昇思25天学习打卡营第17天(+1)|Diffusion扩散模型
1. 学习内容复盘
本文基于Hugging Face:The Annotated Diffusion Model一文翻译迁移而来,同时参考了由浅入深了解Diffusion Model一文。
本教程在Jupyter Notebook上成功运行。如您下载本文档为Python文件,执行Python文件时,请确保执行环境安装了GUI界面。
关于扩散模型(Diffusion Models)有很多种理解,本文的介绍是基于denoising diffusion probabilistic model (DDPM),DDPM已经在(无)条件图像/音频/视频生成领域取得了较多显著的成果,现有的比较受欢迎的的例子包括由OpenAI主导的GLIDE和DALL-E 2、由海德堡大学主导的潜在扩散和由Google Brain主导的图像生成。
实际上生成模型的扩散概念已经在(Sohl-Dickstein et al., 2015)中介绍过。然而,直到(Song et al., 2019)(斯坦福大学)和(Ho et al., 2020)(在Google Brain)才各自独立地改进了这种方法。
本文是在Phil Wang基于PyTorch框架的复现的基础上(而它本身又是基于TensorFlow实现),迁移到MindSpore AI框架上实现的。

实验中我们采用离散时间(潜在变量模型)的观点,另外,读者也可以查看有关于扩散模型的其他几个观点!
实验开始之前请确保安装并导入所需的库(假设您已经安装了MindSpore、download、dataset、matplotlib以及tqdm)。
模型简介
什么是Diffusion Model?
如果将Diffusion与其他生成模型(如Normalizing Flows、GAN或VAE)进行比较,它并没有那么复杂,它们都将噪声从一些简单分布转换为数据样本,Diffusion也是从纯噪声开始通过一个神经网络学习逐步去噪,最终得到一个实际图像。 Diffusion对于图像的处理包括以下两个过程:
- 我们选择的固定(或预定义)正向扩散过程 q𝑞 :它逐渐将高斯噪声添加到图像中,直到最终得到纯噪声
- 一个学习的反向去噪的扩散过程 pθ𝑝𝜃 :通过训练神经网络从纯噪声开始逐渐对图像去噪,直到最终得到一个实际的图像

