利用DeepFlow解决APISIX故障诊断中的方向偏差问题
概要:随着APISIX作为IT应用系统入口的普及,其故障定位能力的不足导致了在业务故障诊断中,APISIX常常成为首要的“嫌疑对象”。这不仅导致了“兴师动众”式的资源投入,还可能使诊断方向“背道而驰”,从而导致业务故障“长期悬而未决”。本文通过回顾一家全球领先智能终端制造商最近处理核心业务响应延迟故障的过程,展示了“背道而驰”现象对诊断效率的巨大影响,并介绍了DeepFlow可观测性平台如何通过短短几分钟和几个简单的步骤,消除APISIX故障诊断中的“背道而驰”,解决了一个悬而未决长达两个月的问题,极大地提高了故障处理的效率。
01 业务故障的定界困境
作为一款云原生时代极受关注的 API 网关产品,Apache APISIX 被越来越多的用户选择作为 IT 应用系统的入口,在网运行的 APISIX 承载着重要等级各有差异的不同业务,但在运维过程中,普遍存在着故障诊断定位的困难。当业务出现异常需要诊断定位时,运维团队无法快速、清晰地确定故障边界,因而 APISIX 经常成为重点 "怀疑对象",一方面投入大量运维人力消耗在无效的读日志、抓包、追踪等诊断工作中,另一方面诊断方向经常 "南辕北辙",业务故障长期得不到解决。
近期某全球领先的智能终端提供商 就在运维工作中陷入了这样的困境,核心业务系统出现明显的响应时延劣化之后,在长达两个月的定位过程中无法确定故障边界,网关、应用、公有云服务商等多个团队在错误的方向投入大量人力但仍无头绪。
故障诊断陷入困境后,故障诊断团队以零基础在两小时内完成 DeepFlow 企业版的部署,数分钟内点亮业务链路拓扑及多个关键位置的性能指标,迅速排除 APISIX 的故障嫌疑,并将故障锁定到后端应用。
从本文的整个定位过程您可以看到 DeepFlow 可观测性平台在实战中,如何用数分钟时间、几步简单的操作解决数名工程师两个月未能完成的故障诊断工作,为包括 APISIX 在内的云原生应用、网关、基础组件、基础设施提供分钟级的故障定界能力,为云原生业务提供端到端的可靠性运维保障能力。
02 警报响起
该智能终端提供商的 IT 业务系统构建在公有云之上,业务部署跨多个可用区,架构复杂,组件众多,运维保障和故障诊断涉及应用、平台、公有云服务商等企业内及企业间不同团队之间的沟通协作。
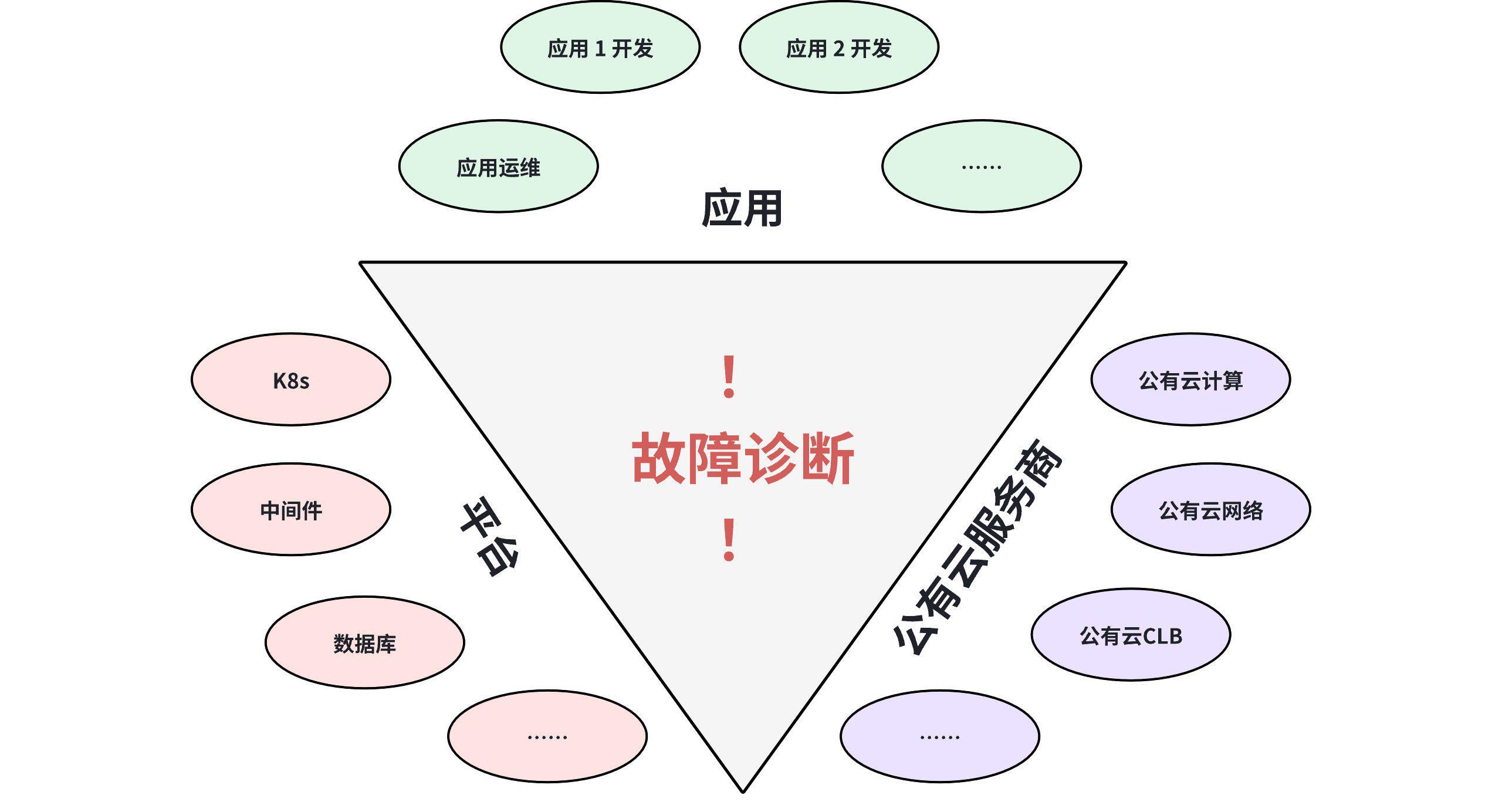
