玩转Easysearch语法
Elasticsearch 是一个基于Apache Lucene的开源分布式搜索和分析引擎,广泛应用于全文搜索、结构化搜索、分析等多种场景。
Easysearch 作为Elasticsearch 的国产化替代方案,不仅保持了与原生Elasticsearch 的高度兼容性,还在功能、性能、稳定性和扩展性方面进行了全面提升。以下是Easysearch的基本知识和语法:
基本概念
- 节点(Node):Elasticsearch集群中的单个服务器。
- 集群(Cluster):由一个或多个节点组成,拥有唯一的集群名。
- 索引(Index):类似于关系数据库中的数据库,一个索引包含了一系列的文档。
- 类型(Type):索引中的一个逻辑分类,在Elasticsearch 6.x以后已被弃用。
- 文档(Document):索引中的基本数据单位,类似于关系数据库中的行。
- 字段(Field):文档中的一个属性,类似于关系数据库中的列。
- 分片(Shard):索引可以被分成多个分片来分布存储。
- 副本(Replica):分片的副本,用于高可用性和故障恢复。

查看集群信息
在Elasticsearch中,可以通过多个API来查看集群的各种信息,包括集群的健康状况、节点信息和索引状态。以下是一些常用的查看集群信息的API和示例:
查看集群健康状况
_cluster/health API可以查看集群的健康状态,包括集群是否处于正常状态、节点数量、分片状态等。
GET /_cluster/health
示例响应:
{"cluster_name": "my_cluster","status": "green","timed_out": false,"number_of_nodes": 3,"number_of_data_nodes": 3,"active_primary_shards": 5,"active_shards": 10,"relocating_shards": 0,"initializing_shards": 0,"unassigned_shards": 0,"delayed_unassigned_shards": 0,"number_of_pending_tasks": 0,"number_of_in_flight_fetch": 0,"task_max_waiting_in_queue_millis": 0,"active_shards_percent_as_number": 100.0
}
查看集群状态
_cluster/stats API可以查看集群的详细状态,包括索引、节点、分片等信息。
GET /_cluster/stats
示例响应:
{"cluster_name": "my_cluster","status": "green","indices": {"count": 10,"shards": {"total": 20,"primaries": 10,"replication": 1.0,"index": {"shards": {"min": 1,"max": 5,"avg": 2.0}}}},"nodes": {"count": {"total": 3,"data": 3,"coordinating_only": 0,"master": 1,"ingest": 2},"os": {"available_processors": 12,"allocated_processors": 12},"process": {"cpu": {"percent": 10},"open_file_descriptors": {"min": 100,"max": 300,"avg": 200}}}
}
查看节点信息
_nodes API可以查看集群中节点的详细信息,包括节点角色、IP地址、内存使用情况等。
GET /_nodes
示例响应:
{"cluster_name": "my_cluster","nodes": {"node_id_1": {"name": "node_1","transport_address": "192.168.1.1:9300","host": "192.168.1.1","ip": "192.168.1.1","roles": ["master", "data", "ingest"],"os": {"available_processors": 4,"allocated_processors": 4},"process": {"cpu": {"percent": 10},"open_file_descriptors": 200}},"node_id_2": {"name": "node_2","transport_address": "192.168.1.2:9300","host": "192.168.1.2","ip": "192.168.1.2","roles": ["data"],"os": {"available_processors": 4,"allocated_processors": 4},"process": {"cpu": {"percent": 15},"open_file_descriptors": 150}}}
}
查看索引状态
_cat/indices API可以查看集群中所有索引的状态,包括文档数、存储大小、分片数等信息。
GET /_cat/indices?v
示例响应:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open index_1 SxNUd84vRl6QH5P7g0T4Vg 1 1 0 0 230b 230b
green open index_2 NxEYib4yToCnA1PpQ8P4Xw 5 1 100 1 10mb 5mb
这些API可以帮助你全面了解Elasticsearch集群的状态和健康状况,从而更好地管理和维护集群。

