leetcode力扣_贪心思想
455.分发饼干(easy-自己想得出来并写好)
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:输入: g = [1,2,3], s = [1,1] 输出: 1
解释: 你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。 虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。 所以你应该输出1
思路:先将饼干大小和孩子的胃口大小都排序,再一一对比...需要注意的是for中的循环条件是饼干不是孩子,孩子加一的条件是前一个孩子得到满足之后,孩子的下标i才会加一!并且一旦这个孩子得到了满足,那么饼干的下标j和孩子的下标i均要直接加1进入下一次判断。所以才有了break语句!
代码如下:
class Solution {
public:int findContentChildren(vector<int>& g, vector<int>& s) {int g_len = g.size() ;int s_len = s.size() ;int i = 0 , j = 0 ,cnt = 0;sort(g.begin(),g.end());sort(s.begin(),s.end());for(j ;j<s_len ;j++){//当饼干满足孩子后,孩子才会加一while((i<g_len) && (s[j]>=g[i])){i++;cnt++;break ;//保证一块饼干只给一个孩子}}return cnt ;}
};435.无重叠区间(hard-自己没什么思路,写不了一点)
给定一个区间的集合 intervals ,其中 intervals[i] = [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。
示例 1:
输入: intervals = [[1,2],[2,3],[3,4],[1,3]] 输出: 1 解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:
输入: intervals = [ [1,2], [1,2], [1,2] ] 输出: 2 解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:
输入: intervals = [ [1,2], [2,3] ] 输出: 0 解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
思路:自己想了一下大概只能想到需要排序,因为这是一个区间,区间怎么排序呢,按照边界排序的话,排好了之后呢?又要怎么做呢?后面就不是很明了了。看了一下官方思路结合下面万能网友的评论大概理清楚了(直接贴一下评论区的某位网友回答,感觉比官方的更容易明白)
- 关于解法二贪心算法的合理性,这里作一下补充。其实这里的难点在于理解“为什么是按照右端点排序而不是左端点排序”。
- 官解里对这个描述的非常清楚了,这个题其实是
预定会议的一个问题,给你若干时间的会议,然后去预定会议,那么能够预定的最大的会议数量是多少?核心在于我们要找到最大不重叠区间的个数。 如果我们把本题的区间看成是会议,那么按照右端点排序,我们一定能够找到一个最先结束的会议,而这个会议一定是我们需要添加到最终结果的的首个会议。(这个不难贪心得到,因为这样能够给后面预留的时间更长)。 - 这里补充一下为什么不能按照区间左端点排序。同样地,我们把本题的
区间看成是会议,如果“按照左端点排序,我们一定能够找到一个最先开始的会议”,但是最先开始的会议,不一定最先结束。举个例子:

理清楚了算法的思路再进一步完成代码的编写,还是不太会,这个sort函数的用法,搜了一下感觉搜出来的都不太一样,有点迷惑,反正先整一份正确答案先。
这种情况是使用自定义比较函数对区间进行排序,然后自定义的比较函数cmp排序准则是,按照区间右端点的升序(a[1] < b[1])进行排序。因为题目中明确说了区间是一个长度为2的数组,所以索引只有0和1,索引0指示左端点,索引1指示右端点。======== 这样排序之后就可以按照上面的思路就行进一步操作了,排序后的第一个区间肯定是需要保留的,遍历后面的区间,留下与前面区间没有重合的即可。下面的代码定义的初始右端点是INT_MIN而不是第一个区间的右端点,道理是一样的。
class Solution {
public://std::sort 期望一个静态函数或一个函数对象//故作为“自定义比较函数”应该定义为static类型//根据题目,intervals是长度为2的数组,故索引只有0和1static bool cmp(vector<int> &a, vector<int> &b){return a[1] < b[1] ;}//vector<vector<int>>& intervals表明intervals是一个二维整数向量int eraseOverlapIntervals(vector<vector<int>>& intervals) {int cnt = intervals.size() ;sort(intervals.begin(), intervals.end(), cmp) ;//使用 INT_MIN 宏来表示最小的 32 位整数值int right = INT_MIN;for(auto i :intervals){//比较新intervals的左端点与当前intervals的右端点)(right)//若左端点i[0]大于等于right,则新的intervals就不需要删除,同时更新right值if(i[0]>=right){right = i[1] ;cnt--;}}return cnt ;}};看了一下另外的解答方法:这里使用的是sort函数的默认排序方法,对于一维数组来说就是把数据按照升序排列好,但是对于区间来说,sort方法的默认排序是按照每个区间的第一个元素(起始位置)进行升序排序,如果起始位置的值是一样的,那么就按照第二个位置(结束位置)进行升序排序。
假设输入的二维数组(几个区间)为:intervals = {{1, 3}, {2, 2}, {3, 4}, {1, 2}},那么直接使用下面的sort函数进行排序,排列后的结果是intervals={{1, 2}, {1, 3} ,{2, 2}, {3, 4} }。
使用sort函数直接排序之后的进一步处理,没有第一种方法那么清晰明了,其实思路最后还是一样,都是需要不断更新区间的右端点,只是上一个右端点是按照升序拍好的,只需要看后一个区间和前一个有无重合就可以,现在这个需要自己来判断并更新右端点的值【因为排序可能会出现右端点的顺序是上面2324这样交错的】,需要理解一下,大概讲讲,意会一下:比如说你使用sort函数排序后得到了这样一组排序好的区间intervals={[1,5],[1,6],[2,3],[3,6],[4,7],[7,8]},按照代码,将排序后的第一个区间的右端点初始化为最小右端点,也就是right=5,然后从第二个区间开始遍历并更新right的值:
i=1时:intervals[1][0]=1 < right=5,表明第二个区间是和第一个区间有重合的,有重合就需要删除区间,所以cnt++,cnt=1,那删除哪个区间呢,根据上面的思想,需要删除右端点大的,保留右端点小的区间,所以就有了这句”right = min(right, intervals[i][1]);“此时right=5;
i=2时:intervals[2][0]=2 < right=5,表明第三个区间是和第二个区间有重合的,有重合就需要删除区间,所以cnt++,cnt=2,那删除哪个区间呢,根据上面的思想,需要删除右端点大的,保留右端点小的区间,所以此时right=3;
i=3时:intervals[3][0]=3 = right=3,表明第四个区间是和第三个区间是没有重合的,没有重合就要保留,就执行else中的语句,更新右端点的值,right=6,此时cnt还是等于2;
后面同理,不再赘述。最后的结果应该是,保留的区间是{[2,3],[3,6],[7,8]},cnt=3。画一个上面的那种线段区间图可以看得更清楚。
class Solution {
public:int eraseOverlapIntervals(vector<vector<int>>& intervals) {int cnt = 0;//这里排序默认是按照每个区间的第一个元素(起始位置)进行升序排序//如果起始位置相同,则按第二个元素(结束位置)进行升序排序。sort(intervals.begin(), intervals.end()) ;//将排序后的第一个区间右端点初始化为最小的右端点int right = intervals[0][1]; for (int i = 1; i < intervals.size(); i++) {//判断当前区间的左端点是否小于上一个区间的右端点//若小于 则需要删除,cnt++,同时更新if (intervals[i][0] < right) {cnt++;right = min(right, intervals[i][1]);} else {right = intervals[i][1];}}return cnt ;}
};⭐关于sort函数:
std::sort 是 C++ 标准库中的一个函数,用于对指定范围内的元素进行排序。可以通过多种方式使用 std::sort,例如按照默认顺序排序,或者使用自定义的比较函数来排序。下面是几个使用示例:
① 按照默认(升序)顺序排序,该代码的输出是:1 2 3 5 7 8
#include <iostream>
#include <vector>
#include <algorithm>int main() {std::vector<int> nums = {5, 3, 8, 1, 2, 7};std::sort(nums.begin(), nums.end());for(int num : nums) {std::cout << num << " ";}return 0;
}
② 按自定义顺序排序(降序),改代码的输出是:8 7 5 3 2 1
#include <iostream>
#include <vector>
#include <algorithm>int main() {std::vector<int> nums = {5, 3, 8, 1, 2, 7};std::sort(nums.begin(), nums.end(), std::greater<int>());for(int num : nums) {std::cout << num << " ";}return 0;
}
③ 使用自定义比较函数排序,该代码的输出是:8 7 5 3 2 1
⭐ 关于这里为什么customCompare函数又不需要定义成静态的,不是很明白,GPT又说“std::sort 函数并不要求传入的自定义比较函数必须是静态函数”可是第一版本的代码中,如果不降传入的cmp函数定义成静态的话运行是会报错的
个人猜测,第一版代码中,cmp函数是定义在类中的,然而这里是一个普通全局函数,先这样记一下吧。
#include <iostream>
#include <vector>
#include <algorithm>bool customCompare(int a, int b) {return a > b; // 降序排序
}int main() {std::vector<int> nums = {5, 3, 8, 1, 2, 7};std::sort(nums.begin(), nums.end(), customCompare);for(int num : nums) {std::cout << num << " ";}return 0;
}
④ 使用 Lambda 表达式排序,该代码的输出是:8 7 5 3 2 1
#include <iostream>
#include <vector>
#include <algorithm>int main() {std::vector<int> nums = {5, 3, 8, 1, 2, 7};std::sort(nums.begin(), nums.end(), [](int a, int b) {return a > b; // 降序排序});for(int num : nums) {std::cout << num << " ";}return 0;
}
相关文章:
leetcode力扣_贪心思想
455.分发饼干(easy-自己想得出来并写好) 假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺…...

