Diffusion模型的微调和引导
留意后续更新,欢迎关注微信公众号:组学之心
Diffusion模型的微调和引导
-
微调(fine-tuning):
从一个已经训练过的模型开始训练,我们就可以从一个学会如何“去噪”的模型开始训练,相对于随机初始化的模型也许是一个更好的起点。如果新的数据和原来模型训练用的数据比较相似的死后,微调的效果会很好。 -
引导(guidance):
在生成模型中,如果没有提供特定的条件(比如图像的某些特征或文本的某些关键词),模型通常不能控制生成的内容。因此,我们可以训练一个“条件模型”,通过给模型额外的输入信息来控制生成过程。但是,如果我们使用的是一个没有条件的模型,该怎么实现相同的控制效果呢?我们可以采用一种叫做“引导”的方法。简单来说,在生成过程中,模型会一步步地生成内容,每一步生成的结果都会通过一些“引导函数”来评估,并根据评估结果进行修改,使得最终生成的内容符合我们的预期。“引导函数”可以是任何能够评估和调整生成结果的函数,这其中有很大的设计空间和灵活性。 -
条件生成:
引导方法可以让我们从一个没有条件的模型中获得更多的控制和收益。如果我们在训练模型时有一些额外的信息(比如图像的类别或文字描述),我们可以直接把这些信息输入模型,让模型利用这些信息进行预测。这样,我们就创建了一个“条件模型”,在生成内容时可以通过输入相关的信息来控制生成过程。有很多方法可以将条件信息输入到模型中。例如:额外通道输入:我们可以把这些条件信息作为额外的通道输入到UNet模型中,这时候条件信息通常和图像有相同的形状(shape),这样模型就能更好地理解和利用这些信息。交叉注意力机制:我们可以在模型中添加一些网络层,这些层带有交叉注意力机制,专门用来处理和结合这些条件信息。交叉注意力机制可以帮助模型在生成内容时更好地关注和利用这些条件信息。
来实际操作一下
1.环境准备
安装好必须的python库
pip install -qq diffusers datasets accelerate wandb open-clip-torchimport numpy as np
import torch
import torch.nn.functional as F
import torchvision
from datasets import load_dataset
from diffusers import DDIMScheduler, DDPMPipeline
from matplotlib import pyplot as plt
from PIL import Image
from torchvision import transforms
from tqdm.auto import tqdmdevice = ("mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available() else "cpu")
在终端中输入huggingface-cli login,登录hugging face的WRITE的Access Tokens,后续上传模型的时候用到。
2.先用管线载入一个预训练过的模型
这是google开发的人脸生成模型,用它来练练手,作图展示一下模型效果
image_pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
image_pipe.to(device)
images = image_pipe().imagesplt.imshow(images[0])
plt.axis('off')
plt.show()

3.使用可以更快的采样DDIM调度器,加速模型计算
DDIMScheduler相对于DDPM,减少了迭代周期来产生不错的采样样本。用几张随即噪音图像进行循环采样,并观察每一步输入图像和预测结果的“去噪”版本
#创建一个新的调度器来对比效果
scheduler = DDIMScheduler.from_pretrained("google/ddpm-celebahq-256")
scheduler.set_timesteps(num_inference_steps=40)# 随机生成4张256×256的彩色图
x = torch.randn(4, 3, 256, 256).to(device)for i, t in tqdm(enumerate(scheduler.timesteps)):# 预测噪声并计算更新后的样本with torch.no_grad():noise_pred = image_pipe.unet(scheduler.scale_model_input(x, t), t)["sample"]x = scheduler.step(noise_pred, t, x).prev_sample# 每隔10步或最后一步显示图像if i % 10 == 0 or i == len(scheduler.timesteps) - 1:fig, axs = plt.subplots(1, 2, figsize=(12, 5))# 当前图像grid = torchvision.utils.make_grid(x, nrow=4).permute(1, 2, 0)axs[0].imshow(grid.cpu().clip(-1, 1) * 0.5 + 0.5)axs[0].set_title(f"Current x (step {i})")# 去噪图像grid = torchvision.utils.make_grid(scheduler.step(noise_pred, t, x).pred_original_sample, nrow=4).permute(1, 2, 0)axs[1].imshow(grid.cpu().clip(-1, 1) * 0.5 + 0.5)axs[1].set_title(f"Predicted denoised images (step {i})")plt.savefig(f"00zuxuezhixin/finetuning_guidance/step_{i}.png")plt.show()





