数据结构——Hash Map
1. Hash Map简介
Hash Map是一种基于键值对的数据结构,通过散列函数将键映射到存储位置,实现快速的数据查找和存储。它可以在常数时间内完成查找、插入和删除操作,因此在需要频繁进行这些操作时非常高效。
2. Hash Map的定义
散列表(Hash table,也叫哈希表)是一种根据键(Key)直接访问内存存储位置的数据结构。通过计算一个键值的函数,将数据映射到表中的一个位置,以加快查找速度。这个映射函数称为散列函数,存放记录的数组称为散列表。
3. 为什么要使用Hash Map?
理想的搜索方法是不经过任何比较,一次直接从表中得到要搜索的元素,即查找的时间复杂度为 O(1)。哈希表通过哈希函数将元素的存储位置与其关键码之间建立一种映射关系,从而实现快速查找。
4. 键值对
键值对是一种常见的数据结构,用于表示两个相关联的数据项:一个是“键”(Key),另一个是“值”(Value)。键用于标识和查找与之关联的值。键值对在许多编程语言中都有特定的表示方法,例如C++的std::pair和Python的字典(dictionary)。
python
dictionary = {"name": "Alice", "age": 30}在C++中:
std::pair<std::string, int> person("Alice", 30);5. Hash Map的基本实现
通过一个简单的数学公式实现Hash Map:
假设有数据集合 {1, 7, 6, 4, 5, 9},哈希函数为:hash(key) = key % capacity,其中capacity为10。存储位置如下:
- 1 -> 1
- 7 -> 7
- 6 -> 6
- 4 -> 4
- 5 -> 5
- 9 -> 9
6. 哈希冲突
如果插入元素66,会与元素6冲突,因为它们的哈希地址相同(都是6)。哈希冲突是指不同关键字通过相同哈希函数计算出相同哈希地址的现象。为了避免冲突,需要设计合理的哈希函数。
7. 改进哈希函数
哈希函数设计原则包括:
哈希函数的定义域必须包括需要存储的全部关键码。
哈希函数计算出来的地址能均匀分布在整个空间中。
哈希函数应该比较简单。
常用哈希函数设计方法:
1. 直接定址法:Hash(Key) = A * Key + B
2. 除留余数法:Hash(key) = key % p (p <= m)
3. 平方取中法:假设关键字为1234,对其平方得到1522756,取中间的3位227作为哈希地址。
4. 折叠法:将关键字分割成几部分,将这些部分叠加求和,取后几位作为哈希地址。
5. 随机数法:选择一个随机函数,取关键字的随机函数值为其哈希地址。
8. 解决哈希冲突的方法
解决哈希冲突的两种常见方法是闭散列和开散列。
8.1 闭散列(开放定址法)
当发生哈希冲突时,将元素存放到冲突位置的下一个空位置中。
线性探测:从冲突位置开始,依次向后探测,直到找到下一个空位置。
查找公式:hashi = hash(key) % N + i(i = 0, 1, 2, 3, ...)
二次探测:为了避免线性探测中的堆积问题,使用平方探测法。找下一个空位置的方法为:hashi = hash(key) % N + i^2(i = 1, 2, 3, 4 ...)
8.2 开散列(链地址法)
将具有相同地址的元素归于同一桶,桶中的元素通过单链表链接起来。哈希桶的极端情况是所有元素都产生冲突,最终都放入一个桶中,此时效率退化为 O(N)。
可以将桶中的链表结构改为红黑树结构,以提高效率。在JDK1.7中,HashMap由数组和链表组成;在JDK1.8中,引入了红黑树,当链表超过8且数组长度超过64时,链表会转换为红黑树,以提高性能。
9. 闭散列实现
以下是闭散列法的具体实现代码:
在python中
class ClosedHashMap:def __init__(self, capacity):self.capacity = capacityself.table = [None] * capacitydef hash_function(self, key):return key % self.capacitydef insert(self, key, value):index = self.hash_function(key)while self.table[index] is not None:index = (index + 1) % self.capacityself.table[index] = (key, value)def search(self, key):index = self.hash_function(key)while self.table[index] is not None:if self.table[index][0] == key:return self.table[index][1]index = (index + 1) % self.capacityreturn Nonedef delete(self, key):index = self.hash_function(key)while self.table[index] is not None:if self.table[index][0] == key:self.table[index] = Nonereturn Trueindex = (index + 1) % self.capacityreturn False10. 开散列实现
以下是开散列法的具体实现代码:
在python中
class Node:def __init__(self, key, value):self.key = keyself.value = valueself.next = Noneclass OpenHashMap:def __init__(self, capacity):self.capacity = capacityself.table = [None] * capacitydef hash_function(self, key):return key % self.capacitydef insert(self, key, value):index = self.hash_function(key)if self.table[index] is None:self.table[index] = Node(key, value)else:current = self.table[index]while current.next is not None:current = current.nextcurrent.next = Node(key, value)def search(self, key):index = self.hash_function(key)current = self.table[index]while current is not None:if current.key == key:return current.valuecurrent = current.nextreturn Nonedef delete(self, key):index = self.hash_function(key)current = self.table[index]prev = Nonewhile current is not None:if current.key == key:if prev is None:self.table[index] = current.nextelse:prev.next = current.nextreturn Trueprev = currentcurrent = current.nextreturn False这些实现展示了如何通过不同的方法来解决哈希冲突,确保Hash Map能够高效地插入和查找元素。
相关文章:

数据结构——Hash Map
1. Hash Map简介 Hash Map是一种基于键值对的数据结构,通过散列函数将键映射到存储位置,实现快速的数据查找和存储。它可以在常数时间内完成查找、插入和删除操作,因此在需要频繁进行这些操作时非常高效。 2. Hash Map的定义 散列表ÿ…...

剪画小程序:视频剪辑-视频播放倍数的调整与应用
在这个快节奏的时代,时间变得越来越宝贵,而视频倍数播放功能就像是我们的时间管理小助手,为我们的视频观看带来了极大的便利。你是否好奇它到底能在哪些地方发挥作用呢?让我们一起来看看! 只要使用小程序【剪画】的里…...
使用 Java Swing 和 XChart 创建多种图表
在现代应用程序开发中,数据可视化是一个关键部分。本文将介绍如何使用 Java Swing 和 XChart 库创建各种类型的图表。XChart 是一个轻量级的图表库,支持多种类型的图表,非常适合在 Java 应用中进行快速的图表绘制。 1、环境配置 在开始之前&…...

信息系统运维管理:实践与发展
信息系统运维管理:实践与发展 信息系统运维管理在现代企业中扮演着至关重要的角色,确保信息系统的高效、安全和稳定运行。本文结合《信息系统运维管理》文档内容,探讨了服务设计阶段、服务转换阶段、委托系统维护管理三个主要章节࿰…...
html+js+css登录注册界面
拥有向服务器发送登录或注册数据并接收返回数据的功能 点赞关注 界面 源代码 <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <title>Login and Registration Form</title> <style> * …...
数据中心GPU介绍)
英伟达(NVIDIA)数据中心GPU介绍
英伟达(NVIDIA)数据中心GPU按性能由高到低排行: 1. NVIDIA H100 架构:Hopper 核心数量:18352 CUDA Cores, 1456 Tensor Cores 显存:80 GB HBM3 峰值性能: 单精度(FP32)…...

Leetcode 3202. Find the Maximum Length of Valid Subsequence II
Leetcode 3202. Find the Maximum Length of Valid Subsequence II 1. 解题思路2. 代码实现 题目链接:3202. Find the Maximum Length of Valid Subsequence II 1. 解题思路 这一题的话是上一题3201. Find the Maximum Length of Valid Subsequence I的升级版&am…...

通过Spring Boot结合实时流媒体技术对考试过程进行实时监控
本章将深入探讨考试系统中常见的复杂技术问题,并提供基于Spring Boot 3.x的解决方案。涵盖屏幕切换检测与防护、接打电话识别处理、行为监控摄像头使用、网络不稳定应对等,每篇文章详细剖析问题并提供实际案例与代码示例,帮助开发者应对挑战&…...

智能扫地机器人避障与防跌落问题解决方案
智能扫地机器人出现避障与防跌落问题时,可以通过以下几种方式来解决: 一、避障问题的解决方案 1.升级避障技术: ① 激光雷达避障:激光雷达通过发射和接收激光信号来判断与障碍物的距离,具有延迟低、效果稳定、准确度…...

