【大模型】Vllm基础学习
前言:vllm是一个大语言模型高速推理框架,旨在提高大模型的服务效率。优势是内存管理,实现的核心是pageattetion算法。仅在gpu上加速,不在cpu加速。
目录
- 1. PageAttention
- 2. 实践
- 2.1 安装
- 2.2 离线推理
- 2.3 适配OpenAI的api
1. PageAttention
- 核心思想:将每个序列的KV cache(键值缓存)分块处理,每块包含固定数量的token。
- 灵感来源:操作系统中的虚拟内存和分页管理技术,旨在动态地为请求分配KV cache显存,提升显存利用率
- 评估结果:vLLM可以将常用的LLM吞吐量提高了2-4倍
2. 实践
2.1 安装
pip install vllm
2.2 离线推理
示例一
from vllm import llmllm = LLM("facebook/opt-13b", tensor_parallel_size=4)
output = llm.generate("San Franciso is a")
示例二
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams# Initialize the tokenizer
tokenizer = AutoTokenizer.from_pretrained("/data/weisx/model/Qwen1.5-4B-Chat")# Pass the default decoding hyperparameters of Qwen1.5-4B-Chat
# max_tokens is for the maximum length for generation.
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)# Input the model name or path. Can be GPTQ or AWQ models.
llm = LLM(model="Qwen/l/Qwen1.5-4B-Chat", trust_remote_code=True)# Prepare your prompts
prompt = "Tell me something about large language models."
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)# generate outputs
outputs = llm.generate([text], sampling_params)# Print the outputs.
for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
- SamplingParams:在VLLM模型中主要负责调整采样过程。采样是在模型生成文本或其他类型输出时的一个关键步骤,它决定了模型如何从可能的输出中选择一个。
- LLM的参数model是模型名,还可以输入其他大语言模型,但要注意不是所有的llm都被vllm支持。
- message中定义了系统的角色内容以及用户的角色内容
2.3 适配OpenAI的api
a. 命令行输入
python -m vllm.entrypoints.openai.api_server --model your_model_path --trust-remote-code
默认监听 8000 端口,–host 和–port 参数可以指定主机和端口。
b. 使用curl与Qwen对接(命令行)
curl http://localhost:8000/generate \-d '{"prompt": "San Francisco is a","use_beam_search": true,"n": 4,"temperature": 0}'
- http://localhost:8000/generate是访问的http地址,也就是客户端地址
- -d后面跟的是参数,可以根据需求配置不同的参数
c. 使用python和Qwen对接
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)chat_response = client.chat.completions.create(model="Qwen/Qwen1.5-4B-Chat",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Tell me something about large language models."},]
)
print("Chat response:", chat_response)
相关文章:

【大模型】Vllm基础学习
前言:vllm是一个大语言模型高速推理框架,旨在提高大模型的服务效率。优势是内存管理,实现的核心是pageattetion算法。仅在gpu上加速,不在cpu加速。 目录 1. PageAttention2. 实践2.1 安装2.2 离线推理2.3 适配OpenAI的api 1. Page…...

使用vue动态给同一个a标签添加内容 并给a标签设置hover,悬浮文字变色,结果鼠标悬浮有的字上面不变色
如果Vue的虚拟DOM更新机制导致样式更新不及时,你可以尝试以下几种方法来解决这个问题: 确保使用响应式数据: 确保你使用的数据是响应式的,并且任何对这些数据的更改都会触发视图的更新。在Vue中,你应该使用data对象中的…...