可以看出一开始预测结果不好,随着模型的推理,预测效果输出逐步改善。也可以直接修改管线载入的模型中的调度器,做后续的任务
image_pipe.scheduler = scheduler
images = image_pipe(num_inference_steps=40).images
开始微调
怎么用新的训练数据重新训练模型,来生成图像呢?这里先加载Vintage Faces人脸数据集(但不是真实人脸的风格),用它来进行微调。
1.加载数据集
dataset = load_dataset("Norod78/Vintage-Faces-FFHQAligned", split="train")# 数据增强
preprocess = transforms.Compose([transforms.Resize((256, 256)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),
])# 定义数据转换函数
def transform(examples):images = []for image in examples["image"]:try:images.append(preprocess(image.convert("RGB")))except Exception as e:print(f"Error processing image: {e}")return {"image": images}# 应用数据转换
dataset.set_transform(transform)# 自定义 collate 函数,过滤掉 NoneType 数据
def collate_fn(batch):batch = [item for item in batch if item["image"] is not None and len(item["image"]) > 0]return {"image": torch.stack([item["image"] for item in batch])}train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=4, shuffle=True, collate_fn=collate_fn)# 看看一个批次的图像长什么样
print("Previewing batch:")
batch = next(iter(train_dataloader))
grid = torchvision.utils.make_grid(batch["image"], nrow=4)
plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5)
plt.axis('off')
plt.show()

2.训练循环
看看训练循环,首先把想要优化的目标参数设定为image_pipe.unet.parameters(),来更新预训练过的模型权重。
image_pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
image_pipe.to(device)
scheduler = DDIMScheduler.from_pretrained("google/ddpm-celebahq-256")
image_pipe.scheduler = scheduler# 设置超参数
num_epochs = 2
grad_accumulation_steps = 2# 初始化优化器
optimizer = torch.optim.AdamW(image_pipe.unet.parameters(), lr=1e-5)# 存储损失值
losses = []# 训练循环
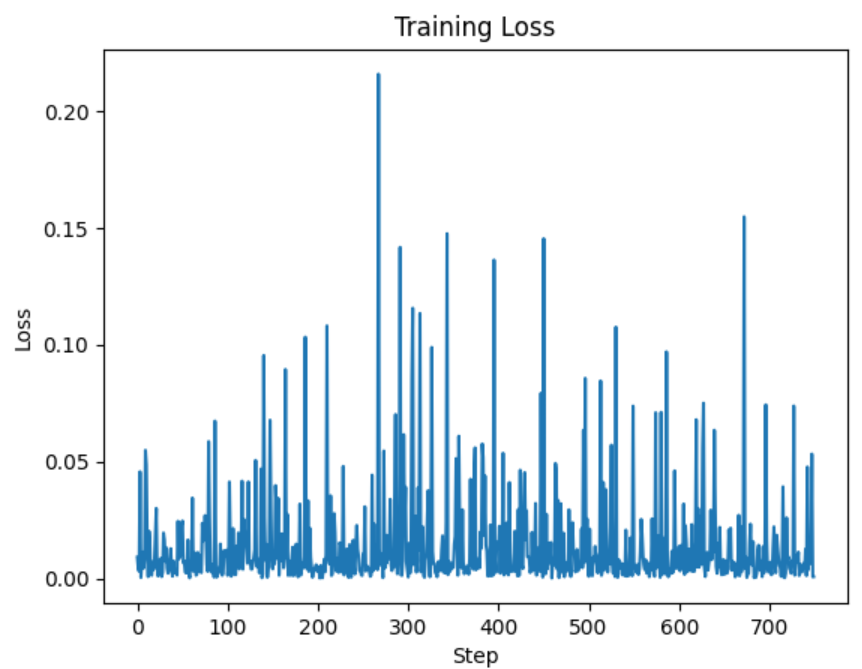
for epoch in range(num_epochs):epoch_losses = []for step, batch in tqdm(enumerate(train_dataloader), total=len(train_dataloader)):clean_images = batch["image"].to(device)noise = torch.randn_like(clean_images) #随机生成噪音,加到图像上# 随机选取一个时间步timesteps = torch.randint(0, image_pipe.scheduler.num_train_timesteps, (clean_images.size(0),), device=device)noisy_images = image_pipe.scheduler.add_noise(clean_images, noise, timesteps) # 前向过程noise_pred = image_pipe.unet(noisy_images, timesteps)[0] #使用带噪音的图像进行网络预测loss = F.mse_loss(noise_pred, noise) # 对真正的噪音和预测结果进行比较,这里是预测噪音losses.append(loss.item())epoch_losses.append(loss.item())loss.backward()## 进行梯度累积,在积累到一定步数后更新模型权重if (step + 1) % grad_accumulation_steps == 0:optimizer.step()optimizer.zero_grad()avg_loss = sum(epoch_losses) / len(epoch_losses)print(f"Epoch {epoch} average loss: {avg_loss}")# 绘制损失曲线
plt.plot(losses)
plt.xlabel('Step')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.savefig(f"00zuxuezhixin/finetuning_guidance/finetuning_test.png")
plt.show()
可以看出损失曲线很混乱,因为每次迭代只用了4个样本,并且添加到的噪声水平也是随机的,对训练来说并不理想。可以用梯度类似来弥补,这样可以得到与使用更大的batch一样的收益,又不会造成内存爆满。具体的做法是运行多几次loss.backward()再调用optimizer.stzer.zero_grad()。梯度累计hugging face会替我们做。
来看看调整后的模型生成的图像:

抽象派大师!可见它在努力的把真人往另一个画风拟合中…
3.使用一个最小化示例程序来微调模型
下载一个最小实例化程序,它会提示要用wandb来操作,我们只要去到wandb官网创建一个账号,在账号设置里创建API Key,在运行脚本的时候会提示我们输入该API Key,然后就可以实现wandb微调。
## 下载微调用的脚本:
wget https://github.com/huggingface/diffusion-models-class/raw/main/unit2/finetune_model.py## 运行脚本,在Vintage Face数据集上训练脚本
## 在终端里跑:
python 00zuxuezhixin/finetuning_guidance/finetune_model.py --image_size 128 --batch_size 8 --num_epochs 16 --grad_accumulation_steps 2 --start_model "google/ddpm-celebahq-256" --dataset_name "Norod78/Vintage-Faces-FFHQAligned" --wandb_project 'dm-finetune' --log_samples_every 100 --save_model_every 1000 --model_save_name 'vintageface'
4.保存和载入微调后的管线
将微调好的模型保存到hugging face,我们在开始的时候就登录了,用以下代码完成模型的保存和上传。
image_pipe.save_pretrained("00zuxuezhixin/finetuning_guidance/finetuned_model")
from huggingface_hub import HfApi, create_repo, get_full_repo_namemodel_name = "ddpm-celebahq-finetuned-vintage-2epochs"
local_folder_name = "00zuxuezhixin/finetuning_guidance"
description = "finetuning_practice_vintage"
hub_model_id = get_full_repo_name(model_name)
create_repo(hub_model_id)
api = HfApi()
api.upload_folder(folder_path=f"{local_folder_name}/scheduler", path_in_repo="", repo_id=hub_model_id
)
api.upload_folder(folder_path=f"{local_folder_name}/unet", path_in_repo="", repo_id=hub_model_id
)
api.upload_file(path_or_fileobj=f"{local_folder_name}/model_index.json",path_in_repo="model_index.json",repo_id=hub_model_id,
)
扩散模型的引导
上一步微调的使用的数据太大,我的4060跑了挺久的…换个数据来进行后续操作。本部分使用在LSUM bedrooms数据集(房间样式的图像数据)上训练并在WikiArt数据集(艺术作品中的人脸图片数据)上进行一轮微调的新模型。下载该模型,从模型中采样图像,并通过DDIM调度器进行推理,看看他的生成效果:
import torch
from tqdm import tqdm
import torchvision
import matplotlib.pyplot as plt
from transformers import DDPMPipeline, DDIMScheduler# 加载预训练的pipeline
pipeline_name = "johnowhitaker/sd-class-wikiart-from-bedrooms"
image_pipe = DDPMPipeline.from_pretrained(pipeline_name).to(device)# 使用DDIM调度器在40步内采样一些图像
scheduler = DDIMScheduler.from_pretrained(pipeline_name)
scheduler.set_timesteps(num_inference_steps=40)# 随机起始点(8张图像的批次)
x = torch.randn(8, 3, 256, 256).to(device)# 最小采样循环
for i, t in tqdm(enumerate(scheduler.timesteps)):model_input = scheduler.scale_model_input(x, t)with torch.no_grad():noise_pred = image_pipe.unet(model_input, t)["sample"]x = scheduler.step(noise_pred, t, x).prev_sample# 展示结果
grid = torchvision.utils.make_grid(x, nrow=4)
plt.figure(figsize=(10, 10))
plt.imshow(grid.permute(1, 2, 0).cpu().clip(0, 1))
plt.axis('off')
plt.show()

