伯克利、斯坦福和CMU面向具身智能端到端操作联合发布开源通用机器人Policy,可支持多种机器人执行多种任务
不同于LLM或者MLLM那样用于上百亿甚至上千亿参数量的大模型,具身智能端到端大模型并不追求参数规模上的大,而是指其能吸收大量的数据,执行多种任务,并能具备一定的泛化能力,如笔者前博客里的RT1。目前该领域一个前沿工作是Octo: An Open-Source Generalist Robot Policy,该工作由美国Robot Learning顶尖高校(UC Berkeley,Stanford University,Carnegie Mellon University)联合推出,性能超过RT1,值得关注。值得注意的是该工作目前还处于ongoing状态,意味着还在推进中,并不成熟,有很大的提升空间。

项目目标和主要贡献
本工作目标为研发一个开源、广泛使用和通用的机器人操作模型打基础,为此本工作首先在Open X-Embodiment数据集上的800k条机器人轨迹数据上进行预训练。Octo具有高度灵活性:支持多RGB输入;可控制多种机械臂;可通过语言或者图像目标进行引导。更重要的是,Octo Transformer backbone的模块化注意力结构使其可被高效地微调适配拥有新传感器配置、动作空间和形态的机器人。
主要贡献包括:
- 预训练好的27M和93M参数量的权重;
- 微调到新目标领域(target domains)的脚本;
- 完整的预训练流程,包括高效的数据加载器以及相关工具链等,以方便研发人员follow。
octo模型架构
octo【英文全称是octopus,八爪鱼】模型可简单划分为三大部分:输入encoder,输出head和Transformer backbone。
输入encoder:使用一个浅层的CNN网络对图像进行编码,使用t5 base预训练语言encoder对文本进行编码,以及一个可学习的readout。更多细节:

图像编码
- 使用了一个浅层的CNN patch encoders,然后将编码之后的embeddings输入给transformer主干网络中进行学习,相对比于其他大型的image encoder,这样的好处是能够将大部分的数据信息都集中在可扩展的transformer里面训练,有利于网络能够学习到更多的信息,参考(Early Convolutions Help Transformers See Better)
- 如果训练过程是需要使用到目标图像(goal image)作为condition来训练网络,这里采用ViNT的方案将目标图像和观测进行提前融合,然后再将融合的patch token输入到transformer中进行训练,相当于提供一个目标与观测之间的关系信息的网络。
- 对比发现,使用ImageNet等非机器人相关的图像数据训练的权重与不加载权重,最终的效果都是一样的。【与RT1的结论相反】
语言编码 - Language encoder用的是t5-base的模型,模型参数111M,T5的全称为Text to Text Transfer Transformer,是谷歌提出的预训练语言模型领域的通用模型,该模型将所有自然语言问题都转化成文本到文本的形式,并用一个统一的模型解决。为了得到大一统的高质量预训练语言模型,T5不可避免地走上了“大力出奇迹”的道路,使用了更大的模型和更多的数据,但是模型和数据规模只是T5通往最强模型的手段之一,T5最核心的理念是:使用前缀任务声明及文本答案生成,统一所有自然语言处理任务的输入和输出。
Readout - 它在进入序列之前会处理观测和任务tokens,但并不会被任务观测和任务tokens所处理,因此它们(观测和任务tokens)只能被动地读取和处理内在的embeddings,而不能影响他们;
- 有点类似ViT里的cls token,用来作为其他token的汇总,可以认为是summary。
输出head
- 一个轻量级的“action head”被应用到与readout tokens相对应的embeddings上,用于产生所需的输出和计算扩散损失。
Transformer Backbone
- 使用一个Transformer对输入的task和observation tokens进行处理,其注意力pattern是block-wise masked:观测tokens只会和来自同一时刻或者之前时刻的观测tokens或者任务tokens发生关联,不存在的观测则会被完全mask(比如没有语言指令的数据集),这种设计使得可以方便地在微调期间增加或者减少观测或者任务。
预训练数据以及数据处理