某段时间,该企业 IT 业务系统中的 "手机收入系统" 的应用服务,在高压力情况下一部分业务请求出现明显的响应时延劣化,直接影响 ToC 客户业务服务过程的交易流畅度,线上用户的业务体验受到影响,企业对此高度重视,组织多个技术团队的技术人员组成故障诊断团队,联合专项定位并每日汇报定位进展。
03 持续 2 个月的鏖战
1)谁是问题的根源?
团队对业务路径进行梳理,确定该业务服务的访问过程经过了 Client、APISIX、公有云、K8s、后端应用等诸多内、外部组件。
到底谁是问题的根源呢?------ 现在首要的问题便是故障定界。
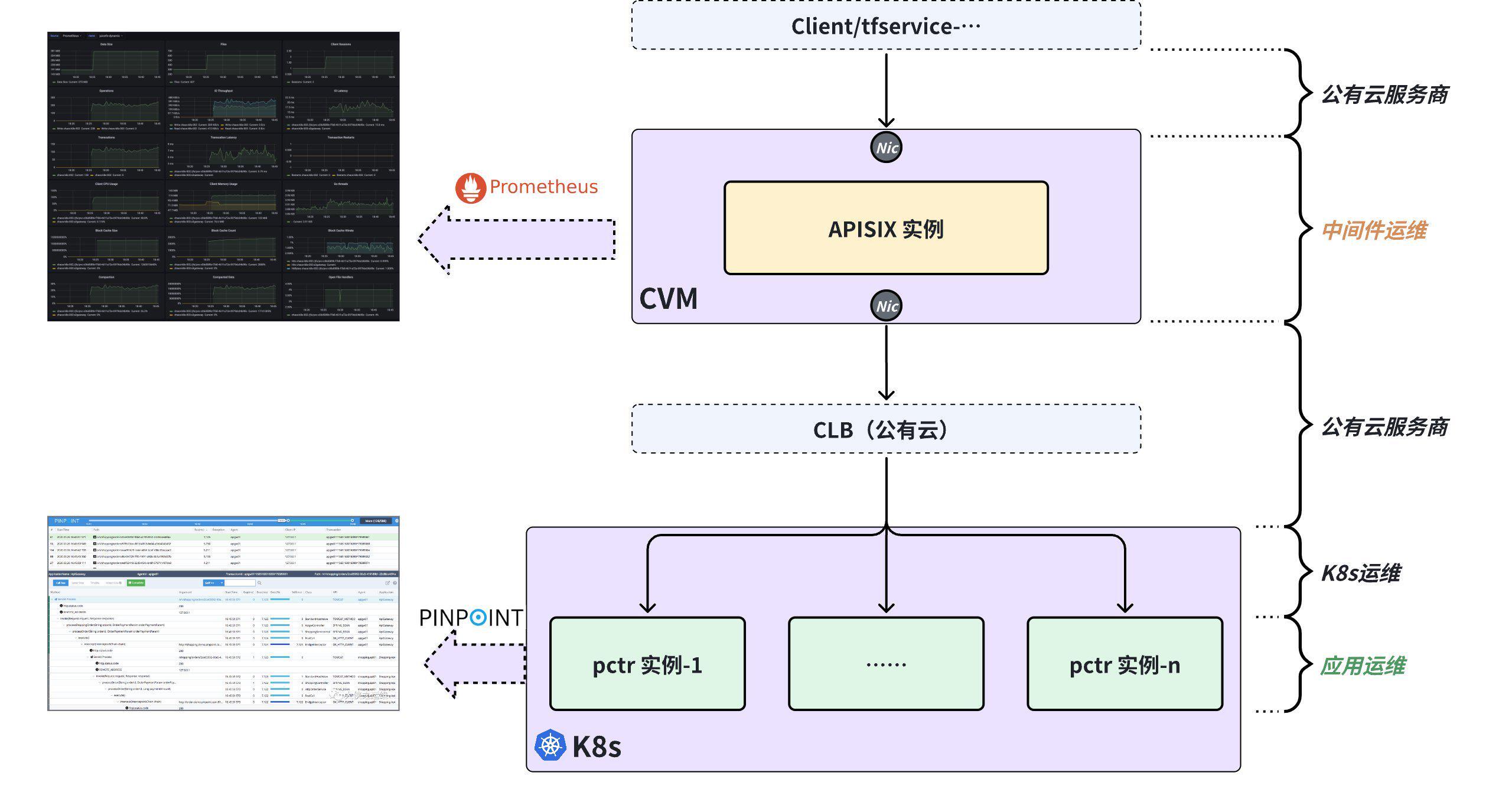
当前可用的运维工具包括 Prometheus 和 Pinpoint,但在对部分业务请求的响应时延劣化的故障进行诊断时,却发现这两种工具组合起来无法回答故障的边界问题:
- Pinpoint 的局限性:Pinpoint 覆盖了后端应用实例(pctr)的内部关键应用函数,但插桩范围之外的代码、K8s 网络、公有云、APISIX 等位置的响应时延均无从了解;
- Prometheus 的局限性:通过 Prometheus 观测的指标是粗粒度的 APISIX 性能指标统计结果,经过 APISIX 的统计计算后已经失去许多关键信息,无法将性能指标细化到 Ingress 方向、Egress 方向,细化到每一个通信对端,细化到每一次业务请求;
- 关联的困难:Prometheus 的粗粒度统计指标与 Pinpoint 的细粒度追踪记录中的时延指标无直接对应关系。
此时,团队无法在 APISIX、后端应用实例、K8s、公有云之间确定故障边界 ,陷入了 " 处处都有可能 " 的困境。
2)插桩 ------ 数据迷雾重重!
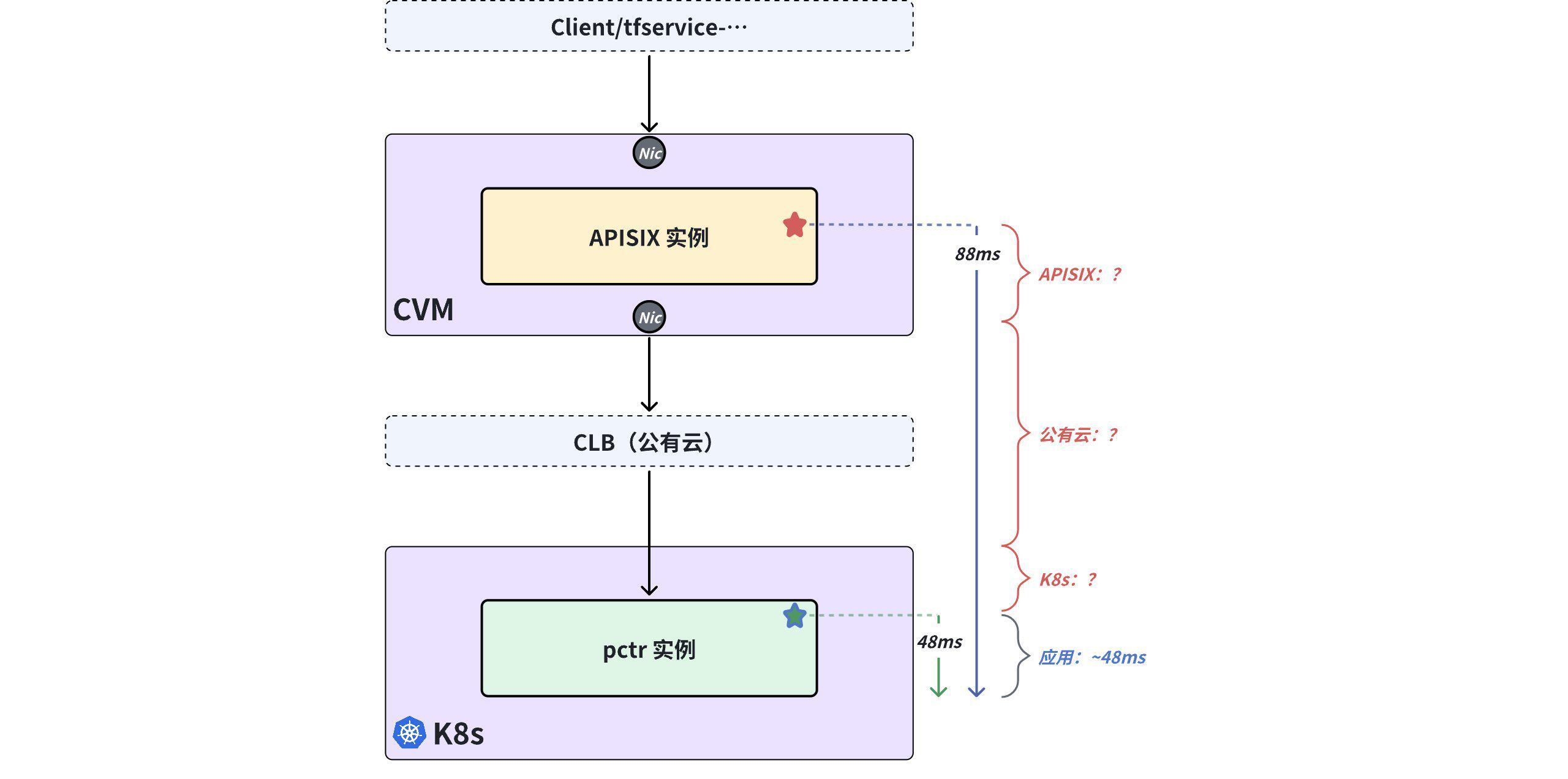
当发现 APISIX 的 Prometheus 指标过粗,无法对此次响应时延劣化的故障进行定界后, 团队迫不得已开始对 APISIX 代码进行追踪插桩的改造并上线新的版本,尝试追踪单条请求在 APISIX、Pinpoint 中的响应时延表现,这时抽样分析(人工分析无法对比每一次请求量,仅能做少量抽样)发现:
- 应用请求在后端应用(pctr) 位置的时延约 48ms(源自 Pinpoint 追踪数据);