增删改查
创建索引
PUT /my_index
{"settings": {"number_of_shards": 3,"number_of_replicas": 2}
}
删除索引
DELETE /my_index
添加文档
POST /my_index/_doc/1
{"name": "John Doe","age": 30,"occupation": "Engineer"
}
PUT /my_index/_doc/1
{"name": "John Doe","age": 30,"occupation": "Engineer"
}

新建文档
PUT /my_index/_create/1
{"a":1}
新建之后再执行报错:
{"error": {"root_cause": [{"type": "version_conflict_engine_exception","reason": "[23]: version conflict, document already exists (current version [1])","index_uuid": "1xWdHLTaTm6l6HbqACaIEA","shard": "0","index": "ss"}],"type": "version_conflict_engine_exception","reason": "[23]: version conflict, document already exists (current version [1])","index_uuid": "1xWdHLTaTm6l6HbqACaIEA","shard": "0","index": "ss"},"status": 409
}
获取文档
GET /my_index/_doc/1
更新文档
原来的字段会保留,更新age字段
POST /my_index/_update/1
{"doc": {"age": 31}
}
删除文档
DELETE /my_index/_doc/1
``#### 查询所有文档
```json
GET /my_index/_search
{"query": {"match_all": {}}
}
这个是《老杨玩搜索》里面的总结的图,可以当作“小抄”来记忆。

_bulk API用于在一次请求中执行多个索引、删除和更新操作。这对于批量处理大规模数据特别有用,可以显著提高性能和效率。以下是如何使用_bulk API的基本知识和示例:
POST /my_index/_bulk
{ "index": { "_id": "1" } }
{ "name": "John Doe", "age": 30, "occupation": "Engineer" }
{ "index": { "_id": "2" } }
{ "name": "Jane Doe", "age": 25, "occupation": "Designer" }
{ "update": { "_id": "1" } }
{ "doc": { "age": 31 } }

_bulk API的请求体由多个操作和文档组成。每个操作行包含一个动作描述行和一个可选的源文档行。动作描述行指明了操作的类型(例如,index、create、delete、update)以及操作的元数据。源文档行则包含了实际的数据。
每个操作之间需要用换行符分隔,并且请求体最后必须以换行符结尾。
POST _bulk
{ "index": {"_index":"a" ,"_id": "1" } }
{ "name": "John Doe", "age": 30, "occupation": "Engineer" }
{ "index": {"_index":"b" , "_id": "2" } }
{ "name": "Jane Doe", "age": 25, "occupation": "Designer" }
{ "update": {"_index":"a" , "_id": "1" } }
{ "doc": { "age": 31 } }
全文检索
分词器
在Easysearch中,分词器(Analyzer)用于将文本分解为词项(terms),是全文搜索和文本分析的基础。分词器通常由字符过滤器(Character Filters)、分词器(Tokenizer)和词项过滤器(Token Filters)组成。以下是关于ES分词器的详细介绍:
- 字符过滤器(Character Filters):在分词之前对文本进行预处理。例如,去除HTML标签,替换字符等。
- 分词器(Tokenizer):将文本分解为词项(tokens)。这是分词过程的核心。
- 词项过滤器(Token Filters):对词项进行处理,如小写化、去除停用词、词干提取等。

内置分词器

我们一起看下
POST /index/_mapping
{"properties": {"content": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"}}
}
-
POST /index/_mapping
- 这个部分表示要向名为
index的索引添加或更新映射设置。
- 这个部分表示要向名为
-
“properties”:
properties定义了索引中文档的字段结构。在这个例子中,定义了一个名为content的字段。
-
“content”:
- 定义了名为
content的字段。
- 定义了名为
-
“type”: “text”
type字段指定content字段的数据类型为text。text类型适用于需要分词和全文搜索的字段。
-
“analyzer”: “ik_max_word”
analyzer字段指定索引时使用的分词器为ik_max_word。ik_max_word是IK分词器中的一种,它会尽可能多地将文本分解为更多的词项。
