Kubernetes 一键部署利器:kubeadm
文章目录
- 集群部署痛点
- kubeadm 的工作原理
- kubeadm init 的工作流程
- kubeadm join 的工作流程
- kubeadm 的部署配置参数
集群部署痛点
Kubernetes 的部署一直以来都是挡在初学者前面的一只“拦路虎”。尤其是在 Kubernetes 项目发布初期,它的部署完全要依靠一堆由社区维护的脚本。
Kubernetes 作为一个 Golang 项目,已经免去了很多类似于 Python 项目要安装语言级别依赖的麻烦。但是,除了将各个组件编译成二进制文件外,用户还要负责为这些二进制文件编写对应的配置文件、配置自启动脚本,以及为 kube-apiserver 配置授权文件等等诸多运维工作。
目前,各大云厂商最常用的部署的方法,是使用 SaltStack、Ansible 等运维工具自动化地执行这些步骤。
但即使这样,这个部署过程依然非常繁琐。因为,SaltStack 这类专业运维工具本身的学习成本,就可能比 Kubernetes 项目还要高。
难道 Kubernetes 项目就没有简单的部署方法了吗?
这个问题,在 Kubernetes 社区里一直没有得到足够重视。直到 2017 年,在志愿者的推动下,社区才终于发起了一个独立的部署工具,名叫:kubeadm。
这个项目的目的,就是要让用户能够通过这样两条指令完成一个 Kubernetes 集群的部署:
- 创建一个 Master 节点
$ kubeadm init
- 将一个 Node 节点加入到当前集群中
$ kubeadm join <Master 节点的 IP 和端口 >
是不是非常方便呢?
kubeadm 的工作原理
在上一篇详细介绍了 Kubernetes 的架构和它的组件。在部署时,它的每一个组件都是一个需要被执行的、单独的二进制文件。所以不难想象,SaltStack 这样的运维工具或者由社区维护的脚本的功能,就是要把这些二进制文件传输到指定的机器当中,然后编写控制脚本来启停这些组件。
不过,在理解了容器技术之后,你可能已经萌生出了这样一个想法,为什么不用容器部署 Kubernetes 呢?
这样,我只要给每个 Kubernetes 组件做一个容器镜像,然后在每台宿主机上用 docker run 指令启动这些组件容器,部署不就完成了吗?
事实上,在 Kubernetes 早期的部署脚本里,确实有一个脚本就是用 Docker 部署 Kubernetes 项目的,这个脚本相比于 SaltStack 等的部署方式,也的确简单了不少。
但是,这样做会带来一个很麻烦的问题,即:如何容器化 kubelet。
我在上一篇文章中,已经提到 kubelet 是 Kubernetes 项目用来操作 Docker 等容器运行时的核心组件。可是,除了跟容器运行时打交道外,kubelet 在配置容器网络、管理容器数据卷时,都需要直接操作宿主机。
而如果现在 kubelet 本身就运行在一个容器里,那么直接操作宿主机就会变得很麻烦。对于网络配置来说还好,kubelet 容器可以通过不开启 Network Namespace(即 Docker 的 host network 模式)的方式,直接共享宿主机的网络栈。可是,要让 kubelet 隔着容器的 Mount Namespace 和文件系统,操作宿主机的文件系统,就有点儿困难了。
比如,如果用户想要使用 NFS 做容器的持久化数据卷,那么 kubelet 就需要在容器进行绑定挂载前,在宿主机的指定目录上,先挂载 NFS 的远程目录。
可是,这时候问题来了。由于现在 kubelet 是运行在容器里的,这就意味着它要做的这个“mount -F nfs”命令,被隔离在了一个单独的 Mount Namespace 中。即,kubelet 做的挂载操作,不能被“传播”到宿主机上。
对于这个问题,有人说,可以使用 setns() 系统调用,在宿主机的 Mount Namespace 中执行这些挂载操作;也有人说,应该让 Docker 支持一个–mnt=host 的参数。
但是,到目前为止,在容器里运行 kubelet,依然没有很好的解决办法,也不推荐你用容器去部署 Kubernetes 项目。
正因为如此,kubeadm 选择了一种妥协方案:
把 kubelet 直接运行在宿主机上,然后使用容器部署其他的 Kubernetes 组件。
所以,使用 kubeadm 的第一步,是在机器上手动安装 kubeadm、kubelet 和 kubectl 这三个二进制文件。kubeadm 的作者已经为各个发行版的 Linux 准备好了安装包,只需要执行:
$ apt-get install kubeadm
就可以了。
接下来,你就可以使用“kubeadm init”部署 Master 节点了。
kubeadm init 的工作流程
执行 kubeadm init 指令后,kubeadm 首先要做的,是一系列的检查工作,以确定这台机器可以用来部署 Kubernetes。这一步检查,我们称为“Preflight Checks”,它可以省掉很多后续的麻烦。
其实,Preflight Checks 包括了很多方面,比如:
- Linux 内核的版本必须是否是 3.10 以上?
- Linux Cgroups 模块是否可用?
- 机器的 hostname 是否标准?在 Kubernetes 项目里,机器的名字以及一切存储在 Etcd 中的 API 对象,都必须使用标准的 DNS 命名(RFC 1123)。
- 用户安装的 kubeadm 和 kubelet 的版本是否匹配?
- 机器上是不是已经安装了 Kubernetes 的二进制文件?
- Kubernetes 的工作端口 10250/10251/10252 端口是不是已经被占用?
- ip、mount 等 Linux 指令是否存在?
- Docker 是否已经安装?
- ……
在通过了 Preflight Checks 之后,kubeadm 要为你做的,是生成 Kubernetes 对外提供服务所需的各种证书和对应的目录。