生成的图像效果很魔幻,通常情况下,想要判断微调的效果并不容易,而且就算模型的性能很好,但在不同的应用场景下,它的水平也会有所变化。在这里来完全重新训练一个模型来适应新的数据集,此时就需要使用较大的学习率并进行长时间的训练。一般比较难从损失曲线中看出模型是否得到了改善,生成的样本也清晰的显示出不同风格的变迁,它在努力的变迁(从用房间样式数据集训练的模型往艺术作品中的人脸变迁),尽管看起来很魔幻。接下来对这种模型进行额外的引导。
1.来开始实战一下
如果想要对生成的样本进行控制该怎么做呢?如果想让生成的图片偏向于靠近某种颜色该怎么做呢?我们可以用引导,在采样的过程中施加额外的控制。首先就需要去定义我们希望优化的指标,这个指标可以是损失值。
下面的函数就是来让生成的图片趋近于晚霞粉紫色的示例:
def color_loss(images, target_color=(0.8, 0.4, 0.6)):"""给定目标颜色(R, G, B),返回图像像素与该颜色的平均距离损失。"""target = (torch.tensor(target_color).to(images.device) * 2 - 1) # 将目标颜色映射到(-1, 1)target = target[None, :, None, None] # 调整形状以与图像匹配 (b, c, h, w)error = torch.abs(images - target).mean() # 图像像素与目标颜色的平均绝对误差return error
接下来需要修改采样循环并执行以下操作:
- 创建新的输入图像,把它的requires_grad属性设置为True
- 计算“去噪”后的图像,并传递给损失函数
- 计算损失函数对输入图像的梯度
- 在使用调度器之前,先用计算出来的梯度修改输入图像,使得输入图像朝着最小化损失值的方向改进。
实现的方法之一是:先将输入图像的requires_grad属性设置为True,然后传递给UNet并计算去噪后的图像
# 定义指导损失系数
guidance_loss_scale = 40
# 随机起始点(4张图像的批次)
x = torch.randn(4, 3, 256, 256).to(device)
# 采样循环
for i, t in tqdm(enumerate(scheduler.timesteps), total=len(scheduler.timesteps)):# 设置 requires_grad 在模型前向传播之前x = x.detach().requires_grad_()model_input = scheduler.scale_model_input(x, t)# 预测(这次带梯度)noise_pred = image_pipe.unet(model_input, t)["sample"]# 获取预测的图像x0 = scheduler.step(noise_pred, t, x).pred_original_sample# 计算损失loss = color_loss(x0) * guidance_loss_scaleif i % 10 == 0:print(i, "loss:", loss.item())# 获取梯度cond_grad = -torch.autograd.grad(loss, x)[0]# 根据梯度修改输入图像x = x.detach() + cond_grad# 使用调度器进行步骤x = scheduler.step(noise_pred, t, x).prev_sample# 创建网格并展示
grid = torchvision.utils.make_grid(x, nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5plt.imshow(im)
plt.axis('off')
plt.savefig(f"00zuxuezhixin/finetuning_guidance/guidance_test.png")
plt.show()
代码输出的损失是:
0%| | 0/40 [00:00<?, ?it/s]0 loss: 17.13970184326172
28%|██▊ | 11/40 [01:08<03:03, 6.34s/it]10 loss: 9.006878852844238
52%|█████▎ | 21/40 [02:11<01:59, 6.28s/it]20 loss: 8.319286346435547
75%|███████▌ | 30/40 [03:06<01:02, 6.21s/it]30 loss: 8.618431091308594
100%|██████████| 40/40 [04:12<00:00, 6.32s/it]
生成的图像:

这种方法的输出更接近于训练模型所使用的数据。增大guidance_loss_scale可以增强颜色迁移的效果。
2.CLIP引导
进阶玩一下,能不能直接用语言描述得到自己想要的图片呢?
可以借助CLIP,它是OpenAI开发的模型,使得我们能够对图片和文字说明进行比较,量化一张图和一段文字的匹配程度。这个过程是可微的,所以可以将其作为损失函数来引导扩散模型。基本流程:
- 文本嵌入:将文本提示语输入CLIP模型,得到512维的文本嵌入向量。
- 图片嵌入:生成多个版本的预测去噪图片,并将这些图片输入CLIP模型,得到图片的嵌入向量。
- 计算匹配度:比较图片嵌入和文本嵌入,计算它们的匹配度(度量方法是great circle distance squared)。
- 计算损失和梯度:计算匹配度损失,然后对带噪输入图像计算梯度。
- 更新输入图像:在使用调度器更新输入图像之前,用计算出的梯度修正图像。
具体想学习CLIP的底层逻辑,请看https://github.com/mlfoundations/open_clip
import open_clip
clip_model, _, preprocess = open_clip.create_model_and_transforms("ViT-B-32", pretrained="openai")
clip_model.to(device)# 图像增强处理,使得数据能够适配CLIP模型
tfms = torchvision.transforms.Compose([torchvision.transforms.RandomResizedCrop(224),torchvision.transforms.RandomAffine(5),torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.Normalize(mean=(0.48145466, 0.4578275, 0.40821073),std=(0.26862954, 0.26130258, 0.27577711),),]
)# 定义损失函数,用于获取图像特征,然后和提示文字的特征进行对比
# 这里引导的采样循环看起来和前面的例子中的类似,只不过是把color_loss()函数换成了新的基于CLIP的损失函数
def clip_loss(image, text_features):image_features = clip_model.encode_image(tfms(image))input_normed = torch.nn.functional.normalize(image_features.unsqueeze(1), dim=2)embed_normed = torch.nn.functional.normalize(text_features.unsqueeze(0), dim=2)dists = (input_normed.sub(embed_normed).norm(dim=2).div(2).arcsin().pow(2).mul(2))return dists.mean()
#文本嵌入
prompt = "Red Rose,red flower painting"
text = open_clip.tokenize([prompt]).to(device)
with torch.no_grad(), torch.cuda.amp.autocast():text_features = clip_model.encode_text(text)# 随机起始点(4张图像的批次)
x = torch.randn(4, 3, 256, 256).to(device)
# 定义参数
guidance_scale = 8
n_scale = 4
scheduler.set_timesteps(50) # 调大timesteps可以让指导发挥更多的作用# 采样循环
for i, t in tqdm(enumerate(scheduler.timesteps), total=len(scheduler.timesteps)):model_input = scheduler.scale_model_input(x, t)# 预测噪声残差with torch.no_grad():noise_pred = image_pipe.unet(model_input, t)["sample"]cond_grad = 0for cut in range(n_scale):# 设置x的梯度x = x.detach().requires_grad_()# 获取预测的x0x0 = scheduler.step(noise_pred, t, x).pred_original_sample# 计算损失loss = clip_loss(x0, text_features) * guidance_scale# 获取梯度(按n_cuts缩放,因为我们需要平均值)cond_grad -= torch.autograd.grad(loss, x)[0] / n_scaleif i % 25 == 0:print("Step:", i, ", Guidance loss:", loss.item())# 根据梯度修改xalpha_bar = scheduler.alphas_cumprod[i]x = (x.detach() + cond_grad * alpha_bar.sqrt())# 使用调度器进行步骤x = scheduler.step(noise_pred, t, x).prev_sample# 展示图象
grid = torchvision.utils.make_grid(x.detach(), nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
plt.imshow(im)
plt.axis('off')
plt.savefig(f"00zuxuezhixin/finetuning_guidance/guidance_CLIP_test.png")
plt.show()