- 应用请求在 APISIX 插桩位置的响应时延约 88ms(源自 APISIX 的追踪打印日志)。
问题 "看起来" 出现在 APISIX、公有云和 K8s 之间。
3)抓包 ------ 历尽千辛万苦!
为了彻底弄清楚 APISIX 是否是问题真正的根源,团队开始投入人力在 APISIX 所在的近百个 CVM 上对接口网卡进行人工抓包、读包,比对应用请求在网卡位置的时延表现,但依然面临两个方面的困难:
- 人力投入巨大 :每一轮的抓包均会包含数十万次业务请求,产生数 GB 数据包,需要投入大量的人力进行分析,工程师只能全力以赴以 7*15 小时的工作节奏投入到抓包读包的工作中;
- 容易陷入 "盲人摸象":人工读包只能解读少量业务请求的交互过程,无法分析每一次业务请求的端到端时延,分析样本量有限,得出的结论容易出现 "盲人摸象",结论可信度容易被质疑。
最终经过连续多周的抓包读包分析,团队发现 CVM 网卡位置的应用响应时延约为 50ms,结合 APISIX 追踪打印日志中的 88ms,因而得到一个阶段性结论:APISIX 对应用响应时延贡献了约 38ms,所以 APISIX 是问题的根源(事后分析这是一个 "南辕北辙" 的结论)。
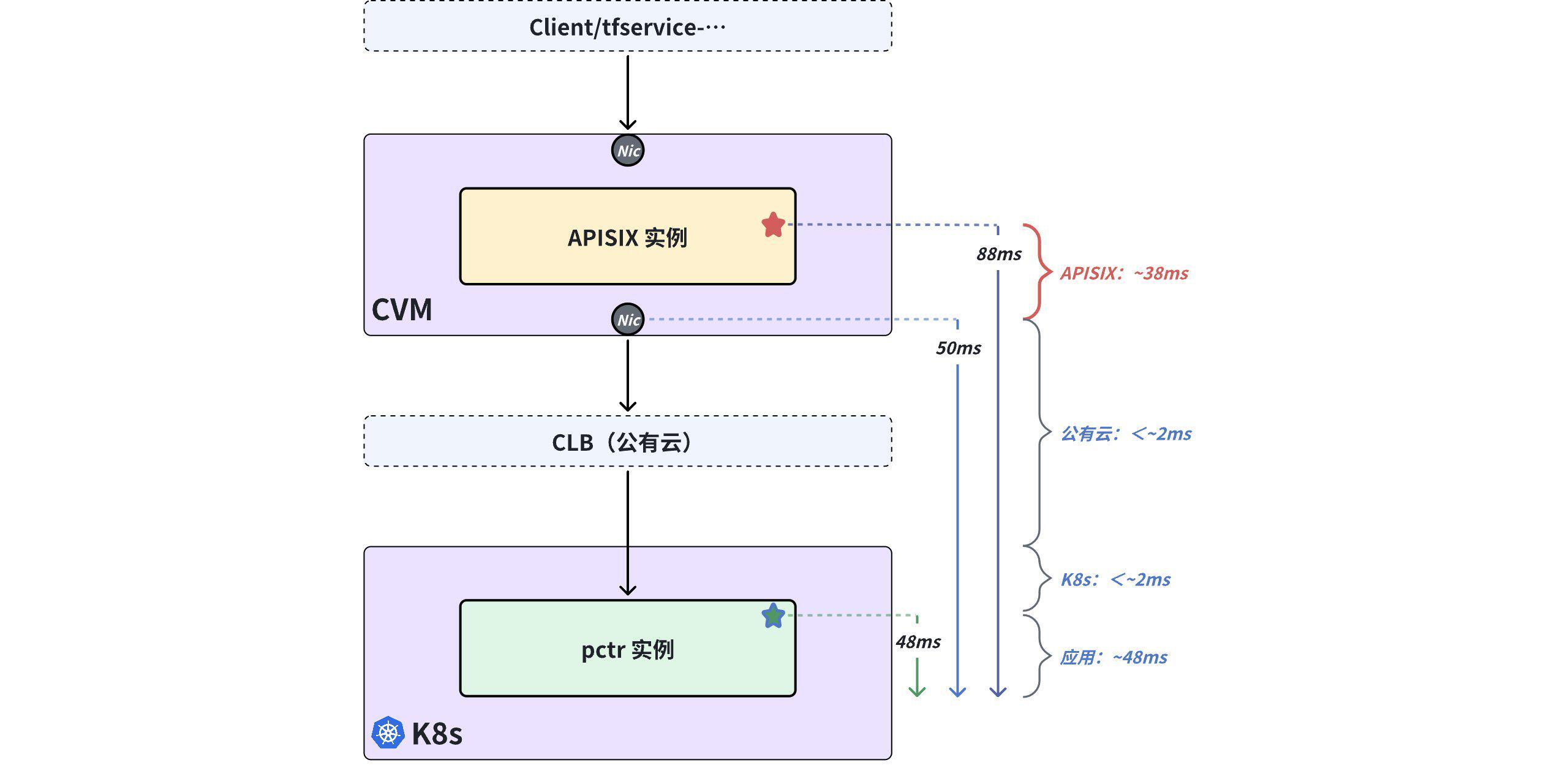
4)怀疑 ------ 插桩数据准确吗?
当抓包数据和插桩数据让我们将所有注意力放到 APISIX 身上后,开发人员开始对 APISIX 的程序代码进行诊断定位,但再次历经连续多天的努力,仍然无法在 APISIX 的代码中找到任何会引入 "38ms "时延的可疑点,而且"38ms" 对于网关产品基本属于天量且难以置信的时延。
团队开始怀疑:APISIX 插桩日志输出的 "88ms" 时延真实、可靠吗?
由于不同开发语言、插桩数量、插桩代码质量均会带来不同程度的「插桩时延 」,而且插桩代码会引入多少「插桩时延」无法得到准确的评估和测量, "88ms" 有多少是由 APISIX 的插桩代码引入,有多少是由 APISIX 自身引入,变成了一个无解的问题。
至此,时间已经过去两个月 ,但 Pinpoint 追踪数据、APISIX 插桩追踪数据、抓包数据让响应时延劣化故障的定界变得更加扑朔迷离,故障诊断定位工作回到原点。
注:「插桩时延」------ 在应用程序中启用追踪插桩后,插桩代码的执行动作会增加服务响应时延,这一部分额外增加的时延可以将其称之为「插桩时延」。
