Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method--论文笔记
论文笔记
资料
1.代码地址
https://github.com/iBelieveCJM/pseudo_label-pytorch
2.论文地址
3.数据集地址
论文摘要的翻译
本文提出了一种简单有效的深度神经网络半监督学习方法。基本上,所提出的网络是以有监督的方式同时使用标记数据和未标记数据来训练的。对于未标记的数据,只要选取具有最大预测概率的类别,就可以使用伪标签,就好像它们是真标签一样。这实际上等同于熵正则化。它支持类之间的低密度分离,这是半监督学习通常假设的先验条件。在MNIST手写数字数据集上,利用去噪自动编码器和丢弃,这种简单的方法在标签数据非常少的情况下优于传统的半监督学习方法。
1背景
所有训练深度神经网络的成功方法都有一个共同点:它们都依赖于无监督学习算法。大多数工作分两个主要阶段进行。在第一阶段,无监督预训练,所有层的权重通过这种分层的无监督训练来初始化。在第二阶段,微调,在有监督的方式下,使用反向传播算法用标签全局地训练权值。所有这些方法也都以半监督的方式工作。我们只需要使用额外的未标记数据来进行无监督的预训练。
我们提出了一种更简单的半监督方式训练神经网络的方法。基本上,所提出的网络是以有监督的方式同时使用标记数据和未标记数据来训练的。对于未标记的数据,只需选取每次权重更新具有最大预测概率的类,就像使用真标签一样使用伪标签。该方法原则上可以结合几乎所有的神经网络模型和训练方法。
这种方法实际上等同于熵正则化(Granvalet等人,2006年)。类概率的条件熵可用于类重叠的度量。通过最小化未标记数据的熵,可以减少类概率分布的重叠性。它支持类之间的低密度分离,这是半监督学习的常见先验假设。
2论文的创新点
3 论文方法的概述
3.1 思路
伪标签是未标记数据的目标类,就好像它们是真标签一样。我们只选取对每个未标记样本具有最大预测概率的类别。
y i ′ = { 1 if i = argmax i ′ f i ′ ( x ) 0 otherwise y_i^{\prime}=\begin{cases}1&\text{if }i=\text{argmax}_{i'}f_{i'}(x)\\0&\text{otherwise}\end{cases} yi′={10if i=argmaxi′fi′(x)otherwise我们在Dropout的微调阶段使用伪标签。用标记和未标记的数据同时以有监督的方式训练预先训练的网络。对于未标记的数据,每次权值更新重新计算的伪标签被用于相同的监督学习任务的损失函数。
由于有标签数据和无标签数据的总数有很大不同,并且它们之间的训练平衡对网络性能非常重要,因此总体损失函数为 L = 1 n ∑ m = 1 n ∑ i = 1 C L ( y i m , f i m ) + α ( t ) 1 n ′ ∑ m = 1 n ′ ∑ i = 1 C L ( y i ′ m , f i ′ m L=\frac{1}{n}\sum_{m=1}^{n}\sum_{i=1}^{C}L(y_{i}^{m},f_{i}^{m})+\alpha(t)\frac{1}{n'}\sum_{m=1}^{n'}\sum_{i=1}^{C}L(y_{i}^{\prime m},f_{i}^{\prime m} L=n1m=1∑ni=1∑CL(yim,fim)+α(t)n′1m=1∑n′i=1∑CL(yi′m,fi′m
其中n是SGD的已标记数据中的批次数, n ′ n\prime n′用于未标记数据, f i m f^m_i fim是已标记数据中 m m m个样本的输出单位, y i m y^m_i yim是标签, f i ′ m f^{\prime m}_{i} fi′m用于未标记数据, y i ′ m y^{\prime m}_{i} yi′m是未标记数据的伪标签, α ( t ) \alpha(t) α(t)是平衡它们的系数。
