Vision Transformer论文阅读笔记
目录
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale -- Vision Transformer
- 摘要
- Introduction—简介
- RELATED WORK—相关工作
- METHOD—方法
- VISION TRANSFORMER (VIT)—视觉Transformer(ViT)
- 分析与评估
- PRE-TRAINING DATA REQUIREMENTS—预训练数据要求
- INSPECTING VISION TRANSFORMER—检查vision transformer
- 总结与展望
- VIT详细网络结构
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale – Vision Transformer
论文链接:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
摘要
(1)本文证明了图像对CNN的依赖不是必要的,将纯Transformer直接用于图像patch序列可以很好地执行图像分类任务。
(2)和最先进的CNN相比,vision transformer(ViT)可以获得出色的结果,同时训练所需的计算资源也相对较少(仍然需要很多资源,只是相对更耗资源的网络而言的)。
Introduction—简介
问题:如何将transformer应用到视觉问题上?
Bert序列长度也就500左右,如果要将图片的每个像素展开变成一个序列,就算224 × 224 = 50176 (≈ 500 × 100)图片输入计算量也十分大。
解决方向:
1、把原图的局部当作一个输入(类似卷积也是局部操作)
2、把处理过的特征图作为输入(下采样降低分辨率)
本文方法
(1)将图像拆分为patches(比如输入为224 × 224,每个patch就是 16 × 16,224 / 16 = 14,输入序列长度就是 14 × 14 = 196 ),并提供这些patches的线性embeddings序列作为 Transformer 的输入。(图像patches和在NLP应用中的token相似)
(2)采用了有监督的方式对图像分类模型进行训练。
不足:在不充足数据下训练,会导致模型泛化性不足。
注意:在中型大小数据集上,如果不加以其他比较强的约束Vit跟同等大小的残差网络相比是比较弱的。
原因:因为卷积神经网络中有归纳偏置,在VIT中没有。归纳偏置其实就是一种先验知识,或者说一种提前做好的假设。
最常见的两个归纳偏置(inductive bias):
locality:图片中相邻区域通常会有相邻的特征(比如桌子和椅子一般都挨在一起),靠的越近的东西相关性就越强。
translation equivariance(平移等变性):公式表达为g(f(x)) = f(g(x)),把g理解为卷积,f理解为平移,就是不管先做哪个操作,结果都是一样的,在卷积神经网络里面只要输入的图片不变,经过同一个卷积核的结果是一定的。
通过这两个归纳偏置,卷积神经网络就有了很多先验信息,可以通过相对少的数据,去学习到一个比较好的模型。
Vit没有这些先验知识,因此往往基于之前的大规模预训练来训练可以获得较好的结果。
Translation Equivariance (平移等变性)和Translation Invariance(平移不变性)
Translation Equivariance (平移等变性):
定义: 一个系统或算法在输入数据经历平移(或移动)时,保持输出相对于输入的相对位置的性质。
示例: 在图像处理中,一个具有平移等变性的算法可以在图像中检测或处理特征,而不受这些特征在图像中的位置变化的影响。它会产生相应的移动,但不会改变特征的识别或提取结果。Translation Invariance (平移不变性):
定义: 一个系统或算法在输入数据经历平移时,保持输出不变的性质。
示例: 在图像处理中,一个具有平移不变性的算法可以在图像中检测或识别特征,而不受这些特征在图像中的位置变化的影响。无论特征的位置如何变化,该算法都会产生相同的识别结果。简而言之,平移等变性表示系统对于输入数据的平移保持输出相对位置的相对性,而平移不变性表示系统对于输入数据的平移保持输出完全不变。
RELATED WORK—相关工作
(1)Transformer: 用于机器翻译的方法,被广泛用于NLP领域
(2)BERT: 使用去噪自我监督的训练前任务
(3)局部多头点积自我注意块: 只在每个查询像素的局部社区中应用自注意力,可以完全取代卷积
(4)稀疏Transformer: 采用了对全局自关注的可扩展近似,以便适用于图像
(5)在不同大小的块中应用: 在极端情况下,只沿着个别轴线应用
(6)iGPT: 无监督的方式,在降低图像分辨率和色彩空间后将Transformers应用于图像像素
无监督对比:BERT类似完型填空,GPT是预测后续的单词
METHOD—方法
VISION TRANSFORMER (VIT)—视觉Transformer(ViT)
(1)第1部分:将图形转化为序列化数据
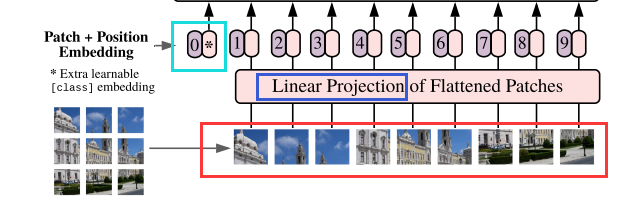
-
首先输入为一张图片,将图片划分成9个patch,然后将每个patch重组成一个向量,得到所谓的flattened patch(上图红框内)。
-
如果图片是H×W×C维的,就用P×P大小的patch去分割图片可以得到N个patch(实际处理通过卷积操作实现,然后卷积核的尺寸个数根据[num_token,token_dim]设置),那么每个patch的大小就是P×P×C,将N个patch 重组后的向量concat在一起就得到了一个N×P×P×C的二维矩阵,相当于NLP中输入Transformer的词向量。
-
patch大小变化时,重组后的向量维度也会变化,作者对上述过程得到的flattened patches向量做了Linear Projection(线性投射层操作,其实就是一个全连接层),将不同长度的flattened patch向量转化为固定长度的向量(记作D维向量)。
综上,原本H×W×C 维的图片被转化为了N个D维的向量(或者一个N×D维的二维矩阵)。
(2)第2部分:Position embedding
图像是一个整体,因此patch之间是有位置信息的,打乱顺序后就不是原来的图片了。
但是在自注意力中两两计算不会涉及位置信息(即便打乱了结果也一样),因此需要加入位置信息。
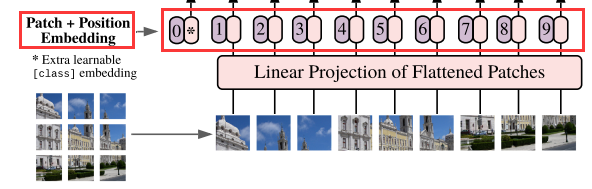
由于Transformer模型本身是没有位置信息的,和NLP中一样,我们需要用position embedding将位置信息加到模型中去。
如上图所示,编号有0-9的紫色框表示各个位置的position embedding,而紫色框旁边的粉色框则是经过linear projection之后的flattened patch向量。
position embedding也是一个可训练的参数,它其实可以看作一个N(patch) × dimension (patch的维度也就是token_dim)的矩阵,然后是可以学习得到的。
原文采用相加(add)的方式将position embedding(即图中紫色框)和patch embedding(即图中粉色框)结合position信息,最终的宽、高、深度都不会改变。
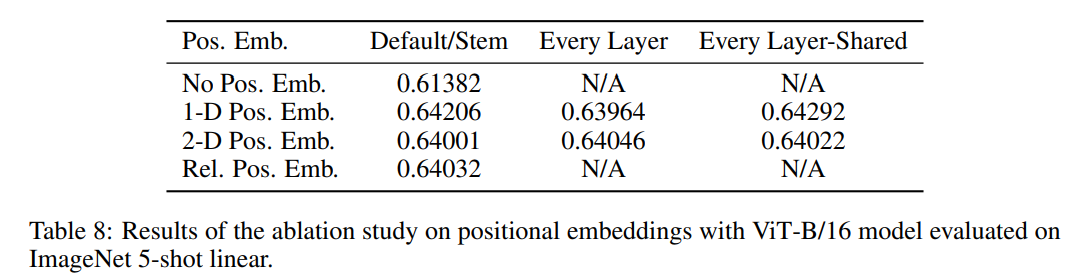
对于position采用1D、2D还是相对位置编码表示,作者进行了消融实验(如下表),相比没有位置信息的效果要好3个百分点,至于用哪种方式表示位置信息,差别不大,只要用了就行。
举例:一张图片划分成九宫格
1D:1,2,3,4,…,8,9
2D:相当于xy轴,11,12,13,21,22,23,31,32,33
relative:比如1D中2和9相差7个单位距离,用7(offset)来表示
(3)第3部分:Learnable embedding

