【笔记】字符串相似度代码分享
目录
- 一、算法介绍
- 1、算法
- 1)基于编辑距离
- 2)基于标记
- 3)基于序列
- 4)基于压缩
- 5)基于发音
- 6)简单算法
- 2、安装
- 二、代码demo
- 1、Hamming 距离
- 2、Levenshtein 距离
- 3、Damerau-Levenshtein距离
- 4、Jaro 相似度
- 5、Jaro-Winkler相似度
- 6、Smith–Waterman相似度
- 7、Jaccard 相似度
- 8、Sørensen-Dice 相似度
- 9、Tversky 相似度
- 10、Overlap coefficient相似度
- 11、Cosine similarity相似度
- 12、N-gram相似度
- 13、最长公共子字符串/子序列相似度
- 14、Ratcliff-Obershelp相似度
- 三、效果分析
- 1、中文文本字符串
- 1)效果最好排序
- 2)速度最快排序
- 3)综合排序
- 2、其他
- 1)基于压缩的应用场景
- 2)基于发音的应用场景
- 3)简单算法的应用场景
一、算法介绍
1、算法
1)基于编辑距离
| 算法 | 类 | 函数 |
|---|---|---|
| Hamming | Hamming | hamming |
| MLIPNS | Mlipns | mlipns |
| Levenshtein | Levenshtein | levenshtein |
| Damerau-Levenshtein | DamerauLevenshtein | damerau_levenshtein |
| Jaro-Winkler | JaroWinkler | jaro_winkler, jaro |
| Strcmp95 | StrCmp95 | strcmp95 |
| Needleman-Wunsch | NeedlemanWunsch | needleman_wunsch |
| Gotoh | Gotoh | gotoh |
| Smith-Waterman | SmithWaterman | smith_waterman |
2)基于标记
| 算法 | 类 | 函数 |
|---|---|---|
| Jaccard index | Jaccard | jaccard |
| Sørensen–Dice coefficient | Sorensen | sorensen, sorensen_dice, dice |
| Tversky index | Tversky | tversky |
| Overlap coefficient | Overlap | overlap |
| Tanimoto distance | Tanimoto | tanimoto |
| Cosine similarity | Cosine | cosine |
| Monge-Elkan | MongeElkan | monge_elkan |
| Bag distance | Bag | bag |
3)基于序列
| 算法 | 类 | 函数 |
|---|---|---|
| 最长公共子序列相似度 | LCSSeq | lcsseq |
| 最长公共子串相似度 | LCSStr | lcsstr |
| Ratcliff-Obershelp 相似度 | RatcliffObershelp | ratcliff_obershelp |
4)基于压缩
使用不同压缩算法的归一化压缩距离。
经典压缩算法:
| 算法 | 类 | 函数 |
|---|---|---|
| 算术编码 | ArithNCD | arith_ncd |
| RLE | RLENCD | rle_ncd |
| BWT RLE | BWTRLENCD | bwtrle_ncd |
常见压缩算法:
| 算法 | 类 | 函数 |
|---|---|---|
| 平方根 | SqrtNCD | sqrt_ncd |
| 熵 | EntropyNCD | entropy_ncd |
正在开发的算法,将两个字符串比较为比特数组:
| 算法 | 类 | 函数 |
|---|---|---|
| BZ2 | BZ2NCD | bz2_ncd |
| LZMA | LZMANCD | lzma_ncd |
| ZLib | ZLIBNCD | zlib_ncd |
5)基于发音
| 算法 | 类 | 函数 |
|---|---|---|
| MRA | MRA | mra |
| Editex | Editex | editex |
6)简单算法
| 算法 | 类 | 函数 |
|---|---|---|
| 前缀相似度 | Prefix | prefix |
| 后缀相似度 | Postfix | postfix |
| 长度距离 | Length | length |
| 身份相似度 | Identity | identity |
| 矩阵相似度 | Matrix | matrix |
2、安装
仅纯Python实现:
pip install textdistance
带有额外库以实现最大速度:
pip install "textdistance[extras]"
包含所有库(用于基准测试和测试):
pip install "textdistance[benchmark]"
带有特定算法的额外库:
pip install "textdistance[Hamming]"
提供额外库的算法有:DamerauLevenshtein、Hamming、Jaro、JaroWinkler、Levenshtein。
二、代码demo
1、Hamming 距离
>> import textdistance as td
>> td.hamming('book', 'look')
1
>> td.hamming.normalized_similarity('book', 'look')
0.75
>> td.hamming('bellow', 'below')
3
>> td.hamming.normalized_similarity('Below', 'Bellow')
0.5