α ( t ) \alpha(t) α(t)的合理调度对网络性能非常重要。如果 α ( t ) \alpha(t) α(t)太高,即使对于已标记的数据,也会干扰训练。而如果 α ( t ) \alpha(t) α(t)太小了,我们就不能利用未标记数据的好处。此外, α ( t ) \alpha(t) α(t)缓慢增加的确定性退火过程有望帮助优化过程避免较差的局部极小值,从而使未标记数据的伪标签尽可能类似于真实标签。 α ( t ) = { 0 t < T 1 t − T 1 T 2 − T 1 α f T 1 ≤ t < T 2 α f T 2 ≤ t \alpha(t)=\begin{cases}0&t<T_1\\\frac{t-T_1}{T_2-T_1}\alpha_f&T_1\leq t<T_2\\\alpha_f&T_2\leq t\end{cases} α(t)=⎩ ⎨ ⎧0T2−T1t−T1αfαft<T1T1≤t<T2T2≤t在 α f {\alpha}_f αf=3、 T 1 T_1 T1=100、 T 2 T_2 T2=600的情况下,不进行预训练;在DAE的情况下, T 1 T_1 T1=200、 T 2 T_2 T2=800。
3.2 Pseudo-Label为什么有效?
半监督学习的目标是利用未标记的数据来提高泛化性能。聚集学习假设指出,决策边界应位于低密度区域,以提高泛化性能。
最近提出的使用流形学习训练神经网络的方法,如半监督嵌入和流形切线分类器,都利用了这一假设。半监督嵌入使用基于嵌入的正则化来提高深度神经网络的泛化性能。由于数据样本的邻居通过嵌入惩罚项与样本具有相似的激活,因此高密度区域的数据样本更有可能具有相同的标签。流形切线分类器鼓励网络输出对低维流形方向的变化不敏感。因此,同样的目的也达到了。
3.3 Entropy Regularization
在最大后验估计的框架下,熵正则化是一种从未标记数据中获益的方法。该方案通过最小化未标记数据的类概率的条件熵来支持类之间的低密度分离,而不需要对密度进行任何建模。 H ( y ∣ x ′ ) = − 1 n ′ ∑ m = 1 n ′ ∑ i = 1 C P ( y i m = 1 ∣ x ′ m ) log P ( y i m = 1 ) H(y|x')=-\frac{1}{n'}\sum_{m=1}^{n'}\sum_{i=1}^{C}P(y_{i}^{m}=1|x'^{m})\operatorname{log}P(y_{i}^{m}=1) H(y∣x′)=−n′1m=1∑n′i=1∑CP(yim=1∣x′m)logP(yim=1)
其中 n ′ n^\prime n′是未标记数据的数目, C C C是类数, y i m y^m_i yim是第 m m m个未标记样本的未知标记, x ′ m x^{\prime m} x′m是第m个未标记样本的输入向量,熵是类重叠的一种度量。随着类重叠的减少,决策边界上的数据点密度变得更低。
MAP估计被定义为后验分布的最大值: C ( θ , λ ) = ∑ m = 1 n log P ( y m ∣ x m ; θ ) − λ H ( y ∣ x ′ ; θ ) C(\theta,\lambda)=\sum_{m=1}^n\log P(y^m|x^m;\theta)-\lambda H(y|x';\theta) C(θ,λ)=m=1∑nlogP(ym∣xm;θ)−λH(y∣x′;θ)
其中n是标记数据的数目, x m x^m xm是第 m m m个标记样本, λ λ λ是平衡两项的系数。通过最大化已标记数据(第一项)的条件对数似然和最小化未标记数据(第二项)的熵,可以获得更好的泛化性能。
图1示出了t-SNE 在MNIST测试数据(未包括在未标记数据中)的网络输出的2D嵌入结果。神经网络用600个已标记数据以及60000个未标记数据和伪标签进行训练。虽然在两种情况下训练误差为零,但通过使用未标记数据和伪标签进行训练,测试数据的网络输出更接近于1-OFK码,换言之,(17)的熵被最小化。