patch + position embedding = token,tokens包含position信息以及图像信息。
在一系列 token 的前面加上加上一个新的 token,叫做class token(上图带星号),它并不是某个patch产生的,增加class token是参考bert网络,它的位置信息永远是0,它的维度(dimension)需要和patch的维度一致。
Class token的作用是作为一个分类字符(也是一个可训练的参数),经过encoder后对应的结果这个token的输出当作整个transformer模型的输出,也就是当作整个图像的特征输出。(个人理解:这个token是附加的,对于全图中其他任何patch的关注都是公平的关注,因此相当于是个全局平均池化的过程,但是如果采用某个patch的token作为输出,受到自身位置信息和相对位置信息的影响,关注度肯定是不平均的,因此不能作为输出)
类比传统卷积神经网络,经过几个block之后得到一个feature map,在分类之前会先对这个feature map执行GAP(全局平均池化)得到一个向量(1 × n),然后这个向量代表全局对于这个图片的特征,就可以把向量拿去做分类。
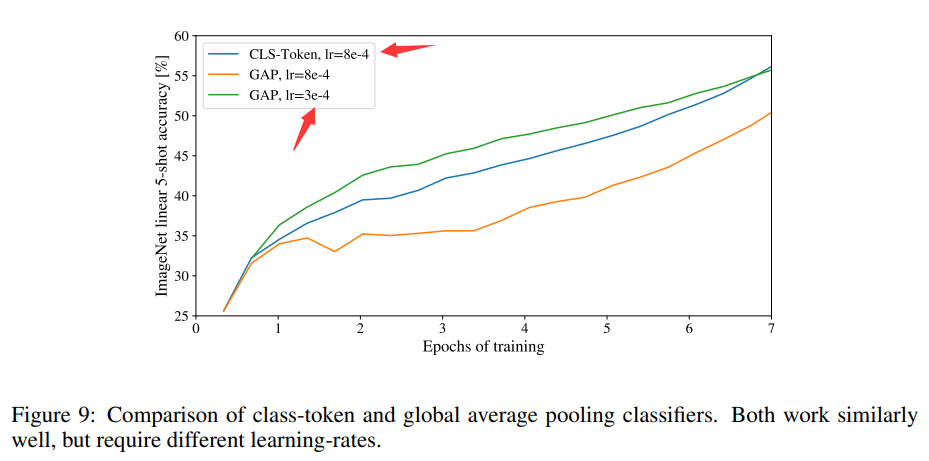
在transformer(如下示意图)中,VIT是使用红色框内的输出(cls token的输出)作为分类的输入;
但其实也可以把每个patch对应token(绿色框内)的输出进行GAP,然后作为分类的输入。