有点像红玫瑰,但不多…
3.参数理解
guidance_scale和n_scale是两个重要的超参数,作用如下:
- guidance_scale:guidance_scale参数控制文本指导损失的强度。它的作用是放大或缩小由文本描述引导生成图像的影响。
①指导损失放大:通过对损失值进行放大,使得生成的图像更加符合文本描述。值越大,生成的图像会越接近文本描述,但如果值过大,可能会导致图像质量下降或者生成图像过度适应描述。
②权衡生成质量和描述匹配度:需要在生成图像的质量和对文本描述的匹配度之间找到一个平衡。一个合理的guidance_scale值可以生成既高质量又符合描述的图像。 - n_scale:n_scale参数控制在每个采样步骤中进行图像裁剪的次数。
①图像裁剪:在每个采样步骤中对图像进行多次裁剪,将这些裁剪后的图像片段输入CLIP模型进行匹配度计算。这有助于提升生成图像的多样性和丰富性。
②损失平均化:通过对多个裁剪后的图像计算损失并取平均值,可以获得更稳定和鲁棒的梯度信息,从而更好地引导图像生成。
此外,这里使用alpha_bar.sqrt()作为因子来缩放梯度,可以有效地适应扩散过程的动态变化,实现更稳定和自然的图像生成。但需要仔细的参数调试和实验,才能优化效果。
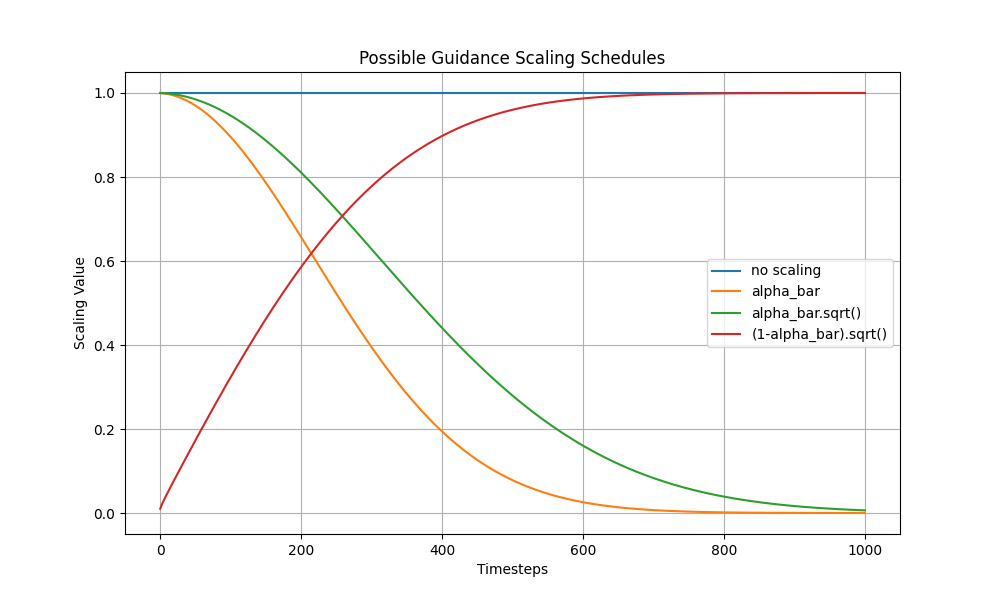
可以做一个图来看看不同梯度的缩放带来的影响:
plt.figure(figsize=(10, 6))
plt.plot([1 for a in scheduler.alphas_cumprod], label="no scaling")
plt.plot([a for a in scheduler.alphas_cumprod], label="alpha_bar")
plt.plot([a.sqrt() for a in scheduler.alphas_cumprod], label="alpha_bar.sqrt()")
plt.plot([(1 - a).sqrt() for a in scheduler.alphas_cumprod], label="(1-alpha_bar).sqrt()")
plt.legend()
plt.title("Possible Guidance Scaling Schedules")
plt.xlabel("Timesteps")
plt.ylabel("Scaling Value")
plt.grid(True)
plt.savefig(f"00zuxuezhixin/finetuning_guidance/guidance_CLIP_Timesteps_alphas_cumprod.png")
plt.show()
No scaling:由于没有缩放,所有时间步中的缩放因子都是1,因此这条线是一条水平线。
alpha_bar:随时间步的增加而减小,说明随着生成过程的推进,噪声水平逐渐降低。
alpha_bar.sqrt():随着时间步的增加也逐渐减小,但比alpha_bar更缓慢地减小。
(1 - alpha_bar).sqrt():这条曲线随着时间步的增加而增大,表示随着生成过程的推进,1-alpha_bar的影响逐渐增加。
通过这些曲线,我们可以理解在不同的缩放调度方案下,指导损失(gradient)在生成过程中的作用。选择合适的缩放调度方案对于生成质量和效率非常重要。
相关文章:
Diffusion模型的微调和引导
留意后续更新,欢迎关注微信公众号:组学之心 Diffusion模型的微调和引导 微调(fine-tuning): 从一个已经训练过的模型开始训练,我们就可以从一个学会如何“去噪”的模型开始训练,相对于随机初始…...

