03.C1W2.Sentiment Analysis with Naïve Bayes
目录
- Probability and Bayes’ Rule
- Introduction
- Probabilities
- Probability of the intersection
- Bayes’ Rule
- Conditional Probabilities
- Bayes’ Rule
- Quiz: Bayes’ Rule Applied
- Naïve Bayes Introduction
- Naïve Bayes for Sentiment Analysis
- P ( w i ∣ c l a s s ) P(w_i|class) P(wi∣class)
- Naïve Bayes
- Laplacian Smoothing
- Laplacian Smoothing
- Introducing P ( w i ∣ c l a s s ) P(w_i|class) P(wi∣class) with smoothing
- Log Likelihood
- Ratio of probabilities
- Naïve Bayes’ inference
- Log Likelihood, Part1
- Calculating Lambda
- Summary
- Log Likelihood, Part 2
- Training Naïve Bayes
- Testing Naïve Bayes
- Predict using Naïve Bayes
- Testing Naïve Bayes
- Applications of Naïve Bayes
- Naïve Bayes Assumptions
- Error Analysis
- Punctuation
- Removing Words
- Adversarial attacks
Probability and Bayes’ Rule
概率与条件概率及其数学表达
贝叶斯规则(应用于不同领域,包括 NLP)
建立自己的 Naive-Bayes 推文分类器
Introduction
假设我们有一个推文语料库,里面包含正面和负面情感的推文:
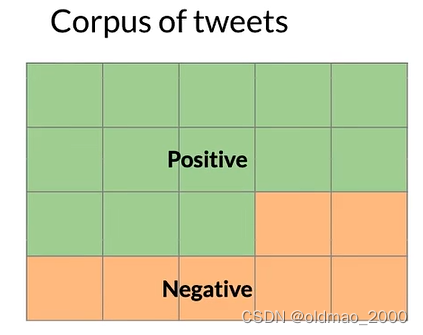
某个单词例如:happy,可能出现在正面或负面情感的推文中:

下面我们用数学公式来表示上面的概率描述。
Probabilities
A A A表示正面的推文,则正面的推文发生的概率可以表示为:
P ( A ) = P ( P o s i t i v e ) = N p o s / N P(A)=P(Positive)=N_{pos}/N P(A)=P(Positive)=Npos/N
以上图为例:
P ( A ) = N p o s / N = 13 / 20 = 0.65 P(A)=N_{pos}/N=13/20=0.65 P(A)=Npos/N=13/20=0.65
而负面推文发生的概率可以表示为:
P ( N e g a t i v e ) = 1 − P ( P o s i t i v e ) = 0..35 P(Negative)=1-P(Positive)=0..35 P(Negative)=1−P(Positive)=0..35
happy可能出现在正面或负面情感的推文中可以表示为 B B B:
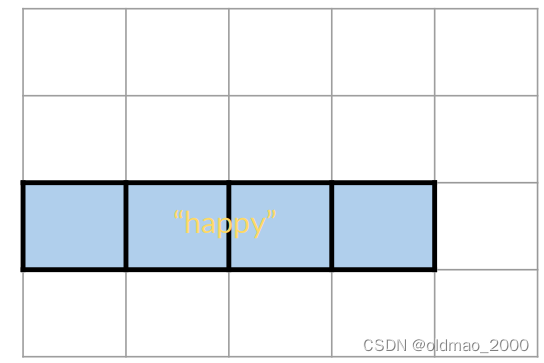
则 B B B发生概率可以表示为:
P ( B ) = P ( h a p p y ) = N h a p p y / N P ( B ) = 4 / 20 = 0.2 P(B) = P(happy) = N_{happy}/N\\ P(B) =4/20=0.2 P(B)=P(happy)=Nhappy/NP(B)=4/20=0.2
Probability of the intersection
下面表示正面推文且包含单词happy可图形化表示为:
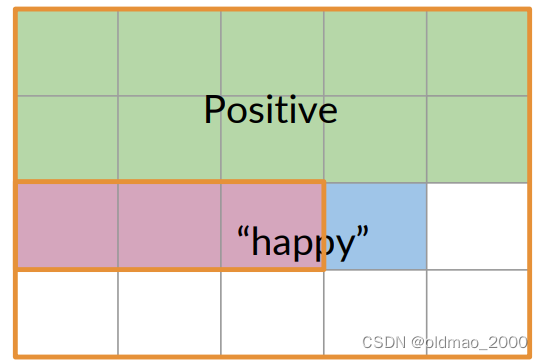
也可以用交集的形式表示:
P ( A ∩ B ) = P ( A , B ) = 3 20 = 0.15 P(A\cap B)=P(A,B)=\cfrac{3}{20}=0.15 P(A∩B)=P(A,B)=203=0.15
语料库中有20条推文,其中有3条被标记为积极且同时包含单词happy
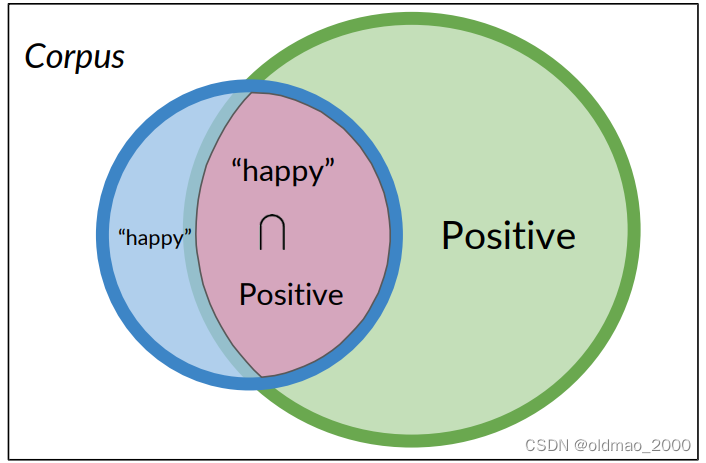
Bayes’ Rule
Conditional Probabilities
如果我们在三亚,并且现在是冬天,你可以猜测天气如何,那么你的猜测比只直接猜测天气要准确得多。
用推文的例子来说:
如果只考虑包含单词happy的推文(4条),而不是整个语料库,考虑这个里面包含正面推文的概率:
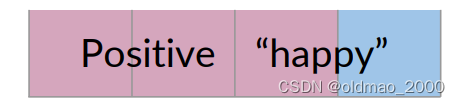
P ( A ∣ B ) = P ( P o s i t i v e ∣ “ h a p p y " ) P ( A ∣ B ) = 3 / 4 = 0.75 P(A|B)=P(Positive|“happy")\\ P(A|B)=3/4=0.75 P(A∣B)=P(Positive∣“happy")P(A∣B)=3/4=0.75
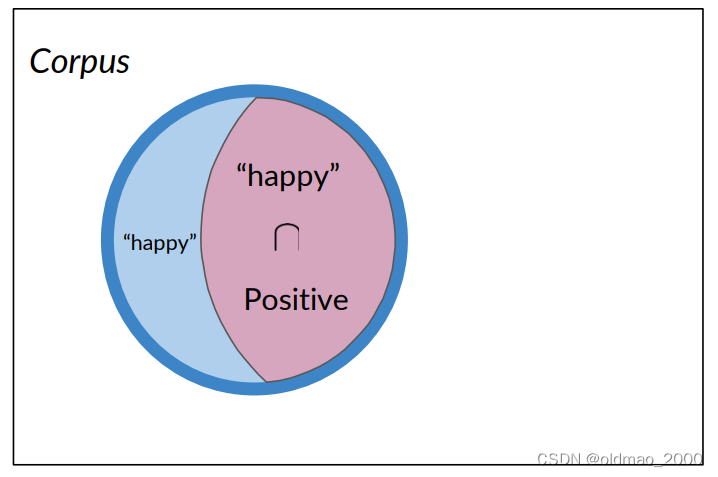
反过来说,只考虑正面推文,看其出现happy单词的推文概率:
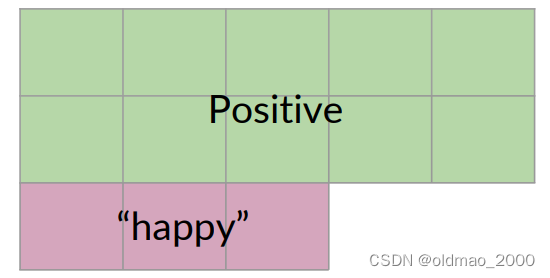
P ( B ∣ A ) = P ( “ h a p p y ” ∣ P o s i t i v e ) P ( B ∣ A ) = 3 / 13 = 0.231 P(B | A) = P(“happy”| Positive) \\ P(B | A) = 3 / 13 = 0.231 P(B∣A)=P(“happy”∣Positive)P(B∣A)=3/13=0.231
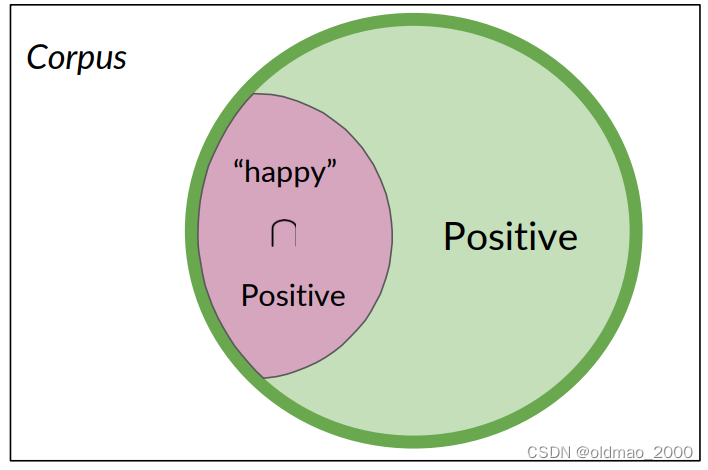
从上面例子可以看到:条件概率可以被解释为已知事件A已经发生的情况下,结果B发生的概率,或者从集合A中查看一个元素,它同时属于集合B的概率。
Probability of B, given A happened
Looking at the elements of set A, the chance that one also belongs to set B
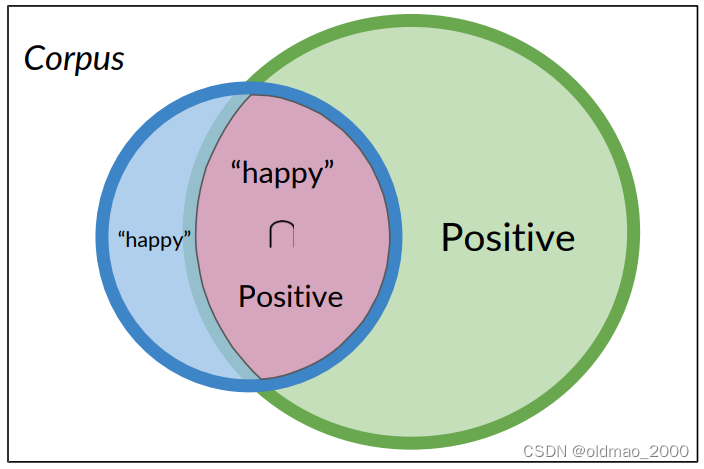
P ( P o s i t i v e ∣ “ h a p p y " ) = P ( P o s i t i v e ∩ “ h a p p y " ) P ( “ h a p p y " ) P(Positive|“happy")=\cfrac{P(Positive\cap “happy")}{P(“happy")} P(Positive∣“happy")=P(“happy")P(Positive∩“happy")
Bayes’ Rule
使用条件概率推导贝叶斯定理
同理:
P ( P o s i t i v e ∣ “ h a p p y " ) = P ( P o s i t i v e ∩ “ h a p p y " ) P ( “ h a p p y " ) P(Positive|“happy")=\cfrac{P(Positive\cap “happy")}{P(“happy")} P(Positive∣“happy")=P(“happy")P(Positive∩“happy")
P ( “ h a p p y " ∣ P o s i t i v e ) = P ( “ h a p p y " ∩ P o s i t i v e ) P ( P o s i t i v e ) P(“happy"|Positive)=\cfrac{P( “happy"\cap Positive)}{P(Positive)} P(“happy"∣Positive)=P(Positive)P(“happy"∩Positive)
上面两个式子的分子表示的数量是一样的。
有了以上公式则可以推导贝叶斯定理。
P ( P o s i t i v e ∣ “ h a p p y " ) = P ( “ h a p p y " ∣ P o s i t i v e ) × P ( P o s i t i v e ) P ( “ h a p p y " ) P(Positive|“happy")=P(“happy"|Positive)\times\cfrac{P(Positive)}{P(“happy")} P(Positive∣“happy")=P(“happy"∣Positive)×P(“happy")P(Positive)
通用形式为:
P ( X ∣ Y ) = P ( Y ∣ X ) × P ( X ) P ( Y ) P(X|Y)=P(Y|X)\times \cfrac{P(X)}{P(Y)} P(X∣Y)=P(Y∣X)×P(Y)P(X)
Quiz: Bayes’ Rule Applied
Suppose that in your dataset, 25% of the positive tweets contain the word ‘happy’. You also know that a total of 13% of the tweets in your dataset contain the word ‘happy’, and that 40% of the total number of tweets are positive. You observe the tweet: '‘happy to learn NLP’. What is the probability that this tweet is positive?
A: P(Positive | “happy” ) = 0.77
B: P(Positive | “happy” ) = 0.08
C: P(Positive | “happy” ) = 0.10
D: P(Positive | “happy” ) = 1.92
答案:A
Naïve Bayes Introduction
学会使用Naïve Bayes来进行二分类(使用概率表)
Naïve Bayes for Sentiment Analysis
假设有以下语料:
按C1W1中提到方法提取词库,并统计正负面词频:

P ( w i ∣ c l a s s ) P(w_i|class) P(wi∣class)
将类别中每个单词的频率除以它对应的类别中单词的总数。
例如:对于单词"I",正面类别的条件概率将是3/13:
p ( I ∣ P o s ) = 3 13 = 0.24 p(I|Pos)=\cfrac{3}{13}=0.24 p(I∣Pos)=133=0.24
对于负面类别中的单词"I",可以得到3/12:
p ( I ∣ N e g ) = 3 12 = 0.25 p(I|Neg)=\cfrac{3}{12}=0.25 p(I∣Neg)=123=0.25
将以上内容保存为表(because的Neg概率不太对,应该是0):
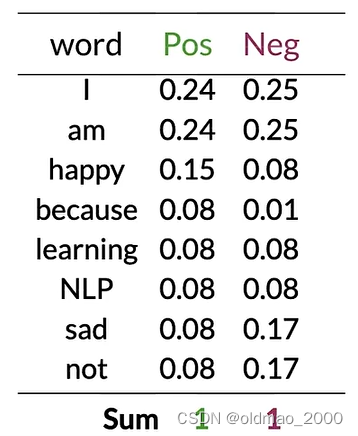
可以看到有很多单词(中性词)在表中的Pos和Neg的值大约相等(Pos≈Neg),例如:I、am、learning、NLP。
这些具有相等概率的单词对情感没有任何贡献。
而单词happy、sad、not的Pos和Neg的值差异很大,这些词对于确定推文的情感具有很大影响,绿色是积极影响,紫色是负面影响。
对于单词because,其 p ( I ∣ N e g ) = 0 12 = 0 p(I|Neg)=\cfrac{0}{12}=0 p(I∣Neg)=120=0
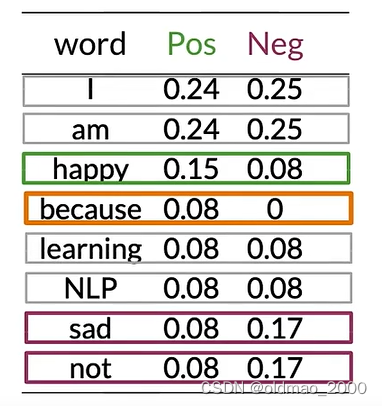
这情况在计算贝叶斯概率的时候会出现分母为0的情况,为避免这个情况发生,可以引入平滑处理。
Naïve Bayes
假如有以下推文:
I am happy today; I am learning.
按上面的计算方式得到词表以及其Pos和Neg的概率值:
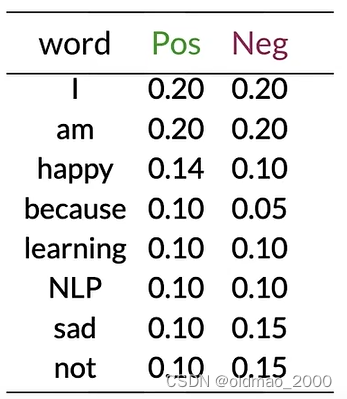
使用以下公式计算示例推文的情感:
∏ i = 1 m P ( w i ∣ p o s ) P ( w i ∣ n e g ) \prod_{i=1}^m\cfrac{P(w_i|pos)}{P(w_i|neg)} i=1∏mP(wi∣neg)P(wi∣pos)
就是计算推文每个单词的第二列比上第三列,然后连乘。
示例推文today不在词表中,忽略,其他单词带入公式:
0.20 0.20 × 0.20 0.20 × 0.14 0.10 × 0.20 0.20 × 0.20 0.20 × 0.10 0.10 = 0.14 0.10 = 1.4 > 1 \cfrac{0.20}{0.20}\times\cfrac{0.20}{0.20}\times\cfrac{0.14}{0.10}\times\cfrac{0.20}{0.20}\times\cfrac{0.20}{0.20}\times\cfrac{0.10}{0.10}=\cfrac{0.14}{0.10}=1.4>1 0.200.20×0.200.20×0.100.14×0.200.20×0.200.20×0.100.10=0.100.14=1.4>1
可以看到,中性词对预测结果没有任何作用,最后结果大于1,表示示例推文是正面的。
Laplacian Smoothing
Laplacian Smoothing主要用于以下目的:
避免零概率问题:在统计语言模型中,某些词或词序列可能从未在训练数据中出现过,导致其概率为零。拉普拉斯平滑通过为所有可能的事件分配一个非零概率来解决这个问题。
概率分布估计:拉普拉斯平滑提供了一种简单有效的方法来估计概率分布,即使在数据不完整或有限的情况下。
平滑处理:它通过为所有可能的事件添加一个小的常数(通常是1),来平滑概率分布,从而减少极端概率值的影响。
提高模型的泛化能力:通过避免概率为零的情况,拉普拉斯平滑有助于提高模型对未见数据的泛化能力。
简化计算:拉普拉斯平滑提供了一种简单的方式来调整概率,使得计算和实现相对容易。
Laplacian Smoothing
计算给定类别下一个词的条件概率的表达式是词在语料库中出现的频率:
P ( w i ∣ c l a s s ) = f r e q ( w i , c l a s s ) N c l a s s c l a s s ∈ { P o s i t i v e , N e g a t i v e } P(w_i|class)=\cfrac{freq(w_i,class)}{N_{class}}\quad class\in\{Positive,Negative\} P(wi∣class)=Nclassfreq(wi,class)class∈{Positive,Negative}
其中 N c l a s s N_{class} Nclass是frequency of all words in class
加入平滑项后公式写为:
P ( w i ∣ c l a s s ) = f r e q ( w i , c l a s s ) + 1 N c l a s s + V c l a s s P(w_i|class)=\cfrac{freq(w_i,class)+1}{N_{class}+V_{class}} P(wi∣class)=Nclass+Vclassfreq(wi,class)+1
V c l a s s V_{class} Vclass是number of unique words in class
分子项+1避免了概率为0的情况,但是会导致总概率不等于1的情况,为了避免这个情况,在分母中加了 V c l a s s V_{class} Vclass
Introducing P ( w i ∣ c l a s s ) P(w_i|class) P(wi∣class) with smoothing
使用之前的例子。