本文也对两种方法进行了对比,可以从下图看出,学习率设置好,采用GAP的方式比采用cls token的方式准确率更高。
以上的操作其实就是对图像进行预处理得到token,对于位置信息的表示和输出分类的特征表示,为了和原来的transformer保持一致所以采取了1D和class token。
(4)第4部分:Transformer encoder
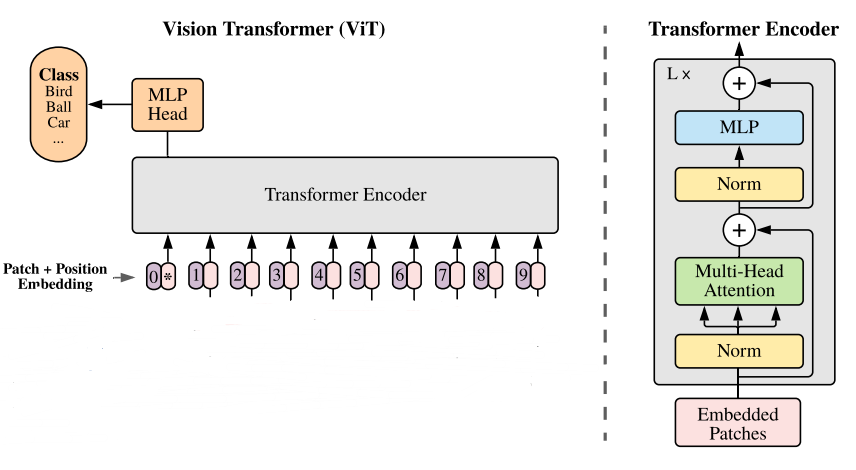
最后输入到 Transformer Encoder 中,对应着右边的图,将 block 重复堆叠 L 次,整个模型也就包括 L 个 Transformer。Transformer Encoder结构和NLP中Transformer结构基本上相同,我们只是需要对它进行一个分类,只提取针对class token所对应的输出,经过 MLP Head 进行类别判断,得到最终分类的结果。
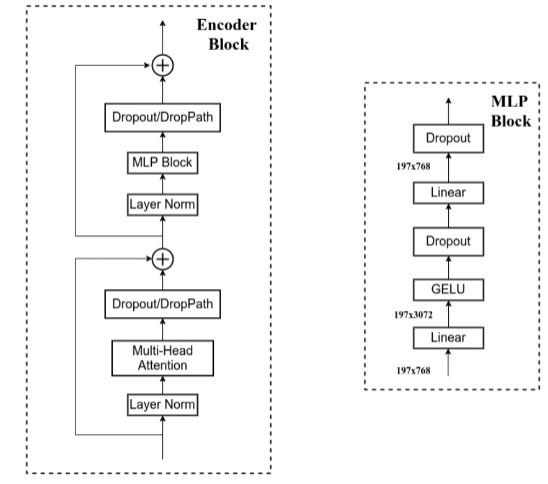
下图是Encoder Block和 MLP Block的内部结构图
分析与评估
PRE-TRAINING DATA REQUIREMENTS—预训练数据要求
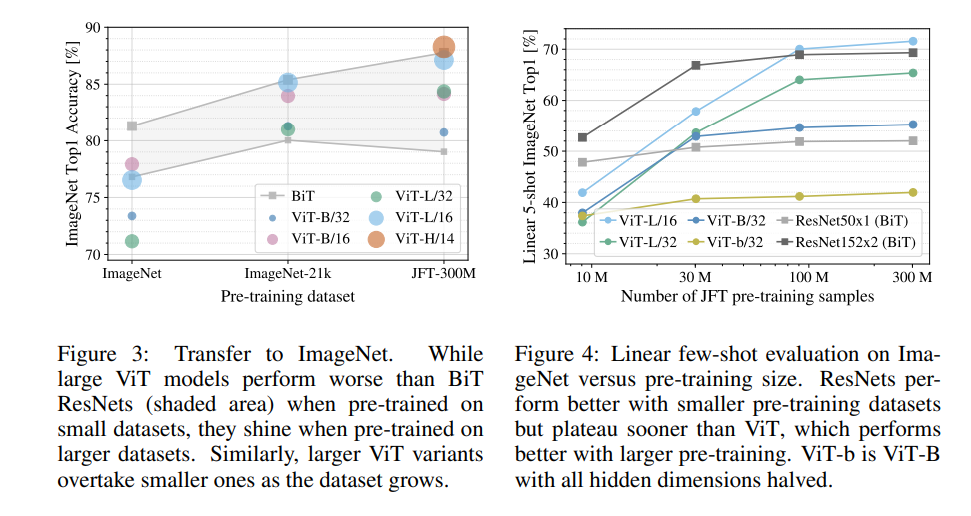