由 t𝑡 索引的正向和反向过程都发生在某些有限时间步长 T𝑇(DDPM作者使用 T=1000𝑇=1000)内。从t=0𝑡=0开始,在数据分布中采样真实图像 x0𝑥0(本文使用一张来自ImageNet的猫图像形象的展示了diffusion正向添加噪声的过程),正向过程在每个时间步长 t𝑡 都从高斯分布中采样一些噪声,再添加到上一个时刻的图像中。假定给定一个足够大的 T𝑇 和一个在每个时间步长添加噪声的良好时间表,您最终会在 t=T𝑡=𝑇 通过渐进的过程得到所谓的各向同性的高斯分布。
扩散模型实现原理
Diffusion 前向过程
所谓前向过程,即向图片上加噪声的过程。虽然这个步骤无法做到图片生成,但这是理解diffusion model以及构建训练样本至关重要的一步。 首先我们需要一个可控的损失函数,并运用神经网络对其进行优化。
设 𝑞(𝑥0) 是真实数据分布,由于𝑥0∼𝑞(𝑥0) ,所以我们可以从这个分布中采样以获得图像 𝑥0 。接下来我们定义前向扩散过程𝑞(𝑥𝑡|𝑥𝑡−1) ,在前向过程中我们会根据已知的方差 0<β1<β2<...<βT<1在每个时间步长 t 添加高斯噪声,由于前向过程的每个时刻 t 只与时刻 t-1 有关,所以也可以看做马尔科夫过程:
q(xt|xt−1)=N(xt;√1−βtxt−1,βtI)
回想一下,正态分布(也称为高斯分布)由两个参数定义:平均值 𝜇 和方差 𝜎2≥0 。基本上,在每个时间步长 𝑡 处的产生的每个新的(轻微噪声)图像都是从条件高斯分布中绘制的,其中
q(μt)=√1−βtxt−1
我们可以通过采样 𝜖∼𝑁(0,𝐼) 然后设置
q(xt)=√1−βtxt−1+√βtϵ
请注意, 𝛽𝑡 在每个时间步长 𝑡 (因此是下标)不是恒定的:事实上,我们定义了一个所谓的“动态方差”的方法,使得每个时间步长的 𝛽𝑡 可以是线性的、二次的、余弦的等(有点像动态学习率方法)。
因此,如果我们适当设置时间表,从 𝑥0 开始,我们最终得到 𝑥1,...,𝑥𝑡,...,𝑥𝑇,即随着 𝑡 的增大 𝑥𝑡 会越来越接近纯噪声,而𝑥𝑇 就是纯高斯噪声。
那么,如果我们知道条件概率分布𝑝(𝑥𝑡−1|𝑥𝑡) ,我们就可以反向运行这个过程:通过采样一些随机高斯噪声 𝑥𝑇,然后逐渐去噪它,最终得到真实分布𝑥0 中的样本。但是,我们不知道条件概率分布𝑝(𝑥𝑡−1|𝑥𝑡) 。这很棘手,因为需要知道所有可能图像的分布,才能计算这个条件概率。
Diffusion 逆向过程
为了解决上述问题,我们将利用神经网络来近似(学习)这个条件概率分布 𝑝𝜃(𝑥𝑡−1|𝑥𝑡) , 其中 𝜃 是神经网络的参数。如果说前向过程(forward)是加噪的过程,那么逆向过程(reverse)就是diffusion的去噪推断过程,而通过神经网络学习并表示 𝑝𝜃(𝑥𝑡−1|𝑥𝑡) 的过程就是Diffusion 逆向去噪的核心。
现在,我们知道了需要一个神经网络来学习逆向过程的(条件)概率分布。我们假设这个反向过程也是高斯的,任何高斯分布都由2个参数定义:
- 由𝜇𝜃 参数化的平均值
- 由 𝜇𝜃 参数化的方差
综上,我们可以将逆向过程公式化为
𝑝𝜃(𝑥𝑡−1|𝑥𝑡)=𝑁(𝑥𝑡−1;𝜇𝜃(𝑥𝑡,𝑡),Σ𝜃(𝑥𝑡,𝑡))
其中平均值和方差也取决于噪声水平 𝑡 ,神经网络需要通过学习来表示这些均值和方差。
- 注意,DDPM的作者决定保持方差固定,让神经网络只学习(表示)这个条件概率分布的平均值 𝜇𝜃 。
- 本文我们同样假设神经网络只需要学习(表示)这个条件概率分布的平均值 𝜇𝜃 。
为了导出一个目标函数来学习反向过程的平均值,作者观察到 𝑞 和 𝑝𝜃 的组合可以被视为变分自动编码器(VAE)。因此,变分下界(也称为ELBO)可用于最小化真值数据样本 𝑥0 的似然负对数(有关ELBO的详细信息,请参阅VAE论文(Kingma等人,2013年)),该过程的ELBO是每个时间步长的损失之和 L=L0+L1+...+LT ,其中,每项的损失 Lt (除了 L0 )实际上是2个高斯分布之间的KL发散,可以明确地写为相对于均值的L2-loss!
如Sohl-Dickstein等人所示,构建Diffusion正向过程的直接结果是我们可以在条件是 𝑥0 (因为高斯和也是高斯)的情况下,在任意噪声水平上采样𝑥𝑡 ,而不需要重复应用 𝑞 去采样 𝑥𝑡 ,这非常方便。使用
αt:=1−βt
¯αt:=Πts=1αs
我们就有
q(xt|x0)=N(xt;√¯αtx0,(1−¯αt)I)
这意味着我们可以采样高斯噪声并适当地缩放它,然后将其添加到 𝑥0 中,直接获得 xt 。
请注意,¯αt 是已知 βt方差计划的函数,因此也是已知的,可以预先计算。这允许我们在训练期间优化损失函数 L的随机项。或者换句话说,在训练期间随机采样 t并优化 Lt。
正如Ho等人所展示的那样,这种性质的另一个优点是可以重新参数化平均值,使神经网络学习(预测)构成损失的KL项中噪声的附加噪声。这意味着我们的神经网络变成了噪声预测器,而不是(直接)均值预测器。其中,平均值可以按如下方式计算:
μθ(xt,t)=1√αt(xt−βt√1−¯αtϵθ(xt,t))
最终的目标函数 Lt如下 (随机步长 t 由 (ϵ∼N(0,I))给定):
∥ϵ−ϵθ(xt,t)∥2=∥ϵ−ϵθ(√¯αtx0+√(1−¯αt)ϵ,t)∥2
在这里, x0是初始(真实,未损坏)图像, ϵ 是在时间步长 t采样的纯噪声,ϵθ(xt,t)是我们的神经网络。神经网络是基于真实噪声和预测高斯噪声之间的简单均方误差(MSE)进行优化的。
训练算法现在如下所示:

换句话说:
- 我们从真实未知和可能复杂的数据分布中随机抽取一个样本 q(x0)
请注意,此列表仅包括在撰写本文,即2022年6月7日之前的重要作品。
目前,扩散模型的主要(也许唯一)缺点是它们需要多次正向传递来生成图像(对于像GAN这样的生成模型来说,情况并非如此)。然而,有正在进行中的研究表明只需要10个去噪步骤就能实现高保真生成。
- 我们均匀地采样1和T之间的噪声水平t(即,随机时间步长)
- 我们从高斯分布中采样一些噪声,并使用上面定义的属性在 t 时间步上破坏输入
- 神经网络被训练以基于损坏的图像 xt 来预测这种噪声,即基于已知的时间表 xt 上施加的噪声
实际上,所有这些都是在批数据上使用随机梯度下降来优化神经网络完成的。
U-Net神经网络预测噪声
神经网络需要在特定时间步长接收带噪声的图像,并返回预测的噪声。请注意,预测噪声是与输入图像具有相同大小/分辨率的张量。因此,从技术上讲,网络接受并输出相同形状的张量。那么我们可以用什么类型的神经网络来实现呢?
这里通常使用的是非常相似的自动编码器,您可能还记得典型的"深度学习入门"教程。自动编码器在编码器和解码器之间有一个所谓的"bottleneck"层。编码器首先将图像编码为一个称为"bottleneck"的较小的隐藏表示,然后解码器将该隐藏表示解码回实际图像。这迫使网络只保留bottleneck层中最重要的信息。
在模型结构方面,DDPM的作者选择了U-Net,出自(Ronneberger et al.,2015)(当时,它在医学图像分割方面取得了最先进的结果)。这个网络就像任何自动编码器一样,在中间由一个bottleneck组成,确保网络只学习最重要的信息。重要的是,它在编码器和解码器之间引入了残差连接,极大地改善了梯度流(灵感来自于(He et al., 2015))。
- 神经网络被训练以基于损坏的图像 xt 来预测这种噪声,即基于已知的时间表 xt 上施加的噪声