德旺训练营称重问题
这是考小学的分治策略,小学的分治策略几乎都是分三组。本着这个策略,我们做看看。 第一次称重: 分三组,16,16,17,拿两个16称,得到A情况,一样重,那么假铜钱在那组17个里面。B情况不…...

数据决策系统详解
文章目录 数据决策系统的核心组成部分:1. **数据收集与整合**:2. **数据处理与分析**:3. **数据可视化**:4. **决策支持**: 数据决策系统的功能:决策类型:数据决策系统对企业的重要性࿱…...

JSON 简述与应用
1. JSON 简述 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于客户端与服务器之间的数据传递。它基于JavaScript对象表示法,但独立于语言,可以被多种编程语言解析和生成。 1.1 特点 轻量级&#…...

ResNet50V2
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、ResNetV1和ResNetV2的区别 ResNetV2 和 ResNetV1 都是深度残差网络(ResNet)的变体,它们的主要区别在于残差块的设计和…...

基于深度学习的虚拟换装
基于深度学习的虚拟换装技术旨在通过计算机视觉和图像处理技术,将不同的服装虚拟地穿在用户身上,实现快速的试穿和展示。这项技术在电商、时尚和虚拟现实领域具有广泛的应用,能够提升用户体验,增加互动性。以下是关于这一领域的系…...

单段时间最优S型速度规划算法
一,背景 在做机械臂轨迹规划的单段路径的速度规划时,除了参考《Trajectory Planning for Automatic Machines and Robots》等文献之外,还在知乎找到了这位大佬 韩冰 写的在线规划方法: https://zhuanlan.zhihu.com/p/585253101/e…...

pom文件-微服务项目结构
一、微服务项目结构 my-microservices-project/ ├── pom.xml <!-- 父模块的pom.xml --> ├── ry-system/ │ ├── pom.xml <!-- 子模块ry-system的pom.xml --> │ └── src/main/java/com/example/rysystem/ │ └── RySystemApplication.…...

解析Kotlin中的Nothing【笔记摘要】
1.Nothing的本质 Nothing 的源码很简单: public class Nothing private constructor()可以看到它是个class,但它的构造函数是 private 的,这就导致我们没法创建它的实例,并且在源码里 Kotlin 也没有帮我们创建它的实例。 基于这…...