04 使用 DeepFlow 快速排障
团队了解到 DeepFlow 可观测性平台的 Agent 通过 eBPF 技术实现观测数据采集能力,具有应用零侵扰 、随时热加载的特点,无需对 APISIX 网关和后端应用实例进行重启操作即可开启从网关到应用的端到端观测能力,因此开始尝试使用 DeepFlow 进行故障诊断。由于初次使用 eBPF 技术,团队决定先在测试环境部署 DeepFlow 对此次故障复现定位。
1)快速部署 DeepFlow
DeepFlow 支持容器化部署,极大降低了部署难度,工程师以零基础在 2 个小时内即完成了 DeepFlow 企业版的部署工作,并将 DeepFlow Agent 覆盖到 APISIX 网关所在的数十个 CVM 和上百个后端应用实例所在的 K8s 容器集群。
随着 Agent 的运行,DeepFlow 随即开始实时采集每一次应用调用在全链路多个位置(如下图中 1、2、3、4、5、6)的响应时延等指标数据:
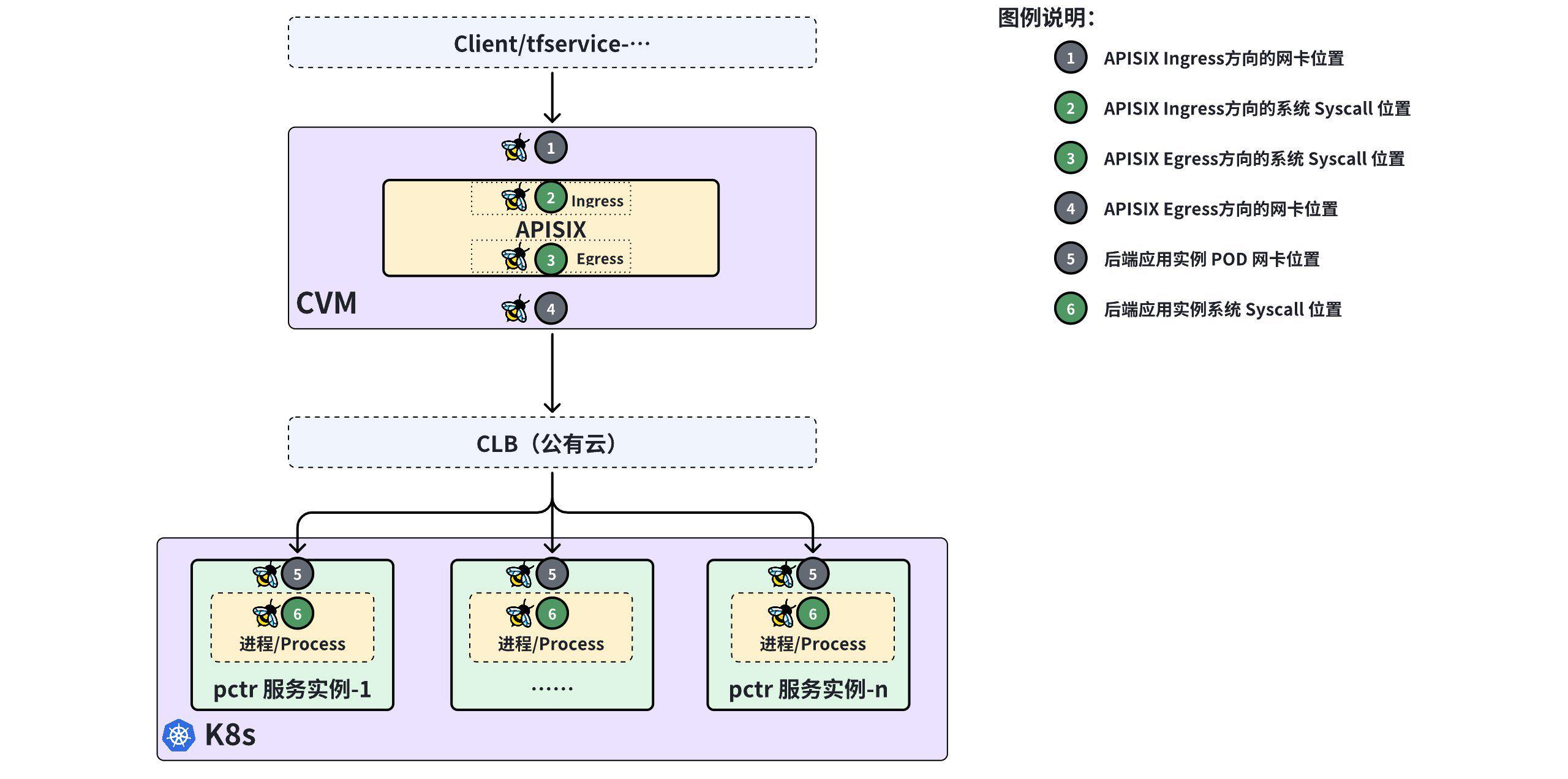
2)应用拓扑,一分钟排除 APISIX 嫌疑
DeepFlow 运行后的数分钟内即可开始进行诊断定位,输入 APISIX 实例的 CVM 名称后,调阅出 APISIX 实例的应用访问拓扑,以及前后端互访的应用性能指标数据:
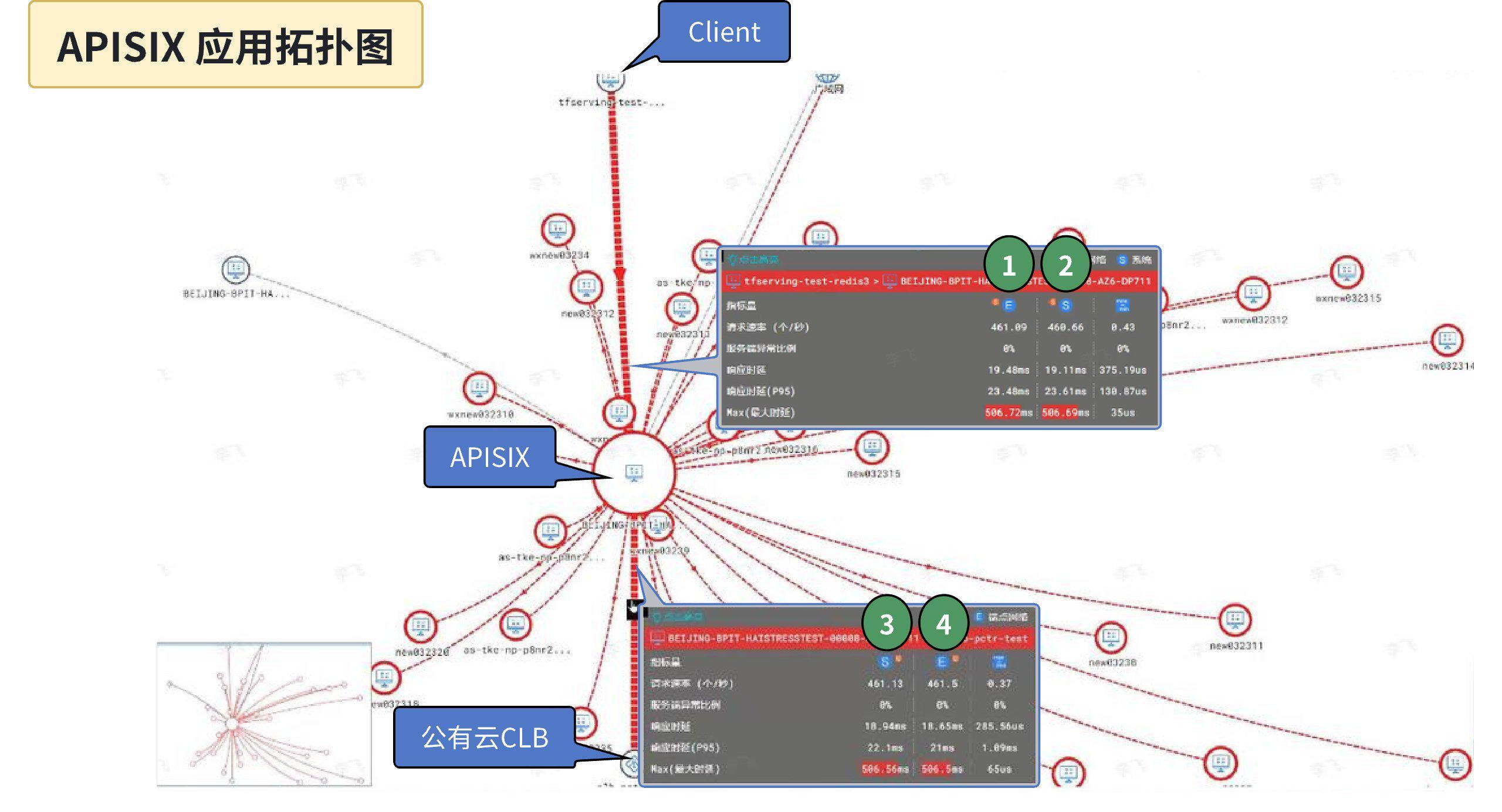
与 Prometheus 指标数据相比,DeepFlow 的应用性能指标数据可以细化区分 Ingress 方向、Egress 方向,细化区分每一个通信对端,细化区分不同采集位置,因此通过 APISIX 应用拓扑图中不同通信对端、不同位置的应用响应「最大时延」指标,我们可以快速发现响应速度最差的应用请求在全链路中不同位置的时延表现:
- (观测点 1 )APISIX Ingress 方向的网卡位置的最大响应时延 ------506.72ms
- (观测点 2 )APISIX Ingress 方向的系统 Syscall 位置的最大响应时延 ------506.69ms
- (观测点 3 )APISIX Egress 方向的系统 Syscall 位置的最大响应时延 ------506.56ms
- (观测点 4 )APISIX Egress 方向的网卡位置的最大响应时延 ------506.5ms