上表中共有8个不同单词, V = 8 V=8 V=8
对于单词I则有:
P ( I ∣ P o s ) = 3 + 1 13 + 8 = 0.19 P ( I ∣ N e g ) = 3 + 1 12 + 8 = 0.20 P(I|Pos)=\cfrac{3+1}{13+8}=0.19\\ P(I|Neg)=\cfrac{3+1}{12+8}=0.20 P(I∣Pos)=13+83+1=0.19P(I∣Neg)=12+83+1=0.20
同理可以计算出其他单词平滑厚度结果:
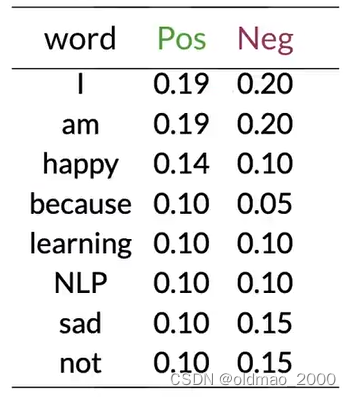
虽然结果已经四舍五入,但是两列概率值总和还是为1
Log Likelihood
Ratio of probabilities
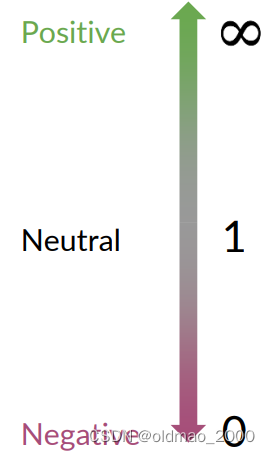
根据之前讲的内容,我们知道每个单词可以按其Pos和Neg的值的差异分为三类,正面、负面和中性词。
我们把这个差异用下面公式表示:
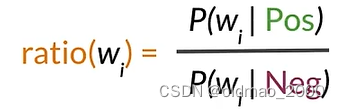
然后,我们可以计算上面概率表中的ratio(吐槽一下,这里because的概率不知道怎么搞的老是变来变去)
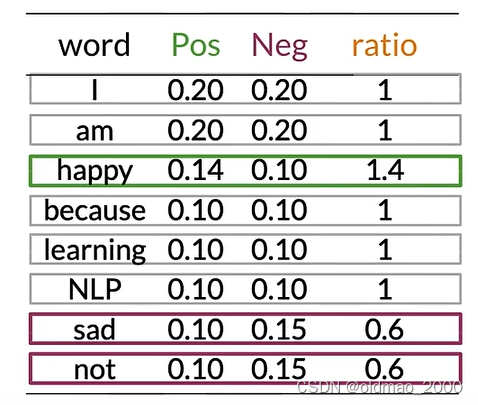
ratio取值与分类的关系很简单:
Naïve Bayes’ inference
下面给出完整的朴素贝叶斯二元分类公式:
P ( p o s ) P ( n e g ) ∏ i = 1 m P ( w i ∣ p o s ) P ( w i ∣ n e g ) > 1 c l a s s ∈ { p o s , n e g } w → Set of m words in a tweet \cfrac{P(pos)}{P(neg)}\prod_{i=1}^m\cfrac{P(w_i|pos)}{P(w_i|neg)}>1\quad class\in\{pos,neg\}\quad w\rightarrow\text{Set of m words in a tweet} P(neg)P(pos)i=1∏mP(wi∣neg)P(wi∣pos)>1class∈{pos,neg}w→Set of m words in a tweet
左边一项其实是先验概率,如果数据集中正负样本差不多,则该项比值为1,可以忽略。这个比率可以看作是模型在没有任何其他信息的情况下,倾向于认为推文是正面或负面情感的初始信念。;
右边一项之前已经推导过。这是条件概率的乘积。对于推文中的每个词 w i , i = 1 , 2 , ⋯ , m w_i,i=1,2,\cdots,m wi,i=1,2,⋯,m(m 是推文中的词的数量),这个乘积计算了在正面情感条件下该词出现的概率与在负面情感条件下该词出现的概率的比值。这个乘积考虑了推文中所有词的证据
如果这个乘积大于1,那么模型认为推文更可能是正面情感;如果小于1,则更可能是负面情感。
Log Likelihood, Part1
上面的朴素贝叶斯二元分类公式使用了连乘的形式,对于计算上说,小数的连乘会使得计算出现underflow,根据对数性质:
log ( a ∗ b ) = log ( a ) + log ( b ) \log(a*b)=\log(a)+\log(b) log(a∗b)=log(a)+log(b)
可以将连乘转化成为连加的形式,同样对公式求对数得到:
log ( P ( p o s ) P ( n e g ) ∏ i = 1 m P ( w i ∣ p o s ) P ( w i ∣ n e g ) ) = log P ( p o s ) P ( n e g ) + ∑ i = 1 m log P ( w i ∣ p o s ) P ( w i ∣ n e g ) \log\left(\cfrac{P(pos)}{P(neg)}\prod_{i=1}^m\cfrac{P(w_i|pos)}{P(w_i|neg)}\right)=\log\cfrac{P(pos)}{P(neg)}+\sum_{i=1}^m\log\cfrac{P(w_i|pos)}{P(w_i|neg)} log(P(neg)P(pos)i=1∏mP(wi∣neg)P(wi∣pos))=logP(neg)P(pos)+i=1∑mlogP(wi∣neg)P(wi∣pos)
也就是:log prior + log likelihood
我们将第一项成为: λ \lambda λ
Calculating Lambda
根据上面的内容计算实例推文的lambda:
tweet: I am happy because I am learning.
先计算出概率表:
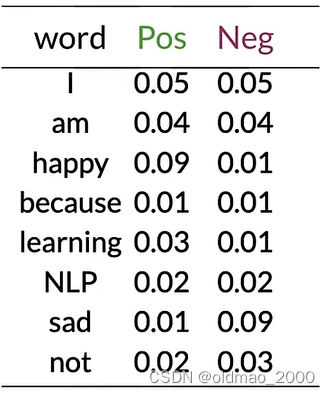
然后根据公式计算出每个单词的 λ \lambda λ:
λ ( w ) = log P ( w ∣ p o s ) P ( w ∣ n e g ) \lambda(w)=\log\cfrac{P(w|pos)}{P(w|neg)} λ(w)=logP(w∣neg)P(w∣pos)
例如对于第一个单词:
λ ( I ) = log 0.05 0.05 = log ( 1 ) = 0 \lambda(I)=\log\cfrac{0.05}{0.05}=\log(1)=0 λ(I)=log0.050.05=log(1)=0
happy:
λ ( h a p p y ) = log 0.09 0.01 = log ( 9 ) = 2.2 \lambda(happy)=\log\cfrac{0.09}{0.01}=\log(9)=2.2 λ(happy)=log0.010.09=log(9)=2.2
以此类推:
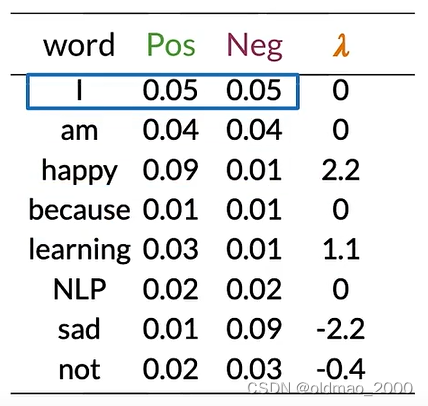
可以看到,这里我们也可以根据 λ \lambda λ值来判断正负面和中性词。
Summary
对于正负面、中性词,这里给出两种判断方式(Word sentiment):
r a t i o ( w ) = P ( w ∣ p o s ) P ( w ∣ n e g ) ratio(w)=\cfrac{P(w|pos)}{P(w|neg)} ratio(w)=P(w∣neg)P(w∣pos)
λ ( w ) = log P ( w ∣ p o s ) P ( w ∣ n e g ) \lambda(w)=\log\cfrac{P(w|pos)}{P(w|neg)} λ(w)=logP(w∣neg)P(w∣pos)
这里要明白,为什么要使用第二种判断方式:避免underflow(下溢)
Log Likelihood, Part 2
有了 λ \lambda λ值,接下来可以计算对数似然,对于以下推文:
I am happy because I am learning.
其每个单词 λ \lambda λ值在上面的图中,整个推文的对数似然值就是做累加:
0 + 0 + 2.2 + 0 + 0 + 0 + 1.1 = 3.3 0+0+2.2+0+0+0+1.1=3.3 0+0+2.2+0+0+0+1.1=3.3
从前面我们可以知道,概率比值以及对数似然的值如何区分正负样本:


这里的推文对数似然的值为3.3,是一个正面样本。
Training Naïve Bayes
这里不用GD,只需简单五步完成训练模型。
Step 0: Collect and annotate corpus

Step 1: Preprocess
包括:
Lowercase
Remove punctuation, urls, names
Remove stop words
Stemming
Tokenize sentences

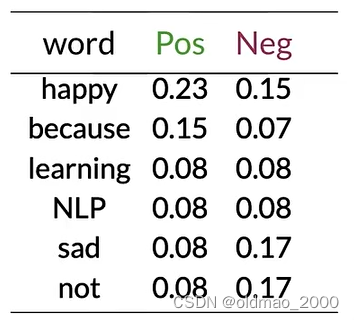
Step 2: Word count
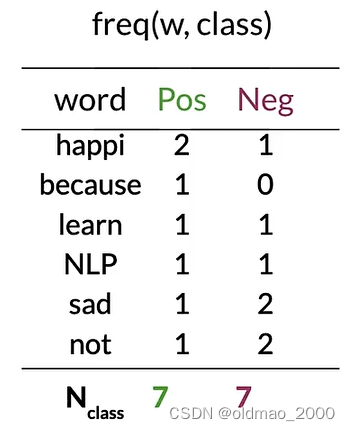
Step 3: P ( w ∣ c l a s s ) P(w|class) P(w∣class)
这里 V c l a s s = 6 V_{class}=6 Vclass=6
根据公式:
f r e q ( w , c l a s s ) + 1 N c l a s s + V c l a s s \cfrac{freq(w,class)+1}{N_{class}+V_{class}} Nclass+Vclassfreq(w,class)+1
计算概率表:
Step 4: Get lambda
根据公式:
λ ( w ) = log P ( w ∣ p o s ) P ( w ∣ n e g ) \lambda(w)=\log\cfrac{P(w|pos)}{P(w|neg)} λ(w)=logP(w∣neg)P(w∣pos)
得到:
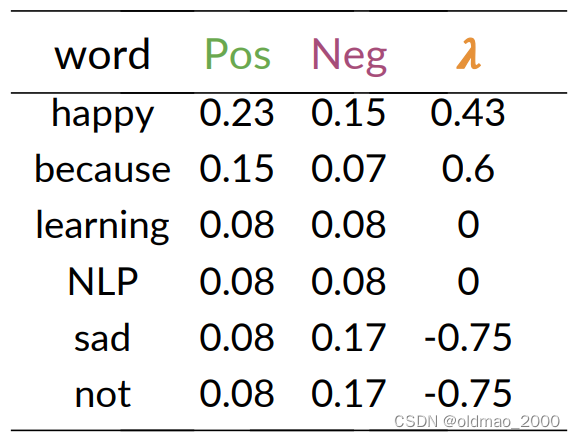
Step 5: Get the log prior
估计先验概率,分别计算:
D p o s D_{pos} Dpos = Number of positive tweets
D n e g D_{neg} Dneg = Number of negative tweets
log prior = log D p o s D n e g \text{log prior}=\log\cfrac{D_{pos}}{D_{neg}} log prior=logDnegDpos
注意:
If dataset is balanced, D p o s = D n e g D_{pos}=D_{neg} Dpos=Dneg and log prior = 0 \text{log prior}=0 log prior=0.
对应正负样本不均衡的数据库,先验概率不能忽略
总的来看是六步:
- Get or annotate a dataset with positive and negative tweets
- Preprocess the tweets: p r o c e s s _ t w e e t ( t w e e t ) ➞ [ w 1 , w 2 , w 3 , . . . ] process\_tweet(tweet) ➞ [w_1 , w_2 , w_3 , ...] process_tweet(tweet)➞[w1,w2,w3,...]
- Compute freq(w, class),注意要引入拉普拉斯平滑
- Get P(w | pos), P(w | neg)
- Get λ(w)
- Compute log prior = log(P(pos) / P(neg))
Testing Naïve Bayes
Predict using Naïve Bayes
进行之前的步骤,我们完成了词典中每个单词对数似然λ(w)的计算,并形成了字典。