Kubernetes 对外提供服务时,除非专门开启“不安全模式”,否则都要通过 HTTPS 才能访问 kube-apiserver。这就需要为 Kubernetes 集群配置好证书文件。
kubeadm 为 Kubernetes 项目生成的证书文件都放在 Master 节点的 /etc/kubernetes/pki 目录下。在这个目录下,最主要的证书文件是 ca.crt 和对应的私钥 ca.key。
此外,用户使用 kubectl 获取容器日志等 streaming 操作时,需要通过 kube-apiserver 向 kubelet 发起请求,这个连接也必须是安全的。kubeadm 为这一步生成的是 apiserver-kubelet-client.crt 文件,对应的私钥是 apiserver-kubelet-client.key。
除此之外,Kubernetes 集群中还有 Aggregate APIServer 等特性,也需要用到专门的证书,这里就不再一一列举了。需要指出的是,你可以选择不让 kubeadm 为你生成这些证书,而是拷贝现有的证书到如下证书的目录里:
/etc/kubernetes/pki/ca.{crt,key}
这时,kubeadm 就会跳过证书生成的步骤,把它完全交给用户处理。
证书生成后,kubeadm 接下来会为其他组件生成访问 kube-apiserver 所需的配置文件。这些文件的路径是:/etc/kubernetes/xxx.conf:
ls /etc/kubernetes/
admin.conf controller-manager.conf kubelet.conf scheduler.conf
这些文件里面记录的是当前这个 Master 节点的服务器地址、监听端口、证书目录等信息。这样,对应的客户端(比如 scheduler,kubelet 等),可以直接加载相应的文件,使用里面的信息与 kube-apiserver 建立安全连接。
接下来,kubeadm 会为 Master 组件生成 Pod 配置文件。在上一篇介绍过 Kubernetes 有三个 Master 组件 kube-apiserver、kube-controller-manager、kube-scheduler,而它们都会被使用 Pod 的方式部署起来。
你可能会有些疑问:这时,Kubernetes 集群尚不存在,难道 kubeadm 会直接执行 docker run 来启动这些容器吗?
当然不是。
在 Kubernetes 中,有一种特殊的容器启动方法叫做“Static Pod”。它允许你把要部署的 Pod 的 YAML 文件放在一个指定的目录里。这样,当这台机器上的 kubelet 启动时,它会自动检查这个目录,加载所有的 Pod YAML 文件,然后在这台机器上启动它们。
从这一点也可以看出,kubelet 在 Kubernetes 项目中的地位非常高,在设计上它就是一个完全独立的组件,而其他 Master 组件,则更像是辅助性的系统容器。
在 kubeadm 中,Master 组件的 YAML 文件会被生成在 /etc/kubernetes/manifests 路径下。比如,kube-apiserver.yaml:
apiVersion: v1
kind: Pod
metadata:annotations:scheduler.alpha.kubernetes.io/critical-pod: ""creationTimestamp: nulllabels:component: kube-apiservertier: control-planename: kube-apiservernamespace: kube-system
spec:containers:- command:- kube-apiserver- --authorization-mode=Node,RBAC- --runtime-config=api/all=true- --advertise-address=10.168.0.2...- --tls-cert-file=/etc/kubernetes/pki/apiserver.crt- --tls-private-key-file=/etc/kubernetes/pki/apiserver.keyimage: k8s.gcr.io/kube-apiserver-amd64:v1.11.1imagePullPolicy: IfNotPresentlivenessProbe:...name: kube-apiserverresources:requests:cpu: 250mvolumeMounts:- mountPath: /usr/share/ca-certificatesname: usr-share-ca-certificatesreadOnly: true...hostNetwork: truepriorityClassName: system-cluster-criticalvolumes:- hostPath:path: /etc/ca-certificatestype: DirectoryOrCreatename: etc-ca-certificates...
关于一个 Pod 的 YAML 文件怎么写、里面的字段如何解读,在后续专门的文章中会详细分析。在这里只需要关注这样几个信息:
这个 Pod 里只定义了一个容器,它使用的镜像是:k8s.gcr.io/kube-apiserver-amd64:v1.11.1 。这个镜像是 Kubernetes 官方维护的一个组件镜像。
这个容器的启动命令(commands)是 kube-apiserver --authorization-mode=Node,RBAC …,这样一句非常长的命令。其实,它就是容器里 kube-apiserver 这个二进制文件再加上指定的配置参数而已。
如果你要修改一个已有集群的 kube-apiserver 的配置,需要修改这个 YAML 文件。
这些组件的参数也可以在部署时指定,稍后会讲解到。
在这一步完成后,kubeadm 还会再生成一个 Etcd 的 Pod YAML 文件,用来通过同样的 Static Pod 的方式启动 Etcd。所以,最后 Master 组件的 Pod YAML 文件如下所示:
$ ls /etc/kubernetes/manifests/
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
而一旦这些 YAML 文件出现在被 kubelet 监视的 /etc/kubernetes/manifests 目录下,kubelet 就会自动创建这些 YAML 文件中定义的 Pod,即 Master 组件的容器。
Master 容器启动后,kubeadm 会通过检查 localhost:6443/healthz 这个 Master 组件的健康检查 URL,等待 Master 组件完全运行起来。
然后,kubeadm 就会为集群生成一个 bootstrap token。在后面,只要持有这个 token,任何一个安装了 kubelet 和 kubadm 的节点,都可以通过 kubeadm join 加入到这个集群当中。
这个 token 的值和使用方法会在 kubeadm init 结束后被打印出来。
在 token 生成之后,kubeadm 会将 ca.crt 等 Master 节点的重要信息,通过 ConfigMap 的方式保存在 Etcd 当中,供后续部署 Node 节点使用。这个 ConfigMap 的名字是 cluster-info。
kubeadm init 的最后一步,就是安装默认插件。Kubernetes 默认 kube-proxy 和 DNS 这两个插件是必须安装的。它们分别用来提供整个集群的服务发现和 DNS 功能。其实,这两个插件也只是两个容器镜像而已,所以 kubeadm 只要用 Kubernetes 客户端创建两个 Pod 就可以了。
kubeadm join 的工作流程
这个流程其实非常简单,kubeadm init 生成 bootstrap token 之后,你就可以在任意一台安装了 kubelet 和 kubeadm 的机器上执行 kubeadm join 了。
可是,为什么执行 kubeadm join 需要这样一个 token 呢?
因为,任何一台机器想要成为 Kubernetes 集群中的一个节点,就必须在集群的 kube-apiserver 上注册。可要想跟 apiserver 打交道,这台机器就必须要获取到相应的证书文件(CA 文件)。为了能够一键安装,我们就不能让用户去 Master 节点上手动拷贝这些文件。
所以,kubeadm 至少需要发起一次“不安全模式”的访问到 kube-apiserver,从而拿到保存在 ConfigMap 中的 cluster-info(它保存了 APIServer 的授权信息)。而 bootstrap token,扮演的就是这个过程中的安全验证的角色。
只要有了 cluster-info 里的 kube-apiserver 的地址、端口、证书,kubelet 就可以以“安全模式”连接到 apiserver 上,这样一个新的节点就部署完成了。
接下来,你只要在其他节点上重复这个指令就可以了。
kubeadm 的部署配置参数
前面讲解了 kubeadm 部署 Kubernetes 集群最关键的两个步骤,kubeadm init 和 kubeadm join。相信你一定会有这样的疑问:kubeadm 确实简单易用,可是我又该如何定制我的集群组件参数呢?
比如,我要指定 kube-apiserver 的启动参数,该怎么办?
在这里,我强烈推荐你在使用 kubeadm init 部署 Master 节点时,使用下面这条指令:
$ kubeadm init --config kubeadm.yaml
这时,你就可以给 kubeadm 提供一个 YAML 文件(比如,kubeadm.yaml),它的内容如下所示(我仅列举了主要部分):
apiVersion: kubeadm.k8s.io/v1alpha2
kind: MasterConfiguration
kubernetesVersion: v1.11.0
api:advertiseAddress: 192.168.0.102bindPort: 6443...
etcd:local:dataDir: /var/lib/etcdimage: ""
imageRepository: k8s.gcr.io
kubeProxy:config:bindAddress: 0.0.0.0...
kubeletConfiguration:baseConfig:address: 0.0.0.0...
networking:dnsDomain: cluster.localpodSubnet: ""serviceSubnet: 10.96.0.0/12
nodeRegistration:criSocket: /var/run/dockershim.sock...
通过制定这样一个部署参数配置文件,你就可以很方便地在这个文件里填写各种自定义的部署参数了。比如,我现在要指定 kube-apiserver 的参数,那么我只要在这个文件里加上这样一段信息:
...
apiServerExtraArgs:advertise-address: 192.168.0.103anonymous-auth: falseenable-admission-plugins: AlwaysPullImages,DefaultStorageClassaudit-log-path: /home/johndoe/audit.log
然后,kubeadm 就会使用上面这些信息替换 /etc/kubernetes/manifests/kube-apiserver.yaml 里的 command 字段里的参数了。
而这个 YAML 文件提供的可配置项远不止这些。比如,你还可以修改 kubelet 和 kube-proxy 的配置,修改 Kubernetes 使用的基础镜像的 URL(默认的 k8s.gcr.io/xxx 镜像 URL 在国内访问是有困难的),指定自己的证书文件,指定特殊的容器运行时等等。
笔记来源于:极客时间《深入剖析Kubernetes》
相关文章:

Kubernetes 一键部署利器:kubeadm
文章目录集群部署痛点kubeadm 的工作原理kubeadm init 的工作流程kubeadm join 的工作流程kubeadm 的部署配置参数集群部署痛点 Kubernetes 的部署一直以来都是挡在初学者前面的一只“拦路虎”。尤其是在 Kubernetes 项目发布初期,它的部署完全要依靠一堆由社区维护…...
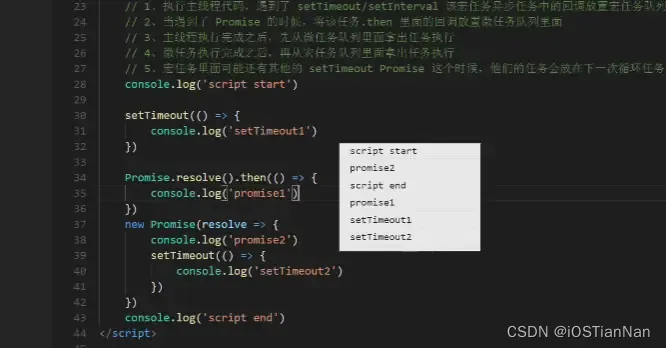
[jS 事件循环理解] 主线程 宏任务 微任务 - 执行顺序优先级理解
最近看了一个帖子 事件循环机制-宏任务-微任务 把js单线程中 , 主线程 | 宏任务 | 微任务 的调用顺序讲解的很直白精巧 , 记录一下以供查阅 1.主线程, 可以理解为从上到下顺序执行的一个js线程 2. 宏任务 script / setTimeOut /setInterval等 3. 微任务主要有promise等 4. 热…...