通过以上数据可直观发现如下信息:
- APISIX (含 CVM)对最大响应时延的贡献仅为 [506.72ms - 506.5ms] =0.22ms
- 后端(含公有云、K8s、后端应用实例)贡献了 506.5ms
至此,我们便在打开 APISIX 拓扑后的 1 分钟内明确排除 APISIX 的故障嫌疑,并将故障源锁定到 APISIX 的后方(包括公有云、K8s、后端应用)。
注:测试环境复现的响应时延与生产环境的实时业务响应时延会有一定差异,但不影响 DeepFlow 故障诊断的分析过程和定界方法。
3)调用链追踪,一分钟锁定后端应用
如何在公有云、K8s、后端应用之间找到故障的根源呢?我们在 DeepFlow 中选择一部分响应时延最大的应用调用进行调用链追踪,发现有两类不同的时延现象。
现象 1------ 后端应用实例「网络 Span」与「系统 Span」差值明显
从第一种时延严重劣化的应用调用链追踪火焰图中(见下图),我们可以看到 pctr 的「网络 Span」时延为 477.48ms,pctr 的「系统 Span」时延为 121.48ms,两者中间出现了约 356ms 的差值,这说明:
- pctr 应用实例的 IO 线程调度处于繁忙状态,网卡收到请求之后延迟约 356ms 方才触发 IO 线程的 Syscall 进行数据读取,导致响应时延劣化。
- pctr 应用实例收到请求后,内部代码处理及其他后端调用消耗 121.48ms 方才回复应用响应。
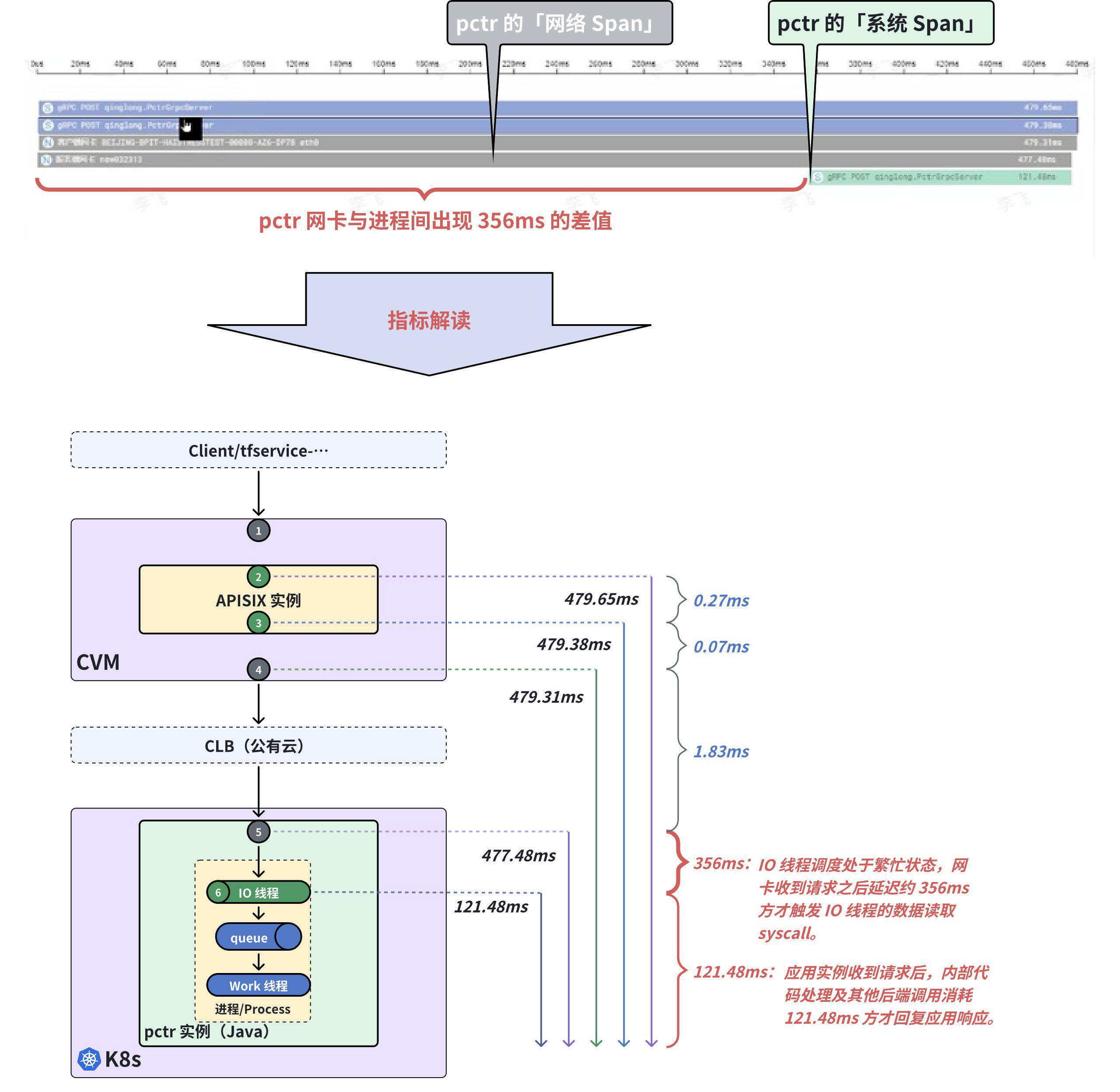
注:「网络 Span」------ 即 DeepFlow Agent 采集的网卡位置的数据,Span 长度表示某次请求在该网络接口的响应时延; 「系统 Span」------ 即 DeepFlow Agent 采集的应用进程系统调用位置的数据,Span 长度表示某次请求在应用进程出入口位置的响应时延。
现象 2------ 后端应用实例「系统 Span」时延大
从第二种时延严重劣化的应用调用链追踪火焰图中(见下图),我们可以看到 pctr 的「系统 Span」时延达到 451.55ms,这说明:pctr 应用实例收到请求后,内部代码处理及其他后端调用消耗 451.55ms 方才回复应用响应,可以判断 Work 线程处于繁忙状态。