-
-
可以看出,U-Net模型首先对输入进行下采样(即,在空间分辨率方面使输入更小),之后执行上采样。
构建Diffusion模型
下面,我们逐步构建Diffusion模型。
首先,我们定义了一些帮助函数和类,这些函数和类将在实现神经网络时使用。
位置向量
由于神经网络的参数在时间(噪声水平)上共享,作者使用正弦位置嵌入来编码t𝑡,灵感来自Transformer(Vaswani et al., 2017)。对于批处理中的每一张图像,神经网络"知道"它在哪个特定时间步长(噪声水平)上运行。
SinusoidalPositionEmbeddings模块采用(batch_size, 1)形状的张量作为输入(即批处理中几个有噪声图像的噪声水平),并将其转换为(batch_size, dim)形状的张量,其中dim是位置嵌入的尺寸。然后,我们将其添加到每个剩余块中。ResNet/ConvNeXT块
接下来,我们定义U-Net模型的核心构建块。DDPM作者使用了一个Wide ResNet块(Zagoruyko et al., 2016),但Phil Wang决定添加ConvNeXT(Liu et al., 2022)替换ResNet,因为后者在图像领域取得了巨大成功。
在最终的U-Net架构中,可以选择其中一个或另一个,本文选择ConvNeXT块构建U-Net模型。
Attention模块
接下来,我们定义Attention模块,DDPM作者将其添加到卷积块之间。Attention是著名的Transformer架构(Vaswani et al., 2017),在人工智能的各个领域都取得了巨大的成功,从NLP到蛋白质折叠。Phil Wang使用了两种注意力变体:一种是常规的multi-head self-attention(如Transformer中使用的),另一种是LinearAttention(Shen et al., 2018),其时间和内存要求在序列长度上线性缩放,而不是在常规注意力中缩放。 要想对Attention机制进行深入的了解,请参照Jay Allamar的精彩的博文。
组归一化
DDPM作者将U-Net的卷积/注意层与群归一化(Wu et al., 2018)。下面,我们定义一个
PreNorm类,将用于在注意层之前应用groupnorm。条件U-Net
我们已经定义了所有的构建块(位置嵌入、ResNet/ConvNeXT块、Attention和组归一化),现在需要定义整个神经网络了。请记住,网络 ϵθ(xt,t)𝜖𝜃(𝑥𝑡,𝑡) 的工作是接收一批噪声图像+噪声水平,并输出添加到输入中的噪声。
更具体的: 网络获取了一批
(batch_size, num_channels, height, width)形状的噪声图像和一批(batch_size, 1)形状的噪音水平作为输入,并返回(batch_size, num_channels, height, width)形状的张量。网络构建过程如下:
- 首先,将卷积层应用于噪声图像批上,并计算噪声水平的位置
- 接下来,应用一系列下采样级。每个下采样阶段由2个ResNet/ConvNeXT块 + groupnorm + attention + 残差连接 + 一个下采样操作组成
- 在网络的中间,再次应用ResNet或ConvNeXT块,并与attention交织
- 接下来,应用一系列上采样级。每个上采样级由2个ResNet/ConvNeXT块+ groupnorm + attention + 残差连接 + 一个上采样操作组成
- 最后,应用ResNet/ConvNeXT块,然后应用卷积层
最终,神经网络将层堆叠起来,就像它们是乐高积木一样(但重要的是了解它们是如何工作的)。
正向扩散
我们已经知道正向扩散过程在多个时间步长T中,从实际分布逐渐向图像添加噪声,根据差异计划进行正向扩散。最初的DDPM作者采用了线性时间表:
- 我们将正向过程方差设置为常数,从β1=10−4线性增加到βT=0.02。
- 但是,它在(Nichol et al., 2021)中表明,当使用余弦调度时,可以获得更好的结果。
数据准备与处理
在这里我们定义一个正则数据集。数据集可以来自简单的真实数据集的图像组成,如Fashion-MNIST、CIFAR-10或ImageNet,其中线性缩放为 [−1,1]。
每个图像的大小都会调整为相同的大小。有趣的是,图像也是随机水平翻转的。根据论文内容:我们在CIFAR10的训练中使用了随机水平翻转;我们尝试了有翻转和没有翻转的训练,并发现翻转可以稍微提高样本质量。
本实验我们选用Fashion_MNIST数据集,我们使用download下载并解压Fashion_MNIST数据集到指定路径。此数据集由已经具有相同分辨率的图像组成,即28x28。
采样
由于我们将在训练期间从模型中采样(以便跟踪进度),我们定义了下面的代码。采样在本文中总结为算法2:
-

