Generative Modeling by Estimating Gradients of the Data Distribution
Generative Modeling by Estimating Gradients of the Data Distribution
本文介绍宋飏提出的带噪声扰动的基于得分的生成模型。首先介绍基本的基于得分的生成模型的训练方法(得分匹配)和采样方法(朗之万动力学)。然后基于流形假设,分析了现有方法面临的低密度区域得分估计不准、标准朗之万动力学采样对于多 pattern 分布混合慢的问题。最后提出解决方法,使用多种等级的噪声对数据分布进行扰动,从而使得在低密度区域有更多的训练信号;并提出退火的朗之万动力学采样方法,基于一个噪声条件模型,在不同等级噪声扰动分布上进行采样,最终采样出数据样本。
一、背景知识:Score-based generative modeling
生成模型就是使用数据集来训练一个模型从 p data ( x ) p_\text{data}(\mathbf{x}) pdata(x) 中生成新的样本。假设有从未知的数据分布 p data ( x ) p_\text{data}(\mathbf{x}) pdata(x) 中 iid 采样的数据集 { x i ∈ R D } i = 1 N \{\mathbf{x}_i\in\mathbb{R}^D\}_{i=1}^N {xi∈RD}i=1N。我们定义分布 p ( x ) p(\mathbf{x}) p(x) 的分数 score 为其概率密度对数的梯度,即 ∇ x log p ( x ) \nabla_\mathbf{x}\log p(\mathbf{x}) ∇xlogp(x)。得分网络 s θ : R D → R D \mathbf{s_\theta}:\ \mathbb{R}^D\rightarrow\mathbb{R}^D sθ: RD→RD 是一个参数化网络,用于估计 p data ( x ) p_\text{data}(\mathbf{x}) pdata(x) 的分数。score-based 生成模型有两个关键部分:得分匹配(score matching),和朗之万动力学(Langevin dynamics),分别对应训练过程和采样生成过程。score matching 用来训练一个神经网络估计数据分布的得分,而朗之万动力学则能够根据分布的得分来进行采样。以下分别进行介绍。
1 score matching for score estimation
score matching 最初是用于基于未知分布的样本点来训练非归一化统计模型(non-normalized statistical model)。之前已经开始有研究将其用于得分估计,本文也是这样做。使用 score matching,我们无需知道数据分布 p data ( x ) p_\text{data}(\mathbf{x}) pdata(x) 本身,而是可以直接训练一个得分网络 s θ ( x ) \mathbf{s_\theta(x)} sθ(x) 来估计数据分布的得分 ∇ x log p data ( x ) \nabla_\mathbf{x}\log p_\text{data}(\mathbf{x}) ∇xlogpdata(x)。
score matching 的目标函数:
1 2 E p data ( x ) [ ∣ ∣ s θ ( x ) − ∇ x log p data ( x ) ∣ ∣ 2 2 ] \frac{1}{2}\mathbb{E}_{p_\text{data}(\mathbf{x})}[||\mathbf{s_\theta}(\mathbf{x})-\nabla_\mathbf{x}\log p_\text{data}(\mathbf{x})||_2^2] 21Epdata(x)[∣∣sθ(x)−∇xlogpdata(x)∣∣22]
可以等价(至多差一个常数)为:
E p data ( x ) [ tr ( ∇ x s θ ( x ) ) + 1 2 ∣ ∣ s θ ( x ) ∣ ∣ 2 2 ] \mathbb{E}_{p_\text{data}(\mathbf{x})}[\text{tr}(\nabla_\mathbf{x}\mathbf{s_\theta}(\mathbf{x}))+\frac{1}{2}||\mathbf{s}_\theta(\mathbf{x})||^2_2] Epdata(x)[tr(∇xsθ(x))+21∣∣sθ(x)∣∣22]
其中 ∇ x s θ ( x ) \nabla_\mathbf{x}\mathbf{s_\theta}(\mathbf{x}) ∇xsθ(x) 表示 s θ ( x ) \mathbf{s_\theta}(\mathbf{x}) sθ(x) 的雅可比矩阵。已有研究工作显示,在一定条件下,方程(3)的最小化解(记作 s θ ∗ ( x ) \mathbf{s_{\theta^*}}(\mathbf{x}) sθ∗(x))也能满足 s θ ∗ ( x ) = ∇ x log p data ( x ) \mathbf{s_{\theta^*}}(\mathbf{x})=\nabla_\mathbf{x}\log p_\text{data}(\mathbf{x}) sθ∗(x)=∇xlogpdata(x)。实际中,可以使用数据样本快速估计上式对 p data ( x ) p_\text{data}(\mathbf{x}) pdata(x) 的期望,但由于迹 tr ( ∇ x s θ ( x ) ) \text{tr}(\nabla_\mathbf{x}\mathbf{s_\theta}(\mathbf{x})) tr(∇xsθ(x)) 的计算复杂度太高,因此得分匹配并不适合直接用深层网络和高维数据训练。下面我们将讨论两种常见的大规模得分匹配的计算方法。
denoising score matching
denoising score matching 是 score matching 的一种变体,它完全绕过了对迹的计算。denoising score matching 中,首先使用预定义的噪声分布 q σ ( x ~ ∣ x ) q_\sigma(\tilde{\mathbf{x}}|\mathbf{x}) qσ(x~∣x) 对数据点 x \mathbf{x} x 进行扰动,然后使用 score matching 估计扰动后的分布,即 q σ ( x ) = △ ∫ q σ ( x ~ ∣ x ) p data ( x ) d x q_\sigma(\mathbf{x})\stackrel{\triangle}{=}\int q_\sigma(\tilde{\mathbf{x}}|\mathbf{x})p_\text{data}(\mathbf{x})d\mathbf{x} qσ(x)=△∫qσ(x~∣x)pdata(x)dx ,的分数。这个目标函数为:
1 2 E q σ ( x ~ ∣ x ) p data ( x ) [ ∣ ∣ s θ ( x ~ ) − ∇ x log q σ ( x ~ ∣ x ) ∣ ∣ 2 2 ) ] \frac{1}{2}\mathbb{E}_{q_\sigma(\tilde{\mathbf{x}}|\mathbf{x})p_\text{data}(\mathbf{x})}[||\mathbf{s_\theta}(\tilde{\mathbf{x}})-\nabla_\mathbf{x}\log q_\sigma(\tilde{\mathbf{x}}|\mathbf{x})||_2^2)] 21Eqσ(x~∣x)pdata(x)[∣∣sθ(x~)−∇xlogqσ(x~∣x)∣∣22)]
