NLP - 基于bert预训练模型的文本多分类示例
项目说明
项目名称
基于DistilBERT的标题多分类任务
项目概述
本项目旨在使用DistilBERT模型对给定的标题文本进行多分类任务。项目包括从数据处理、模型训练、模型评估到最终的API部署。该项目采用模块化设计,以便于理解和维护。
项目结构
.
├── bert_data
│ ├── train.txt
│ ├── dev.txt
│ └── test.txt
├── saved_model
├── results
├── logs
├── data_processing.py
├── dataset.py
├── training.py
├── app.py
└── main.py
文件说明
-
bert_data/:存放训练集、验证集和测试集的数据文件。
- train.txt
- dev.txt
- test.txt
-
saved_model/:存放训练好的模型和tokenizer。
-
results/:存放训练结果。
-
logs/:存放训练日志。
-
data_processing.py:数据处理模块,负责读取和预处理数据。
-
dataset.py:数据集类模块,定义了用于训练和评估的数据集类。
-
training.py:模型训练模块,定义了训练和评估模型的过程。
-
app.py:模型部署模块,使用FastAPI创建API服务。
-
main.py:主脚本,运行整个流程,包括数据处理、模型训练和部署。
数据集数据规范
为了确保数据处理和模型训练的顺利进行,请按照以下规范准备数据集文件。每个文件包含的标题和标签分别使用制表符(\t)分隔。以下是一个示例数据集的格式。
数据文件格式
数据文件应为纯文本文件,扩展名为.txt,文件内容的每一行应包含一个文本标题和一个对应的分类标签,用制表符分隔。数据文件不应包含表头。
数据示例
探索神秘的海底世界 7
如何在家中制作美味披萨 2
全球气候变化的原因和影响 1
最新的智能手机评测 8
健康饮食:如何搭配均衡的膳食 5
最受欢迎的电影和电视剧推荐 3
了解宇宙的奥秘:天文学入门 0
如何种植和照顾多肉植物 9
时尚潮流:今年夏天的必备单品 6
如何有效管理个人财务 4
注意事项
- 标签规范:确保每个标题文本的标签是一个整数,表示类别。
- 文本编码:确保数据文件使用UTF-8编码,避免中文字符乱码。
- 数据一致性:确保训练、验证和测试数据格式一致,便于数据加载和处理。
通过以上规范和示例数据文件创建方法,可以确保数据文件符合项目需求,并顺利进行数据处理和模型训练。
模块说明
1. 数据处理模块 (data_processing.py)
功能:读取数据文件并进行预处理。
load_data(file_path): 读取指定路径的数据文件,并返回一个包含文本和标签的数据框。tokenize_data(data, tokenizer, max_length=128): 使用BERT的tokenizer对数据进行tokenize处理。main(): 加载数据、tokenize数据并返回处理后的数据。
2. 数据集类模块 (dataset.py)
功能:定义数据集类,便于模型训练。
TextDataset: 将tokenized数据和标签封装成PyTorch的数据集格式,便于Trainer进行训练和评估。
3. 模型训练模块 (training.py)
功能:定义训练和评估模型的过程。
train_model(): 加载数据和tokenizer,创建数据集,加载模型,设置训练参数,定义Trainer,训练和评估模型,保存训练好的模型和tokenizer。
4. 模型部署模块 (app.py)
功能:使用FastAPI进行模型部署。
predict(item: Item): 接收POST请求的文本输入,使用训练好的模型进行预测并返回分类结果。- FastAPI应用启动配置。
5. 主脚本 (main.py)
功能:运行整个流程,包括数据处理、模型训练和部署。
main(): 运行模型训练流程,并输出训练完成的提示。
运行步骤
- 安装依赖
pip install pandas torch transformers fastapi uvicorn scikit-learn
- 数据处理
确保bert_data文件夹下包含train.txt、dev.txt和test.txt文件,每个文件包含文本和标签,使用制表符分隔。
- 训练模型
运行main.py脚本,进行数据处理和模型训练:
python main.py
训练完成后,模型和tokenizer将保存在saved_model文件夹中。
- 部署模型
运行app.py脚本,启动API服务:
uvicorn app:app --reload
服务启动后,可以通过POST请求访问预测接口,进行文本分类预测。
示例请求
curl -X POST "http://localhost:8000/predict" -H "Content-Type: application/json" -d '{"text": "你的文本"}'
返回示例:
{"prediction": 3
}
注意事项
- 确保数据文件格式正确,每行包含一个文本和对应的标签,使用制表符分隔。
- 调整训练参数(如batch size和训练轮数)以适应不同的GPU配置。
- 使用
nvidia-smi监控显存使用,避免显存溢出。
项目代码
1. 数据处理模块
功能:读取数据文件并进行预处理。
# data_processing.py
import pandas as pd
from transformers import DistilBertTokenizerdef load_data(file_path):data = pd.read_csv(file_path, delimiter='\t', header=None)data.columns = ['text', 'label']return datadef tokenize_data(data, tokenizer, max_length=128):encodings = tokenizer(list(data['text']), truncation=True, padding=True, max_length=max_length)return encodingsdef main():# 加载Tokenizertokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-chinese')# 加载数据train_data = load_data('./bert_data/train.txt')dev_data = load_data('./bert_data/dev.txt')test_data = load_data('./bert_data/test.txt')# Tokenize数据train_encodings = tokenize_data(train_data, tokenizer)dev_encodings = tokenize_data(dev_data, tokenizer)test_encodings = tokenize_data(test_data, tokenizer)return train_encodings, dev_encodings, test_encodings, train_data['label'], dev_data['label'], test_data['label']if __name__ == "__main__":main()