通过以上两种调用链追踪的结果,我们便可以排除公有云、K8s 的故障嫌疑,明确后端应用是此次响应时延劣化故障的问题根源,APISIX 运维和开发、K8s 运维、公有云服务商便可以从故障诊断团队中释放,由应用开发团队独立定位应用代码的根因。
05 复盘
复盘此次响应时延劣化的定位过程,我们发现快速、准确定界能力的缺失是云原生 IT 系统可靠性保障的最大障碍。
定界能力缺失往往导致 "盲人摸象"、"南辕北辙" 情况的产生,导致故障诊断团队的资源和时间消耗在无效的工作中,导致故障经常在不同团队之间流转、循环、甩锅,导致故障定位率低、定位周期长。而定界能力缺失的主要原因包括:
- APM 追踪的盲区:应用的 APM 追踪能力能够观测应用内部的关键位置,但应用外部仍存在大量盲区;
- Prometheus 指标的粗糙:多数故障的诊断定位需要精细到单次应用调用,而 Prometheus 的粗粒度统计指标数据对此类应用响应时延劣化的追踪诊断无法发挥作用;
- 「插桩时延」的干扰:为诊断故障而临时在 APISIX 中进行追踪插桩,但同时引入的「插桩时延」反而影响诊断结论的准确性,甚至误导故障定位方向;
- 人工分析的 "盲人摸象":人工无法完成海量数据的采集、解析、分析工作,因此人工抓包、读包、读日志、关联比对等操作只能对少量样本抽样分析,分析结论只能 "盲人摸象",很难得出全面、准确的结论。
而对比发现,DeepFlow 的零侵扰调用链追踪能力则全面解决了上述关键难题,从而能够在故障诊断过程中通过客观数据快速确定故障边界:
- 无盲区追踪 :DeepFlow 通过 eBPF 技术实现的零侵扰调用链追踪,将任意一次应用调用的追踪能力覆盖到应用、转发网卡、APISIX,还包括其他各类中间件、负载均衡、消息队列、数据库、DNS 等基础服务,因而可以在各个组件间快速定界;
- 细粒度指标 :DeepFlow 采集分析的应用调用指标可以细化到 Ingress 方向、Egress 方向,细化到每一个通信对端,细化到不同采集位置,快速比对不同位置、不同通信对、出 / 入向的指标数据,因而可以在不同采集位置间快速定界;
- 客观数据 :DeepFlow 通过 eBPF 技术实现了在 Linux 内核中观测数据的旁路采集能力,采集过程不影响应用程序的处理过程,做到对应用响应时延的零影响,因而可以获取各个位置的客观数据,得出更准确、更客观的诊断结论;
- 业务全貌 :DeepFlow 实时采集全链路数据并自动关联分析,因而可以在无需投入大量人工的情况下快速观测业务全貌,得出全面、准确结论。
正是由于以上技术的加持,DeepFlow 能够帮助运维工程师在数分钟内明确故障是否与 APISIX 有关,用几步检索操作替代数名工程师两个月的繁琐抓包读包,并且在故障诊断过程中用精细的数据得出准确的结论。
06 什么是 DeepFlow
DeepFlow 是云杉网络开发的一款可观测性产品,旨在为复杂的云原生 及 AI 应用提供深度可观测性。DeepFlow 基于 eBPF 实现了应用性能指标、分布式追踪、持续性能剖析等观测信号的零侵扰 (Zero Code)采集,并结合智能标签 (SmartEncoding)技术实现了所有观测信号的全栈 (Full Stack)关联和高效存取。使用 DeepFlow,可以让云原生及 AI 应用自动具有深度可观测性,从而消除开发者不断插桩的沉重负担,并为 DevOps/SRE 团队提供从代码到基础设施的监控及诊断能力。
相关文章:
利用DeepFlow解决APISIX故障诊断中的方向偏差问题
概要:随着APISIX作为IT应用系统入口的普及,其故障定位能力的不足导致了在业务故障诊断中,APISIX常常成为首要的“嫌疑对象”。这不仅导致了“兴师动众”式的资源投入,还可能使诊断方向“背道而驰”,从而导致业务故障“…...