已有研究证明,最小化上式的最优解 s θ ∗ ( x ) \mathbf{s_{\theta^*}}(\mathbf{x}) sθ∗(x) 也能满足 s θ ∗ ( x ) = ∇ x log q σ ( x ) \mathbf{s_{\theta^*}}(\mathbf{x})=\nabla_\mathbf{x}\log q_\sigma(\mathbf{x}) sθ∗(x)=∇xlogqσ(x)。但是注意,只有在噪声很小的时候,扰动后的分布才约等于数据分布。在生成时,当 q σ ( x ) ≈ p data ( x ) q_\sigma(\mathbf{x})\approx p_\text{data}(\mathbf{x}) qσ(x)≈pdata(x) 才能使用噪声扰动分布的得分近似当做真实数据分布的得分。
siliced score matching
sliced score matching 使用一个随机映射来对 score matching 中迹 tr ( ∇ x s θ ( x ) ) \text{tr}(\nabla_\mathbf{x}\mathbf{s_\theta}(\mathbf{x})) tr(∇xsθ(x)) 的计算进行近似。目标函数是:
E p v E p data [ v T ∇ x s θ ( x ) v + 1 2 ∣ ∣ s θ ( x ) ∣ ∣ 2 2 ] \mathbb{E}_{p_\mathbf{v}}\mathbb{E}_{p_\text{data}}[\mathbf{v}^T\nabla_\mathbf{x}\mathbf{s_\theta}(\mathbf{x})\mathbf{v}+\frac{1}{2}||\mathbf{s_\theta}(\mathbf{x})||_2^2] EpvEpdata[vT∇xsθ(x)v+21∣∣sθ(x)∣∣22]
其中 p v p_\mathbf{v} pv 是一个简单的随机向量分布(如多元高斯分布)。 v T ∇ x s θ ( x ) v \mathbf{v}^T\nabla_\mathbf{x}\mathbf{s_\theta}(\mathbf{x})\mathbf{v} vT∇xsθ(x)v 这一项可以由自动微分框架的前向模式进行高效地计算。不同于 denoising score matching 估计的是扰动后分布的分数,sliced score matching 估计的是未扰动的原始数据的分布,但这会带来大概四倍的额外计算量。
2 sampling with Langevin dynamics
朗之万动力学可以在仅知道分布的得分函数 ∇ x log p ( x ) \nabla_\mathbf{x}\log p(\mathbf{x}) ∇xlogp(x) 的情况下,采样出分布 p ( x ) p(\mathbf{x}) p(x) 的样本点。具体来说,给定固定的步长 ϵ > 0 \epsilon>0 ϵ>0 和一个先验分布中采样的初始值 x ~ ∼ π ( x ) \tilde{\mathbf{x}}\sim\pi\mathbf({x}) x~∼π(x) ,朗之万迭代进行如下计算:
x ~ t = x ~ t − 1 + ϵ 2 ∇ x log p ( x ~ t − 1 ) + ϵ z t \tilde{\mathbf{x}}_t=\tilde{\mathbf{x}}_{t-1}+\frac{\epsilon}{2}\nabla_\mathbf{x}\log p(\tilde{\mathbf{x}}_{t-1})+\sqrt{\epsilon}\mathbf{z}_t x~t=x~t−1+2ϵ∇xlogp(x~t−1)+ϵzt
其中 z t ∼ N ( 0 , I ) \mathbf{z}_t\sim\mathcal{N}(0,\mathbf{I}) zt∼N(0,I)。当 ϵ → 0 , T → ∞ \epsilon\rightarrow 0,T\rightarrow\infty ϵ→0,T→∞ 时, x ~ T \tilde{\mathbf{x}}_T x~T 的分布等于 p ( x ) p(\mathbf{x}) p(x),此时(在一定条件下) x ~ T \tilde{\mathbf{x}}_T x~T 就相当于是从分布 p ( x ) p(\mathbf{x}) p(x) 中采样出的一个样本点了。严格来说,在中间步,即 ϵ > 0 , T < ∞ \epsilon>0,T<\infty ϵ>0,T<∞ 时,需要使用 Metropolis-Hastings 更新来修正上式的误差。但在实际中,这个误差经常是忽略的,本文也假设在 ϵ \epsilon ϵ 足够小, T T T 足够大的条件下,该误差可以忽略。
在上述采样公式中,可以看到,朗之万动力学只需要知道得分函数 ∇ x log p ( x ) \nabla_\mathbf{x}\log p(\mathbf{x}) ∇xlogp(x) 就可以进行采样生成了。因此,要采样得到数据分布 p data ( x ) p_\text{data}(\mathbf{x}) pdata(x) 的样本,我们只需有一个得分网络能估计数据分布的得分 s θ ( x ) ≈ ∇ x log p data ( x ) \mathbf{s_\theta}(\mathbf{x})\approx\nabla_\mathbf{x}\log p_\text{data}(\mathbf{x}) sθ(x)≈∇xlogpdata(x),然后就可以根据朗之万动力学,使用 s θ ( x ) \mathbf{s_\theta}(\mathbf{x}) sθ(x) 进行采样就行了。这就是基于得分的生成模型(score-based generative modeling)的核心思路。
二、面临挑战:challenges of score-based model generative modeling
以上介绍了 score-based generative modeling 的基本思想与做法,但实际中,这种生成模型也存在着几个问题,导致实际中应用还不广泛。本节将介绍并分析 score-based generative modeling 所面临的难点。
1 the manifold hypothesis
流形假设认为,现实世界中的数据大都集中在嵌入在高维空间中的低维流形上(换句话说,尽管数据可能存在于一个高维空间,但数据点实际上只在一个低维的子空间(流形)上)。该假设是流形学习的基石,在许多数据集上都能得到验证。在流形假设下,score-based generative models 面临着两个问题。首先,得分 ∇ x log p data ( x ) \nabla_\mathbf{x}\log p_\text{data}(\mathbf{x}) ∇xlogpdata(x) 是高维空间分布的数据梯度,而当数据点 x \mathbf{x} x 只分布在低维流形上时,该梯度是未定义的;第二,score matching 的目标函数只有在数据分布充满整个空间中时,得分估计器才是准确的,当数据点只分布在低维流形上时,是不准确的。
数据分布在低维流形上,这对分数估计的影响可以在下图 sliced score matching 在 CIFAR10 训练过程的 ssm loss 曲线中看出。左侧是直接在 CIFAR10 原图上进行训练,可以看到,loss 曲线明显是震荡的,非常不稳定,难以收敛;而右侧是在原图上叠加了很小幅度 N ( 0 , 0.0001 ) \mathcal{N}(0,0.0001) N(0,0.0001) 的高斯噪声,这个噪声幅度人眼几乎看不出来,但是却显著稳定了训练进行,loss 曲线可以收敛。