2. 数据集类模块
功能:定义数据集类,便于模型训练。
# dataset.py
import torchclass TextDataset(torch.utils.data.Dataset):def __init__(self, encodings, labels):self.encodings = encodingsself.labels = labelsdef __getitem__(self, idx):item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}item['labels'] = torch.tensor(self.labels[idx])return itemdef __len__(self):return len(self.labels)
3. 模型训练模块
功能:定义训练和评估模型的过程。
# training.py
import torch
from transformers import DistilBertForSequenceClassification, Trainer, TrainingArguments
from dataset import TextDataset
import data_processingdef train_model():# 加载数据和tokenizertrain_encodings, dev_encodings, test_encodings, train_labels, dev_labels, test_labels = data_processing.main()# 创建数据集train_dataset = TextDataset(train_encodings, train_labels)dev_dataset = TextDataset(dev_encodings, dev_labels)test_dataset = TextDataset(test_encodings, test_labels)# 加载DistilBERT模型model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-chinese', num_labels=10)model.to(torch.device("cuda" if torch.cuda.is_available() else "cpu"))# 设置训练参数training_args = TrainingArguments(output_dir='./results', # 输出结果目录num_train_epochs=3, # 训练轮数per_device_train_batch_size=16, # 训练时每个设备的批量大小per_device_eval_batch_size=64, # 验证时每个设备的批量大小warmup_steps=500, # 训练步数weight_decay=0.01, # 权重衰减logging_dir='./logs', # 日志目录fp16=True, # 启用混合精度训练)# 定义Trainertrainer = Trainer(model=model, # 预训练模型args=training_args, # 训练参数train_dataset=train_dataset, # 训练数据集eval_dataset=dev_dataset # 验证数据集)# 训练模型trainer.train()# 评估模型eval_results = trainer.evaluate()print(eval_results)# 保存模型model.save_pretrained('./saved_model')tokenizer.save_pretrained('./saved_model')if __name__ == "__main__":train_model()
4. 模型部署模块
功能:使用FastAPI进行模型部署。
# app.py
from fastapi import FastAPI
from pydantic import BaseModel
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
import torchapp = FastAPI()# 加载模型和tokenizer
model = DistilBertForSequenceClassification.from_pretrained('./saved_model')
tokenizer = DistilBertTokenizer.from_pretrained('./saved_model')class Item(BaseModel):text: str@app.post("/predict")
def predict(item: Item):inputs = tokenizer(item.text, return_tensors="pt", max_length=128, padding='max_length', truncation=True)outputs = model(**inputs)prediction = torch.argmax(outputs.logits, dim=1)return {"prediction": prediction.item()}if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=8000)
5. 主脚本
功能:运行整个流程,包括数据处理、模型训练和部署。
# main.py
import trainingdef main():# 训练模型training.train_model()print("模型训练完成并保存。")if __name__ == "__main__":main()
详细说明
-
数据处理模块:
- 读取训练集、验证集和测试集的数据文件。
- 使用BERT的Tokenizer对数据进行tokenize处理,生成模型可接受的输入格式。
- 提供主要的数据处理函数,包括加载数据和tokenize数据。
-
数据集类模块:
- 定义一个
TextDataset类,用于将tokenized数据和标签封装成PyTorch的数据集格式,便于Trainer进行训练和评估。
- 定义一个
-
模型训练模块:
- 使用数据处理模块加载和tokenize数据。
- 创建训练和验证数据集。
- 加载DistilBERT模型,并设置训练参数(包括启用混合精度训练)。
- 使用
Trainer进行模型训练和评估,并保存训练好的模型。
-
模型部署模块:
- 使用FastAPI创建一个简单的API服务。
- 加载保存的模型和tokenizer。
- 定义一个预测接口,通过POST请求接收文本输入并返回分类预测结果。
-
主脚本:
- 运行模型训练流程,并输出训练完成的提示。
相关文章:

NLP - 基于bert预训练模型的文本多分类示例
项目说明 项目名称 基于DistilBERT的标题多分类任务 项目概述 本项目旨在使用DistilBERT模型对给定的标题文本进行多分类任务。项目包括从数据处理、模型训练、模型评估到最终的API部署。该项目采用模块化设计,以便于理解和维护。 项目结构 . ├── bert_dat…...

数据库备份和还原
一、备份 备份类型 1.完全备份 全备份是指对整个数据集进行完整备份。每次备份都会复制所有选定的数据,无论这些数据是否发生了变化。 2.增量备份 增量备份是指仅备份自上次备份(无论是全备份还是增量备份)以来发生变化的数据。它记录了…...
谷粒商城-个人笔记(集群部署篇一)
前言 学习视频:Java项目《谷粒商城》架构师级Java项目实战,对标阿里P6-P7,全网最强学习文档: 谷粒商城-个人笔记(基础篇一)谷粒商城-个人笔记(基础篇二)谷粒商城-个人笔记(基础篇三)谷粒商城-个人笔记(高级篇一)谷粒商城-个…...

Linux环境下的字节对齐现象
在Linux环境下,字节对齐是指数据在内存中的存储方式。字节对齐是为了提高内存访问的效率和性能。 在Linux中,默认情况下,结构体和数组的成员会进行字节对齐。具体的对齐方式可以通过编译器选项来控制。 在使用C语言编写程序时,可…...
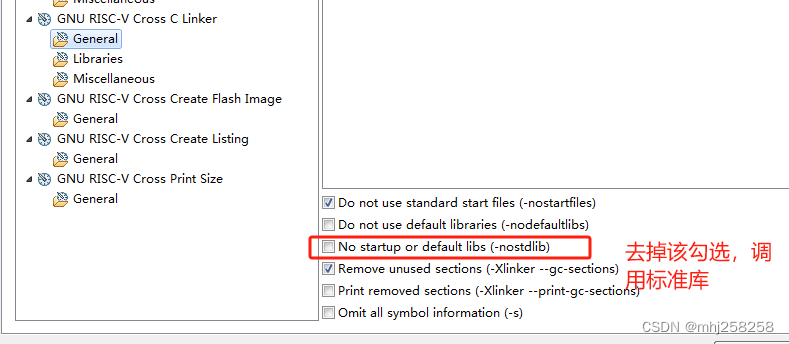
没有调用memcpy却报了undefined reference to memcpy错误
现象 在第5行出现了,undefined reference to memcpy’ 1 static void printf_x(unsigned int val) 2{ 3 char buffer[32]; 4 const char lut[]{0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F}; 5 char *p buffer; 6 while (val || p buffer) { 7 *(p) …...

import和require的区别
import是ES6标准中的模块化解决方案,require是node中遵循CommonJS规范的模块化解决方案。 后者支持动态引入,也就是require(${path}/xx.js),前者目前不支持,但是已有提案。 前者是关键词,后者不是。 前者是编译时加…...

白骑士的Python教学高级篇 3.3 数据库编程
系列目录 上一篇:白骑士的Python教学高级篇 3.2 网络编程 SQL基础 Structured Query Language (SQL) 是一种用于管理和操作关系型数据库的标准语言。SQL能够执行各种操作,如创建、读取、更新和删除数据库中的数据(即CRUD操作)&a…...

macOS 安装redis
安装Redis在macOS上通常通过Homebrew进行,Homebrew是macOS上一个流行的包管理器。以下是安装Redis的步骤: 一 使用Homebrew安装Redis 1、安装Homebrew(如果尚未安装): 打开终端(Terminal)并执…...
【AIGC评测体系】大模型评测指标集
大模型评测指标集 (☆)SuperCLUE(1)SuperCLUE-V(中文原生多模态理解测评基准)(2)SuperCLUE-Auto(汽车大模型测评基准)(3)AIGVBench-T2…...