表2显示了(17)的估计熵。虽然两种情况下已标记数据的熵都接近于零,但通过伪标签训练,未标记数据的熵变低,另外,测试数据的熵也随之降低。这使得分类问题变得更容易,甚至对于测试数据也是如此,并且使得决策边界处的数据点密度更低。根据聚类假设,我们可以得到更好的泛化性能。

3.4 Training with Pseudo-Label as Entropy Regularization
我们的方法通过对未标记数据和伪标签的训练,鼓励预测的类别概率接近K中的1-of-code,从而使公式(17)的熵最小。因此,我们的方法等价于熵正则化。(18)的第一项对应于(15)的第一项,(18)的第二项对应于(15)的第二项,α对应于λ。
相关文章:
Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method--论文笔记
论文笔记 资料 1.代码地址 https://github.com/iBelieveCJM/pseudo_label-pytorch 2.论文地址 3.数据集地址 论文摘要的翻译 本文提出了一种简单有效的深度神经网络半监督学习方法。基本上,所提出的网络是以有监督的方式同时使用标记数据和未标记数据来训练的…...

信息收集-arping
信息收集-arping 简介 arping 是一个用于发送 ARP 请求和接收 ARP 回复的工具。它通常用于检查网络中的 IP 地址是否被使用,或发现网络中的重复 IP 地址。arping 工具类似于 ping 命令,但它使用的是 ARP 协议而不是 ICMP 协议。在 Kali Linux 中&#…...

一文了解常见DNS问题
当企业的DNS出现故障时,为不影响企业的正常运行,团队需要能够快速确定问题的性质和范围。那么有哪些常见的DNS问题呢? 域名解析失败: 当您输入一个域名,但无法获取到与之对应的IP地址,导致无法访问相应的网…...

TCP/IP 网络协议族分层
TCP/IP协议族 TCP/IP不单是TCP和IP两个协议,TCP/IP实际上是一组协议,它包括上百个各种功能的协议,如:远程登录、文件传输和电子邮件等,当然,也包括TCP、IP协议 它将软件通信过程抽象化为四个抽象层&#…...

Qt:5.QWidget属性介绍(Enabled属性-控件可用性设置、geometry属性-控件位置/大小设置)
目录 一、 QWidget属性的介绍: 二、Enabled属性-控件可用性设置: 2.1Enabled属性的介绍: 2.2获取控件当前可用状态的api——isEnabled(): 2.3设置控件当前的可用状态的api—— setEnabled() : 2.4 实例ÿ…...

NoSQL 非关系型数据库 Redis 的使用:
redis是基于内存型的NoSQL 非关系型数据库,本内容只针对有基础的小伙伴, 因为楼主不会做更多的解释,而是记录更多的技术接口使用,毕竟楼主不是做教学的,没有教学经验。 关于redis的介绍请自行搜索查阅。 使用redis数据…...

python库(5):Psutil库实现系统和硬件监控工具
1 psutil简介 psutil(process and system utilities)是一个跨平台库,用于检索运行中进程和系统利用率(包括 CPU、内存、磁盘、网络等)的信息,可以提供丰富的系统监控功能。 2 psutil安装 pip install -i …...

实验四 图像增强—灰度变换之直方图变换
一.实验目的 1.掌握灰度直方图的概念及其计算方法; 2.熟练掌握直方图均衡化计算过程;了解直方图规定化的计算过程; 3.了解色彩直方图的概念和计算方法 二.实验内容: …...

使用el-col和el-row布局,有版心,一页有两栏布局 三栏布局 四栏布局 使用vue动态渲染元素
使用Vue结合Element UI的el-row和el-col组件来实现版心布局,并动态渲染不同栏数的布局,可以通过以下步骤实现: 定义版心容器:使用el-container来定义整个页面的容器,其中el-header、el-main、el-footer分别定义头部、主…...