2 low data density regions
数据点在低密度区域的分布太少,会对 score-based generative models 中 score matching 训练出的噪声估计器的精确度和朗之万动力学的 MCMC 采样过程噪声带来困难。以下分别探讨数据低密度区域对 score matching 训练和朗之万动力学采样造成的影响。
2.1 inaccurate score estimation with score matching
在低数据密度区域,由于数据稀缺,score mathcing 没有足够的参考依据来准确地估计得分。score matching 的目标是最小化得分估计的平均误差,即 1 2 E p data [ ∣ ∣ s θ ( x ) − ∇ x log p data ( x ) ∣ ∣ 2 2 ] \frac{1}{2}\mathbb{E}_{p_\text{data}}[||\mathbf{s_\theta}(\mathbf{x})-\nabla_\mathbf{x}\log p_\text{data}(\mathbf{x})||_2^2] 21Epdata[∣∣sθ(x)−∇xlogpdata(x)∣∣22]。在实际中,关于数据分布的期望是通过对数据分布的独立同分布采样 { x i } i = 1 N ∼ i.i.d p data ( x ) \{\mathbf{x}_i\}_{i=1}^N\stackrel{\text{i.i.d}}{\sim}p_\text{data}(\mathbf{x}) {xi}i=1N∼i.i.dpdata(x)。对任意区域 R ⊂ R D \mathcal{R}\sub \mathbb{R}^{D} R⊂RD,有 p data ( R ) ≈ 0 p_\text{data}(\mathcal{R})\approx 0 pdata(R)≈0。在大多数情况下,有 { x i } i = 1 N ∩ R = ∅ \{\mathbf{x}_{i}\}_{i=1}^N\cap \mathcal{R}=\empty {xi}i=1N∩R=∅,对于该区域中 score matching 没有足够的样本来准确地估计得分。
下图通过一个简易的实验验证了这一点,该实验中,作者用 sliced score matching 来拟合一个简单的数据分布 p data = 1 5 N ( ( − 5 , 5 ) , I ) + 4 5 N ( ( 5 , 5 ) , I ) p_\text{data}=\frac{1}{5}\mathcal{N}((-5,5),\mathbf{I})+\frac{4}{5}\mathcal{N}((5,5),\mathbf{I}) pdata=51N((−5,5),I)+54N((5,5),I),下图左侧是数据分布真实的得分 ∇ x log p data ( x ) \nabla_\mathbf{x}\log p_\text{data}(\mathbf{x}) ∇xlogpdata(x),右侧是模型估计的得分 s θ \mathbf{s_\theta} sθ。可以看到(看箭头),只有在数据密集的区域,得分估计才是准确的。

