Kafka 管理TCP连接
生产者管理TCP连接
Kafka生产者程序概览
Kafka的Java生产者API主要的对象就是KafkaProducer。通常我们开发一个生产者的步骤有4步:
第1步:构造生产者对象所需的参数对象。
第2步:利用第1步的参数对象,创建KafkaProducer对象实例。
第3步:使用KafkaProducer的send方法发送消息。
第4步:调用KafkaProducer的close方法关闭生产者并释放各种系统资源。
上面这4步写成Java代码的话大概是这个样子:
Properties props = new Properties ();
props.put(“参数1”, “参数1的值”);
props.put(“参数2”, “参数2的值”);
……
try (Producer<String, String> producer = new KafkaProducer<>(props)) {producer.send(new ProducerRecord<String, String>(……), callback);……
}何时创建TCP连接
1. TCP连接在创建KafkaProducer实例时建立
在创建KafkaProducer实例时,生产者应用会在后台创建并启动一个名为 Sender的线程,该Sender线程开始运行时首先会创建与Broker的TCP连接的。
如果不调用send方法,这个Producer都不知道给哪个主题发消息,它又怎么能知道连接哪个Broker呢?这是通过Producer的核心参数之一bootstrap.servers参数来指定的。
如果为这个参数指定了1000个Broker连接信息,Producer启动时会首先创建与这1000个Broker的TCP连接,所以不建议把集群中所有的Broker信息都配置到bootstrap.servers中,因为Producer一旦连接到集群中的任一台Broker,就能拿到整个集群的Broker信息,故没必要为bootstrap.servers指定所有的Broker。通过日志可以看出:
[2018-12-09 09:35:45,828] DEBUG[ProducerclientId=producer-1] Sendingmetadatarequest (type=MetadataRequest, topics=) to nodelocalhost:9093 (id:-2 rack: null) (org.apache.kafka.clients.NetworkClient:1068)
Producer向某一台Broker发送了MetadataRequest请求,尝试获取集群的元数据信息——这就是前面提到的Producer能够获取集群所有信息的方法。
2. 在更新元数据后 和 在消息发送时
(1) 当Producer尝试给一个不存在的主题发送消息时,Broker会告诉Producer说这个主题不存在。此时Producer会发送METADATA请求给Kafka集群,去尝试获取最新的元数据信息。
(2) Producer通过metadata.max.age.ms参数定期地去更新元数据信息。该参数的默认值是300000,即5分钟,也就是说不管集群那边是否有变化,Producer每5分钟都会强制刷新一次元数据以保证它是最及时的数据。
何时关闭TCP连接
1. 用户主动关闭
这里的主动关闭实际上是广义的主动关闭,甚至包括用户调用kill-9主动“杀掉”Producer应用。当然最推荐的方式还是调用producer.close()方法来关闭。
2. Kafka自动关闭
这与Producer端参数connections.max.idle.ms的值有关。默认情况下该参数值是9分钟,即如果在9分钟内没有任何请求“流过”某个TCP连接,那么Kafka会主动帮你把该TCP连接关 闭。用户可以在Producer端设置connections.max.idle.ms=-1禁掉这种机制。一旦被设置成-1,TCP连接将成为永久长连接。当然这只是软件层面的“长连接”机制,由于Kafka创建的这些Socket连接都开启了 keepalive,因此keepalive探活机制还是会遵守的。
自动关闭中,TCP连接是在Broker端被关闭的,但其实这个TCP连接的发起方是客户端,因此在TCP看来,这属于被动关闭的场景,即passive close。被动关闭的后果就是会产生大量的 CLOSE_WAIT连接,因此Producer端或Client端没有机会显式地观测到此连接已被中断。
小结:
Java Producer端管理TCP连接的方式是:
1. KafkaProducer实例创建时启动Sender线程,从而创建与bootstrap.servers中所有Broker的TCP连接。
2. KafkaProducer实例首次更新元数据信息之后,还会再次创建与集群中所有Broker的TCP连接。
3. 如果Producer端发送消息到某台Broker时发现没有与该Broker的TCP连接,那么也会立即创建连接。
4. 如果设置Producer端connections.max.idle.ms参数大于0,则步骤1中创建的TCP连接会被自动关闭;如果设置该参数=-1,那么步骤1中创建的TCP连接将无法被关闭,从而成为“僵尸”连接。
消费者管理TCP连接
何时创建TCP连接
和生产者不同的是,构建KafkaConsumer实例时是不会创建任何TCP连接的。TCP连接是在调用KafkaConsumer.poll方法时被创建的。再细粒度地说,在poll方法内部有3个时机可以创建TCP连接:
1.发起FindCoordinator请求时。
消费者端有个组件叫协调者(Coordinator),它驻留在Broker端的内存中,负责消费者组的组成员管理和各个消费者的位移提交管理。当消费者程序首次启动调用poll方法时,它需要向Kafka集群 发送一个名为FindCoordinator的请求,向集群中当前负载最小的那台Broker发送请求。希望Kafka集群告诉它哪个Broker是管理它的协调者。
2.连接协调者时。
Broker处理完上一步发送的FindCoordinator请求之后,会返还对应的响应结果(Response),显式地告诉消费者哪个Broker是真正的协调者,因此在这一步,消费者知晓了真正的协调者后,会创建连向该 Broker的Socket连接。只有成功连入协调者,协调者才能开启正常的组协调操作,比如加入组、等待组分配方案、心跳请求处理、位移获取、位移提交等。
3.消费数据时。
消费者会为每个要消费的分区创建与该分区领导者副本所在Broker连接的TCP。举个例子,假设消费者要消费5个分区的数据,这5个分区各自的领导者副本分布在4台Broker上,那么该消费者在消费时会创建与这4台Broker的Socket连接。
注意:当第三类TCP连接成功创建后,消费者程序就会废弃第一类TCP连接,第一类TCP连接会在后台被默默地关闭掉。对一个运行了一段时间的消费者程序来说,只会有后面两类TCP连接存在。
通过日志查看:
[2019-05-27 10:00:54,142] DEBUG [ConsumerclientId=consumer-1, groupId=test] Initiating connection to nodelocalhost:9092 (id: -1 rack: null) using address localhost/127.0.0.1
(org.apache.kafka.clients.NetworkClient:944)
…
[2019-05-27 10:00:54,188] DEBUG [ConsumerclientId=consumer-1, groupId=test] Sending metadata request MetadataRequestData(topics=[MetadataRequestTopic(name=‘t4’)],
allowAutoTopicCreation=true, includeClusterAuthorizedOperations=false, includeTopicAuthorizedOperations=false) to nodelocalhost:9092 (id: -1 rack: null) (org.apache.kafka.clients.NetworkClient:1097)
…
[2019-05-27 10:00:54,188] TRACE [ConsumerclientId=consumer-1, groupId=test] Sending FIND_COORDINATOR {key=test,key_type=0} with correlation id 0 to node-1
(org.apache.kafka.clients.NetworkClient:496)
[2019-05-27 10:00:54,203] TRACE [ConsumerclientId=consumer-1, groupId=test] Completed receivefrom node-1 for FIND_COORDINATORwith correlation id 0, received
{throttle_time_ms=0,error_code=0,error_message=null, node_id=2,host=localhost,port=9094}(org.apache.kafka.clients.NetworkClient:837)
…
[2019-05-27 10:00:54,204] DEBUG [ConsumerclientId=consumer-1, groupId=test] Initiating connection to nodelocalhost:9094 (id: 2147483645 rack: null) using address localhost/127.0.0.1
(org.apache.kafka.clients.NetworkClient:944)
…
[2019-05-27 10:00:54,237] DEBUG [ConsumerclientId=consumer-1, groupId=test] Initiating connection to nodelocalhost:9094 (id: 2 rack: null) using address localhost/127.0.0.1
(org.apache.kafka.clients.NetworkClient:944)
[2019-05-27 10:00:54,237] DEBUG [ConsumerclientId=consumer-1, groupId=test] Initiating connection to nodelocalhost:9092 (id: 0 rack: null) using address localhost/127.0.0.1
(org.apache.kafka.clients.NetworkClient:944)
[2019-05-27 10:00:54,238] DEBUG [ConsumerclientId=consumer-1, groupId=test] Initiating connection to nodelocalhost:9093 (id: 1 rack: null) using address localhost/127.0.0.1
(org.apache.kafka.clients.NetworkClient:944)日志的第一行是消费者程序创建的第一个TCP连接,就像我们前面说的,这个Socket用于发送FindCoordinator请求。由于这是消费者程序创建的第一个连接,此时消费者对于要连接 的Kafka集群一无所知,因此它连接的Broker节点的ID是-1,表示消费者尚未获取到Broker数据。
日志的第二行,消费者复用了刚才创建的那个Socket连接,向Kafka集群发送元数据请求以获取整个集群的信息。
日志的第三行表明,消费者程序开始发送FindCoordinator请求给第一步中连接的Broker,即localhost:9092,也就是nodeId等于-1的那个。在十几毫秒之后,消费者程序成功地获悉协调者所在的Broker信息, 也就是第四行的“node_id = 2”。
完成这些之后,消费者就已经知道协调者Broker的连接信息了,因此在日志的第五行发起了第二个Socket连接,创建了连向localhost:9094的TCP。只有连接了协调者,消费者进程才能正常地开启消费者组 的各种功能以及后续的消息消费。
在日志的最后三行中,消费者又分别创建了新的TCP连接,主要用于实际的消息获取。要消费的分区的领导者副本在哪台Broker上,消费者就要创建连向哪台Broker的TCP。
那么2147483645是怎么来的呢?
它是由Integer.MAX_VALUE减去协调者所在Broker的真实ID计算得来的。看第四行的内容,我们可以知道协调者ID是2,因此这个Socket连接的节点ID就是 Integer.MAX_VALUE减去2,即2147483647减去2,也就是2147483645。这种节点ID的标记方式目的就是要让组协调请求和真正的数据获取请求使用不同的Socket连接。 至于后面的0、1、2,那就很好解释了。它们表征了真实的Broker ID,也就是我们在server.properties中配置的broker.id值。
何时关闭TCP连接
1. 手动关闭
手动调用KafkaConsumer.close()方法或者是执行Kill命令。
2. 自动关闭
自动关闭是由消费者端参数connection.max.idle.ms控制的,该参数现在的默认值是9分钟,即如果某个Socket连接上连续9分钟都没有任何请求“过境”的话,那么消费者会强行“杀掉”这个Socket连接。
注意:和生产者有些不同的是,如果在编写消费者程序时,使用了循环的方式来调用poll方法消费消息,那么上面提到的所有请求都会被定期发送到Broker,因此这些Socket连接上总是能保证有请求在发送,从而也就实现了“长连接”的效果。
参考:Kafka 核心技术与实战 (geekbang.org)
相关文章:

Kafka 管理TCP连接
生产者管理TCP连接 Kafka生产者程序概览 Kafka的Java生产者API主要的对象就是KafkaProducer。通常我们开发一个生产者的步骤有4步: 第1步:构造生产者对象所需的参数对象。 第2步:利用第1步的参数对象,创建KafkaProducer对象实例…...
electron教程(一)创建项目
一、方式① 根据官网描述将electron/electron-quick-start项目克隆下来并启动 electron/electron-quick-start地址: GitHub - electron/electron-quick-start: Clone to try a simple Electron app git clone https://github.com/electron/electron-quick-start…...

如何在Oracle、MySQL、PostgreSQL上终止会话或取消SQL查询
How to Kill session or Cancel SQL query on Oracle , MySQL, PostgreSQL 数据库维护过程中难免会遇到一些不正常的SQL或会话进程正在占用系统大量资源,临时需要终止查询或kill会话,在Oracle, MySQL, Postgresql数据库中不同的操作。 Oracle KILL会话…...
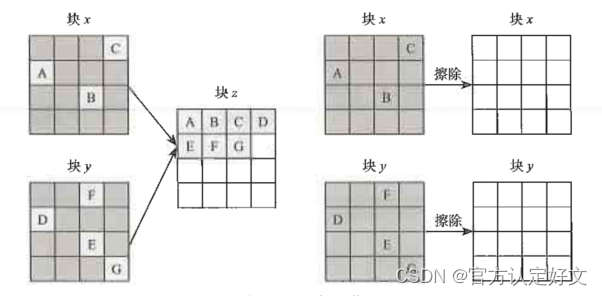
3、FTL基本工作过程
上文描述了FTL的四大功能,这里简述一下每个功能的含义。 地址转换简述 FTL要维护一个地址转换表,这个转换表是主机读/写硬盘的逻辑地址到硬盘实际物理地址的转换关系。 假如SSD的容量是128G,SSD逻辑块的大小是4KB,那SSD的逻辑块…...

