项目实战--Spring Boot大数据量报表Excel优化
一、项目场景
项目中要实现交易报表,处理大规模数据导出时,出现单个Excel文件过大导致性能下降的问题,需求是导出大概四千万条数据到Excel文件,不影响正式环境的其他查询。
二、方案
1.使用读写分离,查询操作由从库处理
2.数据分批查询
3.异步导出数据
4.生成和拆分多个Excel文件
三、实现
1.pom.xml中添加以下依赖:
<dependencies><!-- Spring Boot Starter Data JPA --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><!-- Spring Boot Starter Async --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Apache POI for Excel --><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId></dependency>
</dependencies>
包括SpringBoot、Spring Data JPA、异步处理相关的依赖,以及用于生成Excel文件的Apache POI库。
2.application.properties中加入数据库配置,以及异步任务执行器的配置:
# Database configuration
spring.datasource.url=jdbc:mysql://localhost:3306/yourdatabase
spring.datasource.username=yourusername
spring.datasource.password=yourpassword
# Async configuration
spring.task.execution.pool.core-size=10
spring.task.execution.pool.max-size=20
spring.task.execution.pool.queue-capacity=500
spring.task.execution.thread-name-prefix=Async-thread
3.使用从库进行查询
减轻主库的查询压力,建议在架构上使用读写分离,查询操作由从库处理。这样可以确保主库的操作性能和其他接口查询不受影响。
@Service
public class DataService {@Autowiredprivate DataRepository dataRepository;public List<Data> fetchData(int offset, int limit) {return dataRepository.findAll(PageRequest.of(offset, limit)).getContent();}
}
4.数据分批查询策略
防止一次性查询大量数据导致内存溢出,采用分页查询的方式,每次查询部分数据进行处理。
@Service
public class DataExportService {@Autowiredprivate DataService dataService;@Asyncpublic void exportData() {int pageSize = 10000;int pageNumber = 0;List<Data> dataBatch;do {dataBatch = dataService.fetchData(pageNumber, pageSize);if (!dataBatch.isEmpty()) {// 导出数据到ExcelexportToExcel(dataBatch, pageNumber);}pageNumber++;} while (!dataBatch.isEmpty());}
}
5.异步任务配置
通过@EnableAsync注解启用异步任务,并配置一个任务执行线程来单独执行导出任务。
@Configuration
@EnableAsync
public class AsyncConfig implements AsyncConfigurer {@Overridepublic Executor getAsyncExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(10);executor.setMaxPoolSize(20);executor.setQueueCapacity(500);executor.setThreadNamePrefix("Async-");executor.initialize();return executor;}
}
6.导出任务接口实现
使用@Async注解将导出任务的方法标记为异步执行。
@Service
public class DataExportService {@Autowiredprivate DataService dataService;@Asyncpublic void exportData() {// 数据查询和导出的逻辑}
}
7.生成和拆分Excel文件
使用Apache POI处理Excel,查询到的数据批次,将数据分成多个Excel文件,避免单个文件过大。
public void exportToExcel(List<Data> dataBatch, int batchNumber) {Workbook workbook = new XSSFWorkbook();Sheet sheet = workbook.createSheet("Data");int rowNum = 0;for (Data data : dataBatch) {Row row = sheet.createRow(rowNum++);row.createCell(0).setCellValue(data.getId());row.createCell(1).setCellValue(data.getName());// 其他数据列}try (FileOutputStream fos = new FileOutputStream("data_batch_" + batchNumber + ".xlsx")) {workbook.write(fos);} catch (IOException e) {e.printStackTrace();}
}
相关文章:

项目实战--Spring Boot大数据量报表Excel优化
一、项目场景 项目中要实现交易报表,处理大规模数据导出时,出现单个Excel文件过大导致性能下降的问题,需求是导出大概四千万条数据到Excel文件,不影响正式环境的其他查询。 二、方案 1.使用读写分离,查询操作由从库…...