训练混合数据包括来自各种机器人demonstration、场景和任务的数据。这些数据集不仅在机器人类型方面是异构的,而且在传感器(例如,包括或不包括腕式相机)和标签(例如,包括或不包括语言指令)方面也是异构的。数据处理主要包括数据过滤、数据平衡以及数据padding:

Data Filter
1,滤除那些不含图像观测和没有使用机械臂末端位姿变化量作为action的数据;
2,然后根据多样性和任务相关性将剩下的数据集进行排序,去除重复性较高的冗余数据、图像分辨率太低的数据和过于小众任务的数据;
data balance
3,根据任务和环境将剩余数据粗略地划分为“更多样性”和“少多样性”数据集,在训练期间将前者的权重加倍,同时降低具有许多数据点的几个大数据集的权重。
图像padding和夹爪动作对齐
- 使用zero-padding的方式对缺失的相机数据进行处理;
- Gripper的指令1代表着open,0代表close。
实验
验证目标
- Octo是否可以控制多个机器人本体,并且可以开箱即用式地解决语言和图像引导的任务?
- Octo是否可以作为一个强大的基石微调到新的任务和机器人?并比重新训练和常用的其他预训练表征更好?
- Octo的设计是否支持微调到新的观测和动作空间?
评测任务

我们在3所机构的6个真实机器人系统上对Octo进行了评估。我们的评估涵盖了各种物体交互(例如“WidowX BridgeV2”)、较长任务long task horizons (例如“Stanford Coffee”)以及精确操作(例如“Berkeley Peg Insert”)。我们评估了Octo在不使用任何预训练数据的情况下,对机器人在环境内的控制能力,以及在使用少量目标域数据(~100 demonstrations)的情况下,对机器人进行高效微调以适应新任务和环境的能力。我们还测试了在使用新观测值(“Berkeley Peg Insert”中的力矩输入)和动作空间(“Berkeley Pick-up”中的关节位置控制)的情况下进行微调的能力。
实验结论一:octo具有一定的zero-shot能力,能在某些任务上开箱即用,由于SOTA的RT1-X和RT2-X