微信小程序的跳转页面
在微信小程序中,要实现从当前页面返回到指定页面的功能,通常不直接使用“返回上一页”的逻辑,而是利用小程序的页面栈管理和navigateBack或者重新定向到目标页面的API。下面我将介绍两种主要的方法: 方法一:使用 navi…...
`, `notify()`, `notifyAll()`)
深入理解 Java 中的线程间通信:`wait()`, `notify()`, `notifyAll()`
引言 在多线程编程中,线程间通信是一个重要且复杂的主题。Java 提供了一套基本的机制来实现线程间通信,即使用 wait(), notify(), 和 notifyAll() 方法。这些方法由 Object 类提供,用于协调多个线程对共享资源的访问。本文将详细介绍这些方法…...

23种设计模式【创建型模式】详细介绍之【单例模式】
23种设计模式【创建型模式】详细介绍之【单例模式】 设计模式的分类和应用场景总结单例模式1. 概述2. 实现方式2.1 饿汉式单例模式2.2 懒汉式单例模式(非线程安全)2.3 懒汉式单例模式(线程安全) 3. 单例模式的优缺点3.1 优点3.2 缺…...

某汽车配件制造公司任职资格体系项目成功案例纪实
——基于岗位特点和核心能力要求,分层分级能力测评,实现个性化人才培养 【客户行业】生产制造;汽车配件制造 【问题类型】任职资格体系建立;人才管理系统 【客户背景】 某汽车配件制造公司是一家专注于汽车配件研发、生产和销…...

【Linux】生物信息学常用基本命令
wget网址用于直接从网上下载某个文件到服务器,当然也可以直接从网上先把东西下到本地然后用filezilla这个软件来传输到服务器上。 当遇到不会的命令时候,可以使用man “不会的命令”来查看这个命令的详细信息。比如我想要看看ls这个命令的详细用法&…...
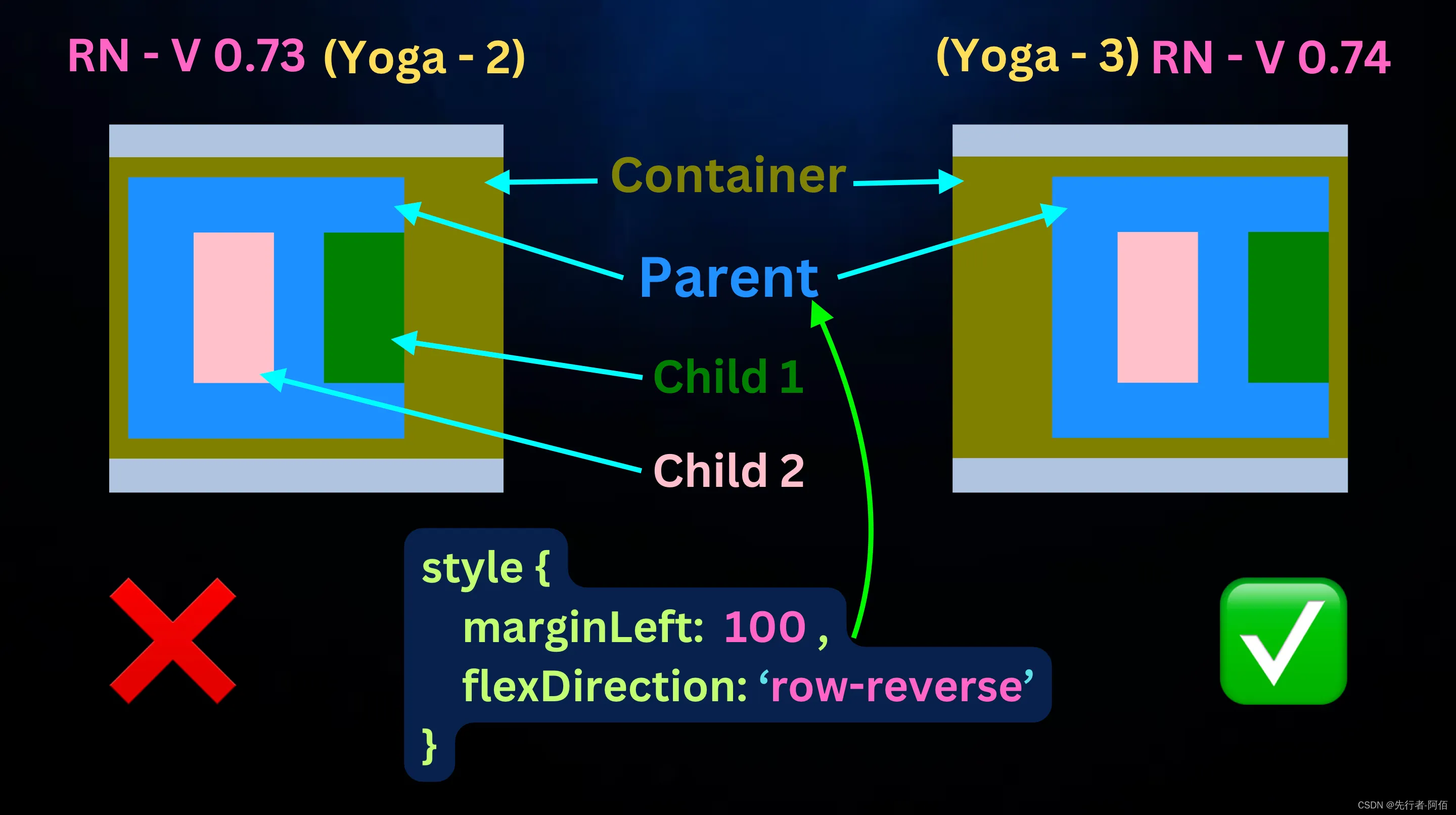
React Native V0.74 — 稳定版已发布
嗨,React Native开发者们, React Native 世界中令人兴奋的消息是,V0.74刚刚在几天前发布,有超过 1600 次提交。亮点如下: Yoga 3.0New Architecture: Bridgeless by DefaultNew Architecture: Batched onLayout UpdatesYarn 3 for New Projects让我们深入了解每一个新亮点…...
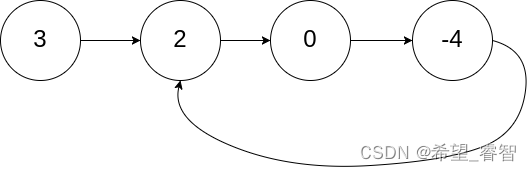
Python面试宝典第4题:环形链表
题目 给你一个链表的头节点 head ,判断链表中是否有环。如果存在环 ,则返回 true 。 否则,返回 false 。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环…...
 底层原理)
Kubernetes (K8s) 底层原理
Kubernetes (K8s) 的底层原理涉及多个关键组件和概念,确保容器化应用程序的自动化部署、扩展和管理。以下是 Kubernetes 的底层原理及其关键组件的详细描述。 核心组件 Etcd 功能:分布式键值存储,用于存储集群的所有数据,包括配置…...
【笔记摘要】)
解析Kotlin中的委托(包括类委托,属性委托)【笔记摘要】
1.委托模式 委托模式:操作对象不会去处理某段逻辑,而是会把工作委托给另外一个辅助对象去处理。 例如我们要设计一个自定义类的来实现Set,可以将该实现委托给另一个对象: class MySet<T> (val helperSet: HashSet<T>…...