C#编程技术指南:从入门到精通的全面教程
无论你是编程新手,还是想要深化.NET技能的开发者,本文都将为你提供一条清晰的学习路径,从C#基础到高级特性,每一站都配有详尽解析和实用示例,旨在帮助你建立坚实的知识体系,并激发你对C#及.NET生态的热情。…...

Redis+定式任务实现简易版消息队列
Redis是一个开源的内存中数据结构存储系统,通常被用作数据库、缓存和消息中间件。 Redis主要将数据存储在内存中,因此读写速度非常快。 支持不同的持久化方式,可以将内存中的数据定期写入磁盘,保证数据持久性。 redis本身就有自己…...

学习在 C# 中使用 Lambda 运算符
在 C# 中,lambda 运算符 > 同时用于 lambda 表达式和表达式体成员。 1. Lambda 表达式 Lambda 表达式是一种简洁的表示匿名方法(没有名称的方法)的方法。它使用 lambda 运算符 >,可以读作“转到”。运算符的左侧指定输入参…...
)
数据结构和算法,单链表的实现(kotlin版)
文章目录 数据结构和算法,单链表的实现(kotlin版)b站视频链接1.定义接口,我们需要实现的方法2.定义节点,表示每个链表节点。3.push(e: E),链表尾部新增一个节点4.size(): Int,返回链表的长度5.getValue(index: Int): E…...

Jdk17是否有可能代替 Jdk8
JDK发展历史和开源 2006年SUN公司开源JDK,成立OpenJDK组织。2009年Oracle收购SUN,加快JDK发布周期。Oracle JDK与OpenJDK功能基本一致,但Oracle JDK提供更长时间的更新支持。 JDK版本特性 JDK11是长期支持版本(LTS)…...

oca和 ocp有什么区别
OCA(Oracle Certified Associate)和OCP(Oracle Certified Professional)在Oracle的认证体系中是两种不同级别的认证,它们之间存在明显的区别。以下是对两者区别的详细解释: 认证级别: OCA&…...

煤矿安全大模型:微调internlm2模型实现针对煤矿事故和煤矿安全知识的智能问答
煤矿安全大模型————矿途智护者 使用煤矿历史事故案例,事故处理报告、安全规程规章制度、技术文档、煤矿从业人员入职考试题库等数据,微调internlm2模型实现针对煤矿事故和煤矿安全知识的智能问答。 本项目简介: 近年来,国家对煤矿安全生产的重视程度不断提升。为了确…...

C++中的C++中的虚析构函数的作用和重要性
在C中,虚析构函数(virtual destructor)的作用和重要性主要体现在多态和继承的上下文中。了解这一点之前,我们先简要回顾一下多态和继承的基本概念。 继承与多态 继承:允许我们定义一个基类(也称为父类或超…...

机器学习 - 文本特征处理之 TF 和 IDF
TF(Term Frequency,词频)和IDF(Inverse Document Frequency,逆文档频率)是文本处理和信息检索中的两个重要概念,常用于计算一个词在文档中的重要性。下面是详细解释: TF(…...
因为自己淋过雨所以想给嵌入式撑把伞
在开始前刚好我有一些资料,是我根据网友给的问题精心整理了一份「嵌入式的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!!新手学嵌入式,…...