图3展示了模型在 ImageNet 数据集上的性能,图4展示了在 JFT300M 数据集的随机子集以及完整数据集上进行了模型训练的结果。
结论:卷积归纳偏置对于规模较小的数据集较为有用,但对于较大的数据集而言,学习相关模式就足够了,甚至更加有效。同时VIT在小样本的训练可能是一个不错的研究方向。
INSPECTING VISION TRANSFORMER—检查vision transformer
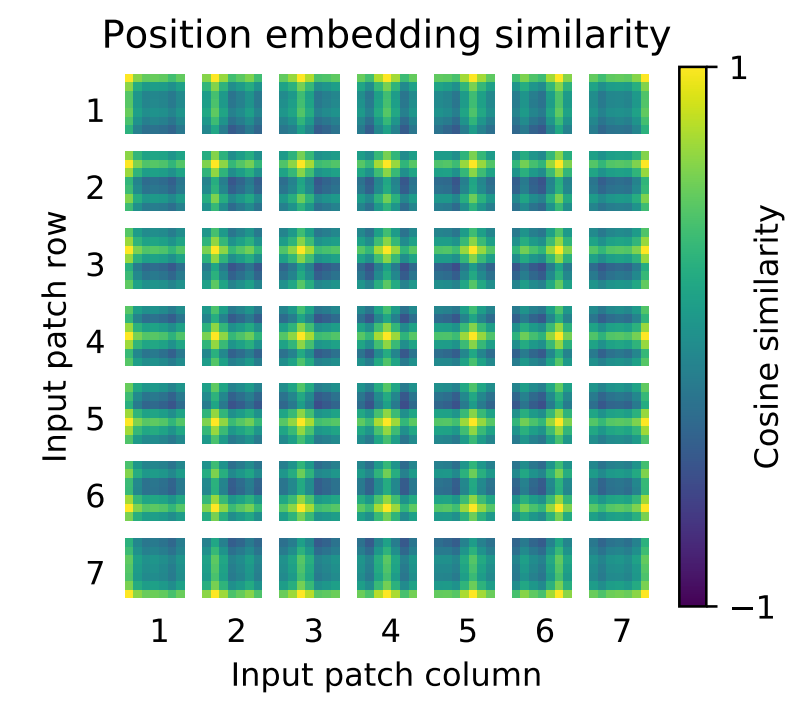
上图为ViT-L/32 的position embedding的相似性。
位置编码:相似性(余弦相似度),所以相似性越高接近1,越低越接近-1。
跟自己相似性最高,同行同列相似性也比较高,虽然是1D编码但是学习到了2D图像的概念(所以使用1D和2D表示位置准确率相差不大)。
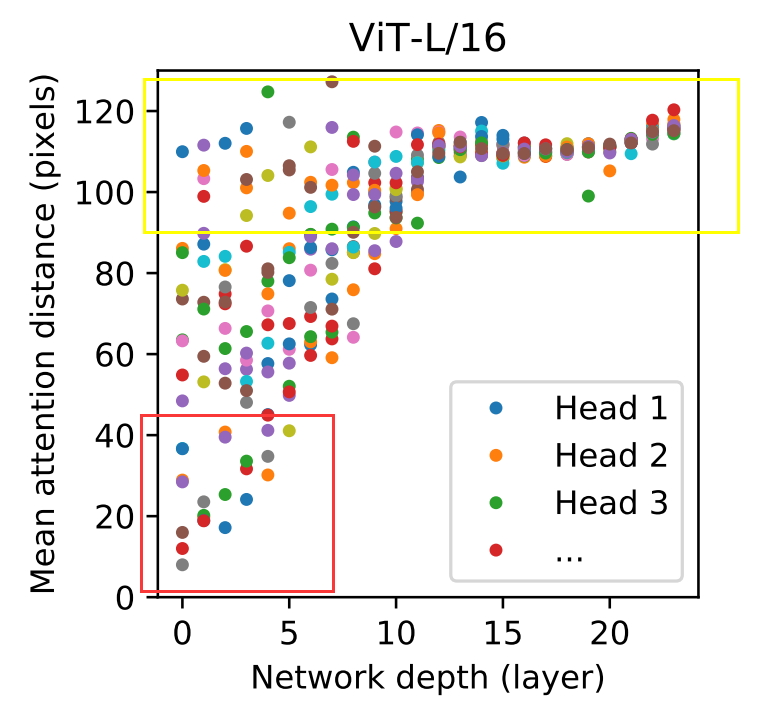
上图按heads和网络深度划分的参与区域大小。
红框部分表示像素点相近的自注意力学习到的信息,黄色框部分表示像素点距离远的自注意力学习到的信息。
横坐标为网络层数,可以看出在浅层网络就能学习到全局(距离远)的信息了,但是在传统卷积网络中,浅层感受野小只能学习到局部信息。
在深层网络基本上就是高层语义信息(像素点之间距离远)。
下图中右边Attention列出来的图,就代表了高层的语义信息。