实验结论二:可以在新领域实现高效学习

讨论和结论
存在的问题和可能的解决方法:
- 当前的Octo模型难以处理手腕相机信息,通常只使用第三视角相机微调时结果更强时,一个可能的原因是预训练数据缺乏腕部相机:只有27%的数据包含腕部相机信息,使得腕部摄像头编码器很可能训练不足。添加更多的腕部相机数据或者和第三人称相机编码器共享权重也许能提高表现;
- 我们发现language-conditioned策略与image goal conditioned策略的表现有很大差异,只有56%的预训练数据包含语言注释,这可能会降低language-conditioned策略的性能。除了在预训练组合中添加更多的语言注释数据外,也可以关注语言信息的融合策略,比如设计observation与language之间的cross attention。
将来计划
- 更好地language conditioned;
- 支持腕部相机;
- 使用更多更好的专家演示数据。
附录:一些消融尝试
有改进的尝试
- Using action chunking: We found it helpful to use “action chunking”to predict multiple actions into the future, for getting more coherent policy movements. We did not find temporal ensembling of future actions to provide additional benefits in the finetuning tasks we tested. 使用action chunking可以取得更好的预测结果
- Decreasing patch size Tokenizing images into patches of size 16 × 16 led to improved performance over patches of size 32 × 32, particularly for grasping and other fine-grained tasks. This does add compute complexity (the number of tokens is 4×), so understanding how to balance compute costs and resolution remains a problem of interest. 图像patches的设计影响也很大,16x16优于32x32
- Increasing shuffle buffer size: Loading data from 25 datasets in parallel is a challenge. Specifically, we found that achieving good shuffling of frames during training was crucial — zero-shot performance with a small shuffle buffer (20k) and trajectory-level interleaving suffered significantly. We solved this issue by shuffling and interleaving frames from different trajectories before decoding the images, allowing us to fit a much larger shuffle buffer (up to 500k). We also subsample at most 100 randomly chosen steps from each training trajectory during data loading to avoid “over-crowding” the shuffle buffer with single, very long episodes.
无改进的尝试
- MSE Action Heads: i.e., replacing our diffusion decoding head with a simple L2 loss, lead to “hedging” policies that move very slowly and e.g., fail to rotate the gripper in Bridge evals.
- Discrete Action Heads: i.e., discretizing actions into 256 bins per dimension and training with cross-entropy loss; lead to more “decisive” policies, yet often observe early grasping issues.
- ResNet Encoders: train faster as they compress the image into fewer tokens, but attain worse zero-shot performance.
- Pretrained Encoders: ImageNet pretrained ResNet encoders did not provide benefit on zero-shot evals, though may be confounded with ResNet architectures underperforming as mentioned above.
- Relative Gripper Action Representation: when aligning the gripper action representations of the different datasets, we tried (A) absolute gripper actions, i.e.,17 actions are +1 when the gripper is open and -1 if it is closed, and (B) relative gripper actions, i.e., gripper action is +1/-1 only in the timestep when the gripper opens/closes. We found that the latter tends to open/close grippers less often since most of the training data represents “do not change gripper” actions, leading to a slightly higher grasp success rate. At the same time, the relative representation led to less retrying behavior after a grasp failed, which was ultimately worse.
- Adding Proprioceptive Inputs: resulting policies seemed generally worse, potentially due to a strong correlation between states and future actions. This might be due to a causal confusion between the proprioceptive information and the target actions。
- Finetuning Language Model: In order to improve the visuo-lingual grounding of Octo we experimented with: i) varying sizes of the T5 encoder small (30M), base (111M), large (386M) and ii) finetuning the last two layers of the encoder. While using the base model resulted in better language-conditioned policies, we did not find improvements when using even larger encoders or finetuning the encoder. This might be due to the lack of rich, diverse, free-form language annotations in most of the datasets.
个人观点
octo首次向研究者展示了具身智能端到端操作大模型的理想范式:支持多种观测、多种condition输入,也支持多种action输出,且可在少量数据上实现高效率学习,支持控制多种不同型号的机器人,这个工作放在将来来看很可能是一个milestone,但目前还有着许多技术和理论问题待解决,具身智能的scaling law还在研究探索中,尤其是跨场景和跨机器人本体泛化性问题【该问题是通用具身智能需要的,在很多工业场景并不怎么需要,所以沿途下蛋还是有希望的】,这种可插拔式的架构设计有望成为具身智能端到端操作大模型的典范。
相关文章:
伯克利、斯坦福和CMU面向具身智能端到端操作联合发布开源通用机器人Policy,可支持多种机器人执行多种任务
不同于LLM或者MLLM那样用于上百亿甚至上千亿参数量的大模型,具身智能端到端大模型并不追求参数规模上的大,而是指其能吸收大量的数据,执行多种任务,并能具备一定的泛化能力,如笔者前博客里的RT1。目前该领域一个前沿工…...

昇思25天学习打卡营第17天(+1)|Diffusion扩散模型
1. 学习内容复盘 本文基于Hugging Face:The Annotated Diffusion Model一文翻译迁移而来,同时参考了由浅入深了解Diffusion Model一文。 本教程在Jupyter Notebook上成功运行。如您下载本文档为Python文件,执行Python文件时,请确…...

【Leetcode笔记】406.根据身高重建队列
文章目录 1. 题目要求2.解题思路 注意3.ACM模式代码 1. 题目要求 2.解题思路 首先,按照每个人的身高属性(即people[i][0])来排队,顺序是从大到小降序排列,如果遇到同身高的,按照另一个属性(即p…...
)
Linux 安装pdfjam (PDF文件尺寸调整)
跟Ghostscript搭配使用,这样就可以将不同尺寸的PDF调整到相同尺寸合并了。 在 CentOS 上安装 pdfjam 需要安装 TeX Live,因为 pdfjam 是基于 TeX Live 的。以下是详细的步骤来安装 pdfjam: ### 步骤 1: 安装 EPEL 仓库 首先,安…...

python+playwright 学习-90 and_ 和 or_ 定位
前言 playwright 从v1.34 版本以后支持and_ 和 or_ 定位 XPath 中的and和or xpath 语法中我们常用的有text()、contains() 、ends_with()、starts_with() //*[text()="文本"] //*[contains(@id, "xx")] //...