在第一个示例中,有一个不同的字符。这使得距离等于1,归一化相似度等于(4-1)/4 = 75%。在第二个示例中,比较“bellow”和“below”,前三个字母相同,但接下来的三个字母不同。因此,距离是3,归一化相似度是(6-3)/6 = 50%。
2、Levenshtein 距离
>> td.levenshtein('book', 'look')
1
>> td.levenshtein.normalized_similarity('book', 'look')
0.75
>> td.levenshtein('bellow', 'below')
1
>> td.levenshtein.normalized_similarity('Below', 'Bellow')
0.84
在第一个示例中,可以通过替换一个字母来得到另一个单词,因此归一化相似度是(4-1)/4 = 75%。在第二个示例中,有一个插入操作,因此距离是1,归一化相似度是(6-1)/6 = 84%。
3、Damerau-Levenshtein距离
>> td.levenshtein('act', 'cat')
2
>> td.levenshtein.normalized_similarity('act', 'cat')
0.34
>> td.damerau_levenshtein('act', 'cat')
1
>> td.damerau_levenshtein.normalized_similarity('act', 'cat')
0.67
Damerau-Levenshtein距离是Levenshtein 距离的一个变种,应用广泛,如拼写检查和序列分析
4、Jaro 相似度
>> td.jaro('bellow', 'below')
0.94
>> td.jaro('simple', 'plesim')
0
>> td.jaro('jaro', 'ajro')
0.92
在第一个示例中,有5个匹配字符和一个插入(这不是置换操作),因此Jaro 相似度为1/3*(5/6+5/5+6/6)。在第二个示例中,有0个匹配字符,因为共同字符不在max(|s1|, |s2|)/2-1的范围内。这就是为什么相似度为0的原因。在最后一个示例中,有4个匹配字符和第一和第二字母之间的1个置换操作,因此相似度为1/3 * (4/4+4/4+3/4) = 0.91。
5、Jaro-Winkler相似度
>> td.jaro("simple", "since")
0.7
>> t.jaro_winkler("simple", "since")
0.76
由于两个字符串有两个共同的前缀字母。Jaro-Winkler相似度大于Jaro相似度:0.7 + 0.12(1–0.7) = 0.7 + 0.06 = 0.76。
6、Smith–Waterman相似度
>> td.smith_waterman("GATTACA", "GCATGCU")
3
>> td.smith_waterman("GATTACA", "GCATGCU")
0.43
Smith–Waterman算法在生物信息学中特别有用,用于识别生物序列中的相似区域或基序
7、Jaccard 相似度
>> td.jaccard('jaccard similarity'.split(), "similarity jaccard".split())
1
>> td.jaccard('jaccard similarity'.split(), "similarity jaccard jaccard".split())
0.66
类似交并比(Intersection of Union,IoU),对比时并不考虑字符串单词的顺序
8、Sørensen-Dice 相似度
>> td.sorencen('jaccard similarity'.split(), "similarity jaccard".split())
1
>> td.sorencen('jaccard similarity'.split(), "similarity jaccard jaccard".split())
0.8
与前者相比,不考虑重复元素
9、Tversky 相似度
>> td.sorencen('tversky similarity'.split(), "similarity tversky tversky".split())
0.8
>> tversky = td.Tversky(ks=(0.5, 0.5))
>> tversky('tversky similarity'.split(), "similarity tversky tversky".split())
0.8
>> td.jaccard('tversky similarity'.split(), "similarity tversky tversky".split())
0.67
>> tversky = td.Tversky(ks=(1, 1))
>> tversky('tversky similarity'.split(), "similarity tversky tversky".split())
0.67
>> tversky = td.Tversky(ks=(0.2, 0.8))
>> tversky('tversky similarity'.split(), "similarity tversky tversky".split())
0.74
10、Overlap coefficient相似度
>> td.overlap('overlap similarity'.split(), "similarity overlap overlap".split())
1.0
计算集合交集大小与较小集合大小的比例
11、Cosine similarity相似度
>> td.cosine('cosine'.split(), "similarity".split())
0
>> td.cosine('cosine sim'.split(), "cosine sim sim".split())
0.81
12、N-gram相似度
N-gram 相似度是一种基于字符串中连续N个字符的相似度度量方法。它通过将字符串拆分为N-gram(N个连续字符的子串),然后比较这些N-gram的集合来计算两个字符串之间的相似度。下面是用 Python 实现 N-gram 相似度的代码示例:
def ngrams(string, n):"""将字符串拆分为N-gram"""return [string[i:i+n] for i in range(len(string)-n+1)]def ngram_similarity(str1, str2, n):"""计算两个字符串的N-gram相似度"""ngrams1 = set(ngrams(str1, n))ngrams2 = set(ngrams(str2, n))intersection = ngrams1.intersection(ngrams2)union = ngrams1.union(ngrams2)return len(intersection) / len(union) if union else 0.0# 示例
str1 = "hello"
str2 = "hallo"
n = 2similarity = ngram_similarity(str1, str2, n)
print(f"{n}-gram 相似度: {similarity:.2f}")
# 2-gram 相似度: 0.33
13、最长公共子字符串/子序列相似度
>> s1, s2 = "RO PATTERN MATCHING", "RO PRACTICE"
>> td.lcsstr(s1, s2), td.lcsseq(s2, s1), td.lcsseq(s2, s1)('RO P', 'RO PRATC', 'RO PRACI')
>> td.lcsstr.normalized_similarity(s1, s2), td.lcsseq.normalized_similarity(s1, s2)(0.21, 0.42)
最长公共子字符串专注于找出两个字符串之间的最长公共子字符串,它通过识别两个字符串共享的最长连续字符序列来衡量字符串之间的相似度
子序列不要求在原始序列中占据连续位置。因此,最长公共子序列总是大于最长公共子字符串
14、Ratcliff-Obershelp相似度
>> s1, s2 = "RO PATTERN MATCHING", "RO PRACTICE"
>> td.ratcliff_obershelp(s1, s2), td.ratcliff_obershelp(s2, s1), len(s1), len(s2)
(0.46, 0.53, 19, 11)
三、效果分析
1、中文文本字符串
在对中文文本字符串进行相似度比较时,效果和速度各有不同的算法可供选择。以下是根据效果最好和速度最快分别排序的算法:
1)效果最好排序
- Levenshtein:计算编辑距离,考虑到中文字符的插入、删除和替换,效果较好。
- Damerau-Levenshtein:比Levenshtein更进一步,考虑到字符的交换,能更准确地反映一些错别字的相似性。
- Jaro-Winkler:考虑字符的匹配和位移,对拼音和形近字有较好的识别效果。
- Needleman-Wunsch:常用于序列比对,适合处理长文本,但速度较慢。
- Smith-Waterman:和Needleman-Wunsch类似,但更精细,适合局部相似性比对。
- Cosine similarity:基于向量空间模型,适合处理词语或短句相似度,但需要预处理成向量表示。
- Jaccard index:基于集合的相似度计算,适合分词后的文本比较。
2)速度最快排序
- Hamming:适合固定长度的字符串比较,速度极快,但只能比较长度相同的字符串。
- Jaccard index:基于集合操作,速度较快,尤其是在分词后的文本上。
- Cosine similarity:向量化处理后计算余弦相似度,速度较快,但依赖预处理。
- Jaro-Winkler:速度相对较快,适合短文本比较。
- Levenshtein:虽然是动态规划算法,但优化后速度也较快,适合中短文本比较。
- Damerau-Levenshtein:考虑交换操作,稍慢于Levenshtein,但仍然较快。
- Smith-Waterman:局部比对,速度较慢,适合较短文本。
- Needleman-Wunsch:全局比对,速度慢,适合处理长文本。
3)综合排序
结合效果和速度,以下是综合排序:
- Levenshtein:综合效果和速度,适合大多数情况。
- Damerau-Levenshtein:效果好于Levenshtein,速度稍慢,但仍然适用。
- Jaro-Winkler:适合拼音和形近字,速度较快。
- Cosine similarity:需要预处理,但在向量化后速度较快,效果也不错。
- Jaccard index:适合分词后的文本比较,速度快。
- Needleman-Wunsch:适合长文本,效果好但速度慢。
- Smith-Waterman:适合局部相似性比较,效果好但速度最慢。
选择具体算法时,可以根据文本的长度、预处理的复杂度以及对效果的要求来综合考虑。
英文文本也适用
2、其他
1)基于压缩的应用场景
基于压缩的算法主要用于处理和比较大规模或复杂的数据集,因为它们能够有效地压缩和分析数据。这些算法常用于以下场景:
- 大数据分析:在需要处理和比较大量文本数据的场景中,如日志文件、网络爬虫数据等。
- 数据压缩和传输:在需要高效压缩和传输数据的应用中,这些算法可以用于优化数据存储和传输效率。
- 文本和字符串匹配:用于需要在大文本库中查找相似文本或字符串的场景。
2)基于发音的应用场景
基于发音的算法主要用于处理语音和文本的相似性计算,这在以下场景中尤为有用:
- 语音识别和处理:在语音识别系统中,用于比较和识别发音相似的词汇。
- 拼写纠正:在文本输入系统中,根据发音相似性来纠正拼写错误。
- 名称匹配:用于比较和匹配发音相似的人名、地名等,如客户关系管理系统中匹配相似的客户名字。
3)简单算法的应用场景
简单算法通常用于需要快速、直接比较的场景,这些场景不需要复杂的计算或大量数据处理:
- 前缀和后缀匹配:用于文件名或路径的匹配和分类,如查找特定前缀或后缀的文件。
- 长度比较:用于需要比较字符串长度的场景,如数据验证和清理。
- 身份相似度:用于简单的字符串相等性比较,如用户输入的验证码验证。
- 矩阵相似度:用于矩阵数据的比较,如图像处理中的像素矩阵比较。
相关文章:

【笔记】字符串相似度代码分享
目录 一、算法介绍1、算法1)基于编辑距离2)基于标记3)基于序列4)基于压缩5)基于发音6)简单算法 2、安装 二、代码demo1、Hamming 距离2、Levenshtein 距离3、Damerau-Levenshtein距离4、Jaro 相似度5、Jaro…...
AI墓地:738个倒闭AI项目的启示
近年来,人工智能技术迅猛发展,然而,不少AI项目却在市场上悄然消失。根据AI工具聚合网站“DANG”的统计,截至2024年6月,共有738个AI项目停运或停止维护。本文将探讨这些AI项目失败的原因,并分析当前AI初创企…...

工程文件参考——CubeMX+LL库+SPI主机 阻塞式通用库
文章目录 前言CubeMX配置SPI驱动实现spi_driver.hspi_driver.c 额外的接口补充 前言 SPI,想了很久没想明白其DMA或者IT比较好用的方法,可能之后也会写一个 我个人使用场景大数据流不多,如果是大批量数据交互自然是DMA更好用,但考…...

LLM - 模型历史
...

Go语言中的时间与日期处理:time包详解
在Go语言中,time包提供了丰富而强大的功能来处理时间和日期,这对于构建精确计时、定时任务、日期格式化等应用场景至关重要。本文将深入浅出地探讨time包的核心概念、常见问题、易错点及其规避策略,并通过实用代码示例加深理解。 一、时间与…...

Java实现单点登录(SSO)详解:从理论到实践
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 ✨✨ 帅哥美女们,我们共同加油!一起进步&am…...

【leetcode82-91动态规划,91-95多维动态规划】
动态规划【82-91】 多维动态规划【91-95】...

Django学习第四天
启动项目命令 python manage.py runserver 分页功能封装到类中去 封装的类的代码 """ 自定义的分页组件,以后如果想要使用这个分页组件,你需要做: def pretty_list(request):# 靓号列表data_dict {}search_data request.GET.get(q, &…...

redis-benchmark 使用
Redis 自带了一个叫 redis-benchmark 的工具来模拟 N 个客户端同时发出 M 个请求。 Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests>] [-k <boolean>]-h <hostname> Server hostname (default 127.0…...

什么是 qobject_cast?
前言 在 C++ 中,类型转换是一项常见的操作,比如将 int 转换为 char 或将 QString 用于 QMessageBox。但是,为什么我们需要将一个类转换为另一个类呢?本文将解释 qobject_cast 是什么,它的作用以及为什么需要类型转换。 dynamic_cast 和 qobject_cast 的概述 什么是 dyn…...