2.2 slow mixing of Langevin dynamics
当数据分布的两个 pattern 被低密度区域分隔开时,朗之万动力学对两个 pattern 的相对权重的预测很慢,从而很难使得采样结果收敛到真实分布。
考虑一个混合分布 p data ( x ) = π p 1 ( x ) + ( 1 − π ) p 2 ( x ) p_{\text{data}}(\mathbf{x}) = \pi p_1(\mathbf{x}) + (1 - \pi) p_2(\mathbf{x}) pdata(x)=πp1(x)+(1−π)p2(x),其中 p 1 ( x ) p_1(\mathbf{x}) p1(x) 和 p 2 ( x ) p_2(\mathbf{x}) p2(x) 是分布区域不相交的归一化分布, π ∈ ( 0 , 1 ) \pi \in (0, 1) π∈(0,1)。在 p 1 ( x ) p_1(\mathbf{x}) p1(x) 的分布区域内,有 $\nabla_x \log p_{\text{data}}(x) = \nabla_x(\log \pi + \log p_1(x)) = \nabla_x \log p_1(x) $,同理在 p 2 ( x ) p_2(\mathbf{x}) p2(x) 的分布区域内,有 ∇ x log p data ( x ) = ∇ x ( log ( 1 − π ) + log p 2 ( x ) ) = ∇ x log p 2 ( x ) \nabla_x \log p_{\text{data}}(\mathbf{x}) = \nabla_x(\log(1 - \pi) + \log p_2(\mathbf{x})) = \nabla_x \log p_2(\mathbf{x}) ∇xlogpdata(x)=∇x(log(1−π)+logp2(x))=∇xlogp2(x)。也就是说,在这两种情况下,得分 ∇ x log p data ( x ) \nabla_x \log p_{\text{data}}(\mathbf{x}) ∇xlogpdata(x) 都与 π \pi π 无关。朗之万动力学使用 ∇ x log p data ( x ) \nabla_x \log p_{\text{data}}(\mathbf{x}) ∇xlogpdata(x) 来从 p data ( x ) p_{\text{data}}(\mathbf{x}) pdata(x) 中采样,所得到的样本将不依赖于权重系数 π \pi π。在实际中,虽然不同的 pattern 可能存在一定的相交分布区域,这部分相交区域的数据密度很低,因此结论是类似的,在这种情况下,理论上朗之万动力学还是可以生成正确的样本,但可能需要非常小的步长、非常大的步数。
为了验证这一分析,作者使用了与上节相同的简单数据分布进行了朗之万动力学采样实验,结果如下图。图中 (a)、(b) 分别是对数据分布直接采样、根据数据分布的真实 score 进行朗之万动力学采样(注意这里的实验设了一个简单的数据分布,也就是说数据分布的确切解析式我们是已知的),显然图 (b) 朗之万动力学得到的样本之间两种 pattern 的相对密度是不正确的,与上述分析相符。