零基础学MySQL:从入门到实践的完整指南
引言: MySQL,作为全球最受欢迎的开源关系型数据库管理系统之一,以其高性能、易用性和灵活性,在Web开发、数据分析等领域占据着举足轻重的地位。如果你是一位编程新手,想要踏入数据库管理的大门,本文将从零…...

澳蓝荣耀时刻,6款产品入选2024年第一批《福州市名优产品目录》
近日,福州市工业和信息化局公布2024年第一批《福州市名优产品目录》,澳蓝自主研发生产的直接蒸发冷却空调、直接蒸发冷却组合式空调机组、间接蒸发冷水机组、高效间接蒸发冷却空调机、热泵式热回收型溶液调湿新风机组、防火湿帘6款产品成功入选。 以上新…...

Frrouting快速入门——OSPF组网(一)
FRR简介 FRR是FRRouting的简称,是一个开源的路由交换软件套件。其作者源自老牌项目quaga的成员,也可以算是quaga的新版本。 使用时一般查看此文档:https://docs.frrouting.org/projects/dev-guide/en/latest/index.html FRR支持的协议众多…...

记录通过Cloudflare部署属于自己的docker镜像源
引言 由于最近国内无法正常拉取docker镜像,然而找了几个能用的docker镜像源发现拉取回来的docker镜像不是最新的版本,部署到Cloudflare里Workers 和 Pages,拉取docker 镜像成功,故记录部署过程。 部署服务 登录Cloudflare后&…...

波动方程 - 在三维图中动态显示二维波动方程的解就像水面波澜起伏
波动方程 - 在三维图中动态显示二维波动方程的解就像水面波澜起伏 flyfish 波动方程的求解结果通常不是一个单一的数值,而是一个函数或一组函数,这些函数描述了波随时间和空间的传播情况。具体来说,波动方程的解可以是关于时间和空间变量的…...

yum命令提示 错误:rpmdb: BDB0113 Thread/process 4153/139708200269632
一、报错信息 [rootDawn yum.repos.d]# yum clean all 错误:rpmdb: BDB0113 Thread/process 4153/139708200269632 failed: BDB1507 Thread died in Berkeley DB library 错误:db5 错误(-30973) 来自 dbenv->failchk:BDB0087 DB_RUNRECOVE…...
欢乐钓鱼大师游戏攻略:在什么地方掉称号鱼?云手机游戏辅助!
《欢乐钓鱼大师》是一款融合了休闲娱乐和策略挑战的钓鱼游戏。游戏中的各种鱼类不仅各具特色,而且钓鱼过程充满了挑战和乐趣。下面将为大家详细介绍如何在游戏中钓鱼,以及一些有效的钓鱼技巧,帮助你成为一个出色的钓鱼大师。 实用工具推荐 为…...

什么是构造函数?Java 中构造函数的重载如何实现?
构造函数,就像是建筑房屋时的奠基仪式,是Java类中一个特殊的方法,主要用于初始化新创建的对象。 每当创建一个类的新实例时,构造函数就会自动调用,负责为这个新对象分配内存,并对其进行必要的设置…...

Linux内核 -- ARMv7 与 ARMv8 中的 asmlinkage 作用及使用
ARMv7 与 ARMv8 中的 asmlinkage 作用及使用 asmlinkage 是一个宏,通常在内核代码中使用,用于定义调用约定,特别是指定函数的参数是通过栈传递而不是通过寄存器。它主要用于内核与汇编之间的接口函数,使得参数传递更加一致和明确…...

GPT提示词模板
BRTR 原则 # 背景(Background) - 描述任务的背景信息,包括任务的起因、目的、相关的历史信息或当前状况。 - 提供足够的背景信息以便让ChatGPT理解任务的上下文。 # 角色(Role) - 定义ChatGPT在任务中所扮演的角色&…...
WRF学习——使用CMIP6数据驱动WRF/基于ncl与vdo的CMIP6数据处理
动力降尺度 国际耦合模式比较计划(CMIP)为研究不同情景下的气候变化提供了大量的模拟数据,而在实际研究中,全球气候模式输出的数据空间分辨率往往较低(>100Km,缺乏区域气候特征,为了更好地研…...

机器人控制系列教程之Delta机器人动力学分析
动力学简介 机器人动力学分析是已知各运动构件的尺寸参数和惯性参数的情况下,求解末端运动状态与主驱动力矩之间的函数关系。 意义:对并联机器人动力学分析的意义体现在: 为伺服电机的选型提供理论依据;获得动力学参数为目标函数的最优问题做性能评价指标;为高精度控制提…...