结论:
(1)模型使用了全局集成信息的能力。其他注意力head在低层中始终具有较小的注意力距离。
(2)该模型关注与分类语义相关的图像区域。
总结与展望
将图片处理成 patch 序列,然后使用 Transformer 去处理,取得了接近或超过卷积神经网络的结果,同时训练起来也更快。
在提取patch和进行位置编码时使用了一些图像特有的归纳偏置,其他和transformer一致。 ( 简单、扩展性好)
将ViT应用于其他计算机视觉任务,如检测和分割。
自监督也行,但是目前还没有监督效果好,继续探索自我监督的预训练方法。
可以进一步扩大ViT的规模,随着模型尺寸的增加,参数越多,性能似乎还没有饱和。(后续原作者的论文证实了这一点)
通过只用transformer实现多模态大一统。
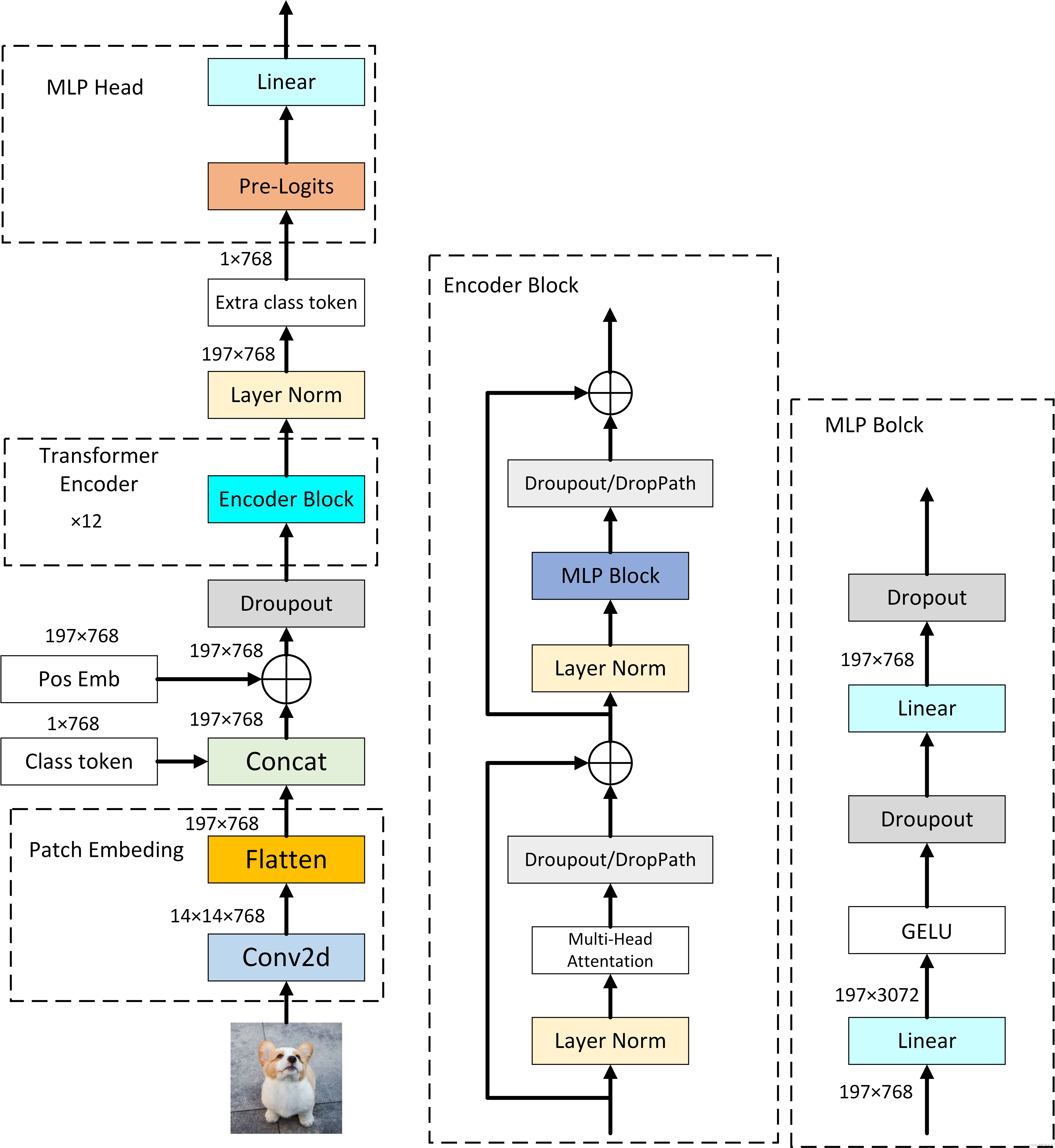
VIT详细网络结构
相关文章:
Vision Transformer论文阅读笔记
目录 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale -- Vision Transformer摘要Introduction—简介RELATED WORK—相关工作METHOD—方法VISION TRANSFORMER (VIT)—视觉Transformer(ViT) 分析与评估PRE-TRAINING DATA REQUIREMENTS—预训练数据…...