【ajax实战06】进行文章发布
本文章目标:收集文章内容,并提交服务器保存 一:基于form-serialize插件收集表单数据 form-serialize插件仅能收集到表单数据,除此之外的数据无法收集到 二:基于axios提交到服务器保存 三:调用alert警告…...
Codeforces Round 954 (Div. 3)(A~E)
目录 A. X Axis B. Matrix Stabilization C. Update Queries D. Mathematical Problem A. X Axis Problem - A - Codeforces 直接找到第二大的数,答案就是这个数与其他两个数的差值的和。 void solve() {vector<ll>a;for (int i 1; i < 3; i){int x;…...
基于Java微信小程序同城家政服务系统设计和实现(源码+LW+调试文档+讲解等)
💗博主介绍:✌全网粉丝10W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟感兴趣的可以先收藏起来,还…...
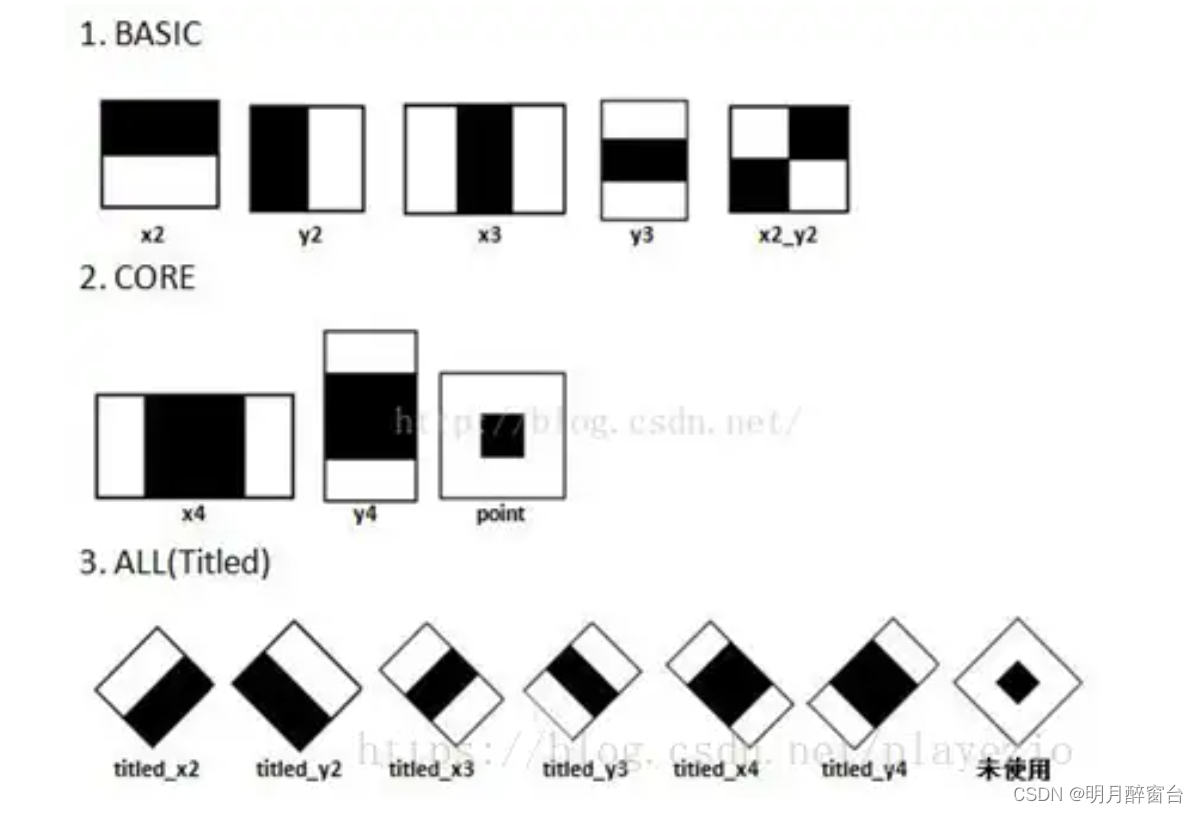
[21] Opencv_CUDA应用之使用Haar级联的对象检测
Opencv_CUDA应用之使用Haar级联的对象检测 Haar级联使用矩形特征来检测对象,它使用不同大小的矩形来计算不同的线和边缘特征。矩形包含一些黑色和白色区域,如下图所示,它们在图像的不同位置居中 类Haar特征检测算法的思想是计算矩形内白色像素和黑色像素之间的差异这个方法的…...
CXL:拯救NVMe SSD缓存不足设计难题-2
LMB提出了基于CXL协议的内存扩展框架和内核模块。该方案利用CXL内存扩展器作为物理DRAM源,旨在提供一个统一的内存分配接口,使PCIe和CXL设备都能方便地访问扩展的内存资源。通过这个接口,NVMe驱动和CUDA的统一内存内核驱动可以直接高效地访问…...

Opencv学习项目6——pyzbar
在之前我们学习了解码图片中的二维码,这次我们开启摄像头来解码视频中二维码 开启摄像头 # 打开摄像头 cap cv2.VideoCapture(0) cap.set(3, 640) # 设置摄像头画面宽度 cap.set(4, 480) # 设置摄像头画面高度 我使用的是笔记本上的摄像头来进行的,…...
 大气层双系统图文教程)
Switch 刷安卓11 (LineageOS 18.1) 大气层双系统图文教程
很多朋友手上已经拥有了完成硬破的 Switch ,但又不甘心仅仅使用 Switch 本身的地平线系统,Switch 刷安卓 (Android 11) 会是一个好的选择,虽然 Switch 的 CPU 性能拉跨,但和桌面平台同一设计思路的TegraX1 GPU 可谓是先于时代&…...