toRefs 和 toRef
文章目录 toRefs 和 toReftoRefstoRef toRefs 和 toRef toRefs toRefs 把一个由reactive对象的值变为一个一个ref的响应式的值 import { ref, reactive, toRefs, toRef } from vue; let person reactive({name: 张三,age: 18, }); // toRefs 把一个由reactive对象的值变为一…...
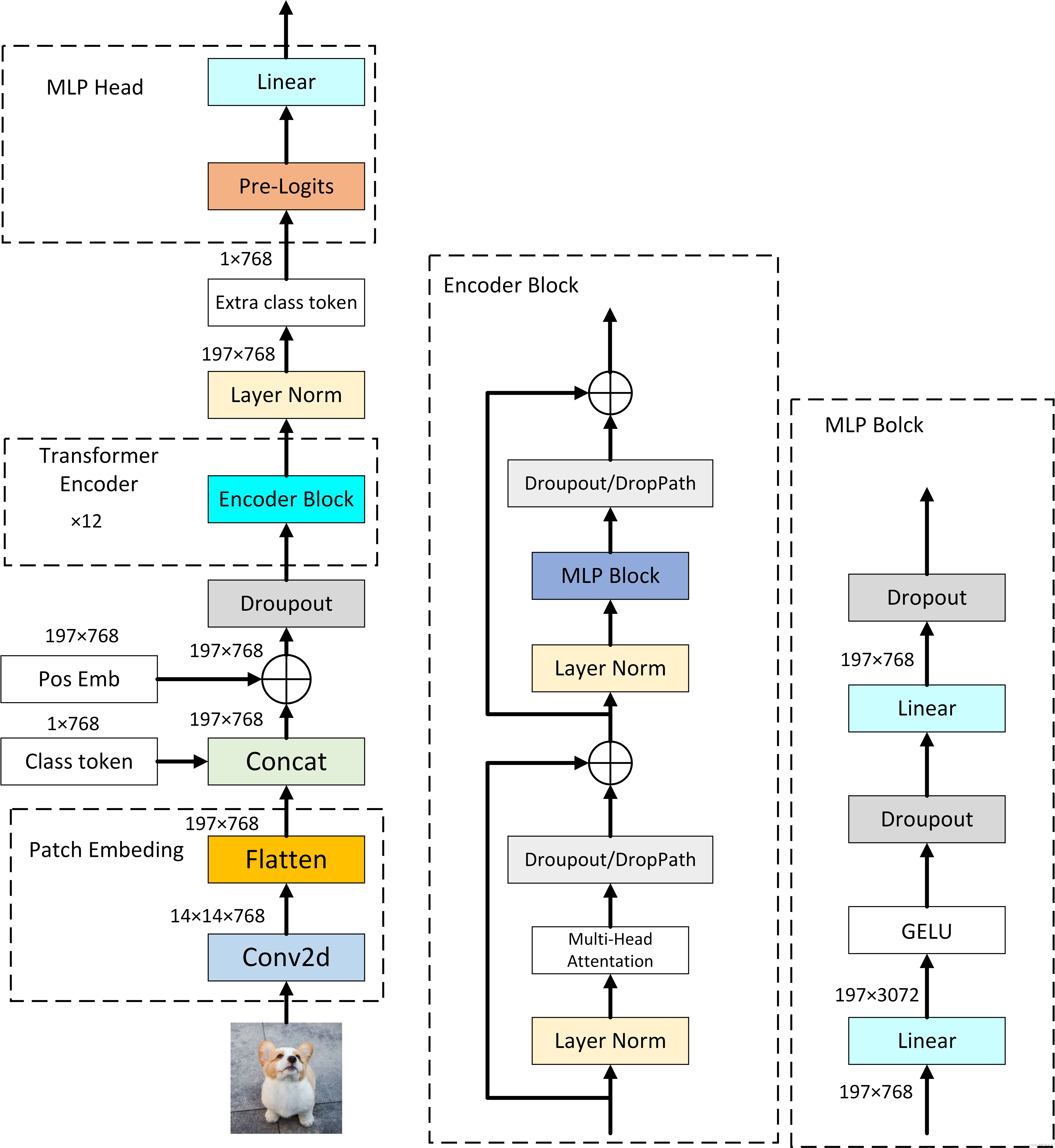
Vision Transformer论文阅读笔记
目录 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale -- Vision Transformer摘要Introduction—简介RELATED WORK—相关工作METHOD—方法VISION TRANSFORMER (VIT)—视觉Transformer(ViT) 分析与评估PRE-TRAINING DATA REQUIREMENTS—预训练数据…...

MapReduce的执行流程排序
MapReduce 是一种用于处理大规模数据集的分布式计算模型。它将作业分成多个阶段,以并行处理和分布式存储的方式来提高计算效率。以下是 MapReduce 的执行流程以及各个阶段的详细解释: 1. 作业提交(Job Submission) 用户通过客户端…...

Stitches API完全指南:从基础配置到自定义扩展
Stitches API完全指南:从基础配置到自定义扩展 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一款强大的HTML5 Sprite Sheet Generator,它提供了直观的API接口&…...

隧道裂缝剥落病害AI识别系统
我国现有公路隧道超2.5万座,总里程超2.8万公里,其中运营超过15年的老旧隧道占比达35%。据交通运输部2025年统计,年均因隧道结构病害导致的交通中断超1200次,直接经济损失超45亿元。传统检测模式暴露四大核心痛点:检测周…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

GEP协议深度解读:AI智能体自我进化的基因工程
OpenAI 官宣全面支持MCP协议,标志着AI应用架构的"连接标准"已定。如果说MCP是AI时代的USB-C,解决了模型与工具的连接问题,那么GEP(Genome Evolution Protocol,基因组进化协议)则正在解决另一个更本质的问题——智能体的自我进化与生命周期管理。 作为下一代AI基…...

观察不同模型在统一 API 下的响应速度与输出风格差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在统一 API 下的响应速度与输出风格差异 在为大语言模型应用选择模型时,开发者通常会关注两个核心维度&am…...

D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析
D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 当…...