三、提出方法:Noise Conditional Score Networks: learning and inference
如何解决 score-based generative models 的上述问题呢?
作者发现,使用随机高斯噪声对数据分布进行扰动,会使得数据分布更适合于 score-based generative modeling。首先,由于高斯分布遍布整个空间,因此使用其对数据分布进行扰动,分布就不会仅局限在低维流形上了,这使得数据分布的得分在整个空间上都是良定义的,消除了流形假设带来的难点。第二,大的高斯噪声可以填满原本未扰动数据分布的低密度区域,从而 score mathcing 的训练过程就更多的监督信号,模型估计的得分就更准。第三,使用多种噪声等级,我们可以获得一系列噪声扰动分布,这一系列噪声扰动分布逐渐逼近真实数据分布。通过使用模拟退火(simulated annealing)和退火重要性采样(annealed importance sampling)的思想,我们可以利用这些中间分布来提高多模态分布上朗之万动力学采样的速率。
基于以上思考,作者提出了对 score-based generative modeling 的改进措施:1)使用多种不同等级的噪声对数据分布进行扰动;2)训练单个(条件)神经网络来同时估计所有噪声等级所对应分布的得分。训练结束后,使用朗之万动力学来进行采样生成时,我们从最大噪声所对应分布的得分开始,逐步退火降低噪声等级,这有助于权衡大小噪声水平的益处,平稳地将大噪声水平的益处逐渐转移到低噪声水平,直到扰动后的数据几乎与原始数据无法区分。下面,我们将更详细地阐述我们方法的细节,包括得分网络的架构、训练目标和退火的朗之万动力学采样。
1 网络:noise conditional score networks
记 { σ i } i = 1 L \{\sigma_i\}_{i=1}^L {σi}i=1L 是一个正的等比序列,满足: σ 1 σ 2 = ⋯ = σ L − 1 σ L > 1 \frac{\sigma_1}{\sigma_2}=\dots=\frac{\sigma_{L-1}}{\sigma_{L}}>1 σ2σ1=⋯=σLσL−1>1,它是我们的噪声等级序列。记 q σ ( x ) = △ ∫ p data ( t ) N ( x ∣ t , σ 2 I ) d t q_\sigma(\mathbf{x})\stackrel{\triangle}{=}\int p_\text{data}(\mathbf{t})\mathcal{N}(\mathbf{x}|\mathbf{t},\sigma^2\mathbf{I})d\mathbf{t} qσ(x)=△∫pdata(t)N(x∣t,σ2I)dt 表示经噪声扰动的数据分布。在我们选定的噪声等级序列中,要满足 1) σ 1 \sigma_1 σ1 足够大,能够消除流形假设中提到的低密度区域训练信号不足问题;2) σ L \sigma_L σL 足够小,在最后减少对真实数据分布的影响。我们要训练一个条件得分网络,来按条件估计不同噪声扰动等级下分布的得分,即 ∀ σ ∈ { σ i } i = 1 L , s θ ( x , σ ) ≈ ∇ x log q σ ( x ) \forall\sigma\in\{\sigma_i\}_{i=1}^L,\ \ \mathbf{s_\theta}(\mathbf{x},\sigma)\approx\nabla_\mathbf{x}\log q_\sigma(\mathbf{x}) ∀σ∈{σi}i=1L, sθ(x,σ)≈∇xlogqσ(x)。注意我们的模型输入输出尺寸是相同的,即当 x ∈ R D \mathbf{x}\in\mathbb{R}^D x∈RD 时, s θ ( x , σ ) ∈ R D \mathbf{s_\theta}(\mathbf{x,\sigma})\in\mathbb{R}^D sθ(x,σ)∈RD。作者将网络 s θ ( x , σ ) \mathbf{s_\theta}(\mathbf{x},\sigma) sθ(x,σ) 命名为噪声条件得分网络(Noise Conditional Score Networks,NCSN)。
具体网络结构方面,由于 NCSN 的输入输出尺寸相同,作者借鉴密集预测类任务(如图像分割),选择了 UNet 作为主体网络结构,加入了空洞卷积、实例归一化等技术,并使用一种改进的条件实例归一化(conditional instance normalization)来将条件 σ \sigma σ 注入到模型中。
2 训练:learning NCSNs via score matching
作者强调,之前介绍的 sliced score matching 和 denoising score matching 都可以用来训练 NCSN。本文中考虑到 dsm 训练更快且更适合我们估计噪声扰动数据分布的得分的任务,故而采用 dsm 进行训练。本文选用噪声分布为
q σ ( x ~ ∣ x ) = N ( x ~ ∣ x , σ 2 I ) q_\sigma(\tilde{\mathbf{x}}|\mathbf{x})=\mathcal{N}(\tilde{\mathbf{x}}|\mathbf{x},\sigma^2\mathbf{I}) qσ(x~∣x)=N(x~∣x,σ2I)
从而有:
KaTeX parse error: Got function '\tilde' with no arguments as subscript at position 9: \nabla_\̲t̲i̲l̲d̲e̲{\mathbf{x}}\lo…
对于给定的 σ \sigma σ,denosing score matching 的目标函数为:
l ( θ ; σ ) = △ 1 2 E p data ( x ) E x ~ ∼ N ( x , σ 2 I ) [ ∣ ∣ s θ ( x ~ , σ ) + x ~ − x σ 2 ∣ ∣ 2 2 ] l(\theta;\sigma)\stackrel{\triangle}{=}\frac{1}{2}\mathbb{E}_{p_\text{data}(\mathbf{x})}\mathbb{E}_{\tilde{\mathbf{x}}\sim\mathcal{N}(\mathbf{x},\sigma^2\mathbf{I})}[||\mathbf{s_\theta}(\mathbf{\tilde{x}},\sigma)+\frac{\tilde{\mathbf{x}}-\mathbf{x}}{\sigma^2}||_2^2] l(θ;σ)=△21Epdata(x)Ex~∼N(x,σ2I)[∣∣sθ(x~,σ)+σ2x~−x∣∣22]
对于所有的 σ ∈ { σ i } i = 1 L \sigma\in\{\sigma_i\}_{i=1}^L σ∈{σi}i=1L 结合起来,统一的目标函数为:
L ( θ ; { σ i } i = 1 L ) = △ 1 L ∑ i = 1 L λ ( σ i ) l ( θ ; σ i ) \mathcal{L}(\theta;\{\sigma_i\}_{i=1}^L)\stackrel{\triangle}{=}\frac{1}{L}\sum_{i=1}^L\lambda(\sigma_i)l(\theta;\sigma_i) L(θ;{σi}i=1L)=△L1i=1∑Lλ(σi)l(θ;σi)
其中 λ ( σ i ) > 0 \lambda(\sigma_i)>0 λ(σi)>0 是一个关于 σ i \sigma_i σi 的加权函数。假设 s θ ( x , σ ) \mathbf{s_\theta}(\mathbf{x},\sigma) sθ(x,σ) 训练得足够好,对所有的 i ∈ [ 1 , L ] i\in[1,L] i∈[1,L] 都能最小化上述目标函数,那么模型就能准确地估计噪声扰动数据分布的得分,即 s θ ∗ ( x , σ ) = ∇ x log q σ i ( x ) \mathbf{s_{\theta^*}}(\mathbf{x},\sigma)=\nabla_\mathbf{x}\log q_{\sigma_i}(\mathbf{{x}}) sθ∗(x,σ)=∇xlogqσi(x)。
对于 λ ( ⋅ ) \lambda(\cdot) λ(⋅) 的选择,可以有很多种。理想情况下,我们希望对所有的 σ i \sigma_i σi,损失 λ ( σ i ) l ( θ ; σ i ) \lambda(\sigma_i)l(\theta;\sigma_i) λ(σi)l(θ;σi) 的值大致在相同的数量级上。实验中,作者发现当网络训练得比较好时,大致有 ∣ ∣ s θ ( x , σ ) ∣ ∣ 2 ∝ 1 / σ ||\mathbf{s_\theta}(\mathbf{x},\sigma)||_2\propto1/\sigma ∣∣sθ(x,σ)∣∣2∝1/σ。作者据此选择 λ ( σ ) = σ 2 \lambda(\sigma)=\sigma^2 λ(σ)=σ2。这是因为在此选择下,有 λ ( σ ) l ( θ ; σ ) = σ 2 l ( ( θ ; σ ) ) = 1 2 E [ ∣ ∣ σ s θ ( x ; σ ) + x ~ − x σ ∣ ∣ 2 2 ] \lambda(\sigma)l(\theta;\sigma)=\sigma^2l((\theta;\sigma))=\frac{1}{2}\mathbb{E}[||\sigma\mathbf{s_\theta}(\mathbf{x};\sigma)+\frac{\tilde{\mathbf{x}}-\mathbf{x}}{\sigma}||^2_2] λ(σ)l(θ;σ)=σ2l((θ;σ))=21E[∣∣σsθ(x;σ)+σx~−x∣∣22] ,而由于 x ~ − x σ ∼ N ( 0 , I ) \frac{\tilde{\mathbf{x}}-\mathbf{x}}{\sigma}\sim\mathcal{N}(0,\mathbf{I}) σx~−x∼N(0,I)、 ∣ ∣ σ s θ ( x ; σ ) ∣ ∣ 2 ∝ 1 ||\sigma\mathbf{s_\theta}(\mathbf{x};\sigma)||_2\propto 1 ∣∣σsθ(x;σ)∣∣2∝1,因此可得此时 λ ( σ ) l ( θ ; σ ) \lambda(\sigma)l(\theta;\sigma) λ(σ)l(θ;σ) 值的数量级与 σ \sigma σ 无关。
3 采样:NCSN inference via annealed Langevin dynamics
在 NCSN s θ ( x , σ ) \mathbf{s_\theta}(\mathbf{x},\sigma) sθ(x,σ) 训练完成后,我们就能够对不同噪声扰动数据分布 q σ i ( x ) q_{\sigma_i}(\mathbf{x}) qσi(x) 的得分 ∇ x q σ 1 ( x ) \nabla_\mathbf{x}q_{\sigma_1}(\mathbf{x}) ∇xqσ1(x) 进行较为准确的估计。这样,就能执行朗之万动力学采样,从各个分布 q σ i ( x ) q_{\sigma_i}(\mathbf{x}) qσi(x) 中采样出样本。但是,如前所述,流形假设指出了朗之万动力学采样对多 pattern 数据分布采样时混合较慢的问题,并且我们的 NCSN 需要估计的是多个噪声扰动分布 q σ i ( x ) q_{\sigma_i}(\mathbf{x}) qσi(x) 的得分,而不是数据分布 p data ( x ) p_\text{data}(\mathbf{x}) pdata(x) 的得分。因此,本文提出了一种新的采用方法——退火的朗之万动力学(Annealed Langevin Dynamics),来使用 NCSN 进行采样生成。
具体算法如下图所示。我们从一个固定的先验分布(如均匀分布)中采样一个初始样本。首先对第一级的噪声扰动数据分布 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 执行 T T T 步朗之万动力学采样,步长为 α 1 \alpha_1 α1。然后将对 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 的最终采样结果作为初始样本,再对 q σ 2 ( x ) q_{\sigma_2}(\mathbf{x}) qσ2(x) 进行朗之万动力学采样,步长为 α 2 \alpha_2 α2,注意 α 2 < α 1 \alpha_2<\alpha_1 α2<α1。迭代进行这种方式,每次使用上一级分布 q σ i − 1 ( x ) q_{\sigma_{i-1}}(\mathbf{x}) qσi−1(x) 朗之万动力学采样迭代的最后一个样本,作为下一级分布 q σ i ( x ) q_{\sigma_i}(\mathbf{x}) qσi(x) 采样的起始样本,并逐渐调小步长 α i = ϵ ⋅ σ i 2 / σ L 2 \alpha_i=\epsilon\cdot\sigma_i^2/\sigma_L^2 αi=ϵ⋅σi2/σL2。最终,我们对最后一级噪声扰动分布 q σ L ( x ) q_{\sigma_L}(\mathbf{x}) qσL(x) 执行朗之万动力学采样,得到最终的生成结果。由于 σ L ≈ 0 \sigma_L\approx0 σL≈0 足够小,因此 q σ L ( x ) q_{\sigma_L}(\mathbf{x}) qσL(x) 已经非常接近真实的数据分布 p data ( x ) p_\text{data}(\mathbf{x}) pdata(x)。