中软国际加入龙蜥社区,促进“技术+生态”双向赋能
近日,中软国际有限公司(简称“中软国际”)签署了 CLA(Contributor License Agreement,贡献者许可协议),正式加入龙蜥社区(OpenAnolis)。 中软国际创立于 2000 年&#x…...
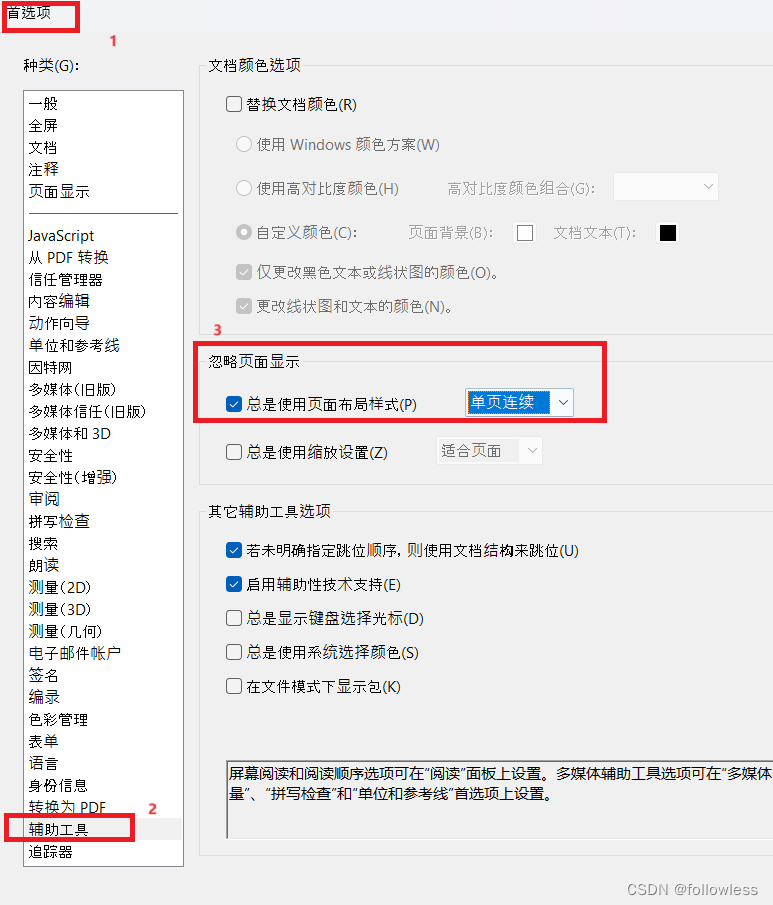
adobe pdf设置默认打开是滚动而不是单页视图
上班公司用adobe pdf,自己还不能安装其它软件。 每次打开pdf,总是默认单页视图,修改滚动后,下次打开又 一样,有时候比较烦。 后面打开编辑->首选项, 如下修改,下次打开就是默认滚动了...

React Hooks 深度解析
Hooks简介 诞生背景: 在React 16.8之前的版本中,组件主要分为函数组件和类组件两大类。函数组件简单轻量,但不支持状态(state)和生命周期方法;而类组件虽然功能强大,但编写和维护起来相对复杂。…...

14-32 剑和诗人6 - GenAI 重塑 SRE 和云工程实践
在不断发展的软件开发和运营领域,各种学科的融合催生了新的范式和实践,旨在简化流程、加强协作和推动创新。DevSecOps、站点可靠性工程 (SRE)、平台工程和云工程已成为支持现代软件系统的重要支柱,每个支柱都解决了独特的挑战和要求。 然而&…...

Towards Deep Learning Models Resistant to Adversarial Attacks
这篇论文的主要内容是关于开发对抗攻击具有抗性的深度学习模型。对抗攻击是通过对输入数据进行微小且精心设计的扰动,诱使深度学习模型做出错误的预测。这种攻击在图像识别、语音识别和自然语言处理等任务中尤为突出。 这篇论文的主要内容是关于开发对抗攻击具有抗…...