Python酷库之旅-第三方库Pandas(001)
目录 一、Pandas库的由来 1、背景与起源 1-1、开发背景 1-2、起源时间 2、名称由来 3、发展历程 4、功能与特点 4-1、数据结构 4-2、数据处理能力 5、影响与地位 5-1、数据分析“三剑客”之一 5-2、社区支持 二、Pandas库的应用场景 1、数据分析 2、数据清洗 3…...
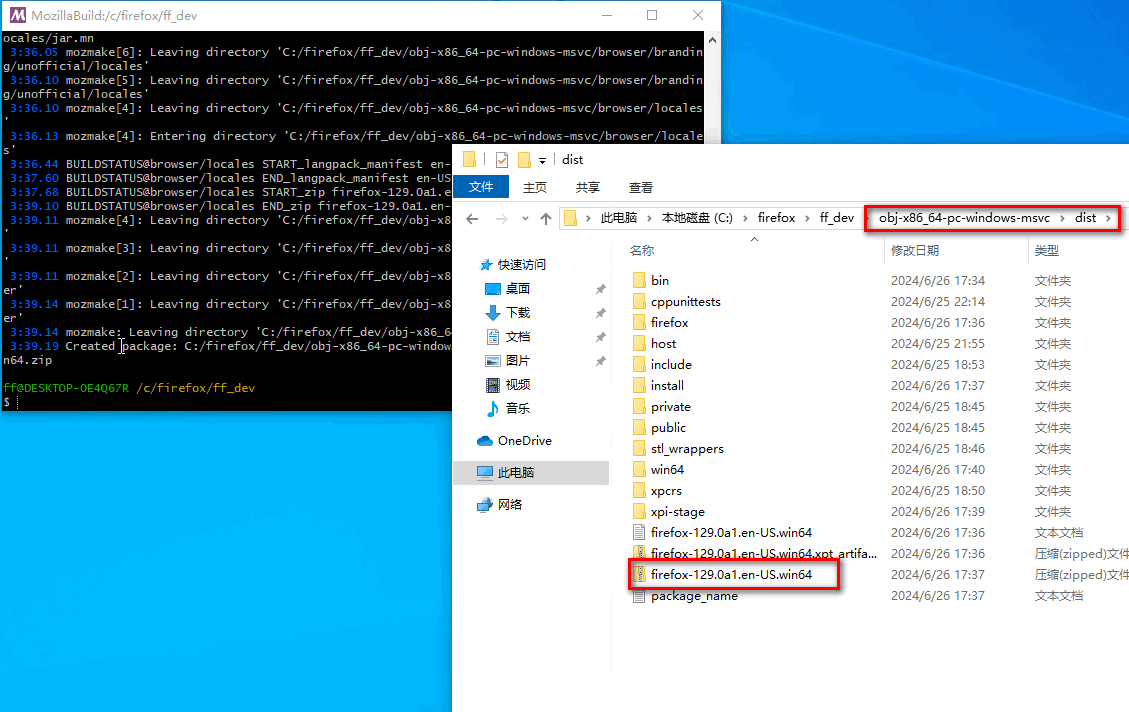
Firefox 编译指南2024 Windows10篇- 编译Firefox(三)
1.引言 在成功获取了Firefox源码之后,下一步就是将这些源码编译成一个可执行的浏览器。编译是开发流程中的关键环节,通过编译,我们可以将源代码转换为可执行的程序,测试其功能,并进行必要的优化和调试。 对于像Firef…...

CSS弹性布局:打造响应式与灵活的网页设计
一、弹性布局是什么? 弹性布局(Flexbox)是一种CSS布局模型,它提供了一种更加高效的方式来对容器中的项目进行布局、对齐和分配空间。与传统的布局方式相比,Flexbox旨在提供一个更加灵活的方式来布局复杂的网页结构&am…...

【高阶数据结构】图的应用--最短路径算法
文章目录 一、最短路径二、单源最短路径--Dijkstra算法三、单源最短路径--Bellman-Ford算法四、多源最短路径--Floyd-Warshall算法 一、最短路径 最短路径问题:从在带权有向图G中的某一顶点出发,找出一条通往另一顶点的最短路径,最短也就是沿…...

腾讯云函数node.js返回自动带反斜杠
云函数返回自动带反斜杠 这里建立了如下一个云函数,目的是当APP过来请求的时候响应支持的版本号: use strict; function main_ret(status,code){let ret {status: status,error: code};return JSON.stringify(ret); } exports.main_handler async (event, context) > {/…...

大模型知识学习
大模型训练过程 数据清洗 拟人化描述:知识库整理 预训练 拟人化描述:知识学习可以使用基于BERT预训练模型进行训练 指令微调 拟人化描述:实际工作技能学习实际操作:让大模型模仿具体的输入输出进行拟合,即模仿学…...

JAVA声明数组
一、声明并初始化数组 直接初始化:在声明数组的同时为其分配空间并初始化元素。 int[] numbers {1, 2, 3, 4, 5}; 动态初始化:先声明数组,再为每个元素分配初始值。 double[] decimals;decimals new double[5]; // 分配空间,但…...