-
“search_analyzer”: “ik_smart”
search_analyzer字段指定搜索时使用的分词器为ik_smart。ik_smart是IK分词器中的另一种,它会更智能地进行分词,以提高搜索的准确性。
当然,在设置这个mapping的时候可以使用同样的分词器,也可以使用不同的分词器。这里介绍下IK分词器:
- IK分词器是一种中文分词器,适用于中文文本的分词。IK分词器有两种分词模式:
ik_max_word和ik_smart。ik_max_word:将文本尽可能多地切分成词项,适用于需要更高召回率的场景。ik_smart:进行最智能的分词,适用于需要更高精度的搜索场景。
这个DSL的设置意味着,在向这个索引添加或更新文档时,content字段的文本会使用ik_max_word分词器进行分词处理,以确保文本被尽可能多地切分成词项。而在搜索时,content字段的文本会使用ik_smart分词器进行分词处理,以提高搜索的准确性和相关性。
以下是关于standard,ik_smart,ik_max_word这几个分词器的对比:
GET /_analyze
{"tokenizer": "standard","text": "我,机器人"
}GET /_analyze
{"tokenizer": "ik_smart","text": "我,机器人"
}GET /_analyze
{"tokenizer": "ik_max_word","text": "我,机器人"
}结果如下:
# GET /_analyze (standard)
{"tokens": [{"token": "我","start_offset": 0,"end_offset": 1,"type": "<IDEOGRAPHIC>","position": 0},{"token": "机","start_offset": 2,"end_offset": 3,"type": "<IDEOGRAPHIC>","position": 1},{"token": "器","start_offset": 3,"end_offset": 4,"type": "<IDEOGRAPHIC>","position": 2},{"token": "人","start_offset": 4,"end_offset": 5,"type": "<IDEOGRAPHIC>","position": 3}]
}
# GET /_analyze(ik_smart)
{"tokens": [{"token": "我","start_offset": 0,"end_offset": 1,"type": "CN_CHAR","position": 0},{"token": "机器人","start_offset": 2,"end_offset": 5,"type": "CN_WORD","position": 1}]
}
# GET /_analyze (ik_max_word)
{"tokens": [{"token": "我","start_offset": 0,"end_offset": 1,"type": "CN_CHAR","position": 0},{"token": "机器人","start_offset": 2,"end_offset": 5,"type": "CN_WORD","position": 1},{"token": "机器","start_offset": 2,"end_offset": 4,"type": "CN_WORD","position": 2},{"token": "人","start_offset": 4,"end_offset": 5,"type": "CN_CHAR","position": 3}]
}

如果使用了不存在的分词器会出现这个错误。
{"error": {"root_cause": [{"type": "illegal_argument_exception","reason": "failed to find global tokenizer under [simple]"}],"type": "illegal_argument_exception","reason": "failed to find global tokenizer under [simple]"},"status": 400
}
精确搜索
多字段查询
布尔查询
SQL搜索
相关文章:
玩转Easysearch语法
Elasticsearch 是一个基于Apache Lucene的开源分布式搜索和分析引擎,广泛应用于全文搜索、结构化搜索、分析等多种场景。 Easysearch 作为Elasticsearch 的国产化替代方案,不仅保持了与原生Elasticsearch 的高度兼容性,还在功能、性能、稳定性…...

【密码学】RSA公钥加密算法
文章目录 RSA定义RSA加密与解密加密解密 生成密钥对一个例子密钥对生成加密解密 对RSA的攻击通过密文来求得明文通过暴力破解来找出D通过E和N求出D对N进行质因数分解通过推测p和q进行攻击 中间人攻击 一些思考公钥密码比对称密码的机密性更高?对称密码会消失&#x…...

【ARMv8/v9 GIC 系列 5.1 -- GIC GICD_CTRL Enable 1 of N Wakeup Function】
请阅读【ARM GICv3/v4 实战学习 】 文章目录 GIC Enable 1 of N Wakeup Function基本原理工作机制配置方式应用场景小结GIC Enable 1 of N Wakeup Function 在ARM GICv3(Generic Interrupt Controller第三代)规范中,引入了一个名为"Enable 1 of N Wakeup"的功能。…...

C++怎么解决不支持字符串枚举?