MapReduce的执行流程排序
MapReduce 是一种用于处理大规模数据集的分布式计算模型。它将作业分成多个阶段,以并行处理和分布式存储的方式来提高计算效率。以下是 MapReduce 的执行流程以及各个阶段的详细解释: 1. 作业提交(Job Submission) 用户通过客户端…...

雅思词汇及发音积累 2024.7.3
银行 check (美)支票 cheque /tʃek/ (英)支票 ATM 自动取款机 cashier 收银员 teller /ˈtelə(r)/ (银行)出纳员 loan 贷款 draw/withdraw money 提款 pin number/passsword/code …...

Vue2和Vue3的区别Vue3的组合式API
一、Vue2和Vue3的区别 1、创建方式的不同: (1)、vue2:是一个构造函数,通过该构造函数创建一个Vue实例 new Vue({})(2)、Vue3:是一个对象。并通过该对象的createApp()方法,创建一个vue实例。 Vue…...

ML307R OpenCPU HTTP使用
一、函数介绍 二、示例代码 三、代码下载地址 一、函数介绍 具体函数可以参考cm_http.h文件,这里给出几个我用到的函数 1、创建客户端实例 /*** @brief 创建客户端实例** @param [in] url 服务器地址(服务器地址url需要填写完整,例如(服务器url仅为格式示…...

【状态估计】线性高斯系统的状态估计——离散时间的递归滤波
前两篇文章介绍了离散时间的批量估计、离散时间的递归平滑,本文着重介绍离散时间的递归滤波。 前两篇位置:【状态估计】线性高斯系统的状态估计——离散时间的批量估计、【状态估计】线性高斯系统的状态估计——离散时间的递归平滑。 离散时间的递归滤波…...
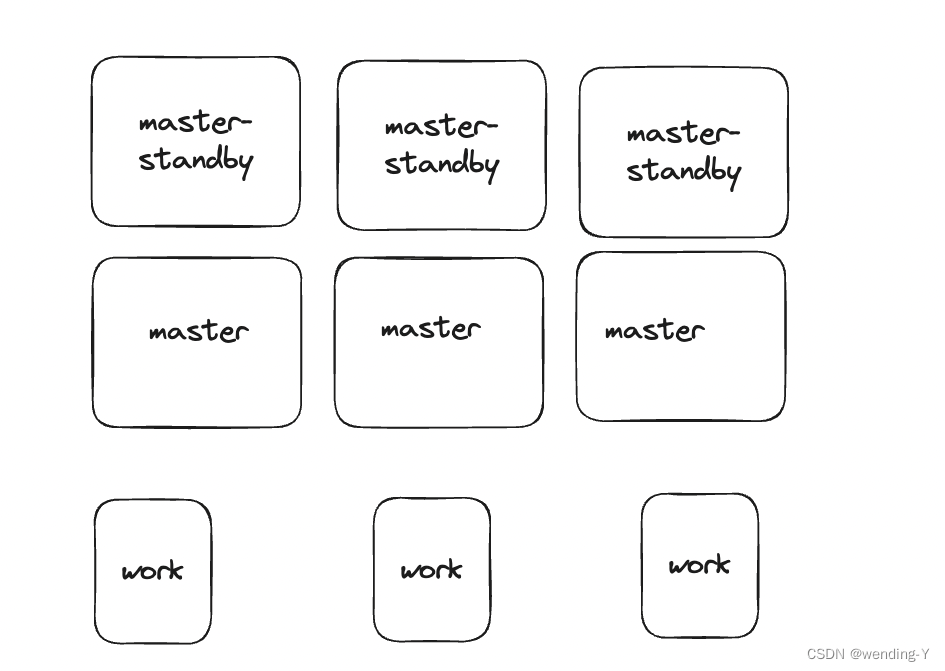
架构设计上中的master三种架构,单节点,主从节点,多节点分析
文章目录 背景单节点优点缺点 主从节点优点缺点 多节点优点缺点 多节点,多backup设计优点缺点 总结 背景 在很多分布式系统里会有master,work这种结构。 master 节点负责管理资源,分发任务。下面着重讨论下master 数量不同带来的影响 单节点 优点 1.设…...