vue3+ts+uniapp+vite+pinia项目配置
开发环境: node >18,npm >8.10.2,vue < 3.2.31 安装项目 npx degit dcloudio/uni-preset-vue#vite-ts vue3-uniapp 1、引入样式规范 npm add -D eslint eslint-config-airbnb-base eslint-config-prettier eslint-import-resolv…...
:面向对象编程)
大数据开发语言 Scala(四):面向对象编程
目录 1. 概述 2. 面向对象编程的基本概念 2.1 类和对象 2.2 继承和多态 2.3 封装和访问控制 3. 面向对象编程在大数据开发中的应用 3.1 Spark中的面向对象编程 3.2 面向对象编程在数据清洗和预处理中 3.3 面向对象编程在机器学习中的应用 4. 面向对象编程的高级特性 …...

C++ //练习 14.31 我们的StrBlobPtr类没有定义拷贝构造函数、赋值运算符及析构函数,为什么?
C Primer(第5版) 练习 14.31 练习 14.31 我们的StrBlobPtr类没有定义拷贝构造函数、赋值运算符及析构函数,为什么? 环境:Linux Ubuntu(云服务器) 工具:vim 解释: 因为…...

通配符和正则表达式之间的关系
通配符和正则表达式(正则)都是用于匹配字符串的工具,但它们的复杂性和用途有所不同。下面是它们之间的主要关系和区别: 通配符 通配符主要用于简单的模式匹配,常见于文件系统操作中,例如在命令行中查找文…...