sqlalchemy获取数据条数
1、sqlalchemy获取数据条数 在SQLAlchemy中,你可以使用count()函数来获取数据表中的记录条数。 from sqlalchemy import create_engine, MetaData, Table# 数据库连接字符串 DATABASE_URI = dialect+driver://username:password@host:port/database# 创建引擎 engine = crea…...
SpringBoot的自动配置核心原理及拓展点
Spring Boot 的核心原理几个关键点 约定优于配置: Spring Boot 遵循约定优于配置的理念,通过预定义的约定,大大简化了 Spring 应用程序的配置和部署。例如,它自动配置了许多常见的开发任务(如数据库连接、Web 服务器配…...

用随机森林算法进行的一次故障预测
本案例将带大家使用一份开源的S.M.A.R.T.数据集和机器学习中的随机森林算法,来训练一个硬盘故障预测模型,并测试效果。 实验目标 掌握使用机器学习方法训练模型的基本流程;掌握使用pandas做数据分析的基本方法;掌握使用scikit-l…...
24位DAC转换的FPGA设计及将其封装成自定义IP核的方法
在vivado设计中,为了方便的使用Block Desgin进行设计,可以使用vivado软件把自己编写的代码封装成IP核,封装后的IP核和原来的代码具有相同的功能。本文以实现24位DA转换(含并串转换,使用的数模转换器为CL4660)为例,介绍VIVADO封装IP核的方法及调用方法,以及DAC转换的详细…...
【大模型LLM面试合集】大语言模型基础_llm概念
1.llm概念 1.目前 主流的开源模型体系 有哪些? 目前主流的开源LLM(语言模型)模型体系包括以下几个: GPT(Generative Pre-trained Transformer)系列:由OpenAI发布的一系列基于Transformer架构…...