Vue中Class数据绑定
Class数据绑定 数据绑定的一个常见需求场景是操作CSS class列表,因为class是attribute(属性),我们可以和其他attribute一样使用v-bind 将它们和动态的字符串绑定。但是,在处理比较复杂的绑定时,通过拼接生…...

Python数据分析案例49——基于机器学习的垃圾邮件分类系统构建(朴素贝叶斯,支持向量机)
案例背景 trec06c是非常经典的邮件分类的数据,还是难能可贵的中文数据集。 这个数据集从一堆txt压缩包里面提取出来整理为excel文件还真不容不易,肯定要做一下文本分类。 虽然现在文本分类基本都是深度学习了,但是传统的机器学习也能做。本案…...

贪心算法-以学籍管理系统为例
1.贪心算法介绍 1.算法思路 贪心算法的基本思路是从问题的某一个初始解出发一步一步地进行,根据某个优化测度,每一 步都要确保能获得局部最优解。每一步只考虑一 个数据,其选取应该满足局部优化的条件。若下 一个数据和部分最优解连在一起…...

PyCharm 安装
PyCharm是一种流行的Python集成开发环境(IDE),由JetBrains公司开发。它提供了丰富的功能,如智能代码补全、实时错误检查、项目导航、调试工具以及版本控制等,极大地提高了Python开发人员的工作效率。以下是PyCharm安装…...

C++:对象指针访问成员函数
使用箭头操作符 (->):ptr->function() 是最常用和推荐的方式,因为它更简洁、更直观。箭头操作符 (->) 被设计为与点操作符 (.) 配合指针一起使用,以便通过指针访问对象的成员。 先解引用指针,然后使用点操作符 (.)&…...

Linux 防火墙配置指南:firewalld 端口管理应用案例(二十个实列)
🏡作者主页:点击! 🐧Linux基础知识(初学):点击! 🐧🐧Linux高级管理专栏:点击! 🔐Linux中firewalld防火墙:点击! ⏰️…...

推荐Bulk Image Downloader插件下载网页中图片链接很好用
推荐:Bulk Image Downloader chome浏览器插件下载图片链接,很好用。 有个网页,上面放了数千的gif的电路图,手工下载会累瘫了不可。想找一个工具分析它的静态链接并下载,找了很多推荐的下载工具,都是不能分…...

详解前缀码与前缀编码
前缀编码是一种数据压缩技术,也被称为可变长度编码。它的基本原理是将频繁出现的字符或字符序列用较短的编码表示,而较少出现的字符或字符序列用较长的编码表示,从而达到压缩数据的目的。 概念定义 前缀码:给定一个编码序列的集合…...
数据库管理工具 -- Navicat Premium v17.0.8 特别版
软件简介 Navicat Premium 是一款功能强大的数据库管理工具,适用于Windows、Mac和Linux平台。它支持多种数据库,包括MySQL、MariaDB、SQL Server、PostgreSQL、Oracle、SQLite等。用户可以通过Navicat Premium轻松地连接到各种数据库服务器,…...