首先,有两种方法:使用命名空间和字符串常量与使用 enum class 和辅助函数。 表格直观展示 特性使用命名空间和字符串常量使用 enum class 和辅助函数类型安全性低 - 编译器无法检查字符串有效性,运行时发现错误高 - 编译期类型检查…...
)
中英双语介绍四大会计师事务所(Big Four accounting firms)
中文版 “四大会计师事务所”(Big Four accounting firms)是全球最具影响力和规模最大的四家专业服务公司,它们在审计、税务、咨询和财务咨询等领域占据着主导地位。这四家公司分别是普华永道(PwC)、德勤(…...

ubuntu 查看联网配置
在Ubuntu中,你可以使用多种命令来查看联网配置。以下是一些常用的方法和命令: 查看网络接口配置: 使用 ip 命令可以查看网络接口的配置信息,包括IP地址、子网掩码等。 ip addr show或者,你也可以使用传统的 ifconfig 命…...

【数据分享】全国乡村旅游重点镇(乡)数据(Excel/Shp格式/免费获取)
之前我们分享过从我国文化和旅游部官网整理的2018-2023年我国50个重点旅游城市星级饭店季度经营状况数据(可查看之前发布的文章)!文化和旅游部官网上也分享有很多与旅游相关的常用数据,我们基于官网发布的名单文件整理得到全国乡村…...

停车场小程序的设计
管理员账户功能包括:系统首页,个人中心,车主管理,商家管理,停车场信息管理,预约停车管理,商场收费管理,留言板管理 微信端账号功能包括:系统首页,停车场信息…...
绿色金融相关数据合集(2007-2024年 具体看数据类型)
数据类型: 1.绿色债券数据:2014-2023 2.绿色信贷相关数据:2007-2022 3.全国各省及地级市绿色金融指数:1990-2022 4.碳排放权交易明细数据:2013-2024 5.绿色金融试点DID数据:2010-2023 数据来源&#…...

【matlab 项目工期优化】基于NSGA2/3的项目工期多目标优化(时间-成本-质量-安全)
一 背景介绍 本文分享了一个通用的项目工期优化的案例,决策变量是每个子项目的工期,优化目标是项目的完成时间最小,项目的总成本现值最小,项目的总安全水平最高,项目的总质量水平最高。采用的算法是NSGA2和NSGA3算法。…...

Python考前复习
选择题易错: python3不能完全兼容python2内置函数是python的内置对象之一,无需导入其他模块python中汉字变量合法,如“小李123”合法;但T-C不合法,因为有“-”集合无顺序,不能索引;range(5)[2]…...

虚拟机交叉编译基于ARM平台的opencv(ffmpeg/x264)
背景: 由于手上有一块rk3568的开发板,需要运行yolov5跑深度学习模型,但是原有的opencv不能对x264格式的视频进行解码,这里就需要将ffmpegx264编译进opencv。 但是开发板算力有限,所以这里采用在windows下,安…...

react之错误边界
错误边界实质是指什么 实际上是组件 错误边界捕获什么时候的错误 在渲染阶段的错误 错误边界捕获的是谁的错误 捕获的是子组件的错误 错误边界不能捕获什么错误 1、不能捕获异步代码 2、不能捕获事件处理函数 3、不能捕获服务端渲染 4、不能捕获自身抛出的错误 错误…...

openEuler系统之使用Keepalived+Nginx部署高可用Web集群
Linux系统之使用Keepalived+Nginx部署高可用Web集群 一、本次实践介绍1.1 本次实践简介1.2 本次实践环境规划二、keepalived介绍2.1 keepalived简介2.2 keepalived主要特点和功能2.3 使用场景三、Keepalived和Nginx介绍3.1 Nginx简介3.2 Nginx特点四、master节点安装nginx4.1 安…...

基于图像处理的滑块验证码匹配技术
滑块验证码是一种常见的验证码形式,通过拖动滑块与背景图像中的缺口进行匹配,验证用户是否为真人。本文将详细介绍基于图像处理的滑块验证码匹配技术,并提供优化代码以提高滑块位置偏移量的准确度,尤其是在背景图滑块阴影较浅的情…...

