集中管理和分析日志:使用 ELK 套件构建强大的日志管理平台
集中管理和分析日志:使用 ELK 套件构建强大的日志管理平台
日志是监控和调试应用程序和系统的重要工具。集中管理和分析日志可以帮助你快速定位问题、了解系统运行状况和性能,并提高你的日志管理效率。ELK 是一个流行的日志管理解决方案,由 Elasticsearch、Logstash 和 Kibana 组成。Elasticsearch 是一个分布式搜索和分析引擎,Logstash 是一个日志收集和解析工具,而 Kibana 是一个可视化界面,用于查看和分析日志数据。
1. 安装 ELK 套件
ELK 套件的安装过程因操作系统而异。以下是在 Ubuntu 和 CentOS 上安装 ELK 套件的步骤。
1.1 在 Ubuntu 上安装 ELK
首先,添加 Elasticsearch 的 APT 仓库:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
更新包列表并安装 Elasticsearch:
sudo apt update
sudo apt install elasticsearch
启动 Elasticsearch 服务:
sudo systemctl start elasticsearch.service
安装 Logstash:
sudo apt update
sudo apt install logstash
安装 Kibana:
sudo apt update
sudo apt install kibana
1.2 在 CentOS 上安装 ELK
首先,添加 Elasticsearch 的 YUM 仓库:
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
sudo sh -c 'echo "[elasticsearch-7.x]" > /etc/yum.repos.d/elastic.repo'
sudo sh -c 'echo "name=Elasticsearch repository for 7.x packages" >> /etc/yum.repos.d/elastic.repo'
sudo sh -c 'echo "baseurl=https://artifacts.elastic.co/packages/7.x/yum" >> /etc/yum.repos.d/elastic.repo'
sudo sh -c 'echo "gpgcheck=1" >> /etc/yum.repos.d/elastic.repo'
sudo sh -c 'echo "gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch" >> /etc/yum.repos.d/elastic.repo'
sudo sh -c 'echo "enabled=1" >> /etc/yum.repos.d/elastic.repo'
sudo sh -c 'echo "autorefresh=1" >> /etc/yum.repos.d/elastic.repo'
sudo sh -c 'echo "type=rpm-md" >> /etc/yum.repos.d/elastic.repo'
安装 Elasticsearch:
sudo yum install elasticsearch
启动 Elasticsearch 服务:
sudo systemctl start elasticsearch.service
安装 Logstash:
sudo yum install logstash
安装 Kibana:
sudo yum install kibana
2. 配置 ELK 套件
2.1 配置 Elasticsearch
Elasticsearch 的配置文件位于 /etc/elasticsearch/elasticsearch.yml。编辑此文件以配置 Elasticsearch:
cluster.name: my-cluster
node.name: my-nodenetwork.host: 192.168.1.10
http.port: 9200discovery.seed_hosts: ["192.168.1.10"]
cluster.initial_master_nodes: ["my-node"]
重新加载 Elasticsearch 配置:
sudo systemctl reload elasticsearch.service
2.2 配置 Logstash
Logstash 的配置文件位于 /etc/logstash/logstash.yml。编辑此文件以配置 Logstash:
input {file {path => "/var/log/syslog"start_position => "beginning"}
}filter {grok {match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }}date {match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]}
}output {elasticsearch {hosts => ["192.168.1.10:9200"]index => "syslog-%{+YYYY.MM.dd}"}
}
启动 Logstash 服务:
sudo systemctl start logstash.service
2.3 配置 Kibana
Kibana 的配置文件位于 /etc/kibana/kibana.yml。编辑此文件以配置 Kibana:
server.port: 5601
server.host: "192.168.1.10"
elasticsearch.hosts: ["http://192.168.1.10:9200"]
启动 Kibana 服务:
sudo systemctl start kibana.service
3. 使用 Kibana 分析日志
在浏览器中访问 Kibana 的 Web 界面:http://<Kibana主机IP>:5601。你可以使用 Kibana 的可视化工具和搜索功能来查看和分析日志数据。
例如,你可以创建一个可视化来显示来自特定日志文件的消息数量:
- 在 Kibana 中,进入 “Visualize” 部分。
- 点击 “Create visualization”。
- 选择 “Area” 类型。
- 在 “Index pattern” 字段中,选择 “syslog-*”。
- 在 “Metrics” 部分,添加一个 “Count” 指标。
- 在 “Buckets” 部分,添加一个 “Date” 桶,并将其设置为 “Auto”。
- 点击 “Save” 保存可视化。
现在,你可以在 Kibana 中查看来自特定日志文件的日志消息数量随时间的变化。
4. 使用 Logstash 收集日志
Logstash 可以从各种来源收集日志数据,例如文件、syslog 和网络套接字。以下是一个示例 Logstash 配置,它将收集来自 /var/log/syslog 的日志数据,并将其发送到 Elasticsearch:
input {file {path => "/var/log/syslog"start_position => "beginning"}
}filter {grok {match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }}date {match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]}
}output {elasticsearch {hosts => ["192.168.1.10:9200"]index => "syslog-%{+YYYY.MM.dd}"}
}
你可以根据需要修改 Logstash 配置,例如添加其他过滤器来解析特定格式的日志数据。
5. 总结
通过安装和配置 ELK 套件,你可以构建一个强大的日志管理平台,用于集中管理和分析日志数据。这将帮助你快速定位问题、了解系统运行状况和性能,并提高你的日志管理效率。
相关文章:

集中管理和分析日志:使用 ELK 套件构建强大的日志管理平台
集中管理和分析日志:使用 ELK 套件构建强大的日志管理平台 日志是监控和调试应用程序和系统的重要工具。集中管理和分析日志可以帮助你快速定位问题、了解系统运行状况和性能,并提高你的日志管理效率。ELK 是一个流行的日志管理解决方案,由 …...

深度学习 - 模型的保存与部署方式汇总
深度学习模型保存和加载格式科普 在深度学习中,模型的保存和加载是非常重要的环节。不同的格式有不同的特点和适用场景。本文将为新手朋友们介绍几种常见的模型格式,包括它们的简介、保存方式、加载方式、优缺点以及应用场景。 1. PyTorch (.pth, .pt)…...

人工智能对网络安全有何影响?
人工智能网络安全在短期、中期和长期如何变化 当今数字时代网络安全的重要性 在谈论人工智能在网络安全中的作用时,必须首先考虑短期影响,因为它们是最明显的,而且它是一个未知的领域,需要超越直接炒作的能力。 因此࿰…...

Oracle的RECYCLEBIN回收站:轻松恢复误删对象
目录 Oracle的RECYCLEBIN回收站:轻松恢复误删对象一、概念二、工作原理三、使用方法1 查看回收站中的对象2 恢复回收站中的对象2.1 恢复表(TABLE)2.2 恢复索引(INDEX)2.3 恢复视图(VIEW)2.4 恢复…...
)
Android 内存原理详解以及优化(二)
上一篇讲了内存原理,如果还没看可以先看上一篇:Android 内存原理详解以及优化(一) 这一篇我总结一下我们经常遇到的内存优化问题: 1.内存抖动 自定义view的ondraw是会被频繁调用的,那在这个方法里面就不能频…...

Shell学习——Shell变量
文章目录 Shell变量使用变量只读变量删除变量变量类型字符串变量: 在 Shell中,变量通常被视为字符串。整数变量: 在一些Shell中,你可以使用 declare 或 typeset 命令来声明整数变量。数组变量: Shell 也支持数组&#…...
)
Java中的持续集成与持续部署(CI/CD)
Java中的持续集成与持续部署(CI/CD) 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨Java中的持续集成(Co…...

极狐GitLab 将亮相2024空天信息大会暨数字地球生态峰会,携手中科星图赋能空天行业开发者
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab :https://gitlab.cn/install?channelcontent&utm_sourcecsdn 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署…...