亲子时光里的打脸高手,贾乃亮与甜馨的父爱如山
贾乃亮这波操作,简直是“实力打脸”界的MVP啊! 7月5号,他一甩手,甩出张合照, 瞬间让多少猜测纷飞的小伙伴直呼:“脸疼不?”带着咱家小甜心甜馨, 回了哈尔滨老家,这趟亲…...

MySQL篇-SQL优化实战
SQL优化措施 通过我们日常开发的经验可以整理出以下高效SQL的守则 表主键使用自增长bigint加适当的表索引,需要强关联字段建表时就加好索引,常见的有更新时间,单号等字段减少子查询,能用表关联的方式就不用子查询,可…...

【MySQL备份】Percona XtraBackup总结篇
目录 1.前言 2.问题总结 2.1.为什么在恢复备份前需要准备备份 2.1.1. 保证数据一致性 2.1.2. 完成崩溃恢复过程 2.1.3. 解决非锁定备份的特殊需求 2.1.4. 支持增量和差异备份 2.1.5. 优化恢复性能 2.2.Percona XtraBackup的工作原理 3.注意事项 1.前言 在历经了详尽…...

【Git 】规范 Git 提交信息的工具 Commitizen
Commitizen是一个用于规范Git提交信息的工具,它旨在帮助开发者生成符合一定规范和风格的提交信息,从而提高代码维护的效率,便于追踪和定位问题。以下是对Commitizen的详细介绍。 1、Commitizen的作用与优势 规范提交信息:通过提供…...

ABB PPC902AE1013BHE010751R0101控制器 处理器 模块
ABB PPC902AE1013BHE010751R0101 该模块是用于自动化和控制系统的高性能可编程控制器。它旨在与其他自动化和控制设备一起使用,以提供完整的系统解决方案 是一种数字输入/输出模块,提供了高水平的性能和可靠性。它专为苛刻的工业应用而设计,…...
)
大模型AIGC转行记录(一)
自从22年11月chat gpt上线以来,这一轮的技术浪潮便变得不可收拾。我记得那年9月份先是在技术圈内讨论,然后迅速地,全社会在讨论,各个科技巨头、金融机构、政府部门快速跟进。 软件开发行业过去与现状 我19年决定转码的时候&…...

element-ui Tree之懒加载叶子节点强制设置父级半选效果
效果: 前言: 我们是先只展示一级的,二级的数据是通过点击之后通过服务器获取数据,并不是全量数据直接一起返回回来的。 问题: 当你设置了默认选中的子节点,但是由于刚进入页面此时tree中数据暂是没有这个…...

Java项目:基于SSM框架实现的高校共享单车管理系统分前后台【ssm+B/S架构+源码+数据库+开题报告+任务书+毕业论文】
一、项目简介 本项目是一套基于SSM框架实现的高校共享单车管理系统 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 该系统功能完善、界面美观、操作简单、…...

【Android】自定义换肤框架02之自定义AssetManager和Resource
ResourceId是如何变成对应Resource的 在上一章中,我们已经讲过,apk中有个资源索引文件 其中保存了每个资源对应的id,name,type,path 资源文件的解析,主要涉及两个类,AssetManager和Resource …...

熵权法、熵值法、熵权TOPSIS三种方法的实用场景及优劣比较
在统计分析与决策分析中,熵权法、熵值法和熵权TOPSIS是三种常用的基于信息熵理论的方法。这些方法在处理多属性或多指标决策问题时,能够客观地反映数据的内在特性和各指标的相对重要性,为科学决策提供了有力支持。 熵权法 实用场景 熵权法是一种基于信息熵的客观赋权方法…...

无人机人员搜救
人员搜救-水域救援 水域搜救:快速水面搜查 物资抛投:救生物资抛投 绳索牵引:牵引救援绳索 领航船艇:水面侦察领航 人员搜救 昼夜搜救,精准定位 水域搜救 经纬 M300 RTK 搭载禅思 H20T 能够满足全天候作业需求&a…...