假设我们数据集中正负样本基本均衡,可以忽略对数先验概率( log prior = 0 \text{log prior}=0 log prior=0)
对于推文:
[I, pass, the , NLP, interview]
计算其对数似然为:
s c o r e = − 0.01 + 0.5 − 0.01 + 0 + log prior = 0.48 score = -0.01+0.5-0.01+0+\text{log prior}=0.48 score=−0.01+0.5−0.01+0+log prior=0.48
其中interview为未知词,忽略。
也就是是预测值为0.48>0,该推文是正面的。
Testing Naïve Bayes
假设有验证集数据: X v a l X_{val} Xval和标签 Y v a l Y_{val} Yval
计算 λ \lambda λ和log prior,对于未知词要忽略(也就相当于看做是中性词)
计算 s c o r e = p r e d i c t ( X v a l , λ , log prior ) score=predict(X_{val},\lambda,\text{log prior}) score=predict(Xval,λ,log prior)
判断推文情感: p r e d = s c o r e > 0 pred = score>0 pred=score>0
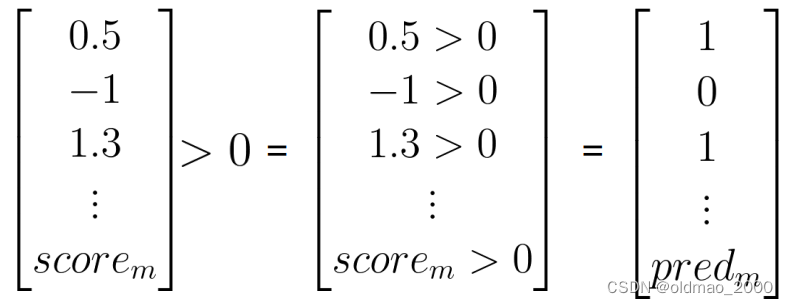
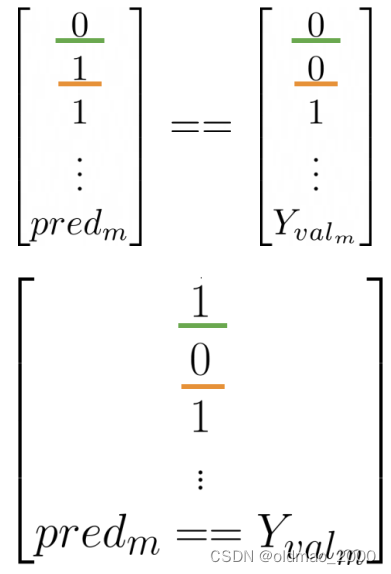
计算模型正确率:
1 m ∑ i = 1 m ( p r e d i = = Y v a l i ) \cfrac{1}{m}\sum_{i=1}^m(pred_i==Y_{val_i}) m1i=1∑m(predi==Yvali)
Applications of Naïve Bayes
除了Sentiment analysis
Naïve Bayes常见应用还包括:
● Author identification
如果有两个大型文集,分别由不同的作者撰写,可以训练一个模型来识别新文档是由哪一位写的。
例如:你手头上有一些莎士比亚的作品和海明威的作品,你可以计算每个词的Lambda值,以预测个新词被莎士比亚使用的可能性,或者被海明威使用的可能性。

●Spam filtering:
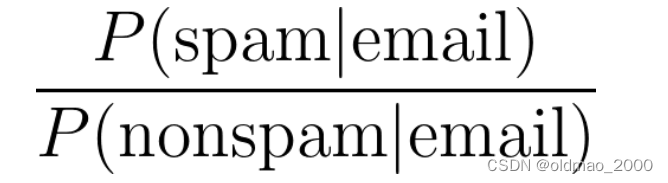
● Information retrieval
朴素贝叶斯最早的应用之一是在数据库中根据查询中的关键字将文档筛选为相关和不相关的文档。
这里只需要计算文档的对数似然,因为先验是未知的。
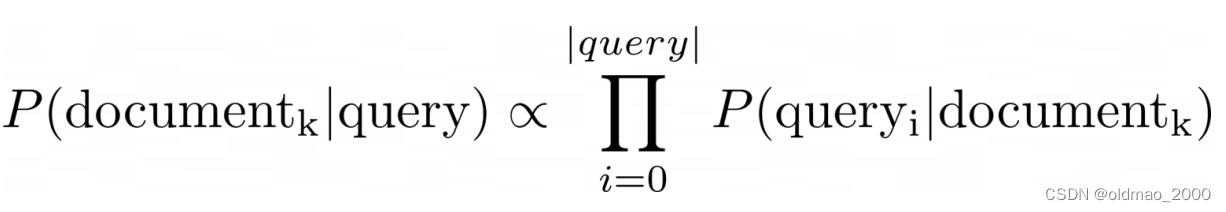
然后根据阈值判断是否查询文档:

● Word disambiguation
假设单词在文中有两种含义,词义消岐可以判断单词在上下文的含义。

bank有河岸和银行两种意思。
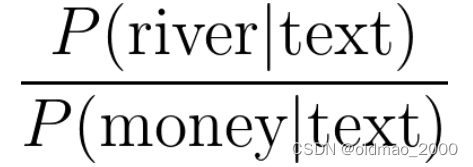
Naïve Bayes Assumptions
朴素贝叶斯是一个非常简单的模型,它不需要设置任何自定义参数,因为它对数据做了一些假设。
● Independence
● Relative frequency in corpus
对于独立性,朴素贝叶斯假设文本中的词语是彼此独立的。看下面例子:
“It is sunny and hot in the Sahara desert.”
单词sunny 和hot 是有关联性的,两个词语在一起可能与其所描述的事物有关,例如:海滩、甜点等。
朴素贝叶斯独立性的假设可能会导致对个别词语的条件概率估计不准确。

例如上图中,winter的概率明显要高于其他单词,但朴素贝叶斯则认为四个单词概率一样。
另外一个问题是依赖于训练数据集的分布。
理想的数据集中应该包含与随机样本相同比例的积极和消极推文,但是实际的推文中,正面推文要比负面推文出现频率要更高。这样训练出来的模型会被戴上有色眼镜。
Error Analysis
造成预测失败的原因有三种:
● Removing punctuation and stop words
● Word order
● Adversarial attacks
Punctuation
Tweet: My beloved grandmother : (
经过标点处理后:processed_tweet: [belov, grandmoth]
我亲爱的祖母,本来是正面推文,但是后面代表悲伤的emoj被过滤掉了。如果换成感叹号那就不一样。
Removing Words
Tweet: This is not good, because your attitude is not even close to being nice.
去掉停用词后:processed_tweet: [good, attitude, close, nice]
Tweet: I am happy because I do not go.
Tweet: I am not happy because I did go.
上面一个是正面的(I am happy),后面一个是负面的(I am not happy)
否定词和词序会导致预测错误。
Adversarial attacks
主要是Sarcasm, Irony and Euphemisms(讽刺、反讽和委婉语),天才Sheldon都不能李姐!!!
Tweet: This is a ridiculously powerful movie. The plot was gripping and I cried right through until the ending!
processed_tweet: [ridicul, power, movi, plot, grip, cry, end]
原文表达是正面的: 这是一部震撼人心的电影。情节扣人心弦,我一直哭到结局!
但处理后的单词却是负面的。
相关文章:
03.C1W2.Sentiment Analysis with Naïve Bayes
目录 Probability and Bayes’ RuleIntroductionProbabilitiesProbability of the intersection Bayes’ RuleConditional ProbabilitiesBayes’ RuleQuiz: Bayes’ Rule Applied Nave Bayes IntroductionNave Bayes for Sentiment Analysis P ( w i ∣ c l a s s ) P(w_i|clas…...