Beats:使用 Filebeat 从 Python 应用程序中提取日志
本指南演示了如何从 Python 应用程序中提取日志并将其安全地传送到 Elasticsearch Service 部署中。你将设置 Filebeat 来监控具有标准 Elastic Common Schema (ECS) 格式字段的 JSON 结构日志文件,然后你将在 Kibana 中查看日志事件发生的实时可视化。虽然此示例使…...
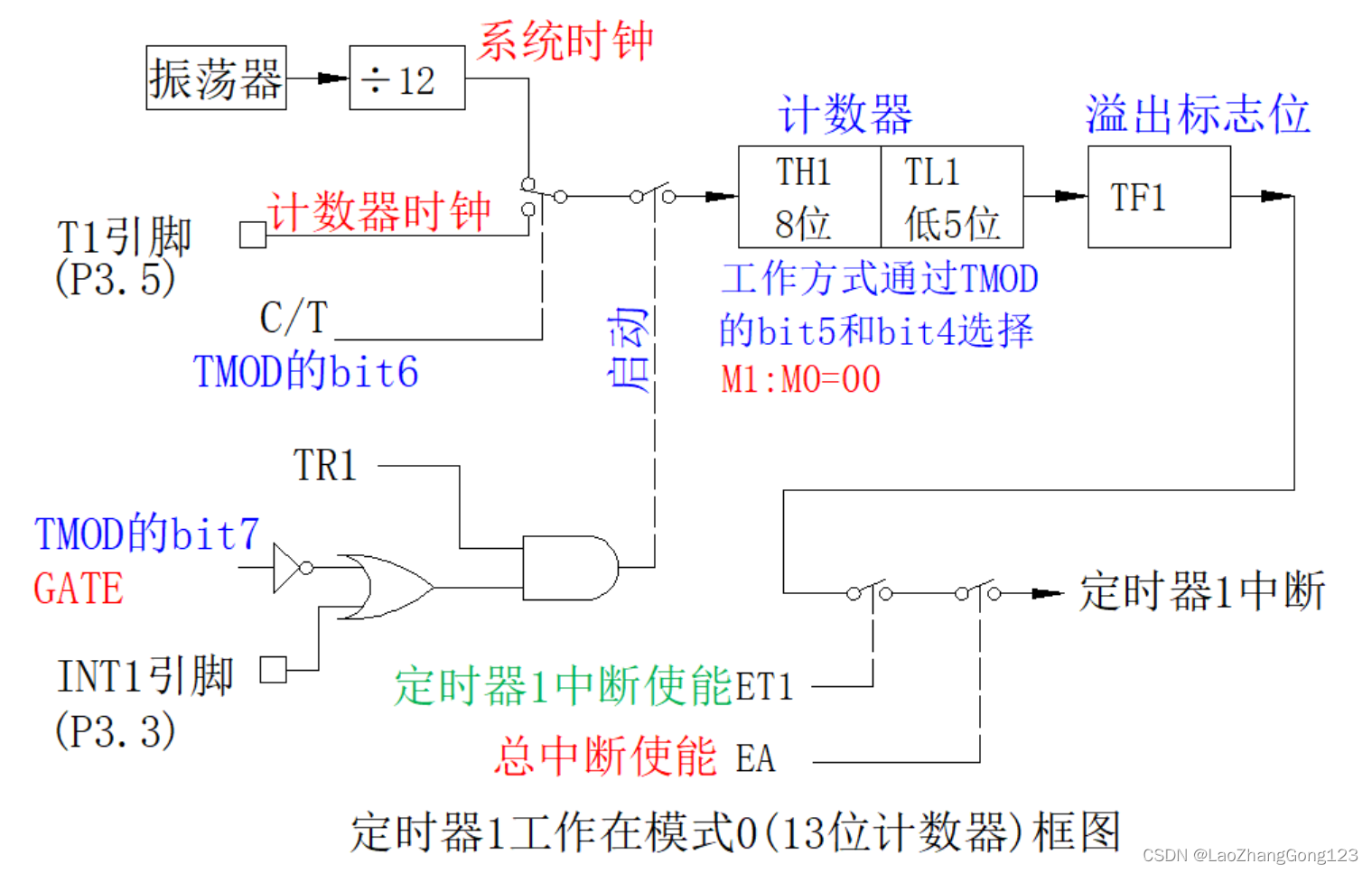
51单片机第23步_定时器1工作在模式0(13位定时器)
重点学习51单片机定时器1工作在模式0的应用。 在51单片机中,定时器1工作在模式0,它和定时器0一样,TL1占低5位,TH1占高8位,合计13位,也是向上计数。 1、定时器1工作在模式0 1)、定时器1工作在模式0的框图…...

linux的服务管理
systemd systemd 是一个系统和服务管理器,用于Linux操作系统中,旨在替代传统的Unix系统V初始化系统(SysV init)。 不一定所有使用 yum 安装的软件都可以通过 systemctl start 来管理。能否通过 systemctl start 管理取决于软件包…...