如何在 SQL 中删除一条记录?
如何在 SQL 中删除一条记录? 在 SQL 中,您可以使用DELETE查询和WHERE子句删除表中的一条记录。在本文中,我将向您介绍如何使用DELETE查询和WHERE子句删除记录。我还将向您展示如何一次从表中删除多条记录 如何在 SQL 中使用 DELETE 这是使…...
JavaSE (Java基础):面向对象(上)
8 面向对象 面向对象编程的本质就是:以类的方法组织代码,以对象的组织(封装)数据。 8.1 方法的回顾 package com.oop.demo01;// Demo01 类 public class Demo01 {// main方法public static void main(String[] args) {int c 10…...

flink使用StatementSet降低资源浪费
背景 项目中有很多ods层(mysql 通过cannal)kafka,需要对这些ods kakfa做一些etl操作后写入下一层的kafka(dwd层)。 一开始采用的是executeSql方式来执行每个ods→dwd层操作,即类似: def main(…...

FineDataLink4.1.9支持Kettle调用
FDL更新至4.1.9后,新增kettle调用功能,支持不增加额外负担的情况下,将现有的Kettle任务平滑迁移到FineDataLink。 一、更新版本前存在的问题与痛点 在此次功能更新前,用户可能会遇到以下问题: 1.对于仅使用kettle的…...

SwanLinkOS首批实现与HarmonyOS NEXT互联互通,软通动力子公司鸿湖万联助力鸿蒙生态统一互联
在刚刚落下帷幕的华为开发者大会2024上,伴随全场景智能操作系统HarmonyOS Next的盛大发布,作为基于OpenHarmony的同根同源系统生态,软通动力子公司鸿湖万联全域智能操作系统SwanLinkOS首批实现与HarmonyOS NEXT互联互通,率先攻克基…...

Win11禁止右键菜单折叠的方法
背景 在使用windows11的时候,会发现默认情况下,右键菜单折叠了。以至于在使用一些软件的右键菜单时总是要点击“显示更多选项”菜单展开所有菜单,然后再点击。而且每次在显示菜单时先是全部展示,再隐藏一下,看着着实难…...
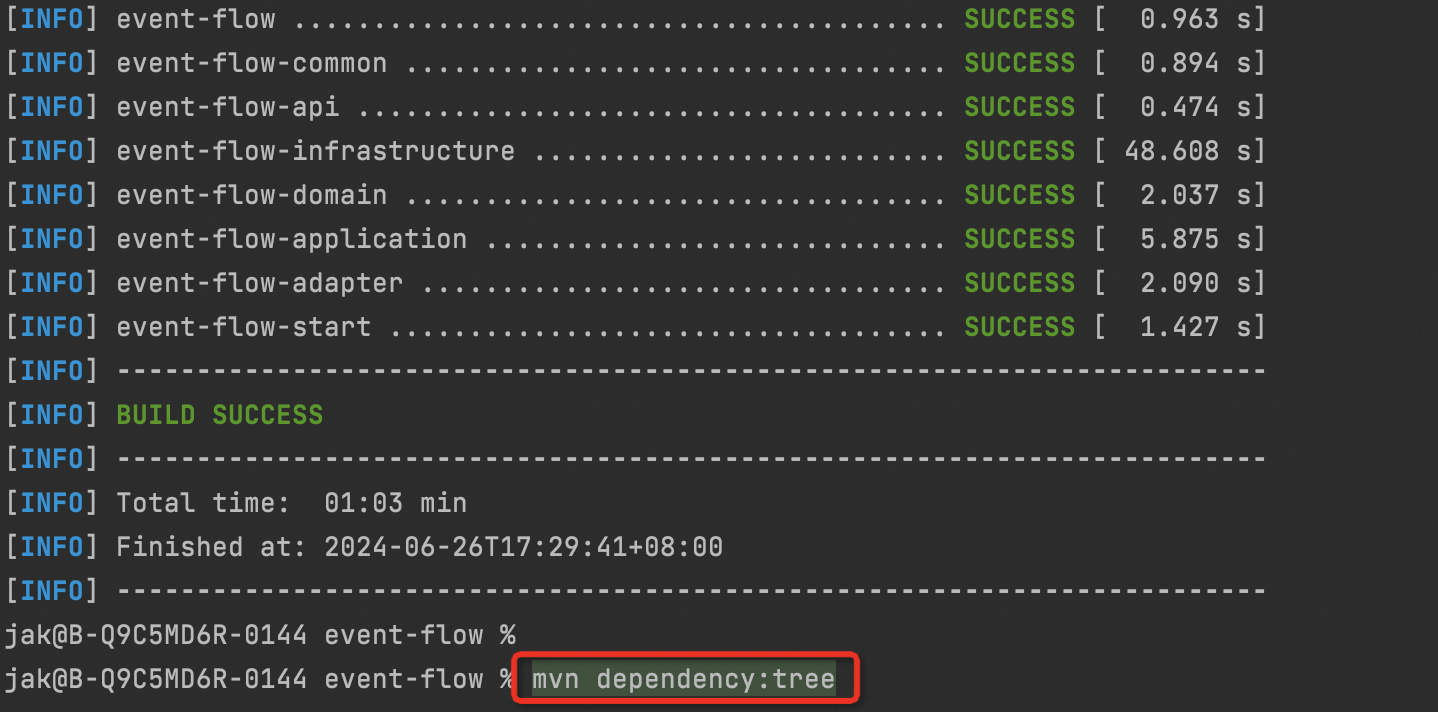
Maven列出所有的依赖树
在 IntelliJ IDEA 中,你可以使用 Maven 插件来列出项目的依赖树。Maven 插件提供了一个名为dependency:tree的目标,可以帮助你获取项目的依赖树详细信息。 要列出项目的依赖树,可以执行以下步骤: 打开 IntelliJ IDEA,…...