【Linux】进程创建和终止 | slab分配器
进程创建 fork 1.fork 之后发生了什么 将给子进程分配新的内存块和内核数据结构(形成了新的页表映射)将父进程部分数据结构内容拷贝至子进程添加子进程到系统进程列表当中fork 返回,开始调度器调度 这样就可以回答之前返回两个值?…...
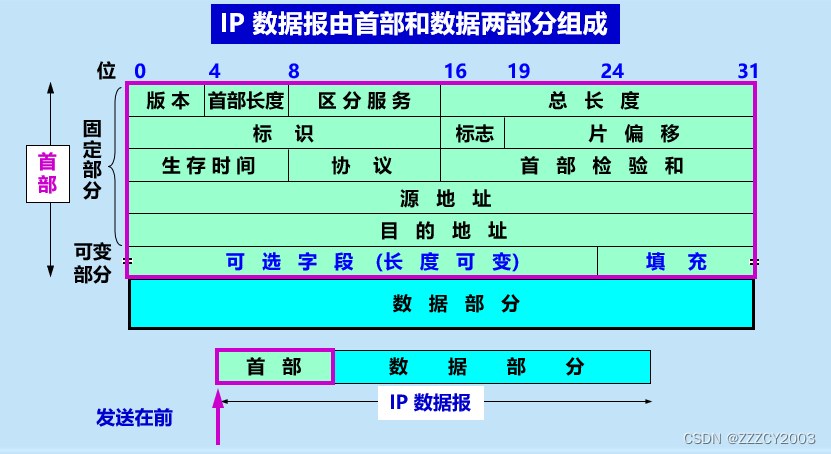
计算机网络--网络层
一、网络层的服务和功能 网络层主要为应用层提供端对端的数据传输服务 网络层接受运输层的报文段,添加自己的首部,形成网络层分组。分组是网络层的传输单元。网络层分组在各个站点的网络层之间传输,最终到达接收方的网络层。接收方网络层将运…...

【CSS】如何实现分栏布局
在CSS分栏布局中,设置宽度和样式是一个基本且重要的步骤。这可以通过直接应用样式到列元素(通常是div元素)上来实现。以下是一些常用的方法来设置分栏布局的宽度和样式: 1. 使用百分比宽度 使用百分比宽度可以使列的大小相对于其…...

2025湖北武汉智慧教育装备信息化展/智慧校园展/湖北高博会
2025武汉教育装备展,2025武汉智慧教育展,2025武汉智慧校园展,2025武汉教育信息化展,2025武汉智慧教室展,湖北智慧校园展,湖北智慧教室展,武汉教学设备展,湖北高教会,湖北高博会 2025湖北武汉智慧教育装备信息化展/智慧校园展/湖北高博会 2025第10届武汉国际教育装备及智慧校园…...

Android Studio Run窗口中文乱码解决办法
Android Studio Run窗口中文乱码解决办法 问题描述: AndroidStudio 编译项目时Run窗口中文乱码,如图: 解决方法: 依次打开菜单:Help--Edit Custom VM Options,打开studio64.exe.vmoptions编辑框…...

代码随想录——划分字母区间(Leetcode763)
题目链接 贪心 class Solution {public List<Integer> partitionLabels(String s) {int[] count new int[27];Arrays.fill(count,0);// 统计元素最后一次出现的位置for(int i 0; i < s.length(); i){count[s.charAt(i) - a] i;}List<Integer> res new Ar…...

SQL注入方法
文章目录 前言如何测试与利用注入点手工注入思路工具sqlmap-r-u-m--level--risk-v-p--threads-batch-smart--os-shell--mobiletamper插件获取数据的相关参数 前言 记录一些注入思路和经常使用的工具,后续有用到新的工具和总结新的方法再继续补充。 如何测试与利用注…...

Vue表单输入绑定v-model
表单输入绑定 在前端处理表单时,我们常常需要将表单输入框的内容同步给Javascript中相应的变量。手动连接绑定和更改事件监听器可能会很麻,v-model 指令帮我们简化了这一步骤。 <template><h3>表单输入绑定</h3><hr> <inpu…...