《C++20设计模式》中单例模式
文章目录 一、前言二、饿汉式1、实现 三、懒汉式1、实现 四、最后 一、前言 单例模式定义: 单例模式(Singleton Pattern)是一种创建型设计模式,其主要目的是确保一个类只有一个实例,并提供全局访问点来访问这个实例。…...
前端技术(说明篇)
Introduction ##编写内容:1.前端概念梳理 2.前端技术种类 3.前端学习方式 ##编写人:贾雯爽 ##最后更新时间:2024/07/01 Overview 最近在广州粤嵌进行实习,项目名称是”基于Node实现多人聊天室“,主要内容是对前端界…...
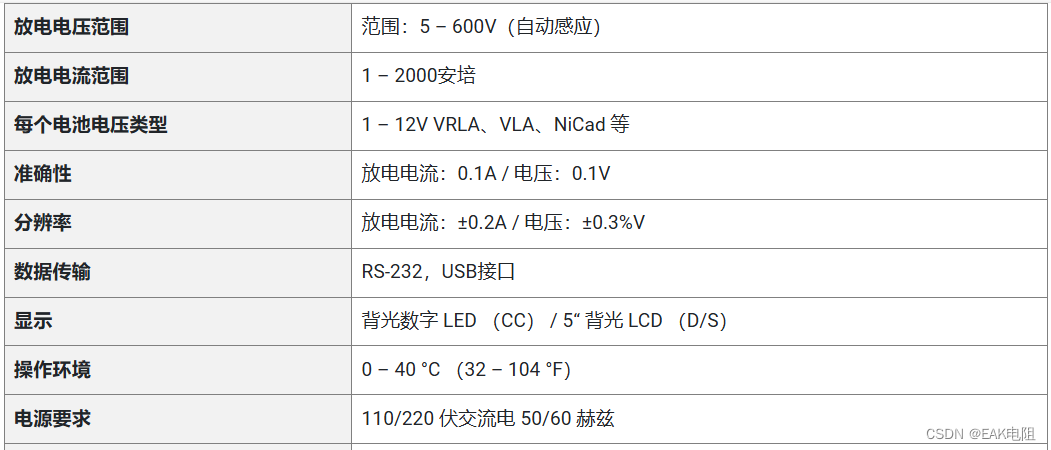
带电池监控功能的恒流直流负载组
EAK的交流和直流工业电池负载组测试仪对于测试和验证关键电力系统的能力至关重要,旨在实现最佳精度。作为一家客户至上的公司,我们继续尽我们所能应对供应链挑战,以提供出色的交货时间,大约是行业其他公司的一半。 交流负载组 我…...

关于Disruptor监听策略
Disruptor框架提供了多种等待策略,每种策略都有其适用的场景和特点。以下是这些策略的详细介绍及其适用场景: 1. BlockingWaitStrategy 特点: 使用锁和条件变量进行线程间通信,线程在等待时会进入阻塞状态,释放CPU资…...
)
大数据面试题之HBase(3)
HBase的预分区 HBase的热点问题 HBase的memstore冲刷条件 HBase的MVCC HBase的大合并与小合并,大合并是如何做的?为什么要大合并 既然HBase底层数据是存储在HDFS上,为什么不直接使用HDFS,而还要用HBase HBase和Phoenix的区别 HBase支…...

c#中赋值、浅拷贝和深拷贝
在 C# 编程中,深拷贝(Deep Copy)和浅拷贝(Shallow Copy)是用于复制对象的两种不同方式,它们在处理对象时有着重要的区别和适用场景。 浅拷贝(Shallow Copy) 浅拷贝是指创建一个新对…...

旧版st7789屏幕模块 没有CS引脚的天坑 已解决!!!
今天解决了天坑一个,大家可能有的人买的是st7789屏幕模块,240x240,1.3寸的 他标注的是老版,没有CS引脚,小崽子长这样: 这熊孩子用很多通用的驱动不吃,死活不显示,网上猛搜ÿ…...

激光粒度分析仪校准步骤详解:提升测量精度的秘诀
在材料科学、环境监测、医药研发等众多领域,激光粒度分析仪以其高精度、高效率的测量性能,成为了不可或缺的测试工具。然而,为了保持其测量结果的准确性和可靠性,定期校准是不可或缺的步骤。 接下来,佰德将为您详细介…...

独一无二的设计模式——单例模式(python实现)
1. 引言 大家好,今天我们来聊聊设计模式中的“独一无二”——单例模式。想象一下,我们在开发一个复杂的软件系统,需要一个全局唯一的配置管理器,或者一个统一的日志记录器;如果每次使用这些功能都要创建新的实例&…...