一个强大的分布式锁框架——Lock4j
一、简介 Lock4j是一个分布式锁组件,它提供了多种不同的支持以满足不同性能和环境的需求,基于Spring AOP的声明式和编程式分布式锁,支持RedisTemplate、Redisson、Zookeeper。 二、特性 • 简单易用,功能强大,扩展性…...
HarmonyOS - 通过.p7b文件获取fingerprint
1、查询工程所对应的 .p7b 文件 通常新工程运行按照需要通过 DevEco Studio 的 Project Structure 勾选 Automatically generate signature 自动生成签名文件,自动生成的 .p7b 文件通常默认在系统用户目录下. 如:C:/Users/zhangsan/.ohos/config/default…...

vue3实现echarts——小demo
版本: 效果: 代码: <template><div class"middle-box"><div class"box-title">检验排名TOP10</div><div class"box-echart" id"chart1" :loading"loading1"&…...
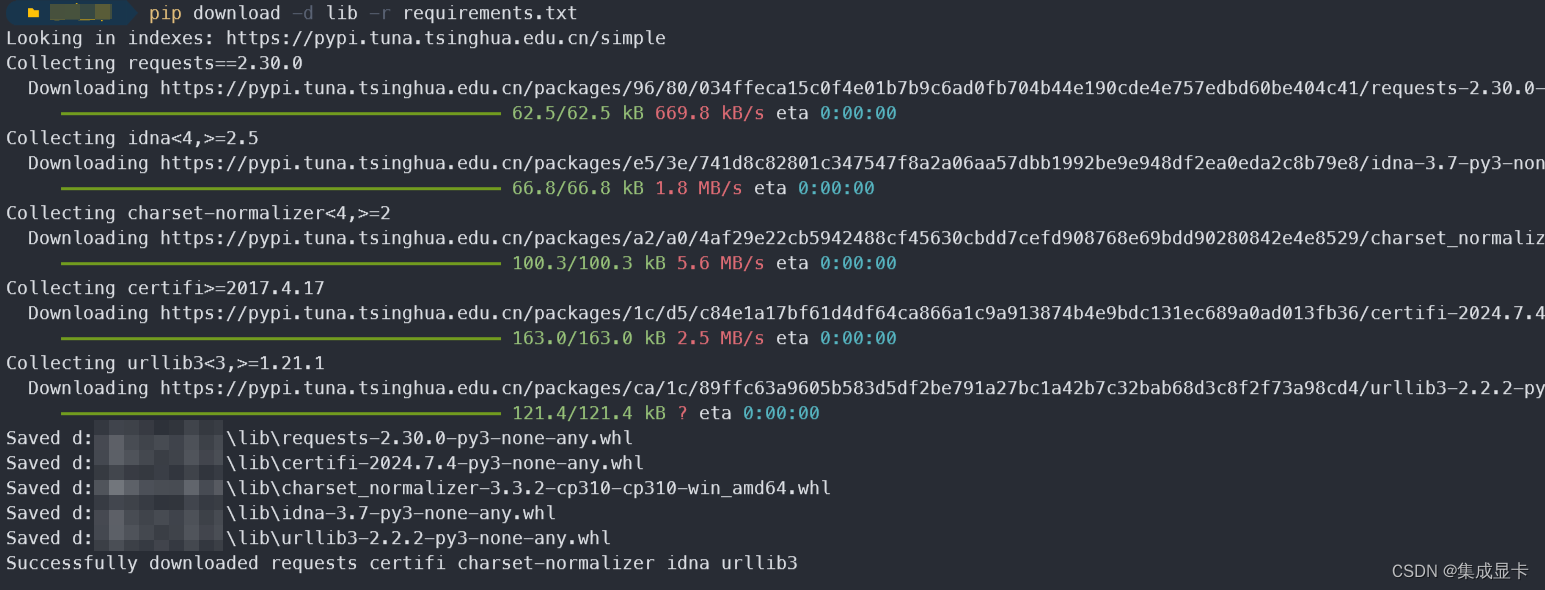
Python 项目依赖离线管理 pip + requirements.txt
背景 项目研发环境不支持联网,无法通过常规 pip install 来安装依赖,此时需要在联网设备下载依赖,然后拷贝到离线设备进行本地安装。 两台设备的操作系统、Python 版本尽可能一致。 离线安装依赖 # 在联网设备上安装项目所需的依赖 # -d …...
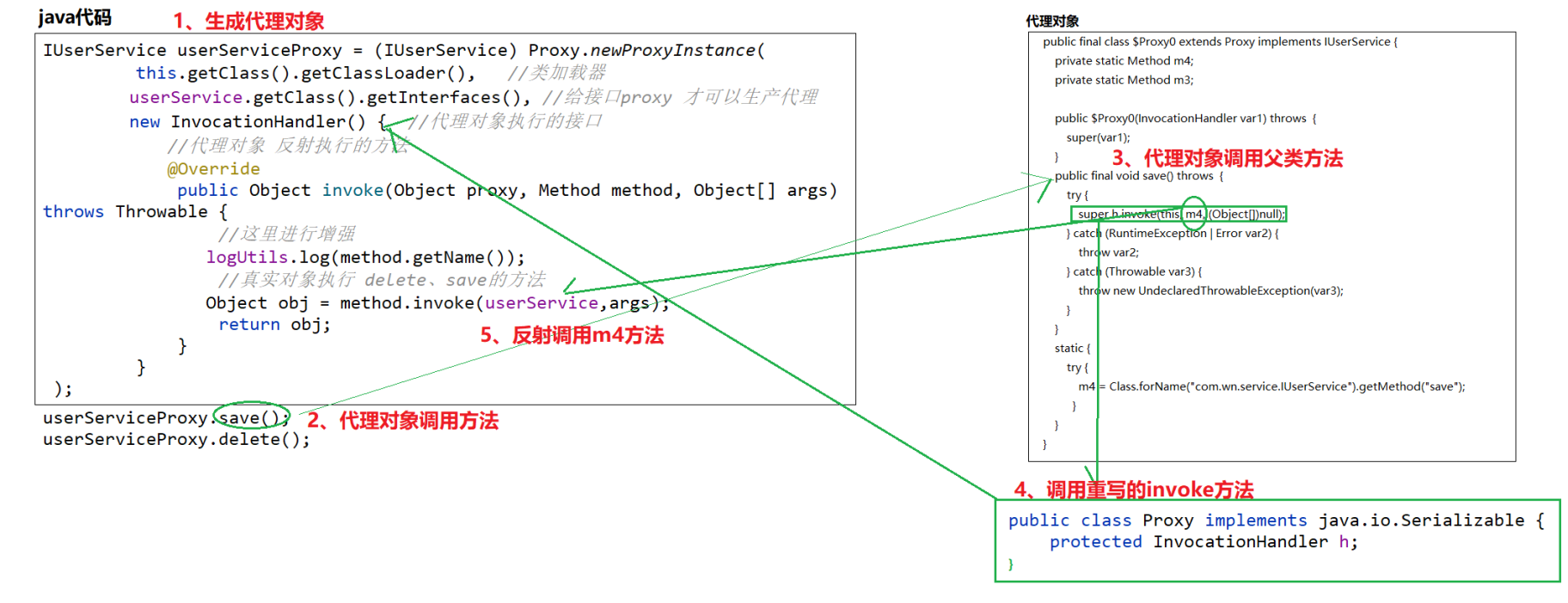
jdk动态代理代码实现
1、jdk动态代理代码实现 1、接口 public interface IUserService {void save();void delete();}2、接口实现 Service public class UserServiceImpl implements IUserService {Overridepublic void save() {System.out.println("UserServiceImpl.save");}Override…...