【分布式系统】ELK 企业级日志分析系统
目录 一.ELK概述 1.简介 1.1.可以添加的其他组件 1.2.filebeat 结合 logstash 带来好处 2.为什么使用ELK 3.完整日志系统基本特征 4.工作原理 二.部署ELK日志分析系统 1.初始化环境 2.完成JAVA部署 三. ELK Elasticsearch 集群部署 1.安装 2.修改配置文件 3.es 性…...
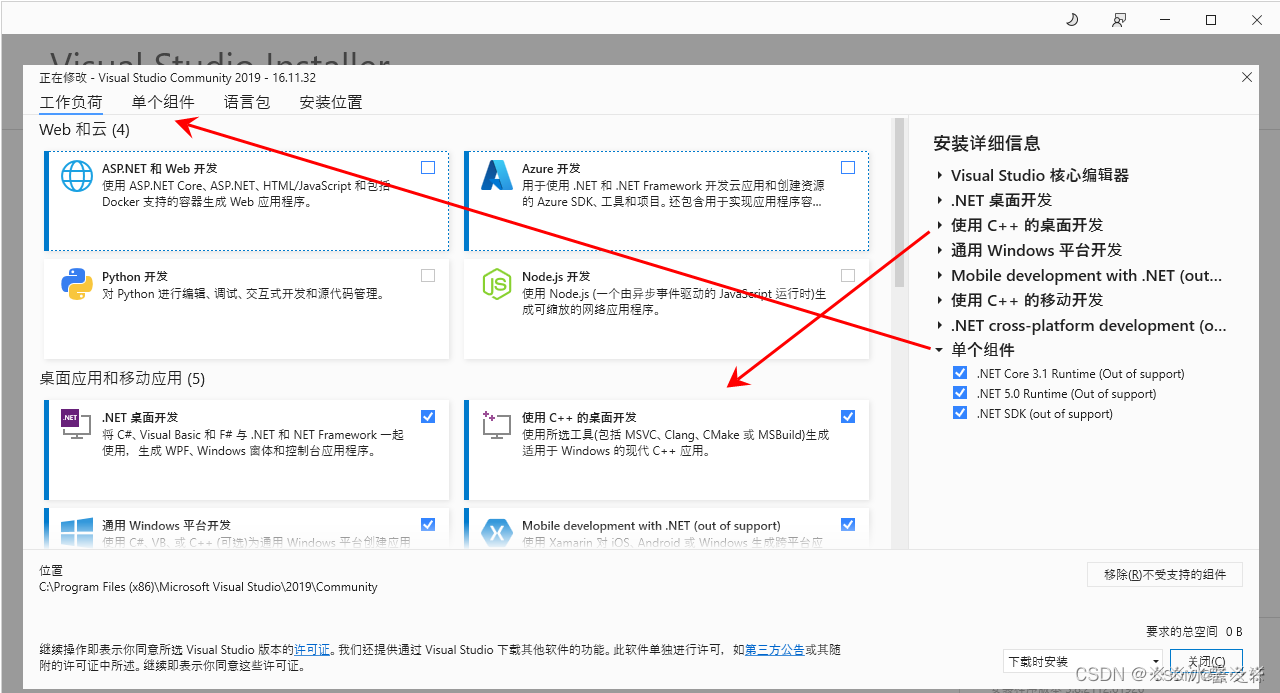
vs2019 无法打开项目文件
vs2019 无法打开项目文件,无法找到 .NET SDK。请检查确保已安装此项且 global.json 中指定的版本(如有)与所安装的版本相匹配 原因:缺少组件 解决方案:选择需要的组件进行安装完成...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...

2026论文降AI怎么挑?亲测好用工具附免费降AI指南
“您的论文AIGC率为42%,超出学校30%的合格线,请修改后重新提交。”赶毕业论文的同学这段时间估计没少收到这样的提醒。2026年知网、万方、维普等主流平台的AI检测算法持续迭代,把AI生成内容改到符合学校要求,已经成了毕业生的刚需…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

XML 服务器
XML 服务器 引言 XML(可扩展标记语言)服务器在现代互联网技术中扮演着至关重要的角色。它为数据的传输和处理提供了灵活且高效的方式。本文将深入探讨XML服务器的概念、工作原理、应用场景及其在软件开发中的重要性。 什么是XML服务器? XML服务器是一种用于存储、处理和…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...

WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案
WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...