顺序表和链表的比较
这两个结构各有优势,相辅相成。 顺序表: 优点: 1.支持随机访问。 2.CPU高速缓存命中率更高。(物理空间连续) 缺点: 1.头部和中部插入和删除时间效率低(O(n))。 2.连续的物理空间,空间不够后需要增容:…...

Java为什么只能单继承???
目录 先屡清楚继承和实现的区别: 分析原因: 多继承虽然能使子类同时拥有多个父类的特征,但是其缺点也是很显著的,主要有两方面: (1)如果在一个子类继承的多个父类中拥有相同名字的实例变量,子类在引用该…...

数据安全-分类分级 调研分析报告
目录 前言一、数据分类分级概述1.数据分类2.数据分级二、数据分类分级原则三、数据分类分级的框架和方法1.数据分类分级的框架2.分类标准分类常见的方法2.1 MECE2.2 线分法和面分法及混合分法2.3 数据主题域2.4 技术选型维度2.5 以业务应用维度2.6 信息安全隐私方面的分类法3.分…...
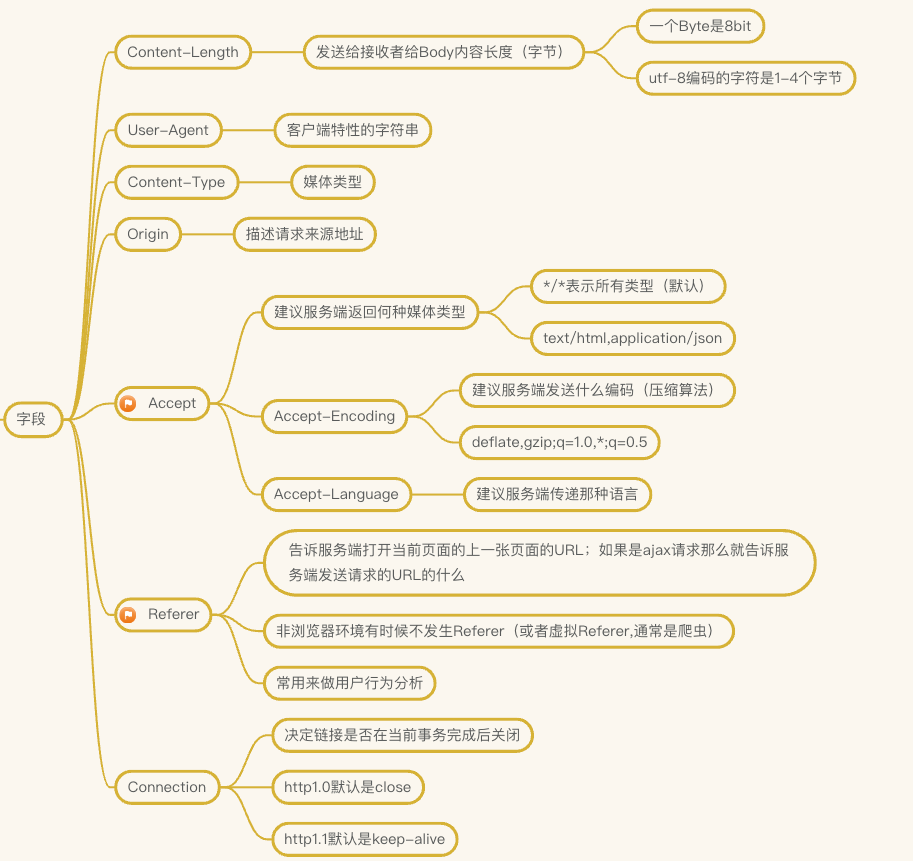
浏览器对象详解
文章目录浏览器对象详解一、参考资料二、认识浏览器运行态下的 js1.问:是否了解浏览器的执行态(分层设计)?2.BOM1.[location](https://developer.mozilla.org/zh-CN/docs/Web/API/Location)拓展方向:2.[History](https…...
)
异步电路后端实现流程(cdc signOff 后端做什么)
一种后端异步电路的signOff流程同步电路和异步电路分别signOff对于同步电路,后端会分析sta setup/hold,这里不在赘述。在该scenario下 异步电路是不会分析,也不会关注异步电路之间的走线在cdc scenario(mode)下sdc有一下设置:将所…...