Spring Boot与Spring Batch的深度集成
Spring Boot与Spring Batch的深度集成 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨在Spring Boot应用中如何实现与Spring Batch的深度集成…...
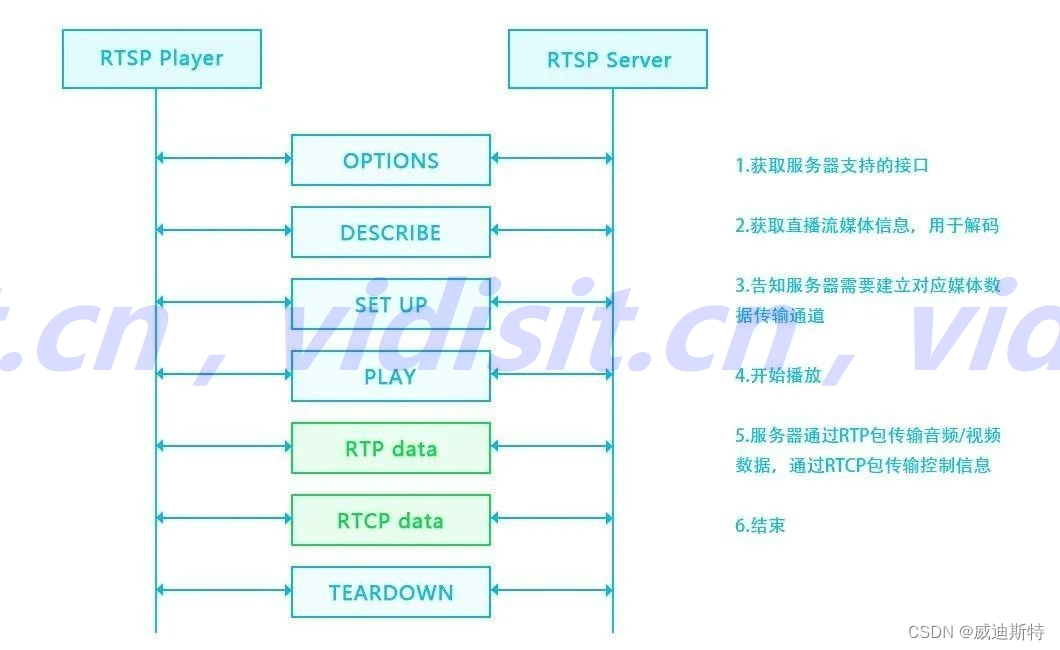
RTSP协议在视频监控系统中的典型应用、以及视频监控设备的rtsp地址格式介绍
目录 一、协议概述 1、定义 2、提交者 3、位置 二、主要特点 1、实时性 2、可扩展性 3、控制功能 4、回放支持 5、网络适应性 三、RTSP的工作原理 1、会话准备 2、会话建立 3、媒体流控制 4、会话终止 5、媒体数据传输 四、协议功能 1、双向性 2、带外协议 …...

Kotlin基础——异步和并发
同步和异步 同步指的是一种行为:当执行IO操作的时候,在代码层面上我们需要主动去等待结果,直到结果返回阻塞指的是一种状态:当执行IO操作的时候,线程处于挂起状态,就是该线程没有执行了 故同步不是阻塞&a…...

消防认证-防火卷帘
一、消防认证 消防认证是指消防产品符合国家相关技术要求和标准,且通过了国家认证认可监督管理委员会审批,获得消防认证资质的认证机构颁发的证书,消防产品具有完好的防火功能,是住房和城乡建设领域验收的重要指标。 二、认证依据…...

SpringBoot3.3集成knif4j-swagger文档方式和使用案例
springboot3 集成 knif4j : 访问地址: swagger 接口文档默认地址:http://localhost:8080/swagger-ui.html# Knife4j 接口文档默认地址:http://127.0.0.1:8080/doc.html Maven: <dependency><groupId>com.github.x…...

老年服务与管理实训室:制定教学模式
随着我国人口老龄化程度的加深,如何为老年人提供优质的养老服务成为社会关注的重点。作为培养老年服务人才的重要阵地,老年服务与管理实训室应制定科学合理的教学模式,满足行业发展需求,培养出高素质的老年服务专业人才。本文针对老年服务与管理实训室的教学模式展开探讨,提出相…...