从扩散模型生成新图像是通过反转扩散过程来实现的:我们从T开始,我们从高斯分布中采样纯噪声,然后使用我们的神经网络逐渐去噪(使用它所学习的条件概率),直到我们最终在时间步t=0结束。如上图所示,我们可以通过使用我们的噪声预测器插入平均值的重新参数化,导出一个降噪程度较低的图像 xt−1。请注意,方差是提前知道的。
理想情况下,我们最终会得到一个看起来像是来自真实数据分布的图像。
训练过程
下面,我们开始训练吧!详见平台实验结果。
推理过程(从模型中采样)
要从模型中采样,我们可以只使用上面定义的采样函数:详见平台实验结果。
总结
请注意,DDPM论文表明扩散模型是(非)条件图像有希望生成的方向。自那以后,diffusion得到了(极大的)改进,最明显的是文本条件图像生成。下面,我们列出了一些重要的(但远非详尽无遗的)后续工作:
- 我们从高斯分布中采样一些噪声,并使用上面定义的属性在 t 时间步上破坏输入
- 改进的去噪扩散概率模型(Nichol et al., 2021):发现学习条件分布的方差(除平均值外)有助于提高性能
- 用于高保真图像生成的级联扩散模型([Ho et al., 2021):引入级联扩散,它包括多个扩散模型的流水线,这些模型生成分辨率提高的图像,用于高保真图像合成
- 扩散模型在图像合成上击败了GANs(Dhariwal et al., 2021):表明扩散模型通过改进U-Net体系结构以及引入分类器指导,可以获得优于当前最先进的生成模型的图像样本质量
- 无分类器扩散指南([Ho et al., 2021):表明通过使用单个神经网络联合训练条件和无条件扩散模型,不需要分类器来指导扩散模型
- 具有CLIP Latents (DALL-E 2) 的分层文本条件图像生成 (Ramesh et al., 2022):在将文本标题转换为CLIP图像嵌入之前使用,然后扩散模型将其解码为图像
- 具有深度语言理解的真实文本到图像扩散模型(ImageGen)(Saharia et al., 2022):表明将大型预训练语言模型(例如T5)与级联扩散结合起来,对于文本到图像的合成很有效
参考
- The Annotated Diffusion Model
- 由浅入深了解Diffusion Model
-
2.平台实验结果












-
-
相关文章:
昇思25天学习打卡营第17天(+1)|Diffusion扩散模型
1. 学习内容复盘 本文基于Hugging Face:The Annotated Diffusion Model一文翻译迁移而来,同时参考了由浅入深了解Diffusion Model一文。 本教程在Jupyter Notebook上成功运行。如您下载本文档为Python文件,执行Python文件时,请确…...

【Leetcode笔记】406.根据身高重建队列
文章目录 1. 题目要求2.解题思路 注意3.ACM模式代码 1. 题目要求 2.解题思路 首先,按照每个人的身高属性(即people[i][0])来排队,顺序是从大到小降序排列,如果遇到同身高的,按照另一个属性(即p…...
)
Linux 安装pdfjam (PDF文件尺寸调整)
跟Ghostscript搭配使用,这样就可以将不同尺寸的PDF调整到相同尺寸合并了。 在 CentOS 上安装 pdfjam 需要安装 TeX Live,因为 pdfjam 是基于 TeX Live 的。以下是详细的步骤来安装 pdfjam: ### 步骤 1: 安装 EPEL 仓库 首先,安…...

python+playwright 学习-90 and_ 和 or_ 定位
前言 playwright 从v1.34 版本以后支持and_ 和 or_ 定位 XPath 中的and和or xpath 语法中我们常用的有text()、contains() 、ends_with()、starts_with() //*[text()="文本"] //*[contains(@id, "xx")] //...