2、Key的层级结构
Key的层级结构 Redis的key允许有多个单词形成层级结构,多个单词之间用’:隔开。 举个例子: 我们有一个项目project,有user和product俩种不同的数据类型,那么我们可以这么定义key: user相关的key:project:user:1 pr…...

如何在Qt使用uchardet库
如何在 Qt 中使用 uchardet 库 文章目录 如何在 Qt 中使用 uchardet 库一、简介二、uchardet库的下载三、在Qt中直接调用四、编译成库文件后调用4.1 编译工具下载4.2 uchardet源码编译4.3 测试编译文件4.4 Qt中使用 五、一些小问题5.1 测试文件存在的问题5.2 uchardet库相关 六…...

G9 - ACGAN理论与实战
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目录 环境步骤环境设置数据准备工具方法模型设计模型训练模型效果展示 总结与心得体会 上周已经简单的了解了ACGAN的原理,并且不经实践的编写了部分…...
合合信息大模型“加速器”亮相2024世界人工智能大会,助力大模型学好“专业课”
7月4日至7日,2024世界人工智能大会在上海拉开帷幕。现阶段,“百模大战”现象背后的中国大模型发展前景与堵点仍然是各界关注的焦点。如何帮助大模型在信息的海洋中快速找准航向,在数据的荒漠中找到高质量的“水源”?合合信息在本次…...

bond网络配置文件中 interface-name 与 id 的区别
在bond网络配置文件中,interface-name和id是两个不同的参数,它们有如下区别: interface-name:该参数用于指定bond设备所使用的物理网卡接口的名称。可以设置一个或多个接口名称,多个接口名称之间使用逗号分隔。例如&am…...
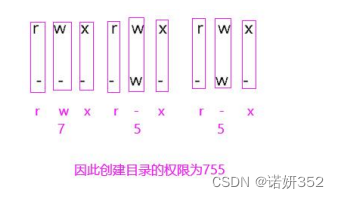
Linux权限概述
一、权限概述 1.权限的基本概念 2.为什么要设置权限 3.linux用户的身份类别 4.user文件的拥有者 5.group文件所属组内用户 6.other其他用户 7.特殊用户root 二、普通权限管理 1.ls -l查看文件权限 2.文件类型以及权限解析 3.文件或文件夹的权限设置 4.通过数字给文件…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

2026长沙智能家居品牌实测,这些本地老牌值得选
2026年,长沙的智能家居市场已经从“概念热”转向“落地战”。我走访了长沙多个本地服务商,实测了不同品牌在别墅、酒店、大平层等场景的真实表现。今天,结合数据与案例,分享几个值得关注的本地品牌,尤其是深耕8年以上的…...

Unity动态自然系统:Forest Environment-Dynamic Nature深度解析
1. 这不是“贴图堆砌”,而是自然系统级建模:Forest Environment-Dynamic Nature 的真实定位你有没有试过在Unity里拖进几棵树、铺点草、加个天空盒,然后发现场景像一张静止的风景明信片——风不动、叶不摇、雨不落、雾不散?我做过…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

Xia Sql插件:可调试的SQL注入决策引擎
1. 这不是又一个“自动扫SQL”的插件,而是把渗透工程师的判断逻辑塞进了Burp里你有没有过这种经历:在Burp Proxy里看着一堆GET参数、POST JSON、Cookie字段,心里清楚“这里大概率能注入”,但手动拼payload试了七八轮,还…...

使用libusb-win32驱动复活老旧USB硬件:以Elektor Magic Eye为例
1. 项目概述:让老硬件在新时代焕发新生手头有一台十多年前的《Elektor》杂志上刊登的“Magic Eye EM84”复古VFD显示屏项目,想把它接到Windows 10电脑上当个酷炫的CPU占用率显示器,却发现官方提供的“AVR309”USB驱动在新系统上彻底罢工了。这…...
)
大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性)
更多请点击: https://codechina.net 第一章:大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性) 传统LLM测试常聚焦于准确率或BLEU等静态指标,而Cla…...