mybatis的xml如何使用java枚举
mybatis的xml如何使用java枚举 使用方式 ${com.haier.baseManage.enums.LoganUploadTaskTypeEnumLOG_TYPE.type} 例子 <?xml version"1.0" encoding"UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" &quo…...

SQL Server中设置端口号
在SQL Server中设置端口号可以通过SQL Server配置管理器进行。以下是具体步骤: 使用SQL Server 配置管理器设置端口 打开SQL Server配置管理器: 在Windows开始菜单中搜索“SQL Server 配置管理器”,然后打开它。 配置SQL Server网络配置&…...
)
CSS Border(边框)
CSS Border(边框) 引言 在网页设计中,边框是增强元素视觉效果和页面布局的重要工具。CSS 提供了丰富的边框样式属性,允许开发者自定义边框的宽度、颜色、样式等。本文将详细介绍 CSS 边框的相关属性,包括基本用法和高级技巧,帮助…...

【鸿蒙学习笔记】@Prop装饰器:父子单向同步
官方文档:Prop装饰器:父子单向同步 [Q&A] Prop装饰器作用 Prop装饰的变量可以和父组件建立单向的同步关系。Prop装饰的变量是可变的,但是变化不会同步回其父组件。 [Q&A] Prop装饰器特点 1・Prop装饰器不能在Entry装饰的…...
-状态模式)
设计模式(实战项目)-状态模式
需求背景:存在状态流转的预约单 一.数据库设计 CREATE TABLE appointment (id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 主键id,appoint_type int(11) NOT NULL COMMENT 预约类型(0:线下查房...),appoint_user_id bigint(20) NOT NULL COMMENT 预约人…...

【python】OpenCV—Color Map
文章目录 cv2.applyColorMapcv2.putText小试牛刀自定义颜色 参考学习来自 OpenCV基础(21)使用 OpenCV 中的applyColorMap实现伪着色 cv2.applyColorMap cv2.applyColorMap() 是 OpenCV 中的一个函数,用于将灰度图像或单通道图像应用一个颜色…...

MySQL:表的内连接和外连接、索引
文章目录 1.内连接2.外连接2.1 左外连接2.2 右外连接 3.综合练习4.索引4.1见一见索引4.2 硬件理解4.3 MySQL 与磁盘交互基本单位(软件理解)4.4 (MySQL选择的数据结构)索引的理解4.5 聚簇索引 VS 非聚簇索引 5.索引操作5.1 创建索引5.2 查询索引5.3 删除索引 1.内连接 内连接实…...
Chrome备份数据
Chrome备份数据 1、 导出谷歌浏览器里的历史记录 参考:https://blog.csdn.net/qq_32824605/article/details/127504219 在资源管理器中找到History文件,文件路径: C:\Users\你的电脑用户名\AppData\Local\Google\Chrome\User Data\Default …...
visual studio远程调试
场景一(被远程调试的电脑) 确定系统位数 我这里是x64的 找到msvsmon.exe msvsmon.exe目录位置解释: “F:\App\VisualStudio\an\Common7\IDE\”是visual studio所在位置、 “Remote Debugger\”是固定位置、 “x64”是系统位数。 拼起来就是…...

if __name__ == “__main__“
在Python中,if __name__ "__main__": 这行代码非常常见,它用于判断当前运行的脚本是否是主程序。这里的 __name__ 是一个特殊变量,当Python文件被直接运行时,__name__ 被自动设置为字符串 "__main__"。但是&…...

数据识别概述
数据识别场景 数据识别确实可以分为两种主要类型:直接识别和间接识别(或称为从文本中发现)。下面我将详细解释这两种类型: 直接识别: 定义:直接识别是指直接判断某个数据是否符合特定的标准或条件。应用场…...

pytorch统计学分布
1、pytorch统计学函数 import torcha torch.rand(2,2) print(a) print(torch.sum(a, dim0)) print(torch.mean(a, dim0)) print(torch.prod(a, dim0))print(torch.argmax(a, dim0)) print(torch.argmin(a, dim0)) print(torch.std(a)) print(torch.var(a)) print(torch.median…...
【网络安全学习】漏洞利用:BurpSuite的使用-03-枚举攻击案例
如何使用BurpSuite进行枚举攻击 1.靶场选择 BurpSuite官方也是有渗透的教学与靶场的,这次就使用BurpSuite的靶场进行练习。 靶场地址:https://portswigger.net/web-security 登录后如下图所示,选择**【VIEW ALL PATHS】**: 找…...

redis 消息订阅命令
在 Redis 中,消息订阅和发布是一种用于实现消息传递的机制。主要命令包括 SUBSCRIBE、UNSUBSCRIBE、PUBLISH 和 PSUBSCRIBE 等。下面是如何使用这些命令的详细说明和示例。 1. SUBSCRIBE 命令 SUBSCRIBE 命令用于订阅一个或多个频道,以接收这些频道发布…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

避坑指南:Unity中AABB碰撞检测失效的5种常见原因及解决方法
Unity中AABB碰撞检测失效的深度排查与解决方案在Unity开发中,AABB(轴对齐包围盒)碰撞检测是基础但容易出问题的环节。许多开发者都遇到过这样的情况:明明逻辑正确,测试时却出现物体穿透、碰撞时有时无等诡异现象。本文…...