由于噪声扰动分布 { q σ i } i = 1 L \{q_{\sigma_i}\}_{i=1}^L {qσi}i=1L 都是由高斯噪声进行扰动,因此这些分布的存在区域都是充满整个空间的,从而他们的得分都是良定义的,避免了前文所述的流形假设指出的分布得分未定义的问题。当 σ 1 \sigma_1 σ1 足够大时,分布 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 的低密度区域就很小,并且不同 pattern 之间也没有那么分离。从而,得分估计就更准,并且朗之万动力学采样对不同 pattern 的混合也更快。因此,朗之万动力学从 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 采样出的结果就是比较好的样本。这些样本很大概率是来自 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 的高密度区域,而由于 q σ 2 ( x ) q_{\sigma_2}(\mathbf{x}) qσ2(x) 与 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 非常接近,从而这些样本同样很大概率落在 q σ 2 ( x ) q_{\sigma_2}(\mathbf{x}) qσ2(x) 的高密度区域。而得分估计和朗之万动力学采样都是在分布的高密度区域工作得更好,也就是说第一级噪声扰动分布 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 中采样出来的最终样本为第二级噪声扰动分布 q σ 2 ( x ) q_{\sigma_2}(\mathbf{x}) qσ2(x) 的朗之万动力学采样提供了很好的初始化。以此类推,每一级分布 q σ i − 1 ( x ) q_{\sigma_{i-1}}(\mathbf{x}) qσi−1(x) 的样本都为下一级分布 q σ i ( x ) q_{\sigma_i}(\mathbf{x}) qσi(x) 的采样提供了很好的初始化。最终我们能从分布 q σ L ( x ) q_{\sigma_L}(\mathbf{x}) qσL(x) 中采样到高质量的结果。
步长 α i \alpha_i αi 的设置也有很多可能。本文的选择是 α i ∝ σ i 2 \alpha_i\propto\sigma_i^2 αi∝σi2。这样设计的动机是想要固定朗之万动力学采样中信噪比 (Signal-to-Noise Ratio, SNR) α i s θ ( x , σ i ) 2 α i z \frac{\alpha_i\mathbf{s_\theta(\mathbf{x},\sigma_i)}}{2\sqrt{\alpha_i}\mathbf{z}} 2αizαisθ(x,σi) 的尺度。注意有 E [ ∣ ∣ α i s θ ( x , σ i ) 2 α i z ∣ ∣ 2 2 ] ≈ E [ α i ∣ ∣ s θ ( x , σ i ) ∣ ∣ 2 2 4 ] ∝ 1 4 E [ ∣ ∣ σ i s θ ( x , σ i ) ∣ ∣ 2 2 ] \mathbb{E}[||\frac{\alpha_i\mathbf{s_\theta(\mathbf{x},\sigma_i)}}{2\sqrt{\alpha_i}\mathbf{z}}||_2^2]\approx\mathbb{E}[\frac{\alpha_i||\mathbf{s_\theta}(\mathbf{x},\sigma_i)||_2^2}{4}]\propto\frac{1}{4}\mathbb{E}[||\sigma_i\mathbf{s_\theta}(\mathbf{x},\sigma_i)||_2^2] E[∣∣2αizαisθ(x,σi)∣∣22]≈E[4αi∣∣sθ(x,σi)∣∣22]∝41E[∣∣σisθ(x,σi)∣∣22]。我们之前提到,当 NCSN 训练得比较好的时候,有 ∣ ∣ s θ ( x , σ ) ∣ ∣ 2 ∝ 1 / σ ||\mathbf{s_\theta}(\mathbf{x},\sigma)||_2\propto1/\sigma ∣∣sθ(x,σ)∣∣2∝1/σ,此时有 E [ ∣ ∣ σ i s θ ( x , σ i ) ∣ ∣ 2 2 ∝ 1 \mathbb{E}[||\sigma_i\mathbf{s_\theta}(\mathbf{x},\sigma_i)||_2^2\propto1 E[∣∣σisθ(x,σi)∣∣22∝1,从而信噪比 E [ ∣ ∣ α i s θ ( x , σ i ) 2 α i z ∣ ∣ 2 2 ] ∝ 1 4 E [ ∣ ∣ σ i s θ ( x , σ i ) ∣ ∣ 2 2 ] ∝ 1 4 \mathbb{E}[||\frac{\alpha_i\mathbf{s_\theta(\mathbf{x},\sigma_i)}}{2\sqrt{\alpha_i}\mathbf{z}}||_2^2]\propto\frac{1}{4}\mathbb{E}[||\sigma_i\mathbf{s_\theta}(\mathbf{x},\sigma_i)||_2^2]\propto\frac{1}{4} E[∣∣2αizαisθ(x,σi)∣∣22]∝41E[∣∣σisθ(x,σi)∣∣22]∝41,与 σ i \sigma_i σi 无关。
为了展示退火朗之万动力学的有效性,本文在前面介绍标准朗之万动力学混合慢的简单实验中,对比了本文所提方法。回顾一下,实验的目标是使用得分从一个简单的两个高斯混合的数据分布中进行采样。退火的朗之万动力学的采样结果如图 © 所示,明显可以看到,采样出的数据能够反映出两个高斯分布的比重差异,也就是说能够更真实地从数据分布中采样,而标准的朗之万动力学采样(图 (b)显然没有做到这一点。
结语
这篇 NCSN 的方法提出在 DDPM 之前,并且对 DDPM 的设计也有启发。更重要的是,笔者认为,基于得分的生成模型似乎更加直觉,更具有可解释性。从理解的角度来说,NSCN 更加顺畅。但是 DDPM 的效果似乎更好?因此一般认为 DDPM 是真正将 Diffusion 这一类方法做 work 的工作。宋飏博士在之后的 score based SDE 中也已经将 NCSN 和 DDPM 统一到了 SDE 的框架下。
相关文章:
Generative Modeling by Estimating Gradients of the Data Distribution
Generative Modeling by Estimating Gradients of the Data Distribution 本文介绍宋飏提出的带噪声扰动的基于得分的生成模型。首先介绍基本的基于得分的生成模型的训练方法(得分匹配)和采样方法(朗之万动力学)。然后基于流形假…...