工厂模式之简单工厂模式
文章目录 工厂模式工厂模式分为工厂模式的角色简单工厂模式案例代码定义一个父类,三个子类定义简单工厂客户端使用输出结果 工厂模式 工厂模式属于创造型的模式,用于创建对象。 工厂模式分为 简单工厂模式:定义一个简单工厂类,根…...

2.(vue3.x+vite)调用iframe的方法(vue编码)
1、效果预览 2.编写代码 (1)主页面 <template><div><button @click="sendMessage">调用iframe,并发送信息...

实战项目——用Java实现图书管理系统
前言 首先既然是管理系统,那咱们就要实现以下这几个功能了--> 分析 1.首先是用户分为两种,一个是管理员,另一个是普通用户,既如此,可以定义一个用户类(user),在定义管理员类&am…...

利用DeepFlow解决APISIX故障诊断中的方向偏差问题
概要:随着APISIX作为IT应用系统入口的普及,其故障定位能力的不足导致了在业务故障诊断中,APISIX常常成为首要的“嫌疑对象”。这不仅导致了“兴师动众”式的资源投入,还可能使诊断方向“背道而驰”,从而导致业务故障“…...

sqlalchemy获取数据条数
1、sqlalchemy获取数据条数 在SQLAlchemy中,你可以使用count()函数来获取数据表中的记录条数。 from sqlalchemy import create_engine, MetaData, Table# 数据库连接字符串 DATABASE_URI = dialect+driver://username:password@host:port/database# 创建引擎 engine = crea…...
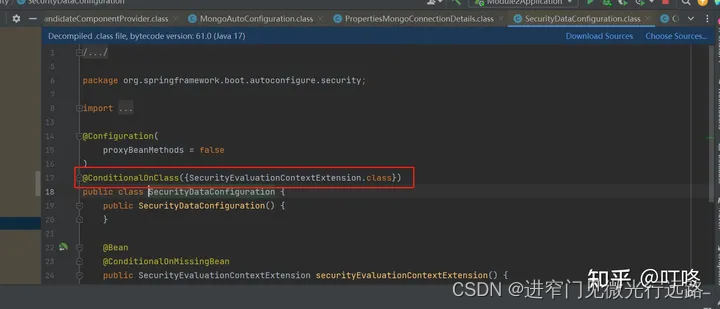
SpringBoot的自动配置核心原理及拓展点
Spring Boot 的核心原理几个关键点 约定优于配置: Spring Boot 遵循约定优于配置的理念,通过预定义的约定,大大简化了 Spring 应用程序的配置和部署。例如,它自动配置了许多常见的开发任务(如数据库连接、Web 服务器配…...

用随机森林算法进行的一次故障预测
本案例将带大家使用一份开源的S.M.A.R.T.数据集和机器学习中的随机森林算法,来训练一个硬盘故障预测模型,并测试效果。 实验目标 掌握使用机器学习方法训练模型的基本流程;掌握使用pandas做数据分析的基本方法;掌握使用scikit-l…...
24位DAC转换的FPGA设计及将其封装成自定义IP核的方法
在vivado设计中,为了方便的使用Block Desgin进行设计,可以使用vivado软件把自己编写的代码封装成IP核,封装后的IP核和原来的代码具有相同的功能。本文以实现24位DA转换(含并串转换,使用的数模转换器为CL4660)为例,介绍VIVADO封装IP核的方法及调用方法,以及DAC转换的详细…...
【大模型LLM面试合集】大语言模型基础_llm概念
1.llm概念 1.目前 主流的开源模型体系 有哪些? 目前主流的开源LLM(语言模型)模型体系包括以下几个: GPT(Generative Pre-trained Transformer)系列:由OpenAI发布的一系列基于Transformer架构…...

Qt时间日期处理与定时器使用总结
一、日期时间数据 1.QTime 用于存储和操作时间数据的类,其中包括小时(h)、分钟(m)、秒(s)、毫秒(ms)。函数定义如下: //注:秒(s)和毫秒(ms)有默认值0 QTime::QTime(int h, int m, int s 0, int ms 0) 若无须初始化时间数据,可…...

数据结构——Hash Map
1. Hash Map简介 Hash Map是一种基于键值对的数据结构,通过散列函数将键映射到存储位置,实现快速的数据查找和存储。它可以在常数时间内完成查找、插入和删除操作,因此在需要频繁进行这些操作时非常高效。 2. Hash Map的定义 散列表ÿ…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南
终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否渴望享受WeMod Pro会员的所…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

MeloTTS实战:多语言语音合成的高效解决方案
MeloTTS实战:多语言语音合成的高效解决方案 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trending/me/…...