GY-30光照传感器软件I2C方式驱动代码,基于STM32Cube
GY-30光照传感器的具体资料可以去淘宝搜索然后问卖家要,网上也有,所以这里我就不多嘴了。 VCC连接3到5伏电压,根据文件开头的描述在STM32CubeMX中配置好外设。 STM32Cube开发方式就是4个字“简单直接”,直接上代码。 gy30.h #…...

双相元编程:一种新语言设计方法
本文讨论了编程语言的一种趋势,即允许相同的语法表达 在两个不同阶段或环境(上下文)中执行的计算同时保持跨阶段(上下文)的一致行为。这些阶段通常在时间上(运行时间)或空间上(运行…...

基于SpringBoot校园外卖配送系统设计和实现(源码+LW+调试文档+讲解等)
💗博主介绍:✌全网粉丝10W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,…...

FastAPI快速入门:环境搭建+第一个接口
FastAPI快速入门:环境搭建第一个接口文章信息 标题:FastAPI快速入门:环境搭建第一个接口字数:4200字预估阅读时间:18分钟难度:⭐☆☆☆☆一、为什么选择FastAPI? 在2026年的Python Web框架生态中…...

STM32移植U8g2库驱动OLED:源码精简与硬件适配实战
1. 项目概述与核心思路之前玩ESP8266的时候,在Arduino环境下用U8g2库驱动OLED,画点线面、显示文字,确实方便。但很多实际项目,尤其是对成本、功耗有要求的,还是绕不开STM32这类更纯粹的MCU。最近有个小项目,…...

2026年实测推荐:10款思维导图工具,开发者效率翻倍
作为技术博主,我常年用思维导图拆解需求、梳理架构、记录学习笔记。2026年,工具们卷出了新高度:AI辅助、白板一体化、实时协作成了标配。本文从开发者视角出发,实测了10款热门工具,帮你选出最适合的那把“瑞士军刀”。…...

僧伽罗文语音本地化迫在眉睫!斯里兰卡新《数字服务法》2024年10月生效前,你必须掌握的7项ElevenLabs合规配置
更多请点击: https://intelliparadigm.com 第一章:僧伽罗文语音本地化的法律动因与技术紧迫性 斯里兰卡《官方语言法》(No. 33 of 1956)及2023年修订的《国家数字包容战略》明确要求:所有面向公众的政府数字服务必须支…...

QtUnblockNeteaseMusic终极指南:跨平台音乐解锁工具的技术实现与应用
QtUnblockNeteaseMusic终极指南:跨平台音乐解锁工具的技术实现与应用 【免费下载链接】QtUnblockNeteaseMusic A desktop client for UnblockNeteaseMusic, made with Qt. 项目地址: https://gitcode.com/gh_mirrors/qt/QtUnblockNeteaseMusic 在数字音乐流媒…...

WeatherBench终极指南:快速构建天气预报AI模型的完整基准平台
WeatherBench终极指南:快速构建天气预报AI模型的完整基准平台 【免费下载链接】WeatherBench A benchmark dataset for data-driven weather forecasting 项目地址: https://gitcode.com/gh_mirrors/we/WeatherBench WeatherBench是一个专为数据驱动天气预报…...

iOS 18.2 Siri大模型升级:从命令响应到意图理解的混合智能架构解析
1. 项目概述:当Siri遇上ChatGPT,一次迟来的“大脑移植”作为一名长期关注移动操作系统与AI交互的从业者,我几乎第一时间就刷到了iOS 18.2 Beta 1的更新包。这次更新的标题——“Siri接入ChatGPT技术”——简单直接,却足以在圈内掀…...

亲身体验AI智能体在实际项目中展现的核心能力
AI 智能体能力实战学习笔记 通过与 AI 智能体的协作,我亲身体验了 AI 在软件开发全流程中的强大能力。本文记录了智能体在实际项目中展现的核心功能,以及如何使用这些能力提高工作效率。 🎯 核心能力概览 能力地图 AI 智能体能力 ├── &a…...

容器化自动化数据抓取平台OpenClaw-Compose部署与实战指南
1. 项目概述:一个容器化的开源自动化抓取与处理平台最近在折腾一个自动化数据抓取和处理的项目,发现了一个挺有意思的GitHub仓库:alexleach/openclaw-compose。乍一看标题,你可能会觉得这又是一个普通的Docker Compose编排文件集合…...

3步掌握OmenSuperHub:惠普游戏本性能控制终极指南
3步掌握OmenSuperHub:惠普游戏本性能控制终极指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方Omen Gaming Hub的臃肿界面…...