vector与list的简单介绍
1. 标准库中的vector类的介绍: vector是表示大小可以变化的数组的序列容器。 就像数组一样,vector对其元素使用连续的存储位置,这意味着也可以使用指向其元素的常规指针上的偏移量来访问其元素,并且与数组中的元素一样高效。但与数…...

四种线程池的使用,优缺点分析
池化思想:线程池、字符串常量池、数据库连接池 提高资源的利用率 下面是手动创建线程和执行任务过程,可见挺麻烦的,而且线程利用率不高。 手动创建线程对象执行任务执行完毕,释放线程对象 线程池的优点: 提高线程的…...

什么是 BEM 规范
BEM(Block, Element, Modifier)是一种 CSS 命名规范,旨在提高代码的可读性和可维护性。BEM 规范通过明确的命名规则来定义组件和组件的各个部分,使开发者能够更容易地理解和维护代码。 BEM 命名规范的基本概念 Block(…...

【Node.JS】入门
文章目录 Node.js的入门涉及对其基本概念、特点、安装、以及基本使用方法的了解。以下是对Node.js入门的详细介绍: 一、Node.js基本概念和特点 定义:Node.js是一个基于Chrome V8引擎的JavaScript运行环境,它使得JavaScript能够运行在服务器…...

Amazon SageMaker 机器学习之旅的助推器
一、前言 在当今的数字化时代,人工智能和机器学习已经成为推动社会进步的重要引擎。亚马逊云科技在 2023 re:Invent 全球大会上,宣布推出五项 Amazon SageMaker 新功能: Amazon SageMaker HyperPod 通过为大规模分布式训练提供专用的基础架构…...

TransMIL:基于Transformer的多实例学习
MIL是弱监督分类问题的有力工具。然而,目前的MIL方法通常基于iid假设,忽略了不同实例之间的相关性。为了解决这个问题,作者提出了一个新的框架,称为相关性MIL,并提供了收敛性的证明。基于此框架,还设计了一…...

3.用户程序与驱动交互
驱动程序请使用第二章https://blog.csdn.net/chenhequanlalala/article/details/140034424 用户app与驱动交互最常见的做法是insmod驱动后,生成一个设备节点,app通过open,read等系统调用去操作这个设备节点,这里先用mknode命令调…...
尽量不写一行if...elseif...写出高质量可持续迭代的项目代码
背景 无论是前端代码还是后端代码,都存在着定位困难,不好抽离,改造困难的问题,造成代码开发越来越慢,此外因为代码耦合较高,总是出现改了一处地方,然后影响其他地方,要么就是要修改…...

xcrun: error: unable to find utility “simctl“, not a developer tool or in PATH
目录 前言 一、问题详情 二、解决方案 1.确认Xcode已安装 2.安装Xcode命令行工具 3.指定正确的开发者目录 4. 确认命令行工具路径 5. 更新PATH环境变量 前言 今天使用cocoapods更新私有库的时候,遇到了"xcrun: error: unable to find utility &…...

【linux高级IO(一)】理解五种IO模型
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:Linux从入门到精通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学更多操作系统知识 🔝🔝 Linux高级IO 1. 前言2. 重谈对…...

前端引用vue/element/echarts资源等引用方法Blob下载HTML
前端引用下载vue/element/echarts资源等引用方法 功能需求 需求是在HTML页面中集成Vue.js、Element Plus(Element UI的Vue 3版本)、ECharts等前端资源,使用Blob下载HTML。 解决方案概述 直接访问线上CDN地址:简单直接,…...

昇思MindSpore学习笔记2-01 LLM原理和实践 --基于 MindSpore 实现 BERT 对话情绪识别
摘要: 通过识别BERT对话情绪状态的实例,展现在昇思MindSpore AI框架中大语言模型的原理和实际使用方法、步骤。 一、环境配置 %%capture captured_output # 实验环境已经预装了mindspore2.2.14,如需更换mindspore版本,可更改下…...

uniapp实现图片懒加载 封装组件
想要的效果就是窗口滑动到哪里,哪里的图片进行展示 主要原理使用IntersectionObserver <template><view><image error"HandlerError" :style"imgStyle" :src"imageSrc" :id"randomId" :mode"mode&quo…...

持续交付:自动化测试与发布流程的变革
目录 前言1. 持续交付的概念1.1 持续交付的定义1.2 持续交付的核心原则 2. 持续交付的优势2.1 提高交付速度2.2 提高软件质量2.3 降低发布风险2.4 提高团队协作 3. 实施持续交付的步骤3.1 构建自动化测试体系3.1.1 单元测试3.1.2 集成测试3.1.3 功能测试3.1.4 性能测试 3.2 构建…...