亲子时光里的打脸高手,贾乃亮与甜馨的父爱如山
贾乃亮这波操作,简直是“实力打脸”界的MVP啊! 7月5号,他一甩手,甩出张合照, 瞬间让多少猜测纷飞的小伙伴直呼:“脸疼不?”带着咱家小甜心甜馨, 回了哈尔滨老家,这趟亲…...

MySQL篇-SQL优化实战
SQL优化措施 通过我们日常开发的经验可以整理出以下高效SQL的守则 表主键使用自增长bigint加适当的表索引,需要强关联字段建表时就加好索引,常见的有更新时间,单号等字段减少子查询,能用表关联的方式就不用子查询,可…...

【MySQL备份】Percona XtraBackup总结篇
目录 1.前言 2.问题总结 2.1.为什么在恢复备份前需要准备备份 2.1.1. 保证数据一致性 2.1.2. 完成崩溃恢复过程 2.1.3. 解决非锁定备份的特殊需求 2.1.4. 支持增量和差异备份 2.1.5. 优化恢复性能 2.2.Percona XtraBackup的工作原理 3.注意事项 1.前言 在历经了详尽…...

【Git 】规范 Git 提交信息的工具 Commitizen
Commitizen是一个用于规范Git提交信息的工具,它旨在帮助开发者生成符合一定规范和风格的提交信息,从而提高代码维护的效率,便于追踪和定位问题。以下是对Commitizen的详细介绍。 1、Commitizen的作用与优势 规范提交信息:通过提供…...

ABB PPC902AE1013BHE010751R0101控制器 处理器 模块
ABB PPC902AE1013BHE010751R0101 该模块是用于自动化和控制系统的高性能可编程控制器。它旨在与其他自动化和控制设备一起使用,以提供完整的系统解决方案 是一种数字输入/输出模块,提供了高水平的性能和可靠性。它专为苛刻的工业应用而设计,…...
)
大模型AIGC转行记录(一)
自从22年11月chat gpt上线以来,这一轮的技术浪潮便变得不可收拾。我记得那年9月份先是在技术圈内讨论,然后迅速地,全社会在讨论,各个科技巨头、金融机构、政府部门快速跟进。 软件开发行业过去与现状 我19年决定转码的时候&…...

element-ui Tree之懒加载叶子节点强制设置父级半选效果
效果: 前言: 我们是先只展示一级的,二级的数据是通过点击之后通过服务器获取数据,并不是全量数据直接一起返回回来的。 问题: 当你设置了默认选中的子节点,但是由于刚进入页面此时tree中数据暂是没有这个…...

Java项目:基于SSM框架实现的高校共享单车管理系统分前后台【ssm+B/S架构+源码+数据库+开题报告+任务书+毕业论文】
一、项目简介 本项目是一套基于SSM框架实现的高校共享单车管理系统 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 该系统功能完善、界面美观、操作简单、…...

【Android】自定义换肤框架02之自定义AssetManager和Resource
ResourceId是如何变成对应Resource的 在上一章中,我们已经讲过,apk中有个资源索引文件 其中保存了每个资源对应的id,name,type,path 资源文件的解析,主要涉及两个类,AssetManager和Resource …...

熵权法、熵值法、熵权TOPSIS三种方法的实用场景及优劣比较
在统计分析与决策分析中,熵权法、熵值法和熵权TOPSIS是三种常用的基于信息熵理论的方法。这些方法在处理多属性或多指标决策问题时,能够客观地反映数据的内在特性和各指标的相对重要性,为科学决策提供了有力支持。 熵权法 实用场景 熵权法是一种基于信息熵的客观赋权方法…...

无人机人员搜救
人员搜救-水域救援 水域搜救:快速水面搜查 物资抛投:救生物资抛投 绳索牵引:牵引救援绳索 领航船艇:水面侦察领航 人员搜救 昼夜搜救,精准定位 水域搜救 经纬 M300 RTK 搭载禅思 H20T 能够满足全天候作业需求&a…...