VBA通过Range对象实现Excel的数据写入
前言 本节会介绍通过VBA中的Range对象,来实现Excel表格中的单元格写入、区域范围写入,当然也可以写入不同类型的数据,如数值、文本、公式,以及实现公式下拉自动填充的功能。 一、单元格输入数据 1.通过Value方法实现输入不同类型…...

记录OSPF配置,建立邻居失败的过程
1.配置完ospf后,在路由表中不出现ospf相关信息 [SW2]ospf [SW2-ospf-1]are [SW2-ospf-1]area 0 [SW2-ospf-1-area-0.0.0.0]net [SW2-ospf-1-area-0.0.0.0]network 0.0.0.0 Jul 4 2024 22:11:58-08:00 SW2 DS/4/DATASYNC_CFGCHANGE:OID 1.3.6.1.4.1.2011.5.25 .1…...
算法体系-25 第二十五节:窗口内最大值或最小值的更新结构
一 滑动窗口设计知识点 滑动窗口是什么? 滑动窗口是一种想象出来的数据结构: 滑动窗口有左边界L和有边界R 在数组或者字符串或者一个序列上,记为S,窗口就是S[L..R]这一部分 L往右滑意味着一个样本出了窗口,R往右滑意味…...

3步精通WaveTools:鸣潮全场景性能优化终极指南
3步精通WaveTools:鸣潮全场景性能优化终极指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 开源优化工具WaveTools作为《鸣潮》玩家必备的性能调校助手,通过深度配置优化实现画质…...

BurpSuite+SqlMap深度集成:构建高可信SQL注入检测流水线
1. 这不是“点几下就出结果”的玩具,而是你真正能放进渗透流程里的SQL注入检测流水线很多人第一次看到“BurpSuiteSqlMap插件5分钟搞定SQL注入检测”这个标题,第一反应是:又一个标题党?点开全是截图堆砌、参数照抄、报错就卡住的半…...

终极指南:如何在macOS上使用eqMac专业音频均衡器提升音质体验
终极指南:如何在macOS上使用eqMac专业音频均衡器提升音质体验 【免费下载链接】eqMac macOS System-wide Audio Equalizer & Volume Mixer 🎧 项目地址: https://gitcode.com/gh_mirrors/eq/eqMac 你是否厌倦了macOS系统单调的音频效果&#…...

量子机器学习:平衡数据复杂度与电路表达力的核心策略
1. 项目概述:量子机器学习中的核心平衡艺术在量子机器学习这个前沿交叉领域摸爬滚打了几年,我越来越深刻地意识到,决定一个模型成败的,往往不是最炫酷的量子门设计,而是一个看似基础却极易被忽视的平衡问题:…...

Beyond Compare 5完整激活教程:3种方法快速生成永久授权密钥
Beyond Compare 5完整激活教程:3种方法快速生成永久授权密钥 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 还在为Beyond Compare 5的30天试用期结束后无法继续使用而烦恼吗&#x…...

三步制作多系统启动盘:Ventoy完全指南告别重复格式化
三步制作多系统启动盘:Ventoy完全指南告别重复格式化 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 你是否还在为每个系统镜像单独制作启动盘而烦恼?是否因为U盘容量充足却只能…...

Propius:面向协同机器学习的异构边缘资源管理平台架构解析
1. 项目概述:当协同机器学习遇上异构边缘资源在分布式机器学习领域,尤其是联邦学习(Federated Learning)这类强调数据隐私的范式,我们常常面临一个核心矛盾:一方面,我们希望利用海量、异构的边缘…...

Seraphine:英雄联盟玩家的智能游戏助手完整指南
Seraphine:英雄联盟玩家的智能游戏助手完整指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款基于英雄联盟官方LCU API开发的智能游戏助手,专为《英雄联盟》玩家设计…...

Frida与objection版本兼容性原理及多版本隔离实战
1. 为什么你装了objection却跑不起来Frida脚本?——版本混乱的真实代价“明明pip install objection装好了,frida-ps -U能看见设备,但objection explore一执行就报错:frida.InvalidOperationError: unable to find suitable world…...

Unity局域网画面同步方案:FMETP STREAM低延迟多终端投射实战
1. 这不是“又一个网络同步教程”,而是解决真实产线卡点的局域网画面投射方案我第一次在客户现场看到这个需求时,是在一家做工业AR巡检系统的公司。他们刚部署完一批HoloLens 2和iPad,准备给产线工人做实时设备状态叠加显示——但问题来了&am…...