【JavaEE精炼宝库】文件操作(1)——基本知识 | 操作文件——打开实用性编程的大门
目录 一、文件的基本知识1.1 文件的基本概念:1.2 树型结构组织和目录:1.3 文件路径(Path):1.4 二进制文件 VS 文本文件:1.5 其它: 二、Java 操作文件2.1 方法说明:2.2 使用演示&…...

常用排序算法_06_归并排序
1、基本思想 归并排序采用分治法 (Divide and Conquer) 的一个非常典型的应。归并排序的思想就是先递归分解数组,再合并数组。归并排序是一种稳定的排序方法。 将数组分解最小之后(数组中只有一个元素,数组有序);然后…...
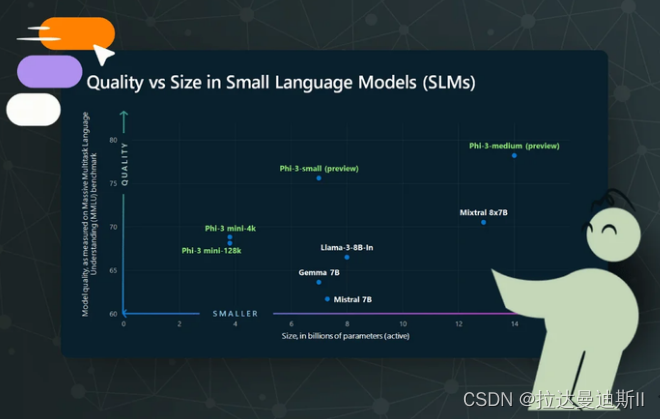
14-8 小型语言模型的兴起
过去几年,我们看到人工智能能力呈爆炸式增长,其中很大一部分是由大型语言模型 (LLM) 的进步推动的。GPT-3 等模型包含 1750 亿个参数,已经展示了生成类似人类的文本、回答问题、总结文档等能力。然而,虽然 LLM 的能力令人印象深刻…...

【Linux】:进程创建与终止
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关Linux程序地址空间的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成! C 语 言 专 栏:C语言:从…...

横截面交易策略:概念与示例
数量技术宅团队在CSDN学院推出了量化投资系列课程 欢迎有兴趣系统学习量化投资的同学,点击下方链接报名: 量化投资速成营(入门课程) Python股票量化投资 Python期货量化投资 Python数字货币量化投资 C语言CTP期货交易系统开…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

零基础轻松拿捏!魔珐星云青少年健康运动教学数字人搭建全流程指南
大家好!本次给大家分享一款面向青少年体育教育的AI创意实践项目——青少年健康运动教学智能数字交互系统。本项目聚焦青少年体质健康痛点,围绕体育教学智能化升级需求,打造集健康知识教学、运动动作陪练、健康知识考核、运动能力评测于一体的…...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案
WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案 【免费下载链接】wtfautolayout The source code for Why The Failure, Auto Layout? 项目地址: https://gitcode.com/gh_mirrors/wt/wtfautolayout 在iOS开发中,Auto Layout是构建灵…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...
)
保姆级教程:手把手教你为ESXi 6.7配置主板BIOS(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7主板BIOS设置完全指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我清楚地记得自己第一次为ESXi配置BIOS时的迷茫——那些专业术语像天书一样,生怕设置错误导致服务器无法…...

如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制
如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web…...

自然语言处理的实战项目:从0到1搭建属于自己的文本分类系统
对于软件测试从业者而言,日常工作中我们每天都会接触大量的文本数据:缺陷管理系统中的bug描述、测试用例的步骤说明、用户反馈的问题报告、需求文档的规格描述,甚至是接口返回的异常信息文本。这些非结构化文本往往隐含着关键业务信息&#x…...
)
保姆级教程:在Ubuntu 22.04上搞定水星MW310UH无线网卡驱动(含安全启动关闭指南)
水星MW310UH无线网卡在Ubuntu 22.04的完整驱动指南当你刚拿到水星MW310UH无线网卡,满心欢喜地插入Ubuntu 22.04系统,却发现系统毫无反应时,那种挫败感我深有体会。作为一款性价比极高的USB无线网卡,MW310UH在Windows下即插即用&am…...