测试开发面试题和答案
Python 请解释Python中的列表推导式(List Comprehension)是什么,并给出一个示例。 答案: 列表推导式是Python中一种简洁的构建列表的方法。它允许从一个已存在的列表创建新列表,同时应用一个表达式来修改或选择元素。…...

llm学习-3(向量数据库的使用)
1:数据读取和加载 接着上面的常规操作 加载环境变量---》获取所有路径---》加载文档---》切分文档 代码如下: import os from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv()) # 获取folder_path下所有文件路径,储存在…...
【01-02】Mybatis的配置文件与基于XML的使用
1、引入日志 在这里我们引入SLF4J的日志门面,使用logback的具体日志实现;引入相关依赖: <!--日志的依赖--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version&g…...
)
Linux-进程间通信(IPC)
进程间通信(IPC)介绍 进程间通信(IPC,InterProcess Communication)是指在不同的进程之间传播或交换信息。IPC 的方式包括管道(无名管道和命名管道)、消息队列、信号量、共享内存、Socket、Stre…...

C++ STL: std::vector与std::array的深入对比
什么是 std::vector 和 std::array 首先,让我们简要介绍一下这两种容器: • std::vector:一个动态数组,可以根据需要动态调整其大小。 • std::array:一个固定大小的数组,其大小在编译时确定。 虽然…...

哈哈看到这条消息感觉就像是打开了窗户
在这个信息爆炸的时代,每一条动态可能成为我们情绪的小小触发器。今天,当我无意间滑过那条由杜海涛亲自发布的“自曝式”消息时,不禁心头一颤——如果这是我的另一半,哎呀,那画面,简直比烧烤摊还要“热辣”…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

机器学习结合基因无关通路映射:从临床数据挖掘新药靶点
1. 项目概述:当机器学习遇见代谢通路,如何从数据中“挖”出新药靶点?在生物医学研究的前沿,我们正面临一个核心矛盾:一方面,我们拥有海量的临床数据,比如血糖、血压、BMI等指标;另一…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

2605.VGGT-Omega 论文解读: 3D重建的Scaling Law, Register Attention效率革命 | Oxford+Meta CVPR26 Oral
VGGT-Omega: Scaling Feed-Forward 3D Reconstruction Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schonberger, et al. Visual Geometry Group, Oxford Meta AI | CVPR 2026 Oral | arXiv 2605.15195 Paper | Project Page 一句话总结 VGGT-Om…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题
如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...

面试官问LinkedBlockingQueue和ArrayBlockingQueue区别?别只答有界无界了,这3个实战坑才是重点
面试官追问LinkedBlockingQueue与ArrayBlockingQueue?别只答基础区别,这3个实战陷阱才是关键 当面试官抛出"LinkedBlockingQueue和ArrayBlockingQueue有什么区别"这个问题时,80%的候选人会条件反射般回答"一个有界一个无界&qu…...