目标检测算法
讯飞星火 目标检测算法是计算机视觉领域的一项核心技术,用于在数字图像或视频中识别和定位一个或多个特定对象实例。这些算法通常需要确定对象的位置(例如通过边界框)和类别(例如人、汽车、狗等)。以下是一些流行的目…...
SpringSecurity 三更草堂学习笔记
0.简介 Spring Security是Spring家族中的一个安全管理框架。相比与另外一个安全框架Shiro,它提供了更丰富的功能,社区资源也比Shiro丰富。 一般来说中大型的项目都是使用SpringSecurity来做安全框架。小项目有Shiro的比较多,因为相比与Spring…...

鸿蒙生态应用开发白皮书V3.0
来源:华为: 近期历史回顾:...
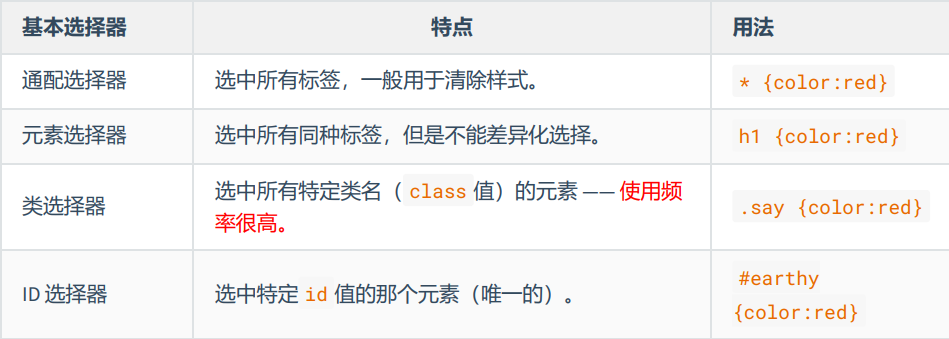
CSS - 深入理解选择器的使用方式
CSS基本选择器 通配选择器元素选择器类选择器id 选择器 通配选择器 作用:可以选中所有HTML元素。语法: * {属性名;属性值; }举例: /* 选中所有元素 */ * {color: orange;font-size: 40px; }在清除样式方面有很大作用 元素选择器…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

在Hermes Agent项目中接入Taotoken作为自定义模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Hermes Agent项目中接入Taotoken作为自定义模型供应商 基础教程类,针对使用Hermes Agent框架的开发者,详…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...

免费抓包工具选型指南:Wireshark、Fiddler、mitmproxy、Charles实战对比
1. 抓包工具不是“黑科技”,而是网络世界的显微镜很多人第一次听说“抓包”,脑子里立刻浮现出黑客电影里满屏滚动的绿色代码、键盘敲得噼啪作响、三秒破解银行防火墙的画面。其实完全不是这样——抓包(Packet Capture)本质上就是把…...

基于PIC32单片机实现Android USB音频转SPDIF输出的DIY方案
1. 项目概述:为Android设备打造一个高保真SPDIF音频接口作为一名长期折腾嵌入式音频和家庭影院的玩家,我经常遇到一个痛点:手头那些性能不错的Android手机或平板,其内置的3.5mm耳机孔或者USB-C口的音频输出质量,在连接…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...

昇腾NPU模型服务化——从离线模型到高可用推理服务
模型训练完只是第一步。真正产生业务价值的是把模型部署成724小时在线服务——毫秒级延迟、支持动态Batching、能扛住流量洪峰,且具备高可用性。 这篇将手把手教你基于昇腾NPU构建生产级模型推理服务,涵盖框架选型、服务化架构、动态Batching优化、热加载…...
)
Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环)
更多请点击: https://kaifayun.com 第一章:Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环) Lovable 方法论的核心不是交付功能,而是培育“工具依赖感”——当一线工程师在凌晨三点调试线上问题时&am…...

使用curl命令调试Taotoken API接口的常见问题排查
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令调试Taotoken API接口的常见问题排查 基础教程类,面向所有需要通过HTTP直接与API交互的开发者,…...