目标检测算法
讯飞星火 目标检测算法是计算机视觉领域的一项核心技术,用于在数字图像或视频中识别和定位一个或多个特定对象实例。这些算法通常需要确定对象的位置(例如通过边界框)和类别(例如人、汽车、狗等)。以下是一些流行的目…...
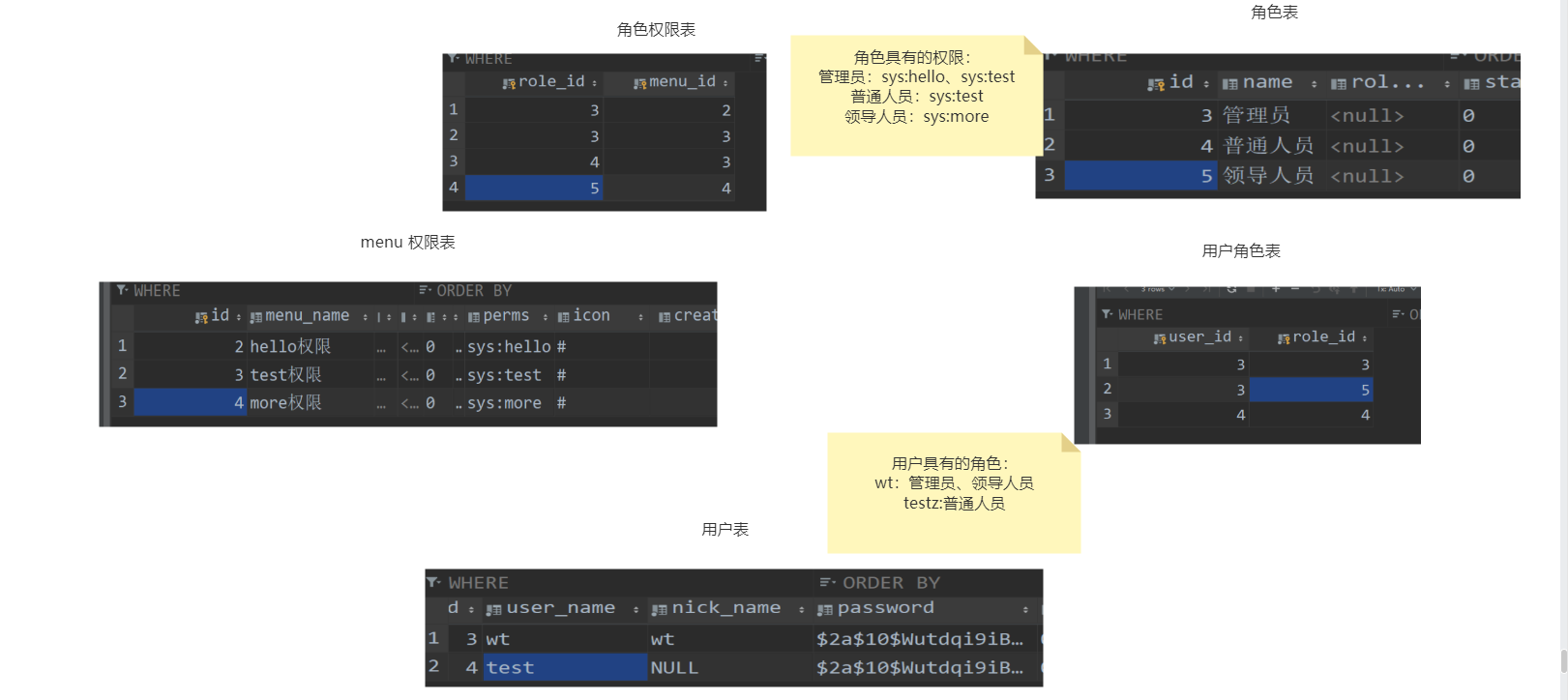
SpringSecurity 三更草堂学习笔记
0.简介 Spring Security是Spring家族中的一个安全管理框架。相比与另外一个安全框架Shiro,它提供了更丰富的功能,社区资源也比Shiro丰富。 一般来说中大型的项目都是使用SpringSecurity来做安全框架。小项目有Shiro的比较多,因为相比与Spring…...