Linux网络编程实战介绍
文章目录 前言一、Linux网络编程介绍二、文章目录总结前言 本专栏将为大家讲解Linux网络编程的知识,本专栏只需要有C语言基础即可学习,学习本专栏将大大提高你的C语言水平,当然了我也还会在ARM板子上进行实验将Linux驱动也和网络编程联系起来,方便大家去实现自己的项目。我…...

C++概述 课堂笔记
函数的重载在C语言中函数名是唯一的,不可以重复定义,当我们利用函数执行,功能相似的函数,我们也不能使用同一个函数,比如说,求整型的函数,不能用来求浮点型、字符型。在C中引入函数重载的概念&a…...

一文读懂SpringBoot整合Elasticsearch(一)
(本篇文章主要介绍Spring Boot如何整合Elasticsearch,包括基本配置、数据操作、搜索功能等方面。) 一、前言 Elasticsearch是一款全文搜索引擎,可用于快速、准确地存储、搜索和分析大量数据。而Spring Boot是一款快速开发框架&a…...
(枚举)(前缀和)1230. K倍区间)
(数论)(枚举)(前缀和)1230. K倍区间
目录 题目链接 一些话 切入点 流程 套路 ac代码 题目链接 1230. K倍区间 - AcWing题库 ~数~啦!我草,又~在~水~字~数~啦!我草,又~在~水&…...

万字带你深入理解 Linux 虚拟内存管理(下)
接上文:万字带你深入理解 Linux 虚拟内存管理(上) 6. 程序编译后的二进制文件如何映射到虚拟内存空间中 经过前边这么多小节的内容介绍,现在我们已经熟悉了进程虚拟内存空间的布局,以及内核如何管理这些虚拟内存区域&…...

【iOS】—— JSONModel源码学习
JSONModel 文章目录JSONModel关于JSONModel的用法initWithDictionary等方法load方法实现load方法调用时机init方法__setup__方法__inspectProperties:方法__doesDictionary方法__importDictionary方法关于JSONModel的用法 可以参考之前写的博客:【iOS】—— JSONMo…...
单片机怎么实现真正的多线程?
所谓多线程都是模拟的,本质都是单线程,因为cpu同一时刻只能执行一段代码。模拟的多线程就是任务之间快速切换,看起来像同时执行的样子。据说最近有多核的单片机,不过成本应该会高很多。对于模拟的多线程,我知道的有两种…...

【LeetCode】剑指 Offer(23)
目录 题目:剑指 Offer 46. 把数字翻译成字符串 - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 写在最后: 题目:剑指 Offer 46. 把…...

[免费专栏] 汽车威胁狩猎之不应该相信的几个威胁狩猎误区
也许每个人出生的时候都以为这世界都是为他一个人而存在的,当他发现自己错的时候,他便开始长大 少走了弯路,也就错过了风景,无论如何,感谢经历 汽车威胁狩猎专栏长期更新,本篇最新内容请前往: …...

LinuxFTP文件传输服务和DNS域名解析服务
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...