VIM介绍
VIM(Vi IMproved)是一种高度可配置的文本编辑器,用于有效地创建和更改任何类型的文本。它是从 vi 编辑器发展而来的,后者最初是 UNIX 系统上的一个文本编辑器。VIM 以其键盘驱动的界面和强大的文本处理能力而闻名,是许…...
课设:选课管理系统(Java+MySQL)
在本博客中,我将介绍用Java、MySQL、JDBC和Swing GUI开发一个简单的选课管理系统。 技术栈 Java:用于编写应用程序逻辑MySQL:用于存储和管理数据JDBC:用于连接Java应用程序和MySQL数据库Swing GUI:用于构建桌面应用程…...

动态规划 剪绳子问题
给一段长度为n的绳子,请把绳子剪成m段,每段绳子的长度为k[0],k[1],k[2],k[3]....k[m].请问k[0]k[1]k[2].....*k[m]的最大乘积为多少 #include <vector> // 包含vector头文件 #include <algorithm> // 包含algorithm头文件,用于m…...
上位机图像处理和嵌入式模块部署(mcu项目1:实现协议)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 这种mcu的嵌入式模块理论上都是私有协议,因为上位机和下位机都是自己开发的,所以只需要自己保证上、下位机可以通讯上&…...
【NLP学习笔记】load_dataset加载数据
除了常见的load_dataset(<hf上的dataset名>)这种方式加载HF上的所有数据外,还有其他custom的选项。 加载HF上部分数据 from datasets import load_dataset c4_subset load_dataset("allenai/c4", data_files"en/c4-train.0000*-of-01024.js…...

企业如何选择好用的供应商管理系统
供应商管理系统软件(SRM)是企业用于管理供应链中各个供应商关系的重要工具。现如今竞争激烈的市场环境下,选择一款合适的SRM软件显得尤为重要。那么,如何选择一款好用的供应商管理系统呢? 企业在选择好用的供应商管理…...

震惊!运气竟能如此放大!运气的惊人作用,你了解吗?
芒格:得到你想要的东西,最保险的办法,就是让自己配得上你想要的那个东西。今天仔细想了想这句话,他其实说的是无数成功人士的心声 —— “我配得上!” 美剧《绝命毒师》有个导演叫文斯吉里根(Vince Gilliga…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

【RT-DETR实战】070、模型分析工具:PyTorch Profiler性能分析
上周在部署RT-DETR到边缘设备时遇到一个诡异现象:模型推理时延波动极大,有时30ms,偶尔突然跳到200ms。 盯着代码看了半天没发现逻辑问题,数据流也正常。这种时候,靠猜是没用的,必须上性能分析工具——PyTorch Profiler。 今天我们就来聊聊怎么用它揪出那些藏在细节里的…...

GEP协议深度解读:AI智能体自我进化的基因工程
OpenAI 官宣全面支持MCP协议,标志着AI应用架构的"连接标准"已定。如果说MCP是AI时代的USB-C,解决了模型与工具的连接问题,那么GEP(Genome Evolution Protocol,基因组进化协议)则正在解决另一个更本质的问题——智能体的自我进化与生命周期管理。 作为下一代AI基…...

PostgreSQL Merge Join 大白话详解
用生活中最直观的例子,彻底搞懂 Merge Join 是什么、为什么快、什么时候用。一、先从生活场景开始 场景一:两摞乱序试卷找同学 期末考试,老师手里有两摞试卷: A 摞:数学试卷,500 份,乱序堆放B 摞…...

茉莉花插件:如何让中文文献管理效率提升300%
茉莉花插件:如何让中文文献管理效率提升300% 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献的元数据抓…...

如何快速解锁加密音乐文件:3个简单步骤让音乐自由播放
如何快速解锁加密音乐文件:3个简单步骤让音乐自由播放 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https…...

Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑
Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你是否曾经因为复杂的视频编辑软件而头疼?想要一个免费、开源且…...
从主题到视频:Pixelle-Video如何用AI重构你的内容创作流程
从主题到视频:Pixelle-Video如何用AI重构你的内容创作流程 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 想象一下…...

Seraphine:英雄联盟玩家的5大核心功能终极助手,一键提升游戏体验
Seraphine:英雄联盟玩家的5大核心功能终极助手,一键提升游戏体验 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款专为《英雄联盟》玩家设计的智能游戏辅助工具…...