鸿蒙生态应用开发白皮书V3.0
来源:华为: 近期历史回顾:...
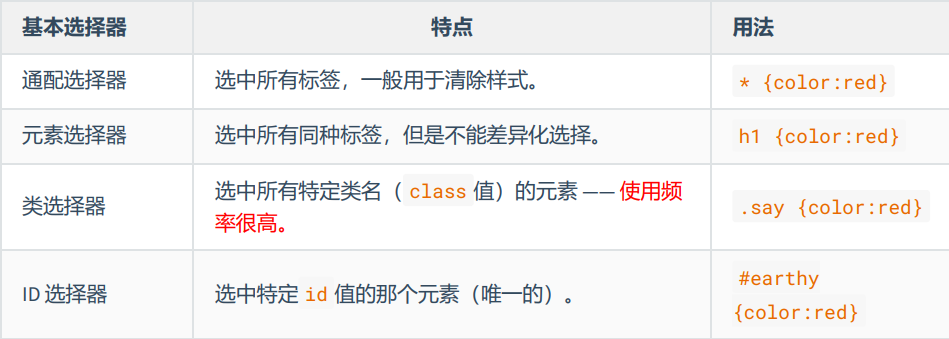
CSS - 深入理解选择器的使用方式
CSS基本选择器 通配选择器元素选择器类选择器id 选择器 通配选择器 作用:可以选中所有HTML元素。语法: * {属性名;属性值; }举例: /* 选中所有元素 */ * {color: orange;font-size: 40px; }在清除样式方面有很大作用 元素选择器…...

动手学深度学习(Pytorch版)代码实践 -循环神经网络-54~55循环神经网络的从零开始实现和简洁实现
54循环神经网络的从零开始实现 import math import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2l import matplotlib.pyplot as plt import liliPytorch as lp# 读取H.G.Wells的时光机器数据集 batch_size, num_steps 32, …...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

Blender渲染通道完全指南:如何像电影后期一样,分离出深度、阴影与反射图
Blender渲染通道完全指南:影视级后期制作的深度解析在数字内容创作领域,Blender已经从一个简单的3D建模工具成长为能够处理复杂视觉特效的全流程解决方案。对于追求影视级质量的中高级用户而言,掌握渲染通道技术是提升作品专业度的关键一步。…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

3分钟掌握抖音视频批量下载:解放双手的素材收集革命
3分钟掌握抖音视频批量下载:解放双手的素材收集革命 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为一个个手动保存抖音视频而烦恼吗?想要高效收集创作者素材却苦于没有合适的…...

还在古法编程?OpenAI Codex 全自动编程!稳定中转 Token 保姆级教程
OpenAI Codex 从安装到进阶实战|终端 AI 编程完全指南(2026 最新) 摘要:OpenAI Codex 是目前最强大的终端 AI 编程工具,支持代码生成、项目重构、Bug 修复、脚本自动化、批量代码优化等全场景能力。本文从零起步&…...

LSTM、GRU与注意力机制在股票预测中的性能对比与实战指南
1. 项目概述与核心价值在量化金融和算法交易这个行当里,预测股票价格走势一直是个充满诱惑又极具挑战的“圣杯”问题。传统的技术分析和基本面分析,虽然各有拥趸,但在面对市场的高噪声、非线性和突发性事件时,往往显得力不从心。我…...

Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑
Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你是否曾经因为复杂的视频编辑软件而头疼?想要一个免费、开源且…...