基于Go的轻量级自托管IM系统OpenWhisp部署与架构解析
1. 项目概述:一个开源的即时通讯解决方案最近在折腾一个内部协作工具,需要集成一个轻量级的即时通讯模块。市面上成熟的方案不少,但要么是SaaS服务,数据不在自己手里,心里不踏实;要么是像Rocket.Chat、Matt…...

MySQL-MVCC核心原理-版本链ReadView与可见性判断
MVCC 全称是 Multi-Version Concurrency Control,也就是多版本并发控制。它的核心思想是:为同一行数据维护多个版本,让读写在很多情况下不用互相阻塞。 没有 MVCC 时,读写冲突通常要大量依赖锁。MVCC 让普通 select 可以读一个可见…...

ESP-SR深度解析:嵌入式语音识别系统的架构设计与性能优化实战指南
ESP-SR深度解析:嵌入式语音识别系统的架构设计与性能优化实战指南 【免费下载链接】esp-sr Speech recognition 项目地址: https://gitcode.com/gh_mirrors/es/esp-sr 在物联网设备智能化浪潮中,语音交互已成为人机交互的重要入口。ESP-SR作为乐鑫…...

CircuitPython嵌入式开发实战:从GPIO到音频输出的完整指南
1. CircuitPython嵌入式开发入门:从GPIO到音频的实战指南如果你刚拿到一块Adafruit的开发板,刷好了CircuitPython,看着板子上那些密密麻麻的引脚,是不是既兴奋又有点无从下手?别担心,几乎所有嵌入式开发者都…...

ModbusTool:工业自动化通信调试的技术实现与实践指南
ModbusTool:工业自动化通信调试的技术实现与实践指南 【免费下载链接】ModbusTool A modbus master and slave test tool with import and export functionality, supports TCP, UDP and RTU. 项目地址: https://gitcode.com/gh_mirrors/mo/ModbusTool 在工业…...

AI教材生成新趋势!低查重AI工具,让教材编写不再困难!
教材创作与AI工具助力 教材初稿终于写好了,然而修改和优化的过程却像是一场“折磨”!逐字逐句地检查逻辑错误和知识点不准确的地方,真的是耗费了不少时间;调整一个章节的结构,就会影响到后面好多部分,修改…...

BLDC电机与锂离子电池集成设计关键技术解析
1. BLDC电机与锂离子电池集成设计概述在电动工具、小型电动车等便携式设备领域,无刷直流电机(BLDC)与锂离子电池的组合已成为行业标配。这种搭配带来了显著的性能提升:BLDC电机相比传统有刷电机效率提升150%以上,而锂离子电池的能量密度是镍镉…...

BES平台音频算法集成避坑指南:从声加ENC案例看副核调度与内存优化
BES平台音频算法深度优化:从ENC案例剖析多核调度与内存管理 在蓝牙音频芯片领域,BES平台凭借其出色的能效比和灵活的架构设计,已成为众多高端TWS耳机厂商的首选方案。然而,当工程师们尝试将ENC(环境噪声消除࿰…...
)
治理场景数字孪生智慧推演方案(2026完整版)
治理场景数字孪生智慧推演方案(2026完整版) 第1章项目概述 1.1项目背景 数字化、智能化转型是新时代国家治理体系和治理能力现代化建设的核心抓手与必经路径,也是各地政府推进政务提质、基层增效、民生优化的核心工作方向。数字孪生技术作为打通物理治理场景与数字虚拟场景的…...
)
STM32单片机如何用IRIG-B解码模块实现10ns级高精度授时(附完整驱动代码)
STM32单片机如何用IRIG-B解码模块实现10ns级高精度授时(附完整驱动代码) 在工业自动化、电力系统同步、通信基站等对时间精度要求苛刻的领域,微秒级甚至毫秒级的时钟同步已经无法满足需求。IRIG-B作为一种标准时间码格式,通过解码…...