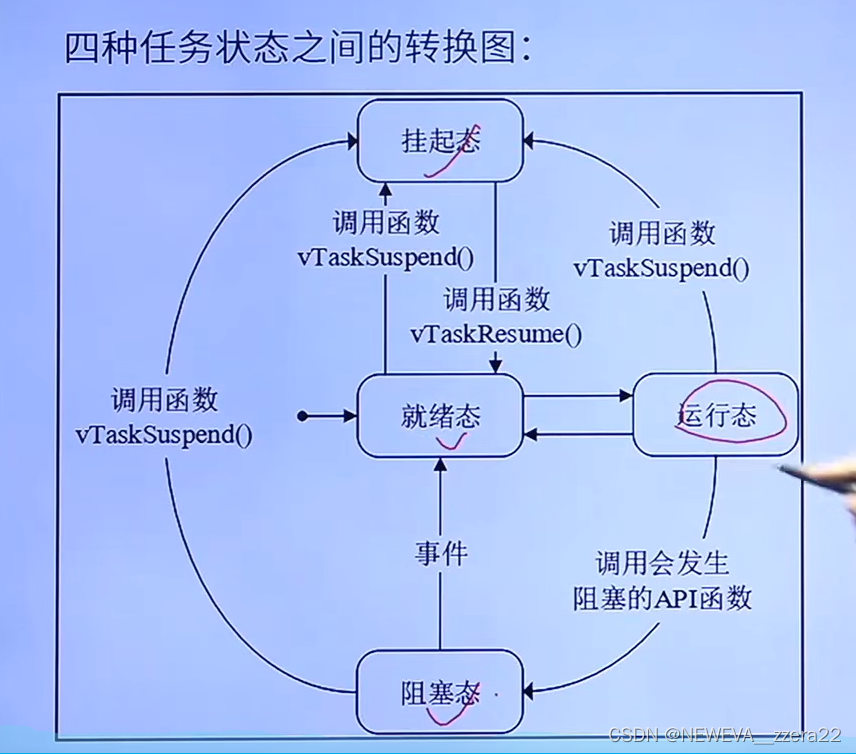
快速入门FreeRTOS心得(正点原子学习版)
对于FreeROTS,我第一反应想到的就是通信里的TDM(时分多址)。不同任务给予分配不同的时间间隔,也就是任务之间在每个timeslot都在来回切换。 这里有重要的一点,就是中断要短小,优先级是自高到底进行打断。 …...

【博主推荐】HTML5实现简洁好看的个人简历网页模板源码
文章目录 1.设计来源1.1 主界面1.2 关于我界面1.3 工作经验界面1.4 学习教育界面1.5 个人技能界面1.6 专业特长界面1.7 朋友评价界面1.8 获奖情况界面1.9 联系我界面 2.效果和源码2.1 动态效果2.2 源代码 源码下载万套模板,程序开发,在线开发,…...

Android应用安装过程
Android 系统源码源码-应用安装过程 Android 中应用安装的过程就是解析 AndroidManifest.xml 的过程,系统可以从 Manifest 中得到应用程序的相关信息,比如 Activity、Service、Broadcast Receiver 和 ContentProvider 等。这些工作都是由 PackageManage…...

Word中输入文字时,后面的文字消失
当在Word中输入文字时,如果发现后面的文字消失,通常是由以下3个原因造成的: 检查Insert键状态:首先确认是否误按了Insert键。如果是,请再次按下Insert键以切换回插入模式。在插入模式下,新输入的文字会插入…...

【LeetCode】合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 解题思路 水题,主要用于后面的链表的归并排序做了该题 AC代码 # Definition for singly-linked list. # class ListNode: # def __init__(self, val0, nex…...

告别整板实心铜:在PADS VX2.7中为你的四层板电源层设置网格覆铜与开窗的完整流程
告别整板实心铜:在PADS VX2.7中为四层板电源层设置网格覆铜与开窗的完整流程 在高速PCB设计中,电源层的处理方式直接影响电路板的散热性能、机械强度和EMI表现。传统实心覆铜虽然阻抗低,但在热应力敏感场景下容易导致板翘曲,而密集…...

FanControl完全指南:Windows风扇智能调速终极解决方案
FanControl完全指南:Windows风扇智能调速终极解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa…...
设计:从模块化到事件驱动的开发者效率工具)
技能开发套件(SDK)设计:从模块化到事件驱动的开发者效率工具
1. 项目概述:一个被低估的开发者效率工具如果你是一名开发者,尤其是经常需要与各种API、服务或硬件设备打交道的全栈或嵌入式工程师,那么你一定经历过这样的场景:为了测试一个新接口,你需要写一堆样板代码来初始化连接…...

3分钟解决Windows热键冲突:Hotkey Detective让你重掌键盘控制权
3分钟解决Windows热键冲突:Hotkey Detective让你重掌键盘控制权 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

Mantic.sh:模块化Shell脚本框架,打造高效终端开发工作流
1. 项目概述:一个为开发者量身定制的终端效率工具如果你和我一样,每天有超过一半的工作时间是在终端里度过的,那么你一定对那种在多个项目、不同目录间反复切换,以及手动敲击冗长命令的繁琐感同身受。效率,对于开发者而…...

基于语义搜索与向量数据库的AI工具发现引擎Lyra架构与实践
1. 项目概述与核心价值最近在折腾一个AI驱动的工具发现平台,核心是解决一个很实际的问题:面对市面上成千上万、层出不穷的AI工具和开源项目,我们如何高效地找到真正适合自己需求的那一个?不是简单地罗列清单,而是能理解…...

3分钟学会使用Unlock Music:浏览器内一键解密你的加密音乐文件
3分钟学会使用Unlock Music:浏览器内一键解密你的加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址…...

Stream-Omni:动态调度实现大模型流式与高质量生成的平衡
1. 项目概述:从“流”到“全”的文本生成新范式最近在自然语言处理社区里,一个名为“Stream-Omni”的项目引起了我的注意。这个由ictnlp团队开源的项目,名字本身就很有意思——“Stream”代表流式,“Omni”代表全能。简单来说&…...
》详细读书笔记)
《简明银行会计(程序员视角)》详细读书笔记
一、核心定位与学习意义本书核心:用程序员能听懂的逻辑,拆解银行会计底层规则、账务流程、核心科目、清算结算逻辑,避开纯财会晦涩术语,贴合金融开发、银行系统、支付清算、账务核心开发场景。程序员学习价值:看懂银行…...
)
Ubuntu history 命令实用教程(设置记录命令行数或永久记录等)
Ubuntu history 命令实用教程简介一、认识 history 是什么二、查看本机当前历史配置1. 查看当前历史条数限制2. 查看历史文件实际已有多少条记录三、手动设置 history 指定记录行数1. 编辑配置文件2. 写入指定行数配置3. 保存退出并生效四、设置 history 永久不删除(…...