VBA常用的字符串内置函数
前言 在VBA程序中,常用的内置函数可以按照功能分为字符串函数、数字函数、转换函数等等,本节主要会介绍常用的字符串的内置函数,包括Len()、Left()、Mid()、Right()、Split()、String()、StrConV()等。 本节的练习数据表以下表为例ÿ…...
)
大数据面试题之Spark(7)
目录 Spark实现wordcount Spark Streaming怎么实现数据持久化保存? Spark SQL读取文件,内存不够使用,如何处理? Spark的lazy体现在哪里? Spark中的并行度等于什么 Spark运行时并行度的设署 Spark SQL的数据倾斜 Spark的exactly-once Spark的…...

AI绘画 Stable Diffusion图像的脸部细节控制——采样器全解析
大家好,我是画画的小强 我们在运用AI绘画 Stable Diffusion 这一功能强大的AI绘图工具时,我们往往会发现自己对提示词的使用还不够充分。在这种情形下,我们应当如何调整自己的策略,以便更加精确、全面地塑造出理想的人物形象呢&a…...

liunx离线安装Firefox
在Linux系统中离线安装Firefox浏览器,您需要先从Mozilla的官方网站下载Firefox的安装包,然后通过终端进行安装。以下是详细的步骤: 准备工作 下载Firefox安装包: 首先,在一台可以上网的电脑上访问Firefox官方下载页面…...
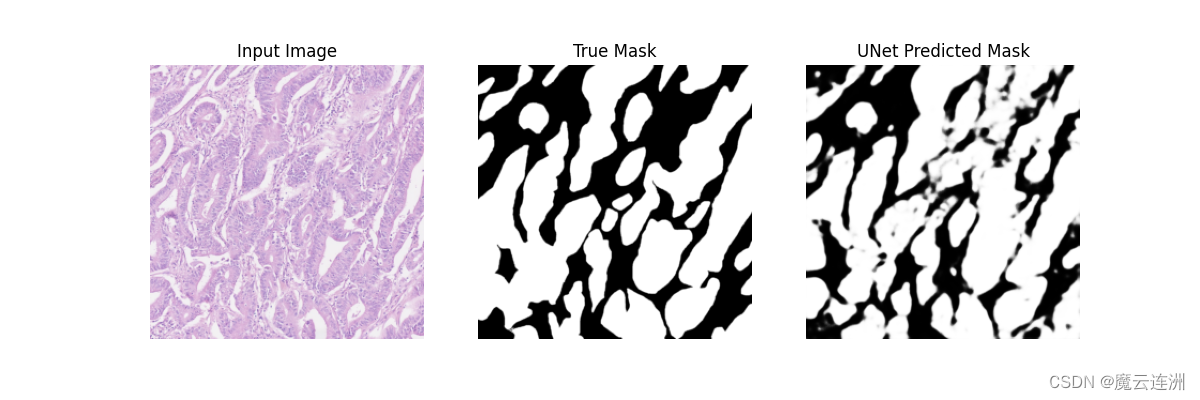
UNet进行病理图像分割
数据集链接:https://pan.baidu.com/s/1IBe_P0AyHgZC39NqzOxZhA?pwdnztc 提取码:nztc UNet模型 import torch import torch.nn as nnclass conv_block(nn.Module):def __init__(self, ch_in, ch_out):super(conv_block, self).__init__()self.conv nn…...

在Node.js服务端项目中集成Taotoken聚合大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务端项目中集成Taotoken聚合大模型能力 对于Node.js后端开发者而言,在构建需要AI能力的Web服务时ÿ…...
ATB:让 Transformer 推理快得像开了挂——昇腾算子加速库技术解析
Transformer 模型推理的瓶颈在哪里?KV Cache 管理、算子融合、分布式调度。ATB(ascend-transformer-boost)把这些问题一次性解决,让推理性能提升 2-3 倍。 上个月帮一个团队做推理优化,他们的 LLaMA-2 70B 模型在 NPU …...
3步掌握Translumo:免费高效的跨语言屏幕翻译解决方案
3步掌握Translumo:免费高效的跨语言屏幕翻译解决方案 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾…...

Golang JWT生产实践:时间精度、密钥轮换与Refresh Token安全设计
1. 这不是“加个Token就完事”的简单活儿 Golang领域JWT——这六个字背后,藏着太多人踩过坑、重写过三遍、上线后半夜被报警电话叫醒的真实故事。我第一次在生产环境用JWT做身份验证时,自信满满地照着某篇教程写了20行代码,结果上线第三天&am…...

BiliBiliCCSubtitle架构解析:C++实现的B站CC字幕高效下载与转换技术方案
BiliBiliCCSubtitle架构解析:C实现的B站CC字幕高效下载与转换技术方案 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle BiliBiliCCSubtitle是一款基于C…...

CompressO:免费开源的终极视频压缩工具,一键将大文件变小90%
CompressO:免费开源的终极视频压缩工具,一键将大文件变小90% 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirro…...

2026年腾讯云OpenClaw/Hermes Agent配置Token Plan搭建详细攻略
2026年腾讯云OpenClaw/Hermes Agent配置Token Plan搭建详细攻略。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

生成式AI驱动业务流程自动化:从流程挖掘到智能重构
1. 从流程执行到流程创造:生成式AI如何重塑BPM在业务流程管理(BPM)领域摸爬滚打了十几年,我亲眼见证了它从一套僵化的流程图和审批流,演变为一个动态的、数据驱动的智能决策中枢。传统的BPM核心在于“建模-执行-监控-优…...

3步掌握终极AMD Ryzen调试工具:免费解锁硬件深层控制
3步掌握终极AMD Ryzen调试工具:免费解锁硬件深层控制 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://git…...

小红书下载神器XHS-Downloader:3分钟解锁隐藏的高级玩法
小红书下载神器XHS-Downloader:3分钟解锁隐藏的高级玩法 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&a…...