二叉搜索树原理及底层实现
二叉搜索树BST 概念 二叉搜索树又称二叉排序树,它可以是一棵空树,或者是具有以下性质的二叉树:若它的左子树不为空,则左子树上所有节点的值都小于根节点的值;若它的右子树不为空,则右子树上所有节点的值都…...

python自动化办公(一)
本文代码参考其他教程书籍实现。 文章目录文件读写open函数读取文本文件写入文本文件文件和目录操作使用os库使用shutil库文件读写 open函数 open函数有8个参数,常用前4个,除了file参数外,其他参数都有默认值。file指定了要打开的文件名称&a…...
LeetCode - 198 打家劫舍
目录 题目来源 题目描述 示例 提示 题目解析 算法源码 题目来源 198. 打家劫舍 - 力扣(LeetCode) 题目描述 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装…...

从Simulink模型到C代码:Assignment模块的‘Index Mode’选Zero还是One?一个影响深远的决定
从Simulink模型到C代码:索引模式选择的工程实践指南 在嵌入式软件开发中,模型与代码的协同设计一直是提高开发效率的关键环节。当Simulink模型工程师将算法模型转换为C代码时,一个看似简单的参数配置——Assignment模块的"Index Mode&q…...

深度解析:3种高效的Windows依赖检测完整方案
深度解析:3种高效的Windows依赖检测完整方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist VisualCppRedist AIO项目是一个专业的Microsoft Visual …...

ArcGIS实战:从DEM数据到精美立体晕渲图的调色与渲染全流程
1. 认识DEM数据与立体晕渲图 第一次接触DEM数据时,我完全被那些密密麻麻的数字搞懵了。后来才发现,这些数字其实就是地形的"指纹"。DEM(Digital Elevation Model)就像是用数字搭建的微缩景观,每个像素点都记…...

我的世界手机版烦人的村民整合包下载基岩国际版2026最新版
在《我的世界》庞大的模组生态中,烦人的村民整合包(Annoying Villagers) 凭借颠覆性的 NPC 设定、硬核战斗机制与深度剧情互动,成为 Java 版最具影响力的高难度生存整合包之一。由 Pugilist_Steve 主导开发,最新 6.0 版…...

从ANSI到EBCDIC:跨越地域与时代的字符编码全景解析
1. 字符编码的前世今生:从ASCII到EBCDIC 第一次在Windows记事本里保存文件时,看到"ANSI"这个选项我就懵了——这玩意儿和ASCII有什么关系?后来在跨国项目里处理日文数据时,更被SJIS和EUC-JP搞得焦头烂额。字符编码就像…...

5大核心功能揭秘:如何用LeagueAkari游戏辅助工具提升竞技水平
5大核心功能揭秘:如何用LeagueAkari游戏辅助工具提升竞技水平 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit LeagueAkari是一款基…...

如果写好AI提示词:这份 Prompt 调试速查表帮你事半功倍
有句话说得好:"好的工程师和差的工程师的区别,不在于他们多聪明,而在于他们有没有一份好的排障清单。"这句话对 Prompt 工程也完全适用。最近三个月,我在 Claude 社区的 Discord 里帮人调试 Prompt。最常见的情况是什么…...
)
手把手教你用Arduino+ELM327读取OBD-II数据(附代码和常见故障码解析)
用Arduino与ELM327打造智能车载数据监控系统 在创客圈子里,车辆数据监控一直是个既实用又有趣的领域。想象一下,用不到200元的硬件成本,就能实时读取发动机转速、油耗数据甚至诊断车辆潜在故障——这正是Arduino与ELM327组合带来的可能性。不…...

终极免费风扇控制软件:FanControl完整配置与优化指南
终极免费风扇控制软件:FanControl完整配置与优化指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...

三步掌握MarkDownload:将网页内容高效转换为结构化笔记
三步掌握MarkDownload:将网页内容高效转换为结构化笔记 【免费下载链接】markdownload A Firefox and Google Chrome extension to clip websites and download them into a readable markdown file. 项目地址: https://gitcode.com/gh_mirrors/ma/markdownload …...