4、DDD、中台和微服务的关系
DDD、中台和微服务的关系 1 DDD和中台的本质 领域驱动设计(DDD)和中台在企业架构中有着密切的关系。DDD的本质在于通过对业务领域的深入分析和建模,构建高内聚、低耦合的系统。而中台则是对企业核心业务能力的抽象和封装,以实现…...
【ACM出版,马来西亚-吉隆坡举行】第四届互联网技术与教育信息化国际会议 (ITEI 2024)
作为全球科技创新大趋势的引领者,中国不断营造更加开放的科技创新环境,不断提升学术合作的深度和广度,构建惠及各方的创新共同体。这是对全球化的新贡献,是构建人类命运共同体的新贡献。 第四届互联网技术与教育信息化国际学术会议…...

走进IT的世界
引言 随着高考的结束,对于即将踏入IT(信息技术)领域的新生而言,这个假期不仅是放松身心的时间,更是提前规划、深化专业知识、为大学生活奠定坚实基础的宝贵机会。以下是一份详尽的高考假期预习与规划指南,…...

Linux 时区文件编译器 zic【man 8 zic】
1. NAME(名) zic - 时区编译器 2. SYNOPSIS(概要) zic [-v] [-d directory] [-l localtime] [-p posixrules] [-L leapsecondfilename] [-s] [-y command] [filename ...]3. DESCRIPTION(函数描述) zic…...

Springboot下使用Redis管道(pipeline)进行批量操作
之前有业务场景需要批量插入数据到Redis中,做的过程中也有一些感悟,因此记录下来,以防忘记。下面的内容会涉及到 分别使用for、管道处理批量操作,比较其所花费时间。 分别使用RedisCallback、SessionCallback进行Redis pipeline …...

2019 年旧作升级!用木材与电路打造更美观的电压表时钟
2019 年旧作升级!用木材与电路打造更美观的电压表时钟早在 2019 年,作者制作了一个简单的电压表时钟,这类时钟使用模拟面板电压表来显示时间,而非传统钟面。不过,网上大多数此类设计过于复杂且不太美观,于是…...

荣品RV1126 SDK编译避坑指南:从环境配置到分区调整,手把手解决常见编译错误
RV1126 SDK编译实战:从环境搭建到分区优化的全流程解决方案 1. 开发环境配置与初始化 RV1126开发环境的搭建是整个开发流程的第一步,也是后续所有工作的基础。一个稳定、高效的开发环境能够显著提升开发效率,减少不必要的错误。 首先需要确保…...

如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南
如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 您是否梦想过在任何设备上畅玩PC游戏&#x…...

Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案
Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 你是否曾在Sketchfab上发现完美的3D…...

Token工厂:从“卖流量”到“卖Token”:中国移动砸百亿建Token生态,三大运营商的AI战争升级,阿里,百度,华为,字节跟进
5月9日,2026移动云大会上,中国移动市场经营部总经理邱宝华扔出一个新概念——"Token运营体系"。未来3-5年,中国移动将投入百亿级Token生态资源,建设千亿级算力基础设施,携手共创万亿级AI产业价值。"百亿…...

Aurora框架解析:一体化高性能云原生开发平台的设计与实践
1. 项目概述与核心价值如果你在开源社区里混迹过一段时间,尤其是对现代化、高性能的Web开发框架感兴趣,那么“Aurora”这个名字你大概率不会陌生。它不是一个简单的库或者工具,而是一个由社区驱动的、旨在构建下一代企业级应用开发平台的雄心…...

多模态AI实战:基于OpenGVLab/Ask-Anything构建视觉问答系统
1. 项目概述:当视觉大模型学会“看图说话”最近在折腾多模态AI应用,发现了一个挺有意思的开源项目,叫OpenGVLab/Ask-Anything。简单来说,它就像一个给AI装上了“眼睛”和“嘴巴”的系统,你给它一张图片或一段视频&…...

Docker容器化Emacs:构建可移植、一致的开发环境解决方案
1. 项目概述:为什么要在Docker里运行Emacs?如果你是一个Emacs的重度用户,或者是一个开发者,你很可能遇到过这样的困境:你精心配置的Emacs环境,在换了一台新电脑、升级了操作系统,或者需要在多台…...

OpenSpeedy终极指南:如何通过开源游戏加速工具突破帧率限制
OpenSpeedy终极指南:如何通过开源游戏加速工具突破帧率限制 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏中的卡顿和帧率限制?Open…...

阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程
阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本OAS是一款专门为《阴阳师》游戏设计的智能自动…...