Qt时间日期处理与定时器使用总结
一、日期时间数据 1.QTime 用于存储和操作时间数据的类,其中包括小时(h)、分钟(m)、秒(s)、毫秒(ms)。函数定义如下: //注:秒(s)和毫秒(ms)有默认值0 QTime::QTime(int h, int m, int s 0, int ms 0) 若无须初始化时间数据,可…...

数据结构——Hash Map
1. Hash Map简介 Hash Map是一种基于键值对的数据结构,通过散列函数将键映射到存储位置,实现快速的数据查找和存储。它可以在常数时间内完成查找、插入和删除操作,因此在需要频繁进行这些操作时非常高效。 2. Hash Map的定义 散列表ÿ…...

剪画小程序:视频剪辑-视频播放倍数的调整与应用
在这个快节奏的时代,时间变得越来越宝贵,而视频倍数播放功能就像是我们的时间管理小助手,为我们的视频观看带来了极大的便利。你是否好奇它到底能在哪些地方发挥作用呢?让我们一起来看看! 只要使用小程序【剪画】的里…...
使用 Java Swing 和 XChart 创建多种图表
在现代应用程序开发中,数据可视化是一个关键部分。本文将介绍如何使用 Java Swing 和 XChart 库创建各种类型的图表。XChart 是一个轻量级的图表库,支持多种类型的图表,非常适合在 Java 应用中进行快速的图表绘制。 1、环境配置 在开始之前&…...

信息系统运维管理:实践与发展
信息系统运维管理:实践与发展 信息系统运维管理在现代企业中扮演着至关重要的角色,确保信息系统的高效、安全和稳定运行。本文结合《信息系统运维管理》文档内容,探讨了服务设计阶段、服务转换阶段、委托系统维护管理三个主要章节࿰…...
html+js+css登录注册界面
拥有向服务器发送登录或注册数据并接收返回数据的功能 点赞关注 界面 源代码 <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <title>Login and Registration Form</title> <style> * …...
数据中心GPU介绍)
英伟达(NVIDIA)数据中心GPU介绍
英伟达(NVIDIA)数据中心GPU按性能由高到低排行: 1. NVIDIA H100 架构:Hopper 核心数量:18352 CUDA Cores, 1456 Tensor Cores 显存:80 GB HBM3 峰值性能: 单精度(FP32)…...

Leetcode 3202. Find the Maximum Length of Valid Subsequence II
Leetcode 3202. Find the Maximum Length of Valid Subsequence II 1. 解题思路2. 代码实现 题目链接:3202. Find the Maximum Length of Valid Subsequence II 1. 解题思路 这一题的话是上一题3201. Find the Maximum Length of Valid Subsequence I的升级版&am…...

通过Spring Boot结合实时流媒体技术对考试过程进行实时监控
本章将深入探讨考试系统中常见的复杂技术问题,并提供基于Spring Boot 3.x的解决方案。涵盖屏幕切换检测与防护、接打电话识别处理、行为监控摄像头使用、网络不稳定应对等,每篇文章详细剖析问题并提供实际案例与代码示例,帮助开发者应对挑战&…...

智能扫地机器人避障与防跌落问题解决方案
智能扫地机器人出现避障与防跌落问题时,可以通过以下几种方式来解决: 一、避障问题的解决方案 1.升级避障技术: ① 激光雷达避障:激光雷达通过发射和接收激光信号来判断与障碍物的距离,具有延迟低、效果稳定、准确度…...

德旺训练营称重问题
这是考小学的分治策略,小学的分治策略几乎都是分三组。本着这个策略,我们做看看。 第一次称重: 分三组,16,16,17,拿两个16称,得到A情况,一样重,那么假铜钱在那组17个里面。B情况不…...

数据决策系统详解
文章目录 数据决策系统的核心组成部分:1. **数据收集与整合**:2. **数据处理与分析**:3. **数据可视化**:4. **决策支持**: 数据决策系统的功能:决策类型:数据决策系统对企业的重要性࿱…...

JSON 简述与应用
1. JSON 简述 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于客户端与服务器之间的数据传递。它基于JavaScript对象表示法,但独立于语言,可以被多种编程语言解析和生成。 1.1 特点 轻量级&#…...

ResNet50V2
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、ResNetV1和ResNetV2的区别 ResNetV2 和 ResNetV1 都是深度残差网络(ResNet)的变体,它们的主要区别在于残差块的设计和…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

如何在macOS上免费解锁QQ音乐加密文件:完整指南
如何在macOS上免费解锁QQ音乐加密文件:完整指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结果…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

【DeepSeek漏洞扫描辅助实战指南】:20年安全专家亲授3大避坑法则与5步提效流程
更多请点击: https://intelliparadigm.com 第一章:DeepSeek漏洞扫描辅助的核心价值与适用边界 DeepSeek漏洞扫描辅助并非通用型渗透测试引擎,而是一个聚焦于大语言模型(LLM)应用层安全的轻量级分析工具。其核心价值在…...

【2026实测】怎么提高论文原创度?盘点8款主流降AI工具,附结构级优化指南
写文章最怕碰到什么,是辛辛苦苦自己码出来的字,却被标了极高的AI值。目前很多文本审核机制对内容的原创度要求极高,纯手写的初稿也可能因为句式太工整被判定为机器生成的。 为了帮几个快被这事折腾疯了的学弟学妹找条出路,我花了…...
)
别再纠结了!给激光焊接新手讲透单模和多模激光到底怎么选(附M²因子解读)
激光焊接设备选型指南:单模与多模激光的实战抉择 当你第一次站在激光焊接设备采购的十字路口,面对"单模"和"多模"这两个专业术语时,那种迷茫感我深有体会。五年前,我作为产线技术负责人,需要为汽车…...

基于STM32WL与LoRaWAN的远程空气质量监测系统全栈开发实践
1. 项目概述:构建一个远程空气质量监测系统最近在做一个挺有意思的玩意儿:一个能自己找地方待着、靠太阳能供电,然后把周围空气数据悄无声息传回来的远程监测终端。核心想法很简单,就是想知道某个犄角旮旯,比如工厂周边…...