动手学深度学习(Pytorch版)代码实践 -循环神经网络-53语言模型和数据集
53语言模型和数据集 1.自然语言统计 引入库和读取数据: import random import torch from d2l import torch as d2l import liliPytorch as lp import numpy as np import matplotlib.pyplot as plttokens lp.tokenize(lp.read_time_machine())一元语法…...
)
Python 学习之自动化运维技术(八)
Python 的自动化运维技术 Python的自动化运维技术是指利用Python编程语言和相关工具实现运维工作的自动化,以提高效率、减轻工作负担。以下是对Python自动化运维技术的清晰归纳和详细介绍: 一、自动化运维的核心优势 ● 提高效率:通过自动化脚…...

【python】PyQt5可视化开发,如何设计鼠标显示的形状?
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

利用大模型知识库,优化智能客服问答效果 | 创新场景
ITValue 痛点 SSC( Share Service Center ,共享服务中心)是企业日常接触最多的场景之一,更多是对内服务,包括 HR 、财务、IT 等。该场景对专业度要求非常高,知识点非常多,对于知识的使用者或者查…...

物联网协议都包含哪些协议?
物联网协议是物联网生态系统中不可或缺的组成部分,它们负责处理和协调物联网设备之间的通信。具体介绍如下: Ethernet:以太网是一种有线网络协议,广泛应用于局域网络(LAN)中,提供稳定的高速数据传输。Wi-Fi࿱…...
】)
面试专区|【52道微服务架构高频题整理(附答案背诵版)】
简述什么是微服务? 微服务是一种软件架构风格,它将应用程序拆分成一系列小型、独立的服务,每个服务都运行在其自己的进程中,通过轻量级通信机制进行通信。每个服务都具有明确的业务能力,并且可以独立开发、测试、部署…...

数据结构之算法的时间复杂度
1.时间复杂度的定义 在计算机科学中,算法的时间复杂度是一个函数,它定量描述了算法的运行时间。一个算法所花费的时间与其中语句的执行次数成正比列,算法中的基本操作的执行次数,为算法的时间复杂度 例1: 计算Func1…...

unity中物体被激活自动执行挂载代码
在Unity中,如果希望当物体被激活时自动执行特定的函数,可以利用 MonoBehaviour 的生命周期函数 OnEnable()。这个方法会在对象被激活时调用,可以用来执行初始化或者处理其他逻辑。以下是如何在脚本中使用 OnEnable() 方法: using UnityEngine;public class ActivateFuncti…...

Pandas数据可视化详解:大案例解析(第27天)
系列文章目录 Pandas数据可视化解决不显示中文和负号问题matplotlib数据可视化seaborn数据可视化pyecharts数据可视化优衣库数据分析案例 文章目录 系列文章目录前言1. Pandas数据可视化1.1 案例解析:代码实现 2. 解决不显示中文和负号问题3. matplotlib数据可视化…...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了
AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了2026年真正值得重视的AI底层能力,是让模型知道该信谁 你有没有发现一个很扎心的变化。 以前我们用AI,最怕它不会。 现在我们用AI,最怕它太会了。 它能写…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...

【DeepSeek灰度发布黄金法则】:20年SRE亲授7步零故障上线实战框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek灰度发布策略全景图 DeepSeek模型服务的灰度发布并非简单的流量切分,而是一套融合可观测性、渐进式验证与多维熔断机制的工程化闭环体系。其核心目标是在保障线上推理稳定性的同时&…...

Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线
Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线 【免费下载链接】Style-Bert-VITS2 Style-Bert-VITS2: Bert-VITS2 with more controllable voice styles. 项目地址: https://gitcode.com/gh_mirrors/st/Style-Bert-VITS2 Style-Bert…...

机器学习的最佳实践:这7个原则让你的模型更稳定
对于软件测试从业者而言,机器学习技术正在快速融入测试流程:从自动化测试用例生成、缺陷预测到测试环境异常检测,机器学习模型的稳定性直接决定了测试结果的可靠性——如果模型在测试环境波动、输入数据变化时性能骤降,不仅无法提…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...